
1、用户参数(User Variables)
- 适用范围:适用于参数取值范围很小,需要少量测试数据时使用。
- 设置步骤
(1)在需要设置参数的请求下添加用户参数:选中“取样器”右键-->添加-->前置处理器-->用户参数;
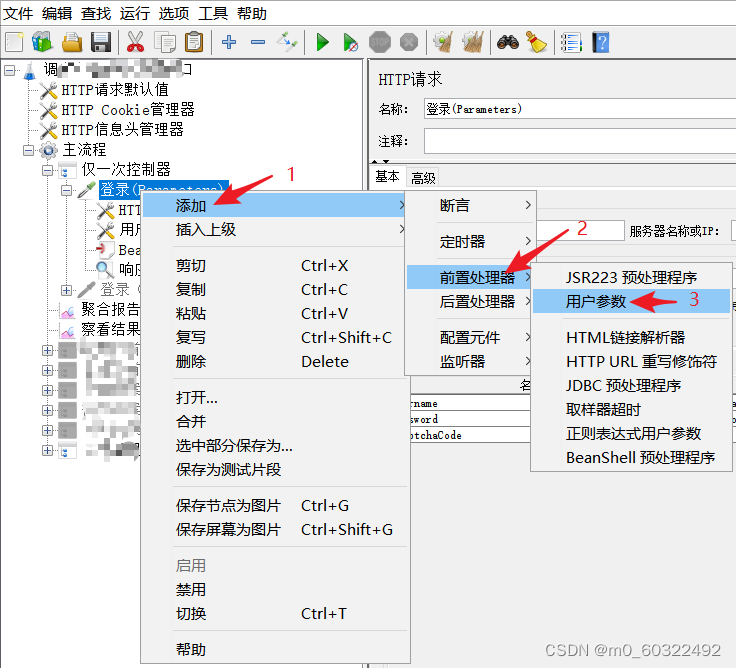
图 1 用户参数--元件位置
(2)点击“添加变量”,在添加的变量行中输入你需要添加的变量名称和变量值;(可添加多个变量)
(3)点击“添加用户”,可以为同一个变量添加多个用户;(一个变量对应多个变量值)
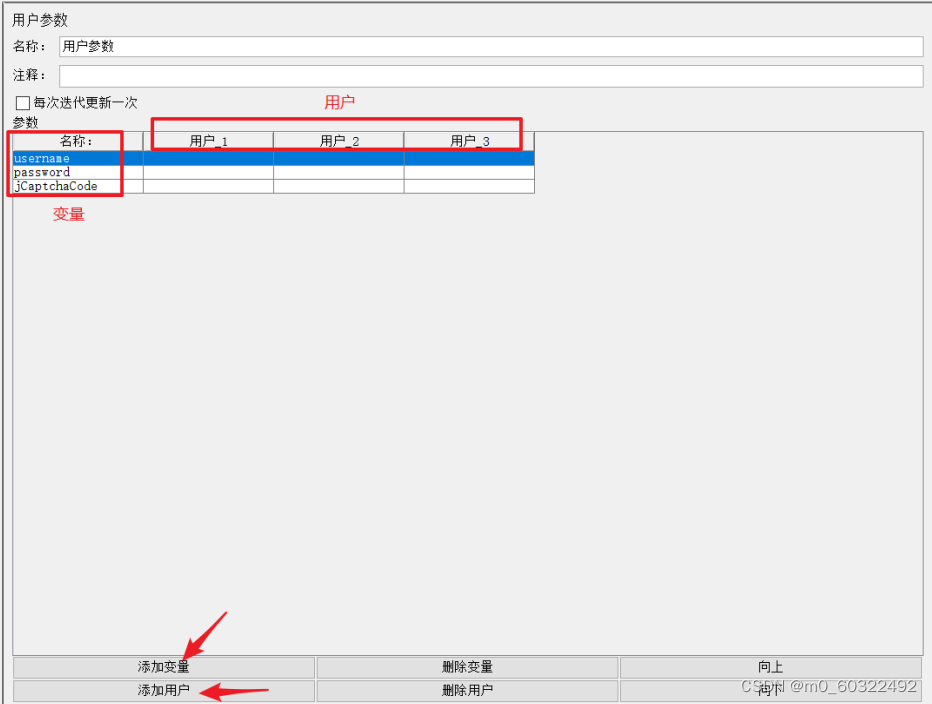
图 2 用户参数--相关参数
- 引用方式:在需要参数化的请求上,引用参数化变量:${变量名}。
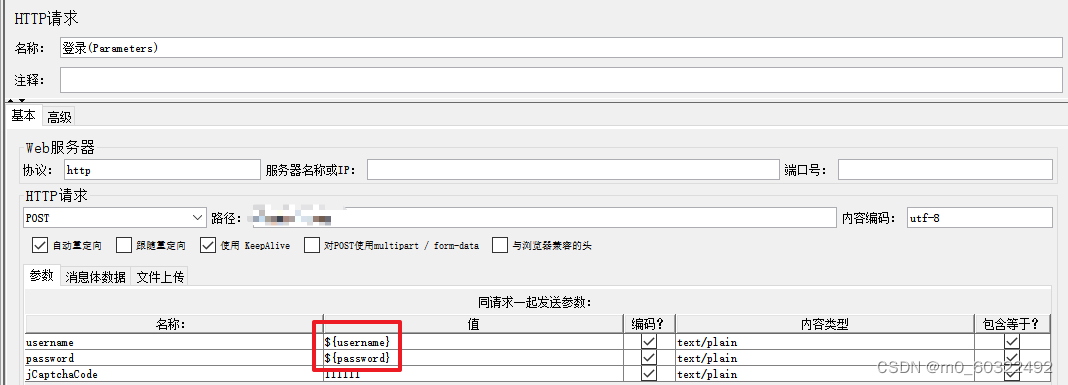
图 3 用户参数--引用方式
- 注意事项
(1)勾选每次迭代更新一次选项,无论是多线程还是多循环,每次运行同一个线程组或者单次循环中每次引用并调取用户参数时不会更新(使用的是第一次引用调取的用户参数值),不同的线程组或者不同循环中会更新一次。
(2)不勾选每次迭代更新一次选项,无论是多线程还是多循环,每个线程组或者每次循环中每次引用并调取用户参数时都会更新一次
2、用户定义的变量(User Defined Variables)
- 适用范围:适用于不需要随迭代发生改变的参数(只取一次的参数),更多用于设置全局变量,常用于数据库地址,测试环境、开发环境地址等常量配置。
- 设置步骤
(1)在需要设置参数的请求下添加用户定义的变量:选中“取样器”右键-->添加-->配置元件-->用户定义的变量;
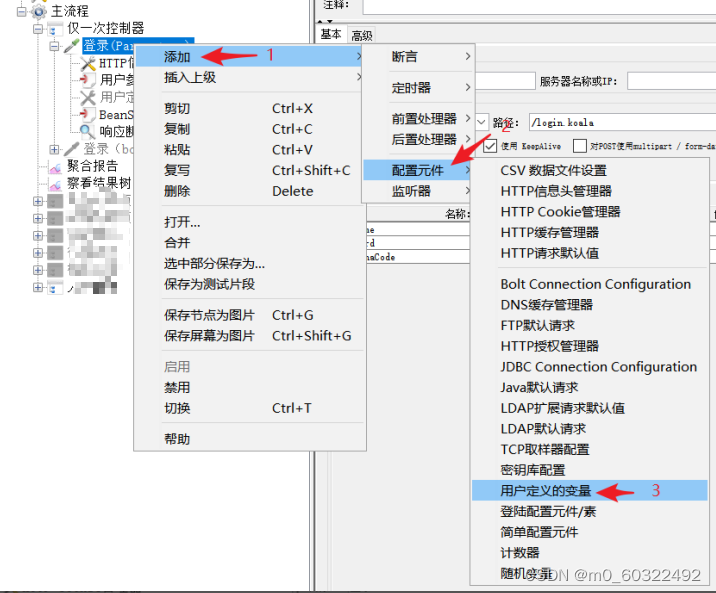
图 4 用户定义的变量--元件位置
