
转载自神龙大侠
我是用olphinScheduler 3.2.1版本做源代码编译部署(部署方式参考我的另外一篇文档《源代码编译,Apache DolphinScheduler前后端分离部署解决方案》)
二进制文件部署本文也适用,只需要修改相对应的配置即可。
资源管理底层基座替换成hdfs
Flink程序jar包是在资源中心进行管理的,对于dolphinscheduler系统来说,资源主要包括3类
文件管理
当在调度过程中需要使用到第三方的 jar 或者用户需要自定义脚本的情况,可以通过在该页面完成相关操作。可创建的文件类型包括:txt/log/sh/conf/py/java 等。并且可以对文件进行编辑、重命名、下载和删除等操作。
UDF管理
资源管理和文件管理功能类似,不同之处是资源管理是上传的 UDF 函数,文件管理上传的是用户程序,脚本及配置文件。
任务组管理
任务组主要用于控制任务实例并发,旨在控制其他资源的压力(也可以控制 Hadoop 集群压力,不过集群会有队列管控)。您可在新建任务定义时,可配置对应的任务组,并配置任务在任务组内运行的优先级。用户仅能查看有权限的项目对应的任务组,且仅能创建或修改具有写权限的项目对应的任务组。
DolphinScheduler支持将资源存储在api-server本地文件系统或者hadoop分布式文件系统hdfs上面(也可以支持s3,我用的hdfs),生产环境把资源存在本地文件系统是不可靠的,所以需要将底层介质存储平台改成hdfs。
对于DolphinScheduler的核心组件,
- 资源的管理是在api-server
- 资源的使用是work-server
所以如果支持hdfs的配置修改需要对api-server和worker-server重新部署。
如果要支持hdfs需要修改(dolphinscheduler-common中的common.properties)如下配置:
resource.storage.upload.base.path=/dolphinscheduler //也可不修改
resource.hdfs.root.user=
resource.hdfs.fs.defaultFS=
hadoop.security.authentication.startup.state=true
java.security.krb5.conf.path= //krb5.conf配置文件
login.user.keytab.username=
login.user.keytab.path=
修改完之后,重新编译api-server, work-server部署,就可以修改资源管理文件系统的底座了。
目前DolphinScheduler支持创建文件夹和上传文件的功能,实际使用如下图所示:
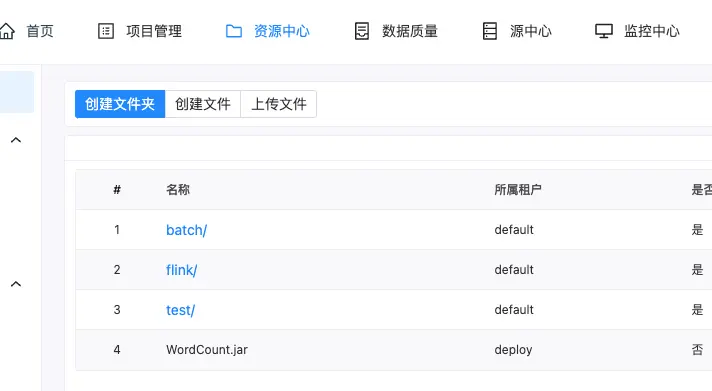
备注:
- 目前admin用户可以看到所有的文件;
- 如果新建一个用户的话,是看不到其他用户创建的文件
Worker支持Flink local模式执行任务
我以WordCount.jar包作为例子,具体可以替换成特定任务的jar包。
WordCount任务是flink的example代码,类似第一个hello world程序,在二进制包examples目录下。有batch和streaming两种任务类型的jar包
在worker机器上部署flink环境(使用1.19版本)
我用的bin二进制部署文件,下载地址为 https://flink.apache.org/2024/06/14/apache-flink-1.19.1-relea...
