
DCGAN理论讲解
DCGAN也叫深度卷积生成对抗网络,DCGAN就是将CNN与GAN结合在一起,生成模型和判别模型都运用了深度卷积神经网络的生成对抗网络。
DCGAN将GAN与CNN相结合,奠定了之后几乎所有GAN的基本网络架构。DCGAN极大地提升了原始GAN训练的稳定性以及生成结果的质量
DCGAN主要是在网络架构上改进了原始的GAN,DCGAN的生成器与判别器都利用CNN架构替换了原始GAN的全连接网络,主要改进之处有如下几个方面,
DCGAN的改进:
(1)DCGAN的生成器和判别器都舍弃了CNN的池化层,判别器保留CNN的整体架构,生成器则是将卷积层替换成了反卷积层。
(2)在判别器和生成器中使用了BatchNormalization(BN)层,这里有助于处理初始化不良导致的训练问题,加速模型训练提升训练的稳定性。要注意,在生成器的输出层和判别器的输入层不使用BN层。
(3)在生成器中除输出层使用Tanh()激活函数,其余层全部使用Relu激活函数,在判别器中,除输出层外所有层都使用LeakyRelu激活函数,防止梯度稀疏
自己画的,凑合着看吧/(/ω\)捂脸/
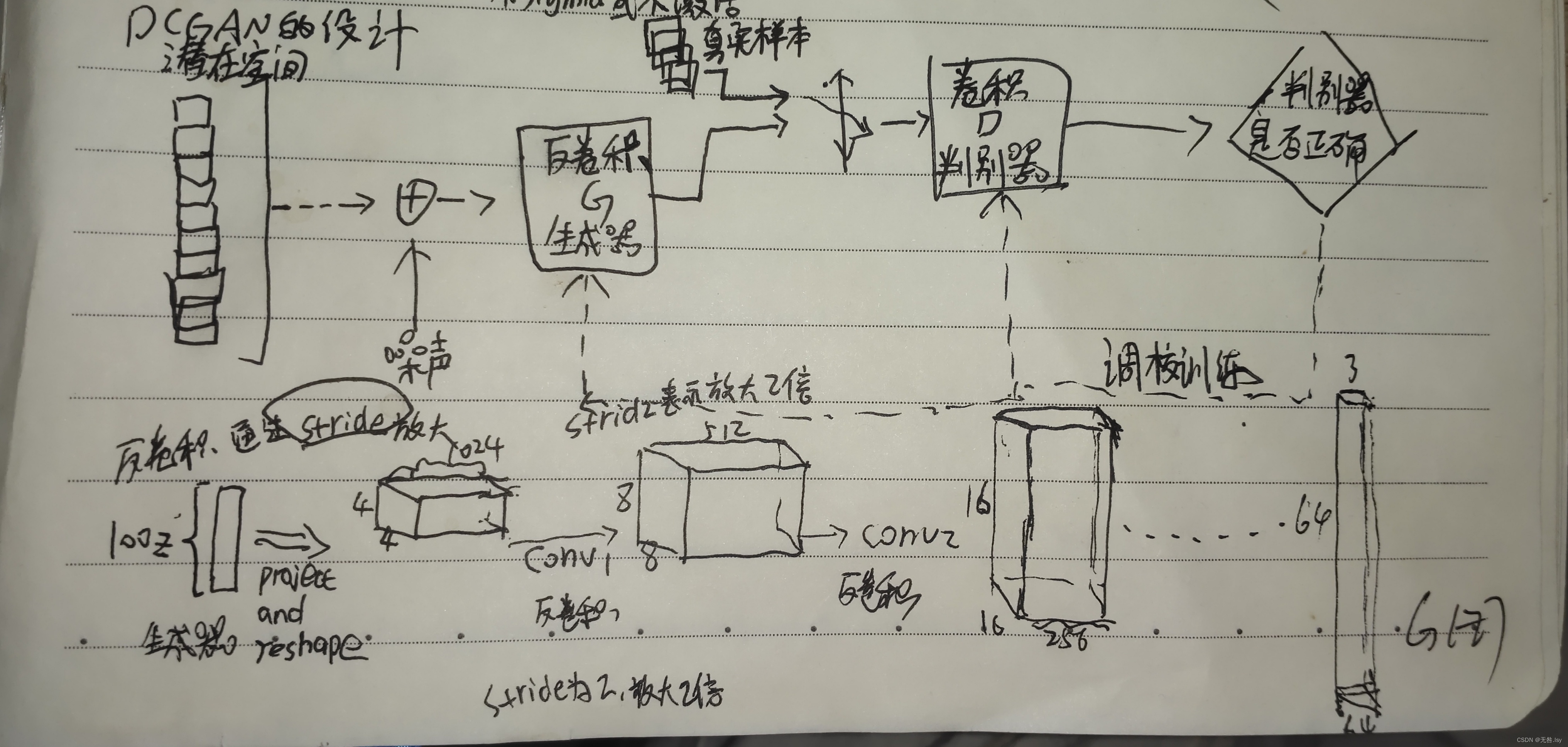
DCGAN的设计技巧
一,取消所有pooling层,G网络中使用转置卷积进行上采样,D网络中加入stride的卷积(为防止梯度稀疏)代替pooling
二,去掉FC层(全连接),使网络变成全卷积网络
三,G网络中使用Relu作为激活函数,最后一层用Tanh
四,D网络中使用LeakyRelu激活函数
五,在generator和discriminator上都使用batchnorm,解决初始化差的问题,帮助梯度传播到每一层,防止generator把所有的样本都收敛到同一点。直接将BN应用到所有层会导致样本震荡和模型不稳定,因此在生成器的输出层和判别器的输入层不使用BN层,可以防止这种现象。
六,使用Adam优化器
七,参数设置参考:LeakyRelu的斜率是0.2;Learing rate = 0.0002;batch size是128.
DCGAN纯代码实现
导入库
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim #优化
import numpy as np
import matplotlib.pyplot as plt #绘图
import torchvision #加载图片
from torchvision import transforms #图片变换
导入数据和归一化
#对数据做归一化(-1,1)
transform=transforms.Compose([
#将shanpe为(H,W,C)的数组或img转为shape为(C,H,W)的tensor
transforms.ToTensor(), #转为张量并归一化到【0,1】;数据只是范围变了,并没有改变分布
transforms.Normalize(mean=0.5,std=0.5)#数据归一化处理,将数据整理到[-1,1]之间;可让数据呈正态分布
])
#下载数据到指定的文件夹
train_ds = torchvision.datasets.MNIST('data/',
train=True,
transform=transform,
download=True)
#数据的输入部分
train_dl=torch.utils.data.DataLoader(train_ds,batch_size=64,shuffle=True)
定义生成器
使用长度为100的noise作为输入,也可以使用torch.randn(batchsize,100,1,1)
class Generator(nn.Module):
def __init__(self):
super(Generator,self).__init__()
