
一、分区表
避免全表扫描, 减少扫描次数, 提高查询效率.
create table t_all_hero_part(
字段1 类型 comment '字段描述信息',
字段2 类型 comment '字段描述信息',
……
) comment '表描述信息'
partitioned by (分区字段 类型 comment '分区字段描述信息')
row format delimited fields terminated by '分隔符';
1.新建分区表
create table t_all_hero_part(
id int comment 'ID',
name string comment '英雄',
hp_max int comment '最大生命',
mp_max int comment '最大法力',
attack_max int comment '最高物攻',
defense_max int comment '最大物防',
attack_range string comment '攻击范围',
role_main string comment '主要定位',
role_assist string comment '次要定位'
) comment '射手表'
partitioned by (role string comment '角色字段-充当分区字段')
row format delimited fields terminated by '\t';
--分区字段(role)必须是表中没有的字段.
2.向分区表插入数据
1.静态分区
需要几个分区文件就写几次完整代码,来上传数据
load data [local] inpath '路径'
into table t_all_hero partition(role='archer');
--写local是Linux路径,不写为HDFS路径
--注意这个role='archer'是分区的文件名,图1
2.动态分区
原表:
后面动态分区表需要用原表插入内容
create table t_all_hero(
id int comment 'ID',
name string comment '英雄',
hp_max int comment '最大生命',
mp_max int comment '最大法力',
attack_max int comment '最高物攻',
defense_max int comment '最大物防',
attack_range string comment '攻击范围',
role_main string comment '主要定位',
role_assist string comment '次要定位'
) comment '射手表'
row format delimited fields terminated by '\t';
关闭严格模式后,就可以通过动态分区的方式插入数据
