
文章目录
1、hive基本概念
1.1、hive架构
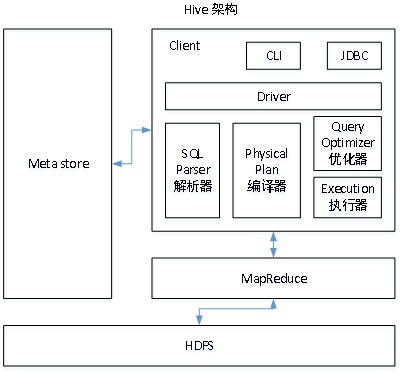
由图我们可以得知:
- 用户连接接口 CLI:是指Shell命令行 JDBC/ODBC:是指Hive的java实现,与传统数据库JDBC类似。 WebUI:是指可通过浏览器访问Hive。
- 元数据:Metastore元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;> 默认存储在自带的derby数据库中,推荐使用MySQL存储Metastore
- thriftserver: hive的可选组件,此组件是一个软件框架服务,允许客户端使用包括Java、C++、Ruby和其他很多种语言,通过编程的方式远程访问Hive。
- 驱动器(Driver)- 解析器(SQLParser):将HQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误。- 编译器(Compiler):对hql语句进行词法、语法、语义的编译(需要跟元数据关联),编译完成后会生成一个执行计划。hive上就是编译成mapreduce的job。- 优化器(Optimizer):将执行计划进行优化,减少不必要的列、使用分区、使用索引等。优化job。- 执行器(Executer):将优化后的执行计划提交给hadoop的yarn上执行。提交job。
- hadoop Jobtracker是hadoop1.x中的组件,它的功能相当于:Resourcemanager+AppMaster TaskTracker相当于:Nodemanager + yarnchildHive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成
1.2、hive工作原理
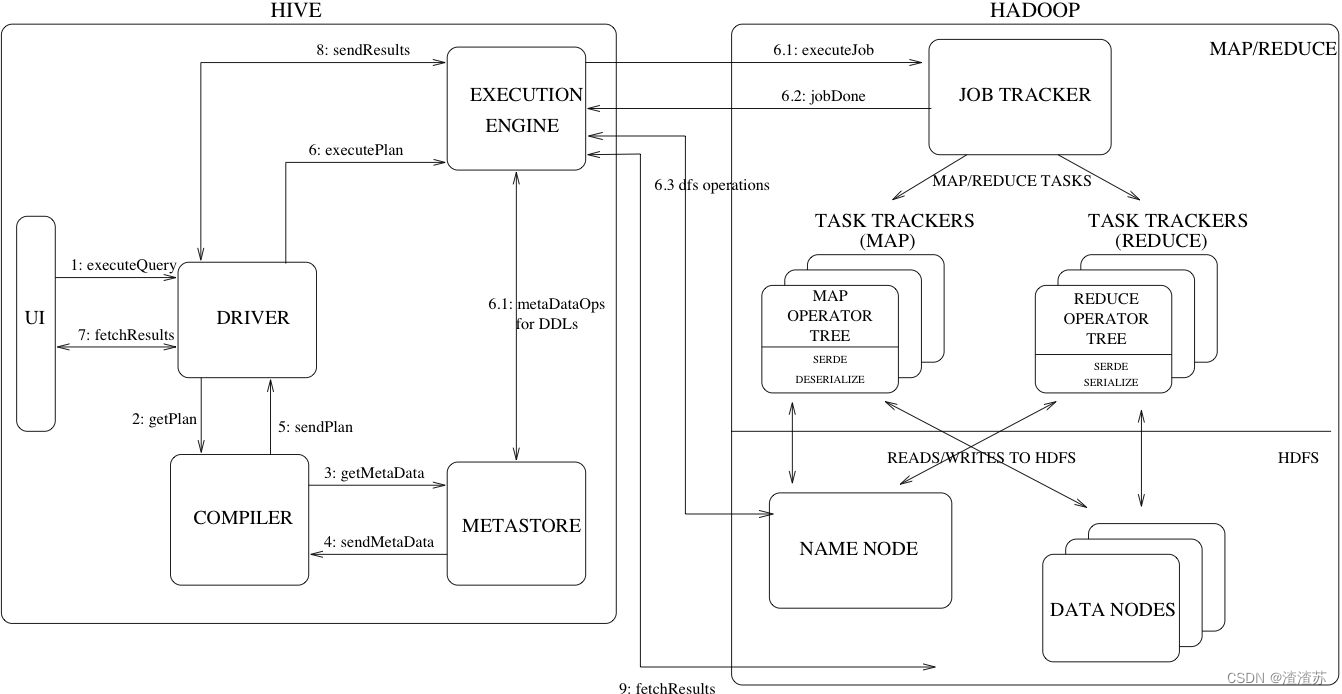
- 用户提交查询任务给Driver。
- 编译器Compiler获得用户的任务计划。
- 编译器Compiler根据用户任务从MetaStore中得到所需要的Hive的元数据信息。
- 编译器Compiler得到元数据信息,对任务进行编译,先将HQL转换为抽象语法树,接着把抽象语法树转换成查询语句块,将查询语句块转化为逻辑的查询计划。
- 把最终的计划提交给Driver。到此为止,查询解析和编译完成。
- Driver将计划Plan提交到Execution Engine,获得元数据信息,接着提交到JobTracker或者Source Manager运行该任务,该任务会直接从HDFS中读取文件并进行相应的操作。
- 取得并返回执行结果
1.3、hive与数据库比较
hive与hadoop关系:
- hive本身其实没有多少功能,hive就相当于在hadoop上面包了一个壳子,就是对hadoop进行了一次封装。
- hive的存储是基于hdfs/hbase的,hive的计算是基于mapreduce。
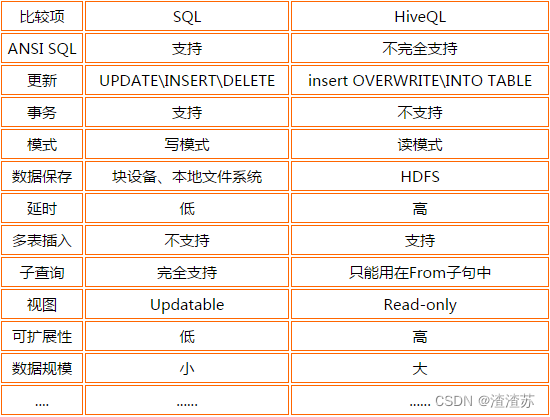
hive与传统数据库比较:
- Hive采用了类SQL的查询语言HQL,因此很容易将Hive理解为数据库。其实从结构上来看,Hive和数据库除了拥有类似的查询语言,再无类似之处。
- 数据库可以用在OLTP的应用中,但是Hive是为数据仓库而设计的,清楚这一点,有助于从应用角度理解Hive的特性。
- Hive不适合用于联机事务处理(OLTP),也不提供实时查询功能。它最适合应用在基于大量不可变数据的批处理作业。Hive 的特点是可伸缩(在Hadoop 的集群上动态的添加设备),可扩展、容错、输入格式的松散耦合。Hive 的入口是DRIVER ,执行的SQL语句首先提交到DRIVER驱动,然后调COMPILER解释驱动,最终解释成MapReduce 任务执行,最后将结果返回。
- MapReduce 开发人员可以把自己写的 Mapper 和 Reducer 作为插件支持 Hive 做更复杂的数据分析。 它与关系型数据库的 SQL 略有不同,但支持了绝大多数的语句(如 DDL、DML)以及常见的聚合函数、连接查询、条件查询等操作。
hive与mysql比较:
- mysql用自己的存储存储引擎,hive使用的hdfs来存储。
- mysql使用自己的执行引擎,而hive使用的是mapreduce来执行。
- mysql使用环境几乎没有限制,hive是基于hadoop的。
- mysql的低延迟,hive是高延迟。
- mysql的handle的数据量较小,而hive的能handle数据量较大。
- mysql的可扩展性较低,而hive的扩展性较高。
- mysql的数据存储格式要求严格,而hive对数据格式不做严格要求。
- mysql可以允许局部数据插入、更新、删除等,而hive不支持局部数据的操作。
2、hive安装
- 解压hive
- 创建文件夹
cd hive mkdir warehouse - 配置环境变量
vim /etc/profile#hiveexportHIVE_HOME=/usr/local/study/hiveexportPATH=$HIVE_HOME/bin:$PATHsource /etc/profile - 安装mysql
解压mkdir mysql# tar -xvf mysql-8.0.29-1.el7.x86_64.rpm-bundle.tar -C mysql#安装cd mysqlrpm -ivh mysql-community-common-8.0.29-1.el7.x86_64.rpm --nodeps --forcerpm -ivh mysql-community-libs-8.0.29-1.el7.x86_64.rpm --nodeps --forcerpm -ivh mysql-community-client-8.0.29-1.el7.x86_64.rpm --nodeps --forcerpm -ivh mysql-community-server-8.0.29-1.el7.x86_64.rpm --nodeps --force对mysql初始化配置mysqld --initializechown mysql:mysql /var/lib/mysql -R#启动MySQL服务systemctl start mysqld.servicesystemctl enable mysqld#改密码cat /var/log/mysqld.log | grep passwordALTER USER 'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'Root123.';#改权限use mysql;select Host ,User from user;update user set Host='%' where User='root'; - 新建元数据库
mysql -uroot -pRoot123.create database metastore;exit; - 配置属性1. 修改 hive-env.sh
HADOOP_HOME=/usr/local/study/hadoopexport HIVE_CONF_DIR=/usr/local/study/hive/confexport HIVE_AUX_JARS_PATH=/usr/local/study/hive/lib2. 创建 hive-site.xmlvim conf/hive-site.xml``````<configuration><!-- 在configuration中加入配置 --><property><name>hive.metastore.warehouse.dir</name><value>/usr/local/study/hive/warehouse</value></property><property><name>hive.metastore.local</name><value>true</value></property><!-- 如果是远程mysql数据库的话需要在这里写入远程的IP或hosts --><property><name>javax.jdo.option.ConnectionURL</name><value>jdbc:mysql://127.0.0.1:3306/metastore?createDatabaseIfNotExist=true</value></property><property><name>javax.jdo.option.ConnectionDriverName</name><value>com.mysql.cj.jdbc.Driver</value></property><property><name>javax.jdo.option.ConnectionUserName</name><value>root</value></property><property><name>javax.jdo.option.ConnectionPassword</name><value>Root123.</value></property></configuration> - 放置mysql驱动包
