
JMeter是一款开源的、免费的、跨平台的、用Java编写的(跨平台:Linux、Windows、嵌入书设备、电视)、可以用来做接口功能测试、接口自动化测试、性能测试的工具。
jmeter官网:Apache JMeter - Apache JMeter™
1、
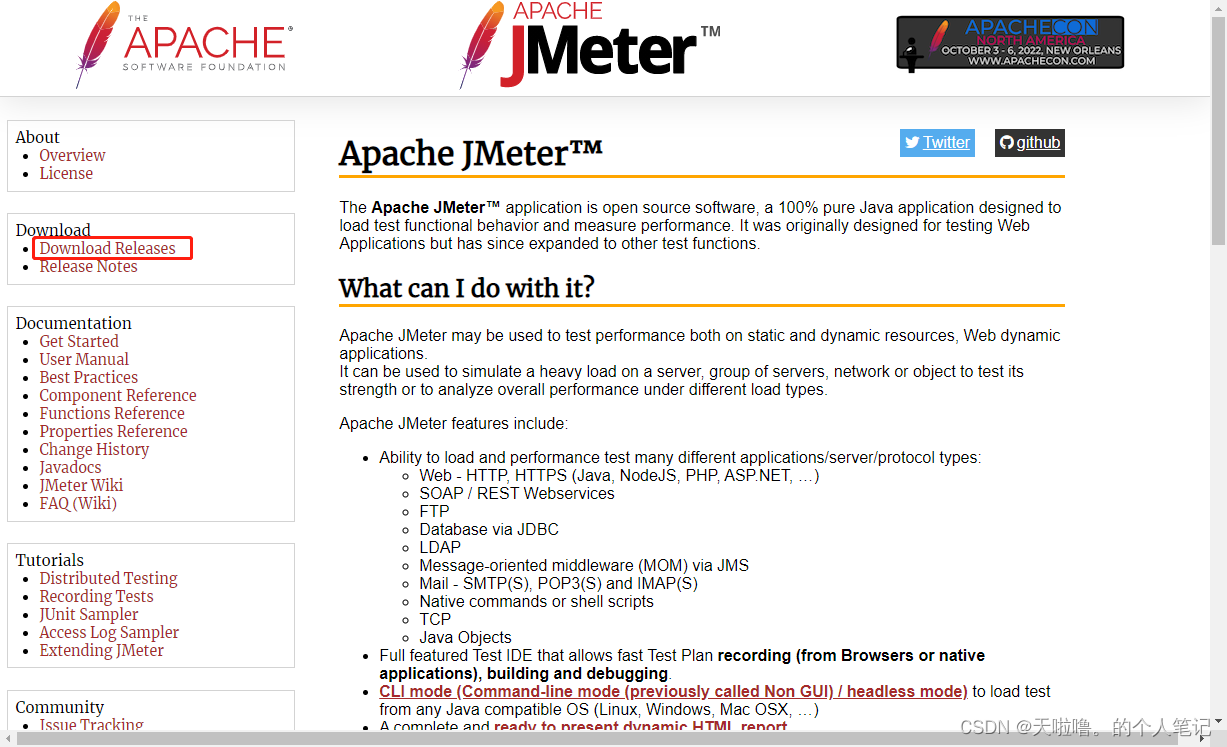
2、
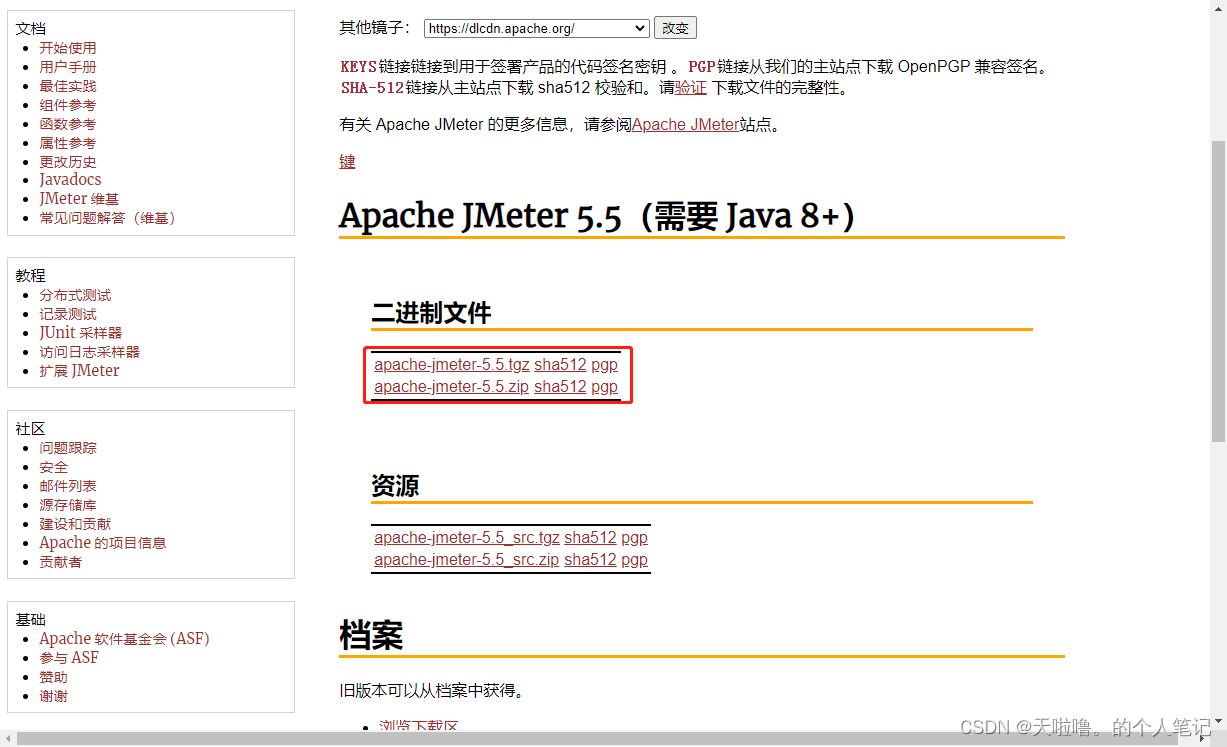
安装
因为JM是用Java写的,所以使用JMeter之前需安装jdk(Java的运行环境),需要安装jdk的版本看jmeter的版本
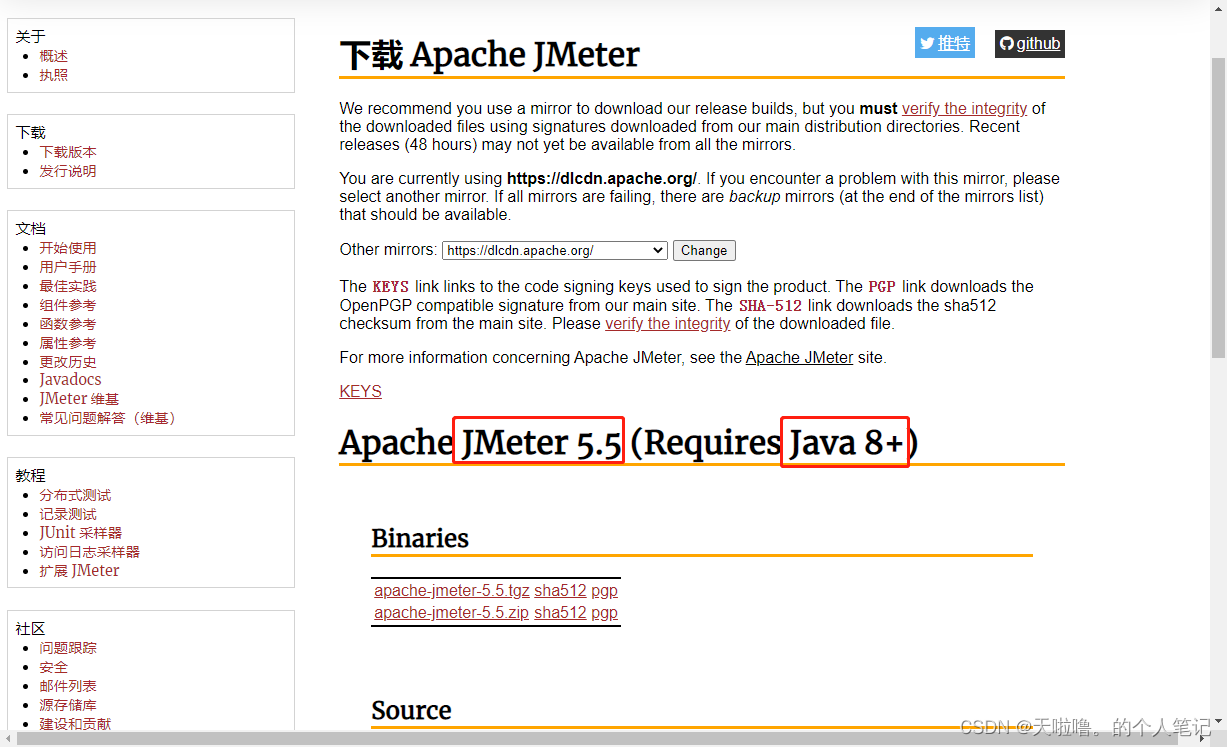
1、下JDK安装包,解压到当前文件夹

2、配置Java环境变量
右键---属性

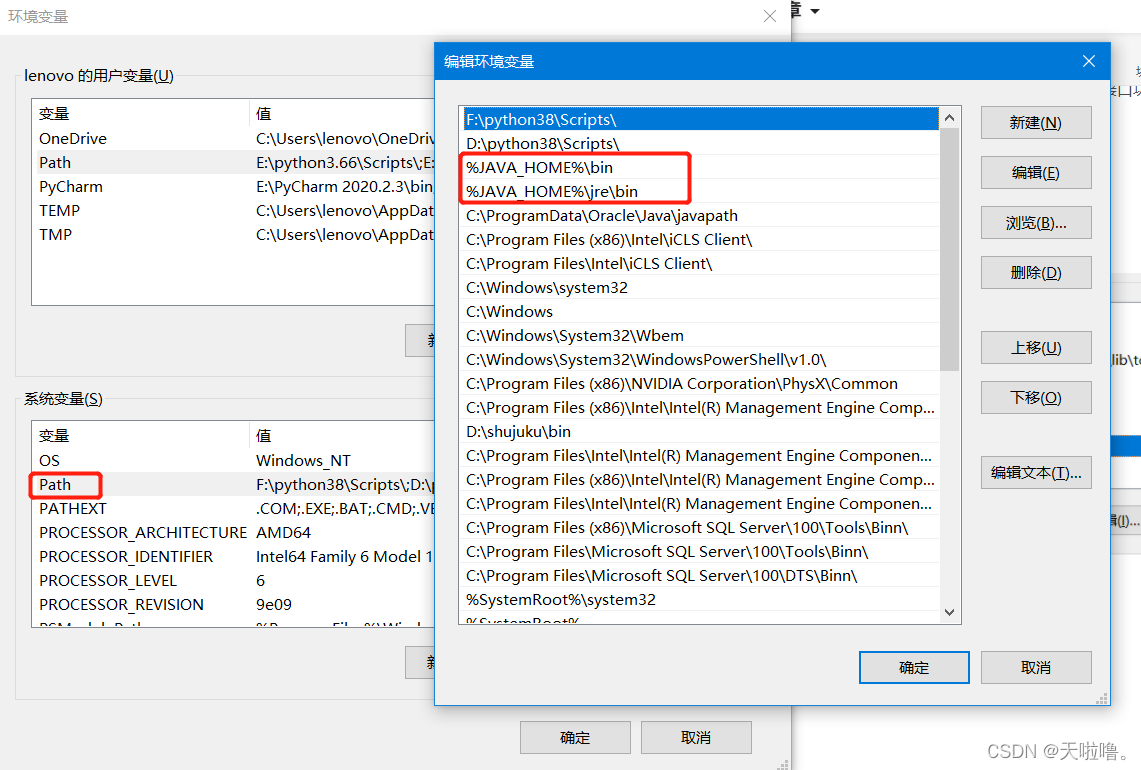
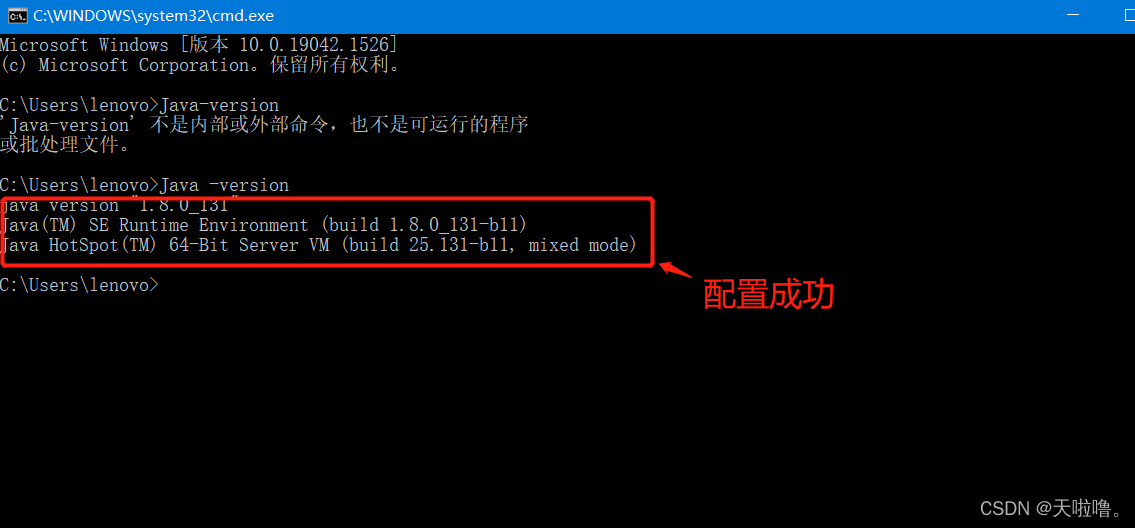
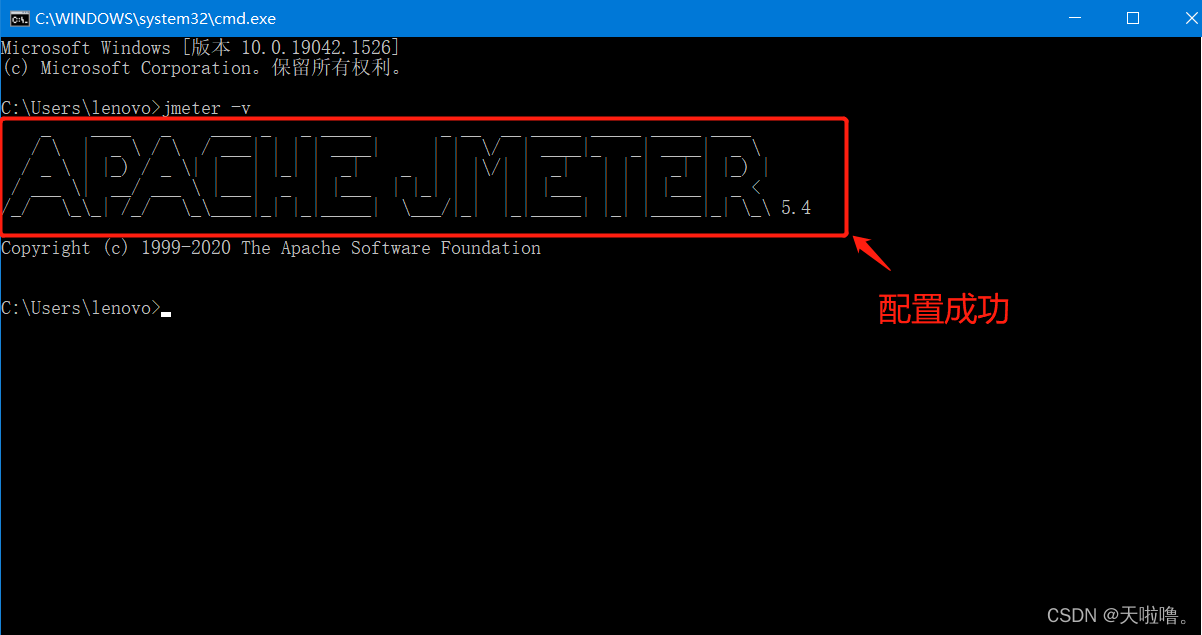
2、配jmeter环境变量配置(压测时需要用jmeter的环境变量)
解压到当前文件夹--右键--属性--高级系统设置
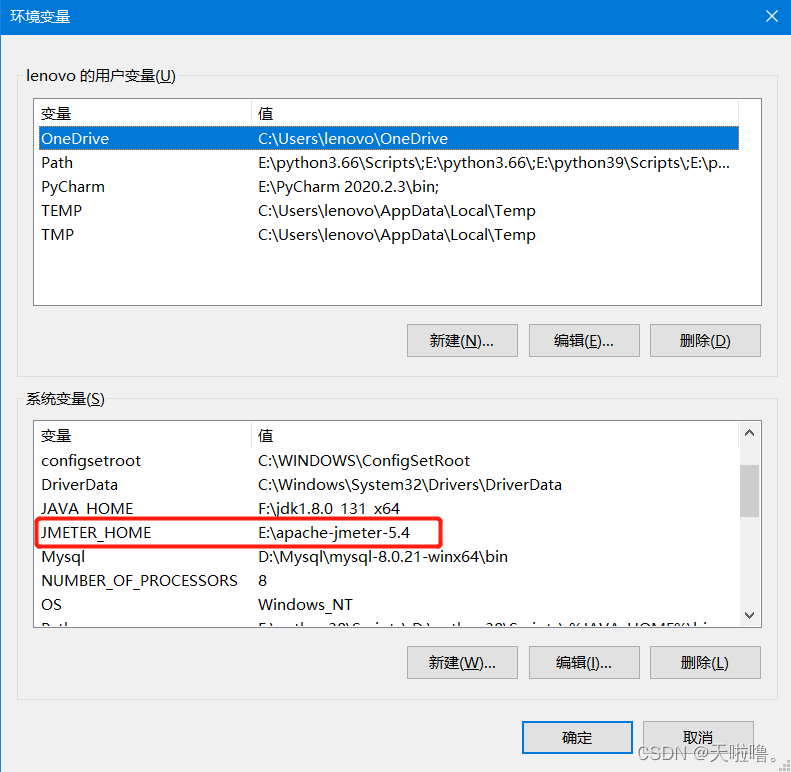
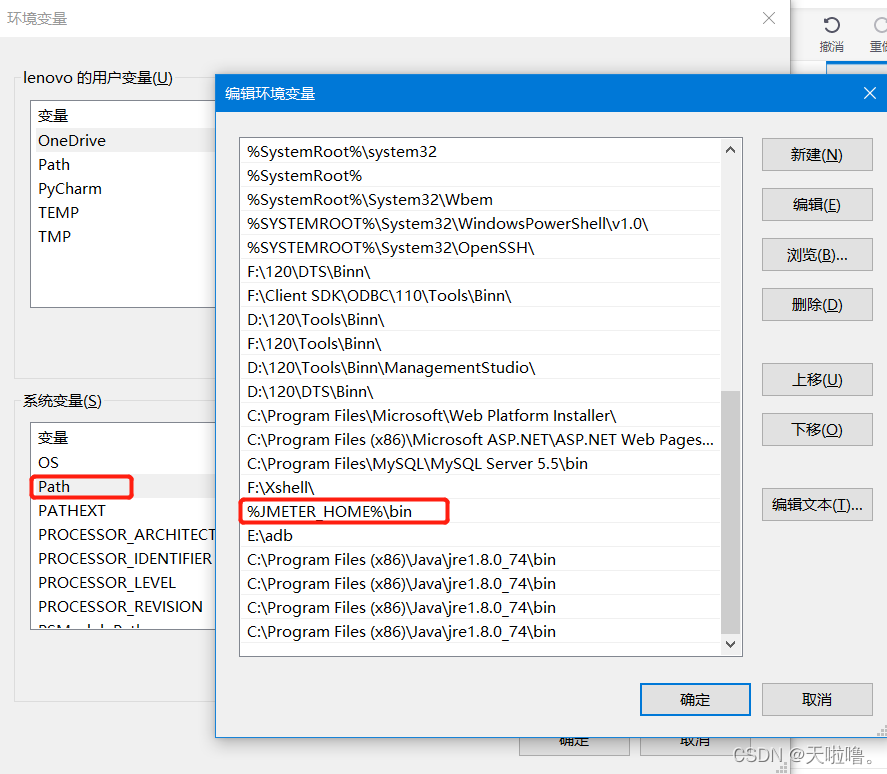
jmeter目录
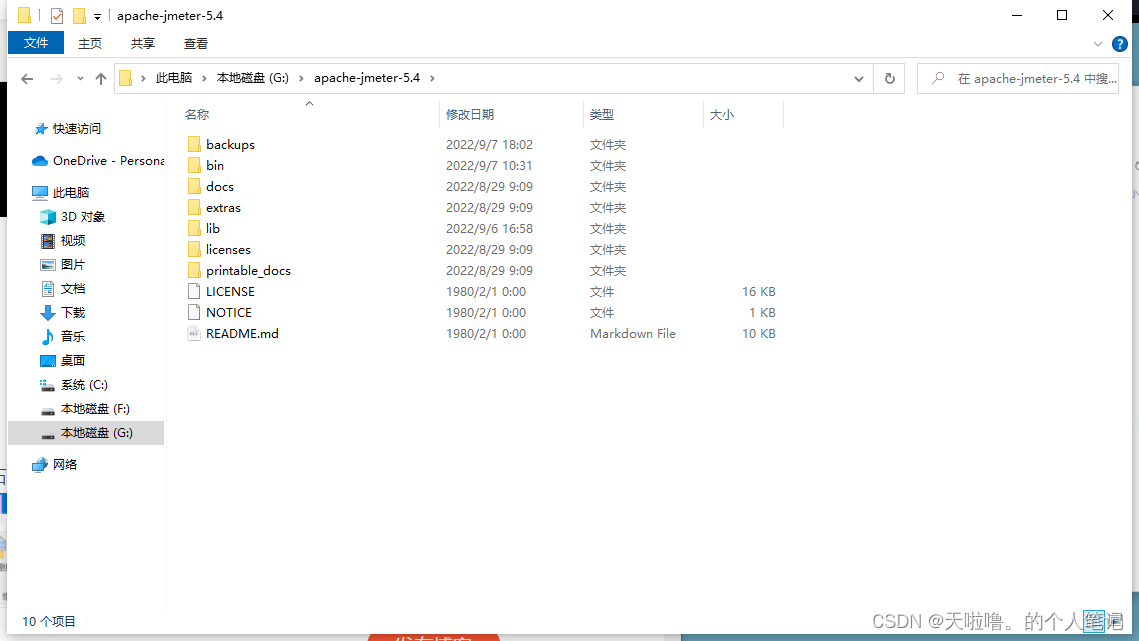
bin目录: 存可执行文件的
docs目录:存接口文档的
extras目录:做持续集成的
lib目录:存依赖的组件
licenses目录:存一些声明文件
printable_docs目录:存用户手册的,看usermanual---index_html即可,是一个离线的用户手册,jmeter里所有的功能都在里面
**运行 **
1、Windows里执行.bat(右键,发送到桌面快捷方式)
2、linux/mac里执行.sh
切换为中文
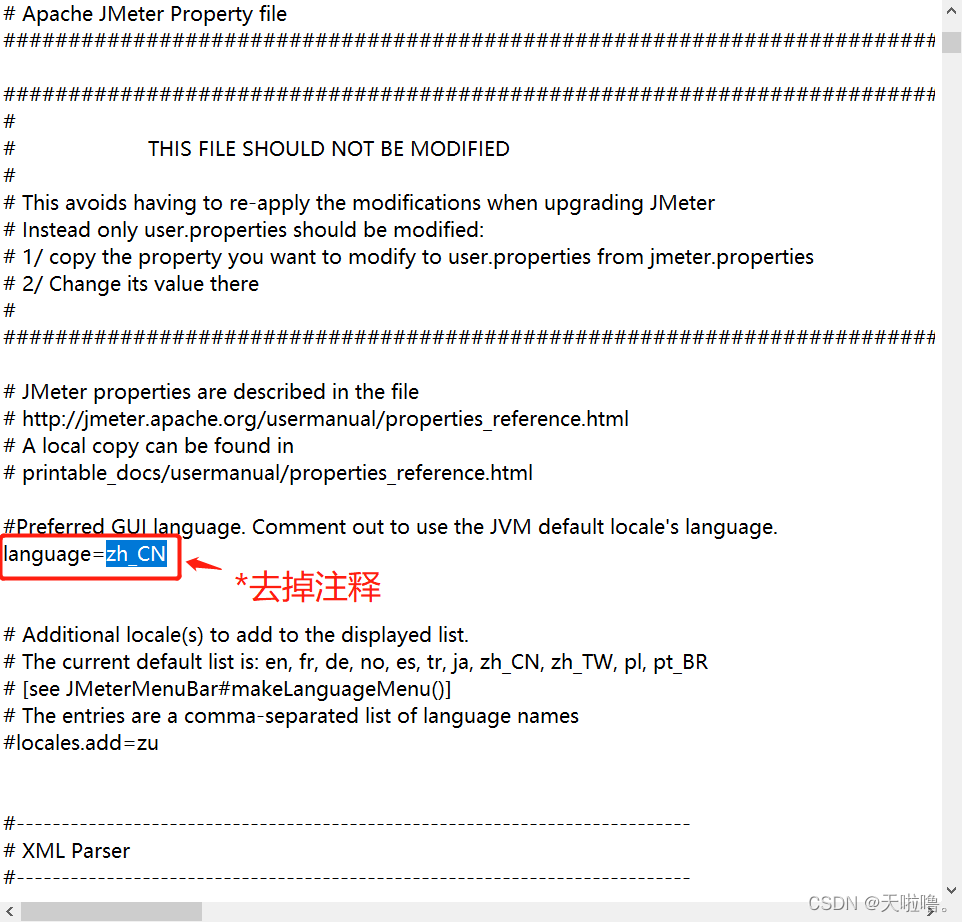
响应结果乱码
修改配置文件
进入Jmeter的bin目录下,找到jmeter.properties文件,以文本形式打开
找到sampleresult.default.encoding这个参数,此行默认是注释的
将ISO-8859-1修改成UTF-8,去掉注释符号,保存后重启Jmeter,即可解决响应数据中文乱码问题

