
本教程使用python语言编写一个简单的mapreduce程序:单词计数
mapper.py
将下面的代码保存在文件
/home/hadoop/workspace/mapper.py
中。它将从STDIN读取数据,拆分为单词并输出一组映射单词和它们数量(中间值)的行到STDOUT。这个Map脚本不会计算出单词出现次数的总和(中间值)。它会立即输出
<word> 1
元组的形式——即使某个特定的单词可能会在输入中出现多次。在我们的例子中,我们让后续的Reduce做最终的总和计数。当然,你可以按照你的想法在你自己的脚本中修改这段代码。
给mapper.py赋予可执行权限
chmod +x /home/hadoop/workspace/mapper.py
本例当中的workspace为exp(自己建立的文件目录)
/home/hadoop/workspace/mapper.py
代码如下
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import sys
# 从标准输入STDIN输入
for line in sys.stdin:
# 移除line收尾的空白字符
line = line.strip()
# 将line分割为单词
words = line.split()
# 遍历
for word in words:
# 将结果写到标准输出STDOUT
# 此处的输出会作为Reduce代码的输入
print('{}t{}'.format(word, 1))
reducer.py
将下面的代码保存在文件
/home/hadoop/workspace/reducer.py
中。它将从STDIN读取mapper.py的结果(故mapper.py的输出格式和reducer.py预期的输入格式必须匹配),然后统计每个单词出现的次数,最后将结果输出到STDOUT中。
同样我们需要给reducer.py赋予可执行权限:
chmod +x /home/hadoop/workspace/reducer.py
/home/hadoop/workspace/reducer.py
代码如下
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
import sys
current_word = None
current_count = 0
word = None
for line in sys.stdin:
# 移除line收尾的空白字符
line = line.strip()
# 解析我们从mapper.py得到的输入
word, count = line.split('t', 1)
# 将字符串count转换为int
try:
count = int(count)
except ValueError:
# 不是数字,不做处理,跳过
continue
# hadoop在将kv对传递给reduce之前会进行按照key进行排序,在这里也就是word
if current_word == word:
current_count += count
else:
if current_word is not None:
# 将结果写入STDOUT
print('{}t{}'.format(current_word, current_count))
current_count = count
current_word = word
# 最后一个单词不要忘记输出
if current_word == word:
print('{}t{}'.format(current_word, current_count))
注意:给文件赋予可执行权限的时候均在容器中进行

在Hadoop上运行python代码
下载实例输入数据
使用的三个文本来自Gutenberg项目:
- The Outline of Science, Vol. 1 (of 4) by J. Arthur Thomson
- The Notebooks of Leonardo Da Vinci
- Ulysses by James Joyce
下载对应链接下的
Plain Text UTF-8
,三个文本对应的地址分别为:
- https://www.gutenberg.org/cache/epub/20417/pg20417.txt
- https://www.gutenberg.org/files/5000/5000-8.txt
- https://www.gutenberg.org/files/4300/4300-0.txt
建立一个新的文本文档并且将项目中的内容全部复制粘贴到你所建的文本文档之中
复制文本文档到Docker的容器当中,本例中建立的文本文档名称为222
C:\Users\A>docker cp C:\Users\A\Desktop\222.txt bgsvr0:\exp
上面的A指代用户名,将mapper.py复制到容器bgsxr0中的exp目录下
C:\Users\A>docker cp C:\Users\A\Desktop\mapper.py bgsvr0:\exp
同理需要将reducer.py复制到容器bgsvr0中
C:\Users\A>docker cp C:\Users\A\Desktop\reducer.py bgsvr0:\exp
win+R启动cmd,先在docker里边启动自己创立的容器,进入容器之中:
docker exec -it bgsvr0 /bin/bash
然后启动hdfs与yarn
cd /bgsys hadoop-3.3.6
#hdfs
/bgsys/hadoop-3.3.6/sbin/start-dfs.sh
#yarn
/bgsys/hadoop-3.3.6/sbin/start-yarn.sh
配置Java的安装路径和将Hadoop的可执行文件路径添加到系统的
PATH
中,以便在命令行中更方便地运行Java和Hadoop命令。
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd6
export PATH=$PATH:/bgsys/hadoop-3.3.6/bin