self.linear1 = nn.Linear(100,256*7*7)
self.bn1=nn.BatchNorm1d(256*7*7)
self.deconv1 = nn.ConvTranspose2d(256,128,
kernel_size=(3,3),
stride=1,
padding=1) #生成(128,7,7)的二维图像
self.bn2=nn.BatchNorm2d(128)
self.deconv2 = nn.ConvTranspose2d(128,64,
kernel_size=(4,4),
stride=2,
padding=1) #生成(64,14,14)的二维图像
self.bn3=nn.BatchNorm2d(64)
self.deconv3 = nn.ConvTranspose2d(64,1,
kernel_size=(4,4),
stride=2,
padding=1) #生成(1,28,28)的二维图像
def forward(self,x):
x=F.relu(self.linear1(x))
x=self.bn1(x)
x=x.view(-1,256,7,7)
x=F.relu(self.deconv1(x))
x=self.bn2(x)
x=F.relu(self.deconv2(x))
x=self.bn3(x)
x=torch.tanh(self.deconv3(x))
return x
定义鉴别器
class Discriminator(nn.Module):
def __init__(self):
super(Discriminator,self).__init__()
self.conv1 = nn.Conv2d(1,64,kernel_size=3,stride=2)
self.conv2 = nn.Conv2d(64,128,kernel_size=3,stride=2)
self.bn = nn.BatchNorm2d(128)
self.fc = nn.Linear(128*6*6,1)
def forward(self,x):
x= F.dropout2d(F.leaky_relu(self.conv1(x)))
x= F.dropout2d(F.leaky_relu(self.conv2(x)) ) #(batch,128,6,6)
x = self.bn(x)
x = x.view(-1,128*6*6) #展平
x = torch.sigmoid(self.fc(x))
return x
初始化和 模型训练
#设备的配置
device='cuda' if torch.cuda.is_available() else 'cpu'
#初化生成器和判别器把他们放到相应的设备上
gen = Generator().to(device)
dis = Discriminator().to(device)
#交叉熵损失函数
loss_fn = torch.nn.BCELoss()
#训练器的优化器
d_optimizer = torch.optim.Adam(dis.parameters(),lr=1e-5)
#训练生成器的优化器
g_optimizer = torch.optim.Adam(dis.parameters(),lr=1e-4)
def generate_and_save_images(model,epoch,test_input):
prediction = np.squeeze(model(test_input).detach().cpu().numpy())
fig = plt.figure(figsize=(4,4))
for i in range(prediction.shape[0]):
plt.subplot(4,4,i+1)
plt.imshow((prediction[i]+1)/2,cmap='gray')
plt.axis('off')