插件管理器
往jmeter的安装目录下添加文件,然后重启jmeter
需要用到的插件

有自动化插件,支持做UI自动化,但是不用这个工具做自动化

Python做性能测试不合适
录制脚本
一、badboy录制
badboy兼容性很差(工具太老,很多网站不支持),实际工作中不会用到,但面试可能会问
1、点击图标,打开软件,默认处于录制状态
2、粘贴url,点击绿色箭头

3、导出录制好的脚本:
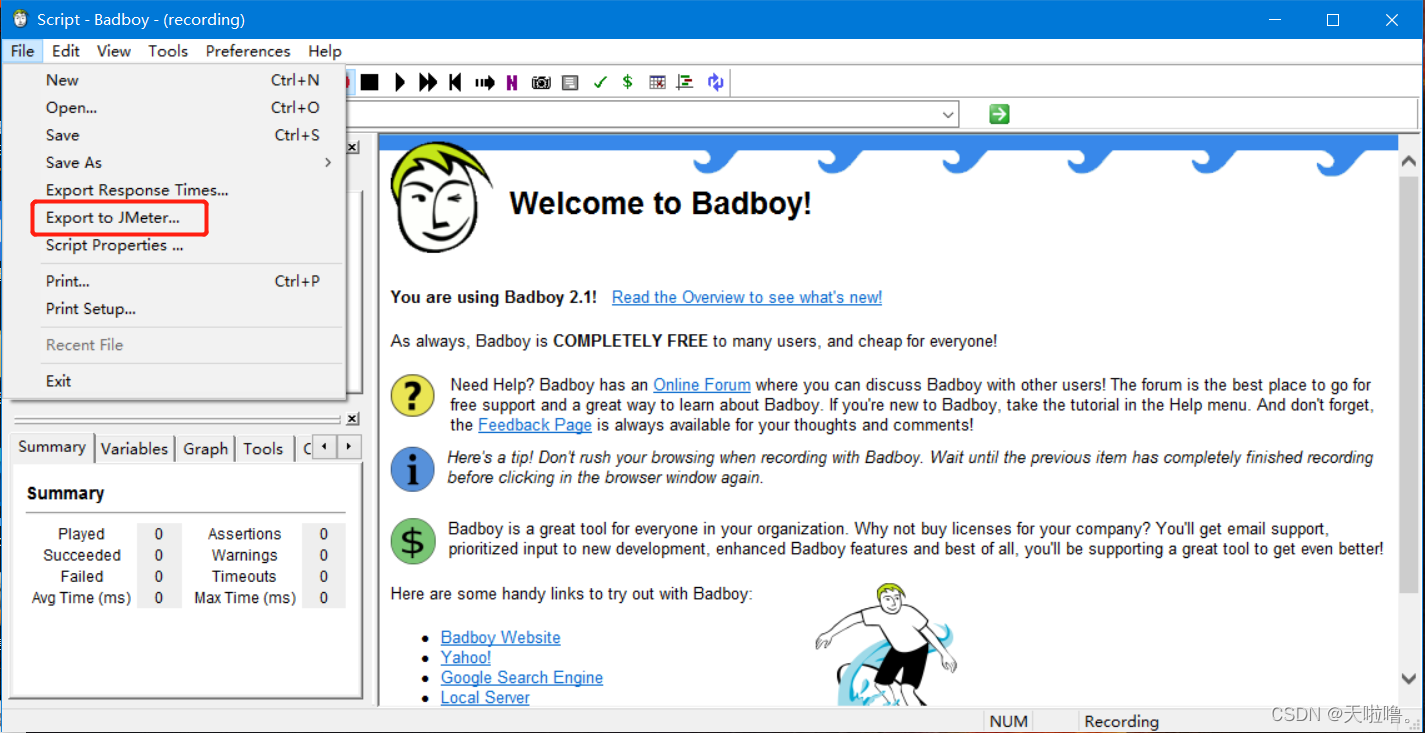
4、打开jmeter,将脚本导进去
压测的时候才需要添加聚合报告
二、jmeter设置代理录制
1、添加线程组
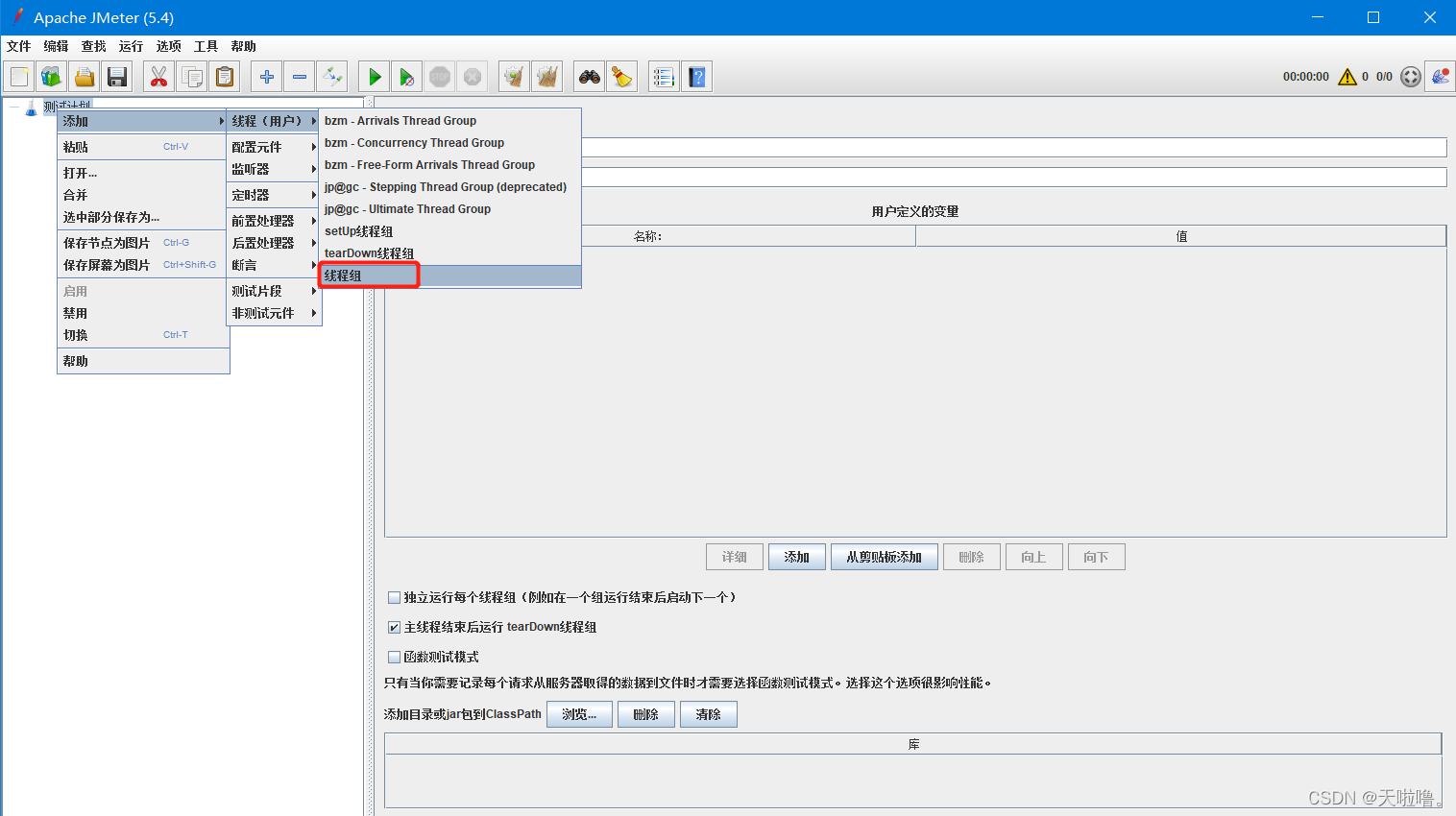
2、在线程组里添加录制控制器
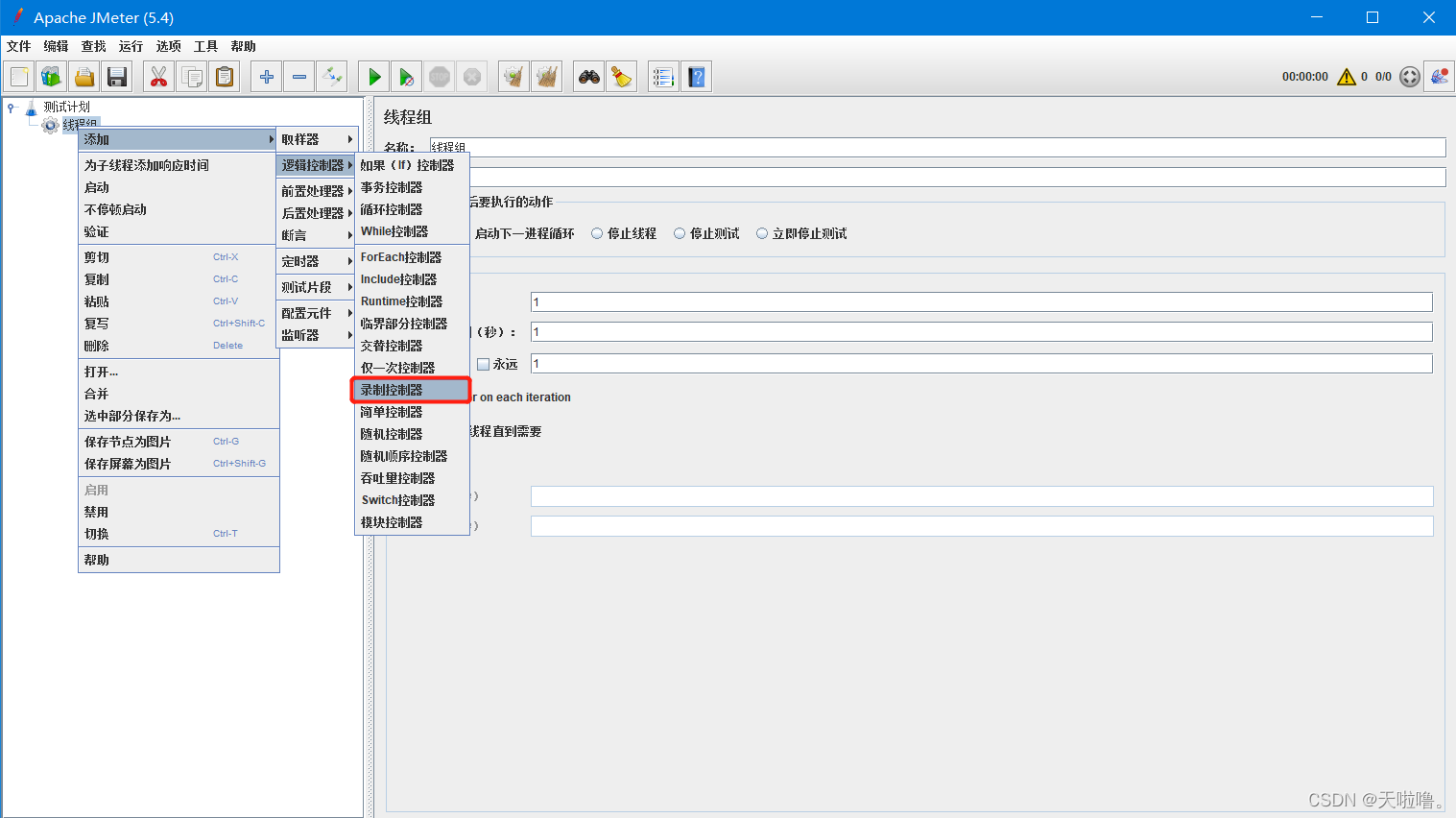
3、添加http代理服务器
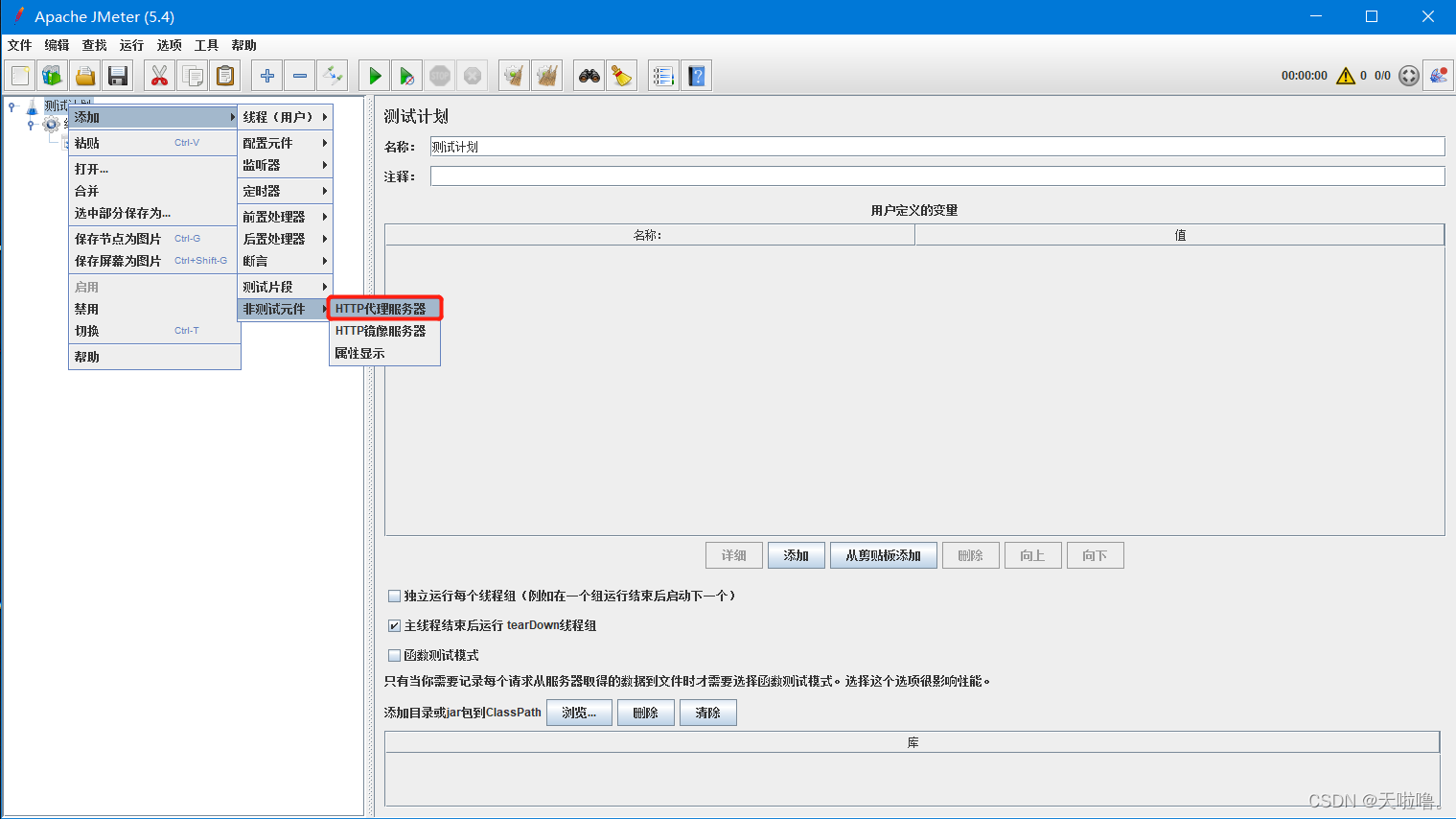
4、最好添加一个cookie管理器
5、http代理服务器里配置端口号
点击启动

