
科普知识
ILSVRC(ImageNet Large Scale Visual Recognition Challenge)是机器视觉领域最受追捧也是最具权威的学术竞赛之一,代表了图像领域的最高水平。 ImageNet数据集是ILSVRC竞赛使用的是数据集,由斯坦福大学李飞飞教授主导,包含了超过1400万张全尺寸的有标记图片。ILSVRC比赛会每年从ImageNet数据集中抽出部分样本,以2012年为例,比赛的训练集包含1281167张图片,验证集包含50000张图片,测试集为100000张图片。

前言
上一期文章中我们一同学习了DenseNet网络,该网络核心在于每一个密集块中的每一层的输入都包含了前面的所有层,这些层通过在通道维度上进行拼接,从而一同作为下一层的输入。此举在一定程度上缓解了梯度消失的问题,也由此可以构建更加深层次的神经网络。
今天我们继续来学习一种新的网络-->SENet,它的出现又一次刷新了卷积神经网络的前进方向。该网络是针对什么问题提出的呢?最终又做了哪些工作呢?效果怎么样呢?我们接着往下走!
**SENet之概述 **
1
SENet: Squeeze-and-Excitation Networks, 直译就是挤压和激励的网络,该网络是2017年ILSVRC比赛的第一名,同时由于其可以很方便的嵌入到其余的卷积神经网络中提升精度,受到了颇多的关注,也由此引发了卷积神经网络对于注意力机制的思考,随后诞生了各式各样的注意力机制,如CBAM,DACNet等。
论文截图


