
1、应用解耦
提高系统容错性和可维护性

在订单系统中,可以通过远程调用直接调用库存系统,支付系统,物流系统。
但是这三个系统耦合度太高了,因为订单系统下完订单首先去库存系统将库存-1,然后将返回值返回给订单系统,然后通过订单系统的返回结果来在支付系统进行支付,当支付完成后将返回结果返回给订单系统,最后物流系统拿着支付系统的返回结果进行物流发货。
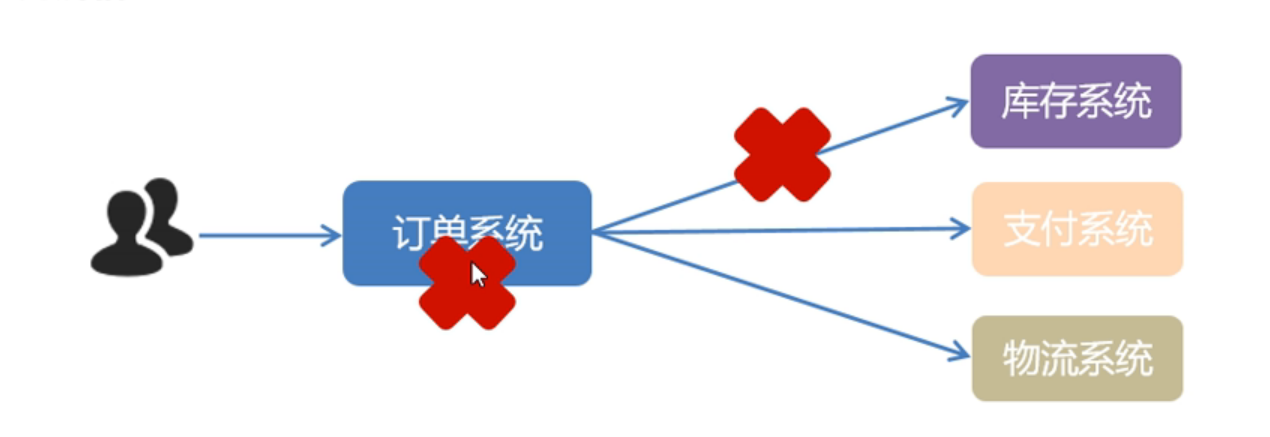 第一种情况是当库存系统因为网络波动无法收到订单系统的消息或者受到时间过长会导致整个链路的崩溃
第一种情况是当库存系统因为网络波动无法收到订单系统的消息或者受到时间过长会导致整个链路的崩溃
 第二种情况是新增一个与订单系统相关联的X系统,就需要在订单系统的源码种进行改写,这样会造成高内聚对后续应用的维护成本较高
第二种情况是新增一个与订单系统相关联的X系统,就需要在订单系统的源码种进行改写,这样会造成高内聚对后续应用的维护成本较高
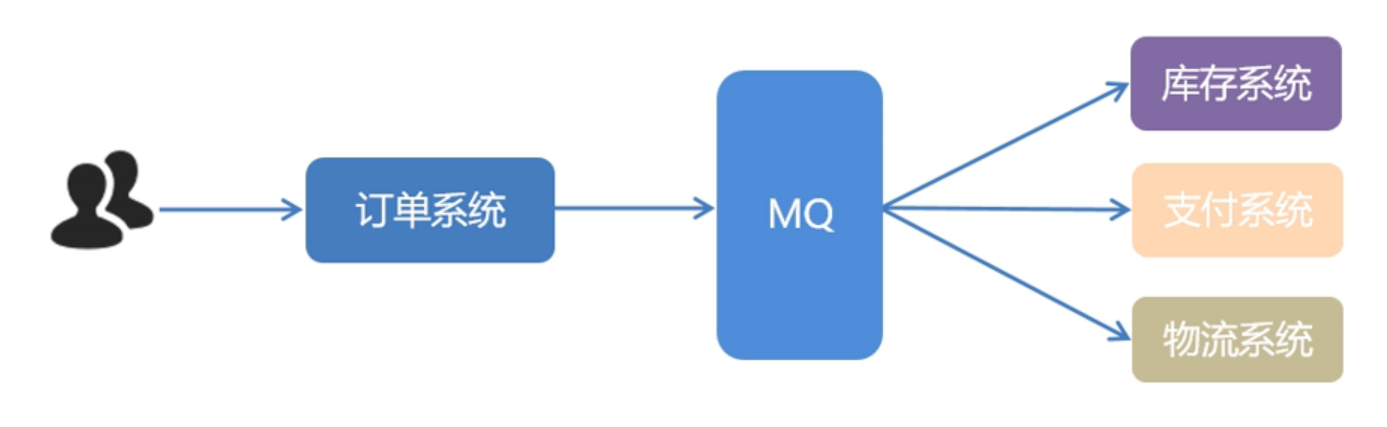 对于以上的情况可以使用MQ来解决,使其应用解耦。