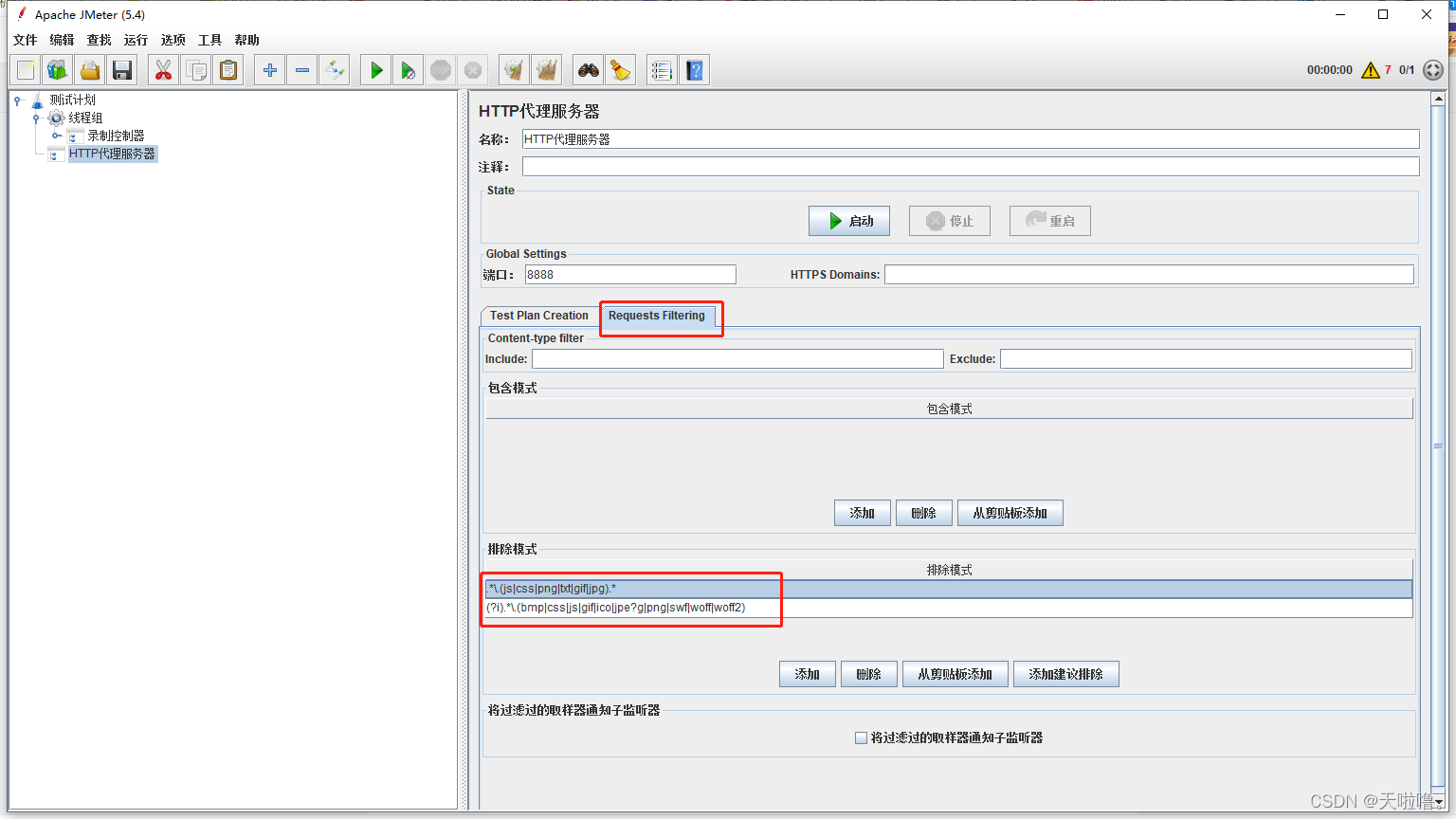
jmeter录制出来的内容太多,使用过滤功能(js、图片都没有用)
点击启动之前,在http代理服务器中设置,有些过滤不掉就再添加一行用正则:..(js|css|png|txt|gif).
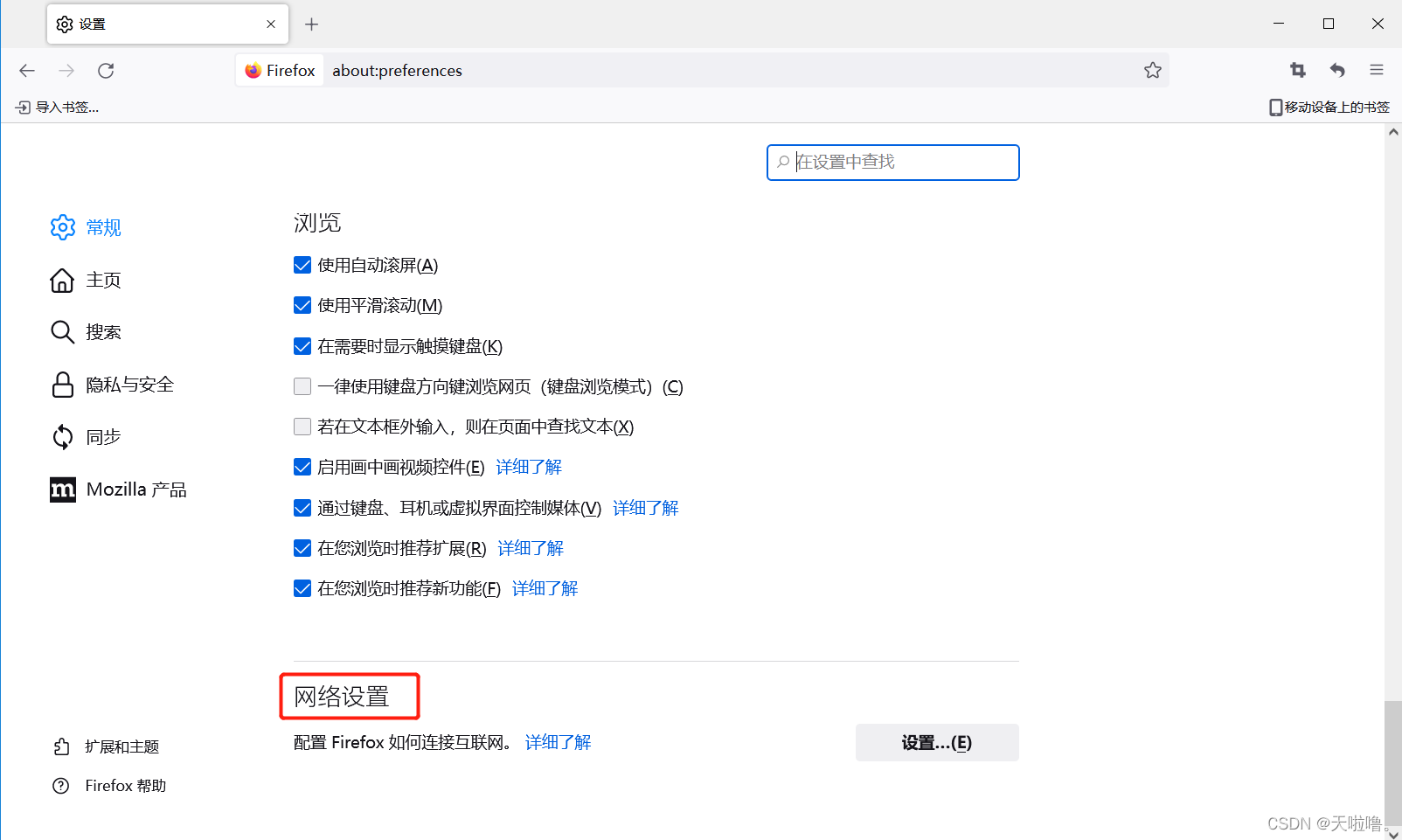
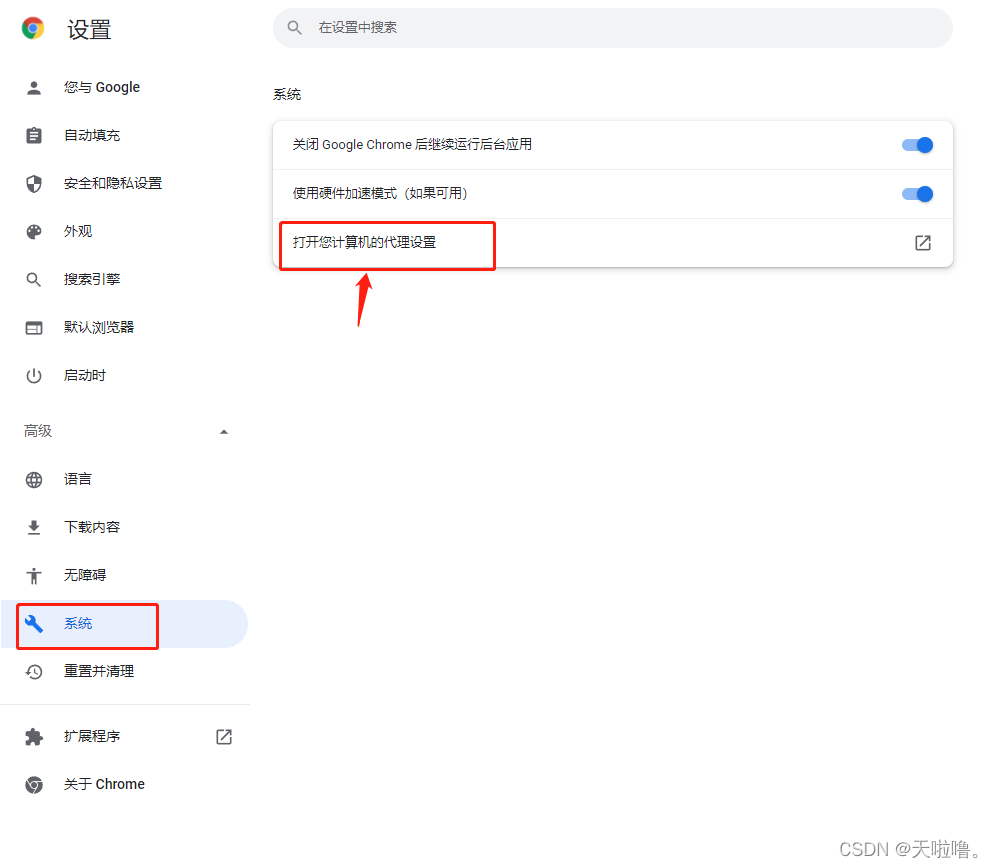
5、设置代理,录制完后要把代理改回去,不改回去jmeter一关闭浏览器就上不了网了
火狐
谷歌
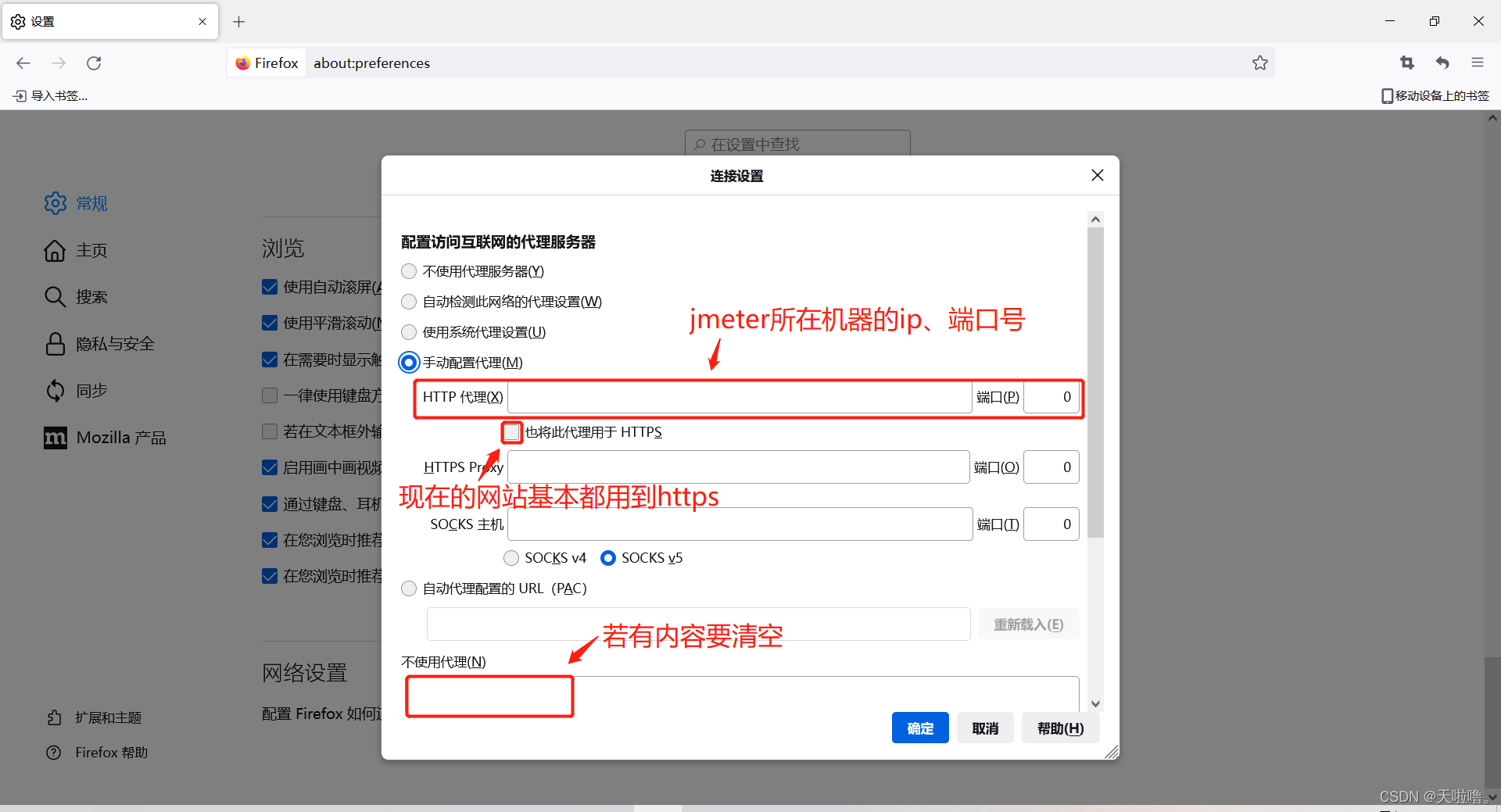
jmeter不但能录本机的还能录制远程的,只要协议是http或https都可以用jmeter录制,jmeter录制脚本不存在兼容性问题
编写脚本
组件:
1、添加线程组(线程组里的线程就是虚拟用户)
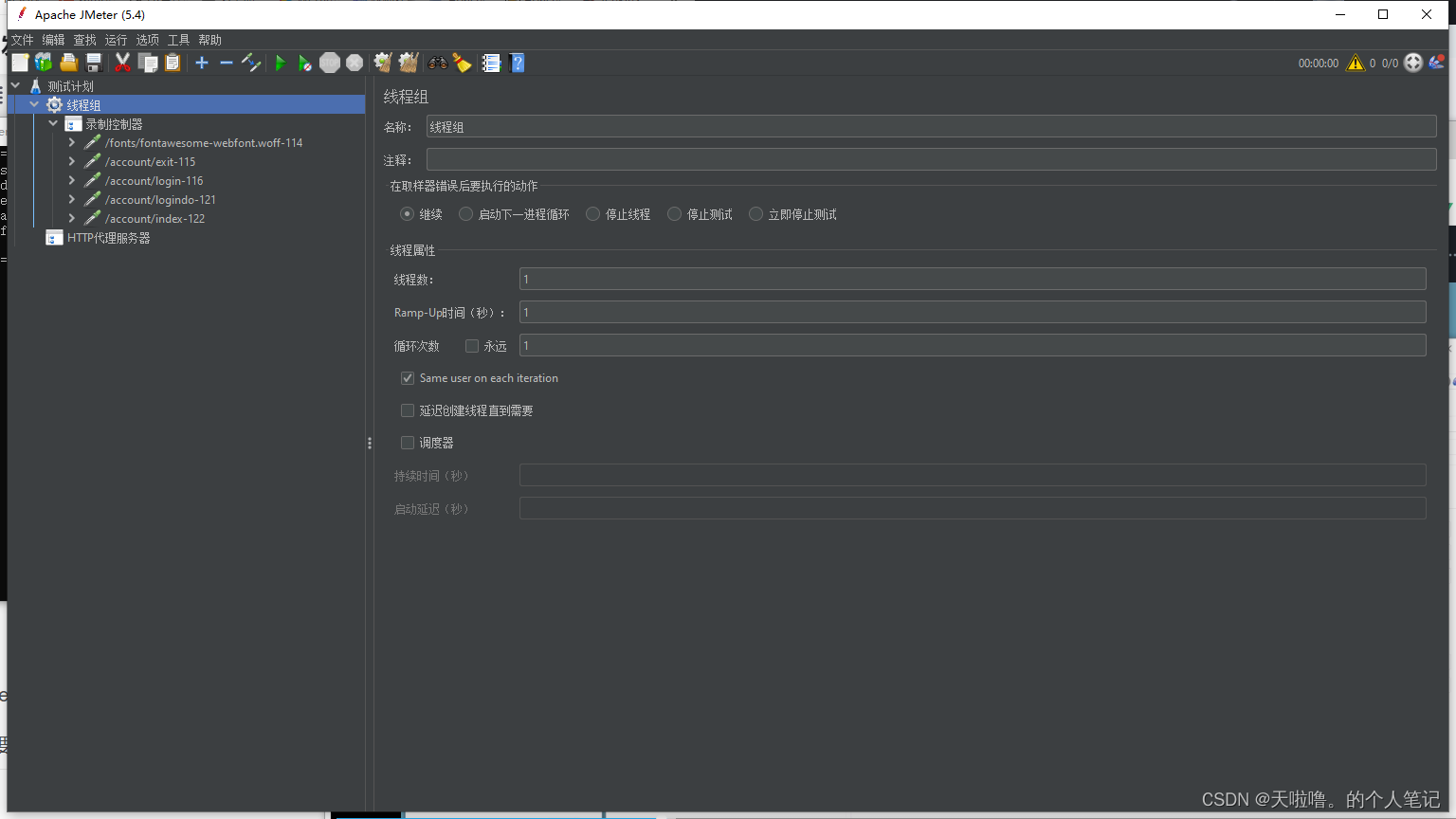
①线程数:虚拟用户数,在这设置并发是不合适的,不能保证同一时间做请求,并发用集合点
②Ramp-Up:线程启动时间。线程少的时候无所谓,线程多时要给足启动时间(不给足①耗费资源②线程起不起来)
③循环次数:迭代次数
④same user on each iteration:每次迭代使用相同的用户
⑤延迟创建线程直至需要:用到线程时才创建,线程不提前创建
⑥调度器:脚本运行的时间,按照需求勾选循环次数
2、在线程组里面添加http请求(HTTPS请求也是用http请求)