cp mysql-connector-java-8.0.29.jar /usr/local/study/soft - scp到另俩个linux中
scp -r hive node2:$PWDscp -r hive node3:$PWD1. 另外节点配置环境变量和mysqlvim /etc/profile#hiveexport HIVE_HOME=/usr/local/study/hiveexport PATH=$HIVE_HOME/bin:$PATHsource /etc/profile2. 另外俩个节点配置mysqlscp -r mysql-8.0.29-1.el7.x86_64.rpm-bundle.tar node2:$PWDscp -r mysql-8.0.29-1.el7.x86_64.rpm-bundle.tar node3:$PWD解压mkdir mysqltar -xvf mysql-8.0.29-1.el7.x86_64.rpm-bundle.tar -C ../mysql#安装cd mysqlrpm -ivh mysql-community-common-8.0.29-1.el7.x86_64.rpm --nodeps --forcerpm -ivh mysql-community-libs-8.0.29-1.el7.x86_64.rpm --nodeps --forcerpm -ivh mysql-community-client-8.0.29-1.el7.x86_64.rpm --nodeps --forcerpm -ivh mysql-community-server-8.0.29-1.el7.x86_64.rpm --nodeps --force#对mysql初始化配置mysqld --initializechown mysql:mysql /var/lib/mysql -R#启动MySQL服务systemctl start mysqld.servicesystemctl enable mysqld#改密码cat /var/log/mysqld.log |grep passwordALTER USER'root'@'localhost' IDENTIFIED WITH mysql_native_password BY 'Root123.';#改权限use mysql;select Host ,User from user;update user setHost='%' where User='root'; - master启动Hadoop
start-all.shzkServer.sh - 三台都启动zookeeper
zkServer.sh - 启动MySQL
service mysql start - 初始化元数据
schematool -initSchema -dbType mysql -verbose - 在2个slave节点中hive-site.xml添加
- 测试启动
hive
3、hive数据类型
3.1、基本数据类型
Hive数据类型Java数据类型长度例子TINYINTbyte1byte有符号整数20SMALINTshort2byte有符号整数20
INT
int4byte有符号整数20BIGINTlong8byte有符号整数20BOOLEANboolean布尔类型,true或者falseTRUE FALSEFLOATfloat单精度浮点数3.14159
DOUBLE
double双精度浮点数3.14159
STRING
string字符系列。可以指定字符集。可以使用单引号或者双引号。‘now is the time’ “for all good men”TIMESTAMP时间类型'2013-01-31 00:13:00.345’BINARY字节数组(二进制)1010
红标为常用的数据类型;
对于Hive的String类型相当于数据库的varchar类型,该类型是一个可变的字符串,不过它不能声明其中最多能存储多少个字符。
3.2、集合数据类型
数据类型描述语法示例STRUCT相当于java语言当中没有方法的对象,只有属性。例如,如果某个列的数据类型是STRUCT{first STRING, last STRING},那么第1个元素可以通过
字段.first
来引用。struct()MAPMAP是一组键-值对元组集合,使用数组表示法可以访问数据。例如,如果某个列的数据类型是MAP,其中键->值对是’first’->’John’和’last’->’Doe’,那么可以通过
字段名[‘last’]
获取最后一个元素map()ARRAY数组是一组具有相同类型和名称的变量的集合。这些变量称为数组的元素,每个数组元素都有一个编号,编号从零开始。例如,数组值为[‘John’, ‘Doe’],那么第2个元素可以通过
数组名[1]
进行引用。Array()
3.3、类型转化
可以使用CAST操作显示进行数据类型转换
例如CAST(‘1’ AS INT)将把字符串’1’ 转换成整数1;如果强制类型转换失败,如执行CAST(‘X’ AS INT),表达式返回空值 NULL。
4、DDL数据定义
库操作:
-- 查看数据库showdatabases;showdatabaseslike'hivetest*';-- 切换数据库use mydb;-- 创建数据库createdatabase zoo;createdatabaseifnotexists zoo;createdatabaseifnotexists qfdb comment'....';createdatabaseifnotexists hivetest location 'hdfs路径';-- 查看数据库信息
语法1:descdatabase databaseName;
语法2:descdatabaseextended databaseName;
语法3:describedatabaseextended databaseName;-- 删除数据库
语法1:dropdatabase databasename;#删除空库dropdatabaseifexists databasename;
语法2:dropdatabase databasename cascade;# 强制删除
表操作:
查看数据库中表:
showtables;# 查看另外一个数据库中的表showtablesin zoo;
查看表结构:
desc tableName
descextended tableName;describeextended tableName;
创建表:
CREATE[EXTERNAL]TABLE[IFNOTEXISTS] table_name
[(col_name data_type [COMMENT col_comment],...)][COMMENT table_comment][PARTITIONED BY(col_name data_type [COMMENT col_comment],...)][CLUSTEREDBY(col_name, col_name,...)[SORTED BY(col_name [ASC|DESC],...)]INTO num_buckets BUCKETS][ROW FORMAT row_format][STORED AS file_format][LOCATION hdfs_path]
- 字段解释说明
- CREATE TABLE 创建一个指定名字的表。如果相同名字的表已经存在,则抛出异常;用户可以用 IF NOT EXISTS 选项来忽略这个异常。
- EXTERNAL关键字可以让用户创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),
Hive创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。在删除表的时候,内部表的元数据和数据会被一起删除,而外部表只删除元数据,不删除数据。 - COMMENT:为表和列添加注释。
- PARTITIONED BY创建分区表
- CLUSTERED BY创建分桶表
- ROW FORMAT
DELIMITED [FIELDS TERMINATED BY char] [COLLECTION ITEMS TERMINATED BY char][MAP KEYS TERMINATED BY char] [LINES TERMINATED BY char]| SERDE serde_name [WITH SERDEPROPERTIES (property_name=property_value,property_name=property_value, …)]用户在建表的时候可以自定义SerDe或者使用自带的SerDe。如果没有指定ROW FORMAT 或者ROW FORMAT DELIMITED,将会使用自带的SerDe。在建表的时候,用户还需要为表指定列,用户在指定表的列的同时也会指定自定义的SerDe,Hive通过SerDe确定表的具体的列的数据。SerDe是Serialize/Deserilize的简称,目的是用于序列化和反序列化。 - STORED AS指定存储文件类型常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、RCFILE(列式存储格式文件)
- LOCATION :指定表在HDFS上的存储位置。
