
文章目录
今天来和大家谈谈分布式锁的内容,在这个快速发展的经济时代,分布式锁也随之而发生。
分布式锁对应的也有
分布式事务,
链接如下:
https://blog.csdn.net/weixin_44797327/article/details/134611487?spm=1001.2014.3001.5502
分布式锁
0-1分布式锁–包含CAP理论模型
参考:文章-分布式锁
概述
随着互联网技术的不断发展,用户量的不断增加,越来越多的业务场景需要用到分布式系统。
分布式系统有一个著名的理论CAP,指在一个分布式系统中,最多只能同时满足下面三项中的两项:
一致性(Consistency):在分布式系统中的所有数据备份,在同一时刻是否同样的值(等同于所有节点访问同一份最新的数据副本)
可用性(Availability):保证每个请求不管成功或者失败都有响应
分区容错性(Partition****tolerance):系统中任意信息的丢失或失败不会影响系统的继续运作
所以在设计系统时,往往需要权衡,在CAP中作选择,要么AP,要么CP、要么AC。
当然,这个理论也并不一定完美,不同系统对CAP的要求级别不一样,选择需要考虑方方面面。
而在分布式系统中访问共享资源就需要一种互斥机制,来防止彼此之间的互相干扰,以保证一致性,这个时候就需要使用分布式锁。
分布式锁:
当在分布式模型下,数据只有一份(或有限的),此时需要利用锁技术来控制某一时刻修改数据的进程数。这种锁即为分布式锁。
为了保证一个方法或属性在高并发的情况下, 同一时间只能被同一个线程执行,在传统单体应用单机部署的情况下,可以使用并发处理相关的功能进行互斥控制。但是,随着业务发展的需要,原单体单机部署的系统被演化成分布式集群系统后,由于分布式系统多线程、多进程并且分布在不同机器上,这将使原单机部署情况下的并发控制锁策略失效,单纯的应用并不能提供分布式锁的能力。为了解决这个问题就需要一种跨机器的互斥机制来控制共享资源的访问,这就是分布式锁要解决的问题!
分布式锁应该具备哪些条件:
互斥性:在分布式系统环境下,一个方法在同一时间只能被一个机器的一个线程执行;
高可用的获取锁与释放锁;
高性能的获取锁与释放锁;
可重入性:具备可重入特性,具备锁失效机制,防止死锁,即就算一个客户端持有锁的期间崩溃而没有主动释放锁,也需要保证后续其他客户端能够加锁成功
非阻塞:具备非阻塞锁特性,即没有获取到锁将直接返回获取锁失败
分布式锁的业务场景:
互联网秒杀(商品库存)
抢优惠券
分布式锁的实现方式有:
主要有几种实现方式:
基于数据库实现
基于Zookeeper实现
基于Redis实现
如图: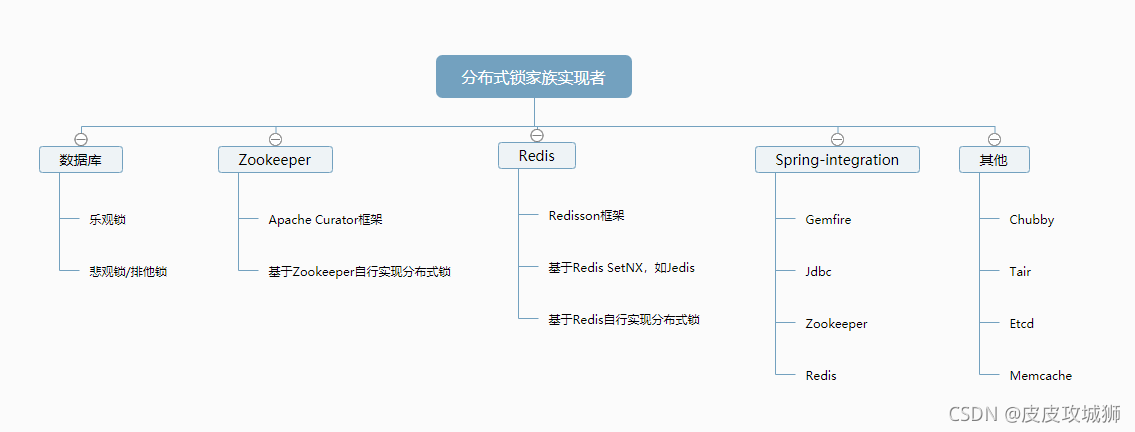
分布式锁对比
从理解的难易程度角度(从低到高):数据库 > 缓存 > Zookeeper
从实现的复杂性角度(从低到高):Zookeeper >= 缓存 > 数据库
从性能角度(从高到低):缓存 > Zookeeper >= 数据库
从可靠性角度(从高到低):Zookeeper > 缓存 > 数据库
基于Zookeeper - 分布式锁
实现思想
ZooKeeper是一个为分布式应用提供一致性服务的开源组件,它内部是一个分层的文件系统目录树结构,规定同一个目录下只能有一个唯一文件名。
基于ZooKeeper实现分布式锁的步骤如下:
创建一个目录mylock;
线程A想获取锁就在mylock目录下创建临时顺序节点;
获取mylock目录下所有的子节点,然后获取比自己小的兄弟节点,如果不存在,则说明当前线程顺序号最小,获得锁;
线程B获取所有节点,判断自己不是最小节点,设置监听比自己次小的节点;
线程A处理完,删除自己的节点,线程B监听到变更事件,判断自己是不是最小的节点,如果是则获得锁。
整个过程如图: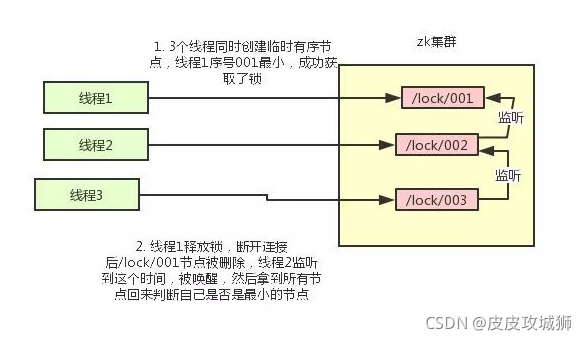
业界推荐直接使用Apache的开源库Curator,它是一个ZooKeeper客户端,Curator提供的InterProcessMutex是分布式锁的实现,acquire方法用于获取锁,release方法用于释放锁。
使用方式很简单:
InterProcessMutex interProcessMutex =newInterProcessMutex(client,"/anyLock");