论文地址:https://arxiv.org/pdf/1709.01507.pdf
SENet之提出缘由
2
我们首先来思考这样一个问题,在之前的经典网络学习中,这些网络到底在改进什么?是从什么角度改进的呢?其实主要是从网络的结构和深度上做了改进,也就是说主要改进的是网络的堆叠和连接方式,很少从网络本身出发去做改进。SENet这篇文章就从网络本身出发做了一定的改进,因此它的核心思想可以很容易的嵌入到之前的经典神经网络架构中(主要是卷积神经网络)。
1、从摘要可以看到:先前的研究试图通过增强CNN整个特征层次的空间编码的质量来提升CNN的表达(表征)能力。这句话稍微专业了,简单一点就是:试图通过提高CNN中特征的质量(为啥呢?所有特征都有用?不一定,那就该增强的增强,该弱化的弱化呗),进而实现一种特征增强的功能(弱化也是增强的的一种负表现),从而使得CNN的特征更具代表性。
2、在引言中:最近的一些研究者通过集成学习机制来捕获特征间的空间相关性来提高CNN(生成的)表征能力。
3、综上所述,之前所述的都是从空间关系上着手提升CNN的表征能力,还有别的地方可以实现同样的功能吗?
4、随后作者提出了是否可以研究特征图通道之间的关系(相互依赖性)以此来提升CNN的表征能力呢?
SENet之贡献
3
本文中,作者研究了网络设计的另一个方面-->通道间的关系。进而提出了一种新的结构单元, 命名为:Squeeze-andExcitation (SE) block。
1、引入了一种叫做SE block的新的结构单元,该结构可以做啥呢?它能够建模特征图通道间的相互依赖关系,这种关系有啥用呢?用来增强CNN的表征质量(相当于特征做了提纯,使得特征表达能力更强,that's right?)。
2、该模块可以很容易到嵌入到大多数CNN,任何层次,任何深度,从早期阶段到后期阶段都可以嵌入,因为它的能力可以实现累积。
3、该模块构成的网络霸榜了当年的ILSVRC比赛,刷新了在ImageNet上的战绩。几乎可以提升之前的所有经典CNN架构的性能。
****SEet之网络架构 ****
4
其实该模块的架构非常简单,但往往简单的东西确实最让人忽略的。总的来说,该模块,精简,高效,轻量化,便于集成。
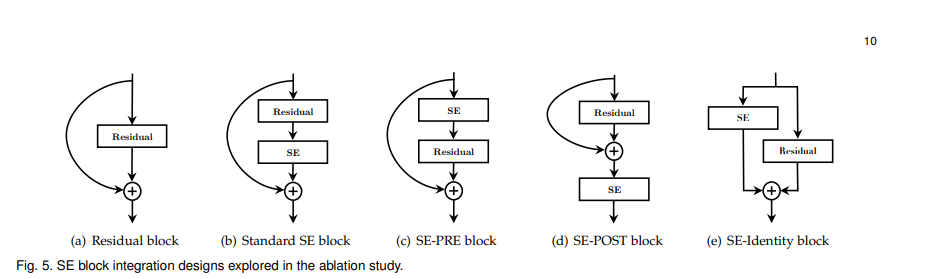
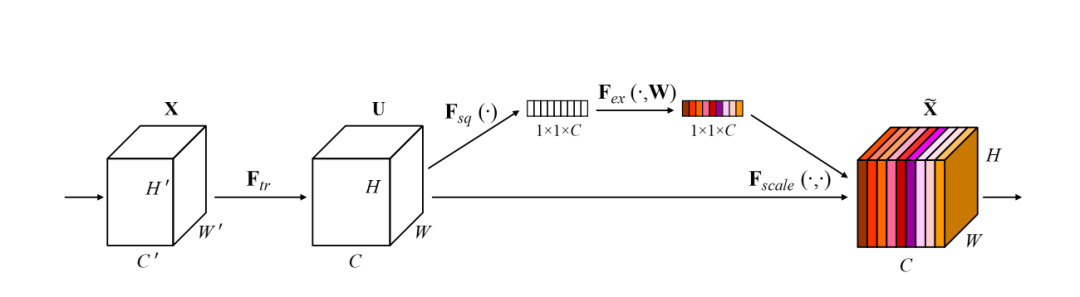
SE块结构图:
嵌入到主流CNN网络中的示意图:
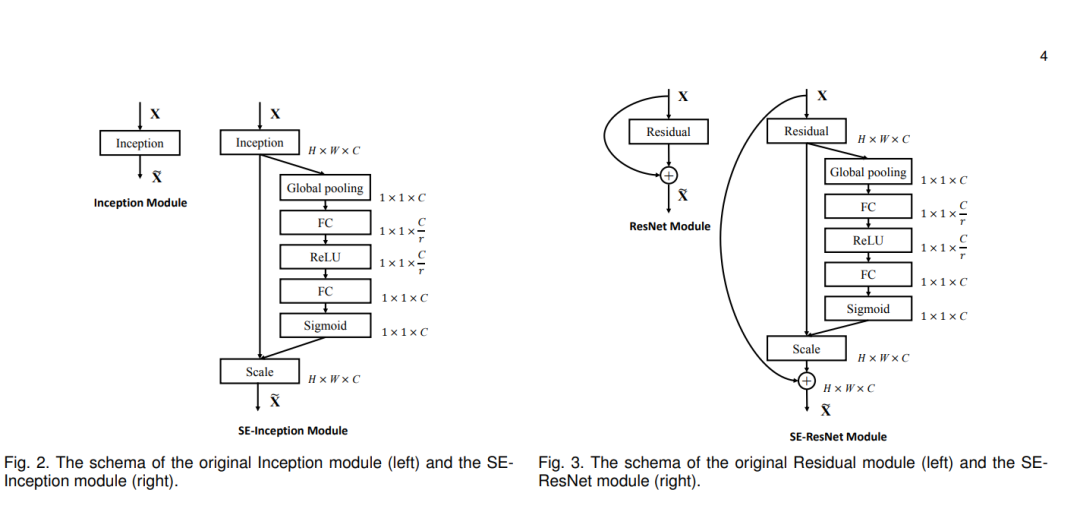
看到第一个图大家有点不是那么懂,或许还得好好看看论文中的公式,但是当看到第二幅图应该就大概明白所谓的SE块是个啥庐山真面目了吧。简单点:SE块嵌入到某一层后,对接收到的特征图首先进行全局平均池化 使得特征图的尺寸变成1x1,通道数不变(为啥不变?要学习的就是通道间的依赖关系?变了怎么学呢?),随后紧跟全连接层--激活层---全连接层--sigmoid激活层层(为啥是它而不是别的激活层,这个函数可以将前面的通道数的具体数值归一化到0-1,由此学习比较容易嘛),后面的Scale层就是将刚才学到的通道数的数值与原始输入的特征图做矩阵乘法(广播形势的点乘)。等等,到这里我们是不是有点醒悟了,SE模块不就是学习了与原始特征图中通道数量的数值吗(0-1范围),这不就相当于为每一个通道学习一个权重吗?确实,能看懂这里,你也就懂了SE的思想了,SE本质就是为每一个通道学习一个自适应的权重,由此决定哪些通道是更需要关注的,哪些是不太重要的,甚至一些是不需要的(权重很接近0),问题来了,每一个通道包含了那么多特征点,我们学习的是一个值啊(每一个通道),所以学习到的权重其实是给每一个通道的所有特征点的,在实际计算的时候会进行将每一个通道的权重广播到该通道上每一个特征点上,这,每一个特征点都得了学习到的权重,这也从侧说明,SE关注的是通道全局性,通道中每一个特征点都视为同样重要的位置。
the end

本期SENet分享就到这里了,有时间的同学可以提前学习论文中给出的代码哦,下期我们将会采用pytorch框架开启实战篇哦,敬请期待!
编辑:玥怡居士 | 审核:小圈圈居士

扫码关注
IT进阶之旅
NO.1
往期回顾
深度学习理论篇之 ( 十八) -- DenseNet之囊括万千
深度学习理论篇之 ( 十七) -- ResNet之深之经典
深度学习理论篇之 ( 十六) -- GoogLeNet之再探深度之谜
过往曾经:
【年终总结】辞旧迎新,2020,我们再出发
【年终总结】2021,辞旧迎新再出发
【年终总结】致敬远去的2021,拥抱不一样的2022
点赞哦
版权归原作者 fengyuxie 所有, 如有侵权,请联系我们删除。