- LIKE:允许用户复制现有的表结构,但是不复制数据。
例子:
语法1:
createtable t_user(id int,name string);
语法2:使用库.表的形式
createtable mydb.t_user(id int,name string);
语法3:指定分隔规则形式
createtableifnotexists t1(
uname string comment'this is name',
chinese int,
math int,
english int)comment'this is my table'row format delimited
fieldsterminatedby'\t'linesterminatedby'\n'
stored as textfile;
修改表结构
- 修改表名
altertable oldTableName renameto newTableName;- 修改列名: 和修改字段类型是同一个语法
altertable tableName change column oldName newName colType;altertable tableName change column colName colName colType;- 修改列的位置: 注意,2.x版本后,必须是相同类型进行移动位置。
altertable tableName change column colName colName colType after colName1;altertable tableName change column colName colName colType first;- 增加字段:
altertable tableName addcolumns(sex int,...);- 删除字段: #注意,2.x版本后,注意类型的问题,替换操作,其实涉及到位置的移动问题。altertable tableName replacecolumns(
id int,
name int,
size int,
pic string
);
注意:实际上是保留小括号内的字段。
删除表:
droptable tableName;
4.1、内部表外部表
内部表
- 也叫管理表
- 表目录会创建在集群上的
{hive.metastore.warehouse.dir}下的相应的库对应的目录中。 - 默认创建的表就是内部表
当我们删除一个管理表时,Hive也会删除这个表中数据。
管理表不适合和其他工具共享数据。
创建内部表
-- 普通创建表createtableifnotexists student2(
id int,
name string
)row format delimited fieldsterminatedby'\t';-- 根据查询结果创建表(查询的结果会添加到新创建的表中)createtableifnotexists student3 asselect id, name from student;-- 根据已经存在的表结构创建表createtableifnotexists student4 like student;-- 查询表的类型desc formatted student2;
外部表
- 外部表需要使用关键字"external",
- 外部表会根据创建表时LOCATION指定的路径来创建目录,
- 如果没有指定LOCATION,则位置跟内部表相同,一般使用的是第三方提供的或者公用的数据。
- 建表语法:必须指定关键字external。
删除该表并不会删除掉这份数据,不过描述表的元数据信息会被删除掉。
create external tableifnotexists student2(
id int,
name string
)row format delimited
fieldsterminatedby'|'
collection items terminatedby','
map keysterminatedby':'linesterminatedby'\n';
内部表与外部表转换:
-- 内转外altertable student2 set tblproperties('EXTERNAL'='TRUE');-- 外转内 altertable student2 set tblproperties('EXTERNAL'='FALSE');
两者应用场景:
每天将收集到的网站日志定期流入HDFS文本文件。在外部表(原始日志表)的基础上做大量的统计分析,用到的中间表、结果表使用内部表存储,数据通过SELECT+INSERT进入内部表。
5、DML数据操作
加载数据
- load
load data [local] inpath '路径'[overwrite] into table 表名 [partition (partcol1=val1,…)];- local:load data [local] inpath ‘路径’ [overwrite] into table 表名 [partition (partcol1=val1,…)];- overwrite:表示覆盖表中已有数据,否则表示追加- partition:表示上传到指定分区 - insert基本插入
insertintotable student partition(month='201709')values(1,'wangwu');insert overwrite table student partition(month='201708')select id, name from student wheremonth='201709';多插入from dept_partition insert overwrite table dept_partition partition(month='201707')select deptno,dname,loc wheremonth='201709'insert overwrite table dept_partition partition(month='201706')select deptno,dname,loc wheremonth='201709'; - as select( 查询语句中创建表并加载数据)
createtableifnotexists student3 asselect id, name from student; - location (创建表时通过Location指定加载数据路径)
createtableifnotexists student5( id int, name string)row format delimited fieldsterminatedby'\t'location '/user/hive/warehouse/student5';#hdfs路径 - import
importtable student2 partition(month='201709')from'/opt/hive/warehouse/export/student';导入eport导出的数据
导出数据
- insert导出到本地
insert overwrite local directory '/opt/datas/dept1'[row format delimited fieldsterminatedby'|']# 格式化后导出select*from dept_partition;导出到hdfsinsertlocal directory '/opt/datas/dept1'row format delimitedfieldsterminatedby'|'select*from dept_partition; - hadoop命令导出
dfs -get /opt/hive/warehouse/employee/employee.txt /opt/datas/dept2/dept.txt; - hive shell导出
hive -e 'select * from hivetest.dept_partition;'> /opt/datas/dept3/dept.txt; - export导出
export table hivetest.dept_partition to'/opt/datas/dept2'; - sqoop导出
清除表数据
truncatetable student;
6、DQL数据查询
查询语法:
[WITH CommonTableExpression (, CommonTableExpression)*](Note: Only available
startingwith Hive 0.13.0)SELECT[ALL|DISTINCT] select_expr, select_expr,...FROM table_reference
[WHERE where_condition][GROUPBY col_list][ORDERBY col_list][CLUSTER BY col_list
|[DISTRIBUTE BY col_list][SORT BY col_list]][LIMIT number]select..from..join[tableName]on..where..groupby..having..orderby..
sort by..limit..union|unionall...