interProcessMutex.acquire();
interProcessMutex.release();
其他分布式锁的核心源码如下:
privatebooleaninternalLockLoop(long startMillis,Long millisToWait,String ourPath)throwsException{boolean haveTheLock =false;boolean doDelete =false;try{if( revocable.get()!=null){
client.getData().usingWatcher(revocableWatcher).forPath(ourPath);}while((client.getState()==CuratorFrameworkState.STARTED)&&!haveTheLock ){// 获取当前所有节点排序后的集合 List<String> children =getSortedChildren();// 获取当前节点的名称 String sequenceNodeName = ourPath.substring(basePath.length()+1);// +1 to include the slash // 判断当前节点是否是最小的节点 PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);if( predicateResults.getsTheLock()){// 获取到锁
haveTheLock =true;}else{// 没获取到锁,对当前节点的上一个节点注册一个监听器 String previousSequencePath = basePath +"/"+ predicateResults.getPathToWatch();synchronized(this){Stat stat = client.checkExists().usingWatcher(watcher).forPath(previousSequencePath);if( stat !=null){if( millisToWait !=null){
millisToWait -=(System.currentTimeMillis()- startMillis);
startMillis =System.currentTimeMillis();if( millisToWait <=0){
doDelete =true;// timed out - delete our node break;}wait(millisToWait);}else{wait();}}}// else it may have been deleted (i.e. lock released). Try to acquire again }}}catch(Exception e ){
doDelete =true;throw e;}finally{if( doDelete ){deleteOurPath(ourPath);}}return haveTheLock;}
其实 Curator 实现分布式锁的底层原理和上面分析的是差不多的。如图详细描述其原理: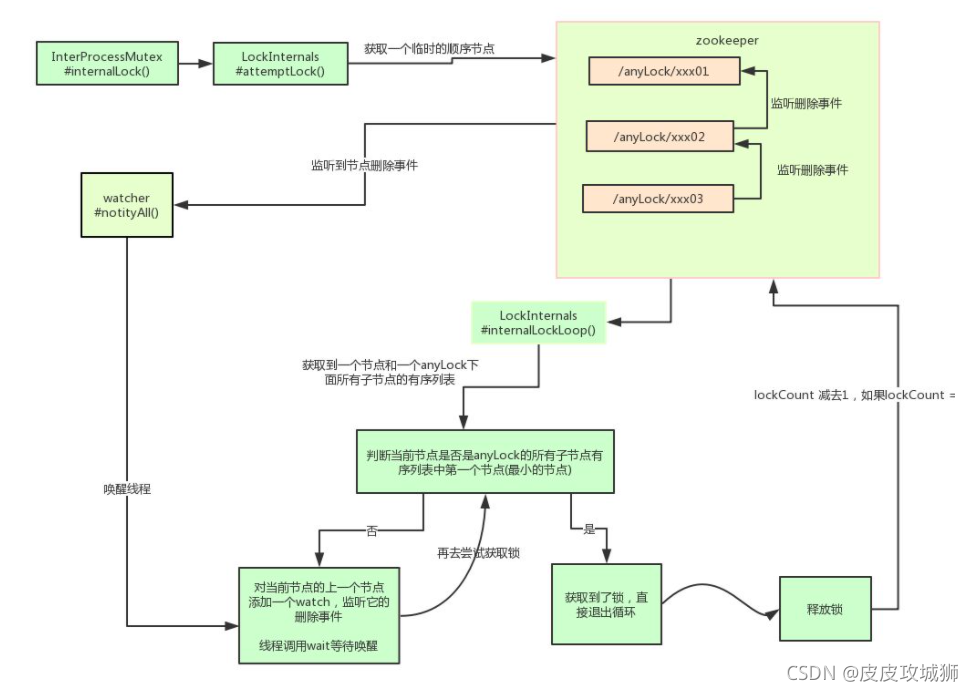
另外,可基于Zookeeper自身的特性和原生Zookeeper API自行实现分布式锁。
优缺点
优点:
可靠性非常高
性能较好
CAP模型属于CP,基于ZAB一致性算法实现
**缺点: **
性能并不如Redis(主要原因是在写操作,即获取锁释放锁都需要在Leader上执行,然后同步到follower)
实现复杂度高
基于Redis - 分布式锁

实现思想
主要是基于命令:
SETNX key value
命令官方文档:https://redis.io/commands/setnx
用法可参考:Redis命令参考
如图:
实现思想的具体步骤:
获取锁的时候,使用setnx加锁,并使用expire命令为锁添加一个超时时间,超过该时间则自动释放锁,锁的value值为一个随机生成的UUID,通过此处释放锁的时候进行判断。
获取锁的时候还设置一个获取的超时时间,若超过这个时间则放弃获取锁。
