
python之web自动化<二> 戳这里
一图了解整个代码驱动浏览器的过程: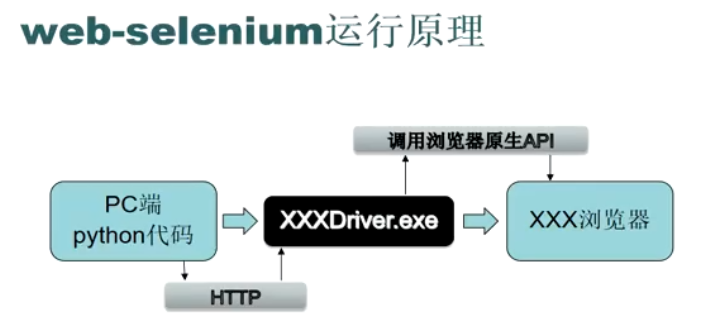
前提:Chrome浏览器驱动下载地址:
http://chromedriver.storage.googleapis.com/index.html
Firefox(火狐)浏览器驱动:
https://github.com/mozilla/geckodriver/releases/
一、基本操作
a.
from selenium import webdriver
# 启动浏览器
driver = webdriver.Chrome(service_log_path='C:\\Users\\joinkwang\\test\\test_project\\common\\chormelog.log')# 访问一个网页
driver.get("http://devci01:8080/login?from=%2F")# 退出访问或者会话 杀掉进程 不占用资源
driver.quit()# 关闭当前窗口 没有杀掉进程 没有退出浏览器进程
driver.close()
b.
from selenium import webdriver
import time
# 启动浏览器
driver = webdriver.Chrome(service_log_path='C:\\Users\\joinkwang\\test\\test_project\\common\\chormelog.log')# 访问一个网页
driver.get("http://devci01:8080/login?from=%2F")# 窗口最大化
driver.maximize_window()# 访问另一个网页
driver.get("http://www.taobao.com")# 退回上一页
driver.back()
time.sleep(1)# 强制等待1S
driver.implicitly_wait(5)# 隐形等待5S,如果等到了进程马上运行,如没有等到,5秒后报错# 退回下一页
driver.forward()# 刷新
driver.refresh()# 获取标题print(driver.title)# 获取网址print(driver.current_url)# 窗口的IDprint(driver.current_window_handle)
二、元素定位。
方式一三:定位对象
方式二:定位对象
方式五:定位对象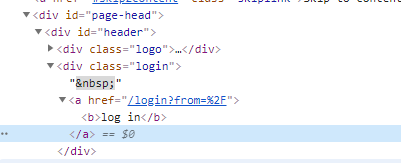
# 元素定位# id、classname、tagname、name、# 启动浏览器
driver = webdriver.Chrome(service_log_path='C:\\Users\\join\\test\\test_project\\common\\chormelog.log')# 访问一个网页
driver.get("http://devci01:8080/login?from=%2F")# 方式一# 查找页面的ID属性,定位元素
ele = driver.find_element_by_id("j_username")print(ele)# 通过查找ID属性对象获取里面的其他属性 autocorrect 和 name等print(ele.get_attribute("autocorrect"))print(ele.get_attribute("name"))# 方式一结果:<selenium.webdriver.remote.webelement.WebElement (session="026d2df4659386ea5bfbe5e25f86e615", element="289aa174-5587-4988-95f2-af72c59254b4")>
off
j_username
# 方式二# find_elements_by_class_name 找class属性 找到class=“noedge”的列表 可能存在多个 noedge 的元素
eles = driver.find_elements_by_class_name("yui-button")print(eles[0])print(eles[0].get_attribute("name"))# find_element_by_class_name 只找到class=“noedge” 的第一个元素(从上往下第一个出现的class=noedge)
eles = driver.find_element_by_class_name("yui-button")# 如果存在多个对象值 选其中一个即可print(eles)print(eles.get_attribute("name"))
方式二结果:
<selenium.webdriver.remote.webelement.WebElement (session="36d96286eefc3d36e109e1911fb47fc6", element="ea3c71e9-c02a-4192-acd6-ec671d99b639")>
Submit
# 方式三# 与方式二一样,elements 返回对象为列表 查找多个 找name属性
eles = driver.find_elements_by_name("j_username")
eles = driver.find_element_by_name("j_username")# 结果与方式一一致# 方式四 查找标签名 与方式二一样