普通查询和数据库SQL一样
执行顺序:
- 第一步: FROM <left_table>
- 第二步: ON <join_condition>
- 第三步: <join_type> JOIN <right_table>
- 第四步: WHERE <where_condition>
- 第五步: GROUP BY <group_by_list>
- 第六步: HAVING <having_condition>
- 第七步: SELECT
- 第八步: DISTINCT <select_list>
- 第九步: ORDER BY <order_by_condition>
- 第十步: LIMIT <limit_number>
标准hive语句的一些规则:
- 列别名的使用,必须完全符合执行顺序,不能提前使用。(mysql除外)
- 在分组查询时,select子句中只能含有分组字段和聚合函数,不能有其他普通字段。(mysql除外)
查询原则
- 尽量不使用子查询、尽量不使用in 或者not in (可以使用 [not] exists替代)
- 尽量避免join连接查询,但是通常避免不了
- 查询永远是小表驱动大表(小表作为驱动表) - 注意:内连接时,默认是左表是驱动表,因此左表一定要是小表。 - 外连接看需求而定。
不同点:
- rlike:通过
Java的正则表达式这个更强大的语言来指定匹配条件。select*from emp where sal RLIKE'[2]'; - Hive支持通常的SQL JOIN语句,
但是只支持等值连接,不支持非等值连接。 - left semi join:在hive中,有一种专有的join操作,left semi join,我们称之为半开连接。它是left join的一种优化形式,只能查询左表的信息,主要用于解决hive中左表的数据是否存在的问题。相当于exists关键字的用法。hive中不支持right semi join
-- 左外连接,左表中的数据全部返回select*from u1 leftjoin u2 on u1.id =u2.id;select*from u1 leftouterjoin u2 on u1.id =u2.id;-- 左半开连接,只显示左表中满足条件的数据。和exists的逻辑是相同的select*from u1 left semi join u2 on u1.id =u2.id;-- exists的写法select*from u1 whereexists(select1from u2 where u2.id =u1.id);-- 验证left semi join 是否可以显示第二张表的信息:错误写法。select A.*, B.*from u1 A left semi join u2 B on A.id =B.id; - 排序- order by:全局排序,一个Reducer- ASC(ascend): 升序(默认)DESC(descend): 降序
select*from emp orderby sal;- Sort By:每个Reducer内部进行排序,对全局结果集来说不是排序- 1.设置reduce个数set mapreduce.job.reduces=3;2.查看设置reduce个数set mapreduce.job.reduces;3.根据部门编号降序查看员工信息select*from dept_partition sort by deptno;- Distribute By:类似MR中partition,进行分区,结合sort by使用。注意,Hive要求DISTRIBUTE BY语句要写在SORT BY语句之前。-select*from dept_partition distribute by deptno sort bymonth;- Cluster By:- 当distribute by和sorts by字段相同时,可以使用cluster by方式。cluster by除了具有distribute by的功能外还兼具sort by的功能。但是排序只能是升序排序,不能指定排序规则为ASC或者DESC。-select*from dept_partition distribute by deptno sort by deptno;select*from dept_partition cluster by deptno;
7、分区和分桶表
7.1、分区简介
为什么分区?
Hive中存放的数据往往是以PB为单位的庞大的数据集,海量的数据需要耗费大量的时间去处理,若是每次查询都对全部数据进行检索,效率会极为低下。而且在计多场景下,我们并不需要对全部数据进行检索,因此引入分区和分桶的方法减少每一次扫描总数据量,这种做法可以显著地改善性能。
如何分区
- 根据业务需求而定,不过通常以年、月、日、小时、地区等进行分区。
分区的语法
createtable tableName(.......)
partitioned by(colName colType [comment'...'],...)
分区的注意事项
- hive的分区名不区分大小写,不支持中文
- hive的分区字段是一个伪字段,但是可以用来进行操作
- 一张表可以有一个或者多个分区,并且分区下面也可以有一个或者多个分区。
- 分区是以字段的形式在表结构中存在,通过describe table命令可以查看到字段存在,但是该字段不存放实际的数据内容,仅仅是分区的表示。
分区的意义
- 让用户在做数据统计的时候缩小数据扫描的范围,在进行select操作时可以指定要统计哪个分区
分区的本质
- 在表的目录或者是分区的目录下在创建目录,分区的目录名为指定字段=值
7.2、分区操作
- 建分区表
# 建表createtableifnotexists part4( id int, name string)partitioned by(year string,month string,DAY string)row format delimited fieldsterminatedby',';-- 测试字段名的大小写,结果不区分。#加载数据loaddatalocal inpath './data/user1.txt'intotable part4 partition(year='2018',month='03',DAy='21');loaddatalocal inpath './data/user2.txt'intotable part4 partition(year='2018',month='03',day='AA'); - 查看分区
show partitions tableName - 修改分区:指的是修改分区字段值对应的映射位置。
altertable part3 partition(year='2020',month='05',day='01')set location 'hdfs://master:8020/user/hive/warehouse/mydb.db/part1/dt=2020-05-05'; - 增加分区- 新增空分区
altertable part3 addpartition(year='2020',month='05',day='02');altertable part3 addpartition(year='2020',month='05',day='03')partition(year='2020',month='05',day='04');- 新增带数据分区altertable part3 addpartition(year='2020',month='05',day='05') location '/user/hive/warehouse/mydb.db/part1/dt=2020-05-06';- 新增多分区altertable part3 addpartition(year='2020',month='05',day='06') location '/user/hive/warehouse/mydb.db/part1/dt=2020-05-05'partition(year='2020',month='05',day='07') location '/user/hive/warehouse/mydb.db/part1/dt=2020-05-06'; - 删除分区- 删除单分区
altertable part3 droppartition(year='2020',month='05',day='07');- 删除多个分区altertable part3 droppartition(year='2020',month='05',day='06'),partition(year='2020',month='05',day='06');
7.3、分区类型详解
分区的种类
- 静态分区:直接加载数据文件到指定的分区,即静态分区表。
- 动态分区:数据未知,根据分区的值来确定需要创建的分区(分区目录不是指定的,而是根据数据的值自动分配的)
- 混合分区:静态和动态都有。
分区的属性设置
hive.exec.dynamic.partition=true,是否支持动态分区操作hive.exec.dynamic.partition.mode=strict/nonstrict: 严格模式/非严格模式hive.exec.max.dynamic.partitions=1000:总共允许创建的动态分区的最大数量hive.exec.max.dynamic.partitions.pernode=100:in each mapper/reducer node
