
欢迎来到《小5讲堂》,大家好,我是全栈小5。
这是《Sql Server》系列文章,每篇文章将以博主理解的角度展开讲解,
特别是针对知识点的概念进行叙说,大部分文章将会对这些概念进行实际例子验证,以此达到加深对知识点的理解和掌握。
温馨提示:博主能力有限,理解水平有限,若有不对之处望指正!

目录
前言
最近在做数据修改,有时候太久没写sql语句,突然想通过子查询的方式去批量更新数据的时候,
还是有点不知所措,那就一步一步来吧,也写篇文章梳理和总结下,毕竟也是基本的操作加深印象。
在做数据批量修改时,有个关键点,就是分组查询后找出另外一个字段不同值得记录,因此本篇文章就针对这个查询梳理一遍。
创建表
假设有一张表,有三个主要字段,城市名称、区县名称、代理商名称。
创建表时,习惯性给表加一个id编号,并且是自增字段,有个序号感觉看起来舒服,hhh~~~
createtable test_name
(
id intidentity(1,1),-- 自增编号
city_name nvarchar(50),-- 城市名称
area_name nvarchar(50),-- 区县名称
agent_name nvarchar(50)-- 代理商名称)
模拟数据
insertinto test_name(city_name,area_name,agent_name)values('广州市','白云区','张三'),('广州市','白云区','张三'),('广州市','白云区','李四'),('广州市','白云区','王五'),('深圳市','龙岗区','张三')
上面是一次性添加多条,所以只需要写一个values即可,也可以分开写。
分开写后,就能看出来重复啰嗦,所以才会有一些简写的方式。
insertinto test_name(city_name,area_name,agent_name)values('广州市','白云区','张三')insertinto test_name(city_name,area_name,agent_name)values('广州市','白云区','张三')insertinto test_name(city_name,area_name,agent_name)values('广州市','白云区','李四')insertinto test_name(city_name,area_name,agent_name)values('广州市','白云区','王五')insertinto test_name(city_name,area_name,agent_name)values('深圳市','龙岗区','张三')
分组查询
城市分组
select city_name from test_name groupby city_name
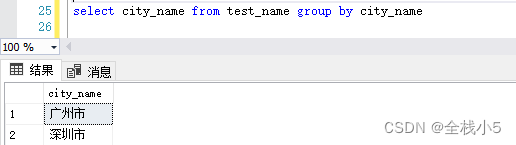
城市区县分组
select city_name,area_name from test_name groupby city_name,area_name
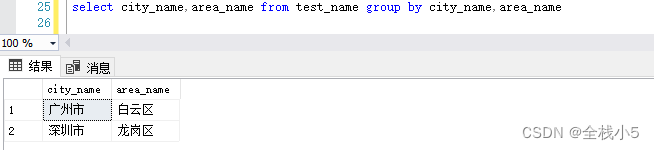
代理商维度
城市、区县、代理商,三者组合唯一查询
select*from test_name
select city_name,area_name,agent_name from test_name groupby city_name,area_name,agent_name
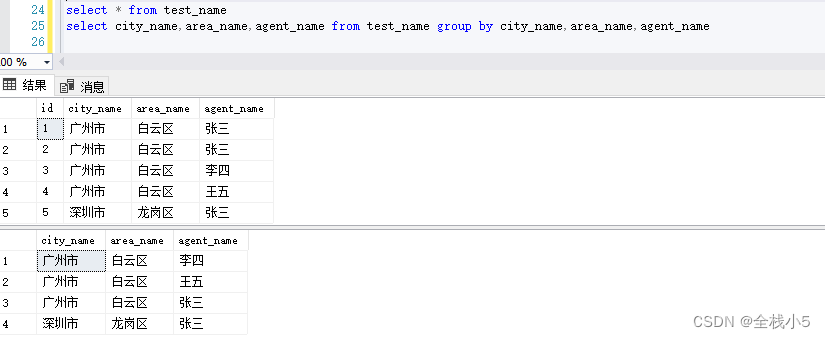
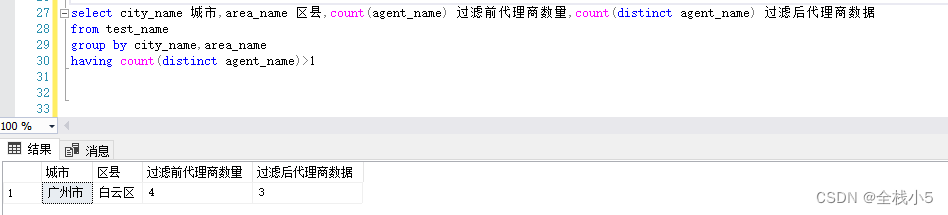
不同代理
同城市区县,但不同代理商的记录。
select city_name 城市,area_name 区县,count(agent_name) 过滤前代理商数量,count(distinct agent_name) 过滤后代理商数据
from test_name
groupby city_name,area_name
havingcount(distinct agent_name)>1
小知识点
identity
在 SQL Server 中,Identity 是一种特殊的属性,用于指定某一列是自动生成的数字列。
通过设置 Identity 属性,可以让 SQL Server 自动生成唯一的数字值,并自动填充到指定的列中。
这样可以很方便地为表中的每一行生成一个唯一的标识符。
在创建表时,可以通过以下语法向列添加 Identity 属性:
CREATETABLE your_table
(
column_name INTIDENTITY(1,1)PRIMARYKEY,-- other columns);
在这个例子中,column_name 是指定了 Identity 属性的列名,INT 是数据类型,IDENTITY(1,1) 表示以1为起始值,1为递增值自动为每个新行生成一个唯一值,PRIMARY KEY 用来指定此列为主键。
当插入数据时,不需要为 Identity 列指定具体的值,数据库会自动生成并填充对应的值。如果需要获取自动生成的 Identity 值,可以使用 SCOPE_IDENTITY() 函数或者 @@IDENTITY 系统变量。
删除数据
基于上面自增编号知识点,来了解下delete和truncate删除数据的最大区别
delete 表名 可按条件删除或者批量删除记录,并且自增id编号会继续从当前记录值开始算,比如最新编号为10,即使删除编号10的记录,那么新插入一条记录,编号为11
truncate table 表名,全表删除,id自增编号重新开始从1或者指定规则计算
分组查询原则
选择列表中的列 ‘test_name.area_name’ 无效,因为该列没有包含在聚合函数或 GROUP BY 子句中。
基本原则就是,查询的字段值必须要在分组里,否则无效。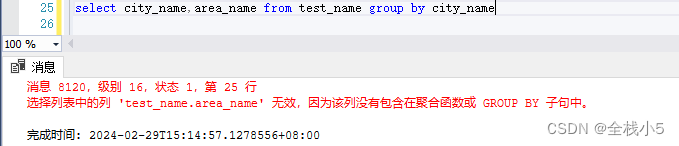
文章推荐
【Sql Server】新手一分钟看懂在已有表基础上修改字段默认值和数据类型
【数据库】Sql Server数据迁移,处理自增字段赋值
【数据类型】C#和Sql Server、Mysql、Oracle等常见数据库的数据类型对应关系
总结:温故而知新,不同阶段重温知识点,会有不一样的认识和理解,博主将巩固一遍知识点,并以实践方式和大家分享,若能有所帮助和收获,这将是博主最大的创作动力和荣幸。也期待认识更多优秀新老博主。
版权归原作者 全栈小5 所有, 如有侵权,请联系我们删除。