直接运行命令:set hive.exec.dynamic.partition.mode=nonstrict;
insert into table t_all_hero_part
partition(role)
select *,role_main from t_t_all_hero;
原表和分区表的文件区别
原表(t_all_hero)
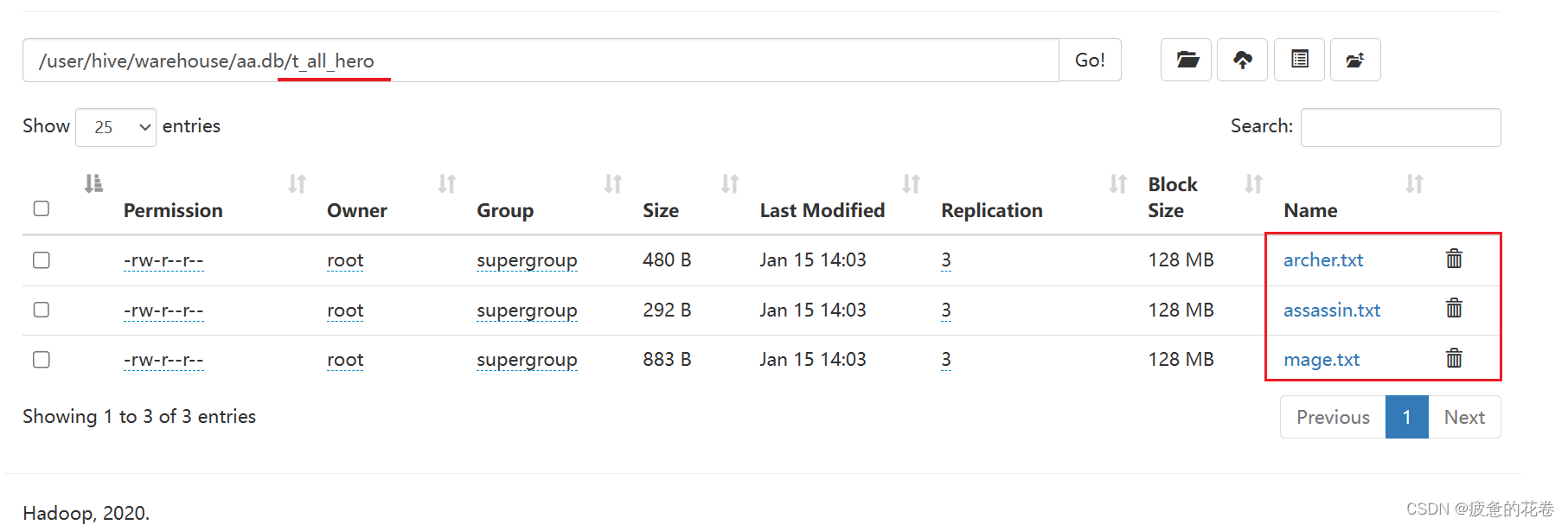

分区表(t_all_hero_part)

打开role=arhcer然后打开000000_0查看插入的内容
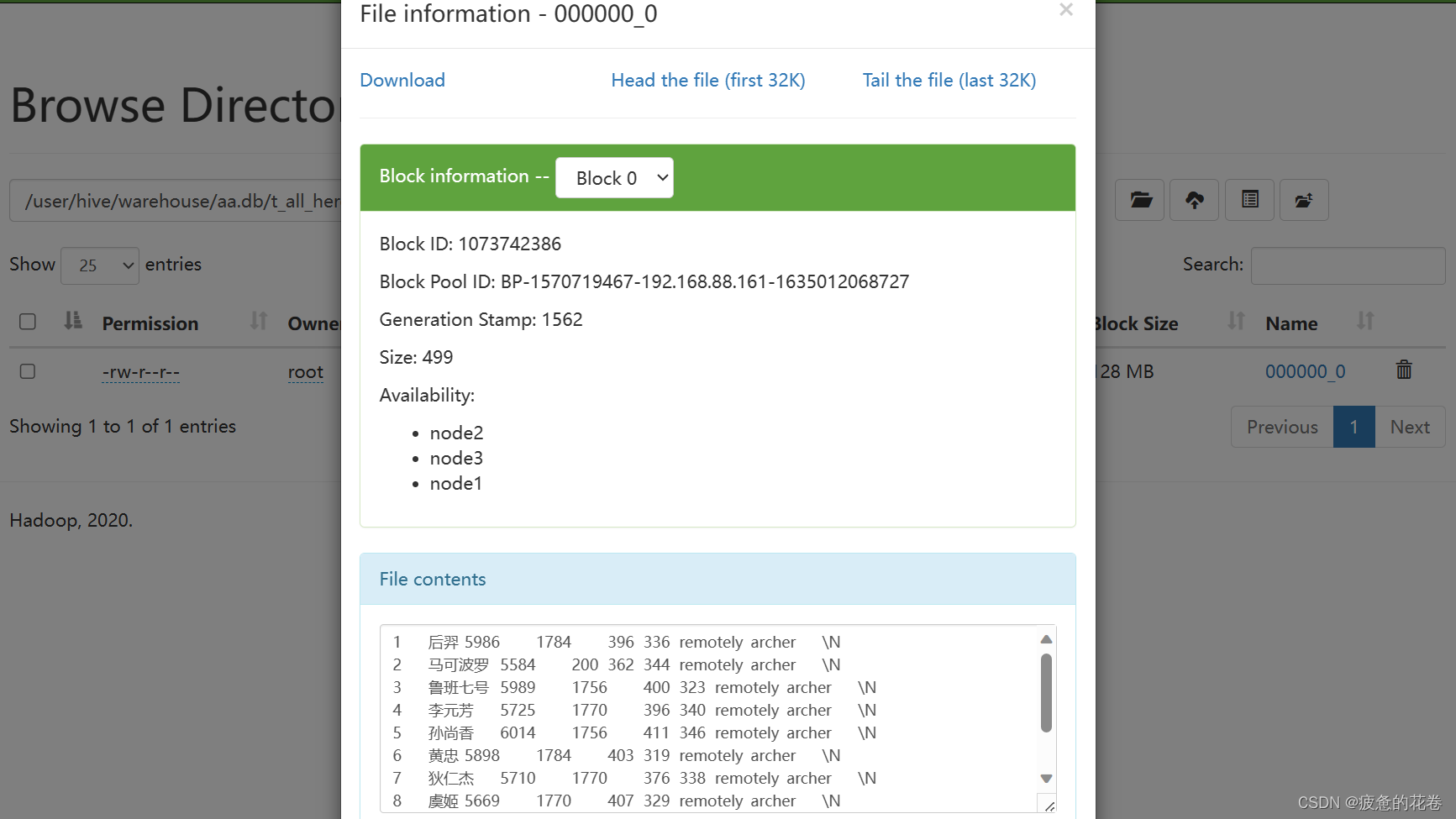
原表2
完整的.txt文件内部包含两种role信息(archer和assassin)
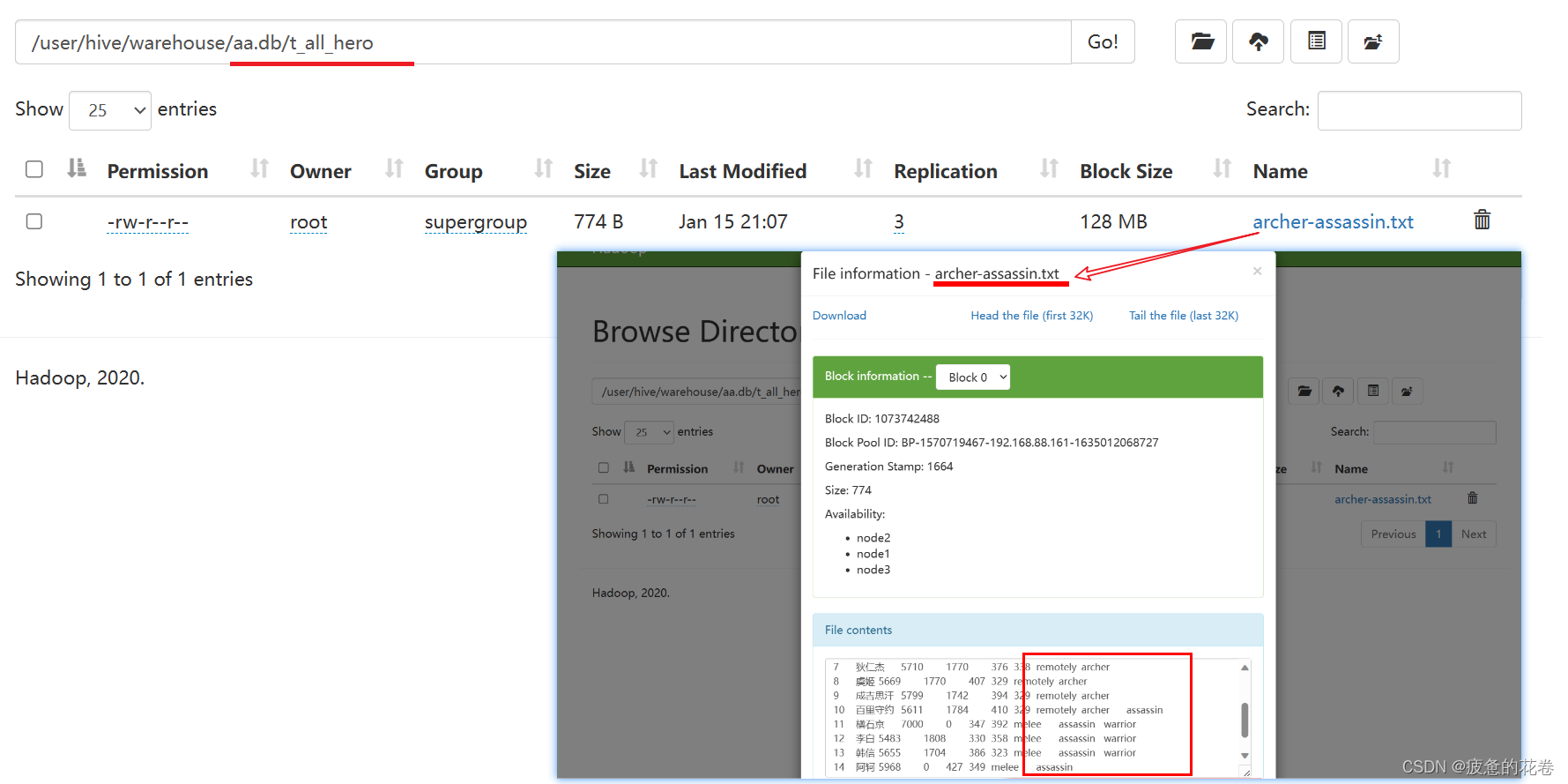
create table t_all_hero_part(
id int comment 'ID',
name string comment '英雄',
hp_max int comment '最大生命',
mp_max int comment '最大法力',
attack_max int comment '最高物攻',
defense_max int comment '最大物防',
attack_range string comment '攻击范围',
role_main string comment '主要定位',