(2)通过界面下方的【添加】、【删除】按钮可以向参数列表增加和删除参数,【向上】和【向下】按钮可以上下移动参数的位置。
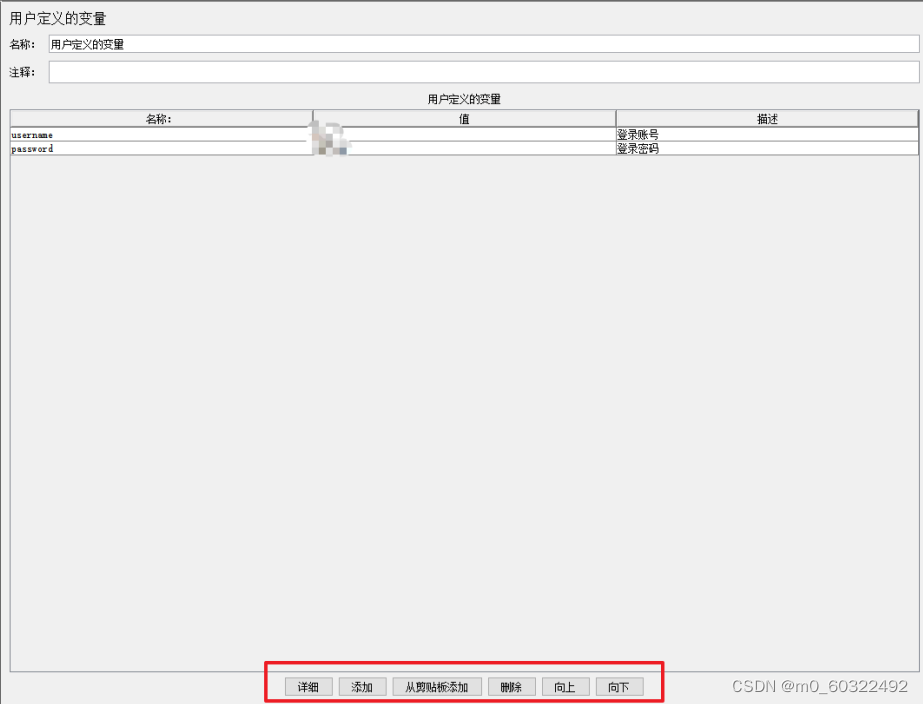
图 5 用户定义的变量--相关参数
- 引用方式:在需要参数化的请求上,引用参数化变量:${变量名}。(与用户变量相同)
- 注意事项
(1)配置元件中的用户定义的变量:无论是多线程还是多循环,每个线程组引用时都使用的是同一个变量值(第一次引用时的用户变量值);
(2)配置元件在jmeter中的执行优先级最高,高于前置处理器。若用户参数和用户自定义变量重名,则优先取用户参数组件中的值。因为配置元件执行完再到前置处理器,所以前置处理器的值会覆盖配置元件中设置的值。
3、CSV 数据文件设置(CSV Data Set Config)
- 适用范围:这种方式是通常所指的参数化。数据存储在文件中,该种参数化方式取值范围大,灵活性强,适用于大量测试数据时的使用。
- 设置步骤
(1)在需要设置参数的请求下:选中“取样器”右键-->添加-->配置元件-->CSV 数据文件设置;
图 6 CSV 数据文件设置--元件位置
(2)参数说明
- 文件名:文件的完整路径,包括文件名和类型;(.csv 文件和.txt 文件)
- 文件编码:填写gb2312;(好像不写也可以,写了utf-8可能会出现中文乱码)
- 变量名称(西文逗号间隔):储存参数的变量名,如果在文件中有写变量名就不需要写了,在这里写的话需要将每个变量名用“,”隔开;
- 忽略首行(只在设置了变量名称后才生效):文件中第一行为变量名称时,设置为True后可忽略首行;
- 分隔符(用’\t'代替制表符):分隔多个参数的分隔符
- 是否允许带引号?:是否有引用数据,ps:如果参数中有逗号或双引号,要选为“true”
- 遇到文件结束符再次循环?:文件读取完后是否继续读取;(设置为True后,允许循环取值)