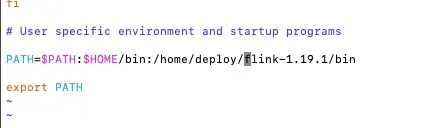
配置Flink path可以修改机器的
bash_profile
文件,也可以修改DolphinScheduler的
dolphinscheduler_env.sh
配置文件。
- bash_profile
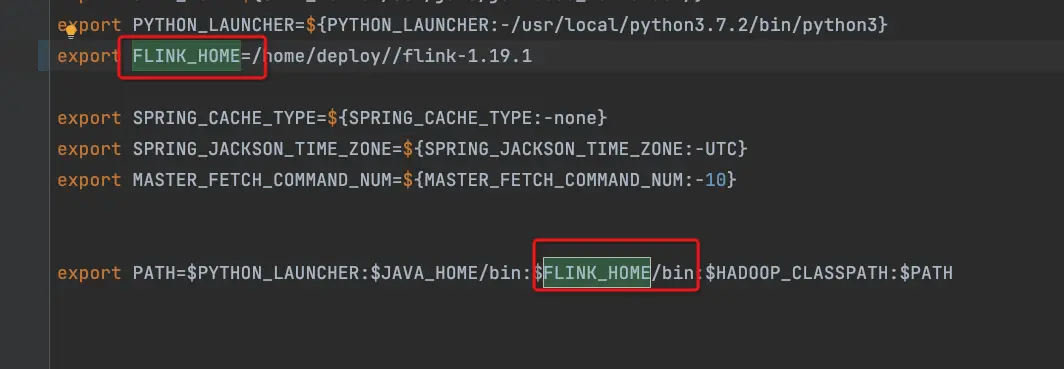
- dolphinscheduler_env.sh
租户的概念
DolphinScheduler支持多个租户,不同的租户之间资源是隔离,租户的实现机制是根据linux上用户来做资源隔离,如下图所示:
所以Flink的环境配置在具体的实施情况可以支持一些非常灵活的特性支持,比如可以在worker机器上创建不同的user:
- flink119
- flink108
- flink112
