
特征选择是面试中一个非常受欢迎的问题。 这篇文章能带你了解这方面相关的知识。

为什么要使用特征选择
你熟悉鸢尾花的数据集吗?(sklearn自带小型数据集)即使是最简单的算法也能得到如此美妙的结果,这难道不令人惊叹吗?
很抱歉让你失望了,但这是不现实的。大多数情况下,特征的数量(p)比样本的数量(N)要多得多(p>>N)——这也被称为维数诅咒。但是,为什么这是个问题呢
高维数据可能导致以下情况:
- 训练时间长
- 过度拟合
即使不是p>>N,有一长串机器学习算法可以假设自变量。采用特征选择方法去除相关特征。此外,将特征空间的维数降至相关特征的子集,可以减少训练的计算量,提高模型的泛化性能。
特征选择是从数据集中删除无关和冗余特征的过程。反过来,该模型将降低复杂性,因此更易于解释。
“有时候,越少越好!”
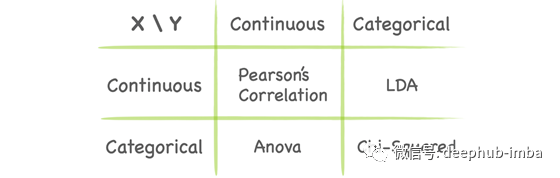
过滤方法
根据特征与目标变量的关系选择特征子集。选择不依赖于任何机器学习算法。相反,过滤方法通过统计检验来衡量特征与输出的“相关性”。你可以参考下表:
皮尔森的相关性
度量两个连续变量之间线性相关性的统计量。从-1到+1,+1为正线性相关,0为无线性相关,-1为负线性相关。
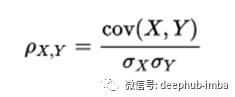
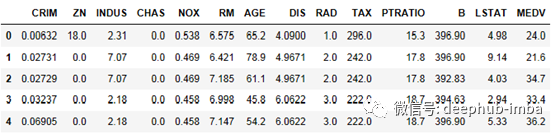
数据集:波士顿房屋房价数据集(sklearn自带)。它包括13个连续特征和业主自住房屋在$1000s的中值(目标变量)。
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.datasets import load_boston
X, y = load_boston(return_X_y=True)
feature_names = load_boston().feature_names
data = pd.DataFrame(X, columns=feature_names)
data['MEDV'] = y
# compute pearson's r
target_correlation = data.corr()[['MEDV']]
# we only care about the target variable
plt.figure(figsize=(7,5))
sns.heatmap(target_correlation, annot=True, cmap=plt.cm.Reds)
plt.show()
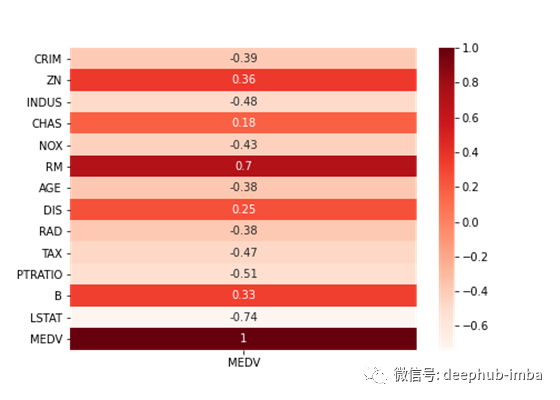
# extract the most correlated features with the output variable
target_correlation[abs(target_correlation)>0.5].dropna()
相关系数的大小在0.5 - 0.7之间,表示可以认为是中度相关的变量,因此我们将阈值设为0.5。
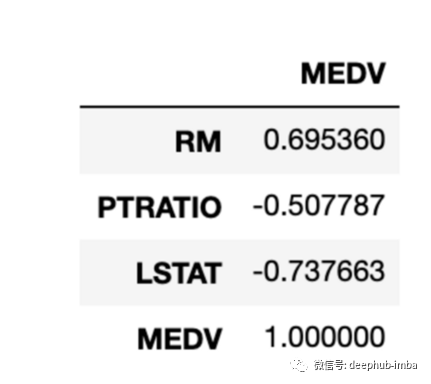
从13个特征中,只有3个与目标有很强的相关性(相关特征);RM, PTRATIO, LSTAT。但是,我们只检查了每个单独特征与输出变量的相关性。由于许多算法,比如线性回归,假设输入特征是不相关的,我们必须计算前3个特征之间的皮尔森r值。
sns.heatmap(data.corr().loc[['RM', 'PTRATIO', 'LSTAT'], ['RM', 'PTRATIO', 'LSTAT']], annot=True, cmap=plt.cm.Reds)
plt.show()
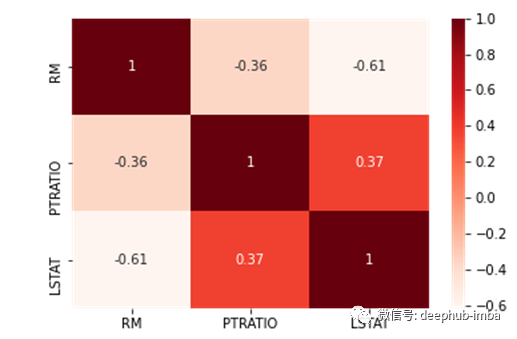
RM和LSTAT是相互关联的,所以我们选择其中一个(去掉RM就等于去掉冗余特征)。由于LSTAT与目标变量MEDV的相关性高于RM,所以我们选择LSTAT。
LDA
线性判别分析是一种有监督的线性算法,它将数据投影到更小的子空间k (k < N-1)中,同时最大化类间的分离。更具体地说,该模型找到的特征的线性组合,实现最大的可分离性,在每个类内的方差最小。