eles = driver.find_elements_by_tag_name("input")# eles = driver.find_element_by_tag_name("input")for i in eles:print(i)# 返回结果:<selenium.webdriver.remote.webelement.WebElement (session="2dece12c51717c69dfd1bcff663d118a", element="043cfe82-17b2-42f4-9d10-57fdcadea7f7")><selenium.webdriver.remote.webelement.WebElement (session="2dece12c51717c69dfd1bcff663d118a", element="be6b54a1-392f-4b41-ad9b-c310c14786f7")><selenium.webdriver.remote.webelement.WebElement (session="2dece12c51717c69dfd1bcff663d118a", element="4d1ab5e9-4357-40e7-9dcd-ce8cdef7e81f")><selenium.webdriver.remote.webelement.WebElement (session="2dece12c51717c69dfd1bcff663d118a", element="62ff10dc-6e36-44d4-a0e3-45926ab4bf0c")><selenium.webdriver.remote.webelement.WebElement (session="2dece12c51717c69dfd1bcff663d118a", element="b779310a-b10d-470f-b231-6bf129e940dc")><selenium.webdriver.remote.webelement.WebElement (session="2dece12c51717c69dfd1bcff663d118a", element="9319edf1-e164-4784-84c0-dedad1cd06fa")><selenium.webdriver.remote.webelement.WebElement (session="2dece12c51717c69dfd1bcff663d118a", element="1658fbe0-a20d-43f2-835b-34dc89381dae")><selenium.webdriver.remote.webelement.WebElement (session="2dece12c51717c69dfd1bcff663d118a", element="a9f6bd6b-8255-407e-bf3f-8822653350ed")># 方式五 针对链接 文字
eles = driver.find_element_by_partial_link_text("log in")# 精准查找# driver.find_elements_by_partial_link_text("in") # 模糊查找# driver.find_element_by_partial_link_text("in") # 模糊查找print(eles.get_attribute("href"))# 返回结果:
http://devci01:8080/login?from=%2F
方式六:xpath定位 xpath:1、相对定位和绝对定位: jenkins登录页面
xpath:1、相对定位和绝对定位: jenkins登录页面
# expat 和 css 多种定位条件的综合组合# 相对定位 以//开头 不依赖于页面的顺序和位置 只看整个页面有没有符合表达式的元素# //标签名称[@属性名称=值]# 单个条件://input[@name="j_username"]# 多个条件://input[@name="j_username" and @type="text"]
ls ='//input[@name="j_username"]'
eles = driver.find_element_by_xpath(ls)print(eles.get_attribute("id"))# 返回值:
j_username
# 绝对定位 以//开头 非常依赖于页面的顺序和位置//*[@id="main-panel"]/div/form/table/tbody/tr[2]/td[2]/input
绝对定位快捷方便,但是后续不稳定,如图:
xpath:2、相对定位中的层级定位:jenkins登录页面
# xpath中相对定位中的层级定位 注意:// 代表后代的子子孙孙后代;/代表是直系下一代。
ls ='//div[@style="margin: 2em;"]//input[@name="j_username"]'# ls = '//*[@style="margin: 2em;"]//input[@name="j_username"]'
eles = driver.find_element_by_xpath(ls)print(eles.get_attribute("name"))# 返回值:
j_username
xpath:3、相对定位中文本text()函数定位:baidu页面 当如果父类下的所有元素一样,仅仅文本不一样的时候,使用text()函数;
当如果父类下的所有元素一样,仅仅文本不一样的时候,使用text()函数;
//*[@id="s-top-left"]//a[text()="视频"]
读取
xpath:4、相对定位部分contains()定位函数:baidu页面
contains(@属性/text(),value):包含部分定位函数
例如:contains(@class,“XXXX”)、contains(text(),“XXXX”)
1.
//span[contains(@class,"quickdelete-wrap")]
逻辑运算:
and 表示条件 与
or 表示条件 或
2.
