
实现访问首页
from os.path import dirname
from selenium import webdriver
classImageAutoSearchAndSave:"""图片自动搜索保存"""def__init__(self):"""初始化"""
self.driver = webdriver.Chrome(executable_path=dirname(__file__)+"/chromedriver.exe")defrun(self):"""开始运行"""print("=======开始=======")# 访问首页
self.driver.get("https://pixabay.com/")print("=======结束=======")if __name__ =='__main__':
ImageAutoSearchAndSave().run()
启动后会自动打开一个页面
实现图片自动欧索
from os.path import dirname
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
classImageAutoSearchAndSave:"""图片自动搜索保存"""def__init__(self, keyword):"""初始化"""
self.keyword = keyword
self.driver = webdriver.Chrome(executable_path=dirname(__file__)+"/chromedriver.exe")defrun(self):"""开始运行"""print("=======开始=======")# 访问首页
self.driver.get("https://pixabay.com/")# 搜索图片
self._search_image()print("=======结束=======")def_search_image(self):'''搜索图片'''
elem = self.driver.find_element_by_css_selector("input[name]")
elem.send_keys(self.keyword + Keys.ENTER)if __name__ =='__main__':
keyword ="cat"
ImageAutoSearchAndSave(keyword).run()
遍历所有图片列表页面
页面分析
第一页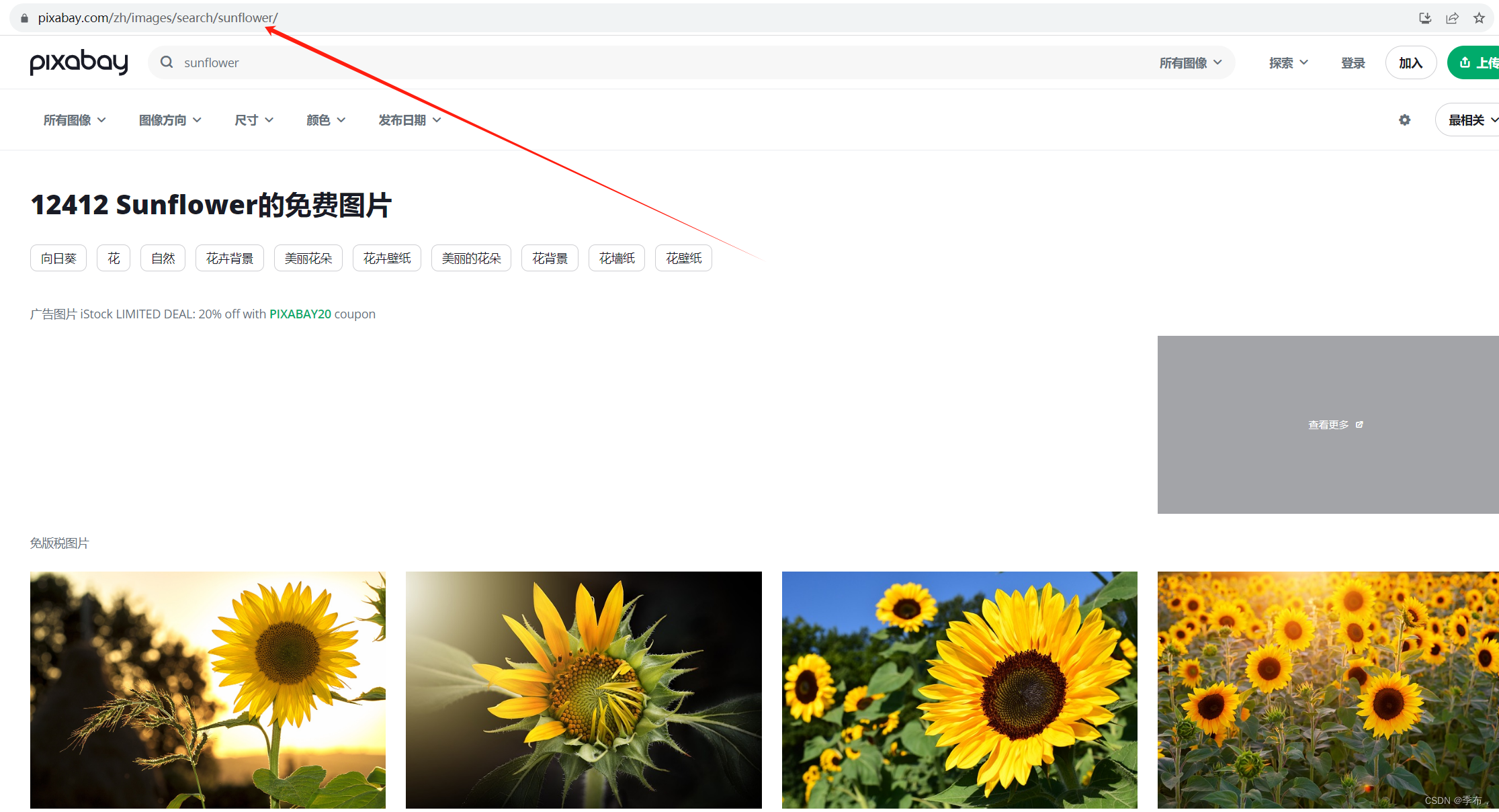
第二页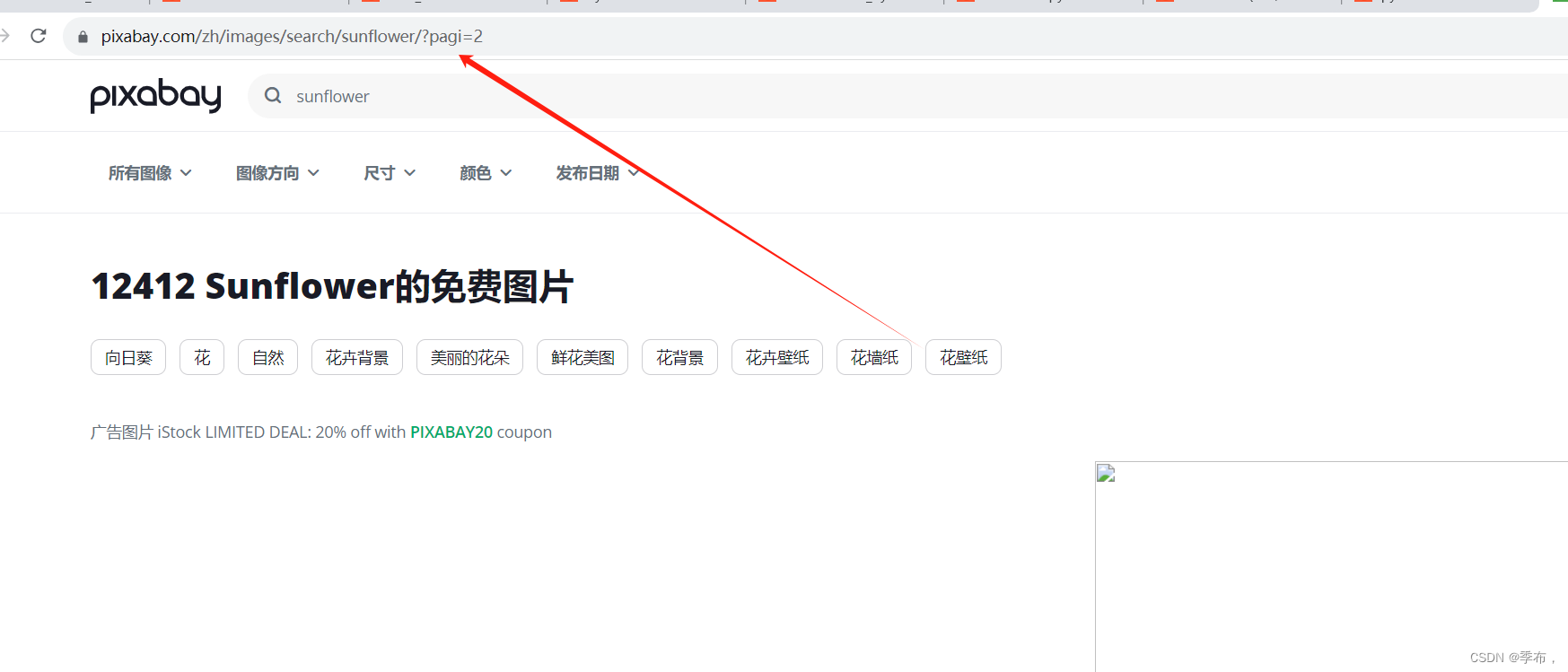
由此可得出变化的只有这里,根据pagi= 展示不同页面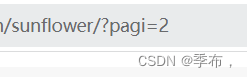
红色箭头定位到页数,绿色的不要使用 是反爬虫的限制,不断变化的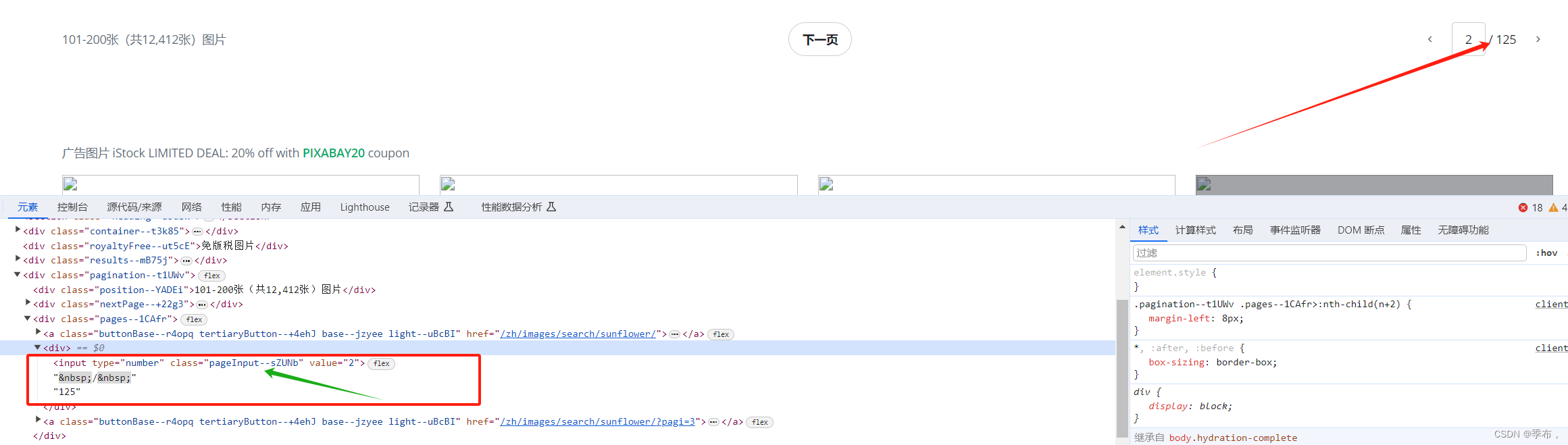
from os.path import dirname
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
classImageAutoSearchAndSave:"""图片自动搜索保存"""def__init__(self, keyword):"""初始化"""
self.keyword = keyword
self.driver = webdriver.Chrome(executable_path=dirname(__file__)+"/chromedriver.exe")defrun(self):"""开始运行"""print("=======开始=======")# 访问首页