- 遇到文件结束符停止线程?:文件读取完后是否停止线程;(当“遇到文件结束符再次循环”为false并且“遇到文件结束符停止线程”为true,则读完文件中的记录后,停止运行,线程数及执行次数无效)
- 线程共享模式:“所有线程”,所有线程循环取值,线程1取第一行,线程二取下一行;“当前线程组”,各个线程组分别循环取值;“当前线程”,该测试计划内的所有线程都取第一行。
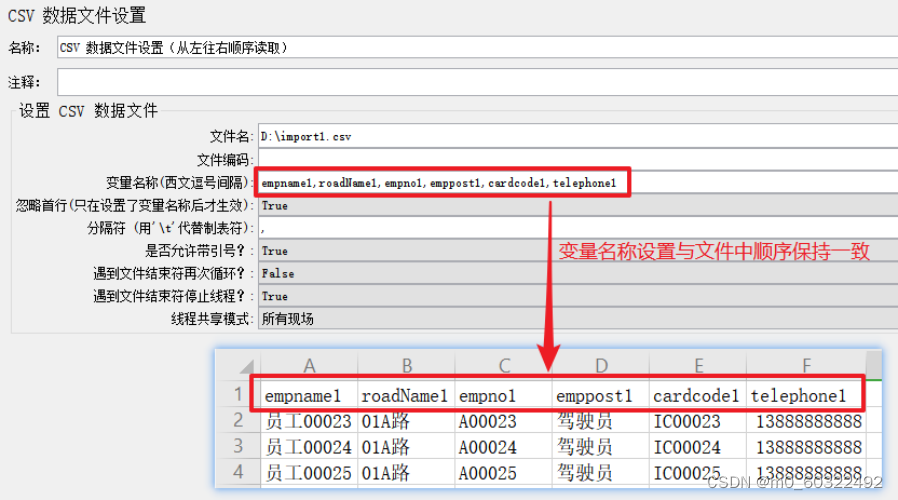
图 7 CSV 数据文件设置--按从左到右的顺序读取参数
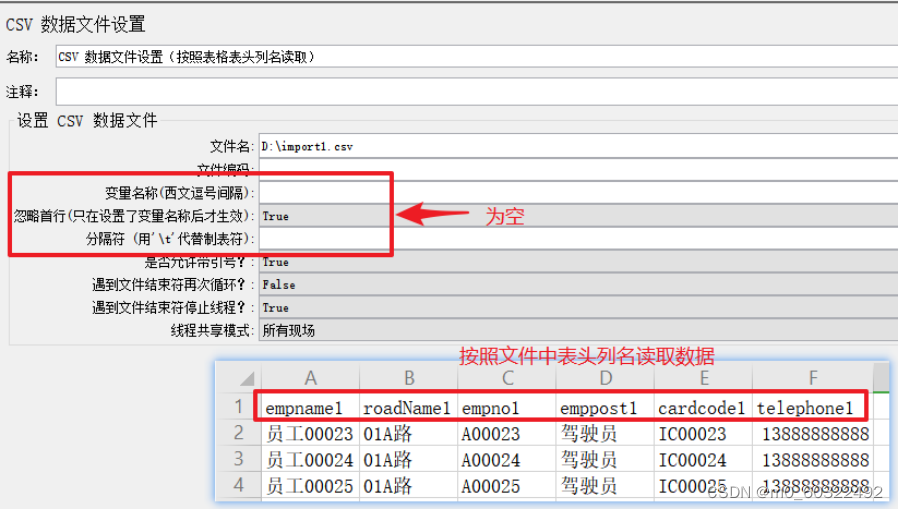
图 8 CSV 数据文件设置--按表头列名读取参数
- 引用方式:在需要参数化的请求上,引用参数化变量:${变量名}。

图 9 CSV 数据文件设置--引用参数
- 依次读取文件参数
(1)设置线程组的线程数或循环次数,文件中有多少个参数就设置多少次;
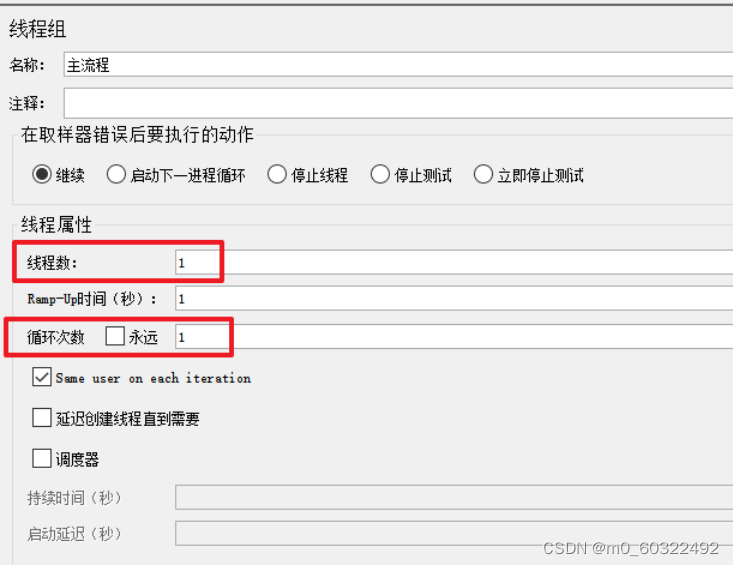
图 10 CSV 数据文件设置--依次读取文件参数--线程组线程数或循环次数
(2)使用循环控制器,把“CSV数据文件设置”设置到脚本的“循环控制器”下一级,在循环控制器中设置循环次数。
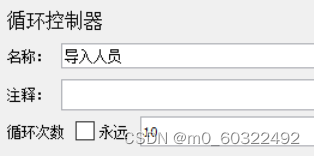
图 11 CSV 数据文件设置--依次读取文件参数--循环控制器
- 注意事项
(1)填写文件地址时,注意使用反斜杠“\”,盘符后冒号使用英文格式;
(2)参数文件使用.csv格式时,先在excel中填写,写完后另存为.csv格式,直接新建文件更改文件后缀为.csv会报错;
(3)变量名可选择写在文件中第一行,或在CSV数据文件设置中写;(变量名不要用中文)
4、借用函数生成参数(以CSVRead函数为例)