释放锁的时候,通过UUID判断是不是该锁,若是该锁,则执行delete进行锁释放。
优缺点
优点:
- 性能非常高
- 可靠性较高
- CAP模型属于AP
缺点:
- 复杂度较高
- 无一致性算法,可靠性并不如Zookeeper
- 锁删除失败 过期时间不好控制
- 非阻塞,获取失败后,需要轮询不断尝试获取锁,比较消耗性能,占用cpu资源
Redis分布式锁实现-例子
以减库存接口为例子,访问接口的时候自动减商品的库存
方案(一)
@ServicepublicclassRedisLockDemo{@AutowiredprivateStringRedisTemplate redisTemplate;publicStringdeduceStock(){ValueOperations<String,String> valueOperations = redisTemplate.opsForValue();//获取redis中的库存int stock =Integer.valueOf(valueOperations.get("stock"));if(stock >0){int newStock = stock -1;
valueOperations.set("stock", newStock +"");System.out.println("扣减库存成功, 剩余库存:"+ newStock);}else{System.out.println("库存已经为0,不能继续扣减");}return"success";}}
表示:
- 先从Redis中读取stock的值,表示商品的库存
- 判断商品库存是否大于0,如果大于0,则库存减1,然后再保存到Redis里面去,否则就报错
改进 方案(一) :
这种简单的从Redis读取、判断值再减1保存到Redis的操作,很容易在并发场景下出问题:
- 商品超卖
比如:
假设商品的库存有50个,有3个用户同时访问该接口,先是同时读取Redis中商品的库存值,即都是读取到了50,即同时执行到了这一行:
int stock =Integer.valueOf(valueOperations.get("stock"));
然后减1,即到了这一行:
int newStock = stock -1;
此时3个用户的realStock都是49,然后3个用户都去设置stock为49,那么就会产生库存明明被3个用户抢了,理论上是应该减去3的,结果库存数只减去了1导致商品超卖。
这种问题的产生原因是因为读取库存、减库存、保存到Redis这几步并不是原子操作
那么可以使用加并发锁synchronized来解决:
@ServicepublicclassRedisLockDemo{@AutowiredprivateStringRedisTemplate redisTemplate;publicStringdeduceStock(){ValueOperations<String,String> valueOperations = redisTemplate.opsForValue();synchronized(this){//获取redis中的库存int stock =Integer.valueOf(valueOperations.get("stock"));if(stock >0){int newStock = stock -1;
valueOperations.set("stock", newStock +"");System.out.println("扣减库存成功, 剩余库存:"+ newStock);}else{System.out.println("库存已经为0,不能继续扣减");}}return"success";}}
注意:在Java中关键字synchronized可以保证在同一时刻,只有一个线程可以执行某个方法或某个代码块。
再改进 方案(一)
以上的代码在单体模式下并没太大问题,但是在分布式或集群架构环境下存在问题,比如架构如下: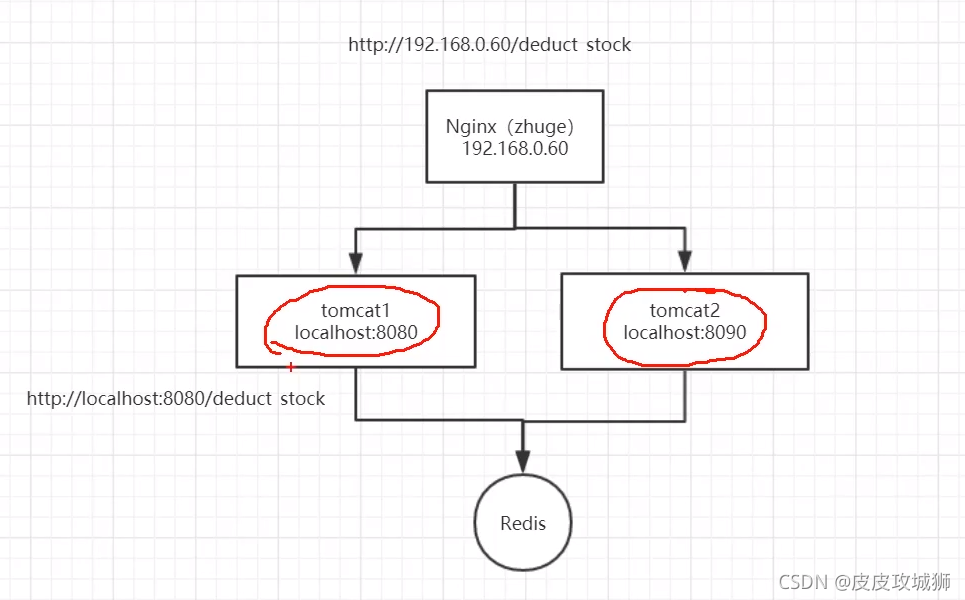
在分布式或集群架构下,synchronized只能保证当前的主机在同一时刻只能有一个线程执行减库存操作,但如图同时有多个请求过来访问的时候,不同主机在同一时刻依然是可以访问减库存接口的,这就导致问题1(商品超卖)在集群架构下依然存在。