self.driver.get("https://pixabay.com/")# 搜索图片
self._search_image()# 遍历所有页面
self._iter_all_page()print("=======结束=======")def_search_image(self):'''搜索图片'''
elem = self.driver.find_element_by_css_selector("input[name]")
elem.send_keys(self.keyword + Keys.ENTER)def_iter_all_page(self):'''遍历所有页面'''# 获取总页面
elem = self.driver.find_element_by_css_selector("input[class^=pageInput]")
page_total =int(elem.text.strip("/ "))# 遍历所有页面
base_url = self.driver.current_url
for page_num inrange(1,page_total+1):if page_num>1:
self.driver.get(f"{base_url}?pagi={page_num}&")if __name__ =='__main__':
keyword ="sunflower"
ImageAutoSearchAndSave(keyword).run()
获取所有图片详情页链接

from os.path import dirname
from lxml.etree import HTML
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
classImageAutoSearchAndSave:"""图片自动搜索保存"""def__init__(self, keyword):"""初始化"""
self.keyword = keyword
self.all_detail_link =[]
self.driver = webdriver.Chrome(executable_path=dirname(__file__)+"/chromedriver.exe")defrun(self):"""开始运行"""print("=======开始=======")# 访问首页
self.driver.get("https://pixabay.com/")# 搜索图片
self._search_image()# 遍历所有页面
self._iter_all_page()print("=======结束=======")def_search_image(self):'''搜索图片'''
elem = self.driver.find_element_by_css_selector("input[name]")
elem.send_keys(self.keyword + Keys.ENTER)def_iter_all_page(self):'''遍历所有页面'''# 获取总页面
elem = self.driver.find_element_by_css_selector("input[class^=pageInput]")
page_total =int(elem.text.strip("/ "))# 遍历所有页面
base_url = self.driver.current_url
for page_num inrange(1, page_total +1):if page_num >1:
self.driver.get(f"{base_url}?pagi={page_num}&")# href 属性
root = HTML(self.driver.page_source)# a标签中的href属性