对于以上的情况可以使用MQ来解决,使其应用解耦。

对于情况一:假如此刻库存系统出问题,好几分钟才恢复好,但是对订单系统没有任何影响,只需要重新从MQ中获取消息即可。
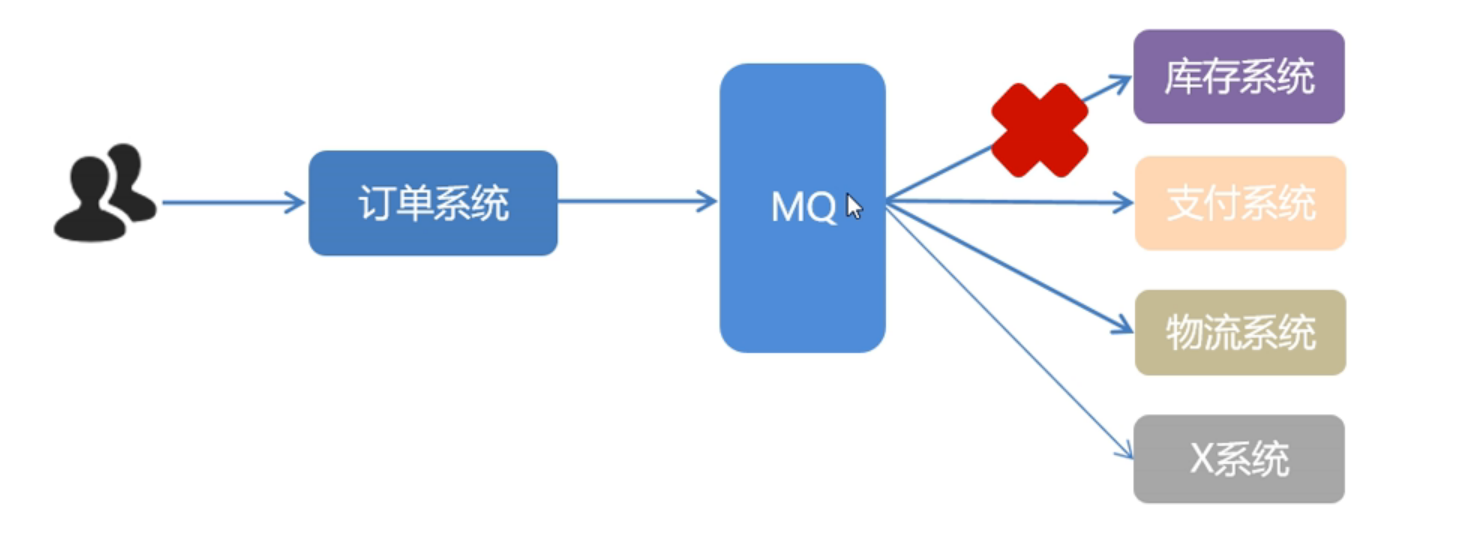
对于情况二:当新增一个X系统,只需要创建独立的X系统模块,然后X系统从MQ中获取消息,不再需要在订单系统源码中添加功能,这样做到了解耦,提高了维护性和容错性。
2、异步提速
提升用户体验和系统吞吐量
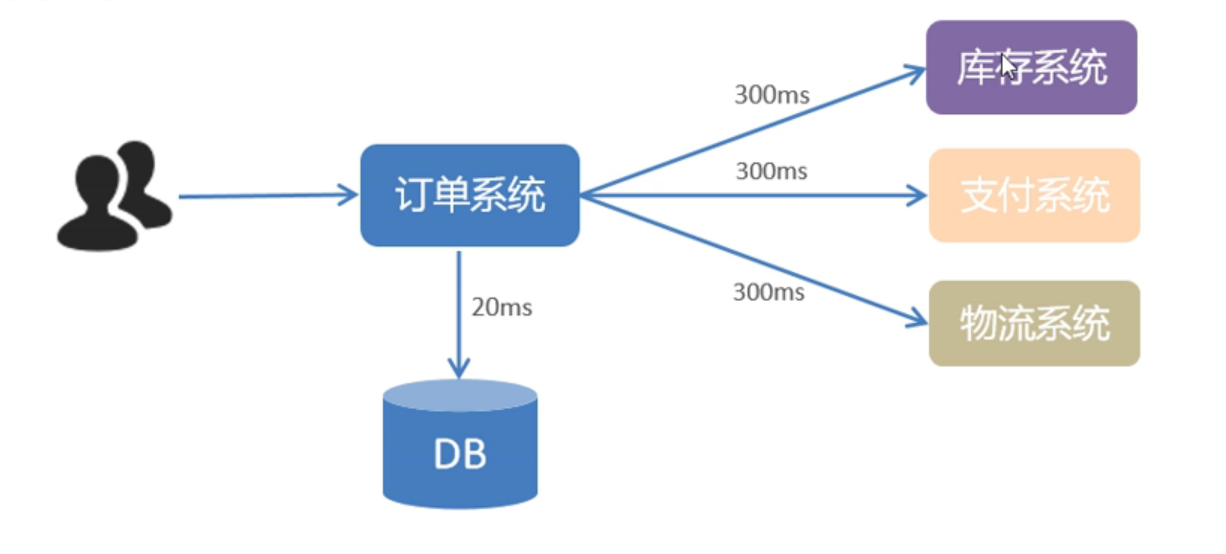 当用户下完单以后,订单系统需要在数据库中保存订单信息到订单表花费20ms,然后订单系统首先在库存系统操作并返回结果到订单系统花费300ms,支付系统和物流系统同意也各自花费300ms。这样就花费300+300+300+20=920ms后订单系统才能将结果返回给用户,延时太长