各种分区的创建
- 动态分区
-- 建表createtable dy_part1(...)partitioned by(dt string)row format delimited fieldsterminatedby',';-- 加载数据#1.建临时表createtable temp_part1(...)row format delimited fieldsterminatedby',';#2.导入数据到临时表loaddatalocal inpath './data/student2.txt'intotable temp_part1;#3.动态加载到表insertinto dy_part1 partition(dt)select sid,name,gender,age,academy,dt from temp_part1;注意:严格模式下,给动态分区表导入数据时,分区字段至少要有一个分区字段是静态值 非严格模式下,导入数据时,可以不指定静态值。 - 混合分区
-- 建表createtable dy_part2( id int, name string)partitioned by(year string,month string,day string)row format delimited fieldsterminatedby',';-- #创建临时表createtable temp_part2( id int, name string,year string,month string,day string)row format delimited fieldsterminatedby',';#导入数据insertinto dy_part2 partition(year='2020',month,day)select id,name,month,dayfrom temp_part2;
分区表注意事项
- hive的分区使用的是表外字段,分区字段是一个伪列,但是分区字段是可以做查询过滤。
- 分区字段不建议使用中文
- 一般不建议使用动态分区,因为动态分区会使用mapreduce来进行查询数据,如果分区数据过多,导致namenode和resourcemanager的性能瓶颈。所以建议在使用动态分区前尽可能预知分区数量。
- 分区属性的修改都可以修改元数据和hdfs数据内容。
Hive分区和Mysql分区的区别
- mysql分区字段用的是表内字段;而hive分区字段采用表外字段。
7.4、分桶
分桶是相对分区进行更细粒度的划分。在分区数量过于庞大以至于可能导致文件系统崩溃时,我们就需要使用分桶来解决问题了。
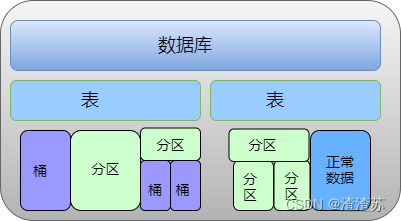
分桶将整个数据内容按照某列属性值的Hash值进行区分。比如,如要按照ID属性分为4个桶,就是对ID属性值的Hash值对4取模,按照取模结果对数据分桶。例如,取模结果为0的数据记录存放到一个文件中,取模为1的数据存放到一个文件中,取模为2的数据存放到一个文件中。
分桶同样应当在建表时就建立,建表语句与建立分区表类似。我们还是创建表person,其建表语句如下:
CREATE TABLEperson(id INT,
name STRING,age INT,
fav ARRAY<STRING>,
addr MAP<STRING,STRING>)COMMENT'This is the person table'ROW FORMAT DELIMITED FIELDSTERMINATEDBY'lt' PARTITIONED BY(dt STRING)CLUSTEREDBY(id)into3 bucketsCOLLECTION ITEMS TERMINATEDBY'-'MAP KEYSTERMINATEDBY':'
STORED AS TEXTFILE;
以字段id为分桶依据,将每个分区分成3个桶,导入数据的语句与分区表时没有区别,还是向分区中导入数据。
LOADDATALOCAL INPATH 'person.txt' OVERWRITE INTOTABLE person partition(dt='20180315');
如果要查询3个桶中第1个桶中的全部数据,可以通过以下查询语句进行查询。
select*from person tablesample (bucket 1outof3on id);
具体过程操作步骤如下(相同的步骤不再重复描述):
- 建表
- 向分区导入数据
- 查询,看分桶内是否成功。
select*from person tablesample(bucket 1outof3on id)
8、函数
在Hive中,函数主要分两大类型,一种是内置函数,一种是用户自定义函数。
8.1、hive内置函数
查看函数
show functions;descfunction functionName;
- 日期函数- 函数1:
current_date(); 当前系统日期 格式:“yyyy-MM-dd”- 函数2:current_timestamp(); 当前系统时间戳: 格式:“yyyy-MM-dd HH:mm:ss.ms”- 函数3:unix_timestamp(); 当前系统时间戳 格式:距离1970年1月1日0点的秒数。- 函数3:unix_timestamp([date[,pattern]])日期转时间戳函数select unix_timestamp('1970-01-01 0:0:0');- 函数4:datediff()、months_between()计算时间差函数select datediff('2019-11-20','2019-11-01');#返回天数select months_between('2019-11-20','2019-11-01');#返回月份- 函数5:year()、month()、day()、hour()、minute()、second()日期时间分量函数selectyear(current_date);- 函数6:last_day()、next_day()日期定位函数--月末:select last_day(current_date)--下周select next_day(current_date,'thursday');- 函数7:date_add()、date_sub()、add_months()日期加减函数select date_add(current_date,1);- 函数8:to_date()字符安川转日期:yyyy-MM-dd格式select to_date('2017-01-01 12:12:12');- 函数8:date_format日期转字符串(格式化)函数select date_format(current_timestamp(),'yyyy-MM-dd HH:mm:ss');select date_format(current_date(),'yyyyMMdd');select date_format('2017-01-01','yyyy-MM-dd HH:mm:ss'); - 字符串函数
lower--(转小写)select lower('ABC');upper--(转大写)select upper('abc');length--(字符串长度,字符数)select length('abc');concat--(字符串拼接)select concat("A",'B');concat_ws --(指定分隔符)select concat_ws('-','a','b','c');substr--(求子串)select substr('abcde',3);split(str,regex)--切分字符串,返回数组。select split("a-b-c-d-e-f","-"); - 类型转换函数
cast(valueastype)-- 类型转换select cast('123'asint)+1; - 数学函数
round --四舍五入((42.3 =>42))selectround(42.3);ceil --向上取整(42.3 =>43)select ceil(42.3);floor --向下取整(42.3 =>42)select floor(42.3); - 其他函数
nvl(value,defaultvalue)-- 如果value为null,则使用default value,否则使用本身value.isnull()isnotnull()casewhenthen....when...then..else...endif(p1,p2,p3)coalesce(col1,col2,col3...)返回第一个不为空的
8.2、窗口函数
- 窗口函数又名开窗函数,属于分析函数的一种。
- 是一种用于解决复杂报表统计需求的函数。
- 窗口函数常用于计算基于组的某种值,它和聚合函数的不同之处是:对于每个组返回多行,而聚合函数对于每个组只返回一行。简单的说窗口函数对每条详细记录开一个窗口,进行聚合统计的查询
- 开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化。
- 窗口函数一般不单独使用
- 窗口函数内也可以分组和排序
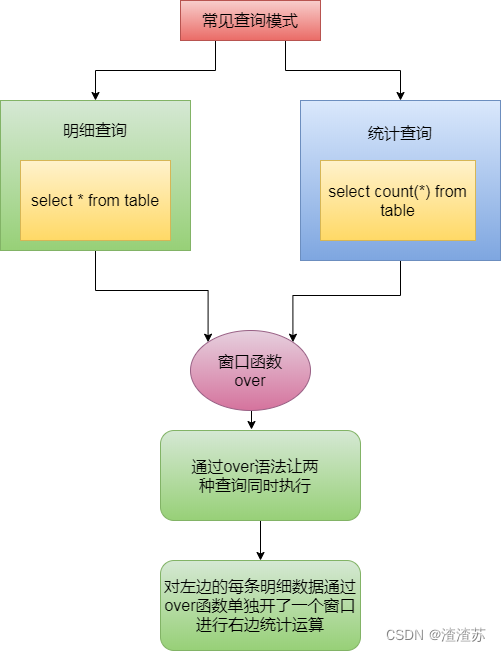
- 简单窗口函数:- 格式:用函数+over()函数- 例子:查询每个订单的信息,以及订单的总数
