
写在前面
这篇文章我们一起来了解一下搜索引擎的原理,以及用go写一个小demo来体验一下搜索引擎。
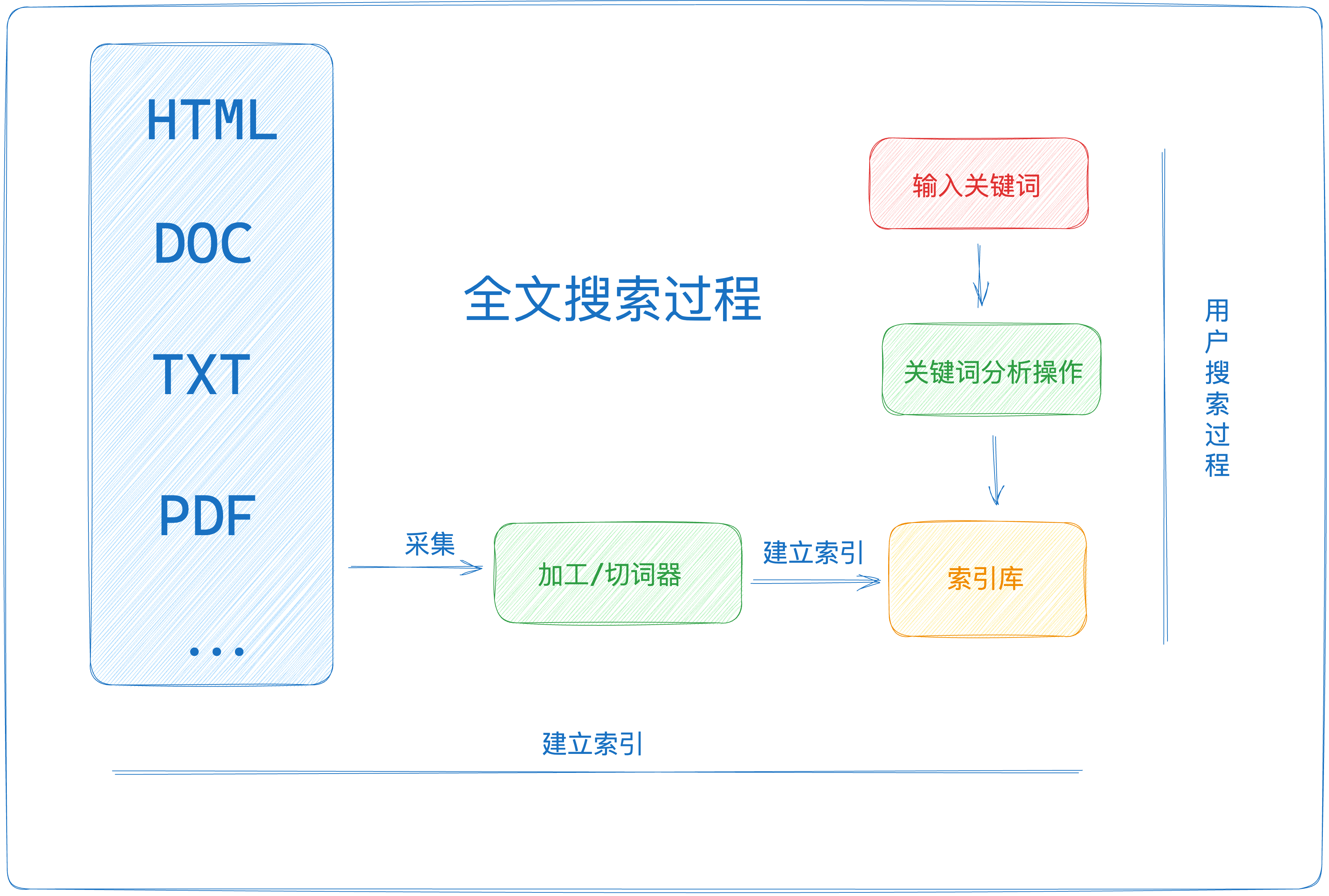
简介
搜索引擎一般简化为三个步骤
- 爬虫:爬取数据源,用做搜索数据支持。
- 索引:根据爬虫爬取到的数据进行索引的建立。
- 排序:对搜索的结果进行排序。
然后我们再对几个专业名词做一个简单解释
- document:用于构建索引库的数据
- term:将一段文本进行分词,分词之后的每个最小单元叫做 Term,比如“苹果发布会”,分词之后就是【苹果,发布会】,“苹果”和“发布会”就是最小单元的 term。
- token:token 是 term 的一次出现,它包含 term 文本和相应的起止偏移,以及一个类型字符串。一句话中可以出现多次相同的词语,它们都用同一个 term 表示,但是用不同的 Token,每个 Token 标记该词语出现的地方。比如 token中不仅有term还有这个term在这个文档的位置。
1. 爬虫
爬虫就很简单了,不是重点,我们准备好数据源即可。
2. 索引
2.1 正排索引&倒排索引
索引分成正排索引和倒排索引。
正排索引:将文档按照文档顺序进行组织的索引结构。
倒排索引:根据词条来组织文档数据的索引结构。
举个例子:
假设我们有三个文档:
文档1,内容为"postman datagrip goland";
文档2,内容为"goland vscode";
文档3,内容为"pycharm goland"。
使用正排索引和倒排索引来存储这些文档:
- 正排索引:
文档1:“postman datagrip goland”
文档2:“goland vscode”
文档3:“pycharm goland”
在正排索引中,我们按照文档的顺序存储了每个文档的完整内容。
- 倒排索引:
postman:文档1,
datagrip:文档1,
goland:文档1,文档2,文档3
vscode:文档2
pycharm:文档3
在倒排索引中,我们将每个词条映射到包含该词条的文档集合上。例如,"postman"出现在文档1中
2.2 构建索引
- 读取数据源
首先观察数据源,确定了我们的索引对象是第16个,也就是电影的主要内容。
读取数据源,构造索引数据
funcfileOpen()[]string{
file, err := os.Open("movies.csv")if err !=nil{
fmt.Println("err", err)}defer file.Close()// 创建一个 Scanner 用来读取文件内容
docx :=make([]string,0)
scanner := bufio.NewScanner(file)// 逐行读取文件内容并打印for scanner.Scan(){
re :=make([]string,0)
line := scanner.Text()
re = strings.Split(line,",")
docx =append(docx, re[16])}
docx = docx[1:]return docx
}
- 分词
当我们读取数据之后,要对数据进行分词,分成一个个的词,用作建立索引库。
但分词之前我们要先数据清洗一下,比如中文就是去掉一些语气词,标点符号;英文则是去除一些语气词,做预干转移(过去式,未来式都变成现在式,比如learning --> learn),转成小写之类的。