协议,默认是http;端口号,默认是80
3、http请求默认值,省去每次http请求都写IP,IP优先取取样器里的。它对同级和上级生效
4、添加cookie管理器
5、察看结果树,调试脚本时用,压测时就禁用了
参数、路径可以抓包获取
最必要的组件:线程组、取样器、断言(看是否符合需求的)
聚合报告一定得有,只要是做压测就要有监控
脚本增强(关联、参数化、检查点、集合点、思考时间)
一、思考时间
在线程组上添加定时器。定时器,在同级以及上级生效,定时器在请求发出之前生效,先等待再请求
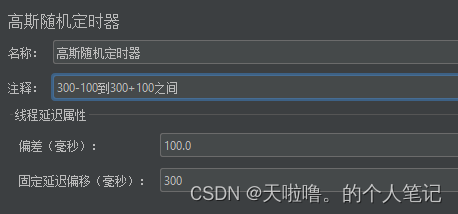
固定定时器
高斯随机定时器,固定延迟偏移,在一定的范围内随机给出思考时间
二、关联
前置处理器:在请求发出之前做的操作
后置处理器:在请求发出之后做的操作
一、提取,工作中要么用正则要么用边界提取(web端适合正则、边界,API-JSON格式适合JSON提取器)
1、正则提取(可解决工作中百分之八九十):
①在要提取的请求上添加正则表达式提取器,并填写相应配置
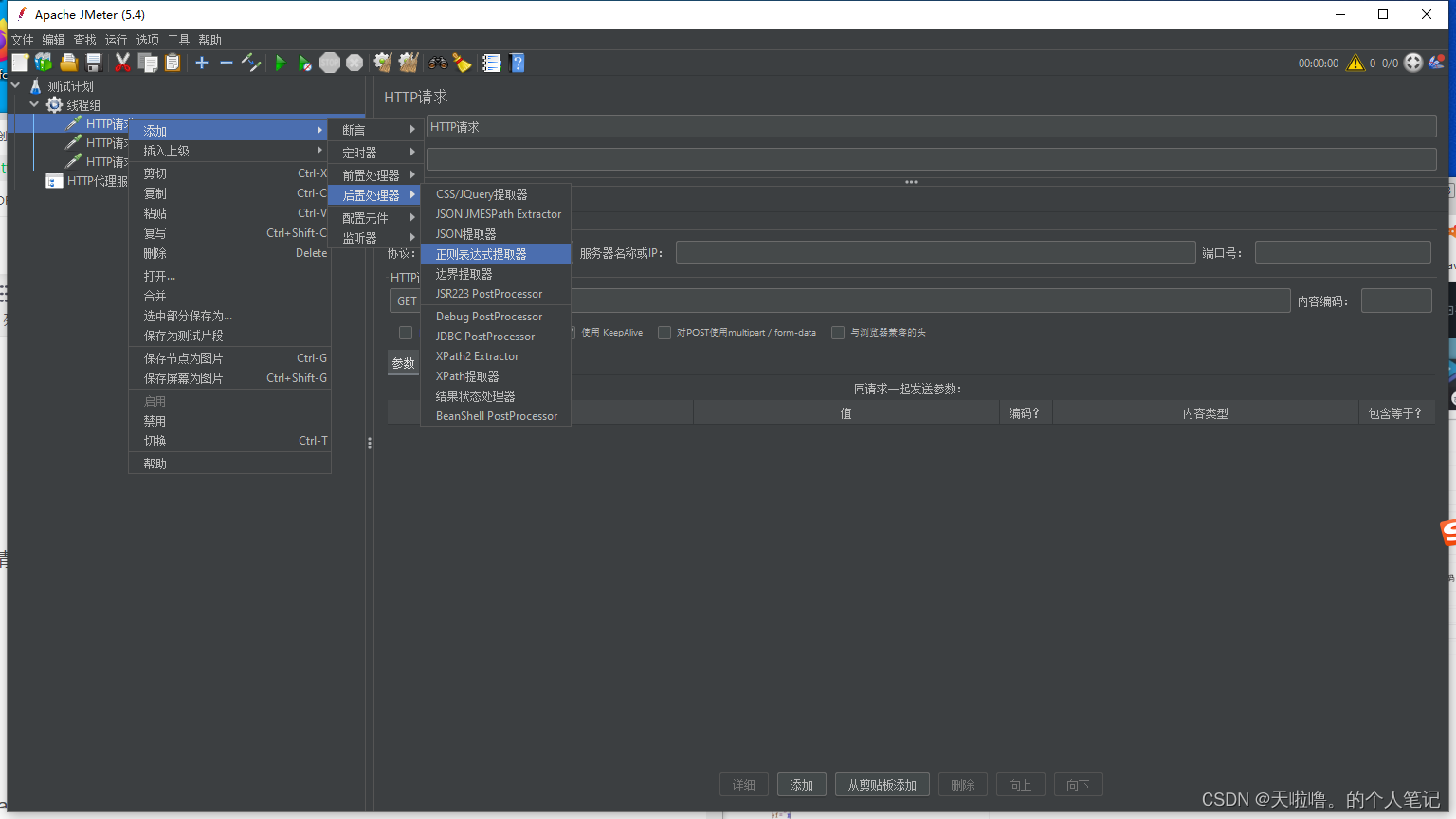
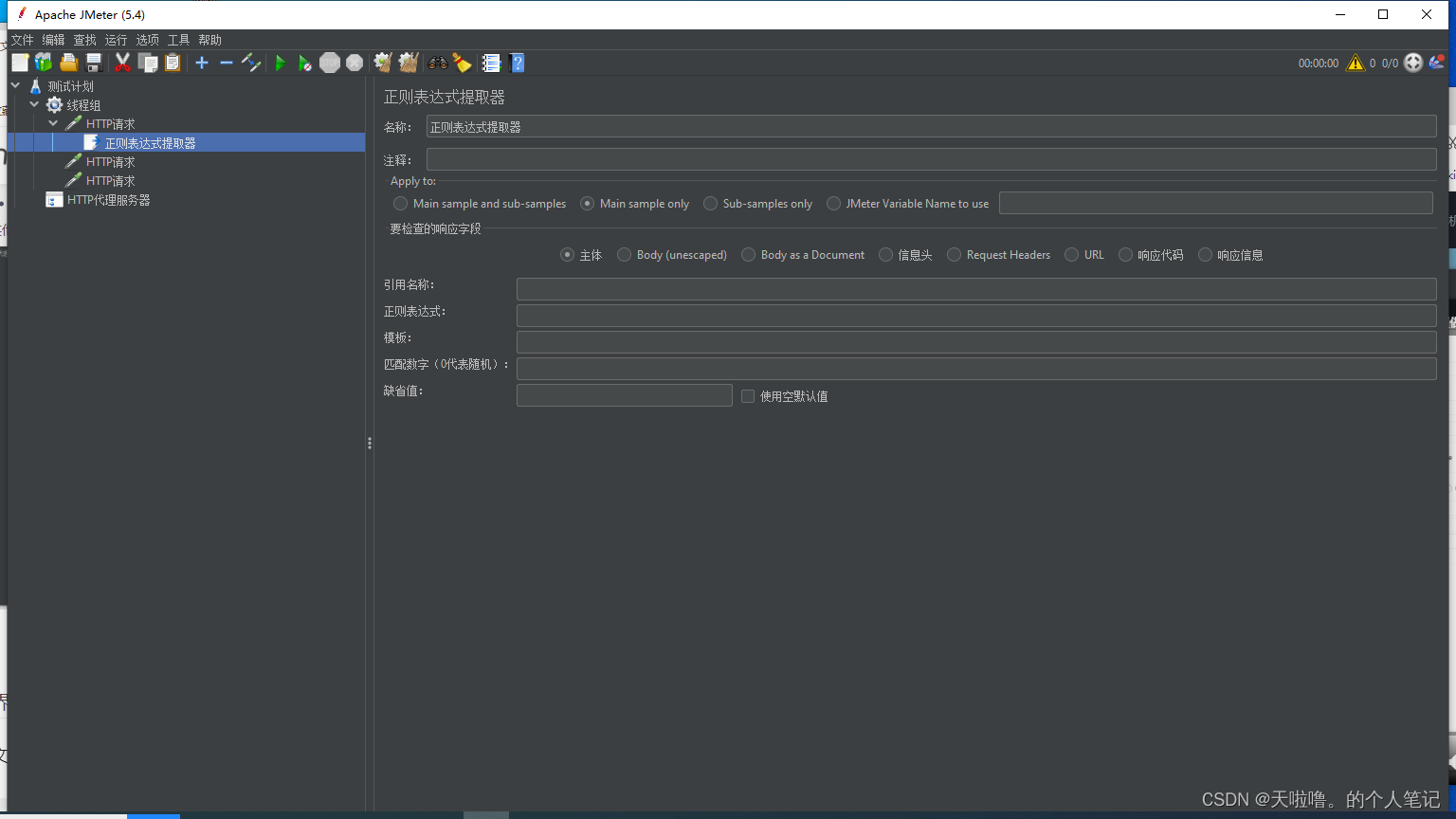
工作区简介
**Apply to **:一般用Main sample only,有子响应(网页有301、302等重定向的时候)时用Main sample and sub-samples
要检查的响应字段(基于Apply to的):一般用主体
(1)主体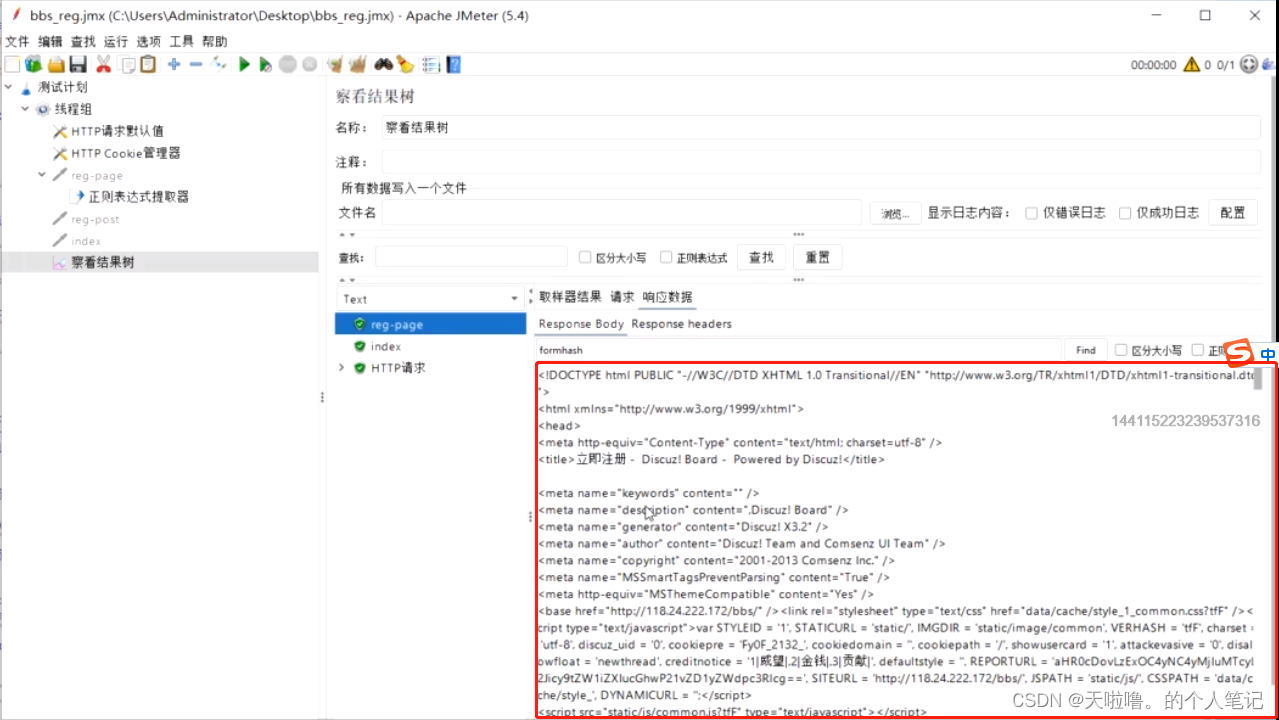
(2) Body
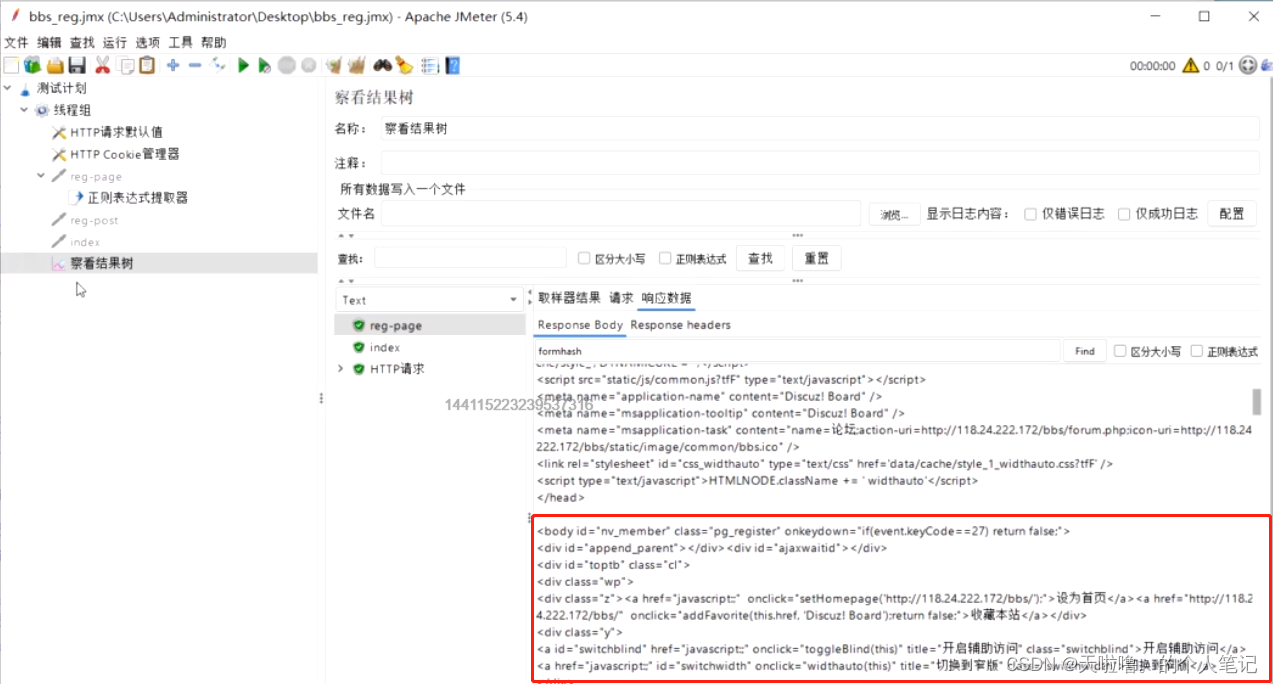
(3)Body as a Document,有的网页返回的是一篇文档
(4)信息头:
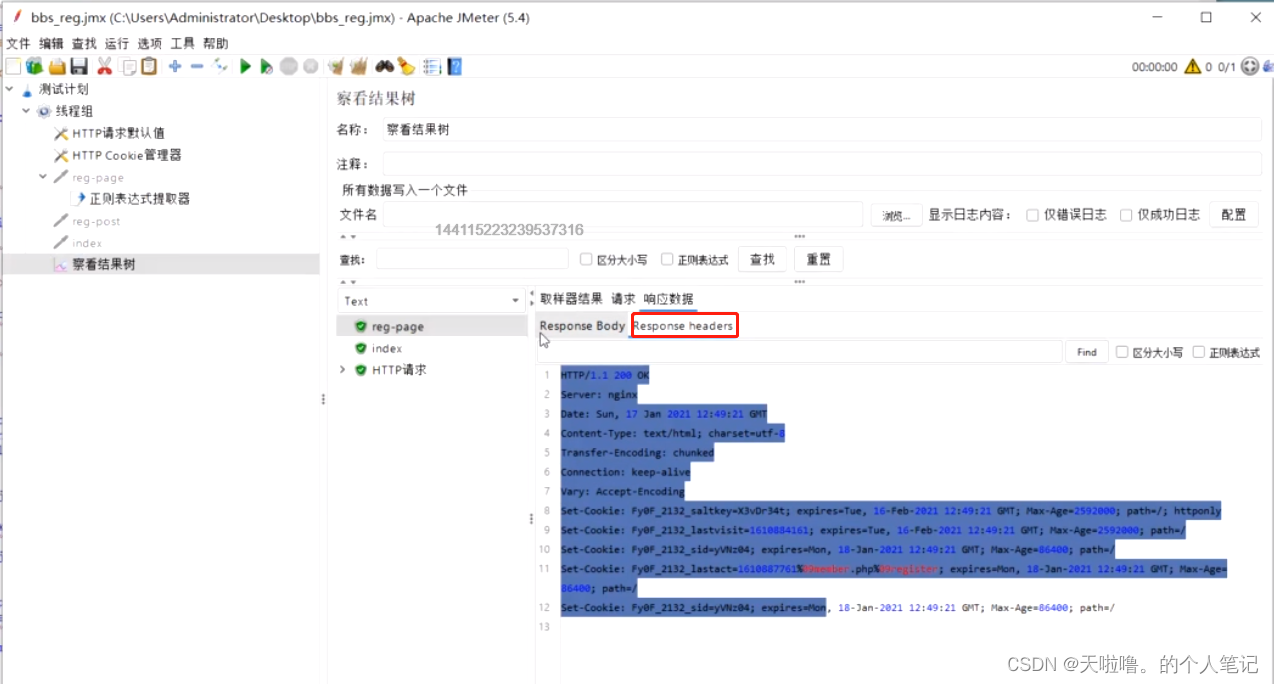
(5) URL
(6)响应代码
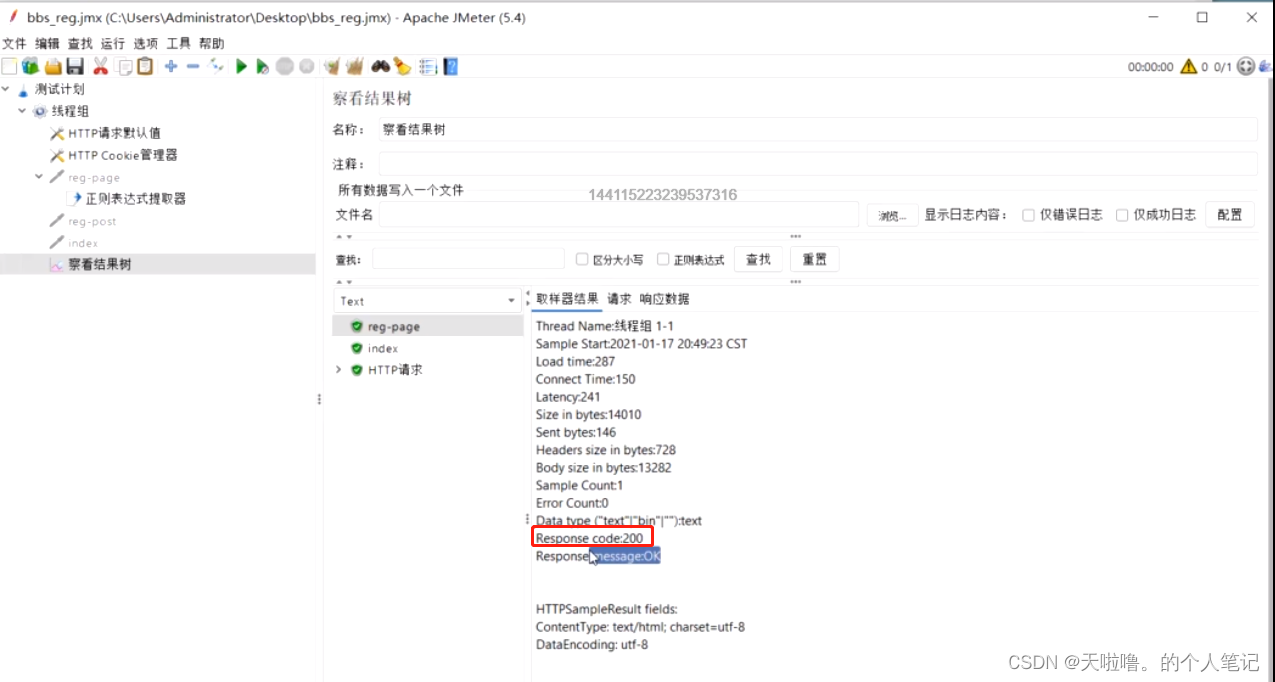
(7)响应信息

引用名称:提取到值后把值命名为这个名字
正则表达式:把要提取的粘过来(最短原则),把想要提取的值用**(.*?)**替换掉,支持提取多个地方,但是不要在一个表达式里提取多个值,可以多添加提取器,一个提取器提一个值
模板:填$1$,代表要提取正则表达式里第一个要提取的地方
匹配数字:1代表提取到后选择第一个值,2代表第二个,-1代表全要
缺省值:提取不到返回的值,可以填null
②调试,在线程组里添加DebugSamplet,就可以在查看结果树里看有没有提取到值