当用户下完单以后,订单系统需要在数据库中保存订单信息到订单表花费20ms,然后订单系统首先在库存系统操作并返回结果到订单系统花费300ms,支付系统和物流系统同意也各自花费300ms。这样就花费300+300+300+20=920ms后订单系统才能将结果返回给用户,延时太长
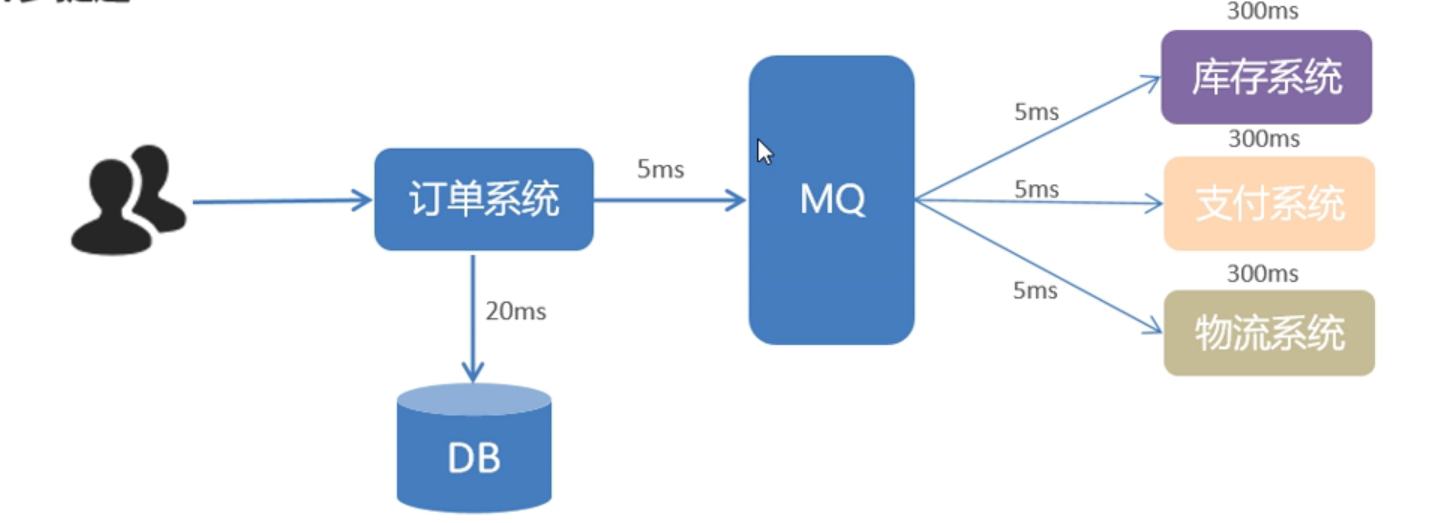 对于这种情况,可以使用MQ来处理,用户下完单就向数据库下单保存订单信息到订单表花费20ms,然后花费ms向MQ发送订单消息,最后MQ分别花费3×5=15ms向库存系统、支付系统、物流系统发送消息 。至于这三个系统收到消息处理的时间多少,就与订单系统不再有关系。用户一共消费5+20=25ms就可以收到下单成功响应。
对于这种情况,可以使用MQ来处理,用户下完单就向数据库下单保存订单信息到订单表花费20ms,然后花费ms向MQ发送订单消息,最后MQ分别花费3×5=15ms向库存系统、支付系统、物流系统发送消息 。至于这三个系统收到消息处理的时间多少,就与订单系统不再有关系。用户一共消费5+20=25ms就可以收到下单成功响应。
3、削峰填谷
提高系统稳定性
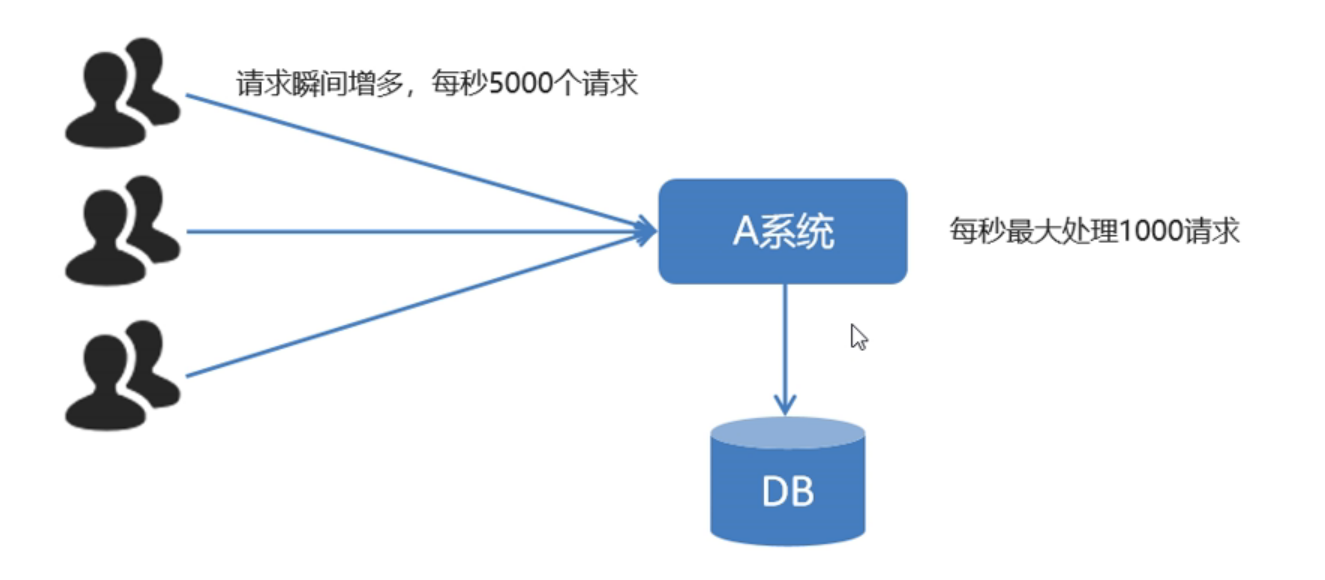
