
双流连结(Join):根据某个字段的值将数据联结起来,“配对”去做处理
窗口联结(Window Join)
可以定义时间窗口,并将两条流中共享一个公共键(key)的数据放在窗口中进行配对处理
代码逻辑
首先需要调用 DataStream 的
.join()
方法来合并两条流,得到一个 JoinedStreams;接着通过
.where()
和
.equalTo()
方法指定两条流中联结的 key;然后通过
.window()
开窗口,并调用
.apply()
传入联结窗口函数进行处理计算
stream1.join(stream2)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(<WindowAssigner>)
.apply(<JoinFunction>)
对于
JoinFunction
:
public interface JoinFunction<IN1, IN2, OUT> extends Function, Serializable {
OUT join(IN1 first, IN2 second) throws Exception;
}
使用时需要实现内部的
join
方法,有两个参数,分别表示两条流中成对匹配的数据
JoinFunciton 并不是真正的“窗口函数”,它只是定义了窗口函数在调用时对匹配数据的具体处理逻辑
实现流程

两条流的数据到来之后,首先会按照 key 分组、进入对应的窗口中存储;当到达窗口结束时间时,算子会先统计出窗口内两条流的数据的所有组合,也就是对两条流中的数据做一个笛卡尔积(相当于表的交叉连接,cross join),然后进行遍历,把每一对匹配的数据,作为参数(first,second)传入 JoinFunction 的.join()方法进行计算处理。所以窗口中每有一对数据成功联结匹配,JoinFunction 的.join()方法就会被调用一次,并输出一个结果
实例分析
// 基于窗口的join
public class WindowJoinTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream<Tuple2<String, Long>> stream1 = env
.fromElements(
Tuple2.of("a", 1000L),
Tuple2.of("b", 1000L),
Tuple2.of("a", 2000L),
Tuple2.of("b", 2000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<Tuple2<String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> stringLongTuple2, long l) {
return stringLongTuple2.f1;
}
}
)
);
DataStream<Tuple2<String, Long>> stream2 = env
.fromElements(
Tuple2.of("a", 3000L),
Tuple2.of("b", 3000L),
Tuple2.of("a", 4000L),
Tuple2.of("b", 4000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<Tuple2<String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> stringLongTuple2, long l) {
return stringLongTuple2.f1;
}
}
)
);
stream1
.join(stream2)
.where(r -> r.f0)
.equalTo(r -> r.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new JoinFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() {
@Override
public String join(Tuple2<String, Long> left, Tuple2<String, Long> right) throws Exception {
return left + "=>" + right;
}
})
.print();
env.execute();
}
}
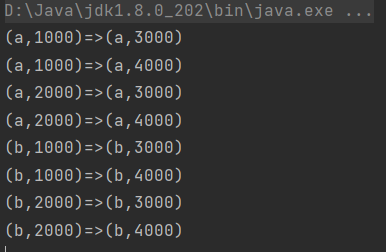
运行结果如下:
间隔联结(Interval Join)
统计一段时间内的数据匹配情况,不应该用滚动窗口或滑动窗口来处理——因为匹配的两个数据有可能刚好“卡在”窗口边缘两侧
因此需要采用”间隔联结“的操作,针对一条流的每个数据,开辟出其时间戳前后的一段时间间隔,看这期间是否有来自另一条流的数据匹配
原理
给定两个时间点,分别叫作间隔的“上界”(upperBound)和“下界”(lowerBound);
于是对于一条流(不妨叫作 A)中的任意一个数据元素 a,就可以开辟一段时间间隔:
[a.timestamp + lowerBound, a.timestamp + upperBound]
,即以 a 的时间戳为中心,下至下界点、上至上界点的一个闭区间:我们就把这段时间作为可以匹配另一条流数据的“窗口”范围
所以对于另一条流(不妨叫 B)中的数据元素 b,如果它的时间戳落在了这个区间范围内,a 和 b 就可以成功配对,进而进行计算输出结果
匹配条件为:
a.timestamp + lowerBound <= b.timestamp <= a.timestamp + upperBound
举例分析如下:

下方的流 A 去间隔联结上方的流 B,所以基于 A 的每个数据元素,都可以开辟一个间隔区间。我们这里设置下界为-2 毫秒,上界为 1 毫秒。于是对于时间戳为 2 的 A 中元素,它的可匹配区间就是[0, 3],流 B 中有时间戳为 0、1 的两个元素落在这个范围内,所以就可以得到匹配数据对(2, 0)和(2, 1)。同样地,A 中时间戳为 3 的元素,可匹配区间为[1, 4],B 中只有时间戳为 1 的一个数据可以匹配,于是得到匹配数据对(3, 1)
代码逻辑
基于KeyedStream进行联结操作:
①DataStream 通过 keyBy 得到KeyedStream
②调用
.intervalJoin()
来合并两条流,得到的是一个 IntervalJoin 类型
③通过
.between()
方法指定间隔的上下界,再调用
.process()
方法,定义对匹配数据对的处理操作
④调用
.process()
需要传入一个处理函数:
ProcessJoinFunction
stream1
.keyBy(<KeySelector>)
.intervalJoin(stream2.keyBy(<KeySelector>))
.between(Time.milliseconds(-2), Time.milliseconds(1))
.process (new ProcessJoinFunction<Integer, Integer, String(){
@Override
public void processElement(Integer left, Integer right, Context ctx, Collector<String> out) {
out.collect(left + "," + right);
}
});
实例分析
// 基于间隔的join
public class IntervalJoinTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
SingleOutputStreamOperator<Tuple3<String, String, Long>> orderStream = env.fromElements(
Tuple3.of("Mary", "order-1", 5000L),
Tuple3.of("Alice", "order-2", 5000L),
Tuple3.of("Bob", "order-3", 20000L),
Tuple3.of("Alice", "order-4", 20000L),
Tuple3.of("Cary", "order-5", 51000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Tuple3<String, String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Tuple3<String, String, Long>>() {
@Override
public long extractTimestamp(Tuple3<String, String, Long> element, long recordTimestamp) {
return element.f2;
}
})
);
SingleOutputStreamOperator<Event> clickStream = env.fromElements(
new Event("Bob", "./cart", 2000L),
new Event("Alice", "./prod?id=100", 3000L),
new Event("Alice", "./prod?id=200", 3500L),
new Event("Bob", "./prod?id=2", 2500L),
new Event("Alice", "./prod?id=300", 36000L),
new Event("Bob", "./home", 30000L),
new Event("Bob", "./prod?id=1", 23000L),
new Event("Bob", "./prod?id=3", 33000L)
).assignTimestampsAndWatermarks(WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner(new SerializableTimestampAssigner<Event>() {
@Override
public long extractTimestamp(Event element, long recordTimestamp) {
return element.timestamp;
}
})
);
orderStream.keyBy(data -> data.f0)
.intervalJoin(clickStream.keyBy(data -> data.user))
.between(Time.seconds(-5), Time.seconds(10))
.process(new ProcessJoinFunction<Tuple3<String, String, Long>, Event, String>() {
@Override
public void processElement(Tuple3<String, String, Long> left, Event right, Context ctx, Collector<String> out) throws Exception {
out.collect(right + " => " + left);
}
})
.print();
env.execute();
}}
运行结果如下:

窗口同组联结(Window CoGroup)
用法跟
window join
非常类似,也是将两条流合并之后开窗处理匹配的元素,调用时只需要将
.join()
换为
.coGroup()
就可以了
代码逻辑
stream1.coGroup(stream2)
.where(<KeySelector>)
.equalTo(<KeySelector>)
.window(TumblingEventTimeWindows.of(Time.hours(1)))
.apply(<CoGroupFunction>)
与 window join 的区别在于,调用.apply()方法定义具体操作时,传入的是一个
CoGroupFunction
:
public interface CoGroupFunction<IN1, IN2, O> extends Function, Serializable {
void coGroup(Iterable<IN1> first, Iterable<IN2> second, Collector<O> out) throws Exception;
}
coGroup
方法与
FlatJoinFunction
中
.join()
方法类似,其中的三个参数依旧是两条流中的数据以及用于输出的收集器;但前两个参数不再是单独的配对数据,而是可遍历的数据集合;
因此该方法中直接把收集到的所有数据一次性传入,然后自定义配对方式,不需要再计算窗口中两条流数据集的笛卡尔积;
实例分析
// 基于窗口的join
public class CoGroupTest {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStream<Tuple2<String, Long>> stream1 = env
.fromElements(
Tuple2.of("a", 1000L),
Tuple2.of("b", 1000L),
Tuple2.of("a", 2000L),
Tuple2.of("b", 2000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<Tuple2<String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> stringLongTuple2, long l) {
return stringLongTuple2.f1;
}
}
)
);
DataStream<Tuple2<String, Long>> stream2 = env
.fromElements(
Tuple2.of("a", 3000L),
Tuple2.of("b", 3000L),
Tuple2.of("a", 4000L),
Tuple2.of("b", 4000L)
)
.assignTimestampsAndWatermarks(
WatermarkStrategy
.<Tuple2<String, Long>>forMonotonousTimestamps()
.withTimestampAssigner(
new SerializableTimestampAssigner<Tuple2<String, Long>>() {
@Override
public long extractTimestamp(Tuple2<String, Long> stringLongTuple2, long l) {
return stringLongTuple2.f1;
}
}
)
);
stream1
.coGroup(stream2)
.where(r -> r.f0)
.equalTo(r -> r.f0)
.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.apply(new CoGroupFunction<Tuple2<String, Long>, Tuple2<String, Long>, String>() {
@Override
public void coGroup(Iterable<Tuple2<String, Long>> iter1, Iterable<Tuple2<String, Long>> iter2, Collector<String> collector) throws Exception {
collector.collect(iter1 + "=>" + iter2);
}
})
.print();
env.execute();
}
}
运行结果如下:

学习课程链接:【尚硅谷】Flink1.13实战教程(涵盖所有flink-Java知识点)_哔哩哔哩_bilibili
版权归原作者 THE WHY 所有, 如有侵权,请联系我们删除。