
文章目录
⛳️ 实战场景
上一篇博客我们首次接触年轻的自动化模块
playwright
,惊讶于其代码录制功能,今天咱们接着学习一下,其 API 相关知识。
正式学习前,先把基础示例代码呈现给大家。
from playwright.sync_api import sync_playwright
with sync_playwright()as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("http://example.com")print(page.title())
browser.close()
注意上述代码使用的不是无头浏览器,运行代码得到请求站点的标题,下面继续对代码进行扩展。
⛳️ 实现浏览器截图
通过浏览器打开站点之后,可以对网页默认展示区域进行截图操作,代码如下:
from playwright.sync_api import sync_playwright
with sync_playwright()as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
page.goto("http://example.com")
page.screenshot(path="example.png")
browser.close()
在运行目录生成如下图片: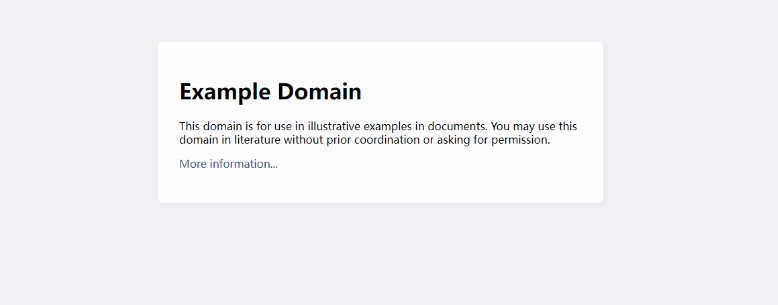
⛳️ 将截图代码优化为异步模式
上述截图代码为同步模式,可以进行简单的修改,从而调整为异步模式。
import asyncio
from playwright.async_api import async_playwright
asyncdefmain():asyncwith async_playwright()as p:
browser =await p.chromium.launch(headless=False)
page =await browser.new_page()await page.goto('http://example.com')await page.screenshot(path='example.png')await browser.close()
asyncio.get_event_loop().run_until_complete(main())
这里一定要注意
async_playwright
和
sync_playwright
导入模式,互联网很多博客这里都写错误,也不知道他们的代码是怎么运行起来的,对比代码如下所示:
from playwright.async_api import async_playwright # 异步导入from playwright.sync_api import sync_playwright # 同步导入
⛳️ 模拟手机端访问
模拟手机操作用到的核心方法如下所示:
p.devices[phone_name]:选择设备名,可以从谷歌浏览器的开发者工具中进行选择,截图在代码后。browser.new_context():初始化浏览器的时候,可以进行参数配置。
from playwright.sync_api import sync_playwright # 同步导入with sync_playwright()as p:
phone_name ='iPhone 13'
iphone_13 = p.devices[phone_name]
browser = p.webkit.launch(headless=False)
context = browser.new_context(**iphone_13,
locale='zh-CN')
page = context.new_page()
page.goto('https://baidu.com')
page.screenshot(path=f'{phone_name}.png')# browser.close()
可以选择的设备名称(包含但不限于!)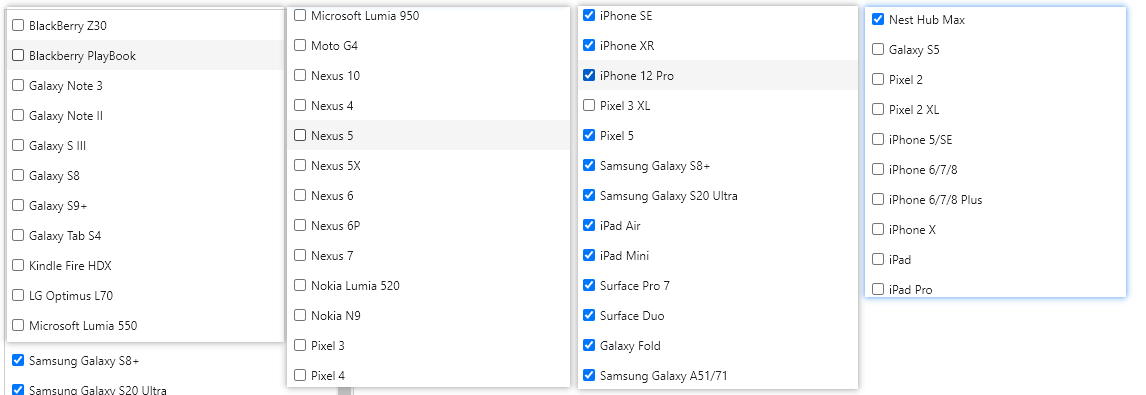
运行上述代码,可以模拟手机访问效果。
本篇博客最后补充的知识点是
browser.new_context()
方法的详细参数说明(全网首发)。
accept_downloads:布尔类型,是否自动下载所有附件,默认为True;base_url:根路径,这个参数要配合goto(),route()方法使用;bypass_csp:布尔类型,跨域攻击配置;device_scale_factor:设备比例基数,默认是1.0;extra_http_headers:字典对象,每个请求发送的附加 HTTP 头的对象;geolocation:地理位置,字典格式,包含经纬度,以及精度;ignore_https_errors:发送网络请求时是否忽略 HTTPS 错误;is_mobile:是否考虑 meta-viewport 标记并启用触摸事件,不支持火狐;java_script_enabled:是否支持 JS;locale:指定用户区域设置;no_viewport:不强制固定窗口,允许在标题模式下调整窗口大小;offline:是否离线模式;proxy:代理设置;storage_state:用户状态设置,例如cookies,origins。user_agent:用户代理设置;viewport:窗口大小,默认 1280*720,也可以通过字典设置宽度和高度。
📢📢📢📢📢📢
💗 你正在阅读 【梦想橡皮擦】 的博客
👍 阅读完毕,可以点点小手赞一下
🌻 发现错误,直接评论区中指正吧
📆 橡皮擦的第 730 篇原创博客
从订购之日起,案例 5 年内保证更新
- ⭐️ Python 爬虫 120,点击订购 ⭐️
- ⭐️ 爬虫 100 例教程,点击订购 ⭐️
本文转载自: https://blog.csdn.net/hihell/article/details/127187899
版权归原作者 梦想橡皮擦 所有, 如有侵权,请联系我们删除。
版权归原作者 梦想橡皮擦 所有, 如有侵权,请联系我们删除。