-- 不使用窗口函数# 查询所有明细select*from t_order;# 查询总量selectcount(*)from t_order;-- 使用窗口函数select*,count(*)over()from t_order;- 窗口函数是针对每一行数据的.如果over中没有指定参数,默认窗口大小为全部结果集 - distribute by子句:在over窗口中进行分组,对某一字段进行分组统计,窗口大小就是同一个组的所有记录- 语法:
over(distribute by colname[,colname.....])- 例子:查看顾客的购买明细及月购买总额select name, orderdate, cost,sum(cost)over(distribute bymonth(orderdate))from t_order;saml 2018-01-0110205saml 2018-01-0855205tony 2018-01-0750205saml 2018-01-0546205 - sort by子句:sort by子句会让输入的数据强制排序 (强调:当使用排序时,窗口会在组内逐行变大)- 语法:
over([distribute by colname] [sort by colname [desc|asc]])- 例子::查看顾客的购买明细及每个顾客的月购买总额,并且按照日期降序排序select name, orderdate, cost,sum(cost)over(distribute by name,month(orderdate) sort by orderdate desc)from t_order;注意:可以使用partition by + order by 组合来代替distribute by+sort by组合select name, orderdate, cost,sum(cost)over(partitionby name,month(orderdate)orderby orderdate desc)from t_order;- 例子:注意:也可以在窗口函数中,只写排序,窗口大小是全表记录。select name, orderdate, cost,sum(cost)over(orderby orderdate desc)from t_order;neil 2018-06-128080-统计信息会逐行增加neil 2018-05-101292mart 2018-04-1394186mart 2018-04-1175261 - Window子句:如果要对窗口的结果做更细粒度的划分,那么就使用window子句- 常见的:
PRECEDING:往前 FOLLOWING:往后 CURRENT ROW:当前行 UNBOUNDED:起点,UNBOUNDED PRECEDING:表示从前面的起点, UNBOUNDED FOLLOWING:表示到后面的终点 - 一般window子句都是rows开头- 例子:
- 一般window子句都是rows开头- 例子:select name,orderdate,cost,sum(cost)over()as sample1,--所有行相加sum(cost)over(partitionby name)as sample2,-- 按name分组,组内数据相加sum(cost)over(partitionby name orderby orderdate)as sample3,-- 按name分组,组内数据累加sum(cost)over(partitionby name orderby orderdate rowsbetweenUNBOUNDEDPRECEDINGandcurrentrow)as sample4 ,-- 与sample3一样,由起点到当前行的聚合sum(cost)over(partitionby name orderby orderdate rowsbetween1PRECEDINGandcurrentrow)as sample5,-- 当前行和前面一行做聚合sum(cost)over(partitionby name orderby orderdate rowsbetween1PRECEDINGAND1FOLLOWING)as sample6,-- 当前行和前边一行及后面一行sum(cost)over(partitionby name orderby orderdate rowsbetweencurrentrowandUNBOUNDEDFOLLOWING)as sample7 -- 当前行及后面所有行from t_order;
8.3、序列函数
- NTILE:ntile 是Hive很强大的一个分析函数。可以看成是:它把有序的数据集合 平均分配 到 指定的数量(num)个桶中, 将桶号分配给每一行。如果不能平均分配,则优先分配较小编号的桶,并且各个桶中能放的行数最多相差1。- 例子:
select name,orderdate,cost, ntile(3)over(partitionby name),# 按照name进行分组,在分组内将数据切成3份from t_order;mart 2018-04-13941mart 2018-04-11751mart 2018-04-09682mart 2018-04-08623neil 2018-06-12801neil 2018-05-10122saml 2018-01-01101 - LAG和LEAD函数:lag返回当前数据行的前第n行的数据,lead返回当前数据行的后第n行的数据- 例子:求5分钟内点击100次的用户
dt id url2019-08-2219:00:01,1,www.baidu.com2019-08-2219:01:01,1,www.baidu.com2019-08-2219:02:01,1,www.baidu.com2019-08-2219:03:01,1,www.baidu.comselect id,dt,lag(dt,100)over(partitionby id orderby dt)from tablename where dt-lag(dt,100)over(partitionby id orderby dt)>=5 - first_value和last_value:irst_value 取分组内排序后,截止到当前行,第一个值,last_value 分组内排序后,截止到当前行,最后一个值- 例子:
select name,orderdate,cost, first_value(orderdate)over(partitionby name orderby orderdate)as time1, last_value(orderdate)over(partitionby name orderby orderdate)as time2from t_order;
8.4、排名函数
- row_number() 从1开始,按照顺序,生成分组内记录的序列,row_number()的值不会存在重复,当排序的值相同时,按照表中记录的顺序进行排列
- RANK() 生成数据项在分组中的排名,排名相等会在名次中留下空位
- DENSE_RANK() 生成数据项在分组中的排名,排名相等会在名次中不会留下空位
8.5、自定义函数
hive的内置函数满足不了所有的业务需求。hive提供很多的模块可以自定义功能,比如:自定义函数、serde、输入输出格式等。而自定义函数可以分为以下三类:
- UDF:user defined function用户自定义函数,一对一的输入输出 (最常用的)。
- UDAF:user defined aggregation function:用户自定义聚合函数,多对一的输入输出,比如:count sum max。
- UDTF:user defined table-generate function用户自定义表生产函数 一对多的输入输出,比如:lateral view explode
开发udf方式
- 在maven中加入
<dependency><groupId>org.apache.hive</groupId><artifactId>hive-exec</artifactId><version>2.1.1</version></dependency> - 编写UDF函数1. 注意:(1)继承
org.apache.hadoop.hive.ql.exec.UDF(2)编写evaluate(),这个方法不是由接口定义的,因为它可接受的参数的个数,数据类型都是不确定的。Hive会检查UDF,看能否找到和函数调用相匹配的evaluate()方法2.importorg.apache.hadoop.hive.ql.exec.UDF;publicclassConcatStringextends UDF {publicStringevaluate(String str){return str +"!";}} - 打包
- 加载使用1. 命令加载(值针对当前session有效)