③上游请求提取到数据后,在下游请求里引用数据,${引用名称}
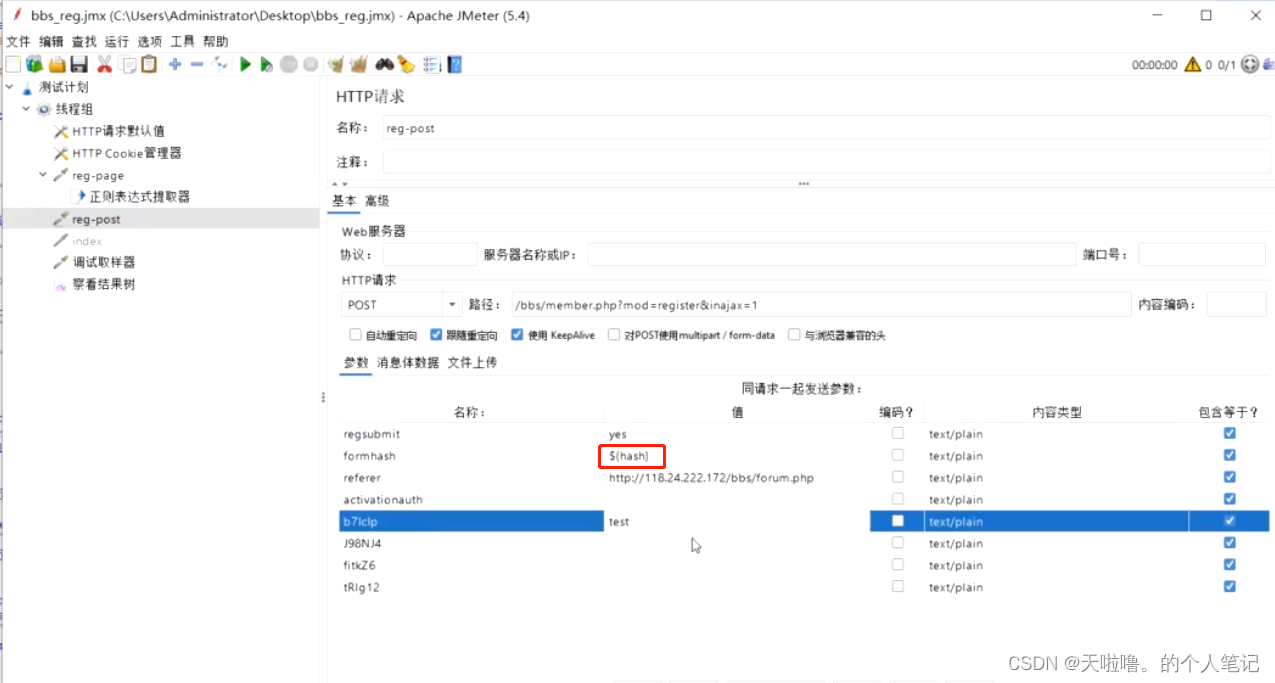
2、边界提取
①在上游请求添加边界提取器,并填写相应配置

工作区和正则表达式提取器类似
左边界:要提取的值的左边
右边界:要提取的值的右边
②③和正则提取步骤一致,注意首尾空格,多了空格会导致提取不到值
3、JSON提取,接口测试时用合适
看响应结果用JSON Path Tester

怎么提取key对应的value?例如提取jinghuaqi的值,用$.aqi.jinghuaqi($取的是所有,这个语法叫做jsonpath),要分清楚层级还要注意数组[]
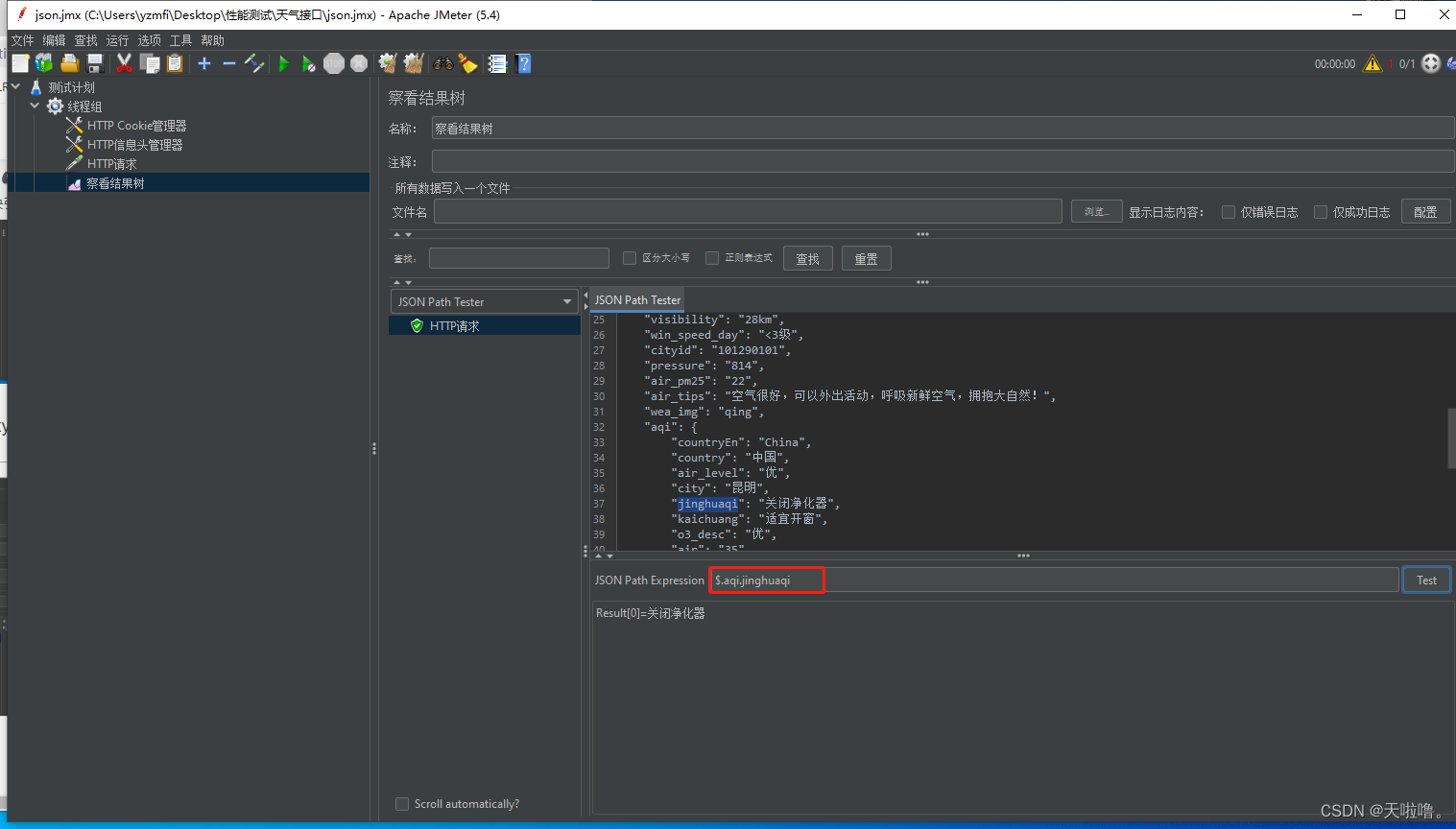
①在上游请求添加JSON提取器,并填写相应配置
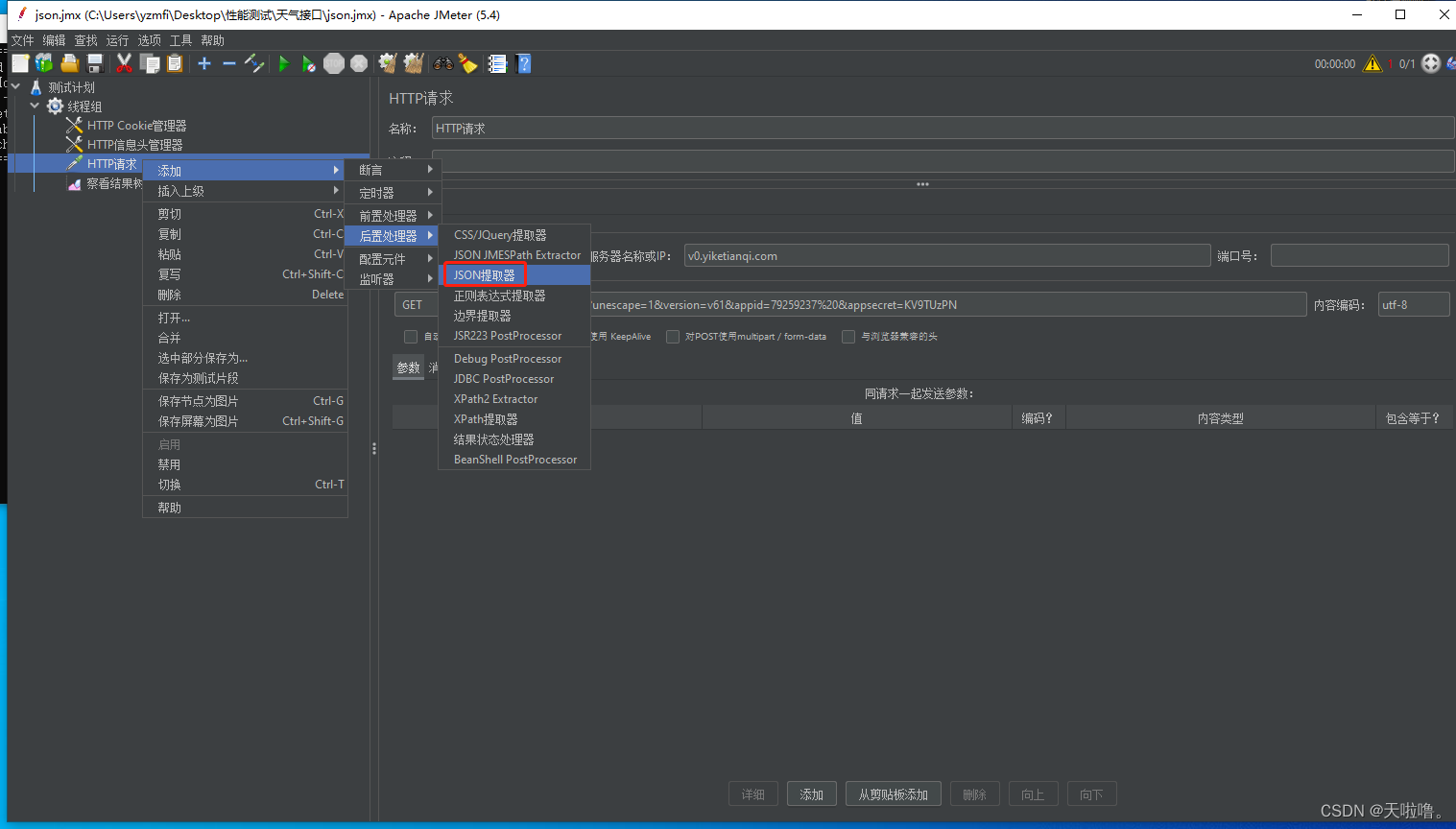
工作区介绍:
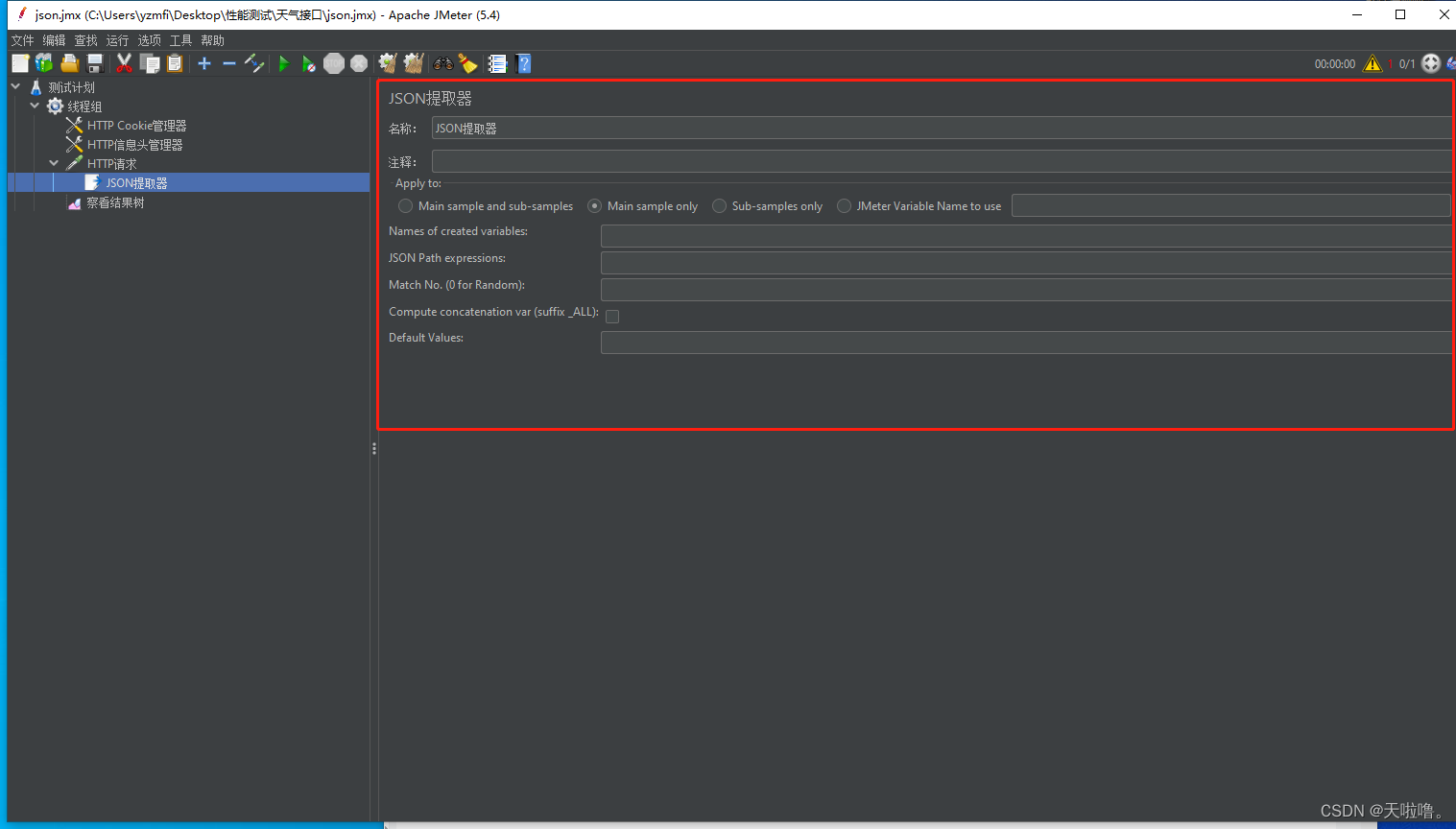
Names of created variable:为提取的值取名字
JSON Path expressions:提取JSON值的表达式
Match No:一般填1,代表取第一个值。0代表随机取一个,-1代表要全部取到的值
Default Values:一般填null
②③和正则提取步骤一致
三、参数化
场景:需要批量注册一批用户
方法(1)用函数读取文本,工具--函数助手对话框--CSVRead(不建议使用)
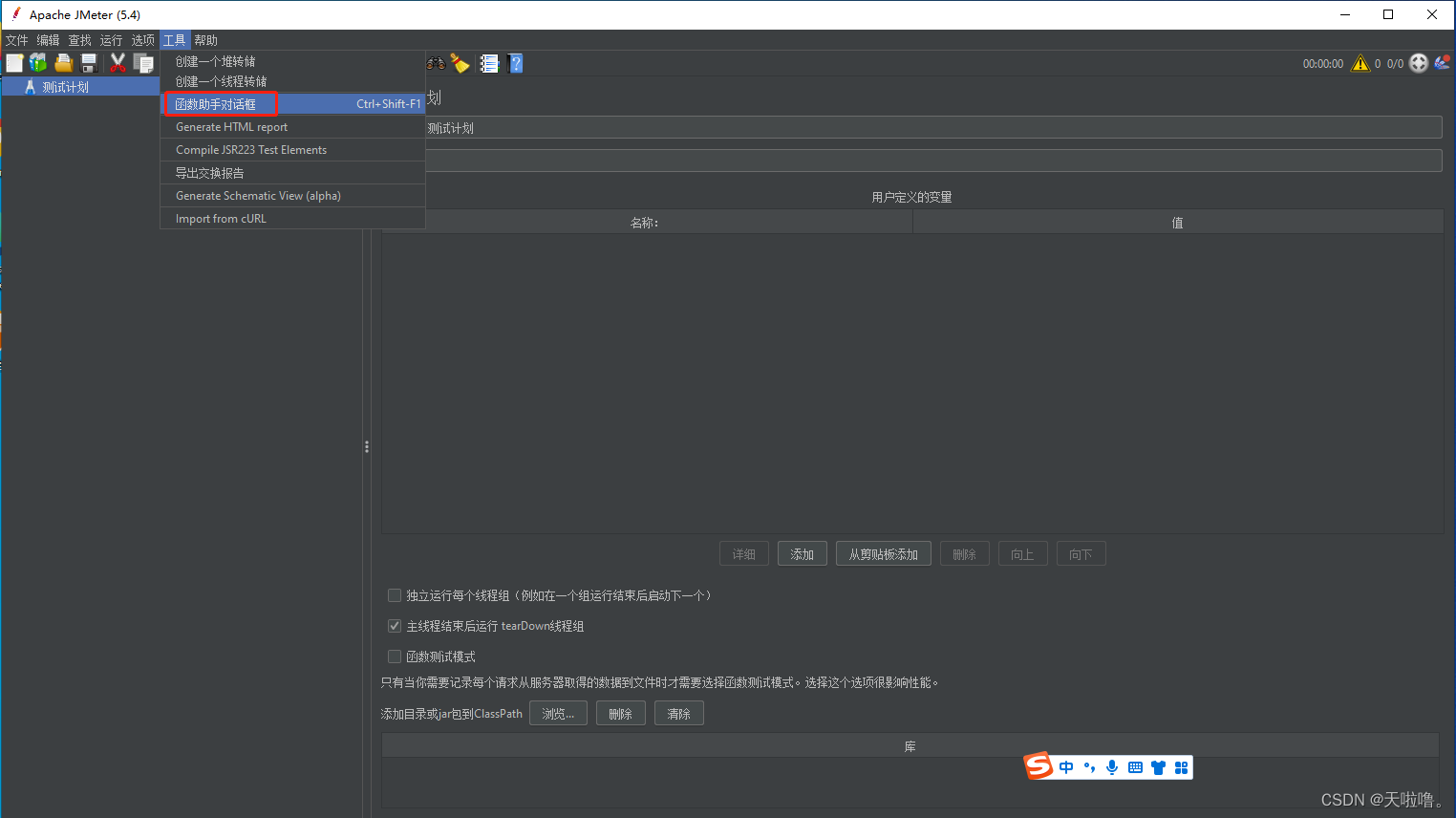