role_assist string comment '次要定位'
) comment '射手表'
partitioned by (role string comment '角色字段')
row format delimited fields terminated by '\t';
set hive.exec.dynamic.partition.mode=nonstrict;
--插入数据
insert into table t_all_hero_part
partition(role)
select *,role_main from t_all_hero;
show partitions t_all_hero_part;
分区表2内容
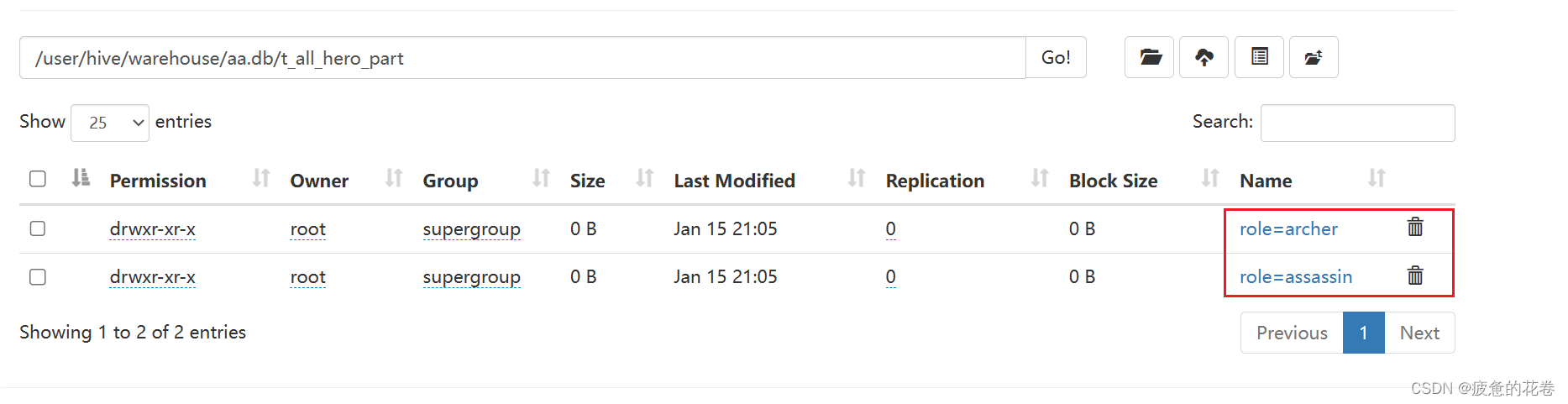
3.创建多级分区
注意:分区字段的个数
alter table t_all_hero_part add partition(role='mage');
create table products(
pid int,
pname string,
price int,
cid string
) comment '商品表'
partitioned by (year int, month int) -- 按照年, 月分区, 2级分区
row format delimited fields terminated by ',';
添加分区数据