1. 将编写好的UDF打包并上传到服务器,将jar包添加到hive的classpath中hive>add jar /data/first.jar;2. 创建一个自定义的临时函数名hive> create temporary function myConcatStr as 'com.su.hive.udf.FirstUDF';3. 查看我们创建的自定义函数,hive> show functions;4.在hive中使用函数进行功能测试 hive>select myupper('a');5. 如何删除自定义函数?在删除一个自定义函数的时候一定要确定该函数没有调用hive> drop temporary functionif exists myConcatStr;2. 启动参数加载(只针对当前session有效)1. 将编写好的自定义函数上传到服务器2. 写一个配置文件,将添加函数的语句写入配置文件中,hive在启动的时候加载这个配置文件[root@master ~]# vim $HIVE_HOME/conf/hive-init文件中的内容如下add jar /data/first.jar;create temporary function myUpper as 'com.qf.hive.udf.FirstUDF'; 3. 启动hive时[root@master ~]# hive -i $HIVE_HOME/conf/hive-init3. 配置文件加载(所有皆可用)1、将编写好的自定函数上传到服务器2、在hive的安装目录下的bin目录中创建一个文件,文件名为.hiverc[root@master hive]# vim $HIVE_HOME/bin/.hiverc3、将添加函数的语句写入这文件中 add jar /data/first.jar;create temporary function myUpper as 'com.qf.hive.udf.FirstUDF'; 4、直接启动hive
9、索引与视图
9.1、索引
- 0.7版本之后hive支持索引
- 优点:提高查询效率,避免全表扫描
- 缺点:冗余存储,加载数据较慢
- 索引文件的特点:索引数据有序,并且数据量较小
- 索引的关键字:index
创建索引:
createindex index_rate2
ontable rate2(uid)as'compact'-- 索引文件的存储格式with deferred rebuild -- 索引能够重建;
修改索引(重建索引):目的产生索引文件
alterindex index_rate2 on rate2 rebuild;
查看索引:
showindexon rate2;
创建联合索引:
createindex index_rate2_uid_movie
ontable rate2(uid,movie)as'bitmap'with deferred rebuild;alterindex index_rate2_uid_movie on rate2 rebuild;
删除索引
dropindex index_rate2 on rate2;
9.2、视图
- hive的视图简单理解为逻辑上的表
- hive只支持逻辑视图,不支持物化视图
- 视图存在的意义 1. 对数据进行局部暴露(涉及隐私的数据不暴露)2. 简化复杂查询
创建视图:
createviewifnotexists v_1 asselect uid,movie from rate2 where uid <3;
查看视图
showtables;showcreatetable v_1;desc v_1;
对视图进行查询时:只能使用视图中的字段。不可以使用视图中没有的字段。
视图是否可以克隆?
- 没有必要对视图进行克隆,因为视图没有数据存储
- 修改视图:直接修改元数据(修改元数据中查询语句)
- 先删除再创建就可以
删除视图
dropviewifexists v_1;
注意:
- 切忌先删除视图所依赖的表再去查询视图
- 视图不能用insert into 或者load 加载数据
- 视图是只读的不能修改其结构、相关属性
10、压缩和存储
10.1、序列化和反序列化
文件读取/解析的方式:
- select过程 磁盘上的数据—>row对象 <------反序列化 InputFormat
- insert过程 row对象---->磁盘上的数据 <-----序列化 OutputFormat
在建表语句中,指定了记录的切分格式以及字段的切分符号。实际上,hive在解析文件的时候,涉及到了两个类型。
- 一个类用于从文件中读取一条一条的记录(根据记录分隔符确定一条记录)
row format: 用于指定使用什么格式解析一行的数据delimited: 表示使用org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe进行的内容解析 - 一个类用于从上面读到的记录中切分出一个一个的字段(根据指定字符作为分隔符)
fields terminated by: 表示用什么字符进行字段之间的分隔lines terminated by: 表示用什么字符进行行之间的分隔
强调:hive在select时,这个过程是将字节序列转成hive中的java对象。
hive在insert时,这个过程是将hive中的java对象转成字节序列。
Serde简介
- SerDe是“Serializer and Deserializer”的简称。
- Hive使用SerDe(和FileFormat)来读/写表的Row对象。
- HDFS文件-> InputFileFormat -> <key,value> -> Deserializer -> Row对象
- Row对象->Serializer -> <key,value> -> OutputFileFormat -> HDFS文件
注意,“key”部分在读取时会被忽略,而在写入时始终是常数。基本上Row对象存储在“值”中。
注意,org.apache.hadoop.hive.serde是一个过时的SerDe库。使用最新版本的org.apache.hadoop.hive.serde2。
常用的Serde
- csv: 逗号分隔值
- tsv: tab分隔值
- json: json格式的数据
- regexp: 数据需要复合正则表达式
LazySimpleSerDe:
默认Hive分隔符**
- 行分隔符:\n
- 列分隔符:^A
在Hive中,建表时一般用来来指定字段分隔符和列分隔符。一般导入的文本数据字段分隔符多为逗号分隔符或者制表符(但是实际开发中一般不用着这种容易在文本内容中出现的的符号作为分隔符),当然也有一些别的分隔符,也可以自定义分隔符。有时候也会使用hive默认的分隔符来存储数据。在建表时通过下面语法来指定:
ROW FORMAT DELIMITED FIELDSTERMINATEDBY' '-- 指定列分隔符LINESTERMINATEDBY'\n'-- 指定行分隔符
CSV
默认分隔符:
列分隔符:逗号
CSV格式的文件也称为逗号分隔值(Comma-Separated Values,CSV,有时也称为字符分隔值,因为分隔字符也可以不是逗号。),其文件以纯文本形式存储表格数据(数字和文本)。CSV文件由任意数目的记录组成,记录间以换行符分隔;每条记录由字段组成,字段间的分隔符是其它字符或字符串,最常见的是逗号或制表符。通常,所有记录都有完全相同的字段序列。
在CSV的Serde中有以下三个默认属性
1. 默认转义字符(DEFAULT_ESCAPE_CHARACTER): \ <--反斜线
2. 默认引用字符(DEFAULT_QUOTE_CHARACTER): " <--双引号
3. 默认分隔符(DEFAULT_SEPARATOR): , <-逗号
json
- json serde 可以是自己写的jar包也可以是第三方的jar包
- 要把这种jar包添加到hive的class path中
add jar ./data/json-serde-1.3-jar-with-dependencies.jar;
Regex Serde
hive默认情况下只支持单字节分隔符,如果数据中的分隔符是多字节的,则hive默认是处理不了的。需要使用正则Serde
createtableifnotexists t_regex(
id string,
uname string,
age int)row format serde 'org.apache.hadoop.hive.serde2.RegexSerDe'with serdeproperties('input.regex'='(.*)\\|\\|(.*)\\|\\|(.*)','output.format.string'='%1$s %2$s %3$s')
stored as textfile;
10.2、存储格式
hive的存储格式分为两大类:一类纯文本文件,一类是二进制文件存储。
- 第一类: 纯文本文件存储 - textfile: 纯文本文件存储格式,不压缩,也是hive的默认存储格式,磁盘开销大,数据解析开销大
- 第二类:二进制文件存储 - sequencefile: 会压缩,不能使用load方式加载数据- parquet: 会压缩,不能使用load方式加载数据- rcfile: 会压缩,不能load。查询性能高,写操作慢,所需内存大,计算量大。此格式为行列混合存储,hive在该格式下,会尽量将附近的行和列的块存储到一起。- orcfile: rcfile的升级版
配置项
<property><name>hive.default.fileformat</name><value>TextFile</value><description>
Expects one of [textfile, sequencefile, rcfile, orc].