解决方法
使用如下方案(二)的分布式锁进行解决; 注意:方案(一)并不是分布式锁
方案(二)
分布式锁的简单实现图如下:
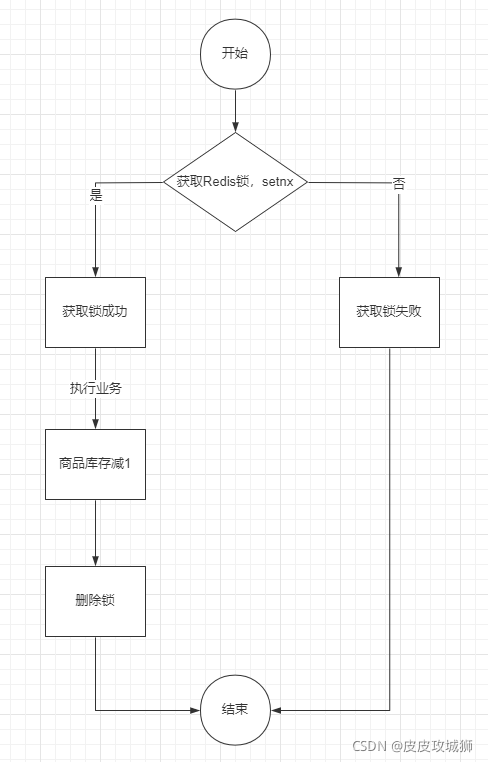
简单的实现代码如下:
@ServicepublicclassRedisLockDemo{@AutowiredprivateStringRedisTemplate redisTemplate;publicStringdeduceStock(){ValueOperations<String,String> valueOperations = redisTemplate.opsForValue();String lockKey ="product_001";//加锁: setnxBoolean isSuccess = valueOperations.setIfAbsent(lockKey,"1");if(null== isSuccess || isSuccess){System.out.println("服务器繁忙, 请稍后重试");return"error";}//------ 执行业务逻辑 ----start------int stock =Integer.valueOf(valueOperations.get("stock"));if(stock >0){int newStock = stock -1;//执行业务操作减库存
valueOperations.set("stock", newStock +"");System.out.println("扣减库存成功, 剩余库存:"+ newStock);}else{System.out.println("库存已经为0,不能继续扣减");}//------ 执行业务逻辑 ----end------//释放锁
redisTemplate.delete(lockKey);return"success";}}
其实就是对每一个商品加一把锁,代码里面是product_001
- 使用setnx对商品进行加锁
- 如成功说明加锁成功,如失败说明有其他请求抢占了该商品的锁,则当前请求失败退出
- 加锁成功之后进行扣减库存操作
- 删除商品锁
以上的代码方式是有可能会造成死锁的,比如说加锁成功之后,扣减库存的逻辑可能抛异常了,即并不会执行到释放锁的逻辑,那么该商品锁是一直没有释放,会成为死锁的,其他请求完全无法扣减该商品的
使用
try...catch...finally
的方式可以解决抛异常的问题,如下:
@ServicepublicclassRedisLockDemo{@AutowiredprivateStringRedisTemplate redisTemplate;publicStringdeduceStock(){ValueOperations<String,String> valueOperations = redisTemplate.opsForValue();String lockKey ="product_001";try{//加锁: setnxBoolean isSuccess = valueOperations.setIfAbsent(lockKey,"1");if(null== isSuccess || isSuccess){System.out.println("服务器繁忙, 请稍后重试");return"error";}//------ 执行业务逻辑 ----start------int stock =Integer.valueOf(valueOperations.get("stock"));if(stock >0){int newStock = stock -1;//执行业务操作减库存
valueOperations.set("stock", newStock +"");System.out.println("扣减库存成功, 剩余库存:"+ newStock);}else{System.out.println("库存已经为0,不能继续扣减");}//------ 执行业务逻辑 ----end------}finally{//释放锁
redisTemplate.delete(lockKey);}return"success";}}
改进方案(二)
那么上面的方式是不是能够解决死锁的问题呢?