- 适用范围:有时候数据不适合被指定,可使用函数生成随机数字和随机字符串实现参数化。
- 设置步骤
(1)点击函数助手对话框,弹出函数助手页面;
(2)在函数选择框中选择函数CSVRead;
(3)填写csv文件的完整路径(包括文件名和类型),填写文件列号(从0开始);
(4)点击【生成】按钮,下方可查看参数取值内容。
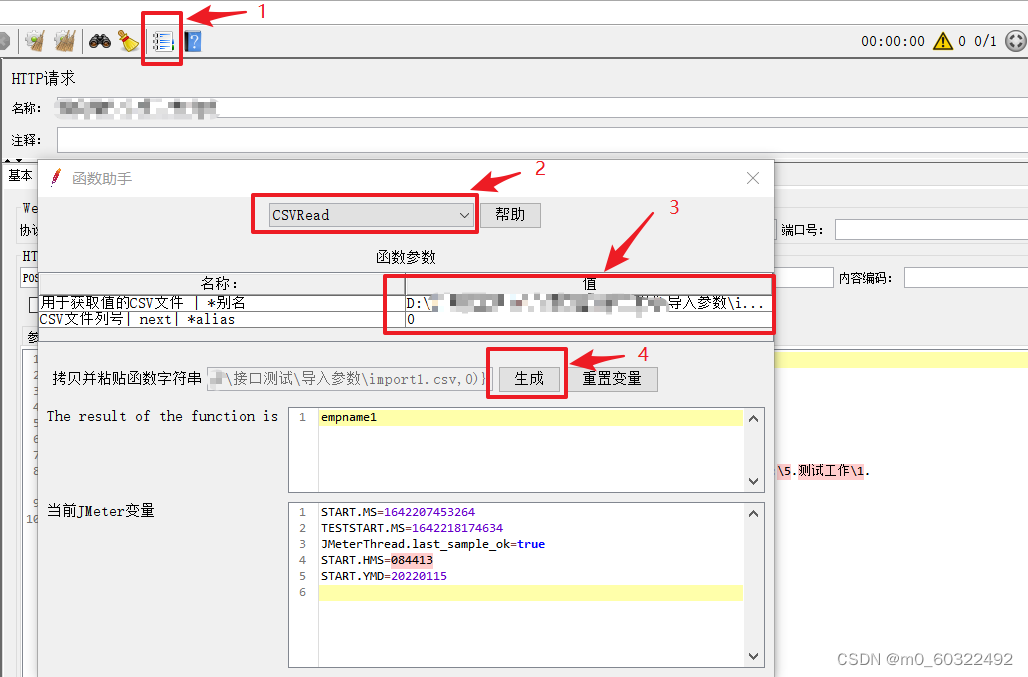
图 12 借助函数生成参数--设置步骤
- 引用方式:拷贝并粘贴函数字符串,去替换要参数化的值。

图 13 借助函数生成参数--引用方式
- 依次读取文件参数
(1)设置线程组的线程数或循环次数,文件中有多少个参数就设置多少次;
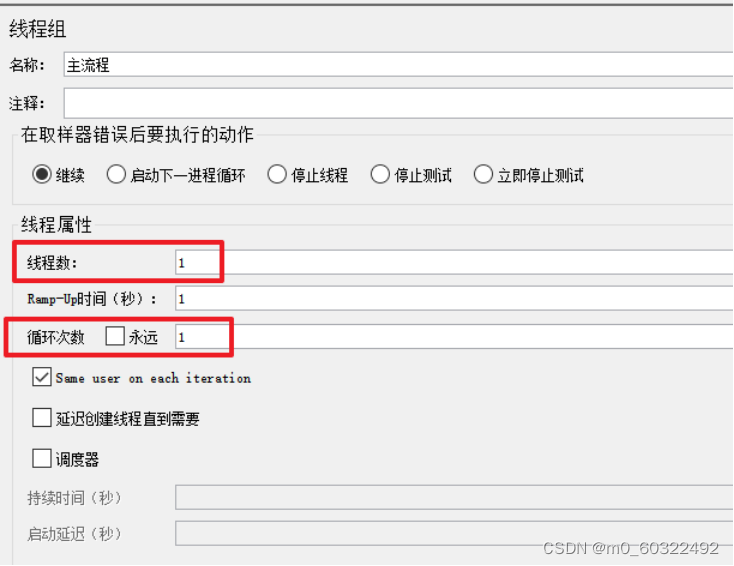
图 14 借助函数生成参数--依次读取文件参数--线程组线程数或循环次数
(2)使用循环控制器,把“CSV数据文件设置”设置到脚本的“循环控制器”下一级,在循环控制器中设置循环次数。
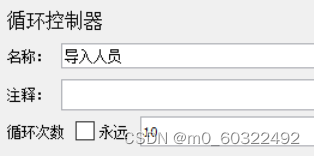
图 15 借助函数生成参数--依次读取文件参数--循环控制器
- 注意事项
(1)函数CSVRead读取文件不可忽略首行,csv文件中第一行直接为变量值;
(2)循环控制器不能自动换行取值,在循环控制器下使用函数CSVRead要实现换行取值需要在响应断言里添加${__CSVRead(文件目录,next)}

图 16 借助函数生成参数--循环控制器换行取值
5、正则表达式提取器
- 适用范围:适用于获取上一个接口的返回值传给下一个接口,达到传参的目的。
- 设置步骤
(1)在需要被提取响应数据的请求下添加正则表达式提取器:选中请求右击-->添加-->后置处理器-->正则表达式提取器;

图 17 正则表达式提取器--元件位置
(2)参数说明