Default file format for CREATE TABLE statement. Users can explicitly override it by CREATE TABLE ... STORED AS [FORMAT]
</description></property>
10.3、压缩
HQL语句最终会被编译成Hadoop的Mapreduce job,因此hive的压缩设置,实际上就是对底层MR在处理数据时的压缩设置。
10.3.1、hive在map阶段的压缩
map阶段的设置, 就是在MapReduce的shuffle阶段对mapper产生的中间结果数据压缩 。 在这个阶段,优先选择一个低CPU开销的算法。
<!-- 指定要不要开启中间压缩 --><property><name>hive.exec.compress.intermediate</name><value>false</value></property><!-- 指定中间压缩想要使用的压缩编码器(类文件) --><property><name>hive.intermediate.compression.codec</name><value><value/></property><!-- 指定压缩编码器中的那种压缩类型 --><property><name>hive.intermediate.compression.type</name><value><value/></property>
10.3.2、hive在reduce阶段的压缩
即对reduce阶段的输出数据进行压缩设置。
<!-- 指定要不要开启最终压缩。 --><property><name>hive.exec.compress.output</name><value>false</value></property>
注意:如果开启,默认使用中间压缩配置的压缩编码器和压缩类型。
10.3.3、常用压缩格式
压缩格式压缩比压缩速度需要安装支持切分bzip2最高慢否是gzip很高比较快否否snappy比较高很快是否lzo比较高很快是是(需要建立索引)
10.3.4、压缩编码器:
压缩格式压缩编码器deflateorg.apache.hadoop.io.compress.DefaultCodecgziporg.apache.hadoop.io.compress.GzipCodecbzip2org.apache.hadoop.io.compress.BZip2Codeclzocom.hadoop.compression.lzo.LzopCodec(中间输出使用)snappyorg.apache.hadoop.io.compress.SnappyCodec(中间输出使用)
案例测试:
# 开启中间压缩机制
hive (mydb)>set hive.exec.compress.intermediate=true;# 设置中间压缩编码器
hive (mydb)>set hive.intermediate.compression.codec=org.apache.hadoop.io.compress.DefaultCodec;# 设置压缩类型
hive (mydb)>set hive.intermediate.compression.type=RECORD;# 开启reduce端的压缩机制
hive (mydb)>set hive.exec.compress.output=true;12345678
create external table if not exists stocks_seq_2 (
exchange1 string,
symbol string,
ymd string,
price_open float,
price_high float,
price_low float,
price_close float,
volume int,
price_adj_close float
)
row format delimited
fields terminated by ','
stored as sequencefile;
--动态加载数据:
insert into stocks_seq_2 select * from stocks_1;
验证数据是否变小了..........
10.3.5、知识扩展:
什么是可分割
在考虑如何压缩那些将由MapReduce处理的数据时,考虑压缩格式是否支持分割是很重要的。考虑存储在HDFS中的未压缩的文件,其大小为1GB,HDFS的块大小为128MB,所以该文件将被存储为8块,将此文件用作输入的MapReduce作业会创建1个输人分片(split,也称为“分块”。对于block,我们统一称为“块”。)每个分片都被作为一个独立map任务的输入单独进行处理。
现在假设,该文件是一个gzip格式的压缩文件,压缩后的大小为1GB。和前面一样,HDFS将此文件存储为8块。然而,针对每一块创建一个分块是没有用的,因为不可能从gzip数据流中的任意点开始读取,map任务也不可能独立于其他分块只读取一个分块中的数据。gzip格式使用DEFLATE来存储压缩过的数据,DEFLATE将数据作为一系列压缩过的块进行存储。问题是,每块的开始没有指定用户在数据流中任意点定位到下一个块的起始位置,而是其自身与数据流同步。因此,gzip不支持分割(块)机制。
在这种情况下,MapReduce不分割gzip格式的文件,因为它知道输入是gzip压缩格式的(通过文件扩展名得知),而gzip压缩机制不支持分割机制。因此一个map任务将处理16个HDFS块,且大都不是map的本地数据。与此同时,因为map任务少,所以作业分割的粒度不够细,从而导致运行时间变长。
11、调优
Hive常用调优方法
12、Hive面试题
- 说下为什么要使用Hive?Hive的优缺点?Hive的作用是什么?
- 说下Hive是什么?跟数据仓库区别?
- Hive架构
- Hive内部表和外部表的区别?
- 为什么内部表的删除,就会将数据全部删除,而外部表只删除表结构?为什么用外部表更好?
- Hive建表语句?创建表时使用什么分隔符?
- Hive删除语句外部表删除的是什么?
- Hive数据倾斜以及解决方案
- Hive如果不用参数调优,在map和reduce端应该做什么
- Hive的用户自定义函数实现步骤与流程
- Hive的三种自定义函数是什么?实现步骤与流程?它们之间的区别?作用是什么?
- Hive的cluster by、sort bydistribute by、orderby区别?
- Hive分区和分桶的区别
- Hive的执行流程
- Hive SQL转化为MR的过程?
- Hive SQL优化处理
- Hive的存储引擎和计算引擎
- Hive的文件存储格式都有哪些
- Hive中如何调整Mapper和Reducer的数目
- 介绍下知道的Hive窗口函数,举一些例子
- Hive的count的用法
- Hive的union和unionall的区别
- Hive的join操作原理,leftjoin、right join、inner join、outer join的异同?
- Hive如何优化join操作
- Hive的mapjoin
- Hive语句的运行机制,例如包含where、having、group by、orderby,整个的执行过程?
- Hive使用的时候会将数据同步到HDFS,小文件问题怎么解决的?
- Hive Shuffle的具体过程
- Hive有哪些保存元数据的方式,都有什么特点?
- Hive SOL实现查询用户连续登陆,讲讲思路
- Hive的开窗函数有哪些
- Hive存储数据吗
- Hive的SOL转换为MapReduce的过程?
- Hive的函数:UDF、UDAF、UDTF的区别?
- UDF是怎么在Hive里执行的
- Hive优化
- row_number,rank,dense_rank的区别
- Hive count(distinct)有几个reduce,海量数据会有什么问题
- HQL:行转列、列转行
- 一条HQL从代码到执行的过程
- 了解Hive SQL吗?讲讲分析函数?
- 分析函数中加Order By和不加Order By的区别?
- Hive优化方法
- Hive里metastore是干嘛的
- HiveServer2是什么?
- Hive表字段换类型怎么办
- parquet文件优势
版权归原作者 Provence°_博 所有, 如有侵权,请联系我们删除。