数据集:乳腺癌威斯康辛(诊断)数据集,包括569个记录,每个由30个特征描述。这项任务是将肿瘤分类为恶性或良性。
import pandas as pd
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
from sklearn.model_selection import StratifiedKFold, cross_val_score
from sklearn.pipeline import Pipeline
df = pd.read_csv('breast_cancer.csv').iloc[:,1:-1]
X = df.drop(['diagnosis'], axis=1)
le = LabelEncoder()
y = le.fit_transform(df.diagnosis)
labels = le.classes_
steps = [('lda', LinearDiscriminantAnalysis()), ('m', LogisticRegression(C=10))]
model = Pipeline(steps=steps)
# evaluate model
cv = StratifiedKFold(n_splits=5)
n_scores_lda = cross_val_score(model, X, y, scoring='f1_macro', cv=cv, n_jobs=-1)
model = LogisticRegression(C=10)
n_scores = cross_val_score(model, X, y, scoring='f1_macro', cv=cv, n_jobs=-1)
# report performance
print('f1-score (macro)\n')
print('With LDA: %.2f' % np.mean(n_scores_lda))
print('Without LDA: %.2f' % np.mean(n_scores))

使用LDA作为预处理步骤,性能提高了4%。
ANOVA
方差分析(Analysis of Variance )是检验不同输入类别对输出变量是否有显著差异的一种统计方法。来自sklearn的f_classifmethod允许对多个数据组进行分析,以确定样本之间和样本内部的可变性,从而获得关于独立变量和从属变量之间的关系的信息。例如,我们可能想测试两种程序,看看哪一种在收入方面比另一种表现更好。
from sklearn.feature_selection import f_classif, SelectKBest
fs = SelectKBest(score_func=f_classif, k=5)
X_new = fs.fit(X, y)
注意:之前,我们只设k=5。如果不是5而是4呢?我们可以通过k-fold交叉验证执行网格搜索来微调所选特征的数量
from sklearn.model_selection import StratifiedKFold, GridSearch
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LinearRegression
cv = StratifiedKFold(n_splits=5)
pipeline = Pipeline(steps=[('anova',fs), ('lr', LinearRegression(solver='liblinear'))])
params = {['anova__k']: [i+1 for i in range(X.shape[1])]}
search = GridSearchCV(pipeline, params, scoring='accuracy', n_jobs=-1, cv=cv)
results = search.fit(X, y)
print('Best k: %s' % results.best_params_)
χ²卡方
卡方检验特定特征和特定类的出现是否使用它们的频率分布是独立的。零假设是两个变量是独立的。但是,如果方差值大,则应拒绝原假设。在选择特征时,我们希望提取那些高度依赖于输出的特征。