//span[contains(@class,"quickdelete-wrap") and contains(@class,"s_ipt_wr")]
//div[@class="XXXX" and contains(@style,"display:visibility")]
xpath:5、轴定位:jenkins登录页面
ancestor:祖先节点
parent:父节点
preceding-sibling:当前元素节点标签之前的所有兄弟节点
following-sibling:当前元素节点标签之后的所有兄弟节点
使用语法:
/轴名称::节点名称
例如1:
//input[contains(@id,"j_username")]/ancestor::tbody//input[@type="password"]
 祖先定位:
祖先定位:
//input[contains(@id,"j_username")]/ancestor::tbody//input[@type="password"]
其中
/ancestor::tbody
是指回到祖先节点tbody
例如2:祖先兄弟后定位:
//input[contains(@id,"j_username")]/ancestor::tr/following-sibling::tr//input

三、等待
# 时间等待方式# 第一种:固定延迟 5simport time
time.sleep(5)# 第二种:隐形等待 如果等到了进程马上运行,如没有等到,5秒后报错# 启动Chrome驱动from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动Chrome驱动
driver = webdriver.Chrome()
driver.implicitly_wait(30)# 在启动后到启动结束所有进程都保持30S处理时间。# 打开一个网页
driver.get('https://www.baidu.com/')# 点击登录
driver.find_element(By.XPATH,'//div[@id="u1"]//a[@name="tj_login"]').click()# 点击短信登录
driver.find_element(By.ID,"TANGRAM__PSP_11__changeSmsCodeItem").click()# 第三种:显形等待# 明确等待某个条件的满足之后,再去执行下一步的操作。# 程序每隔XX秒看一眼,如果条件成立了,则执行下一步,否则继续等待,直到超过设置最长时间,然后抛出TimeoutException。# 使用之前,引入相关的库from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By # 八种定位方式# WebDriverWait类:显性等待类# WebDriverWait(driver,等待时常,轮询周期).until()条件/until_not()直到条件不成立# expected_conditions模块:提供了一系列期望发生的条件。# driver.find_element(By.ID, 'TANGRAM__PSP_28__changePwdCodeItem')# 启动Chrome驱动
driver = webdriver.Chrome()# driver.implicitly_wait(30)# 打开一个网页
driver.get('https://www.baidu.com/')# 点击登录
driver.find_element(By.XPATH,'//div[@id="u1"]//a[@name="tj_login"]').click()# 以下是显性等待使用方法:# 1、先确认元素的定位表达式
s_id ='TANGRAM__PSP_11__regLink'# ID定位立即注册按钮# 2、设置显性等待 WebDriverWait(driver,等待时常:10S,轮询周期:默认值0.5S).until()/until_not():条件成立/直到条件不成立
WebDriverWait(driver,10).until(EC.presence_of_element_located((By.ID, s_id)))# 条件 (元素定位为的类型,元素定位的表达式)# 3、使用后续的方法 比如:点击
driver.find_element(By.ID,'TANGRAM__PSP_11__regLink').click()
附:常用的 expected_conditions 模块下的条件:
# EC.presence_of_element_located():元素存在# EC.visibility_of_element_located():元素可见# EC.element_to_be_clickable():元素可点击# EC.new_window_is_opened() # 新窗口是否打开# EC.frame_to_be_available_and_switch_to_it() # 可用并且切换进去# EC.alert_is_present() # 弹出框的出现# EC.element_selection_state_to_be() # 下拉列表状态# EC.element_to_be_selected() # 某一个定位表达式的值应该是被选中的# EC.element_selection_state_to_be() # 定位表达式的选中状态是什么# EC.element_to_be_selected() # 元素可用被选中的# EC.invisibility_of_element() # 隐形的元素# EC.number_of_windows_to_be() # 窗口的个数应该为# # EC.presence_of_all_elements_located() # 所有元素应该都存在# EC.text_to_be_present_in_element() # 元素出现的文本内容# EC.text_to_be_present_in_element_value() # 元素出现的文本内容值# EC.url_changes() # url的改变# EC.url_contains() # url的包含# EC.url_matches() # url的匹配# EC.url_to_be() # url的应该是什么
四、切换一,iframe
1.先切换iframe元素再定位到对应html页面下元素。
# 切换 iframe=进入另外一个html页面。 一个页面可能存在多个html (原则上一个iframe下存在对应一个Html页面).# 如果页面定位不好到下一个html页面中的元素,可以先切换到ifranme对应的html页面再然后去定位这个html页面下的元素。# 下面总体的三种方法就代表:先进入另外一个html页面。# iframe 定位三种方法,第一种是定位iframe的name属性
driver.switch_to.frame('name')# 第二种是 iframe 里面根据下标,根据html页面的iframe的个数 从1开始