其实不然,除了抛异常之外,比如程序崩溃、服务器宕机、服务器重启、请求超时被终止、发布、人为kill等都有可能导致释放锁的逻辑没有执行,比如对商品加分布式锁成功之后,在扣减库存的时候服务器正在执行重启,会导致没有执行释放锁。
可以通过对锁设置超时时间来防止死锁的发生,使用Redis的expire命令可以对key进行设置超时时间,如图: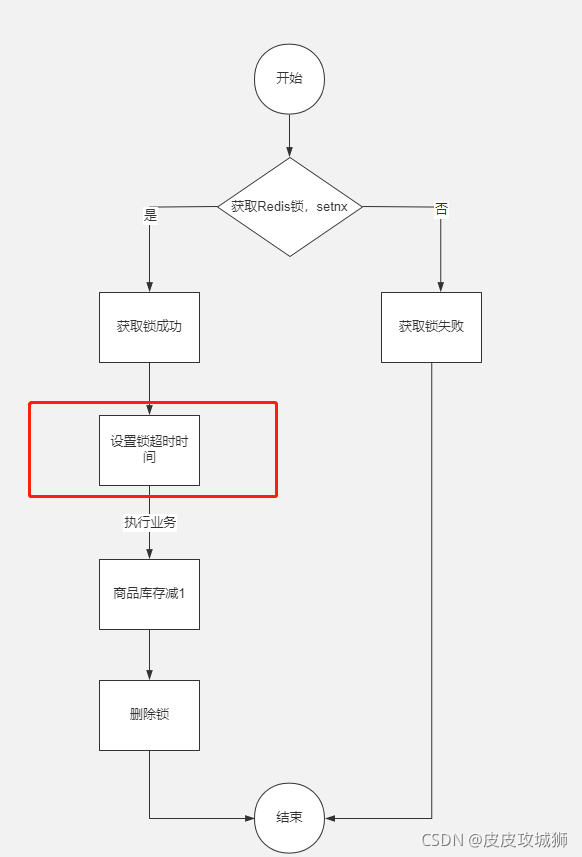
代码实现如下:
@ServicepublicclassRedisLockDemo{@AutowiredprivateStringRedisTemplate redisTemplate;publicStringdeduceStock(){ValueOperations<String,String> valueOperations = redisTemplate.opsForValue();String lockKey ="product_001";try{//加锁: setnxBoolean isSuccess = valueOperations.setIfAbsent(lockKey,"1");//expire增加超时时间
redisTemplate.expire(lockKey,10,TimeUnit.SECONDS);if(null== isSuccess || isSuccess){System.out.println("服务器繁忙, 请稍后重试");return"error";}//------ 执行业务逻辑 ----start------int stock =Integer.valueOf(valueOperations.get("stock"));if(stock >0){int newStock = stock -1;//执行业务操作减库存
valueOperations.set("stock", newStock +"");System.out.println("扣减库存成功, 剩余库存:"+ newStock);}else{System.out.println("库存已经为0,不能继续扣减");}//------ 执行业务逻辑 ----end------}finally{//释放锁
redisTemplate.delete(lockKey);}return"success";}}
加锁成功之后,把锁的超时时间设置为10秒,即10秒之后自动会释放锁,避免死锁的发生。
再改进方案(二)
但是上面的方式同样会产生死锁问题,加锁和对锁设置超时时间并不是原子操作,在加锁成功之后,即将执行设置超时时间的时候系统发生崩溃,同样还是会导致死锁。
改进图案如下:
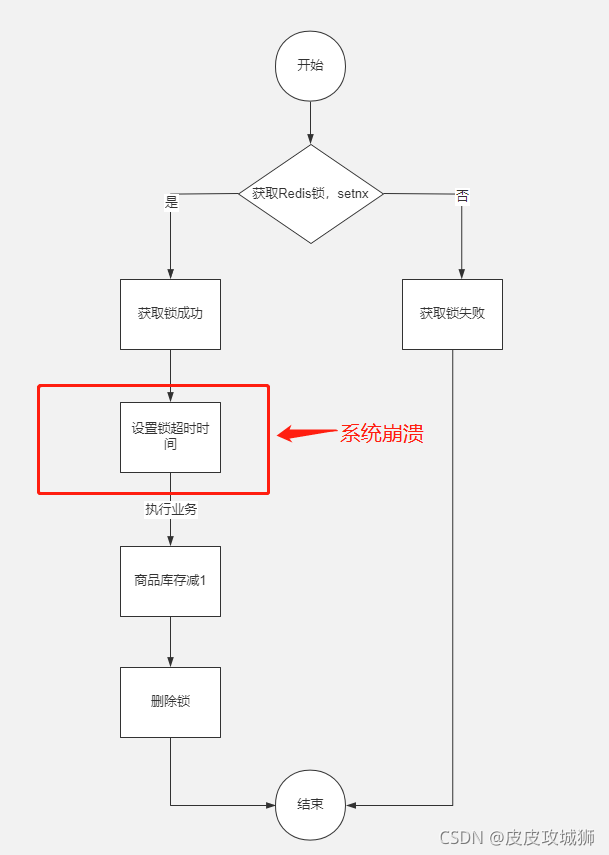
对此,有两种做法:
lua脚本
set原生命令(Redis 2.6.12版本及以上)
一般是推荐使用set命令,Redis官方在2.6.12版本对set命令增加了NX、EX、PX等参数,即可以将上面的加锁和设置时间放到一条命令上执行,通过set命令即可:
命令官方文档:https://redis.io/commands/set
用法可参考:Redis命令参考
如图:
SET key value NX 等同于 SETNX key value命令,并且可以使用EX参数来设置过期时间
注意:其实目前在Redis 2.6.12版本之后,所说的setnx命令,并非单单指Redis的SETNX key value命令,一般是代指Redis中对set命令加上nx参数进行使用,一般不会直接使用SETNX key value命令了
注意:Redis2.6.12之前的版本,只能通过lua脚本来保证原子性了。
如图: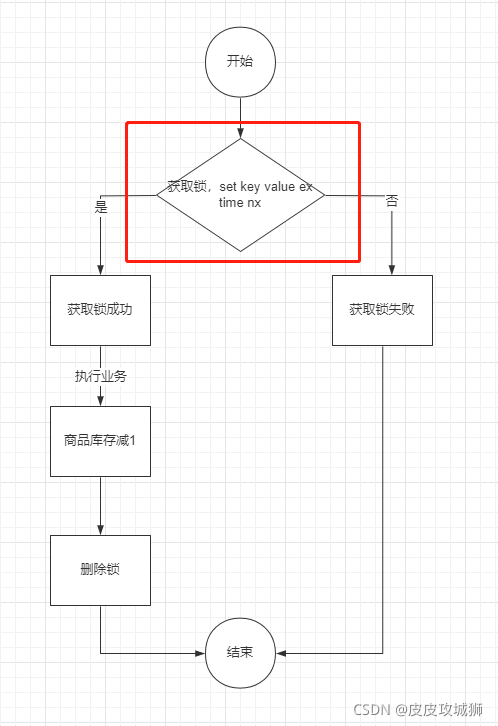