对于秒杀活动,很多用户会在同一时间疯狂的下单,这样导致大量的请求让系统无法响应导致宕机。
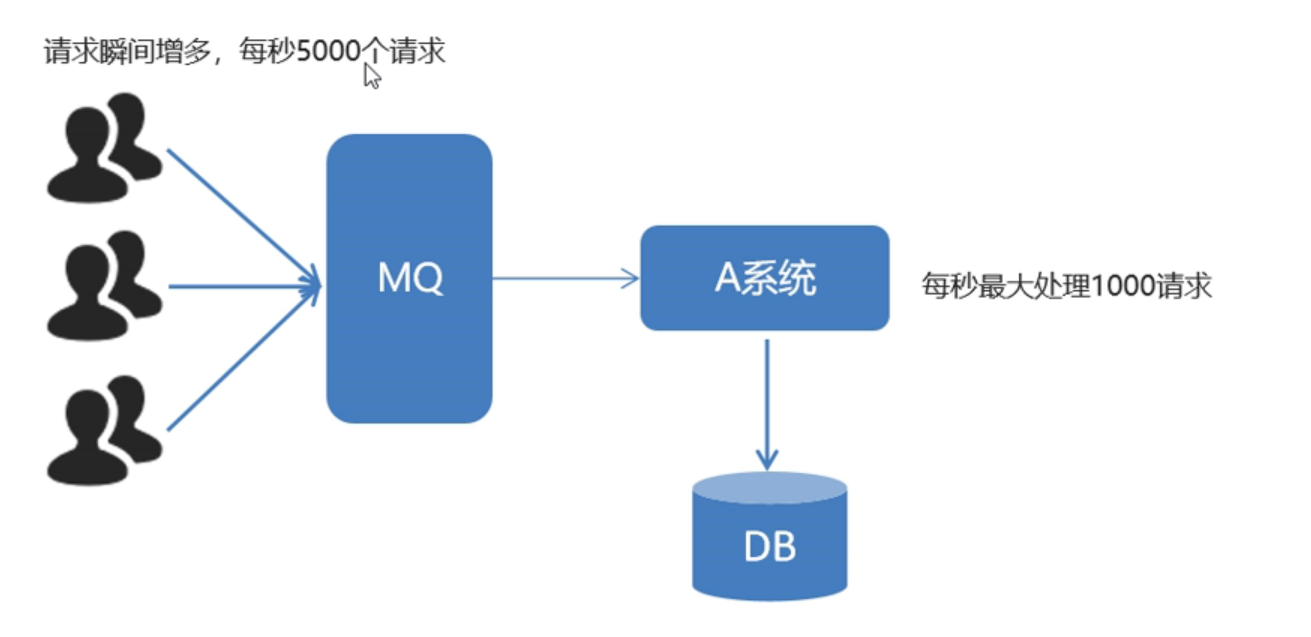
对于以上的情况可以使用MQ来解决,用户的大量请求不再直接与系统对接,而是与MQ对接。然后大量消息进入队列。
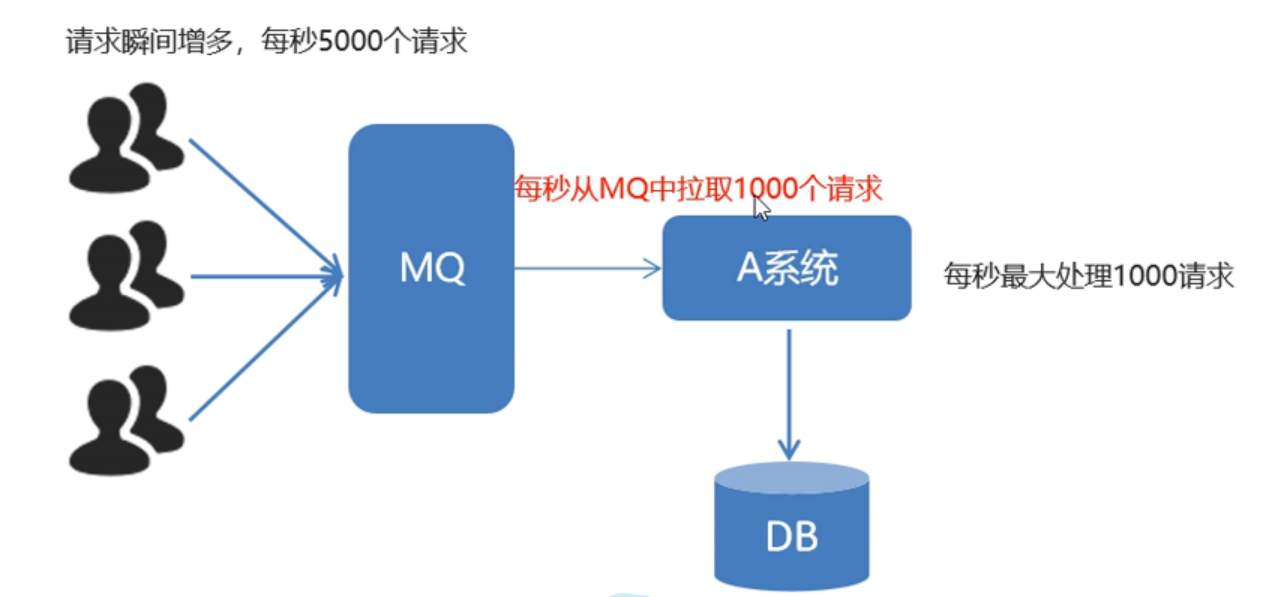
然后系统每秒从MQ中拉取自己所称承受的最大请求,这样就可以解决这种问题,可以提高系统的稳定性。
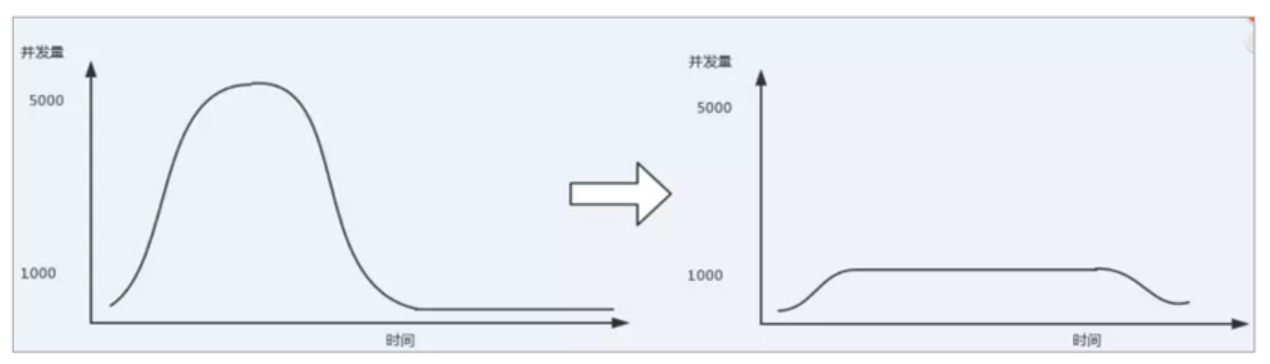
使用了MQ之后,限制消费消息的速度为1000,这样一来,高峰期产生的数据势必会被积压在 MQ 中,高峰就被“削”掉了,但是因为消息积压,在高峰期过后的一段时间内,消费消息的速度还是会维持在1000,直到消费完积压的消息,这就叫做“填谷”
二、RabbitMQ的缺点

1、系统可用性降低
系统引入的外部依赖越多,系统稳定性越差。一旦 MQ 宕机,就会对业务造成影响。如何保证MQ的高可用?
