
1. HTML语义化
标签语义化是指在开发时尽可能使用有语义的标签,比如
header
,
footer
,
h
,
p
,少使用无语义如
div
好处:
- 对于开发者而言,语义化标签有着更好的页面结构,利于个人的代码编写。
- 对于用户而言,当网络卡顿时有良好的页面结构,有利于增加用户的体验。
- 对于爬虫来说,有利于搜索引擎的SEO优化,利于网站有更靠前的排名。
- 对于团队来讲,有利于代码的开发和后期的维护。
2. 盒模型
css盒子的组成包括margin、border、padding、content- 有两种盒模型:W3C标准盒模型 和 IE怪异盒模型
- 标准盒模型在设置
width和height时设置的是content的大小,盒子的大小还要加上padding、border - 怪异盒模型设置
width和height时设置的是盒子的大小,会压缩content区域 - 默认使用标准盒模型,也可以通过控制
box-sizing属性决定盒模型: -content-box代表标准盒模型-border-box代表怪异盒模型
3. 浮动
- 1.作用:常用于图片,可以实现文字环绕图片 - 设置了浮动的块级元素可以排列在同一行- 设置了浮动的行内元素可以设置宽高,同时可以按照浮动设置的方向对齐排列盒子
- 2.特点:脱离文档流,容易造成盒子塌陷,影响其他元素的排列- 当父元素不设高度需要子元素来撑开,而子元素设置浮动就会导致父元素的高度塌陷
- 3.解决塌陷问题: - 父元素中添加
overflow: hidden- 给父元素添加高度- 在下方创建一个空白div,添加clear: both- 在父级添加伪元素::after{ content:'', clear:both, display:table }
4. 样式优先级的规则
!important>- 内联样式 >
- ID 选择器
(#id{})> - 类选择器
(.class{})= 属性选择器(a[href="segmentfault.com"]{})= 伪类选择器(:hover{})> - 标签选择器
(span{})= 伪元素选择器( ::before{})= 后代选择器(.father .child{})> - 子选择器
(.father > .child{})= 相邻选择器(.bro1 + .bro2{})> - 通配符选择器
(*{})
5. CSS尺寸设置的单位
- 共有五个长度单位,分别是
px,em,rem,vw,vh - 除了
px是绝对单位,其余都是相对单位 em相对于自身大小(但在font-size中相对于父元素字体大小)rem相对于根元素的字体大小vw相对于可视化窗口的宽(1vw就是1%可视化窗口宽度)vh相对于可视化窗口的高(1vh就是1%可视化窗口高度)- 一般采用
rem+ 媒体查询或者rem+vw来实现响应式布局。原理是当窗口大小发生变化时,通过媒体查询或者vw改变根元素的字体大小,从而改变以rem为单位的元素大小
6. BFC
- 定义:块级格式化上下文,独立的渲染区域,不会影响边界外的元素
- 形成条件: - 浮动- 非静态定位
static-overflow: hidden-display: table - 布局规则: - 区域内容
box从上到下排列-box垂直方向的距离由margin决定- 同一个BFC内box的margin会重叠-BFC不会与float元素重叠-BFC计算高度也会计算float元素 - 解决的问题: - 解决浮动元素重叠- 解决父元素高度塌陷- 解决
margin重叠
7. 未知宽高元素水平垂直居中的办法
- 1.设置元素相对父级定位
position: absolute; left: 50%; top: 50%,让自身平移自身高度50%transform: translate(-50%, -50%);- 兼容性好,被广泛使用的一种方式 - 2.设置元素的父级为弹性盒子
display: flex,设置父级和盒子内部子元素水平垂直都居中justify-content: center; align-items: center- 代码简洁,但兼容性ie 11以上支持 - 3.设置元素的父级为网格元素
display: grid,设置父级和盒子内部子元素水平垂直都居中justify-content: center; align-items: center- 代码简洁,但兼容性ie 10以上支持 - 4.设置元素的父级为表格元素
display: table-cell,其内部元素水平垂直都居中text-align: center; vertical-align: middle;,设置子元素为行内块display: inline-block;
8. 三栏布局的实现方案
- flex布局:- 将最外层盒子设为弹性布局,左右两边的盒子固定
宽度200px- 将中间的盒子flex设为1 - 这样中间盒子的宽度就能一直得到全部宽度减去左右盒子的宽度,这个宽度会随着窗口的大小而变化 - grid布局:- 左右两边的宽度固定,将剩余的空间给中间的主体部分- 要用到
grid-template-columns:定义网格的列大小和数量 - 圣杯布局:实现原理:
float+margin负值 +position: relative- 保证中间栏最先加载,那就要把middle容器写在前面<div class="container"> <div class="middle"></div> <div class="left">left</div> <div class="right">right</div></div>- 给父容器添加`padding:0 200px,腾开位置- middle中间容器设置width:100%,此时的宽度继承了父容器的100%- 并给三个子容器都设置float: left,都向左浮动,去到同一行- 给左右容器**相对定位**,让它们相对自己原本文档流的位置进行定位.left{ width: 200px; background: #76d1ea; position: relative; margin-left: -100%; //向左挪动父容器宽度的100% left: -200px; //再向左挪动自身的200宽度 }- 此时right接替了left原本的位置,同理,这时候只需要给right设置:margin-right: -200px;,就可以实现三栏布局了 - 双飞翼布局:- 结构稍微改造一下,在middle容器里面多用了个
inner容器- 设置了middle的width:100%,这时候我们只需要设置inner容器为padding:0 200px-left、middle、right同样使用浮动- left设置margin-left:-100%(父容器的整个宽度)- right设置margin-left:-200px
详细实现请看:三栏布局的实现方法
9. JS数据类型及区别
- 分为两类:基本数据类型(简单数据类型)、引用数据类型(复杂数据类型)
- 基本数据类型包含7种,分别是
Number、String、Boolean、Null、Undefined、BigInt、Symbol-Symbol是ES6新出的一种数据类型,特点是没有重复的数据,可以作为object的key- 使用Symbol数据作为key不能使用for获取到这个key,需要使用Object.getOwnPropertySymbols(obj)获得这个obj对象中key-BigInt也是ES6新出的一种数据类型,特点就是数据涵盖的范围大,能够解决超出普通数据类型范围报错的问题 - 引用数据类型通常用
Object代表,普通对象、数组、正则、日期、Math数学函数都属于Object - 本质区别:在内存中的存储方式不同- 基本数据类型:存储在栈中的简单数据段,占据空间小,属于被频繁使用的数据- 引用数据类型:存储在堆内存中,占据空间大 - 引用数据类型在栈中存储了指针,该指针指向堆中该实体的起始地址,当解释器寻找引用值时,会检索其在栈中的地址,取得地址后从堆中获得实体。
10. null和undefined的区别
null是定义并赋值null,typeof判定为object- 表示一个变量被人为的设置为空对象,而不是原始状态-null其实属于自己的类型Null,而不属于Object类型,typeof之所以会判定为Object类型,是因为JavaScript数据类型在底层都是以二进制的形式表示的,二进制的前三位为 0 会被typeof判断为对象类型,而null的二进制位恰好都是 0 ,因此,null被误判断为Object类型。undefined是定义未赋值,typeof判定为undefined
11. JS判断变量的类型的方法
typeof:根据二进制判断,不能判断数据类型null和objectintanceof:根据原型链判断,原生数据类型不能判断constructor.name:根据构造器判断,不能判断null数据类型Object.prototype.toString.call():用Object的toString方法判断,所有类型数据都能判断,判断结果打印为:'[object Xxx]'
12. 数组去重的方法
- 利用对象属性
key排除重复项:遍历数组,每次判断对象中是否存在该属性,不存在就存储在新数组中,并且把数组元素作为key,设置一个值,存储在对象中,最后返回新数组 Array.from(new Set(arr)):不考虑兼容性,这种方法去重代码最少,但还没无法去掉{}空对象indexOf:if(array.indexOf(arr[i]) == -1){ array.push(arr[i]) }filter + indexof:利用Array自带的filter方法,返回arr.indexOf(num)等于index的num- 利用
for嵌套for,使用splice,ES5中常用 reduce +includes:利用reduce遍历和传入一个空数组作为去重后的新数组,内部判断新数组中是否存在当前遍历的元素,不存在就插入到新数组中
13. 数组和伪数组的区别
- 伪数组的特点: - 类型是
object- 不能使用数组其他方法,比如增删改- 可以用for in遍历,可以获取长度,可以用下标获取对应元素 - 常见的伪数组: - 函数的
arguments参数-querySelector-Map和Set的keys()、values()、entires() - 转化成真数组: -
Array.from(伪数组)-Array.prototype.slice.call(伪数组)-[].slice.call(伪数组)
14. map和forEach的区别
- 相同点: - 都是循环遍历数组的每一项- 每次执行匿名函数都支持三个参数:
item(当前的每一项)、index、arr(原数组)- 匿名函数中的this都指向window- 只能遍历数组 - 不同点: -
map()会分配内存空间存储新数组并返回,forEach()不会返回数据-forEach()允许callback更改原数组的元素,map()返回新的数组
15. ES6的箭头函数