@ServicepublicclassRedisLockDemo{@AutowiredprivateStringRedisTemplate redisTemplate;publicStringdeduceStock(){ValueOperations<String,String> valueOperations = redisTemplate.opsForValue();String lockKey ="product_001";try{//加锁: setnx 和 expire增加超时时间Boolean isSuccess = valueOperations.setIfAbsent(lockKey,"1",10,TimeUnit.SECONDS);if(null== isSuccess || isSuccess){System.out.println("服务器繁忙, 请稍后重试");return"error";}//------ 执行业务逻辑 ----start------int stock =Integer.valueOf(valueOperations.get("stock"));if(stock >0){int newStock = stock -1;//执行业务操作减库存
valueOperations.set("stock", newStock +"");System.out.println("扣减库存成功, 剩余库存:"+ newStock);}else{System.out.println("库存已经为0,不能继续扣减");}//------ 执行业务逻辑 ----end------}finally{//释放锁
redisTemplate.delete(lockKey);}return"success";}}
再再次改进 方案(二)
以上的方式其实还是存在着问题,在高并发场景下会存在问题,超时时间设置不合理导致的问题
大概的流程图可参考:
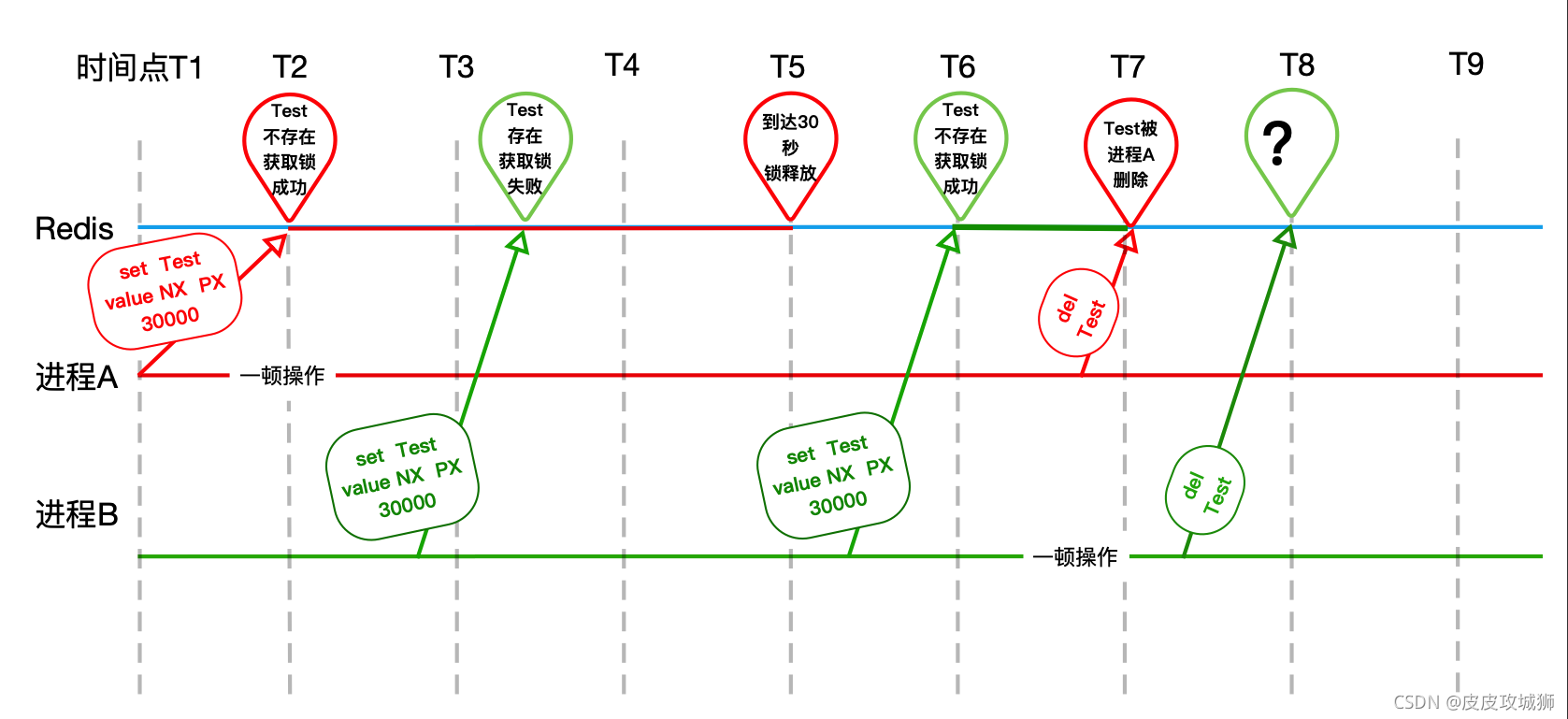
流程:
- 进程A加锁之后,扣减库存的时间超过设置的超时时间,这里设置的锁是10秒
- 在第10秒的时候由于时间到期了所以进程A设置的锁被Redis释放了(T5)
- 刚好进程B请求进来了,加锁成功(T6)
- 进程A操作完成(扣减库存)之后,把进程B设置的锁给释放了
- 刚好进程C请求进来了,加锁成功 进程B操作完成之后,也把进程C设置的锁给释放了
- 以此类推…
解决方法也很简单:
- 加锁的时候,把值设置为唯一值,比如说UUID这种随机数
- 释放锁的时候,获取锁的值判断value是不是当前进程设置的唯一值,如果是再去删除
如图: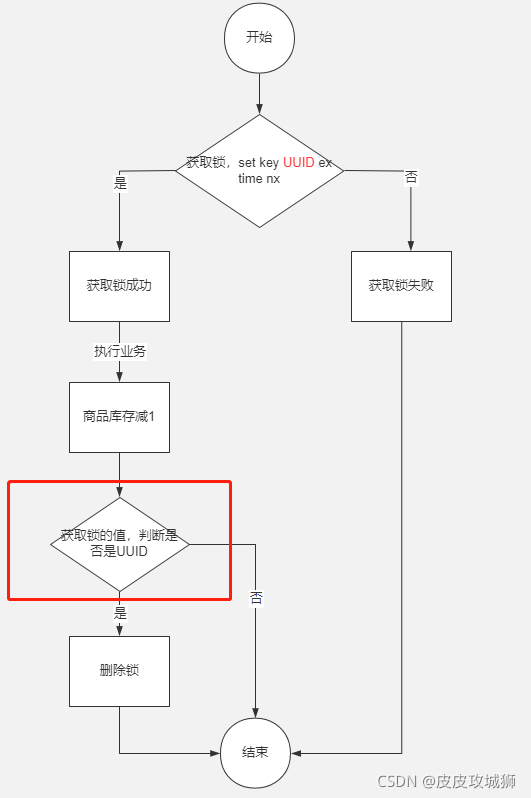
实现的代码如下:
@ServicepublicclassRedisLockDemo{@AutowiredprivateStringRedisTemplate redisTemplate;publicStringdeduceStock(){ValueOperations<String,String> valueOperations = redisTemplate.opsForValue();String lockKey ="product_001";String clientId =UUID.randomUUID().toString();try{//加锁: setnx 和 expire增加超时时间Boolean isSuccess = valueOperations.setIfAbsent(lockKey, clientId,10,TimeUnit.SECONDS);if(null== isSuccess || isSuccess){System.out.println("服务器繁忙, 请稍后重试");return"error";}//------ 执行业务逻辑 ----start------int stock =Integer.valueOf(valueOperations.get("stock"));if(stock >0){int newStock = stock -1;//执行业务操作减库存