detail_links = root.xpath("//div[start-with(@class,'result')]//a[start-with(@class,'link')]/@href")for detail_link in detail_links:
self.all_detail_link.append(detail_link)if __name__ =='__main__':
keyword ="sunflower"
ImageAutoSearchAndSave(keyword).run()
增加下载数量的限制

from os.path import dirname
from lxml.etree import HTML
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
classImageAutoSearchAndSave:"""图片自动搜索保存"""def__init__(self, keyword,limit=0):"""初始化"""
self.keyword = keyword
self.all_detail_link =[]
self.limit=limit #0表示没有限制
self.count =0#用来计数
self.driver = webdriver.Chrome(executable_path=dirname(__file__)+"/chromedriver.exe")defrun(self):"""开始运行"""print("=======开始=======")# 访问首页
self.driver.get("https://pixabay.com/")# 搜索图片
self._search_image()# 遍历所有页面
self._iter_all_page()print("=======结束=======")def_search_image(self):'''搜索图片'''
elem = self.driver.find_element_by_css_selector("input[name]")
elem.send_keys(self.keyword + Keys.ENTER)def_iter_all_page(self):'''遍历所有页面'''# 获取总页面
elem = self.driver.find_element_by_css_selector("input[class^=pageInput]")# page_total = int(elem.text.strip("/ "))
page_total =5# 遍历所有页面
base_url = self.driver.current_url
for page_num inrange(1, page_total +1):if page_num >1:
self.driver.get(f"{base_url}?pagi={page_num}&")# href 属性
root = HTML(self.driver.page_source)
is_reach_limit =False# 获取每一页详情链接 a标签中的href属性
detail_links = root.xpath("//div[start-with(@class,'result')]//a[start-with(@class,'link')]/@href")for detail_link in detail_links:
self.all_detail_link.append(detail_link)
self.count +=1if self.limit >0and self.count == self.limit:
is_reach_limit =Truebreakif is_reach_limit:breakif __name__ =='__main__':
keyword ="sunflower"
limit =3
ImageAutoSearchAndSave(keyword,limit).run()
获取所有图片详情、获取图片下载链接
from os.path import dirname
from lxml.etree import HTML
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
class ImageAutoSearchAndSave:"""图片自动搜索保存"""
def __init__(self, keyword, limit=0):"""初始化"""
self.keyword = keyword
self.all_detail_link =[]
self.limit = limit # 0表示没有限制
self.count =0 # 用来计数
self.all_download_link =[] # 图片详情的下载链接
self.driver = webdriver.Chrome(executable_path=dirname(__file__)+"/chromedriver.exe")
def run(self):"""开始运行"""
print("=======开始=======")
# 访问首页
self.driver.get("https://pixabay.com/")
# 搜索图片
self._search_image()
# 遍历所有页面
self._iter_all_page()
# 访问图片详情页
self._visit_image_detail()
# 释放资源
self.driver.close()
del self.all_detail_link
print("=======结束=======")
def _search_image(self):'''搜索图片'''
elem = self.driver.find_element_by_css_selector("input[name]")
elem.send_keys(self.keyword + Keys.ENTER)
def _iter_all_page(self):'''遍历所有页面'''
# 获取总页面
elem = self.driver.find_element_by_css_selector("input[class^=pageInput]")
# page_total =int(elem.text.strip("/ "))
page_total =5
# 遍历所有页面
base_url = self.driver.current_url
for page_num in range(1, page_total +1):if page_num >1:
self.driver.get(f"{base_url}?pagi={page_num}&")
# href 属性
root =HTML(self.driver.page_source)
is_reach_limit = False
# 获取每一页详情链接 a标签中的href属性
detail_links = root.xpath("//div[start-with(@class,'result')]//a[start-with(@class,'link')]/@href")for detail_link in detail_links:
self.all_detail_link.append(detail_link)
self.count +=1if self.limit >0 and self.count == self.limit:
is_reach_limit = True
breakif is_reach_limit:break
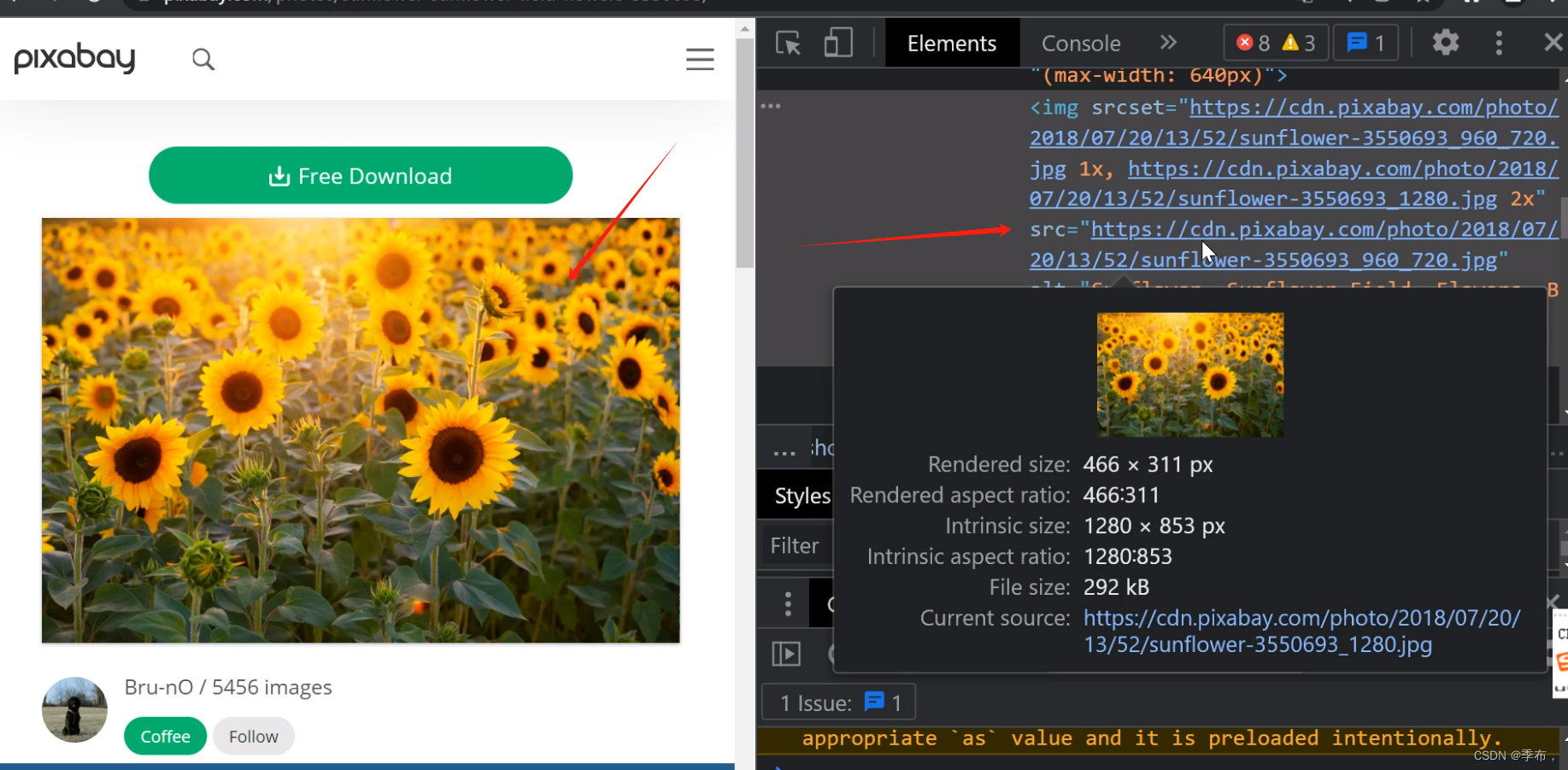
def _visit_image_detail(self):'''访问图片详情页'''for detail_link in self.all_detail_link:
self.driver.get(detail_link)
elem = self.driver.find_element_by_css_selector("#media_container > picture > img")
download_link = elem.get_attribute("src")
self.all_download_link.append(download_link)if __name__ =='__main__':
keyword ="sunflower"
limit =3ImageAutoSearchAndSave(keyword, limit).run()
下载所有图片
from io import BytesIO
from os import makedirs
from os.path import dirname
from time import strftime
import requests
from PIL import Image
from lxml.etree import HTML
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
class ImageAutoSearchAndSave:"""图片自动搜索保存"""
def __init__(self, keyword, limit=0):"""初始化"""
self._keyword = keyword
self.all_detail_link =[]
self._limit = limit # 0表示没有限制
self._count =0 # 用来计数
self.all_download_link =[] # 图片详情的下载链接
self._driver = webdriver.Chrome(executable_path=dirname(__file__)+"/chromedriver.exe")
def run(self):"""开始运行"""
print("=======开始=======")
# 访问首页
self._driver.get("https://pixabay.com/")
# 搜索图片
self._search_image()
# 遍历所有页面
self._iter_all_page()
# 访问图片详情页
self._visit_image_detail()
# 释放资源
self._driver.close()
del self.all_detail_link
# 下载所有图片
self._download_all_image()print("=======结束=======")
def _search_image(self):'''搜索图片'''
elem = self._driver.find_element_by_css_selector("input[name]")
elem.send_keys(self._keyword + Keys.ENTER)
def _iter_all_page(self):'''遍历所有页面'''
# 获取总页面
elem = self._driver.find_element_by_css_selector("input[class^=pageInput]")
# page_total =int(elem.text.strip("/ "))
page_total =5
