
Java进阶16
一、单元测试
单元测试就是针对最小的功能单元编写测试代码,Java程序最小的功能单元是方法,因此,单原测试就是针对Java方法的测试,进而检查方法的正确性。简单理解就是测试代码的工具。
1、Junit
1.1 Junit引入
目前测试代码,只能在main方法中测试,如果某个方法的测试失败,其他方法测试会受到影响,而Junit解决了这个问题。
1.2 Junit优点
- JUnit可以灵活的选择执行哪些测试方法,可以一键执行全部测试方法
- 单元测试中的某个方法测试失败了,不影响其他方法的测试
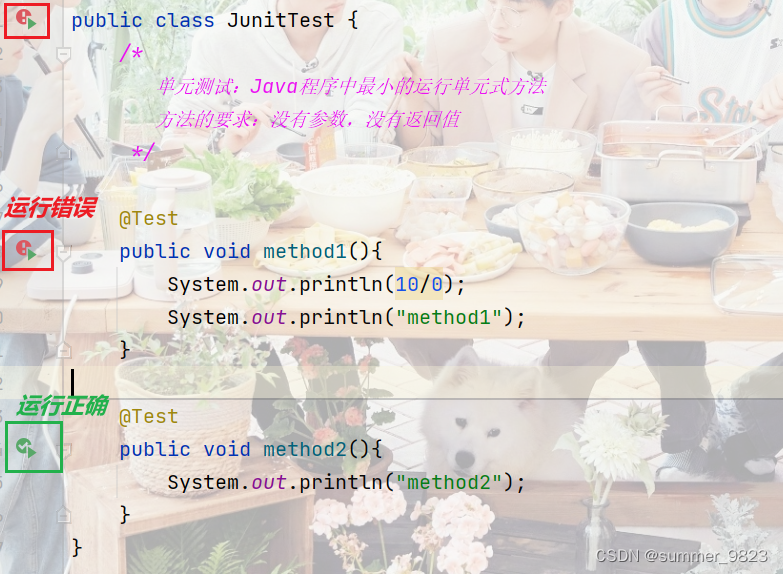
- 运行成功是绿色,运行失败是红色
1.3 Junit基本使用
- 步骤①手动导入jar包或在外部网络的情况下根据提示敲回车(add 'Junit4' to classpath)②在需要测试的方法上,加入@Test注解③运行绿色(正确),红色(错误)
- 注意Junit测试的方法,必须是public的,且没有参数,没有返回值
二、XML
1、XML引入
XML全称EXtensible Markup Language,是一种可扩展的标记语言。【标记语言:通过标签来描述数据的一门语言】【可扩展:标签名可以自定义】xml文件可以为计算机程序配置参数和初始设置,使用xml文件的好处是可以让项目中使用的数据,灵活的加载和多变,实现解耦。
2、分类
2.1 Properties文件
用于一对一的存储
- 键值对
- username=root
- password=123456
2.1 xml文件
常用于一对多存储
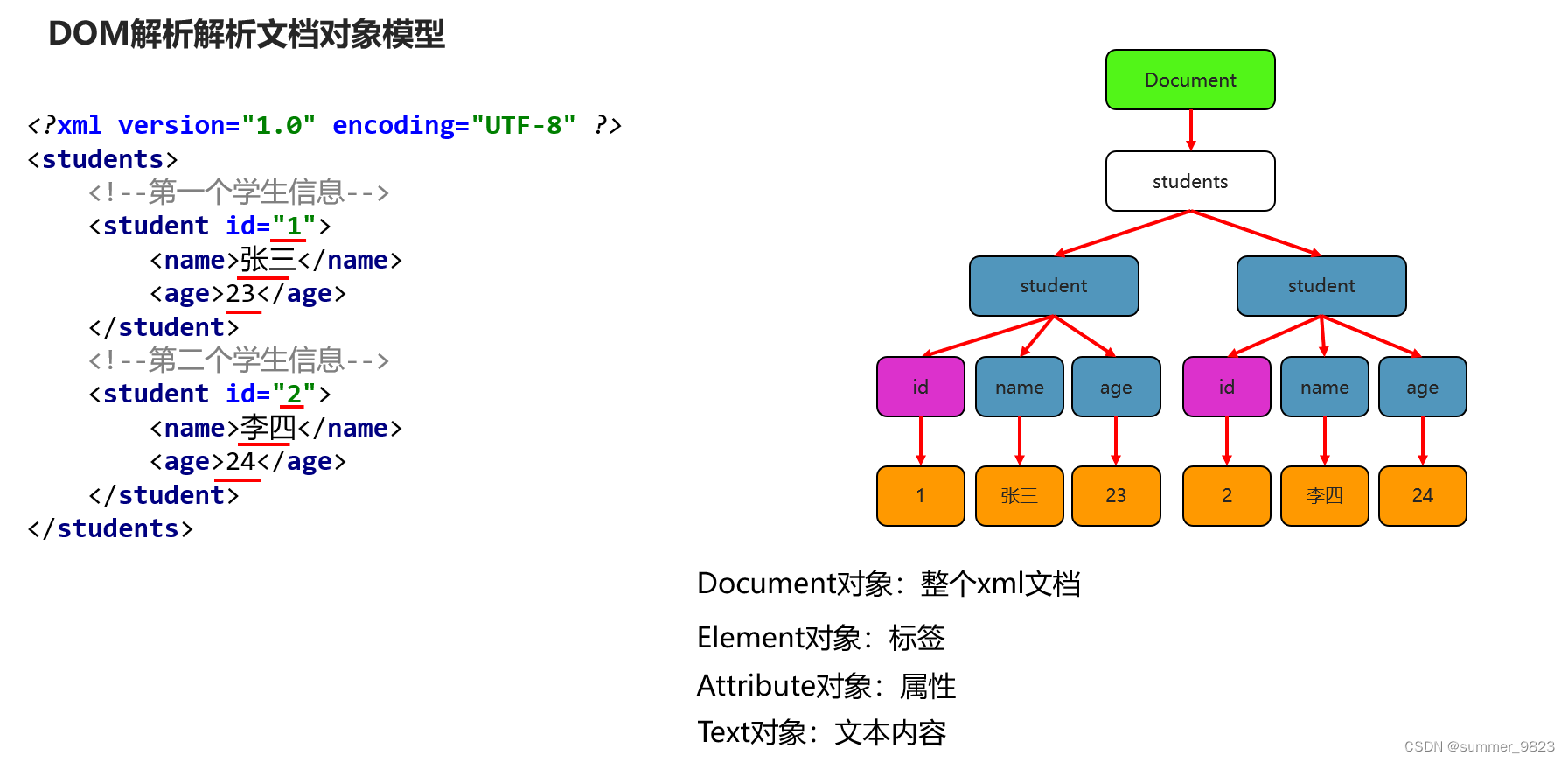
<?xml version="1.0" encoding="utf-8" ?> <students> <!--第一个学生信息--> <student> <name>张三</name> <age>23</age> </student> <!--第二个学生信息--> <student> <name>李四</name> <age>24</age> </student> </students>
3、优点
- 作为软件的配置文件
- 用于进行存储数据和传输数据(其内部格式更便于传输数据)
4、XML语法
4.1 语法规则
- 创建创建一个XML类型的文件,要求文件的后缀必须使用xml。如hello_world.xml
- 文档声明文档声明必须是第一行第一列
<?xml version="1.0" encoding="UTF-8" ?>- version:版本,该属性是必须存在- encoding:该属性不是必须的,指定打开当前的xml文件应该用什么字符编码表(一般都是UTF-8)- standalone:该属性不是必须的,描述XML文件是否依赖其他的XML文件,取值为yes/no- 标签规则- 必须存在一个根标签,有且只能有一个- 标签由一对尖括号和合法标识组成- 标签必须成对出现
<student></student>- 特殊的标签可以不成对,但是必须有结束标记<address/>- 标签中可以定义属性,属性和标签名空格隔开,属性值必须用引号引起来<studnet id="1"></studnet>- 标签需要正确的嵌套<!--这是正确的嵌套--> <student id="1"> <name>张三</name></student> <!--这是错误的嵌套--> <student id="1"> <name>张三 </student></name>- 细节- XML文件中可以定义注释信息
<!--这是一条注释信息-->- XML文件中可以存在以下特殊字符< < 小于> > 大于& & 和号&apos ' 单引号" " 引号- XML文件中可以存在CDATA区<![CDATA[...内容...]]>
4.2 Demo
需求:编写一个城市对应区的xml文件【城市city;区域area】
<?xml version="1.0" encoding="utf-8" ?> <citys> <city name="北京市"> <area>东城区</area> <area>西城区</area> <area>朝阳区</area> <area>海淀区</area> <area>昌平区</area> </city> </citys>