2、系统复杂度提高
MQ 的加入大大增加了系统的复杂度,以前系统间是同步的远程调用,现在是通过 MQ 进行异步调用。如何保证消息没有被重复消费?怎么处理消息丢失情况?那么保证消息传递的顺序性?
3、 一致性问题
A系统处理完业务通过MQ给B、C、D三个系统发消息数据,如果B 系统、C系统处理成功,D 系统外理失败。如何保证消息数据处理的一致性?
三、RabbitMQ的五种队列形式
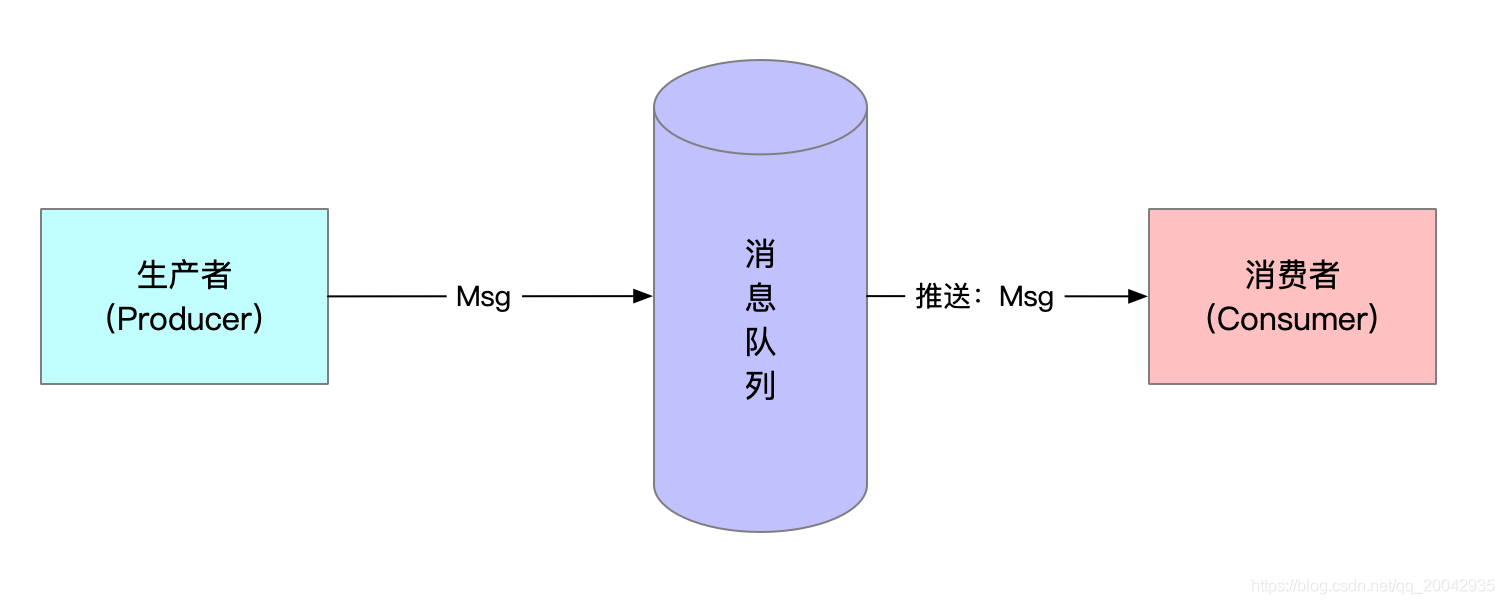
1、点对点队列
功能:一个生产者投递消息给队列,只能允许有一个消费者进行消费。
推拉模式:
- 推:消费者已经启动了,建立长连接,一旦生产者向队列投递消息会马上推送给消费者。
- 拉:生产者先投递消息到队列进行缓存,这时候消费者再启动的时候就会向队列获取消息。
应答模式:
- 自动应答:不在乎消费者对这个消息处理是否成功,都会告诉队列删除消息,如果处理消息失败的情况下,实现自动补偿。
- 手动应答:消费处理完业务逻辑,手动返回ACK(通知)告知对队列服务器是否删除该消息。
为了确保消息不会丢失,RabbitMQ支持消息应答。消费者发送一个消息应答,告诉RabbitMQ这个消息已经接收并且处理完毕了。RabbitMQ就可以删除它了
如果一个消费者挂掉却没有发送应答,RabbitMQ会理解为这个消息没有处理完全,然后交给另一个消费者去重新处理。这样,你就可以确认即使消费者偶尔挂掉也不会丢失任何消息了。
没有任何消息超时限制;只有当消费者挂掉时,RabbitMQ才会重新投递。即使处理一条消息会花费很长的时间。
消息应答是默认打开的。我们通过显示的设置autoAsk=true关闭这种机制。现即自动应答开,一旦我们完成任务,消费者会自动发送应答。通知RabbitMQ消息已被处理,可以从内存删除。如果消费者因宕机或链接失败等原因没有发送ACK(不同于ActiveMQ,在RabbitMQ里,消息没有过期的概念),则RabbitMQ会将消息重新发送给其他监听在队列的下一个消费者
2、工作队列模式
功能:队列服务器向消费者发送消息的时候,消费者采用手动应答模式,队列服务器必须要接到消费者发送ack结果通知,才会继续发送下一个消息。工作队列称为“能者多劳队列”,谁应答的快,谁就能多消费信息。

工作模式(默认消费者集群均摊消费):
- 假设生产者向队列发送10个消息,消费者1和消费者2都各自消费5个,保证了消费的唯一性。
弊端:
- 均摊消费会带来一些弊端:如果每个消费者处理消费的业务时间不相同的情况,可能对消费者处理比较慢的服务器不公平