- a****pply to:应用范围,四个选项
- main sample and sub-samples:匹配范围包括当前取样器并覆盖至子取样器;
- main sample only:匹配范围是当前父取样器;
- sub-samples only:仅匹配子取样器;
- jmeter variable:支持对jmeter变量值进行匹配;
- 引用名称:匹配出来的信息通过该名称访问,例如****${引用名称}****;
- 正则表达式:在响应数据中把要提取的目标值左右若干字符包含目标值的一行拷贝出来,粘贴到正则表达式框内,再把目标值用一对小括号替换,括号里用添上合适的匹配符,如*(.);
- 模板:****$1$,代表匹配的第一个值,$2$****,代表匹配的第二个值,以此类推;
- 匹配数字:0即随机取值;-1即取所有值;1、2、3即取对应的第几个值(例如:如果该正则匹配出来了多个值,多个rulesid,但是我们只想用第二个rulesid,这个地方的匹配数字就写成2,下面的接口就会只使用第二个rulesid)
- 缺省值:如果没有匹配到可以指定一个默认值

图 18 正则表达式提取器--相关参数
- 引用方式
(1)如果正则表达式只获取一个值,那么就可使用${引用名称}的方式使用;
(2)如果正则表达式获取多个值,那么在线程组中添加调试取样器,然后发送请求,在调试取样器中查看正则表达式提取器匹配的结果,引用名称_X(其中,X为对应值的排序序号)即为匹配的值,需要引用哪个,就用${引用名称_X}的方式使用。
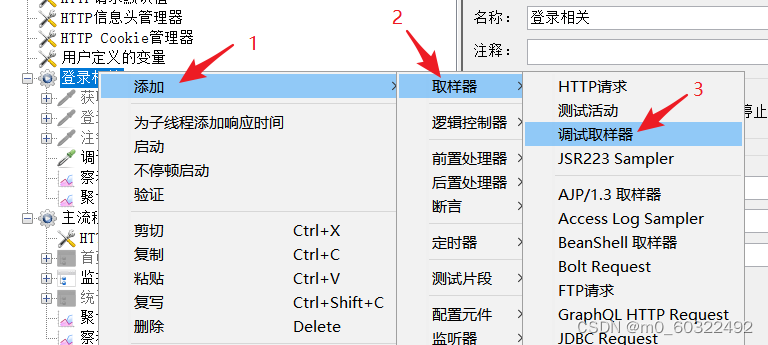
图 19正则表达式提取器--引用参数--调试取样器(1)
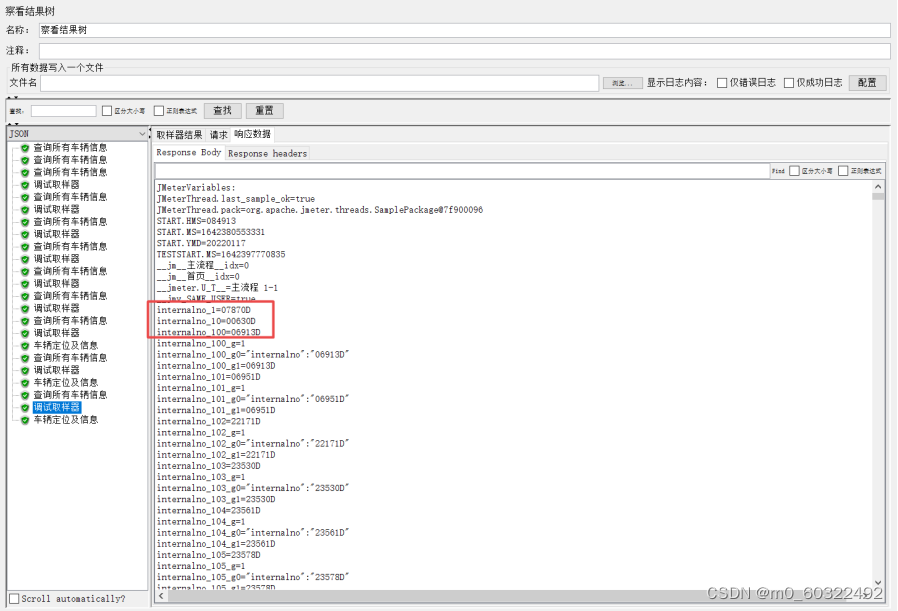
图 20 正则表达式提取器--引用参数--调试取样器(2)