函数参数:
①用于获取值的CSV文件 | *别名
在桌面建一个txt文件,把文件路径复制到函数助手对话框中(直接在文件属性中复制文件可能会出错,可以先复制到文本编辑器里在复制到函数助手对话框中)
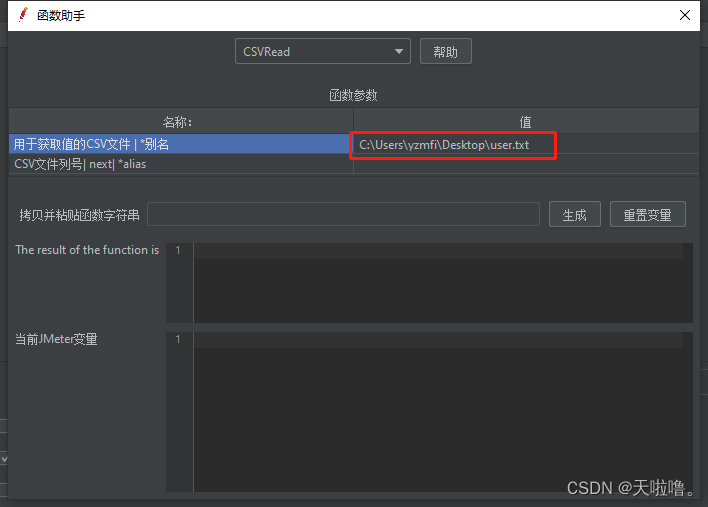
②CSV文件列号| next| *alias(要获取文档中哪一列值的意思,一般填0,文档中的第一列数据用0表示,第二列数据用1表示......)
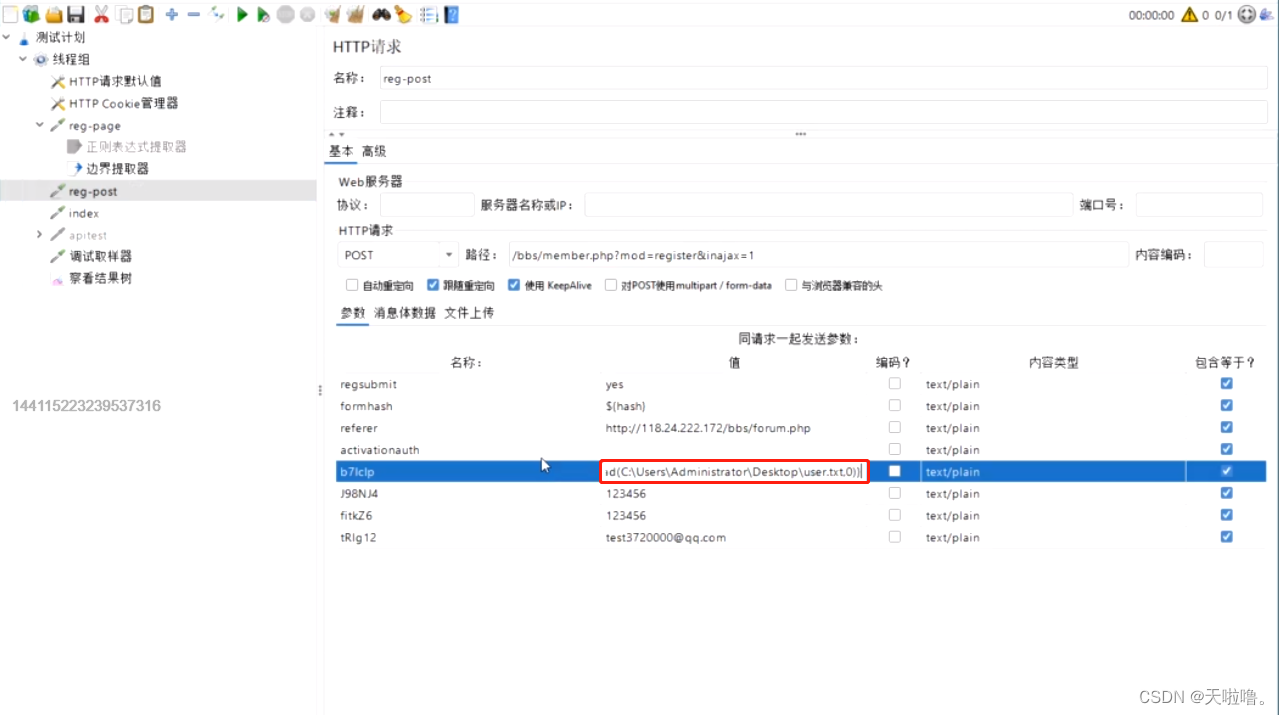
之后点击“生成”,将生成的一个字符串

将生成的字符串粘贴至需要随机生成参数的地方
文档中需要造一批数据(可以填多列数据,用逗号分隔开,数据最后一个数据后不能有回车),eg:
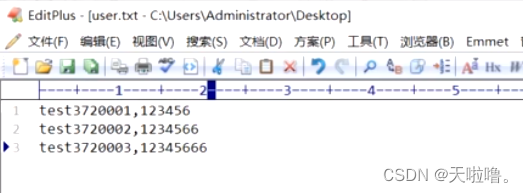
注意修改线程数和循环次数
方法(2)在线程组上添加CSV Data Set Config(不支持随机取数据)
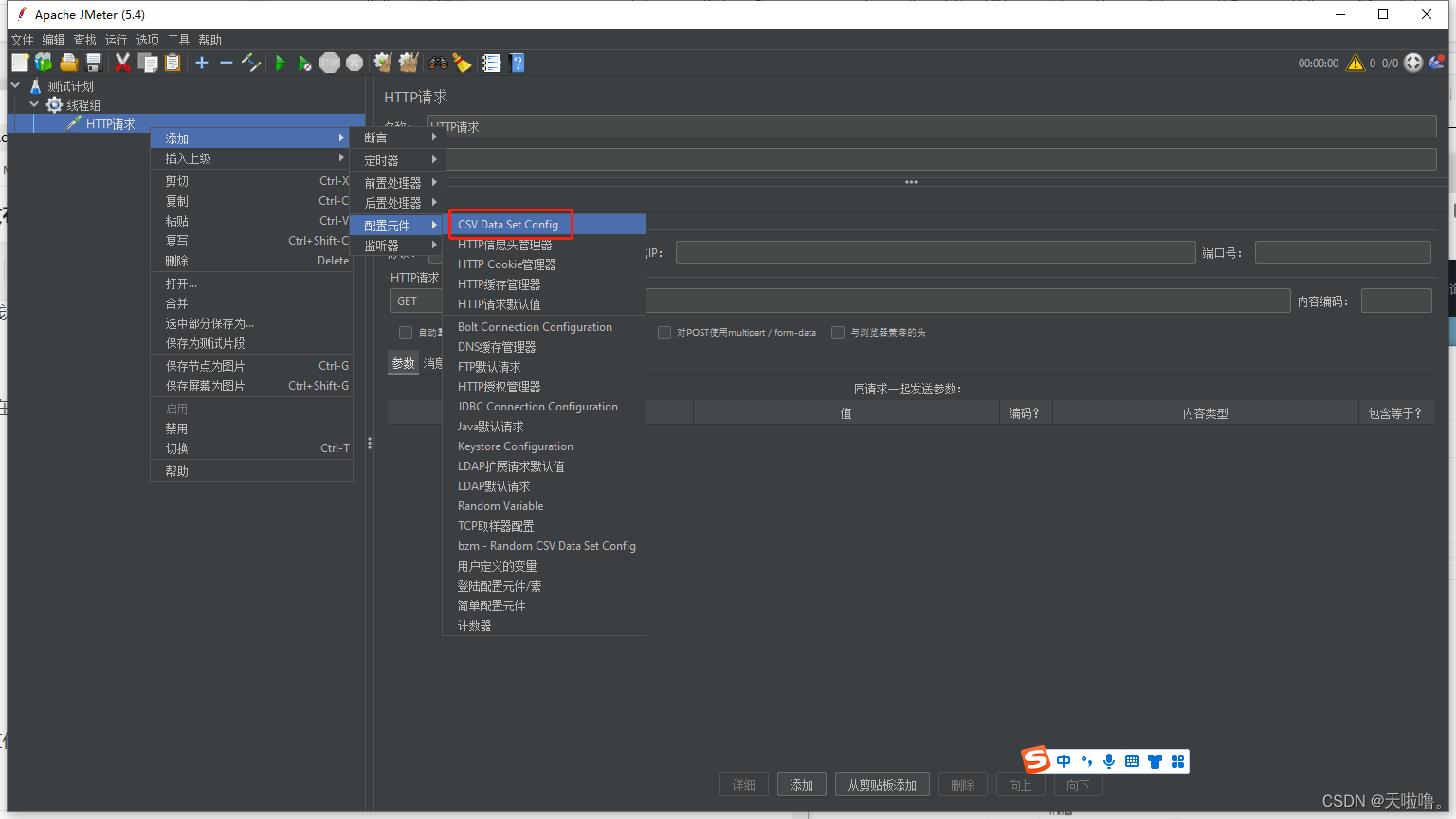
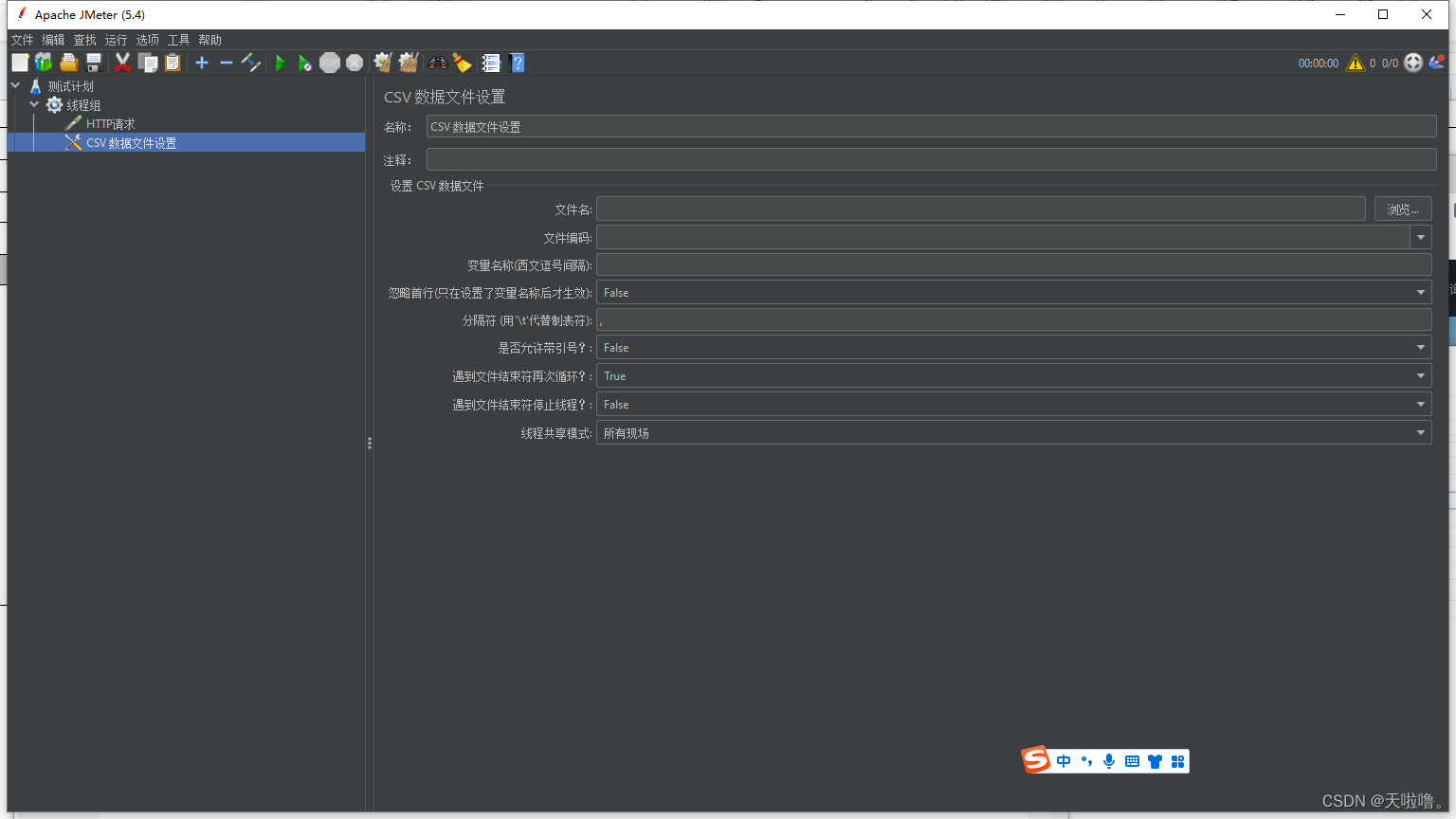
工作区介绍
文件名:浏览你建的数据文件
文件编码:默认utf-8
变量名称:数据文档中存了好多个参数(用户名、密码、邮箱等),为每列数据取一个参数名

忽略首行:数据文档中第一行是变量名就需要忽略首行,第一行是数据就不需要忽略首行
分隔符:默认一个逗号
是否允许带引号:文档数据中参数带引号就需要填true,一般不需要带引号
遇到文件结束符再次循环/遇到文件结束符停止线程:涉及到参数的取值方式(文件结束符:每个文档最后都会有eof)
不同场景不同搭配,注册,用完文档中的参数后不能再循环,遇到文件结束符再次循环false,遇到文件结束符停止线程true;登录,可以重复登录,所以可以循环
扩展:把请求禁用,加一个调试取样器,就可以不用去请求就能看结果
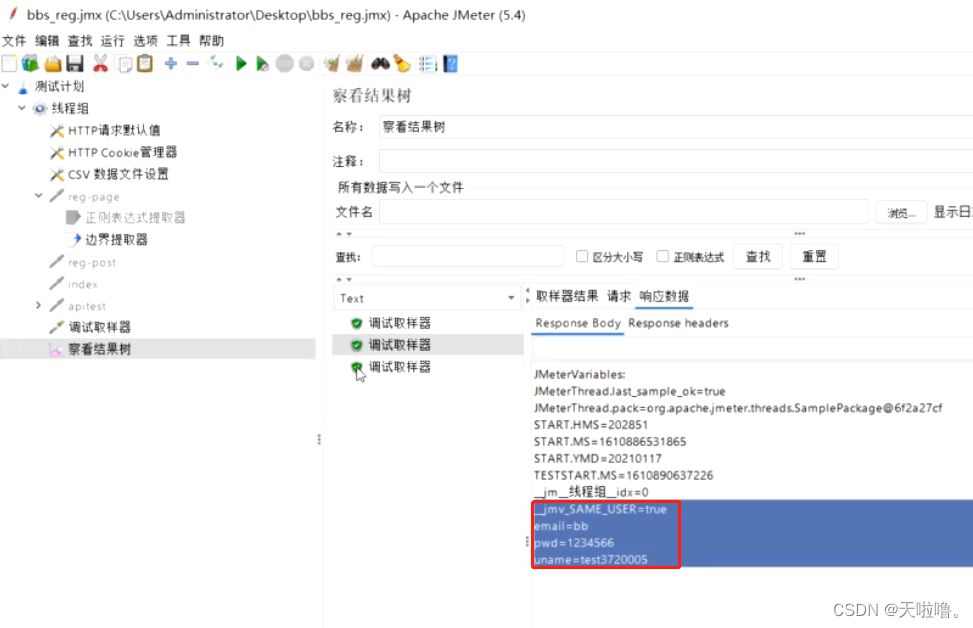
要随机取数据用插件Random CSV Data Set
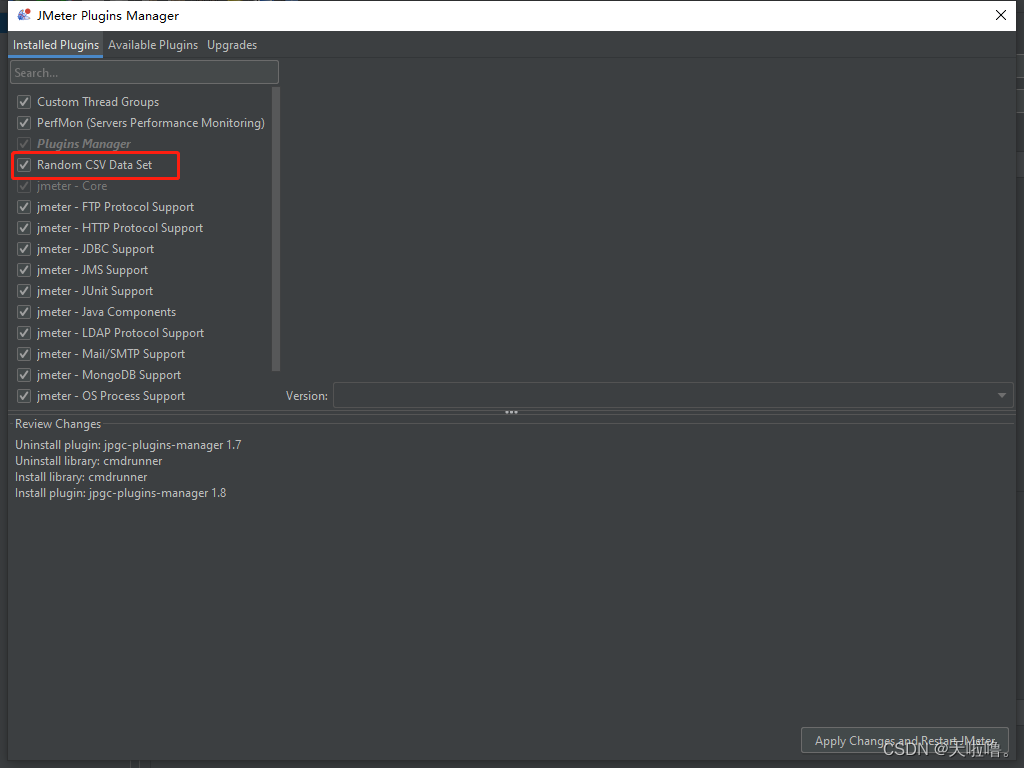
在线程组上添加Random CSV Data Set Config
工作区介绍
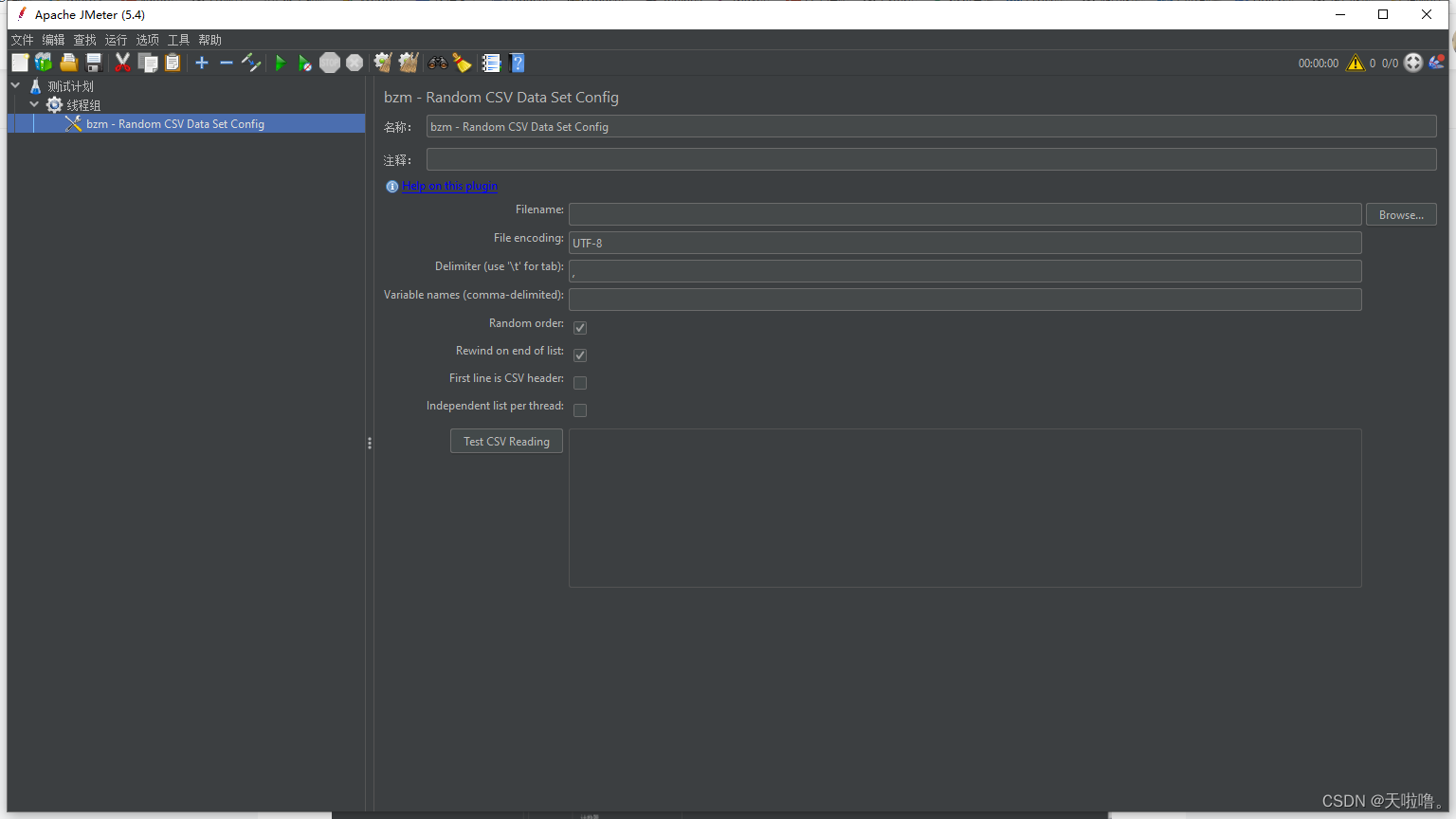
random order:要√,√了才能随机取值,否则与上面一种没区别
rewind on end of list:是否重来
first line is CSV header:是否忽略首行
independent list per thread:线程共享模式
方法(3)函数取值:
a.造数据:在线程组上面添加计数器(可以造有规律的数据)
工作区介绍:
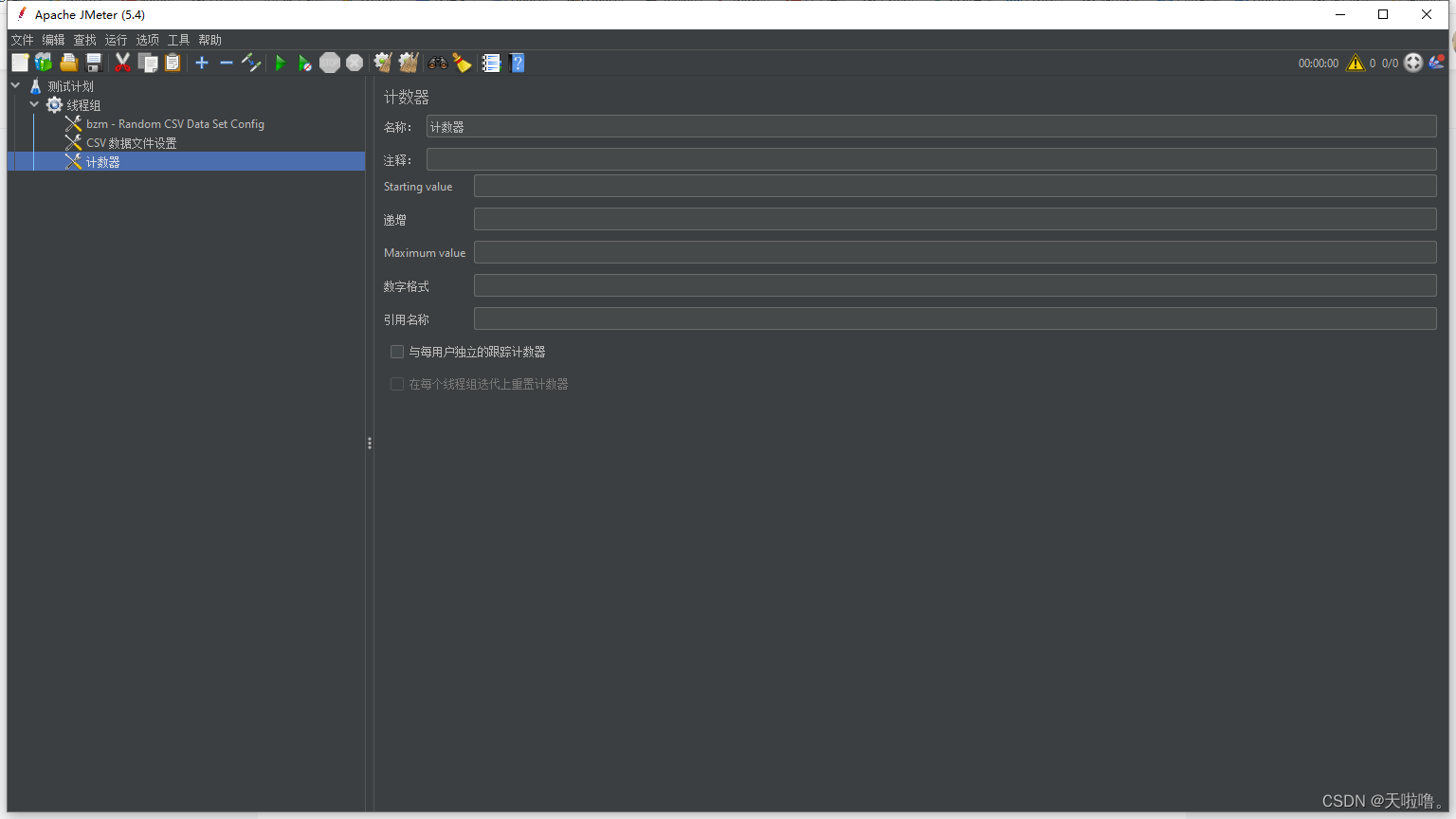
starting value: 从哪个数字开始
递增:每次加几
数字格式:占位的意思
b.引用数据:{名称}
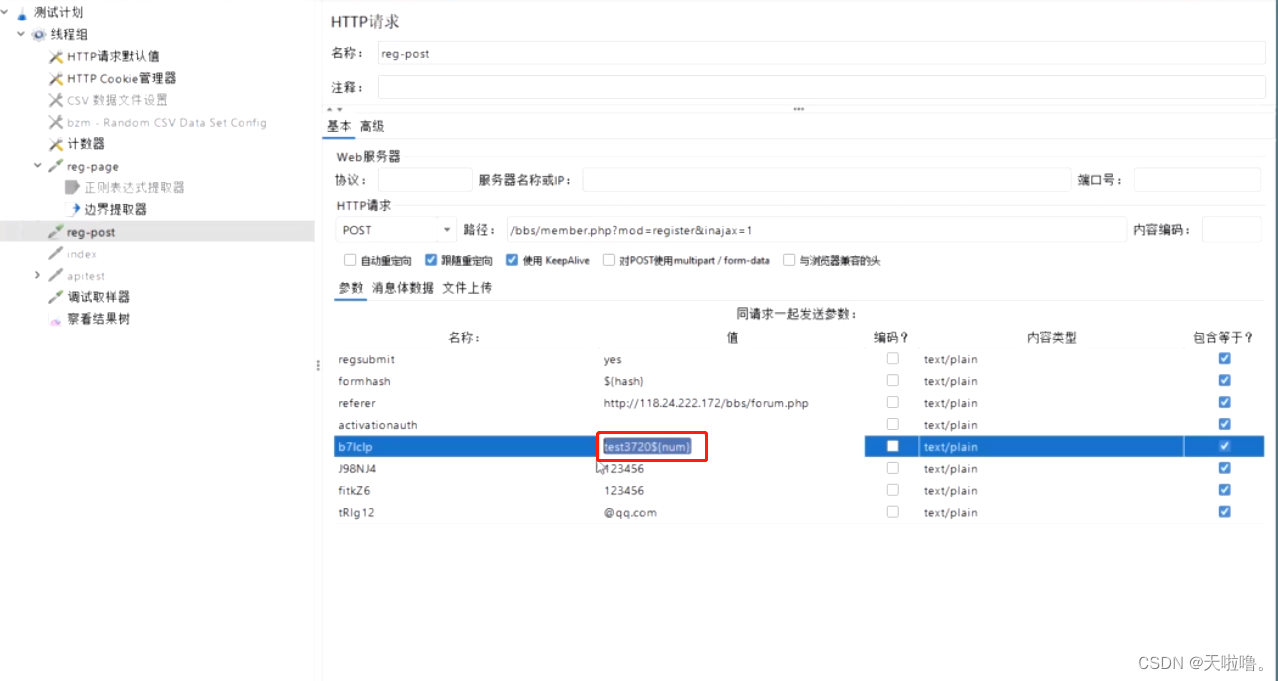
批量造数据,用计数器的方式最简单
方式(4)从数据库取值:
方式(5)随机取值,用函数助手:
常用函数①:

填写最小值、最大值后,点击“生成”,然后把生成的字符串复制到需要引用的地方
常用函数②(取随机的日期,只支持年月日不支持时分秒):
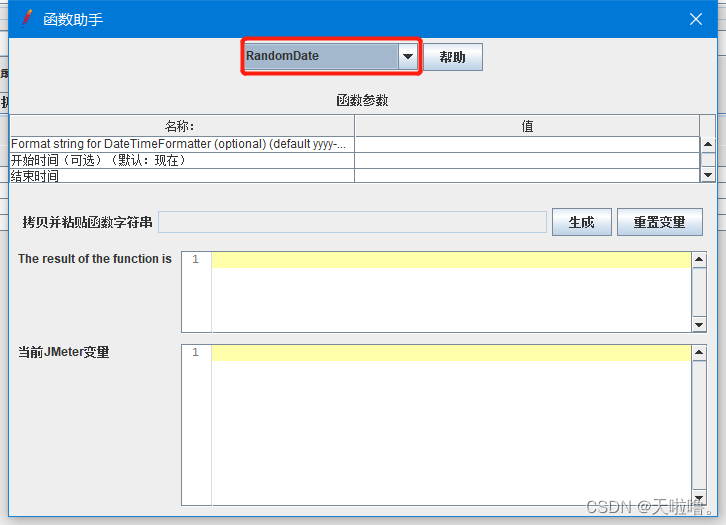
填写日期格式(默认yy—mm—dd)、初始日期、结束日期、时区(默认即可)
常用函数③(随机生成一个字符串):
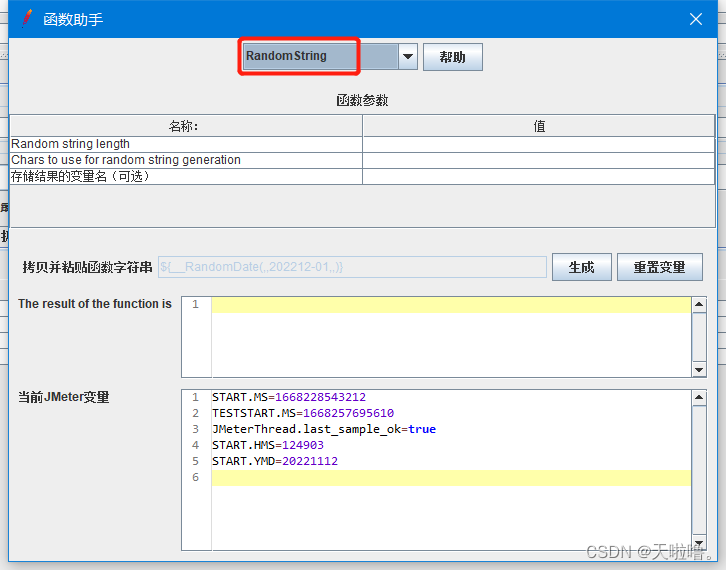
填写随机生成字符串的长度、随机元素(中文也可以)
常用函数④(取当前的时间):
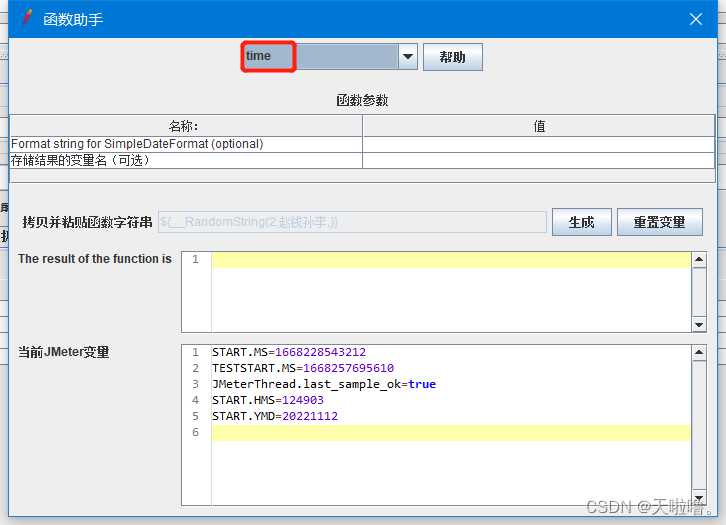
生成的是时间戳(从1970年开始到现在所经历的秒数,分为13位的(毫秒)、10位的(秒)、16位的)
常用函数⑤(可用来生成不重复的订单号):
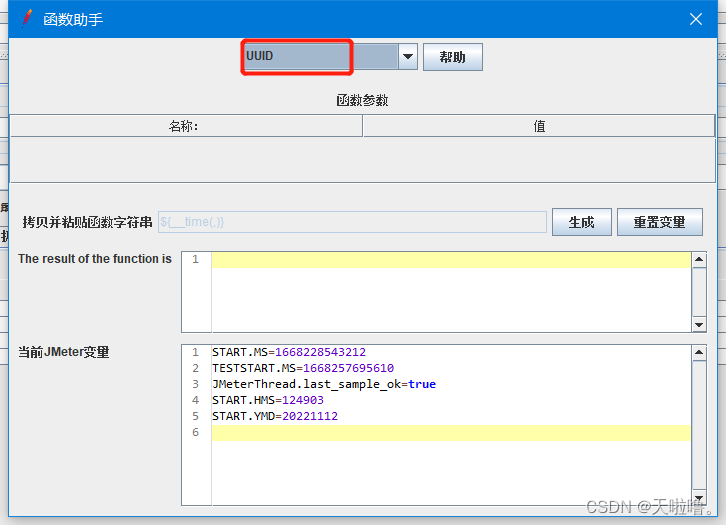
扩展:
①用户参数,调试脚本的时候使用,可以先不准备测试数据文件( 接入 ),先用用户参数看取值是否正确,调试完成后把用户参数删除或禁用,然后把
),先用用户参数看取值是否正确,调试完成后把用户参数删除或禁用,然后把 接入进来即可
接入进来即可
②用户定义的变量,有的地方需要用到一个值,这个值会变化,但是不会频繁变化(①在测试环境时,标识是testdev;在生产环境时,标识是prodev②数据库配置),这可以使调试脚本更加方便
四、集合点
做哪个接口的并发就把syn放在哪个接口下
工作区介绍:
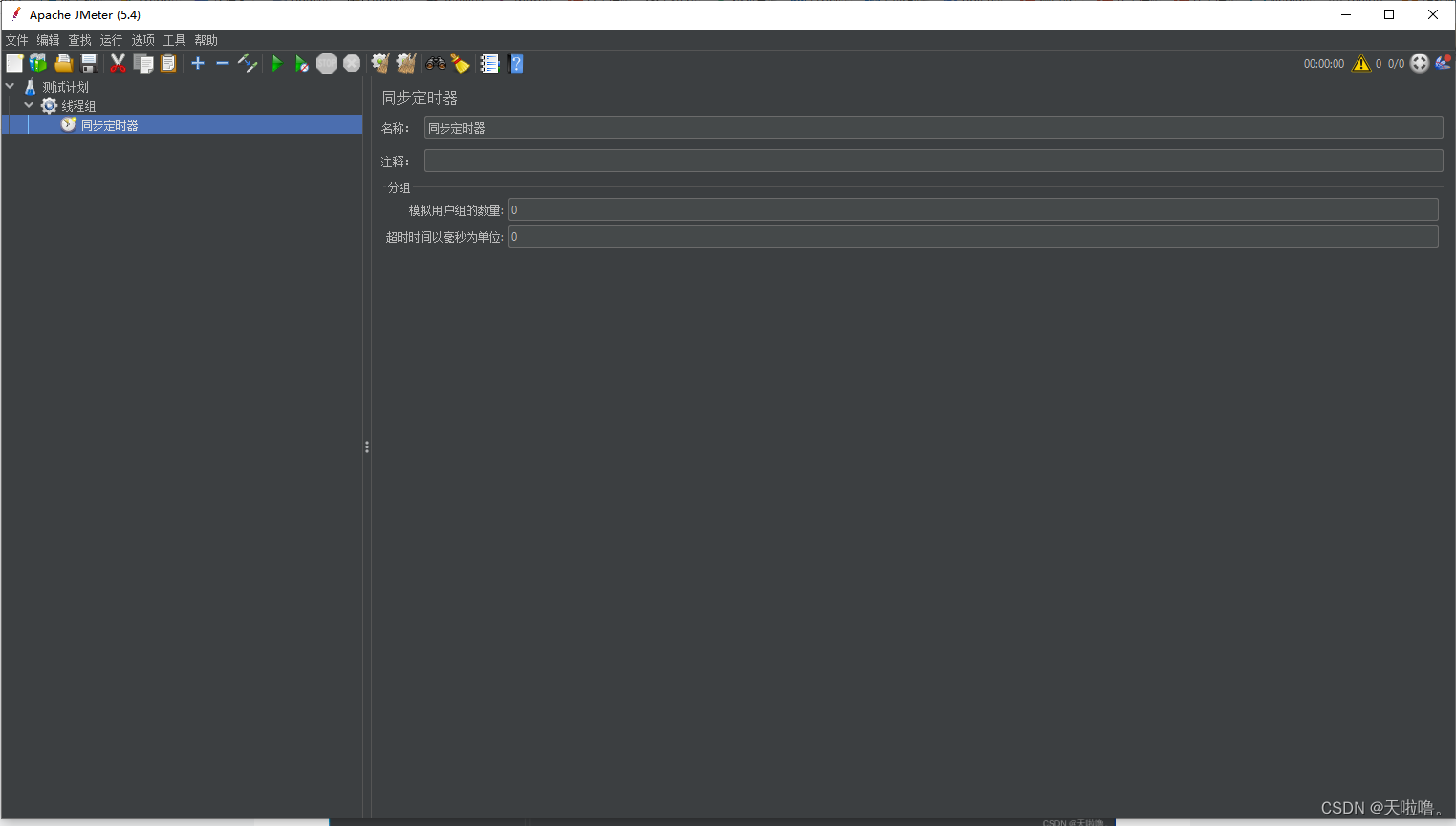 模拟用户组的数量:等待够了几个用户才会跑脚本,0代表线程组设置了几个这里的数量就是几个
模拟用户组的数量:等待够了几个用户才会跑脚本,0代表线程组设置了几个这里的数量就是几个
超时时间以毫秒为单位:时间到等到几个用户就跑几个用户,0代表永不超时等够了才跑脚本
五、断言
看返回的结果准不准确
(1)响应断言,返回的是网页时用比较好
工作区介绍:

测试状态:忽略状态(场景:返回的正确状态码就是4××或5××)
模式匹配规则:一般用字符串,”或者“表示有多条测试模式时满足其中一条都表示响应正确
测试模式:可添加多条,之间是与关系,必须同时满足才表示响应正确
自定义失败消息:响应失败时返回什么
(2)JSON断言,