- 比普通函数写法更简洁快捷
- 没有原型
prototype和super,所以无法创建this - 无自己的
this,继承上一个作用域的this(全局或上一个函数),在找不到最外层的普通函数时,其this一般指向window - 不能使用
new - 没有
arguments - 也不能作为
generator函数 - 不能使用
yield命令 - 不能用于对象域和回调函数动态this中,一般用在内部没有
this引用
16. 事件扩展符(…) 什么场景下用
- 数组克隆、去重、合并
- 伪数组转真数组
- 做为函数传递参数时不确定形参个数的时候
17. 闭包的理解
- 原理:作用域链,当前作用域可以访问上级作用域中的变量
- 解决的问题:能够让函数作用域中的变量在函数执行结束之后不被销毁,同时也能在函数外部可以访问函数内部的局部变量
- 带来的问题:由于垃圾回收器不会将闭包中变量销毁,于是就造成了内存泄露,内存泄露积累多了就容易导致内存溢出
- 应用: - 能够模仿块级作用域- 能够实现柯里化- 在构造函数中定义特权方法-
Vue中数据响应式Observer中使用闭包
18. 变量提升
- 是指JS的
var变量和函数声明会在代码编译期,提升到代码的最前面 - 前提:使用
var关键字进行声明的变量,并且变量提升的时候只有声明被提升,赋值并不会被提升,同时函数的声明提升会比变量的提升优先 - 结果:可以在变量初始化之前访问该变量,返回的是
undefined,在函数声明前可以调用该函数 let和const声明的变量只是创建提升,在预编译中将其创建,形成暂时性死区,不能提前访问和调用变量,只能在赋值之后进行调用和访问
19. this指向(普通函数、箭头函数)
- 在全局环境中调用普通函数,严格模式下
this指向undefined,非严格模式下this指向window - 在对象之中调用,将会是指向当前的对象
- 通过
new创建出来的对象将会是指向当前的新对象,如果是使用call、bind、apply修改了指向,将会指向绑定后的this - 在箭头函数之中将会指向函数的外层执行上下文,当函数定义之后将会确定当前的
this,继承了上一层执行环境的this
20. call apply bind的作用
- 三个方法都可以用来改变函数的
this指向,区别如下: fn.call (newThis, params):第一个参数是this的新指向,后面依次传入函数fn要用到的参数,会立即执行fn函数fn.apply (newThis, paramsArr):第一个参数是this的新指向,第二个参数是fn要用到的参数数组,会立即执行fn函数fn.bind (newThis, params):第一个参数是this的新指向,后面的参数可以直接传递,也可以按数组的形式传入, 不会立即执行fn函数,且只能改变一次fn函数的指向,后续再用bind更改无效,返回的是已经更改this指向的新fn
21. JS继承的方法和优缺点
原型链继承:
- 优点:写法简单、容易理解
- 缺点: - 引用类型的值会被所有实例共享- 在子类实例对象创建时,不能向父类传参
借用构造函数继承:
- 优点: - 避免了引用类型的值会被所有实例共享- 在子类实例对象创建时,可以向父类传参
- 缺点:方法在构造函数中,每次创建实例对象时都会重新创建一遍方法
组合继承:
- 优点: 融合原型链和借用构造函数的优点,是最常用的继承方式
- 缺点:无论什么情况下,父类构造函数都会被调用两次,一是创建子类原型对象时,二是子类构造函数内部
原型式继承:
- 优点:不需要单独创建构造函数
- 缺点:引用类型的值会被所有实例共享
寄生式继承:
- 优点:不需要单独创建构造函数
- 缺点:方法在构造函数中,每次创建实例对象时都会重新创建一遍
寄生组合继承:
- 优点: - 高效率只调用一次父类构造函数,并且避免了子类原型对象上不必要、多余的属性- 能将原型链保持不变,因此能使用
instanceof和isPrototypeOf - 缺点:代码复杂
22. new会发生什么
- 1.创建一个新对象
- 2.将新对象的__proto__(原型)指向构造函数的
prototype(原型对象) - 3.构造函数绑定新对象的this并执行返回结果
- 4.判断返回结果是否为null,如果为null,返回新对象,否则直接返回执行结果
23. defer和async的区别
html文件都是按顺序执行的,script标签中没有加defer和async时,浏览器在解析文档时遇到script标签就会停止解析阻塞文档解析- 先加载
JS文件,加载完之后立即执行,执行完毕后才能继续解析文档 - 而在
script标签中写入defer或者async时,就会使JS文件异步加载,即html执行到script标签时,JS加载和文档解析同时进行 async是在JS加载完成后立即执行JS脚本,阻塞文档解析- defer则是JS加载完成后,在文档解析完成后执行JS脚本
24. Promise是什么及使用方法
- Promise是异步编程的一种解决方案,用于解决回调地狱问题,让代码可读性更高,更利于维护
- Promise通过
new Promise()将构造函数实例化,有两个参数resolve、reject,这两个参数也是方法,成功调用resolve(),失败调用reject() - 实例创建完成后,可以使用