RabbitMQ的公平转发:
目前消息转发机制是平均分配,这样就会出现俩个消费者,奇数的任务很耗时,偶数的任何工作量很小,造成的原因就是近当消息到达队列进行转发消息。并不在乎有多少任务消费者并未传递一个应答给RabbitMQ。仅仅盲目转发所有的奇数给一个消费者,偶数给另一个消费者。
为了解决这样的问题,我们可以使用basicQos方法,传递参数为prefetchCount= 1,这样告诉RabbitMQ不要在同一时间给一个消费者超过一条消息。
换句话说,只有在消费者空闲的时候会发送下一条信息。调度分发消息的方式,也就是告诉RabbitMQ每次只给消费者处理一条消息,也就是等待消费者处理完毕并自己对刚刚处理的消息进行确认之后,才发送下一条消息,防止消费者太过于忙碌,也防止它太过去清闲。(通过设置channel.basicQos(1);)
3、发布订阅模式
功能:一个生产者发送消息,多个消费者获同样的消息(包括一个生产者、一个交换机、多个队列、多个消费者)。

「点对点」和「工作队列模式」都是消息只能发送到指定的queue中,但是想要类似广播的效果,发给所有消费者,这时候就需要用到交换机(exchange)了。
注意:交换机没有存储消息功能,如果消息发送到没有绑定消费队列的交换机,消息则丢失。
4、路由模式Routing
功能: 生产者发送消息到交换机并指定一个路由key,消息队列绑定到交换机时要指定路由key(key匹配就能接收消息,key不匹配就不能接收消息)。
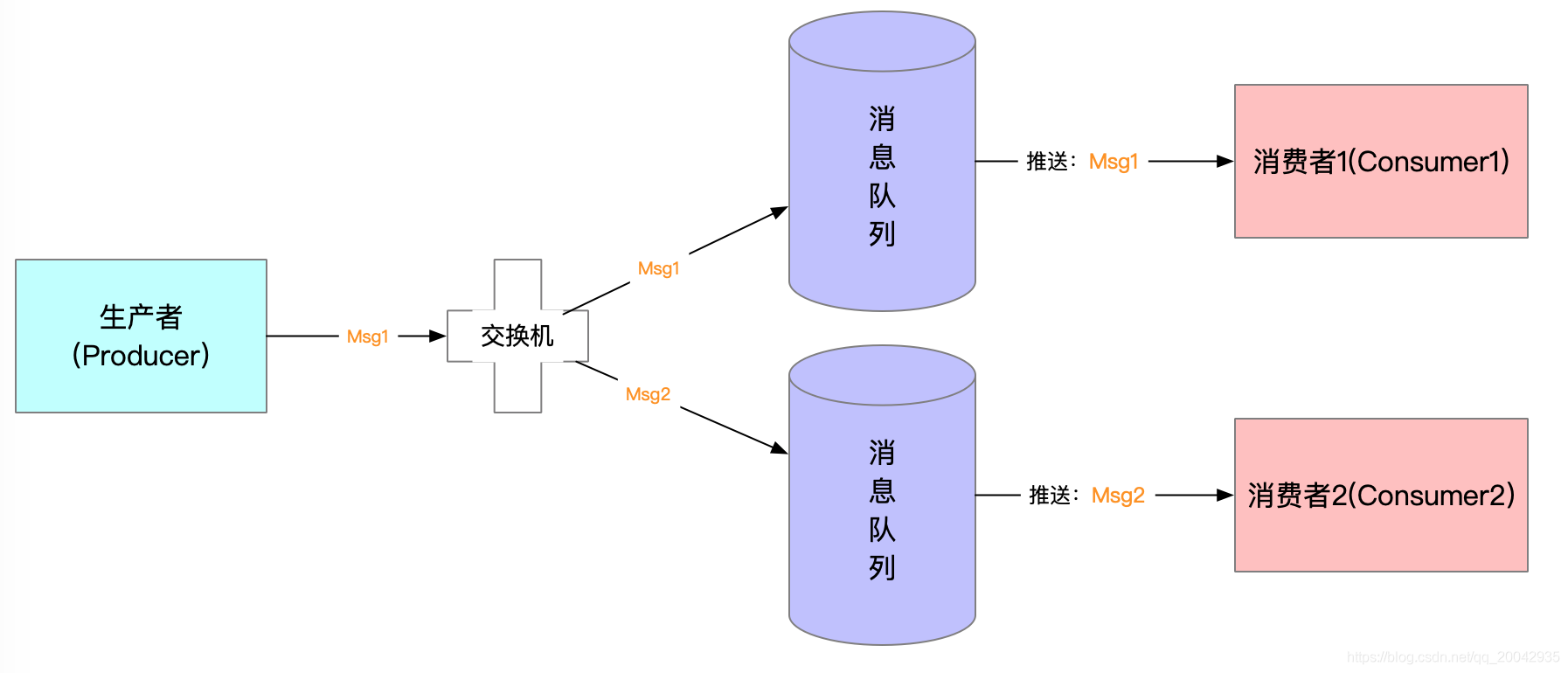
这其实就是Direct组播模式,设置好Exchange交换机的类型,转发的时候,会检查队列中的RoutingKey值,如果和消息的关键字相同则转发,否则丢弃。
5、通配符模式Topics
功能: 此模式是在路由模式的基础上,使用了通配符来管理消费者接收消息。生产者发送消息到交换机,交换机根据绑定队列的RoutingKey的值进行通配符匹配;
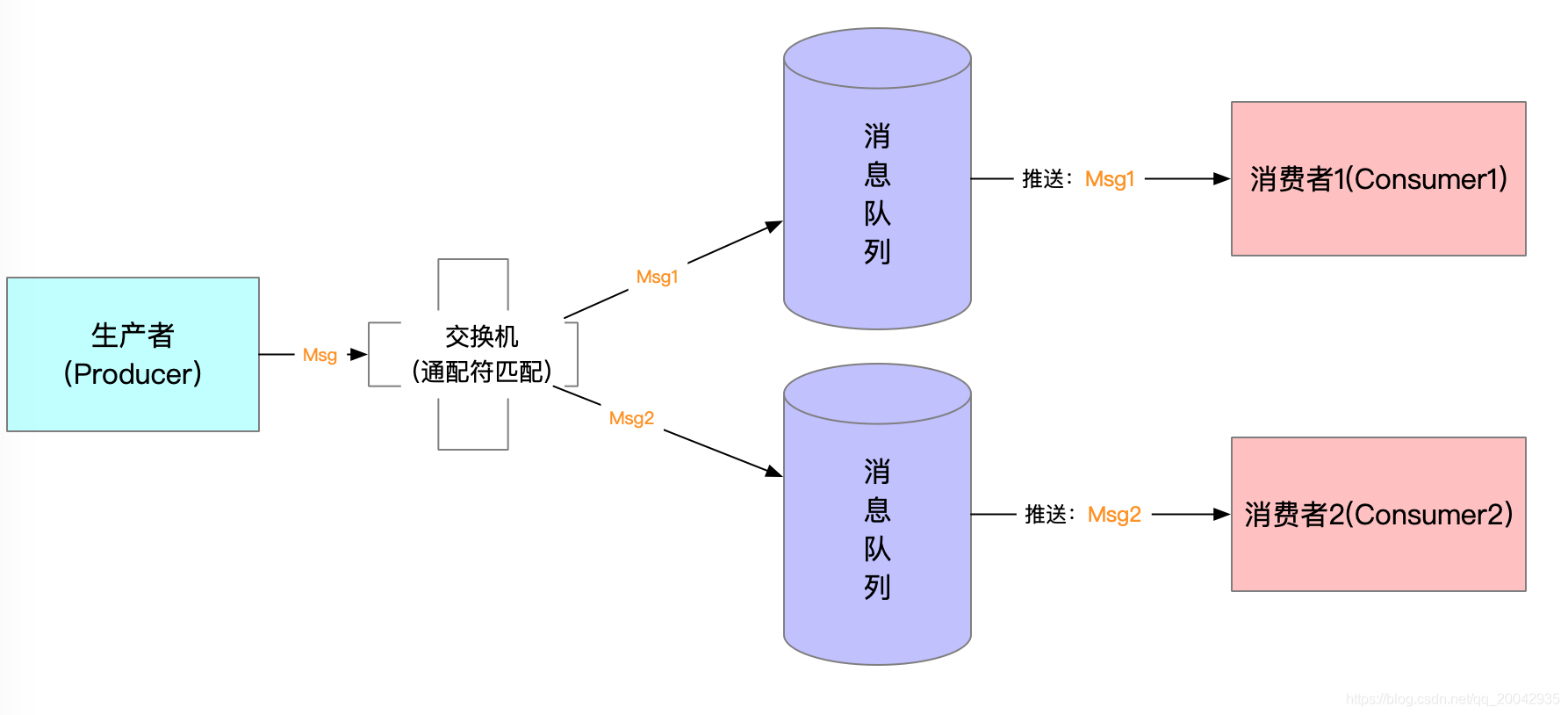
通配符模式,其实和路由模式相类似,但是这个支持模糊匹配。
例如:
- 符号#:匹配一个或者多个词lazy.# 可以匹配lazy.irs或者lazy.irs.cor
- 符号:只能匹配一个词lazy. 可以匹配lazy.irs或者lazy.cor
四、RabbitMQ高级特性
1、消息的可靠投递
在使用 RabbitMQ的时候,作为消息发送方希望杜绝任何消息丢失或者投递失败场景。RabbitMQ为我们提供了两种方式用来控制消息的投递可靠性模式。
