
前言:本文以一台服务器来搭建集群示例。
Kafka官方网址:Apache Kafka

点击Download下载需要的版本:

下载后的文件:

将下载后的文件上传到服务器中指定的位置:
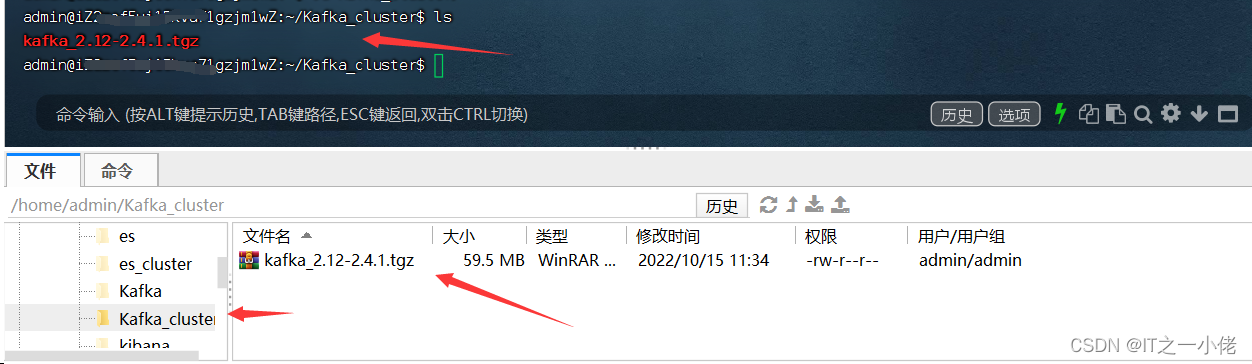 在Kafka_cluster文件夹中新建Kafka_node1, Kafka_node2, Kafka_node3三个文件夹,并将上述压缩包分别解压到这三个文件夹中。
在Kafka_cluster文件夹中新建Kafka_node1, Kafka_node2, Kafka_node3三个文件夹,并将上述压缩包分别解压到这三个文件夹中。

将文件分别解压到三个文件夹中:

首先先对node1进行配置文件修改,修改config中的server.properties文件:
# 指定broker的id
broker.id=0
# 指定Kafka的绑定监听的地址
listeners=PLAINTEXT://node1.test.cn:9092
# 指定Kafka数据位置
log.dirs=/home/admin/Kafka_cluster/Kafka_node1/kafka_2.12-2.4.1/kafka_data
# 配置zk的三个节点
zookeeper.connect=node1.test.cn:2181,node2.test.cn:2182,node3.test.cn:2183