5、XML约束(了解)
XML约束用来限定xml文件中可使用的标签以及属性,约束文件以后不需要我们自己写,了解即可。有DTD约束和Schema约束
5.1 DTD约束
① 编写DTD约束
- 步骤1.创建一个后缀名为.dtd的文件2.看xml文件中使用了哪些元素<!ELEMENT>可以定义元素3.判断元素是简单元素还是复杂元素【简单元素】没有子元素【复杂元素】有子元素的元素
- 代码实现
<!--这是一个dtd文件 persondtd.dtd--><!ELEMENT persons (person)><!ELEMENT person (name,age)><!ELEMENT name (#PCDATA)><!ELEMENT age (#PCDATA)>
② 引入DTD约束
在xml文件内部直接引入> >
> <!DOCTYPE 根元素名称 [ dtd文件内容 ]>>> >> <?xml version="1.0" encoding="UTF-8" ?>> <!DOCTYPE persons [> <!ELEMENT persons (person)>> <!ELEMENT person (name,age)>> <!ELEMENT name (#PCDATA)>> <!ELEMENT age (#PCDATA)>> ]>> > <persons>> <person>> <name>张三</name>> <age>23</age>> </person>> > </persons>>- 引入本地dtd>
> <!DOCTYPE 根元素名称 SYSTEM 'DTD文件的路径'>>> >> <!--在person1.xml文件中引入persondtd.dtd约束-->> <?xml version="1.0" encoding="UTF-8" ?>> <!DOCTYPE persons SYSTEM 'persondtd.dtd'>> > <persons>> <person>> <name>张三</name>> <age>23</age>> </person>> > </persons>> - 引入网络dtd>
> <!DOCTYPE 根元素的名称 PUBLIC "DTD文件名称" "DTD文档的URL">>> >> <?xml version="1.0" encoding="UTF-8" ?>> <!DOCTYPE persons PUBLIC "dtd文件的名称" "dtd文档的URL">> > <persons>> <person>> <name>张三</name>> <age>23</age>> </person>> > </persons>>
5.2 Schema约束
①编写schema约束
- 步骤1.创建一个文件,这个文件的后缀名为.xsd2.定义文档声明3.**schema文件的根标签为<schema>**4.在<scheam>中定义如下属性:- xmlns=http://www.w3.org/2001/XMLSchema- targetNamespace = 唯一的url地址,指定当前这个schema文件的名称空间(理解起个名字,顺便打广告)- elementFormDefault="qualified“,表示当前schema文件是一个质量良好的文件5.通过element定义元素6.判断当前元素是简单元素还是复杂元素
- 代码实现
<?xml version="1.0" encoding="UTF-8" ?><schema xmlns="http://www.w3.org/2001/XMLSchema" targetNamespace="http://www.itheima.com" elementFormDefault="qualified"> <element name="students"> <complexType> <sequence> <element name="student" maxOccurs="unbounded"> <complexType> <sequence> <element name="name" type="string"></element> <element name="age" type="int"></element> </sequence> <attribute name="id" use="required"/> </complexType> </element> </sequence> </complexType> </element></schema>