valueOperations.set("stock", newStock +"");System.out.println("扣减库存成功, 剩余库存:"+ newStock);}else{System.out.println("库存已经为0,不能继续扣减");}//------ 执行业务逻辑 ----end------}finally{if(clientId.equals(valueOperations.get(lockKey))){//释放锁
redisTemplate.delete(lockKey);}}return"success";}}
分段锁
怎么在高并发的场景去实现一个高性能的分布式锁呢?
电商网站在大促的时候并发量很大:
(1)若抢购不是同一个商品,则可以增加Redis集群的cluster来实现,因为不是同一个商品,所以通过计算 key 的hash会落到不同的 cluster上;
(2)若抢购的是同一个商品,则计算key的hash值会落同一个cluster上,所以加机器也是没有用的。
针对第二个问题,可以使用库存分段锁的方式去实现。
分段锁
假如产品1有200个库存,可以将这200个库存分为10个段存储(每段20个),每段存储到一个cluster上;将key使用hash计算,使这些key最后落在不同的cluster上。
每个下单请求锁了一个库存分段,然后在业务逻辑里面,就对数据库或者是Redis中的那个分段库存进行操作即可,包括查库存 -> 判断库存是否充足 -> 扣减库存。
具体可以参照 ConcurrentHashMap 的源码去实现,它使用的就是分段锁。
高性能分布式锁具体可参考链接:每秒上千订单场景下的分布式锁高并发优化实践!【石杉的架构笔记】
原理如图: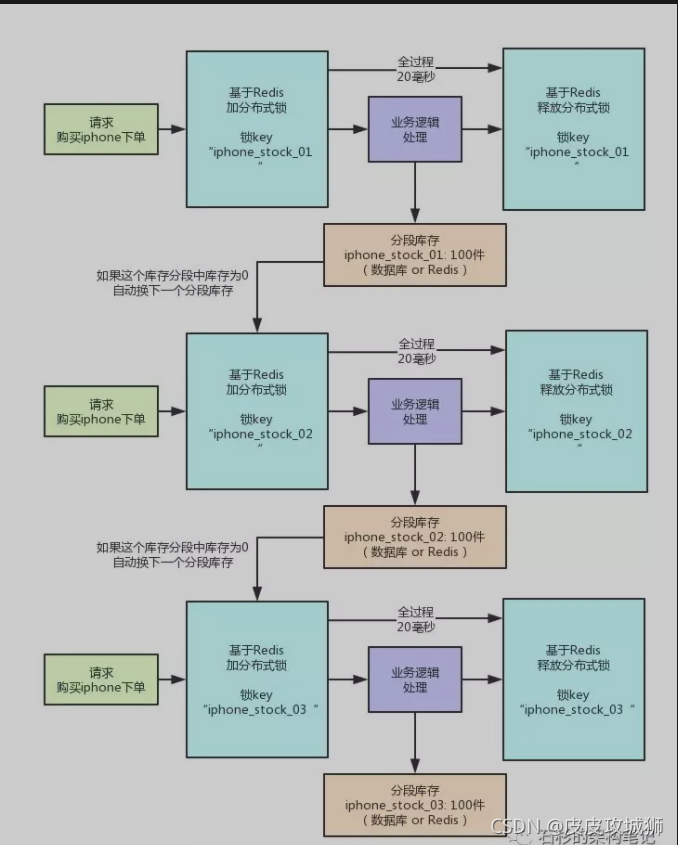
基于数据库 - 分布式锁
实现思想
主要有两种方式:
悲观锁
乐观锁
A. 悲观锁(排他锁)
利用select * form table where xx=yy for update 排他锁
注意:这里需要注意的是 where xx=yy,xx字段必须要走索引,否则会锁表。有些情况下,比如表不大,mysql优化器会不走这个索引,导致锁表问题。
核心思想:以「悲观的心态」操作资源,无法获得锁成功,就一直阻塞着等待。
注意:该方式有很多缺陷,一般不建议使用。
实现:
创建一张资源锁表:
CREATETABLE`resource_lock`(`id`int(4)NOTNULLAUTO_INCREMENTCOMMENT'主键',`resource_name`varchar(64)NOTNULLDEFAULT''COMMENT'锁定的资源名',`owner`varchar(64)NOTNULLDEFAULT''COMMENT'锁拥有者',`desc`varchar(1024)NOTNULLDEFAULT'备注信息',`update_time`timestampNOTNULLDEFAULT''COMMENT'保存数据时间,自动生成',PRIMARYKEY(`id`),UNIQUEKEY`uidx_resource_name`(`resource_name `)USINGBTREE)ENGINE=InnoDBDEFAULTCHARSET=utf8 COMMENT='锁定中的资源';
注意:resource_name 锁资源名称必须有唯一索引
使用事务查询更新:
@Transactionpublic void lock(String name) {
ResourceLock rlock = exeSql("select * from resource_lock where resource_name = name for update");if(rlock ==null) {
exeSql("insert into resource_lock(reosurce_name,owner,count) values (name, 'ip',0)");
}
}
使用 for update 锁定的资源 :
如果执行成功,会立即返回,执行插入数据库,后续再执行一些其他业务逻辑,直到事务提交,执行结束;