then方法指定成功或者失败的回调函数,也可以用catch捕获失败,then和catch最后也是返回promise对象,所以可以链式调用 promise.all(iterable):iterable是由多个promise实例组成的可迭代对象(如Array,Map,Set),当promise实例都返回成功的结果组成的数组。只要有一个回调执行失败,then是不会执行的,则在catch中回调第一个失败的结果。promise.race():只等待第一个结果或error(谁快返回谁
25. JS实现异步的方法
- 执行顺序:所有异步任务都是在同步任务执行完成后,从任务队列中取出依次执行
- 方式: - 宏任务: - 定时器
setTimeout、setTimeinterval-ajax请求:XMLHttpRequest、fetch、axios- 事件监听:on...,addEventListener- 微任务: -Promise.then-async/await - 异步在于创建宏任务和微任务,通过事件循环机制实现异步机制,在调用栈中执行完一个宏任务后,接着统一处理执行该宏任务期间产生的所有微任务,之后页面会进行一次重绘,再接着处理下一个宏任务
26. cookie sessionStorage localStorage 的区别
- 共同点: - 都是浏览器存储,都存储在浏览器本地- 三者的数据共享都遵循同源原则,
sessionStorage还限制必须是同一个页面 cookie由服务器写入,sessionStorage以及localStorage都是由前端写入cookie的生命周期由服务器端写入时就设置好的,localStorage是写入就一直存在,除非手动清除,sessionStorage是由页面关闭时自动清除cookie存储空间大小约4kb,sessionStorage及localStorage空间比较大,大约5M- 在前端给后端发送请求的时候会自动携带
cookie中的数据,但是SessionStorage、 LocalStorage不会 - 使用场景: -
cookie一般存储登录验证信息或者token-localStorage常用于存储不易变动的数据,减轻服务器压力-sessionStorage可以用来监测用户是否是刷新进入页面,如音乐播放器恢复进度条功能
27. 如何实现可过期的localstorage数据
- 1.惰性删除:获取数据的时候,拿到存储的时间和当前时间做对比,如果超过过期时间就清除
Cookie - 2.定时删除: - 每隔一段时间执行一次删除操作,并通过限制删除操作执行的次数和频率,来减少删除操作对CPU的长期占用- 获取所有设置过期时间的key判断是否过期,过期就存储到数组中- 遍历数组,每隔1S(固定时间)删除5个(固定个数),直到把数组中的key从
localstorage中全部删除
28. token 能放在cookie中吗
- 实现上是可以的,但功能上不推荐,容易产生
csrf问题 token是用来判断用户是否登录的,客户端输入用户名和密码,服务器收到请求,去验证用户名和密码,验证成功后,服务端签发一个token发送给客户端,客户端可以把它保存在cookie和localStorage应用下次验证登录,在cookie里面只要不设置时间就行token一般存储在sessionStorage/localStorage里面,它的出现就是为了解决用户登录后的鉴权问题,如果采用cookie + session的鉴权方式,则无法有效地防止CSRF攻击- 同时,如果服务端采用负载均衡策略进行分布式架构,
session也会存在一致性问题,需要额外的开销维护session一致性
29. axios的拦截器原理及应用
- 拦截器分为 请求(request)拦截器和 响应(response)拦截器 - 请求拦截器用于在接口请求之前做的处理,比如为每个请求带上相应的参数(token,时间戳等)- 返回拦截器用于在接口返回之后做的处理,比如对返回的状态进行判断(token是否过期)
- 原理: - 创建一个
chn数组,数组中保存了拦截器相应方法以及dispatchRequest(dispatchRequest这个函数调用才会真正开始下发请求)- 请求拦截器的方法放到dispatchRequest的前面,响应拦截器的方法放到dispatchRequest的后面- 请求拦截器和响应拦截器forEach将它们分unshift, push到chn数组中- 为了保证它们的执行顺序,需要使用promise,以出队列的方式对chn数组中的方法挨个执行 - 应用: - 从浏览器中创建
XMLHttpRequests- 从node.js创建http请求- 支持Promise API- 可拦截请求和响应- 可转换请求数据和响应数据- 可取消请求- 可自动转换JSON数据- 客户端支持防御XSRF
30. 创建ajax过程
- 1.创建异步对象,即
XMLHttpRequest对象 - 2.使用
open(method, url, async)设置请求参数- 参数分别是请求的方法、请求的url、是否异步- 第三个参数如果不写,则默认为 true - 3.发送请求:
send() - 4.注册事件:注册
onreadystatechange事件,状态改变时就会调用。如果要在数据完整请求回来的时候才调用,需要手动写一些判断的逻辑。 - 5.服务端响应,获取返回的数据
31. fetch请求方式