数据集: Dream Housing Finance公司处理所有住房贷款,并希望自动化贷款资格流程。数据集包含11个分类和数字特征,用于描述客户的个人资料。目标变量是二元的-客户是否有资格获得贷款
from sklearn.feature_selection import chi2, SelectKBest
loan = pd.read_csv('loan_data_set.csv')
loan = loan.drop('Loan_ID', axis=1) # irrelevant feature
#Transform the numerical feature into categorical feature
loan['Loan_Amount_Term'] = loan['Loan_Amount_Term'].astype('object')
loan['Credit_History'] = loan['Credit_History'].astype('object')
#Dropping all the null value
loan.dropna(inplace = True)
#Retrieve all the categorical columns except the target
categorical_columns = loan.select_dtypes(exclude='number').drop('Loan_Status', axis=1).columns
#Retrieve all the categorical columns except the target
categorical_columns = loan.select_dtypes(exclude='number').drop('Loan_Status', axis=1).columns
fs = SelectKBest(score_func=chi2, k=5)
X_kbest = fs.fit_transform(X, y)
非线性关系呢?
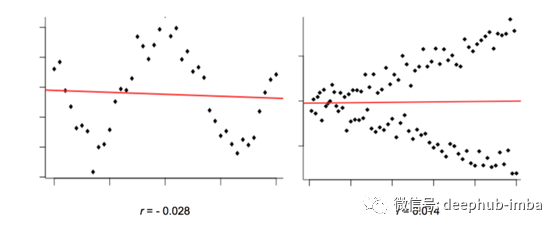
到目前为止,我们一直在讨论假设两个元素X,Y之间存在线性关系的方法。这些方法无法捕获除此以外的任何关系。为了解决这个问题,我们可以看一下特征与目标变量之间的互信息(MI)。MI的范围是0(无互信息)和1(完全相关)。Sklearn为回归和分类任务提供实施。
from sklearn.feature_selection import mutual_info_regression, mutual_info_classif, SelectKBest
fs = SelectKBest(score_func=mutual_info_classif, k=5)
# top 5 features
X_subset = fs.fit_transform(X, y)
可以使用主成分分析吗?
当然可以。但是请不要将特征提取与特征选择混淆。PCA是一种无监督的线性变换技术。这是减少维数的另一种方法-但是要小心,尽管在这种方法中我们不选择特征,而是通过将数据投影到较低维的空间中同时保留最大方差来变换特征空间。该技术导致不相关的变量(主要成分)是旧变量的线性组合。不幸的是,您并不真正了解这些新功能代表什么,因此尽管降低了维度,但您肯定会丧失可解释性。
注意:不要犯年轻的ML从业人员最常见的错误之一:在非连续特征上应用PCA。我知道在离散变量上运行PCA时代码不会中断,但这并不意味着您应该这样做。
注意事项
尽管我们已经看到了很多进行特征选择的方法(还有更多方法),但总会有答案“我不会做”。我知道这听起来可能很奇怪,尤其是当它来自本文的作者时,但是我需要给出所有可能的答案,这就是其中之一。
“特征选择”需要时间,您可能不考虑既不花费时间也不花费精力。您必须始终牢记两件事:1.由于您正在放弃特征,所以肯定会丢失信息;2.即使您尝试了所有技术,也可能看不到模型性能的重大改进。
作者:Elli Tzini
deephub翻译组
原文链接:https://tzinie.medium.com/feature-selection-73bc12a9b39e