alter table products add partition(year=2023,month=1)
partition(year=2024,month=4);
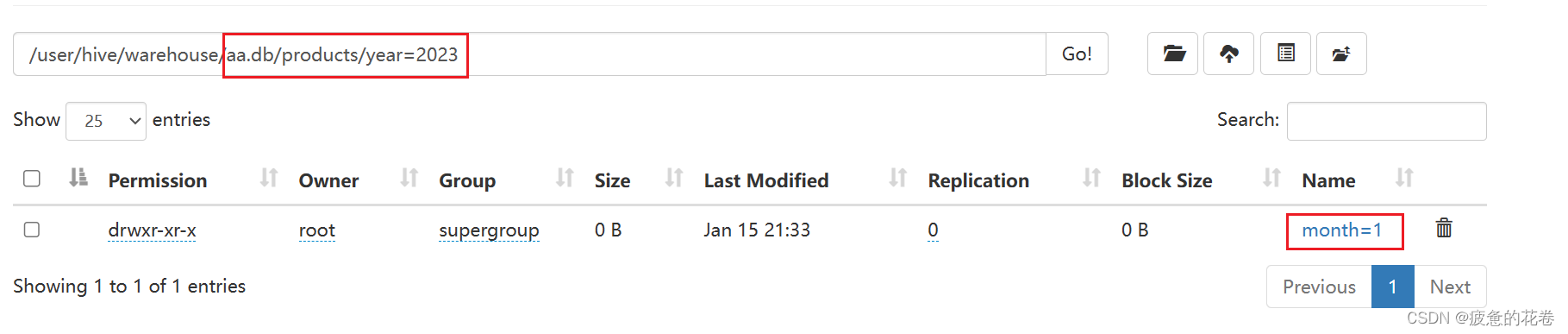
分区的个人总结:
分区是针对文件夹(内部文件例如.txt也会被分),原理和SQL的group by类似,是将原表中一个或多个文件,通过给新字段对应原表字段分区,分成多个文件夹存放文件,存放到分区表中,这样在扫描特定文件(以分区字段来查询)的时候不需要全盘扫描。
查询某个分区的数据.
select * from products where role=archer;
二、分桶表
分桶 = 分文件, 相当于把数据 根据分桶字段, 拆分成N个文件.
作用:
1. 方便进行数据采样.
2. 减少join的次数, 提高查询效率.
细节:
1. 分桶字段必须是表中已有的字段.
2. 分桶数量 = HDFS文件系统中, 最终的文件数量.
3. 分桶规则用的是: 哈希取模分桶法, 简单来说, 就是根据分桶字段计算它的哈希值, 然后和桶的个数取余, 余数为几, 就进哪个桶
4. set mapreduce.job.reduces=n; 可以设置ReduceTask任务的数量, 这个设置只在 分桶查询中会用到.
分桶建表的时候, 不用该参数.
5. 分桶表的数据不建议load data方式 或者 手动上传, 而是: insert into | overwrite的方式添加.