driver.switch_to.frame(3)# 第三种是 iframe 里面属性根据属性名称来取值,iframe从0开始取值
driver.switch_to.frame(driver.find_elements(By.TAG_NAME,"iframe")[0])# 不管哪种方法接下来都是等待0.5S,加载定位完成到html页面后,再根据定位方法定位到对应元素上。
time.sleep(0.5)# 等待一下
driver.find_element(By.XPATH,"//iframe[@id='qrlogin_img']")
例:
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By # 八种定位方式import time
# 启动驱动,点击登录
driver = webdriver.Chrome()
driver.get('https://ke.qq.com/')
driver.find_element(By.XPATH,'//a[@id="js_login"]').click()# 点击登录,登录后自动跳转到微信扫码页面的html。思路:先跳转到iframe,再点击账号密码登录# 切换里面其中另一个html页面,iframe 在第三个位置 //iframe[@scrolling="no" and @width="368px"]# WebDriverWait(driver, 10).until(EC.frame_to_be_available_and_switch_to_it('iframe')[2])# 通过第三种方法,iframe的取值从0开始取值。
driver.switch_to.frame(driver.find_elements(By.TAG_NAME,"iframe")[2])
time.sleep(0.5)
driver.find_element(By.XPATH,"//a[@id='switcher_plogin' and text()='帐号密码登录']").click()
2.iframe切换
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By # 八种定位方式import time
# 这种frame_to_be_available_and_switch_to_it方法利用iframe一定存在,采用的方法,后面参数与切换1一致,但是对于切换中的第三种取值方法不适应,这点要注意。
WebDriverWait(driver,10).until(EC.frame_to_be_available_and_switch_to_it('name'))
time.sleep(0.5)# 等待一下
driver.find_element(By.XPATH,"//iframe[@id='qrlogin_img']")
3.回到
# 从iframe回到主页面的html。
driver.switch_to.default_content()# 从iframe回到上一级的html页面,即是一个html页面回到上级html页面。
driver.switch_to.parent_frame()
切换二 窗口切换(句柄切换)
1、
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By # 八种定位方式import time
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches",["enable-automation"])
driver = webdriver.Chrome(options=options)
driver.get('https://www.baidu.com/')
driver.find_element(By.ID,'kw').send_keys('柠檬班')
driver.find_element(By.ID,'su').click()
WebDriverWait(driver,20).until(EC.visibility_of_element_located((By.XPATH,'//a[contains(text(),"吧 - 百度贴吧")]')))
driver.find_element(By.XPATH,'//a[contains(text(),"吧 - 百度贴吧")]').click()
time.sleep(0.5)# 窗口切换# step1: 获取窗口的总数以及句柄 (新打开的窗口,位于最后一个。)
handles = driver.window_handles # 打印所有句柄 driver.current_window_handle # 打印当前句柄print(handles)# ['CDwindow-302305DC0B30AA06F25F38445E5F9C81', 'CDwindow-AC6C8AB9635F7F6B54C1A606E888511B']# 获取当前窗口的句柄# print(driver.current_window_handle)# 切换浏览器的页面
driver.switch_to.window(handles[-1])
WebDriverWait(driver,20).until(EC.visibility_of_element_located((By.ID,'j_head_focus_btn')))
driver.find_element(By.ID,'j_head_focus_btn').click()---------------------------------------------------------------------------------------------# 或者可以将弹出来的页面先关闭,再进行窗口切换
handles = driver.window_handles # 打印所有句柄# ['CDwindow-302305DC0B30AA06F25F38445E5F9C81', 'CDwindow-AC6C8AB9635F7F6B54C1A606E888511B']classwindow_h(self):defclose(self):
windows = self.driver.window_handles
iflen(windows)>1:
self.driver.switch_to.window(windows[1-len(windows)])
self.driver.close()
self.driver.switch_to.window(windows[0])else:
self.driver.close()defparent(self):
handle = self.driver.window_handles[1]
self.driver.switch_to.window(handle)if __name__ =='__main__':
window_h().close()
window_h().parent()
2、
from selenium import webdriver
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By # 八种定位方式import time
# 使用后打开浏览器不显示自动化测试工具的title
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches",["enable-automation"])
driver = webdriver.Chrome(options=options)
driver.get('https://www.baidu.com/')
driver.maximize_window()
driver.find_element(By.ID,'kw').send_keys('柠檬班')
driver.find_element(By.ID,'su').click()# 搜索到满足表达式的条件后继续下一步,否者报错
WebDriverWait(driver,20).until(EC.visibility_of_element_located((By.XPATH,'//a[contains(text(),"吧 - 百度贴吧")]')))# step1: 现在获取窗口的总数是1
handles = driver.window_handles # 获取的句柄总数为1,也即是窗口数# step2: 获取窗口的总数变成2.因为下面有点击操作
driver.find_element(By.XPATH,'//a[contains(text(),"吧 - 百度贴吧")]').click()# step3:等待新的窗口出现,满足条件,现在获取的总数:handles窗口的总数<后面新开的句柄窗口数,利用 new_window_is_opened 方法判断
WebDriverWait(driver,10).until(EC.new_window_is_opened(handles))# step4:满足step3条件后切换新的窗口操作,需要重新获取窗口
handle = driver.window_handles[-1]# 获取最新的窗口,即最后打开的窗口
driver.switch_to.window(handle)print(handle)
time.sleep(0.5)
WebDriverWait(driver,20).until(EC.visibility_of_element_located((By.ID,'j_head_focus_btn')))
driver.find_element(By.ID,'j_head_focus_btn').click()
切换三 alert切换(弹出框处理)
确定:弹出框说到底不是html页面元素
1、在pychrm中新建一个html文件。 写入以下代码,然后利用浏览器打开这个html文件,那么就会出现弹出框提示:everything is ready!!
<title>python-20211229</title>
<script>
window.onload = function(){alert("everything is ready!!")}
</script>
如图: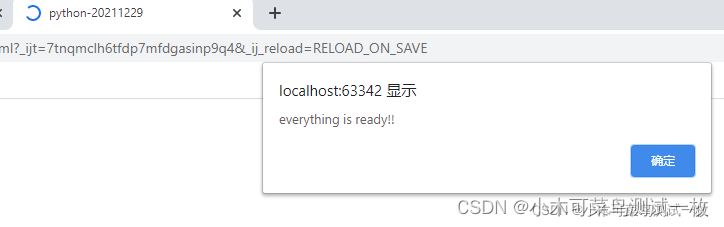
2.代码集成处理:
import os
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.firefox.service import Service as Services
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By # 八种定位方式from common.config_reader import ConfigReader
import time
classBaseMethod():def__init__(self):
self.driver =None
self.driver_file_path = ConfigReader().get_value('file','runstatus_file_path')defoper_url(self, url):# 两种方式打开浏览器if"chromedriver"in self.driver_file_path:# 如果是谷歌驱动执行以下程序
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches",["enable-automation"])
driver_obj = Service(self.driver_file_path)
self.driver = webdriver.Chrome(service=driver_obj, options=options)elif"geckodriver"in self.driver_file_path:# 如果是火狐驱动执行以下程序
driver_obj = Services(self.driver_file_path)
self.driver = webdriver.Firefox(service=driver_obj)
self.driver.get(url)
self.driver.maximize_window()
self.oper_baidu()
self.driver_alert()defoper_baidu(self):
self.driver.find_element(By.ID,'kw').send_keys('柠檬班')
self.driver.find_element(By.ID,'su').click()# 搜索到满足表达式的条件后继续下一步,否者报错
WebDriverWait(self.driver,20).until(EC.visibility_of_element_located((By.XPATH,'//a[contains(text(),"吧 - 百度贴吧")]')))# step1: 现在获取窗口的总数是1
handles = self.driver.window_handles # 获取的句柄总数为1,也即是窗口数# step2: 获取窗口的总数变成2.因为下面有点击操作
self.driver.find_element(By.XPATH,'//a[contains(text(),"吧 - 百度贴吧")]').click()# step3:等待新的窗口出现,满足条件,现在获取的总数:handles窗口的总数<后面新开的句柄窗口数,利用 new_window_is_opened 方法判断