- confirm确认模式
- return退回模式
rabbitmq整个消息投递的路径为:producer--->exchange--->queue--->consumer
- confirm确认模式:消息从producer到exchange 则会返回一个confirmCallback。交换机接收消息如果成功了返回成功的消息,如果失败了返回失败的消息。
- return退回模式:消息从exchange-->queue 投递失败则会返回一个 returnCallback。当消息发送给交换机,交换机路由到队列失败了只返回失败的消息,成功的消息不返回。
2、Consumer ACK
ack指Acknowledge,确认。 表示消费端收到消息后的确认方式。
有三种确认方式:
自动确认:acknowledge=“none” 默认方式
手动确认:acknowledge=“manual”
根据异常情况确认:acknowledge=“auto”,(这种方式使用麻烦)
其中自动确认是指,当消息一旦被Consumer接收到,则自动确认收到,并将相应 message 从 RabbitMQ 的消息缓存中移除。 但是在实际业务处理中,很可能消息接收到,业务处理出现异常,那么该消息就会丢失。如果设置了手动确认方式,则需要在业务处理成功后,调用channel.basicAck(),手动签收,如果出现异常,则调用channel.basicNack()方法,让其自动重新发送消息。
3、消费端限流
如上图场景,A系统最大处理请求位1000个,当A系统维护的时候,MQ以及堆积了很多消息。此刻A系统已经维护好了,如果MQ消息全部大量涌向A系统就会造成A系统宕机,所以需要进行消费的限流,将MQ的消息发送数量进行限制,让A系统所能消化的最大请求量。
- 配置 prefetch属性设置消费端一次拉取多少消息(spring 设置) springboot在yml文件中设置
- 消费端的确认模式一定为手动确认。acknowledge=“manual”,只有手动签收之后才会拉去下一条消息
spring:
rabbitmq:
listener:
simple:
prefetch: 1 # 一次拉去多少消息
acknowledge-mode: manual # 设置确认模式
这样就可以限制消费者每次对消息拉取的次数,防止大量消息涌入导致宕机
4、TTL存活时间
- TTL 全称 Time To Live(存活时间/过期时间)。
- 当消息到达存活时间后,还没有被消费,会被自动清除。