如果执行失败,就会一直阻塞着。
可以在数据库客户端工具上测试出来这个效果,当在一个终端执行了 for update,不提交事务。在另外的终端上执行相同条件的 for update,会一直卡着
虽然也能实现分布式锁的效果,但是会存在性能瓶颈。
优点:
简单易用,好理解,保障数据强一致性。
缺点:
1)在 RR 事务级别,select 的 for update 操作是基于间隙锁(gap lock) 实现的,是一种悲观锁的实现方式,所以存在阻塞问题。
2)高并发情况下,大量请求进来,会导致大部分请求进行排队,影响数据库稳定性,也会耗费服务的CPU等资源。
当获得锁的客户端等待时间过长时,会提示:
[40001][1205] Lock wait timeout exceeded; try restarting transaction
高并发情况下,也会造成占用过多的应用线程,导致业务无法正常响应。
3)如果优先获得锁的线程因为某些原因,一直没有释放掉锁,可能会导致死锁的发生。
4)锁的长时间不释放,会一直占用数据库连接,可能会将数据库连接池撑爆,影响其他服务。
5)MySql数据库会做查询优化,即便使用了索引,优化时发现全表扫效率更高,则可能会将行锁升级为表锁,此时可能就更悲剧了。
6)不支持可重入特性,并且超时等待时间是全局的,不能随便改动。
B. 乐观锁
所谓乐观锁与悲观锁最大区别在于基于 CAS思想 ,表中添加一个时间戳或者是版本号的字段来实现,update xx set version=new_version where xx=yy and version=Old_version,通过增加递增的版本号字段实现乐观锁。
不具有互斥性,不会产生锁等待而消耗资源,操作过程中认为不存在并发冲突,只有update version失败后才能觉察到。
抢购、秒杀就是用了这种实现以防止超卖的现象。
实现:
创建一张资源锁表:
CREATETABLE`resource`(`id`int(4)NOTNULLAUTO_INCREMENTCOMMENT'主键',`resource_name`varchar(64)NOTNULLDEFAULT''COMMENT'资源名',`share`varchar(64)NOTNULLDEFAULT''COMMENT'状态',`version`int(4)NOTNULLDEFAULT''COMMENT'版本号',`desc`varchar(1024)NOTNULLDEFAULT'备注信息',`update_time`timestampNOTNULLDEFAULT''COMMENT'保存数据时间,自动生成',PRIMARYKEY(`id`),UNIQUEKEY`uidx_resource_name`(`resource_name `)USINGBTREE)ENGINE=InnoDBDEFAULTCHARSET=utf8 COMMENT='资源';
为表添加一个字段,版本号或者时间戳都可以。通过版本号或者时间戳,来保证多线程同时间操作共享资源的有序性和正确性。
伪代码实现:
Resrouce resource = exeSql("select * from resource where resource_name = xxx");boolean succ = exeSql("update resource set version= 'newVersion' ... where resource_name = xxx and version = 'oldVersion'");if(!succ) {
// 发起重试
}
实际代码中可以写个while循环不断重试,版本号不一致,更新失败,重新获取新的版本号,直到更新成功。
优缺点
优点:
实现简单,复杂度低
保障数据一致性
缺点:
性能低,并且有锁表的风险
可靠性差
非阻塞操作失败后,需要轮询,占用CPU资源
长时间不commit或者是长时间轮询,可能会占用较多的连接资源
版权归原作者 皮皮攻城狮 所有, 如有侵权,请联系我们删除。