②引入schema约束
<?xml version="1.0" encoding="UTF-8" ?>
<!--这里xsi只是因为需要引入多个约束怕属性重名所以取的别名-->
<students xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://www.itheima.com"
xsi:schemaLocation="http://www.itheima.com students.xsd">
<student id="1">
<name>张三</name>
<age>23</age>
</student>
<student id="2">
<name>李四</name>
<age>24</age>
</student>
</students>
5.3 Schema和dtd的区别
- schema约束文件也是一个xml文件,符合xml的语法,这个文件的后缀名.xsd。Schema文件用来约束一个xml文件,同时它自己也被其他文件约束着
- 一个xml中可以引用多个schema约束文件,多个schema使用名称空间区分(名称空间类似于java包名)
- dtd里面元素类型的取值比较单一常见的是PCDATA类型,但是在schema里面可以支持很多个数据类型
- schema 语法更加的复杂
6、XML解析
解析方式有两种:SAX解析和DOM解析
SAX解析DOM解析解析方式不会把整体的xml文件都加载到内存中,而是从上往下逐行进行扫描会把整体的xml文件都加载到内存****优点因为逐行解析,无需将整体的xml文件都加载到内存,所以可以解析较大的xml文件可以读取,可以添加,可以删除,可以做任何事情缺点只能读取,不能添加,不能删除需要xml文件全部加载到内存,所以不能解析非常大的xml文件
6.1 DOM解析
6.1.1 解析文档对象模型
6.1.2 常见解析工具
名称说明JAXPSUN公司提供的一套XML解析的APIJDOMJDOM是一个开源项目,它基于树型结构,利用纯JAVA的技术对XML文档实现解析、生成、序列化以及多种操作Dom4j是JDOM的升级品,用来读写XML文件的。具有性能优异,功能强大和极其易使用的特点,它的性能超过sun公司官方的dom技术,同时它也是一个开放源代码的软件,Hibernate也用它来读写配置文件jsoup功能强大DOM方式的XML解析开发包,尤其对HTML解析更加方便
6.1.3 准备动作
①导入jar包
②获取Document对象
SAXReader reader = new SAXReader(); Document document = reader.read(url); System.out.println(document);
6.1.4 方法
方法说明Element getRootElement()获取根元素对象方法说明**List<Element> elements()*得到当前元素下所有子元素List<Element> elements(String name)得到当前元素下指定名字的子元素返回集合*Element element(String name)*得到当前元素下指定名字的子元素,如果有很多名字相同的返回第一个String getName()得到元素名字*String attributeValue(String name)**通过属性名直接得到属性值String elementText(子元素名)得到指定名称的子元素的文本String getText()得到文本
6.1.5 Demo(解析xml信息存入集合)
public class ParseXml {