(3)如果正则表达式获取多个值,可使用For Each控制器遍历所有数据;
- 正则表达式提取器中匹配数字写-1;
- 已设置调试取样器;(调试取样器中即可观察到多个取值结果)
- 在线程中添加For Each控制器,配置For Each控制器;
- 输入变量前缀:正则表达式提取器的引用名称,假设为msg;
- 开始循环字段:调试取样器中第一次出现msg_x,x代表开始循环字段
- 结束循环字段:调试取样器中第二次出现msg_x,x代表结束循环字段
- 输出变量名称:每次循环得到的值,后续请求通过${XXX}引用
- 数字之前加下划线"_":勾选,输入变量前缀+循环字段,通过msg_x来获得每次循环的值
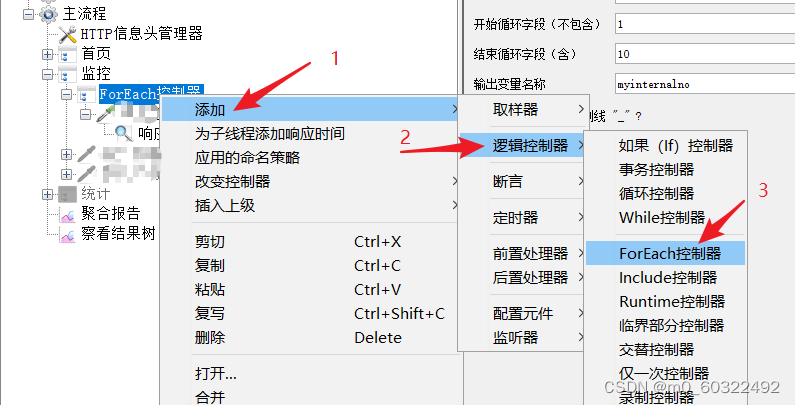
图 21 正则表达式提取器--引用参数--ForEach控制器(1)

图 22 正则表达式提取器--引用参数--ForEach控制器(2)
- 在该控制下在添加HTTP请求,引用ForEach控制器每次循环得到的值${XXX};
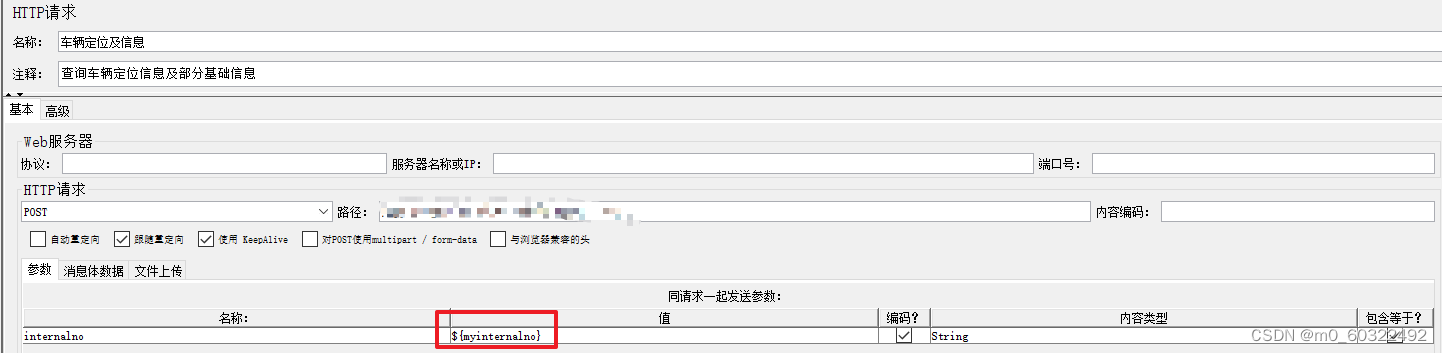
图 23 正则表达式提取器--引用参数--ForEach控制器(3)
- 发送请求,在查看结果树中,查看每次循环请求的参数,与调试取样器中对应序号取值一致。
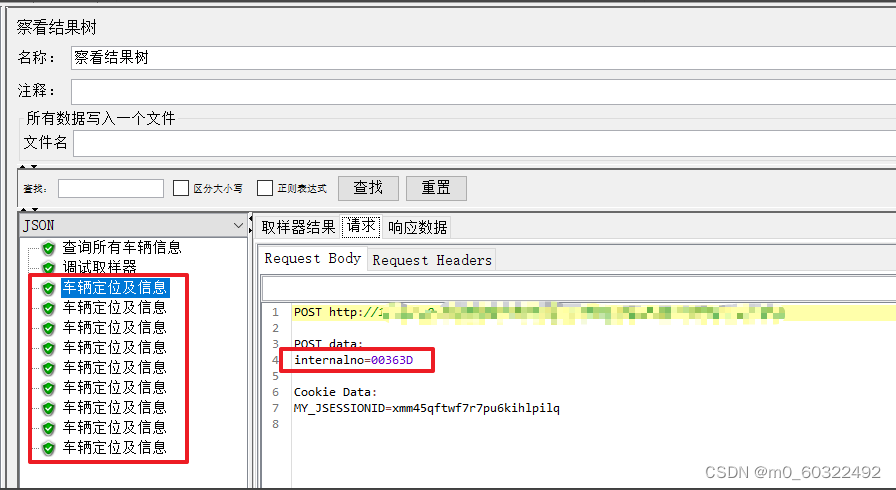
图 24 正则表达式提取器--引用参数--ForEach控制器(4)
- 注意事项
(1)正则表达式可同时取多个值,中间用英文逗号隔开,例如:{“status”:1,“code”:"(.)",“msg”:"(.)"};
(2)如果一个正则表达式需要提取多个值,那么模板以$1$ $2$…$n$将匹配的值进行提取。
(3)正则表达式匹配符
元字符
意义
限定符
意义
.
任意单个字符
匹配至少大于1次
/d