不同user配置不同的Flink版本环境信息,这样Flink任务可以根据选择租户的不同来支持Flink多版本特性的支持。
上传Flink任务jar包
我这直接使用Flink的
example jar
包了,
/batch/
目录下的
WrodCount.jar
。
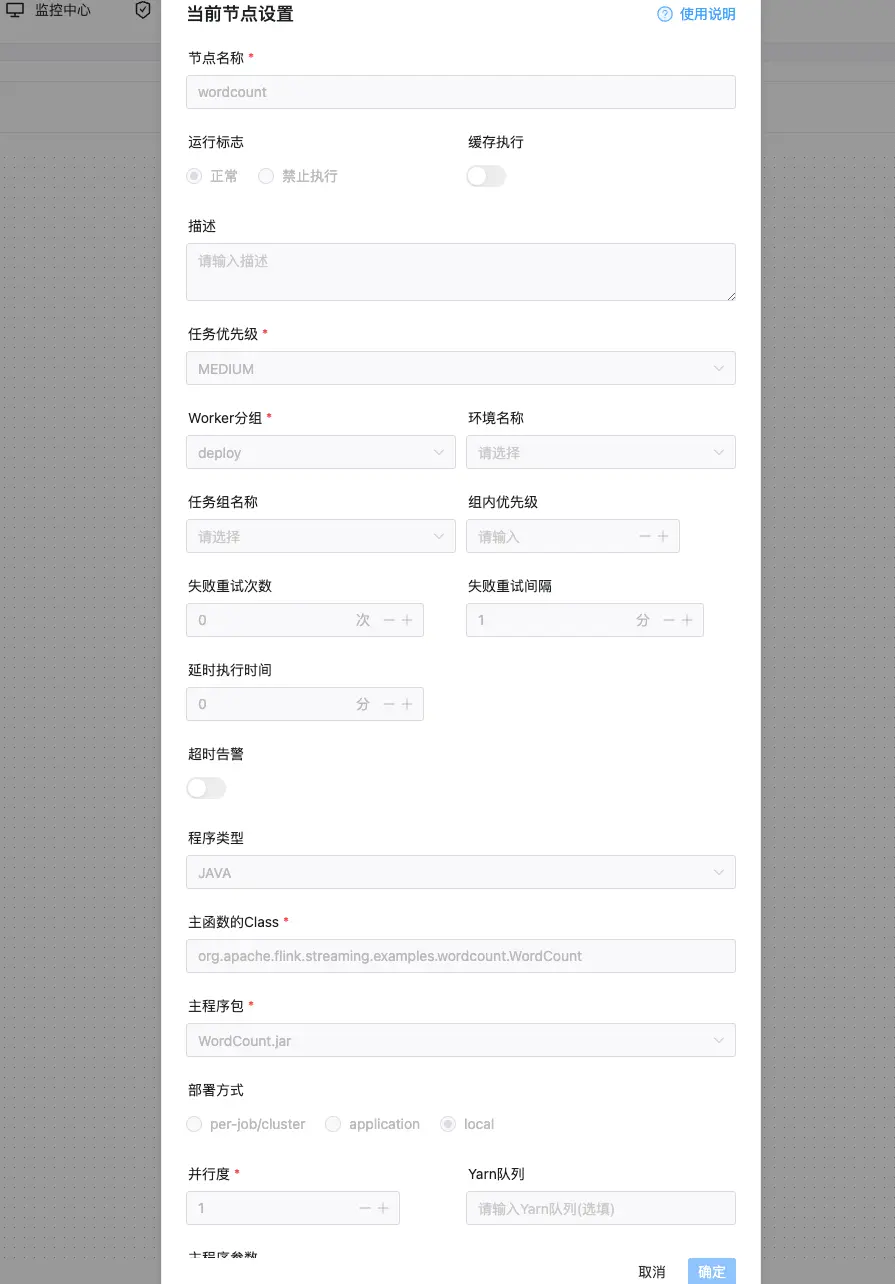
注意,非常重要,执行的时候,需要选择正确的租户。
否则,要不找不到Flink,要不对于版本差异的代码 会有不符合预期的执行情况噢。
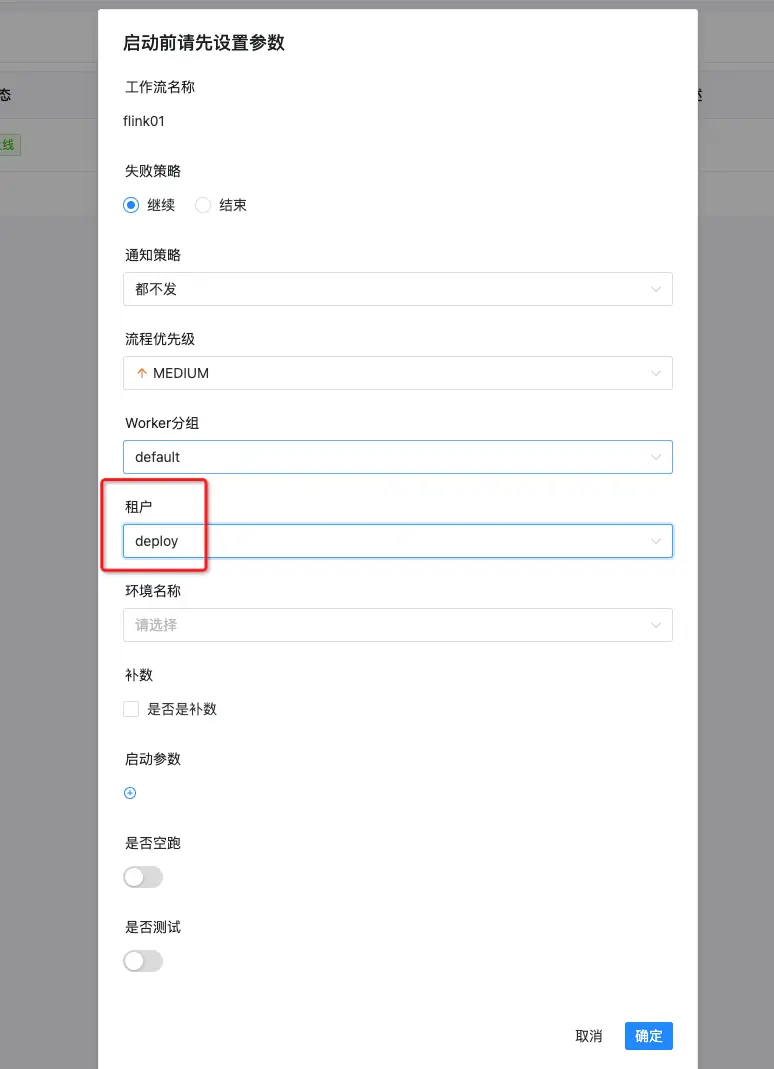
Flink任务运行对于batch和streaming任务有不同的效果,streaming任务会一直执行,batch任务执行完之后就退出了。
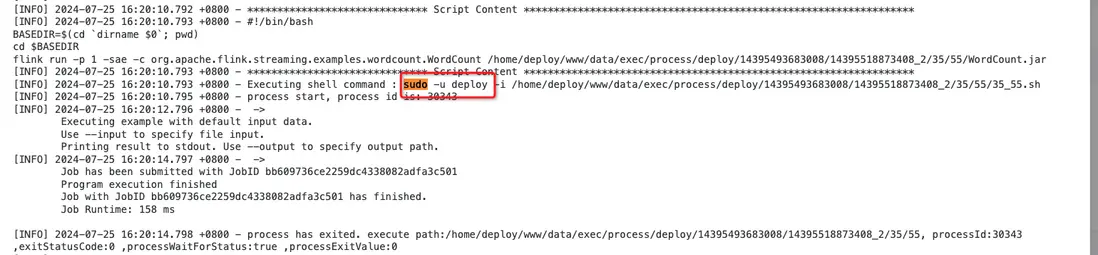
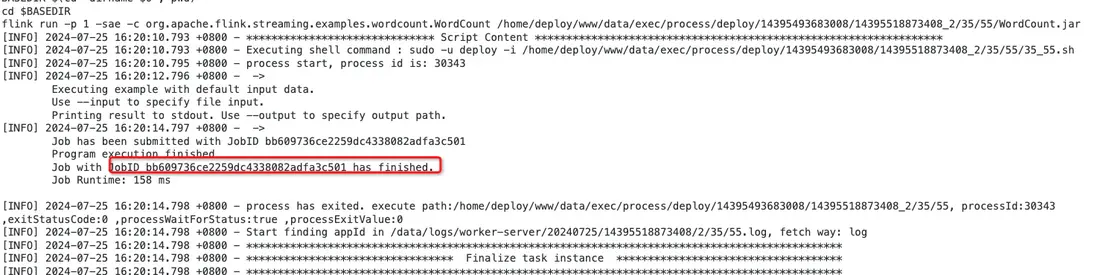
可以在任务实例查看flink任务的执行日志,如下图所示:
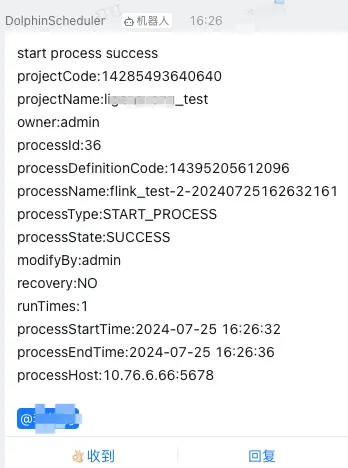
也可以将任务的执行情况,发送到钉钉:
Flink on yarn支持
Flink on yarn和Flink local对于hello world程序来说没有什么特别的不同,只是需要worker机器本身的部署用户(我的是deploy用户)配置好hadoop环境。
配置好
$HADOOP_HOME
和
$HADOOP_CLASSPATH
即可。
flink on yarn运行效果看图:
Yarn中application运行日志:

原文链接:https://segmentfault.com/a/1190000045101168
本文由 白鲸开源科技 提供发布支持!
版权归原作者 DolphinScheduler社区 所有, 如有侵权,请联系我们删除。