fecth是一种HTTP数据请求的方式,是XMLHttpRequest的一种替代方式,Fetch函数就是原生js,没有使用XMLHttpRequest对象。Fetch对象返回一个promise解析response来自request显示状态的方法XMLHTTPRequest特点:- 所有功能集中在一个对象上,写的代码可维护性不强且容易混乱- 不能适配新的Promise API- Fetch特点:- 精细的功能分割:头部信息,请求信息,响应信息等均分布在不同的对象上,可以处理各种复杂的数据交互场景- 也可以适配Promise API- 同源请求也可以自定义不带cookie,某些服务不需要cookie的场景下能少些流量
32. 有什么方法可以保持前后端实时通信
- 轮询:客户端和服务器之间会一直进行连接,每隔一段时间就询问一次- 适用于:小型应用,实时性不高
- 长轮询:对轮询的改进版,客户端发送HTTP给服务器之后,如果没有新消息就一直等待,有新消息才会返回给客户端- 适用于:一些早期的对及时性有一些要求的应用:web IM 聊天
iframe流:是在页面中插入一个隐藏的iframe,利用其src属性在服务器和客户端之间创建一条长连接,服务器向iframe传输数据(通常是HTML,内有负责插入信息的javascript),来实时更新页面- 适用于:客服通信等WebSocket:类似Socket的TCP长连接的通讯模式,一旦WebSocket连接建立后,后续数据都以帧序列的形式传输- 适用于:微信、网络互动游戏等SSE(Server-Sent Event):建立在浏览器与服务器之间的通信渠道,服务器向浏览器推送信息- 适用于:金融股票数据、看板等
33. 浏览器输入URL发生了什么
- 1.URL解析:判断浏览器输入的是搜索内容还是URL
- 2.查找缓存:如果能找到缓存则直接返回页面,没有缓存则需要发送网络请求页面
- 3.DNS域名解析:将域名转换为IP地址的过程,得到了服务器具体的IP地址,才可以进行TCP链接以及数据的传输
- 4.三次握手建立TCP连接:- 第一次握手:客户端主动链接服务器,发送初始序列号
seq=x与SYN=1同步请求标志,并进入同步已发送SYN_SENT状态,等待服务器确认- 第二次握手:服务端收到消息后发送确认标志ACK=1与同步请求标志SYN=1,发送自己的序列号seq=y以及客户端确认序号ack=x+1,此时服务器进入同步收到SYN_RECV状态- 第三次握手:客户端收到消息后发送确认标志ACK=1,发送自己的序列号seq=x+1与服务器确认号ack=y+1,发送过后即确认链接已建立状态ESTABLISHED,服务端接收确认信息后进入链接已建立状态ESTABLISHED - 5.发起HTTP请求:浏览器构建HTTP请求报文,并通过TCP协议传送到服务器的指定端口,HTTP请求报文共有三个部分:- 报文首部:通常包含请求行与各种请求头字段等- 空行:告诉服务器请求头部到此为止- 报文主体:即发送的数据信息,通常并不一定要有报文主体
- 6.服务器响应并返回结果:服务端响应HTTP请求,返回响应报文,HTTP响应报文由四部分组成:响应行、响应头、空行、响应体
- 7.通过四次握手释放TCP连接
- 8.浏览器渲染
- 9.JS引擎解析
34. 浏览器如何渲染页面
- 1.解析HTML,生成DOM树
- 2.解析CSS,生成CSSOM树
- 3.浏览器会将CSSOM树附着在DOM树上,并结合两者生成Render树
- 4.计算布局,浏览器通过解析计算出树的节点位置和大小,绘制页面的所有节点- 回流发生在这个阶段
- 5.绘制布局在屏幕上- 重绘发生在这个阶段
35. 重绘、重排区别如何避免
- 重排:DOM元素的布局发生变化,重新排列元素位置
- 重绘:DOM元素的样式发生变化,重新绘制元素图层
- 重排又叫回流,发生在重绘之前
- 避免重排和重绘的方式,即避免JS频繁操作DOM:
- 使用
fragment生成一个DOM切换,在切片上多次操作DOM再一次性更新到真实DOM上 Vue中虚拟DOM,多次操作虚拟DOM再一次性与真实DOM进行比较,减少操作DOM引起的重绘- 此外,JS引擎每次执行完宏任务之后,页面会重绘一次,控制宏任务的产生频率也能减少重绘
- 防抖和节流:控制事件处理程序的调用频率
36. 浏览器垃圾回收机制
- 有两种机制:标记清除、引用计数
- 标记清除:从根元素开始,周期性标记可被访问的对象,同时回收不可被访问的对象 - 问题:收集垃圾时程序会等待,且回收后的内存空间不连续
- 于是出现了标记-整理算法:标记结束后,算法将活动对象压入内存一端,则需要清理的对象在边界,直接被清理掉就行,但效率又会降低
- 引用计数:一个对象不被其他对象引用时会被回收 - 问题:循环引用时无法回收
37. 事件循环Event loop 宏任务与微任务
- 事件循环:- 遇见同步任务,直接推入调用栈中执行- 遇到异步任务,将任务挂起,等到异步任务有返回之后推入到任务队列中- 当同步任务全部执行完成,再从异步队列中依次执行
- 异步任务又分为宏任务和微任务
- 执行时,会先执行宏任务,再执行宏任务下所有的微任务,再开启下一次的宏任务执行
- 宏任务有:- 定时器-
Dom事件-ajax事件 - 微任务有:-
promise的回调-MutationObserver的回调-process.nextTick
38. 跨域是什么 如何解决跨域问题
- 跨域:当前页面中的某个接口请求的地址和当前页面的地址的协议、域名、端口其中有一项不同,就说该接口跨域了
- 跨域限制的原因:由浏览器的同源策略造成的,也是浏览器施加安全的限制
- 跨域解决方案: -