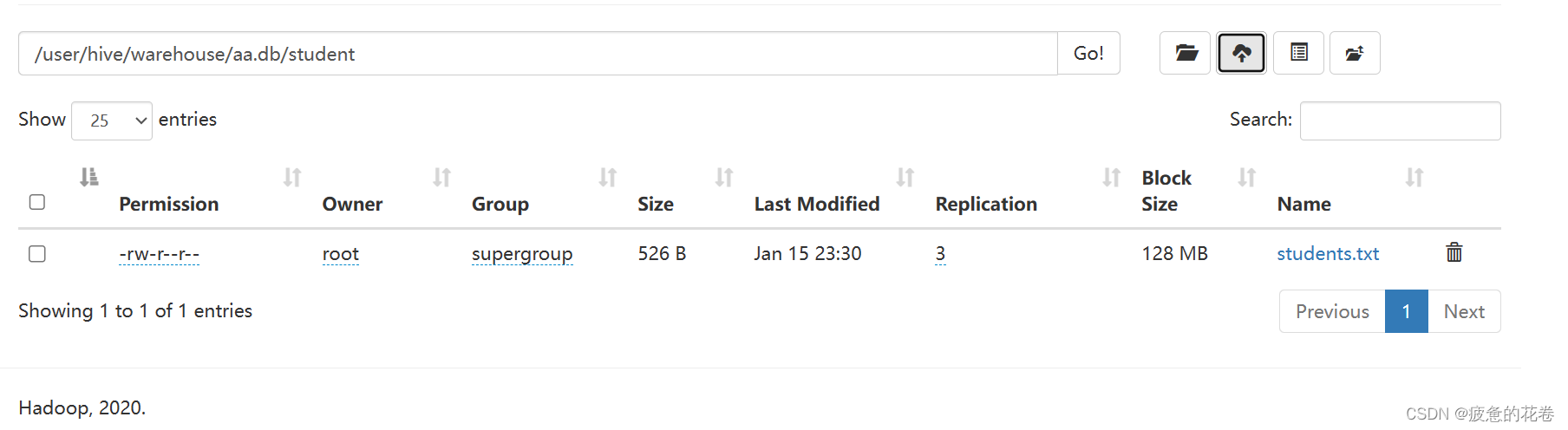
1.新建原表
create table student(
sid int,
name string,
gender string,
age int,
major string
) comment '学生信息表'
row format delimited fields terminated by ',';

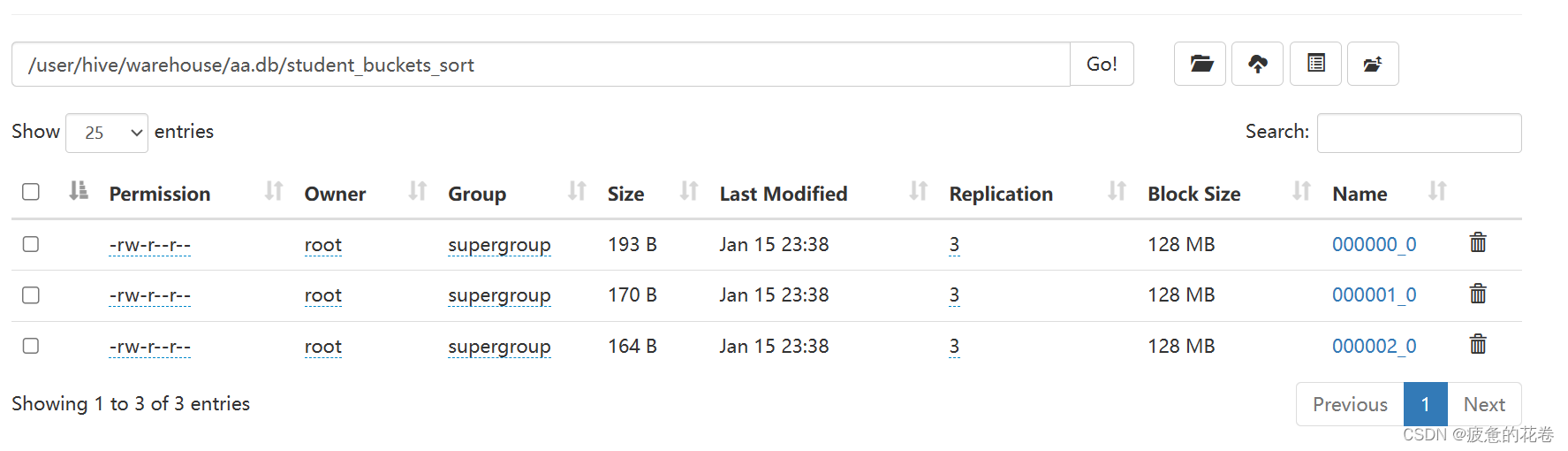
2.建立分桶表并按照sid排序
create table student_buckets_sort(
sid int,
name string,
gender string,
age int,
major string
) comment '学生信息表'
clustered by (sid) sorted by (sid) into 3 buckets;
-- 按照学生id进行分桶, 分成 3 个桶, 桶内部按照 sid 升序排列.