public static void main(String[] args) throws DocumentException {
//准备集合
ArrayList<Student> list = new ArrayList<>();
SAXReader reader = new SAXReader();
Document document = reader.read("day16\\src\\com\\itheima\\xml\\students.xml");
//1、获取根标签
Element rootElement = document.getRootElement();
//2、获取根标签下的所有子标签
List<Element> elements = rootElement.elements();
//3、遍历集合
for (Element element : elements) {
//4、获取标签属性
String id = element.attributeValue("id");
//5、获取name标签的值
String name = element.element("name").getText();
//6、获取age标签的值
String age = element.element("age").getText();
//7、封装为Student学生对象
Student stu = new Student(id,name,Integer.parseInt(age));
//8、添加到集合
list.add(stu);
}
list.forEach(System.out::println);
}
}
三、注解
Annotation标识注解,是JDK1.5的新特性,作用是对程序进行标注。其实可以对照注释理解(注释是给人看的,而注解是给编译器或虚拟机看的),通过注解可以给类增加一些额外的信息,让编译器或jvm可以根据注解来完成对应的功能
1、JDK常见注解
- @Override:表示方法的重写
- @Deprecated:表示修饰的方法已过时
- @SuppressWarinings("all"):压制警告
除此之外,还需要掌握第三方框架中提供的注解:比如Junit中
- @Test表示运行测试方法
- @Before表示在Test之前运行,进行初始化
- @After表示在Test之后运行,进行收尾
2、自定义注解(了解)
自定义注解单独存在没有意义,一般会跟反射结合起来使用
2.1 格式
public @interface 注解名称 { public 属性类型 属性名 () default 默认值 ; } public @interface Anno { String show() default "show..." ; }
属性类型可以是:基本数据类型、String、Class、注解、枚举、以及上述类型的一维数组
public @interface MyAnno { public static final int num1 = 100; public static final String num2 = "abc"; public static final MyAnno num3 = null; public static final Class num4 = String.class; public static final int[] num5 = {}; public abstract String show1() default "show1"; public abstract int show2() default 132; public abstract MyAnno2 show3() default @MyAnno2; public abstract Class show4() default String.class; public abstract int[] show5() default {1, 2, 3}; }public @interface MyAnno { int num1 = 100; String num2 = "abc"; MyAnno num3 = null; Class num4 = String.class; int[] num5 = {}; String show1() default "123"; int show2() default 132; MyAnno2 show3() default @MyAnno2; Class show4() default String.class; int[] show5() default {1, 2, 3}; }