JSONP:利用script中src属性发送jsonp请求,但这种方式只支持get请求,且不安全- 前端proxy代理 + 后端nginx反向代理- 前端在vue-cli中在vue.config.js中的devServer配置proxy代理-nginx:node.js中间件代理跨域,通过node开启一个代理服务器- 后端服务器的CORS:配置响应头:setHeader(access-control-allow-origin,对应的域名),服务器开启跨域资源共享-postmessage:H5新增API,通过发送和接收API实现跨域通信
39. vue钩子函数
vue2
的钩子函数:
挂载阶段:
beforeCreate:创建实例之前 - 可访问data,watch,computed,methods上的方法和数据,可进行数据请求- 未挂载到DOM结构上,不能获得el属性- 如果要进行dom操作,就要用nextTick函数created:实例创建完成beforeMount:在挂载开始之前被调用mounted:实例挂载到DOM上- 可以通过DOM API获取
dom节点,可以进行数据请求
更新阶段:
beforeUpdate:响应式数据更新时调用 - 适合在更新之前访问现有的dom,比如手动移除已添加的事件监听器updated:组件DOM已经更新
销毁阶段:
beforeDestroy:实例销毁之前调用,this仍能获取到实例 - 常用于销毁定时器、解绑全局事件、销毁插件对象等操作destroyed:实例销毁之后
vue3
的与
vue2
做对比: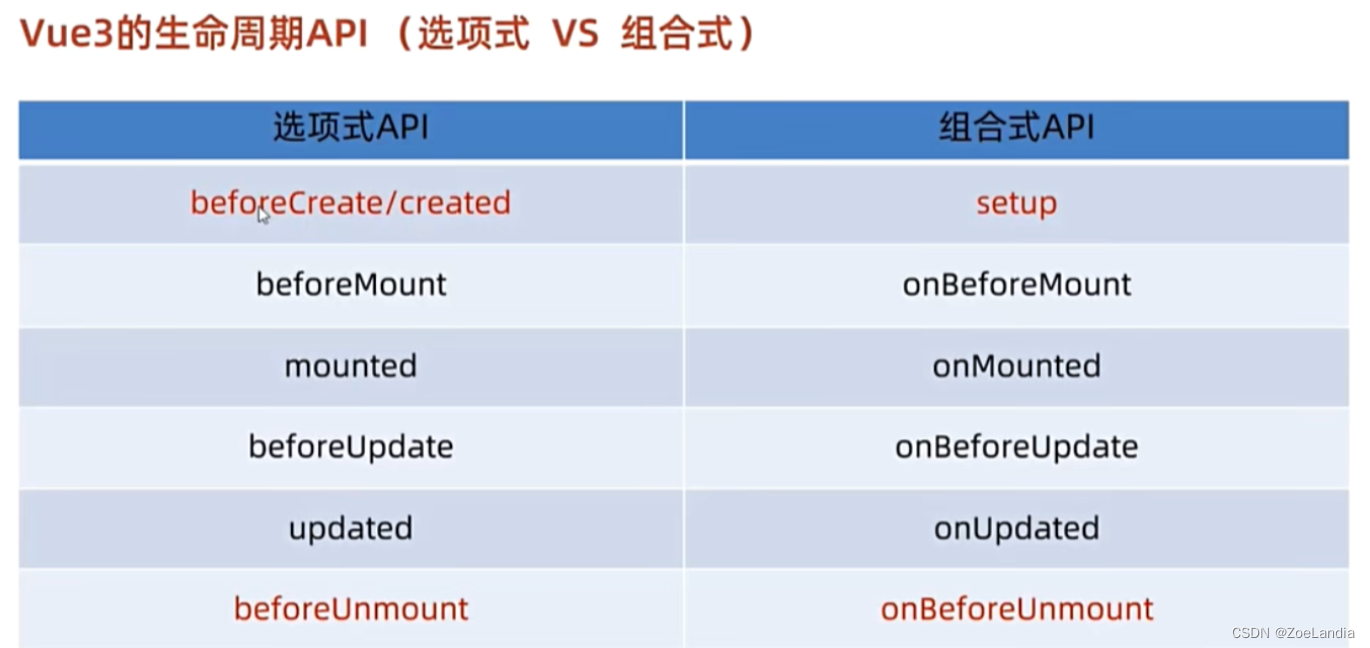
40. 组件通信的方式
Vue组件通信一般分为三大类:- 父子组件通信: - 最常见的使用
props和emit,父组件通过props将数据传递给子组件,子组件通过emit触发父组件中的方法来修改数据- 还可以通过$ref、$parent和$child进行通信 - 祖孙组件通信:一般也可以用
props和emit,只不过逐层传递会很麻烦,可以使用$listener和$attrs来进行通信 - 兄弟组件通信:可以创建
eventBus事件总线,通过$emit和$on的方式进行通信 - 其次还有全局数据通信,可以使用
Vuex作为全局状态管理来实现
41. computed和watch的区别
- 功能上: -
computed是计算属性-watch是监听一个值的变化,然后执行对应的回调 - 是否调用缓存: -
computed中的函数所依赖的属性没有发生变化,那么调用当前的函数会从缓存中读取-watch在每次监听的值发生变化的时候都会执行回调 - 是否调用return: -
computed中的函数必须要用return-watch中的函数不是必须要用return - 是否第一次加载就监听: -
computed默认第一次加载的时候就开始监听-watch默认第一次加载不做监听,如果需要第一次加载做监听,添加immediate:true - 使用场景: - computed: - 一个属性受多个属性影响的时候- 购物车商品结算- watch: - 一条数据影响多条数据的时候- 搜索框
42. v-if 和 v-show区别
- 都是控制元素隐藏和显示的指令,区别如下:
- 实现方式: -
v-if:动态向DOM树内添加或者删除DOM元素-v-show:通过设置DOM元素的display样式属性控制显隐 - 编译过程: -
v-if切换有一个局部编译卸载的过程,切换过程中合适地销毁和重建内部的事件监听和子组件-v-show只是简单的基于CSS切换 - 编译条件: -
v-if是惰性的,如果初始条件为假,则什么也不做,只有在条件第一次变为真时才开始局部编译-v-show是在任何条件下都被编译,然后被缓存,而且DOM元素保留 - 性能消耗: -
v-if有更高的切换消耗-v-show有更高的初始渲染消耗 - 使用场景: -
v-if适合条件不太可能改变的情况-v-show适合条件频繁切换的情况
43. vue 的 keep-alive
- 作用:能在内存保持其中的组件状态,放置重复渲染DOM,减少加载时间,从而提高性能
- 有三个属性: -
include:只有匹配的组件才会被保存-exclude:只有匹配的组件才不会被保存-max:最多能保存的组件数,使用LRU算法替换 - 结合
Router使用:在相应组件下规定mate属性,并将keep-alive设置为true - 源码实现方面: - 结合
Vue组件实例加载顺序讲解:VNode-> 实例化 ->_updata-> 真实Node- 在实例化的时候会判断该组件是否被keep-alive保存过,是的话则直接拿其中的DOM进行渲染
44. Vue 中 $nextTick 作用与原理
- 作用:
Vue更新DOM是异步执行的,当数据发生变化时,Vue会开启一个异步更新队列,视图需要等队列中所有数据更新完后再更新视图,所以$nextTick可以解决这样的问题,相当于一种优化策略 - 原理: - 1.把回调函数放入
callbacks等待执行- 2.将执行函数放到微任务或者宏任务中- 3.事件循环到了微任务或者宏任务,执行函数依次执行callbacks中的回调
45. Vue 列表为什么加 key
key实际上是给vnode的唯一标识,也是diff的一种优化策略,可以根据key更快更准确找到对应的vnode节点 -diff算法判断新旧VDOM是否相同的依据是节点的tag和key,如果tag和key相同则会进一步进行比较,使得尽可能多的节点进行复用- 如果不用
key就会使用就地复用原则,下一个元素使用上一个在当前位置元素的状态 - 如果在一个