任意单个数字
?
匹配0次或1次
[0-9]
等价0-9
匹配0次或多次
[a-zA-Z]
等价所有的大小写字母
{n,}、{n,m}、{n}
匹配限定次数
使用元字符+限定符进行匹配,匹配数字123456:.*、\d*、\d{6}、[0-9]{6}。(可搜索使用网上的正则表达式测试工具验证是否获取正确的值)
正则表达式在线测试 | 菜鸟工具
常用匹配符:
- (.+?)提取1个字符串及以上,不要太贪婪,在找到第一个匹配项后停止;
- (.*?)提取0个字符串及以上,要取的值是空值的时候可以取得到。
5、Json提取器
- 适用范围:使用JSON-PATH语法从JSON格式的响应中提取数据。
- 设置步骤
(1)在需要被提取响应数据的请求下添加Json提取器:选中请求右击-->添加-->后置处理器-->Json提取器;
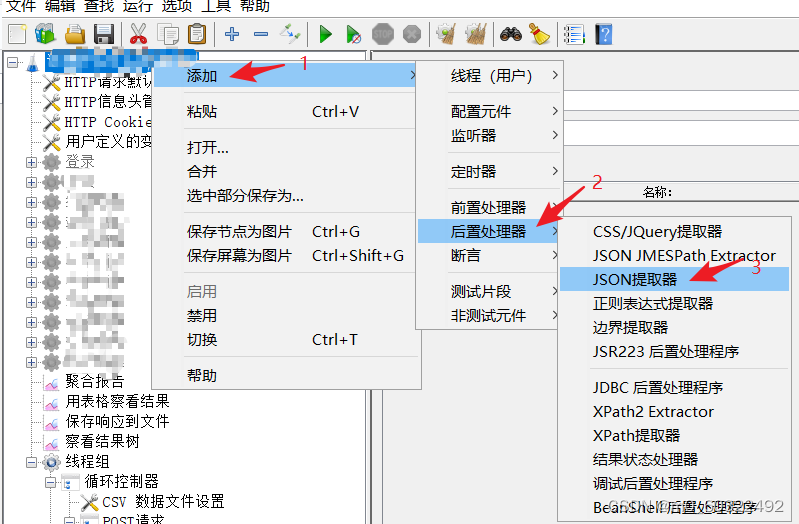
图 25 Json提取器--元件位置
(2)参数说明
- a****pply to:应用范围,四个选项
- main sample and sub-samples:匹配范围包括当前取样器并覆盖至子取样器;
- main sample only:匹配范围是当前父取样器;
- sub-samples only:仅匹配子取样器;
- jmeter variable:支持对jmeter变量值进行匹配;
- Names of created variables****(保存的变量名): 以 ; 分隔的变量名称(需要匹配JSON Path的数量)
- JSON Path Expressions(JSON Path表达式****) :以 ; 分隔的JSON Path表达式(必须匹配变量数量)
- ****Match No. (0 for Random) ****(匹配数字):如果JSON Path提取到多个结果,则可以设置选择提取哪个结果作为变量,其中,0即随机取值;-1即取所有值;X即取对应的第X个值(如果此X大于匹配数量,则不返回任何内容,将使用默认值);