3.向分桶表插入数据
insert into table student_buckets_sort select * from student;
4.分桶原理
哈希值: 根据值的内容, 内存地址值等信息, 计算出来的1个数字.
hash('数值或者文本') 函数返回一个值然后模要分桶的个数
例如:sid的值 模 分桶个数3 结果可能为 0、1、2 那么记录讲会均匀的分到0、1、2三个桶中。
select hash(123); -- 整数的哈希值, 是本身.
select hash('乔峰'); -- 哈希值: -870432061
select hash('乔峰') % 3; -- -1
5.分桶排序
cluster by(分桶且排序,分桶字段和排序字段必须一样)
distribute by(分桶)+sort by(排序)(分桶字段和排序字段可以不一样)
select * from 分桶表 cluster by 分桶字段;
select * from 分桶表 distribute by 分桶字段 sort by 排序字段;
三、复杂类型
1.array
数据格式

建表
array中只能存储字符串类型数据.
切割后, 数据格式为: "zhangsan", ["beijing", "shanghai" ,"tianjin", "hangzhou"]
create table t_array(
name string comment '姓名',
city array<string> comment '城市'
)
row format delimited fields terminated by '\t'
collection items terminated by ','; --array内部切割方式
查询数据信息
select name,city,size(city) from t_array;
--size(复杂类型) 可以查看复杂类型的元素个数。
select name,city[0] from t_array;
--查询city中的第一个值
select name,city,array_contains(city,'tianjin') from t_array;
--array_contains(列名,'查询的值'),查询数组中是否包含‘tianjin’返回结果为 true/false
select name,city from t_array where not array_contains(city,'tianjin');
--查询 city列 不包含tinajin的值,不加not就是包含tianjin的
2.struct
数据格式
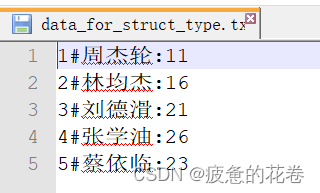
建表
create table t_struct(
id int,
info struct<name:string,age:int> --<key:values,key:values,……>
)
row format delimited fields terminated by '#' -- 切割后: "1", "周杰轮:11"
collection items terminated by ':'; --collection items 是负责切割: 数组, 结构体的
查询数据
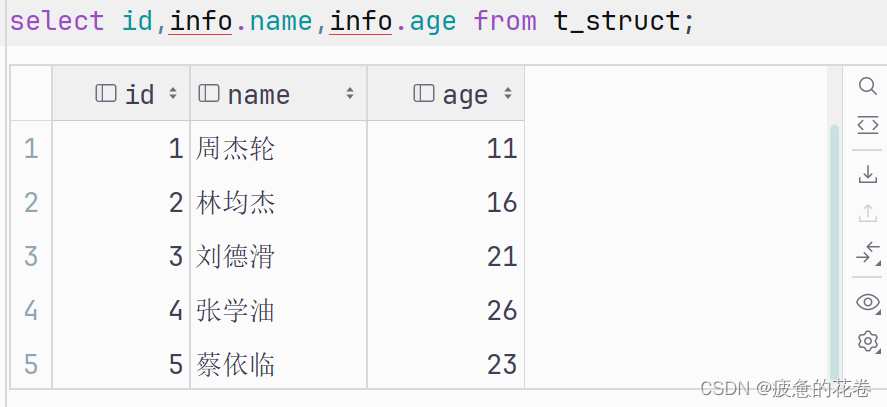
select id,info.name,info.age from t_struct;
3.map
数据格式

建表
create table t_map(
id int comment '编号',
name string comment '姓名',
members map<string, string> comment '家庭成员', -- 左边的string: 键的类型, 右边的string: 值的类型.