plt.savefig('image_at_epoch_{:04d}.png'.format(epoch))
plt.show()
test_input = torch.randn(16,100 ,device=device) #16个长度为100的随机数
D_loss = []
G_loss = []
#训练循环
for epoch in range(30):
#初始化损失值
D_epoch_loss = 0
G_epoch_loss = 0
count = len(train_dl.dataset) #返回批次数
#对数据集进行迭代
for step,(img,_) in enumerate(train_dl):
img =img.to(device) #把数据放到设备上
size = img.shape[0] #img的第一位是size,获取批次的大小
random_seed = torch.randn(size,100,device=device)
#判别器训练(真实图片的损失和生成图片的损失),损失的构建和优化
d_optimizer.zero_grad()#梯度归零
#判别器对于真实图片产生的损失
real_output = dis(img) #判别器输入真实的图片,real_output对真实图片的预测结果
d_real_loss = loss_fn(real_output,
torch.ones_like(real_output,device=device)
)
d_real_loss.backward()#计算梯度
#在生成器上去计算生成器的损失,优化目标是判别器上的参数
generated_img = gen(random_seed) #得到生成的图片
#因为优化目标是判别器,所以对生成器上的优化目标进行截断
fake_output = dis(generated_img.detach()) #判别器输入生成的图片,fake_output对生成图片的预测;detach会截断梯度,梯度就不会再传递到gen模型中了
#判别器在生成图像上产生的损失
d_fake_loss = loss_fn(fake_output,
torch.zeros_like(fake_output,device=device)
)
d_fake_loss.backward()
#判别器损失
disc_loss = d_real_loss + d_fake_loss
#判别器优化
d_optimizer.step()
#生成器上损失的构建和优化
g_optimizer.zero_grad() #先将生成器上的梯度置零
fake_output = dis(generated_img)
gen_loss = loss_fn(fake_output,
torch.ones_like(fake_output,device=device)
) #生成器损失
gen_loss.backward()
g_optimizer.step()
#累计每一个批次的loss
with torch.no_grad():
D_epoch_loss +=disc_loss
G_epoch_loss +=gen_loss
#求平均损失
with torch.no_grad():
D_epoch_loss /=count
G_epoch_loss /=count
D_loss.append(D_epoch_loss)
G_loss.append(G_epoch_loss)
generate_and_save_images(gen,epoch,test_input)
print('Epoch:',epoch)
运行结果
因篇幅有限,这里展示第一张和最后一张,这里我训练了30个epoch,有条件的可以多训练几次,训练越多效果越明显哦


希望我的文章能对你有所帮助。欢迎👍点赞 ,📝评论,🌟关注,⭐️收藏

版权归原作者 无咎.lsy 所有, 如有侵权,请联系我们删除。