v-for list里面,删除中间的一个item,后面的index都会变化,那么diff就会计算出后面的item的key-index映射都发生了变化,就会全部重新渲染,大大影响性能
46. vue-router 实现懒加载的方法
- 核心思想:按需加载(异步加载),只有请求到该组件的时候,才会对该组件进行网络请求并加载
- 懒加载有利于解决页面首次请求资源过多,导致白屏时间长的问题
- 实现方法:
ES6的import方式:conponent:( )=>import(/*webpackChunkName:"about" */'.../views/About.vue')Vue中的异步组件:component:resolve=>(require['../views/About'],resolve)- 动态
import:在Webpack2中,可以使用动态import语法来定义代码分块点split point
47. HashRouter 和 HistoryRouter的区别和原理
history和hash都是利用浏览器的特性实现前端路由hashRouter原理:通过window.onhashchange获取url中hash值,修改实现对应跳转historyRouter原理:通过H5提供的pushState,replaceState…等实现url的修改和对应跳转,也可以通过监听popState事件来监听用户点击前进、后退按钮实现对应跳转- 区别如下: -
hash是监听location hash值变化事件来实现-history是利用浏览历史记录栈的API实现 - 形式上: -
hash的url有#号-history的url没有#号 history是H5新增,需要后端协助实现- 因为hash模式#后面的hash值不会带入请求url中,所以服务器觉得hash模式下的url是不变的- 而history模式url在/a /b之间不断变化,必须要服务器对这些请求进行重定向,一直返回一个指定页面即可
48. Vuex是什么 每个属性是干嘛的 如何使用
Vuex是为Vue开发的管理状态模式,集中存储管理所有组件的状态- 属性分别是
state、getters、mutations、actions、module - (1)
state用来定义所要存储的数据,通过$store.state调用数据 - (2)
getters可以认为是store的计算属性,通过$store.getters调用属性 - (3)
mutations用来存放改变state数据的同步方法,每个方法接收的参数都是state,用$store.commit来调用mutations中的同步方法 - (4)
actions用来存放异步方法,接收的参数是context(mutations中的方法),通过$store.dispatch调用actions中的方法 - (5)
module将store分割成模块,每个模块有自己的state、getters、mutations、actions,甚至嵌套子模块,从上至下进行同步分割 - 前四个属性除了用
$store的方法调用,还能通过import { mapState/mapGetters/... } from 'vuex'引入,再用...mapState/mapGetter/...(['属性/方法名'])的形式映射进来调用
49. Vue2.0 双向绑定的原理与缺陷
- 原理:数据劫持
defineProperty+ 发布订阅者模式- 当vue实例初始化后observer会针对实例中的data中的每一个属性进行劫持- 并通过defineProperty()设置值后在get()中向发布者添加该属性的订阅者- 在编译模板时就会初始化每一属性的watcher,在数据发生更新后调用set的时候会通知对应的订阅者做出数据更新,同时将新的数据更新到视图上显示 - 缺陷: - 只能够监听初始化实例中的
data数据,动态添加值不能响应,要使用对应的Vue.set()- 无法监听数组长度和index变化问题,defineProperty只能监听对象的单个属性,需要递归对所有属性的监听,VUE3已经改成proxy
50. Vue3.0 实现数据双向绑定的方法
- 在
Vue2.0的基础上将Object.definedproperty换成了proxy,原理相同 - 在
vue实例初始化的时候调用Observe类的实例方法observe,传入数据(若是对象则发生递归) - 将每个数据进行一遍数据劫持-
get实现依赖收集-set实现事件派发(这里的模式为发布订阅模式) - 相对
vue2.0解决的问题: - 解决无法监听新增属性或删除属性的响应式问题- 解决无法监听数组长度和index变化问题
51. 前端性能优化手段
1. HTML&&CSS
- 减少
DOM数量,减轻浏览器渲染计算负担 - 使用异步和延迟加载
js文件,避免js文件阻塞页面渲染 - 压缩
HTML、CSS代码体积,删除不要的代码,合并CSS文件,减少HTTP请求次数和请求大小 - 减少
CSS选择器的复杂程度,复杂度越高浏览器解析时间越长 - 避免使用
CSS表达式在javascript代码中 - 使用
css渲染合成层如transform、opacity、will-change等,提高页面相应速度减少卡顿现象 - 动画使用
CSS3过渡,减少动画复杂度,还可以使用硬件加速
2. JS
- 减少
DOM操作数量 - 避免使用
with语句、eval函数,避免引擎难以优化 - 尽量使用原生方法,执行效率高
- 将