在HDFS中创建实验的输入和输出目录,并将本地文件上传到输入目录中,以便后续在Hadoop集群上运行相应的MapReduce任务或其他大数据处理任务。这里的文档文件名可自己命名,本例中为222.txt。
hdfs dfs -mkdir /exp_input
hdfs dfs -mkdir /exp_output
hdfs dfs -put /exp/222.txt /exp_input/

安装
dos2unix
工具。
dos2unix
是一个用于转换文本文件格式的工具,将DOS或Windows格式的文本文件(带有CRLF换行符)转换为Unix/Linux格式的文本文件(带有LF换行符)。
将
/exp/mapper.py
文件从DOS格式转换为Unix/Linux格式。这是因为在不同操作系统上编辑的文件可能使用不同的换行符格式,为了确保在Unix/Linux环境中正确解释脚本,可能需要将其转换为正确的格式。
将
/exp/reducer.py
文件从DOS格式转换为Unix/Linux格式,遵循同样的理由。代码如下:
apt-get install dos2unix
dos2unix /exp/mapper.py
dos2unix /exp/reducer.py


将文件打包为 JAR 文件并进行 MapReduce 处理
Hadoop jar /bgsys/hadoop-3.3.6/share/hadoop/tools/lib/hadoop-streaming-3.3.6.jar -file /exp/mapper.py -mapper /exp/mapper.py \ -file /exp/reducer.py -reducer /exp/reducer.py \ -input /exp_input/222.txt -output /exp_output2024

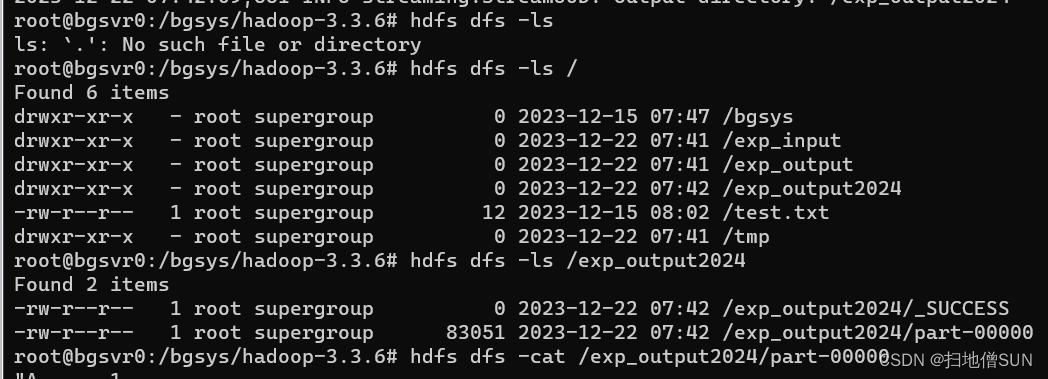
获取数值
hdfs dfs -ls /exp_output2024
hdfs dfs -cat /exp_output2024/part-00000
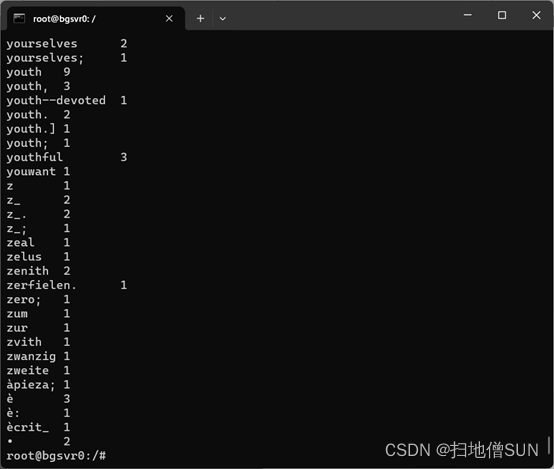
查看结果
程序适应大数据环境的原因分析:
1.分布式处理能力:MapReduce框架使程序能够分解数据处理任务以并行执行。这有助于利用集群中的多个节点,从而加快处理速度。
2.与HDFS的兼容性:该程序采用MapReduce,与Hadoop的HDFS (Distributed File System)无缝集成,实现重要的数据处理。HDFS的数据分布和复制机制允许在集群内高效地处理大规模数据。
3.水平可扩展性:MapReduce程序通过轻松扩展到额外的节点和更大的数据集来展示可扩展性。这种容量使程序能够在不影响性能的情况下适应不断增长的数据量。
版权归原作者 扫地僧SUN 所有, 如有侵权,请联系我们删除。