- RabbitMQ可以对消息设置过期时间,也可以对整个队列(Queue)设置过期时间。
过期时间策略有两种:
- 会对整个队列消息统一过期。
- 当该消息在队列头部时(消费时)会单独判断这一消息是否过期。
5、死信队列
死信队列,英文缩写:DLX 。Dead Letter Exchange(死信交换机),当消息成为Dead message后,可以被重新发送到另一个交换机,这个交换机就是DLX。
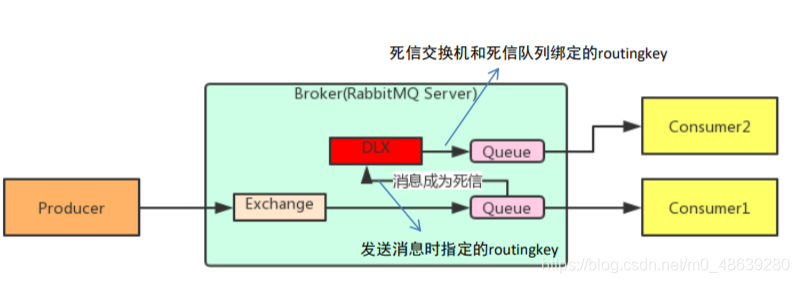
消息成为死信的三种情况:
- 消息被拒绝
- 消息TTL过期
- 队列达到最大长度
6、延迟队列
延迟队列,即消息进入队列后不会立即被消费,只有到达指定时间后,才会被消费。
- 但在RabbitMQ中并未提供延迟队列功能。
- 可以使用: TTL+死信队列 组合实现延迟队列的效果
需求:
- 淘宝七天自动确认收货。在我们签收商品后,物流系统会在七天后延时发送一个消息给支付系统,通知支付系统将货款打给商家,这个过程持续七天,就是使用了MQ的延迟推送功能;
- 订单在十分钟之内未支付则自动取消;
- 新创建的店铺,如果在十天内都没有上传过商品,则自动发送消息提醒;
- 用户注册成功后,如果三天内没有登陆则进行短信提醒;
- 用户发起退款,如果三天内没有得到处理则通知相关运营人员;
- 预定会议后,需要在预定的时间点前十分钟通知各个与会人员参加会议。

如上图,实现一个下单30分钟后未支付,取消订单并且回滚库存这个功能就可以使用延迟队列。
当订单系统下单后,发送一条消息给MQ,然后MQ收到消息设置30分钟后消费消息。当到30分钟时候,将这条消息发送给库存系统,判断订单是否支付,如果支付了就不做什么,如果未支付,那么就取消订单,回滚库存。
当然定时任务也可以勉强实现这个功能,不过定时任务时间设置不能完美的达到要求,如果时间设置过长,比如1分钟判断一次,那么就会造成29分钟或者31分钟进行判断。如果1秒判断一次会造成频繁的查询数据库导致数据库访问压力过大。
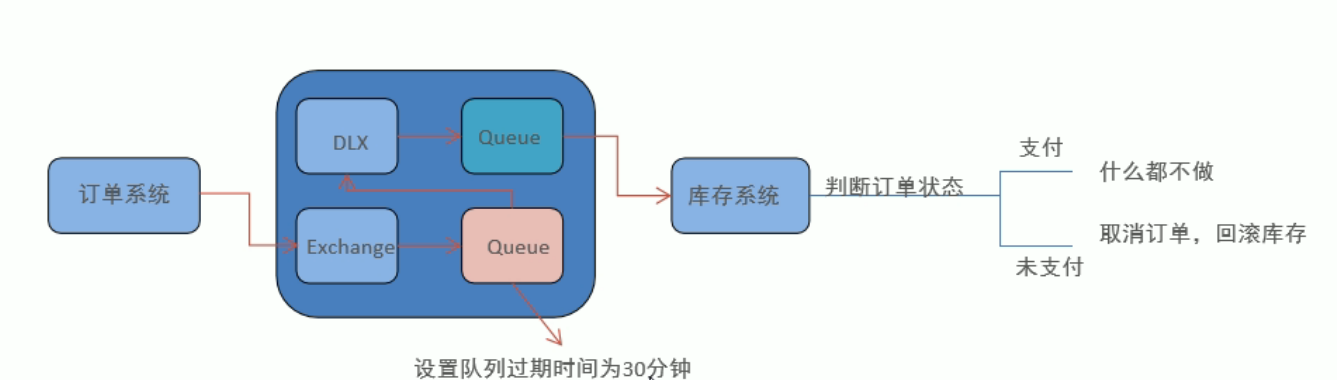
不过RabbitMQ没有延迟队列功能,不过可以使用TTL+死信队列完成延迟队列。
如上图,当订单系统下完订单发送消息给队列,这条消息的TTL时间设置为30分钟。当30分钟后该消息过期了进入死信交换机,死信交换机将该过期消息发送给私信队列,最后死信队列将过期消息发送给库存系统提醒库存系统进行判断该订单是否支付。
版权归原作者 梁山教父 所有, 如有侵权,请联系我们删除。