age int comment '年龄'
)
row format delimited fields terminated by ',' -- 切完后, 数据为: 1, "林杰均", "father:林大明#mother:小甜甜#brother:小甜", 28
collection items terminated by '#' -- 切完后, 数据为: 1, "林杰均", ["father:林大明", "mother:小甜甜", "brother:小甜"], 28
map keys terminated by ':'; -- 切完后, 数据为: 1, "林杰均", {"father" : "林大明", "mother" : "小甜甜", "brother" : "小甜"}, 28
查询数据

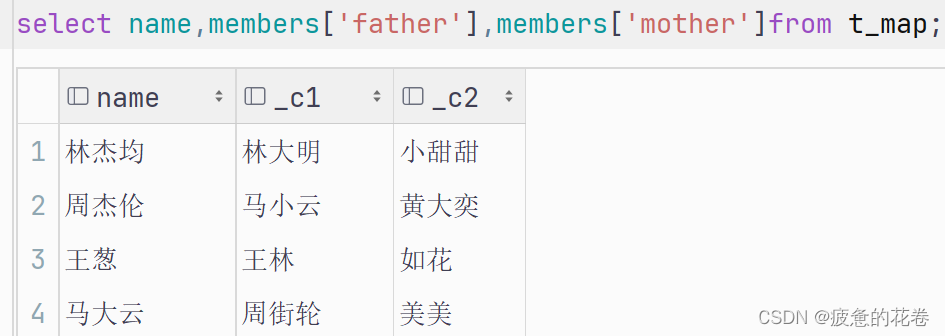
查找某个key 的值
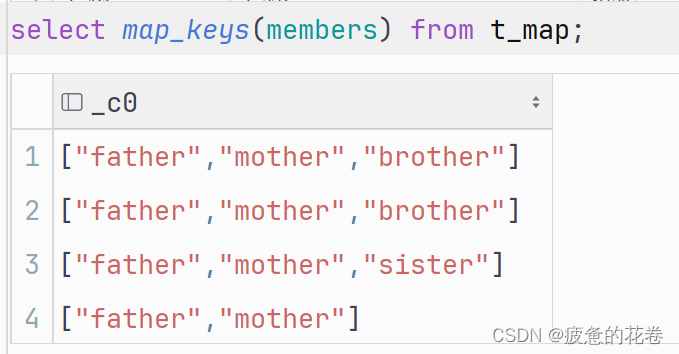
查看map 的key
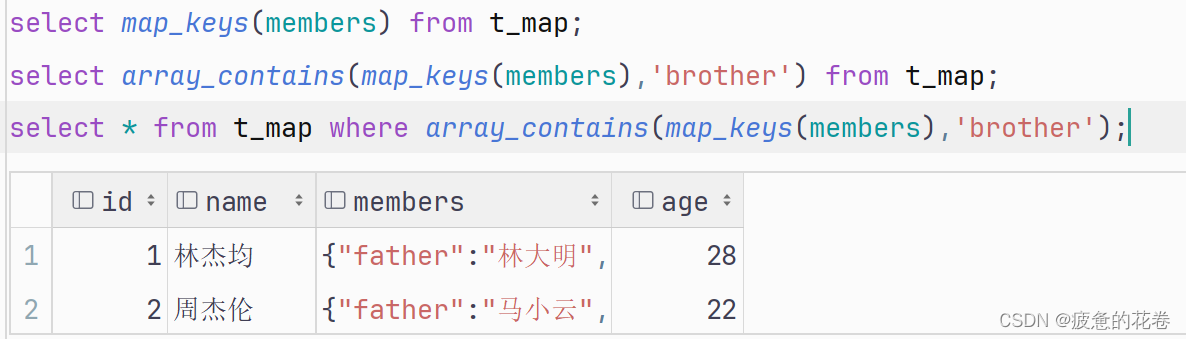
查看map的value

例题:查询map的key中有brother的数据
1.查询t_map表members列中所有的key
2.查询brother键是否在members列中
3.筛选数据
4.插入数据
insert into t_map(id,name,members,age) values(18,邓紫棋,member('father:XXX,mother:XXX,brother:XXX'));
版权归原作者 疲惫的花卷 所有, 如有侵权,请联系我们删除。