WebDriverWait(self.driver,10).until(EC.new_window_is_opened(handles))# step4:满足step3条件后切换新的窗口操作,需要重新获取窗口
handle = self.driver.window_handles[-1]
self.driver.switch_to.window(handle)print(handle)
time.sleep(0.5)
WebDriverWait(self.driver,20).until(EC.visibility_of_element_located((By.ID,'j_head_focus_btn')))
self.driver.find_element(By.ID,'j_head_focus_btn').click()defdriver_alert(self):# 可以不要self ,把所有的 self 去掉,但是 self.driver_file_path
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches",["enable-automation"])
driver_obj = Service(self.driver_file_path)# 驱动存在的路径可以改成绝对路径
self.driver = webdriver.Chrome(service=driver_obj, options=options)
self.driver.maximize_window()
self.driver.get(os.getcwd()+r"\7788.html")# 文件路径和我们是同一级 不是的话可以放绝对路径
WebDriverWait(self.driver,10).until(EC.alert_is_present())# 判断alert弹出框是否出现为条件,等待alert出现# 首先对弹框进行处理时候,先要要去访问一个有弹出框的网页 dismiss 拒绝;取消,accept 确定 ,send_keys 输入
alert = self.driver.switch_to.alert # 获取弹框对象print(alert.text)# 打印弹框内容# 关闭弹出框
alert.accept()# 点击确定# alert.dismiss() # 取消if __name__ =='__main__':
BaseMethod().driver_alert()
或者代码直接处理:建议直接拿这个调试玩一玩
import os
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
defdriver_alert():
driver_file_path ='..\data\chromedriver.exe'
options = webdriver.ChromeOptions()
options.add_experimental_option("excludeSwitches",["enable-automation"])
driver_obj = Service(driver_file_path)
driver = webdriver.Chrome(service=driver_obj, options=options)
driver.maximize_window()
driver.get(os.getcwd()+r"\7788.html")# 文件路径和我们是同一级 不是的话可以放绝对路径
WebDriverWait(driver,10).until(EC.alert_is_present())# 判断alert弹出框是否出现为条件,等待alert出现# 首先对弹框进行处理时候,先要要去访问一个有弹出框的网页 dismiss 拒绝;取消,accept 确定 ,send_keys 输入
alert = driver.switch_to.alert # 获取弹框对象print(alert.text)# 打印弹框内容# 关闭弹出框操作 取消 OR 确定
alert.accept()# 点击确定# alert.dismiss() # 取消if __name__ =='__main__':
driver_alert()
五、webdriver中常用的操作元素的方法:
clear():清除对象的内容
driver.find_element_by_id(‘kw’).clear()
send_keys():在对象上模拟按键输入
driver.find_element(By.ID,‘kw’).send_keys(“12306”)
click():单击对象,强调对象的独立性
driver.find_element(By.ID,‘su’).click()
submit():提交表单,要求对象必须是表单
driver.find_element(By.ID,‘form’).submit()
size:返回对象的尺寸
driver.find_element_by_css_selector("#J_username").size
text:获取对象的文本
driver.find_element_by_css_selector(“a.sendpwd”).text
get_attribute(“属性名”):获取对象的属性值
driver.find_element_by_css_selector("#J_username").get_attribute(“name”)
is_displayed():用来判断对象是否可见,即css的display属性是否为none
driver.find_element_by_css_selector("#J_username").is_displayed()
is_enabled():判断对象是否被禁用
driver.find_element_by_css_selector("#J_username").is_enabled()
is_selected():判断对象是否被选中
driver.find_element_by_id(“head_checkbox”).is_selected()
tag_name:获取对象标签名称
driver.find_element_by_id(“head_checkbox”).tag_name
location:获取元素坐标
driver.find_element_by_id(“head_checkbox”).location
最后利用JavaScript操作web页面的元素

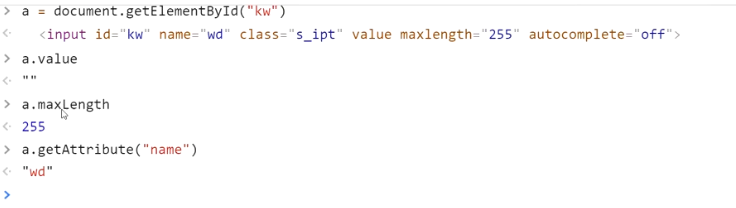
改变属性的value
版权归原作者 小木可菜鸟测试一枚 所有, 如有侵权,请联系我们删除。