js文件放到文件页面底部,避免阻塞页面渲染 - 使用事件委托,减少事件绑定次数
- 合理使用缓存,避免重复请求数据
3. Vue
- 合理使用
watch和computed,数据变化就会执行,避免使用太多,减少不必要的开销 - 合理使用组件,提高代码可维护性,同时也会降低代码组件的耦合性
- 使用路由懒加载:在需要的时候才会进行加载,避免一次性加载太多路由,导致页面阻塞
- 使用
Vuex缓存数据 - 合理使用
mixins,抽离公共代码封装成模块,避免重复代码 - 合理使用
v-if、v-show v-for不要和v-if一起使用,v-for的优先级会比v-if高v-for中不要用index做key,要保证key的唯一性- 使用异步组件,避免一次性加载太多组件
- 避免使用
v-html,存在安全问风险和性能问题,可以使用v-text - 使用
keep-alive缓存组件,避免组件重复加载
4. Webpack优化
- 代码切割:使用
code splitting将代码进行分割,避免将所有代码打包到一个文件,减少响应体积 - 按需加载代码:在使用使用的时候加载代码
- 压缩代码体积
- 优化静态资源:使用字体图标、雪碧图、
webp格式的图片、svg图标等 - 使用
Tree Shaking删除未被引用的代码 - 开启
gzip压缩 - 静态资源使用
CDN加载,减少服务器压力
5. 网络优化
- 使用
HTTP/2 - 减少、合并
HTTP请求:通过合并CSS、JS文件、精灵图等方式减少请求数量 - 压缩文件:开启
nginx,Gzip对静态资源压缩 - 使用
HTTP缓存:如强缓存、协商缓存 - 使用
CDN:将网站资源分布到各地服务器上,减少访问延迟
52. 性能优化有哪些性能指标 如何量化
- 首屏加载时间FCP:浏览器首次绘制页面中至少一个文本、图像等元素的时间,代表页面首次加载的时间点
- 首次绘制时间FP:浏览器首次在屏幕中渲染像素的时间,代表页面开始渲染的时间点
- 最大内容绘制时间LCP:页面上最大的可见元素绘制完成的时间,代表用户视觉上感知到页面加载完成的时间点
- 用户可交互时间TTI:页面加载完成并且用户能够与页面进行交互的时间,代表页面可以开始操作页面的时间点
- 页面总阻塞时间TBT:在页面变得完全交互之前,用户与页面上的元素交互时出现阻塞的时间 - TBT应该尽可能小,通常在300毫秒之内
- 量化的方法: -
Chrome Performance选项卡-Lighthouse生成性能检测报告- 浏览器的开发者模式:可以调用性能监测API 或 建立前端监控系统(无痕埋点)
53. 服务端渲染SSR
- 概念:从服务端侧完成页面DOM结构和数据的拼接,再发送给浏览器,为其绑定事件和状态,能完成交互的过程
- 实现方式: - 传统的
JSP-express+react-express+ejs-vue+nuxt - 优点: - 减少前端耗时,解决首屏加载慢问题- 利于
SEO- 无需占用客户端资源 - 缺点: - 占用更多服务器端资源(更多的CPU和内存)- 部署和开发要求稍高,前后端耦合
- 使用场景: - 一般不会用在公司项目内,涉及前后端分离开发问题- 可以用户博客网站、官网、营销类网站等比较注重加载速度和渲染效率的时候
54. XSS攻击
- XSS是跨站脚本攻击
- 攻击者可以通过向Web页面里面插入
script代码,当用户浏览这个页面时,就会运行被插入的script代码,达到攻击者的目的 - 危害: - 泄露用户的登录信息
cookie- 恶意跳转:直接在页面中插入window.location.href进行跳转 - 防止XSS攻击的方法: - 对输入框内容进行过滤和转码:过滤掉用户输入的与事件有关的回调,如
onclick,过滤掉用户输入的style,script标签- 设置cookie的httponly:告诉浏览器不对客户端开放访问权限- 对用户的输入做html实体编码- 不对html实体直接进行解码
55. CSRF攻击
- 概念:跨域请求伪造
- 被攻击的情况: - 目标站点仅使用
cookie来验证,并且cookie是允许跨域的,这就使得恶意站点的页面能拿到用户的cookie- 目标站点后端没有验证请求的来源,导致任何带有效cookie的请求都被处理- 用户被诱导访问了恶意站点 - 预防CSRF攻击主要有以下策略:
- 使用验证码:在表单中添加一个随机的数字或者字母验证码,强制要求用户和应用进行直接的交互
- HTTP中
Referer字段:检查是不是从正确的域名访问过来,它记录了HTTP请求的来源地址 - 使用
token认证:在HTTP请求中添加token字段,并且在服务器建立一个拦截器验证这个token,如果token不对,就拒绝这个请求
56. Diff算法
- 出现:主流框架中多采用
VNode更新结点,更新规则为diff算法 - 原理:- 框架会将所有的结点先转化为虚拟节点
Vnode- 在发生更改后将VNode和原本页面的OldNode进行对比- 以VNode为基准,在oldNode上进行准确的修改- 修改准则: - 原本没有新版有,则增加- 原本有新版没有,则删除- 都有则进行比较: - 都为文本结点则替换值- 都为静态资源不处理- 都为正常结点则替换
本文转载自: https://blog.csdn.net/triggerV/article/details/136597958
版权归原作者 ZoeLandia 所有, 如有侵权,请联系我们删除。
版权归原作者 ZoeLandia 所有, 如有侵权,请联系我们删除。