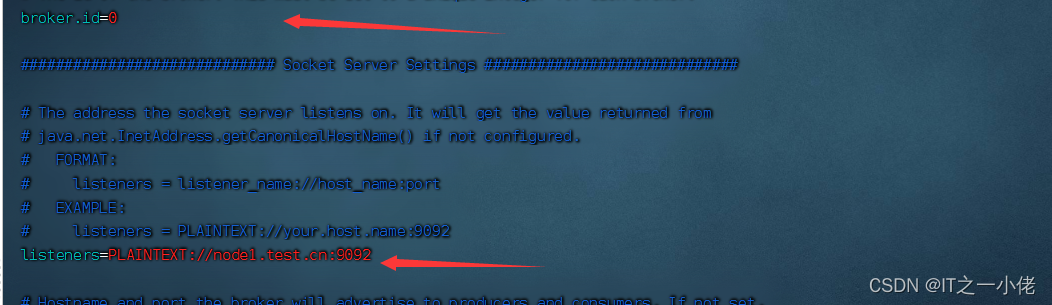


注意:对于绑定的监听地址有时候直接在浏览器输入node1不识别,写全称如node1.test.cn
同理,将node1上述操作在node2和node3中做同样的操作:
# node2
# 指定broker的id
broker.id=1
# 指定Kafka的绑定监听的地址
listeners=PLAINTEXT://node2.test.cn:9093
# 指定Kafka数据位置
log.dirs=/home/admin/Kafka_cluster/Kafka_node2/kafka_2.12-2.4.1/kafka_data
# 配置zk的三个节点
zookeeper.connect=node1.test.cn:2181,node2.test.cn:2182,node3.test.cn:2183
# node3
# 指定broker的id
broker.id=2
# 指定Kafka的绑定监听的地址
listeners=PLAINTEXT://node3.test.cn:9094
# 指定Kafka数据位置
log.dirs=/home/admin/Kafka_cluster/Kafka_node3/kafka_2.12-2.4.1/kafka_data
# 配置zk的三个节点
zookeeper.connect=node1.test.cn:2181,node2.test.cn:2182,node3.test.cn:2183
注意:记得kafka_data文件夹不存在时要先新建。
修改hosts文件:
sudo vim /etc/hosts

注意:如果对外开放的话,这儿的127.0.0.1要改为0.0.0.0
配置KAFKA_HOME环境变量:
sudo vim /etc/profile
# KAFKA_HOME
export KAFKA_HOME1=/home/admin/Kafka_cluster/Kafka_node1/kafka_2.12-2.4.1
export PATH=:$PATH:${KAFKA_HOME1}
export KAFKA_HOME2=/home/admin/Kafka_cluster/Kafka_node2/kafka_2.12-2.4.1
export PATH=:$PATH:${KAFKA_HOME2}
export KAFKA_HOME3=/home/admin/Kafka_cluster/Kafka_node3/kafka_2.12-2.4.1
export PATH=:$PATH:${KAFKA_HOME3}
加载环境变量:
source /etc/profile
启动服务器,首先启动ZooKeeper:
./bin/zookeeper-server-start.sh ./config/zookeeper.properties
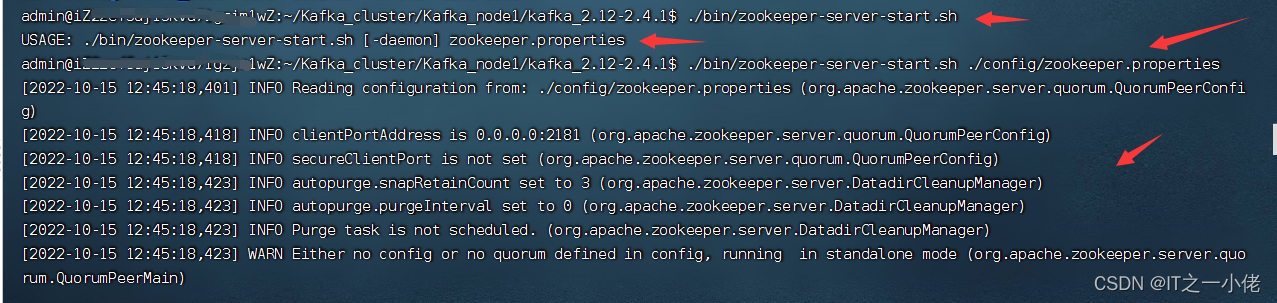
注意:因为测试使用的是同一台服务器,在这儿启动一个node的zookeeper即可。
注意:如果服务器没有安装java环境时,启动zookeeper会报错。
启动Kafka:
./bin/kafka-server-start.sh ./config/server.properties
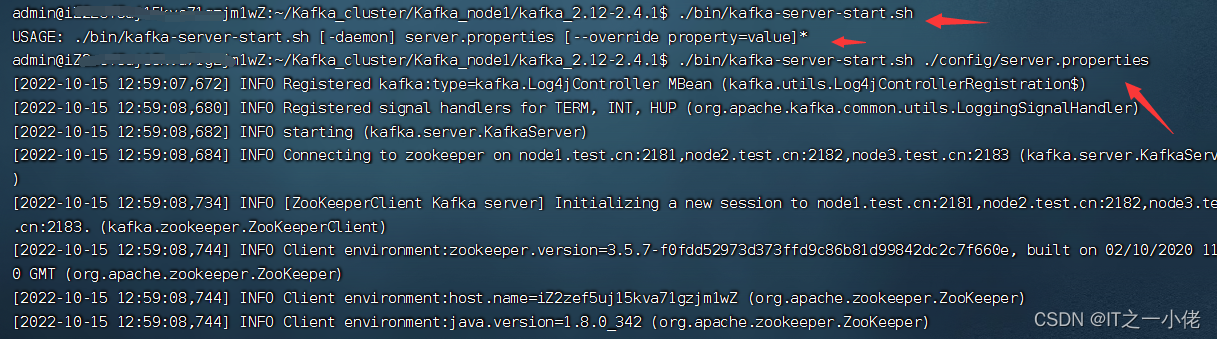
同理:启动node2和node3。
测试Kafka集群是否启动成功:

启动成功后,日志文件也对应的生成了:

为了可视化查看Kafka集群启动状况,可以下载可视化工具ZooInspector:
下载链接:https://issues.apache.org/jira/secure/attachment/12436620/ZooInspector.zip

在上面Kafka启动成功后,我们需要以后台形式的启动Kafka,可以借助工具nohup来后台启动。
为了方便快速的启动所有的程序,可以把命令写到一个脚本中进行执行,如下所示:



nohup ../Kafka_node1/kafka_2.12-2.4.1/bin/zookeeper-server-start.sh ../Kafka_node1/kafka_2.12-2.4.1/config/zookeeper.properties > logs/zookeeper_satrt.logs 2>&1 &

nohup ../Kafka_node1/kafka_2.12-2.4.1/bin/kafka-server-start.sh ../Kafka_node1/kafka_2.12-2.4.1/config/server.properties > logs/node1_start.logs 2>&1 &
nohup ../Kafka_node2/kafka_2.12-2.4.1/bin/kafka-server-start.sh ../Kafka_node2/kafka_2.12-2.4.1/config/server.properties > logs/node2_start.logs 2>&1 &
nohup ../Kafka_node3/kafka_2.12-2.4.1/bin/kafka-server-start.sh ../Kafka_node3/kafka_2.12-2.4.1/config/server.properties > logs/node3_start.logs 2>&1 &
注意事项:
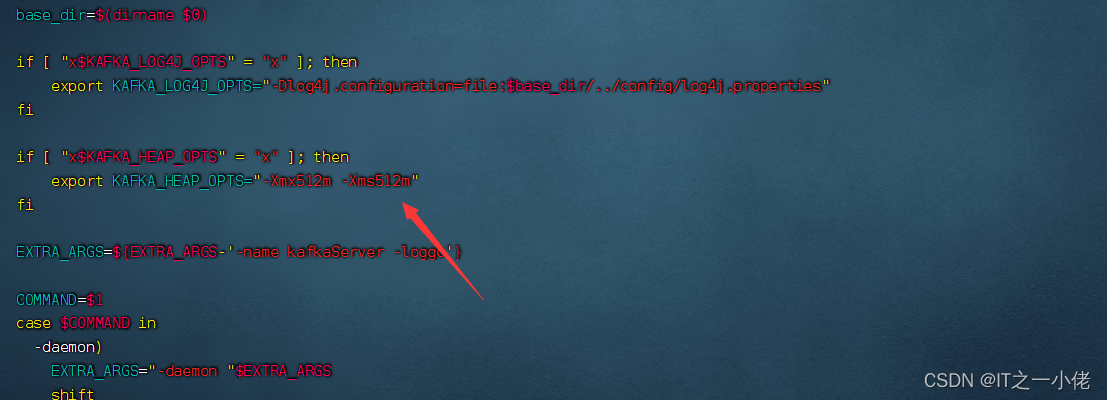
zookeeper和Kafka启动过程中内存可能占用的比较多,可以对内存大小进行修改。

版权归原作者 IT之一小佬 所有, 如有侵权,请联系我们删除。