工作区介绍:
Assert JSON Path exists :看JSON结构体是否正确,不看值是否正确
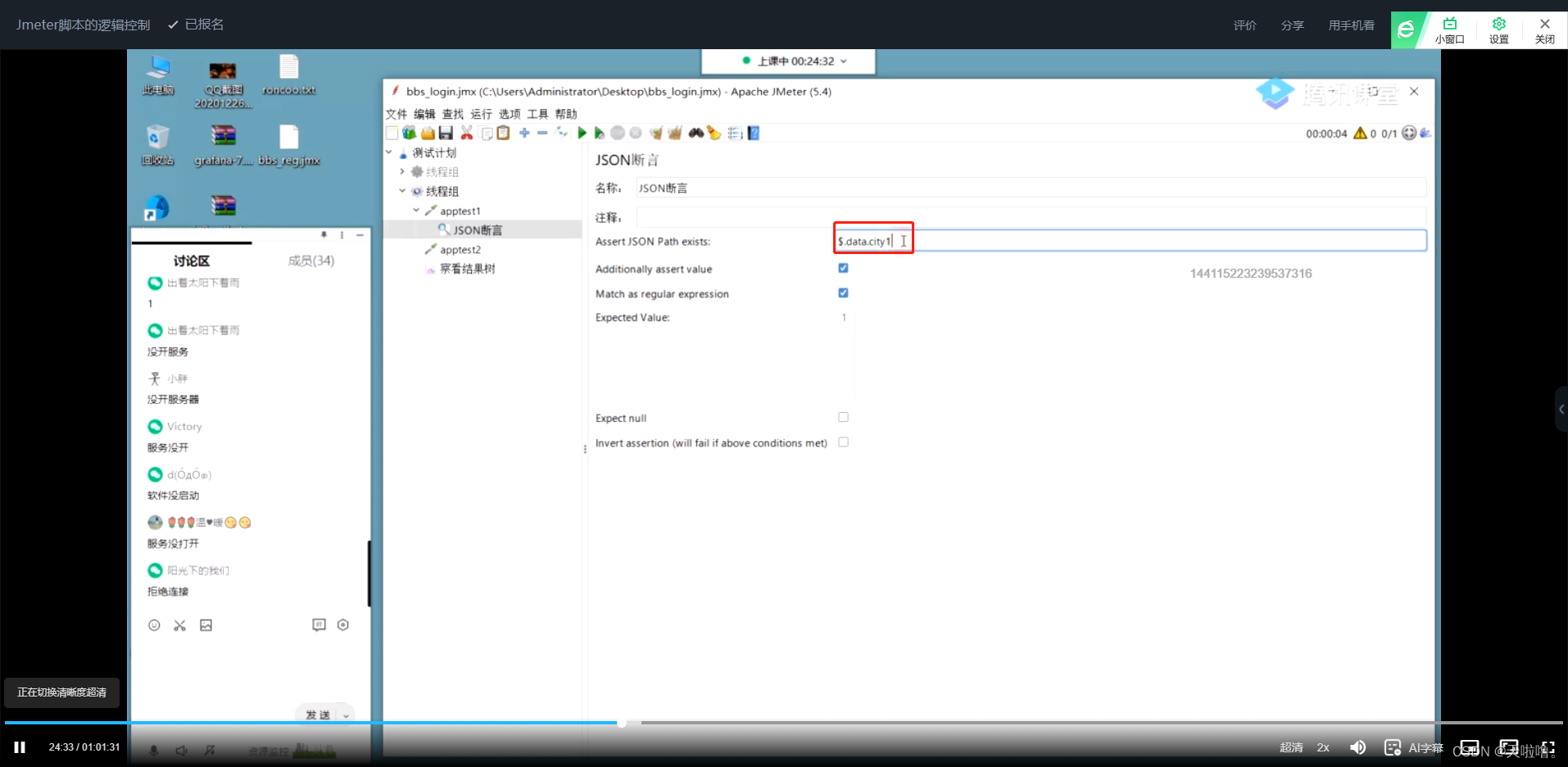
Additionally assert value:判断JSON值是否正确
Match as regular expression:是否支持正则表达式
Expect null:返回的值中是否包含null
Invert assertion (will fail if above conditions met:与响应断言中模式匹配规则中的“否”意思一致,反转的意思
(3)断言持续时间,与响应断言和JSON断言一起使用的,返回数据正确并且在规定的时间内返回才算响应数据正确
工作区介绍:
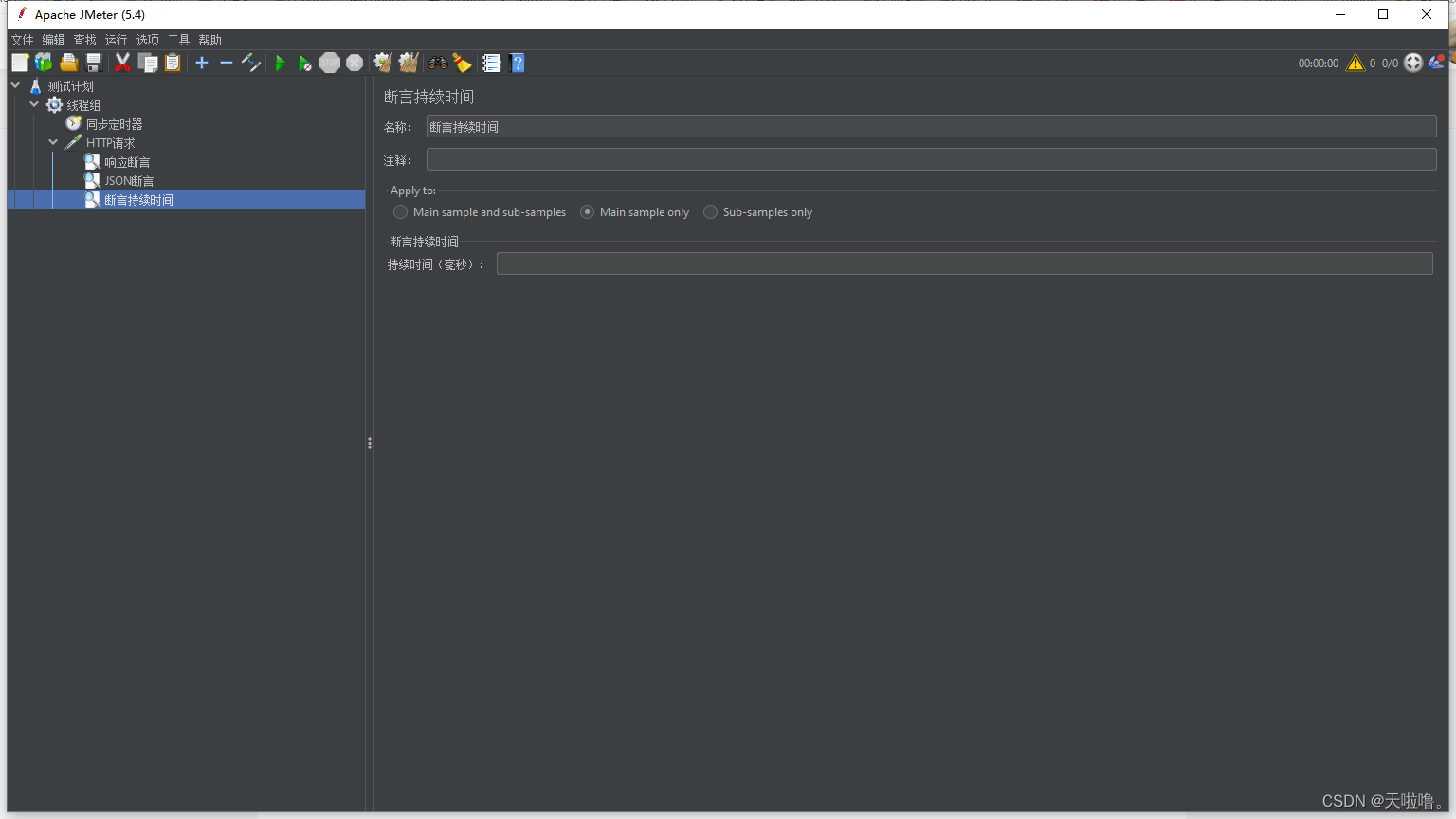
持续时间:在这个时间内返回才算响应正确
补充:
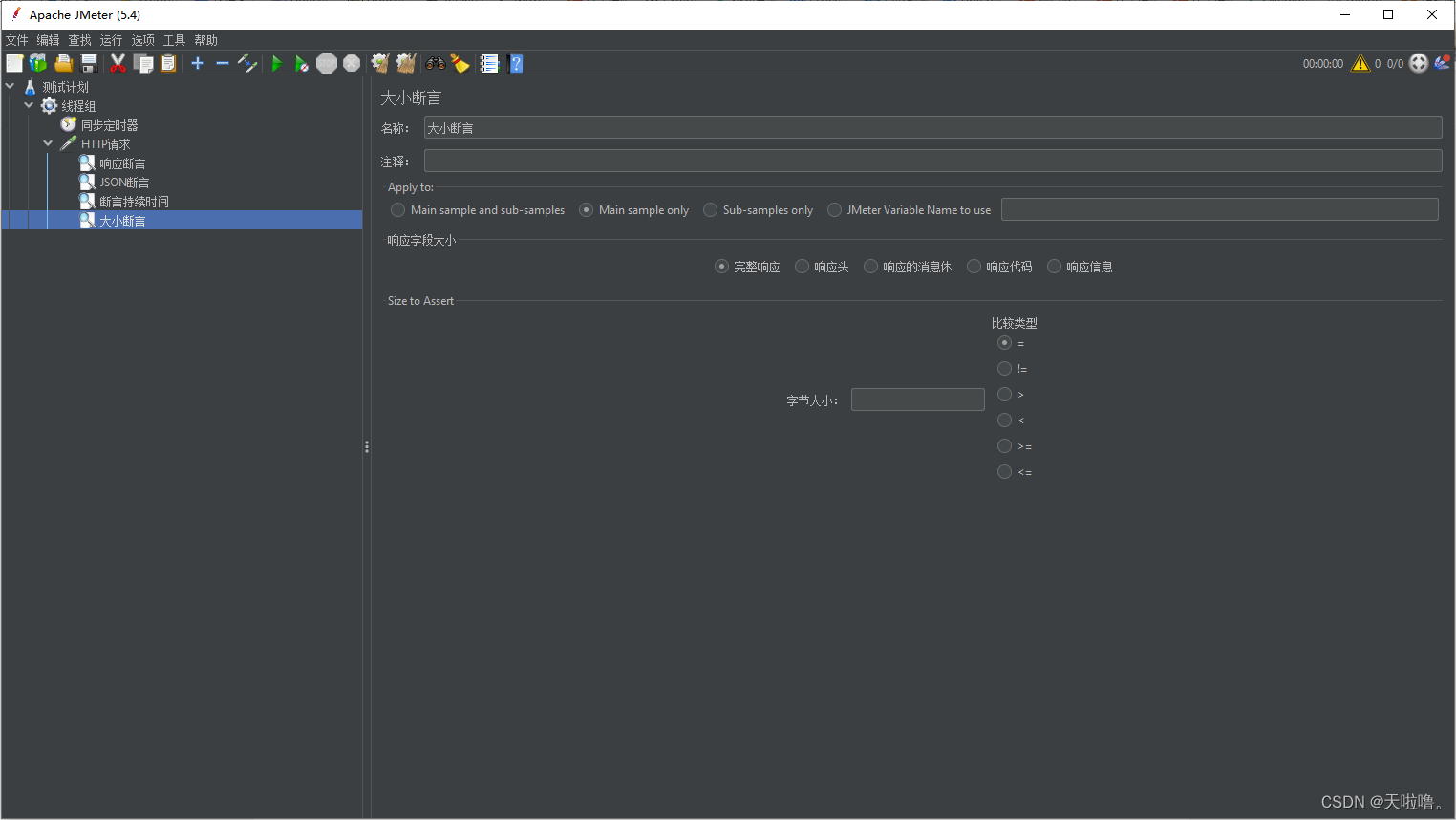
(4)大小断言,断言响应数据的大小
工作区介绍:
(5)MD5断言,可以测服务端返回的hash和本地的hash是否相等
六、如果控制器(P9053min)
七、事务控制器
八、循环控制器
九、while控制器
十、include控制器
十一、交替控制器
十二、随机控制器
随机抽取一个请求运行
十三、随机顺序控制器
请求都运行,但顺序是随机的
十四、简单控制器(P91)
没实质性作用,把脚本分组的
十五、临界部分控制器
大并发时,保证请求执行的顺序
十六、吞吐量控制器
控制
十七、查看结果树
十八、聚合报告
用户较多用命令行压测,命令行压测不需要添加聚合报告,测试结果就是聚合报告
十九、命令行压测
(1)桌面shift+右键→在此处打开powershell窗口
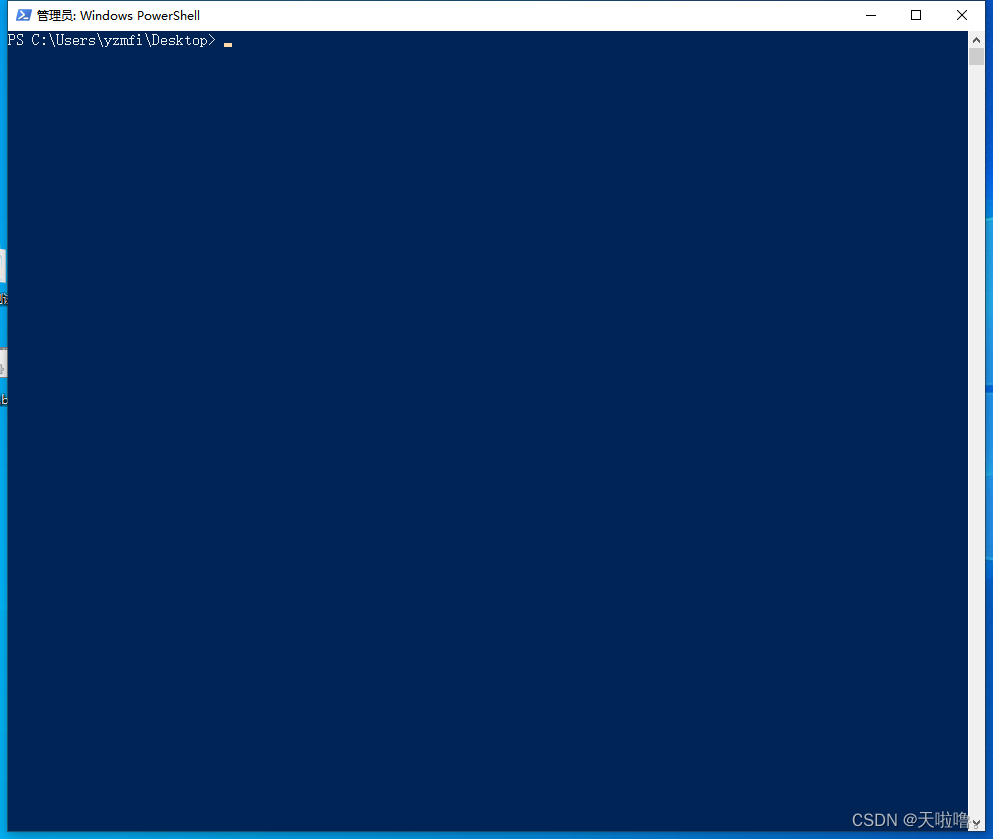
(2)输入命令:jmeter -n -t 云南省用途管制并发测试.jmx -l bbs.jtl -e -o ./out
命令解析:
-n:使用no GUI模式去跑
-t:脚本名字,当前脚本就在当前目录上,不在当前目录d:\
-l:后面跟测试结果,不是报告,jtl文件就是聚合报告
-e:输出HTML测试报告
-o:后面跟测试结果目录
并发量大时,对本机资源消耗较大,先生成测试结果后续在生成测试报告
命令1:不要-e -o ./out(先压测和生成测试结果)
命令2:jmeter -g bbs.jtl -e -o ./out(生成测试报告)
目前监控的只是外部/应用的指标,若监控服务器指标
(1)需添加插件
(2)将ServerAgent-2.2.1解压到本地,放到被监控的服务器的任何地方,装在哪就是监控哪(P91,53min)
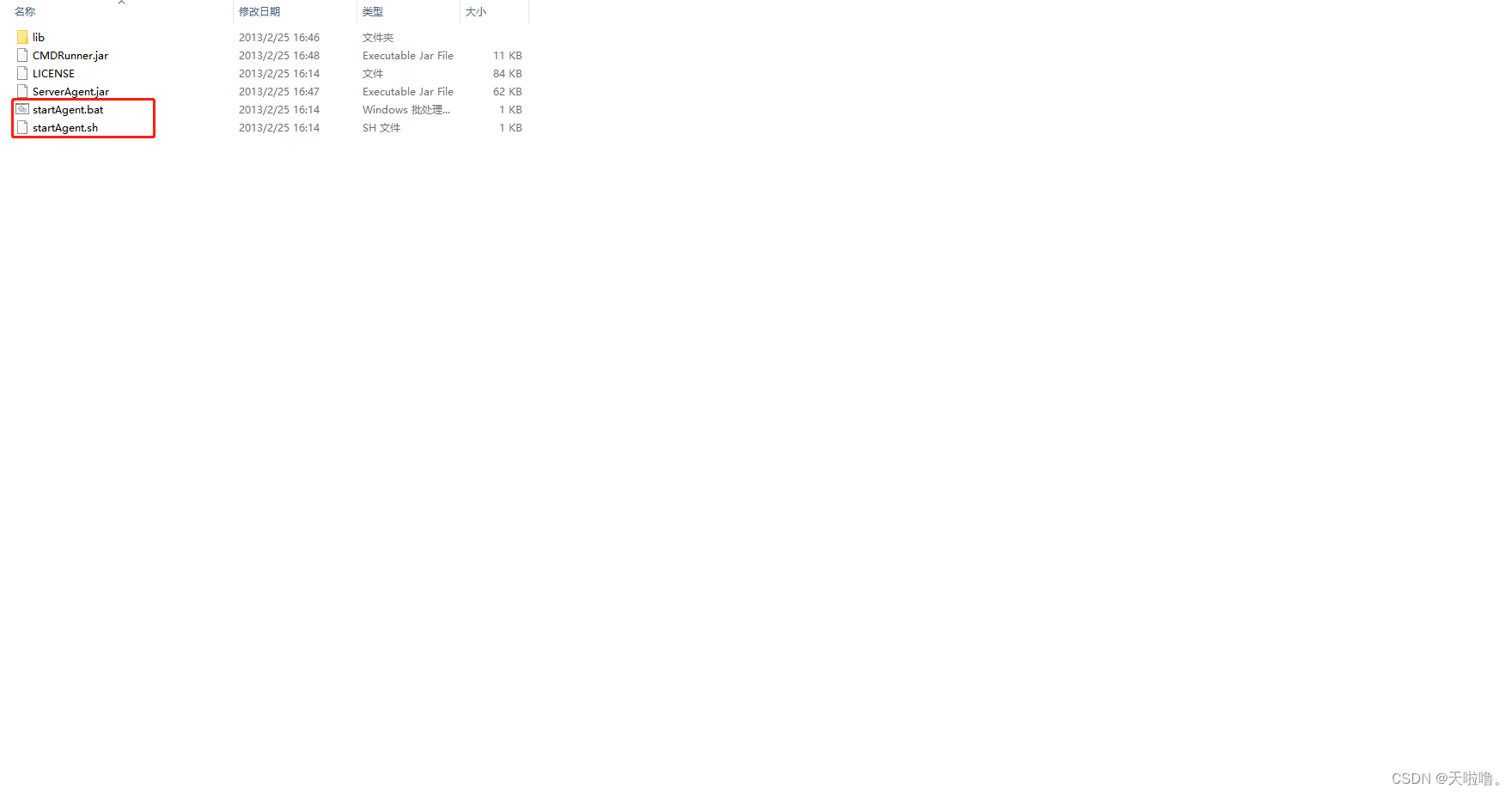
Windows用.bat启动,Linux用.sh启动
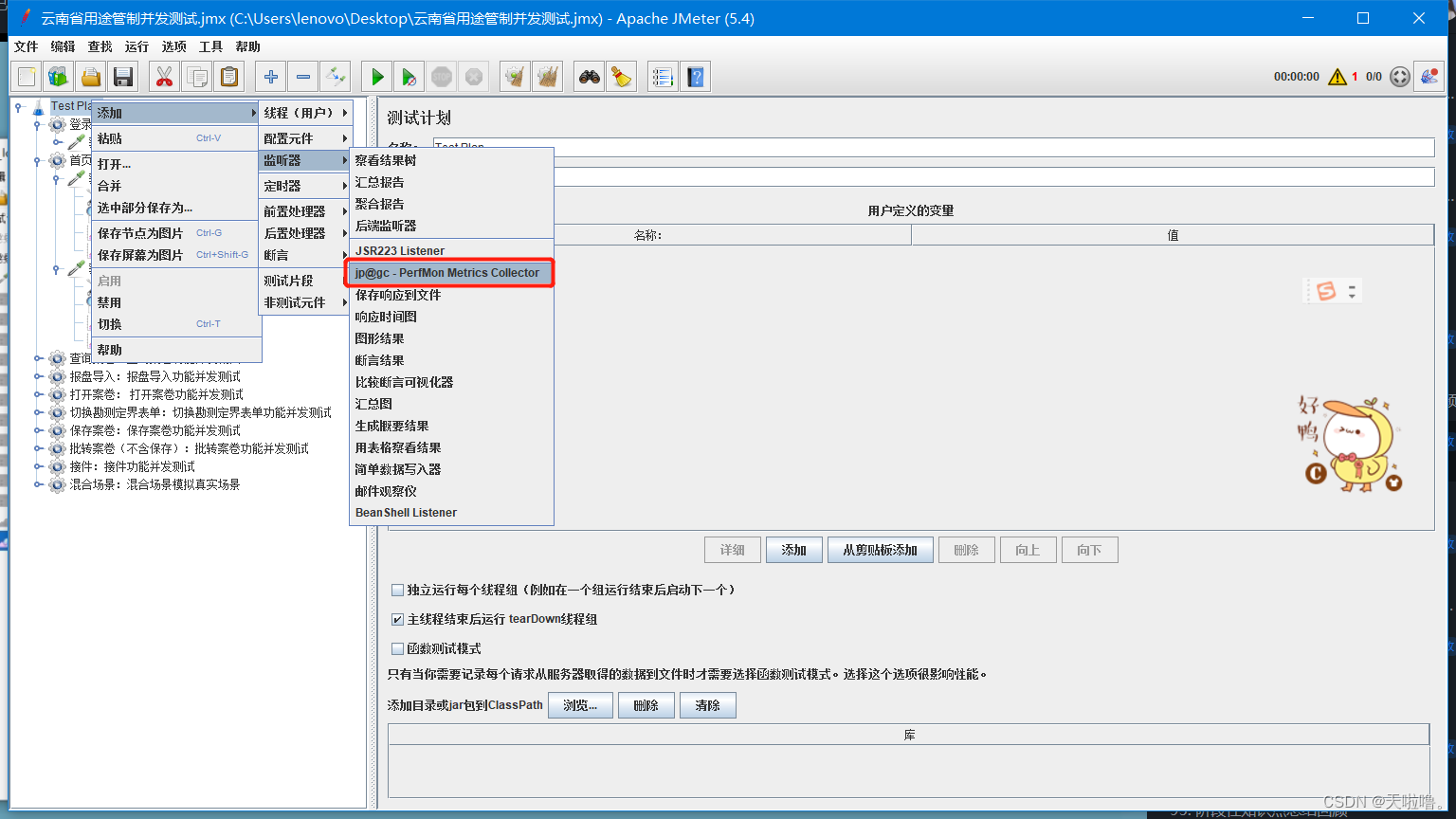
(3)添加监听器
二十、保存响应到文件
二十一、断言结果
几种常见协议的测试
版权归原作者 天啦噜。 所有, 如有侵权,请联系我们删除。