注意事项:
- 在使用注解时,如果注解的属性没有给出默认值,需要手动给出;如@Anno(name="张三")
- 如果数组中只有一个属性值,在使用时{}是可以省略的
- 定义注解中,如果有多个属性没有赋值,使用时需要全部赋值
- 定义注解中如果只有一个属性名称为value,没有赋值,使用时直接给出值,不需要写属性名。如@Anno("要给value赋的值")
3、元注解(了解)
元注解就是描述注解的注解
元注解名说明@Target指定了注解能在哪里使用@Retention可以理解为保留时间(生命周期)
3.1 Target注解
用来标识注解使用的位置,如果没有使用该注解标识,则自定义的注解可以使用在任意位置,可使用的值定义在ElementType枚举类中,常用值如下:
- TYPE,类,接口
- FIELD,成员变量(很少用)
- METHOD,成员方法
- PARAMETER,方法参数
- CONSTRUCTOR,构造方法
- LOCAL_VARIABLE,局部变量
3.2 Retention注解
用来标识注解的生命周期(有效范围),可使用的值定义在RetentionPolicy枚举类中,常用值如下:
- SOURCE:注解只作用在源码阶段,生成的字节码文件中不存在
- CLASS:注解作用在源码阶段,字节码文件阶段,运行阶段不存在,默认值
- RUNTIME:注解作用在源码阶段,字节码文件阶段,运行阶段
4、案例(自定义注解)
需求:自定义一个注解@MyAnno,用于指定类的方法上,如果某一个类的方法上使用了该注解,就执行该方法
实现步骤:1.自定义一个注解MyAnno,并在类中的某几个方法上加注解2.在测试类中,获取注解所在的类的Class对象3.获取类中所有的方法对象4.遍历每一个方法对象,判断是否有对应的注解
//自定义注解@Target(ElementType.METHOD)@Retention(RetentionPolicy.RUNTIME)public @interface MyAnno {}
//Test类public class MethodTest { @MyAnno public void show1(){ System.out.println("show1..."); } @MyAnno public void show2(){ System.out.println("show2..."); } public void show3(){ System.out.println("show3..."); }}
public class ReflectTest { /* 简易的测试框架,通过反射操作字节码对象,执行需求的逻辑 */ public static void main(String[] args) throws Exception{ //1、通过反射获取字节码文件对象 Class<MethodTest> methodTestClass = MethodTest.class; //2、创建对象 MethodTest mt = methodTestClass.getConstructor().newInstance(); //3、通过反射获取这个类里面所有的方法对象 Method[] methods = methodTestClass.getMethods(); //4、遍历数组,得到每一个方法对象 for (Method method : methods) { //核心:判断这个方法头上有没有注解 if(method.isAnnotationPresent(MyAnno.class)){ //执行方法 method.invoke(mt); } } }}
版权归原作者 summer_9823 所有, 如有侵权,请联系我们删除。