- Compute concatenation var (是否统计所有):如果找到许多结果,将使用’,'分隔符将它们连接起来,并将其存储在名为 _ALL的中;
- Default Values****(默认值) :以 ; 分隔的默认值,若表达式没有匹配结果,则使用默认值
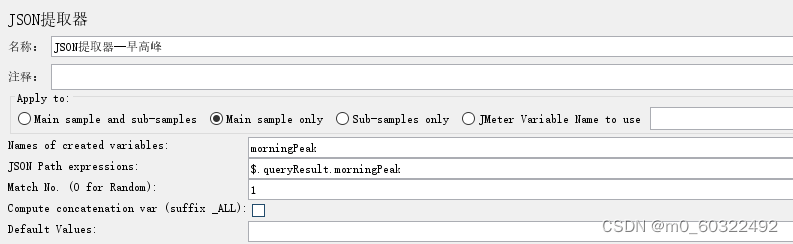
图 26 Json提取器--提取单个变量
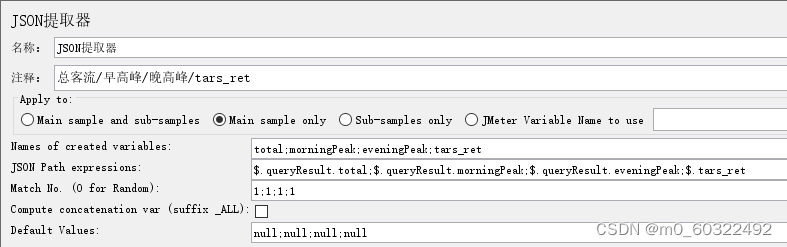
图 27 Json提取器--提取多个变量
- 引用方式:在需要参数化的请求上,引用参数化变量:${变量名}。
- 注意事项
(1)在查看结果树中选择JSON Path Tester,输入表达式即可拿来测试书写的Json提取器表达式是否能正常工作;
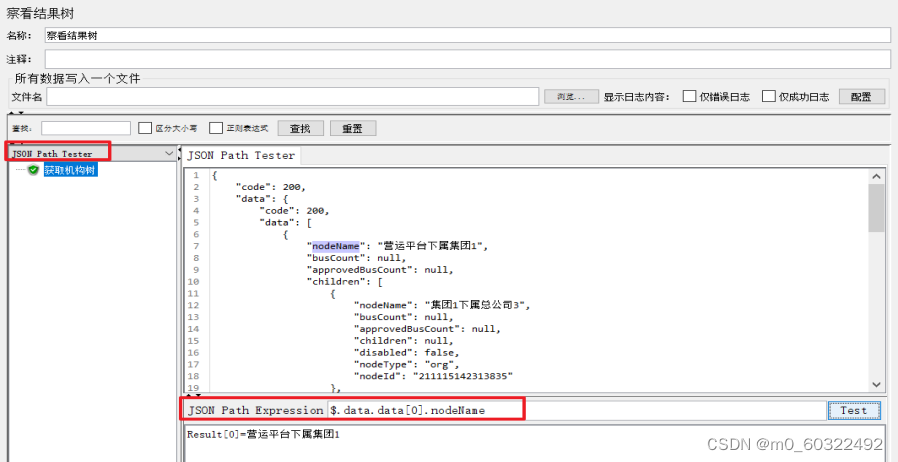
图 28 Json提取器--JSON Path Tester
(2)Json Path表达式
场景
表达式
描述
/
$
代表整个json,根节点
/
.
点代表下个节点
/
获取所有列表元素
获取第一层中的某个value值
$.key
获取根节点下的key的value值
获取第二层List中某个key的value值
$.list[0].key
获取根节点下的list(列表)中第一个对象的key的value值
获取列表下全部的某一个元素
$.list[*].key
获取根节点下的list(列表)中所有对象的key的value值
获取前N个值
$.list[:2]
获取根节点下的list(列表)中前2个对象的值
版权归原作者 m0_60322492 所有, 如有侵权,请联系我们删除。