# 遍历所有页面
base_url = self._driver.current_url
for page_num in range(1, page_total +1):if page_num >1:
self._driver.get(f"{base_url}?pagi={page_num}&")
# href 属性
root =HTML(self._driver.page_source)
is_reach_limit = False
# 获取每一页详情链接 a标签中的href属性
detail_links = root.xpath("//div[start-with(@class,'result')]//a[start-with(@class,'link')]/@href")for detail_link in detail_links:
self.all_detail_link.append(detail_link)
self._count +=1if self._limit >0 and self._count == self._limit:
is_reach_limit = True
breakif is_reach_limit:break
def _visit_image_detail(self):'''访问图片详情页 获取对应的图片链接'''
for detail_link in self.all_detail_link:
self._driver.get(detail_link)
elem = self._driver.find_element_by_css_selector("#media_container > picture > img")
download_link = elem.get_attribute("src")
self.all_download_link.append(download_link)
def _download_all_image(self):'''下载所有图片'''
download_dir = f"{dirname(__file__)}/download/{strftime('%Y%m%d-%H%M%S')}-{self._keyword}"makedirs(download_dir)
#下载所有图片
count =0for download_link in self.all_download_link:
response = requests.get(download_link)
count +=1
# response.content 二进制内容 response.text 文本内容
image = Image.open(BytesIO(response.content))
# rjust 000001.png
filename = f"{str(count).rjust(6,'0')}.png"
file_path = f"{download_dir}/{filename}"
image.save(file_path)if __name__ =='__main__':
keyword ="sunflower"
limit =3ImageAutoSearchAndSave(keyword, limit).run()
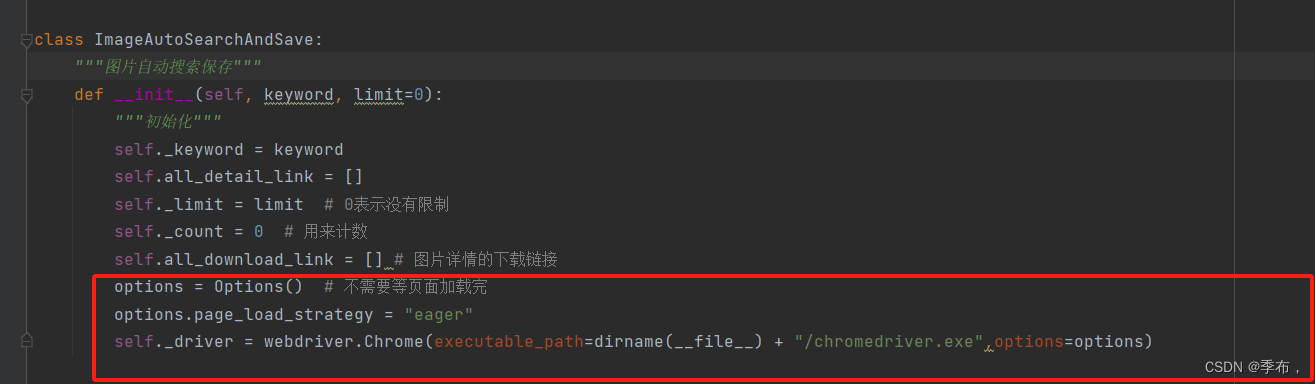
可以适当的进行优化,使用selnium的页面加载策略
本文转载自: https://blog.csdn.net/weixin_47906106/article/details/134639240
版权归原作者 季布, 所有, 如有侵权,请联系我们删除。
版权归原作者 季布, 所有, 如有侵权,请联系我们删除。