先定义一下StopWord,如果出现StopWord里面的词,就进行删除替换。
var StopWord =[]string{",",".","。","*","(",")","'","\""}
定义一个 removeShopWord 的 func,传入 word,也就是段落,先进行数据的清洗,再将word进行分词。
funcremoveShopWord(word string)string{for i :=range StopWord {
word = strings.Replace(word, StopWord[i],"",-1)}return word
}
定义一个 tokenize 进行分词操作。使用 github.com/go-ego/gse 包进行分词操作。
var gobalGse gse.Segmenter
funcInitConfig(){
gobalGse,_= gse.New()}functokenize(text string)[]string{
text =removeShopWord(text)return gobalGse.CutSearch(text)}
3. 索引构建
定义一个map结构,key 是一个 term,value 是包含有 term 关键字的文档的 id 数组。
type InvertedIndex map[string][]int
构建索引
funcBuildIndex(docx []string) InvertedIndex {
index :=make(InvertedIndex)for i, d :=range docx {// 遍历所有的docxfor_, word :=rangetokenize(d){// 对所有的docx进行tokenif_, ok := index[word];!ok {// 如果index不存在这个term了
index[word]=[]int{i}// 初始化并放入 行数}else{
index[word]=append(index[word], i)// 如果index不存在,则放入该term所在的 行数,也就是 行数}}}return index
}
这里我们的 token 和 term 是一样的了,因为token中只有term,没有定义别的东西,比如term在doc的位置等等…
3.1 搜索 排序
- 搜索
我们定义 query 为搜索的内容,对query进行分词操作,然后再存储符合要求的docx文档的id。
那我们的search函数的传入就是 倒排索引 index,搜索词条 query,正排索引 docs
funcsearch(index InvertedIndex, query string, docs []string)([]string,[]string){
result :=make(map[int]bool)
qy :=tokenize(query)// query词条进行分词for_, word :=range qy {// 遍历分完词的每一个termif doc, ok := index[word]; ok {// 搜索倒排索引中,term对应的doc数组,doc数组就是存在该term词条的所有的doc idfor_, d :=range doc {// 对doc数组进行遍历,获取所有的doc id,并且进行标志。
result[d]=true}}}
output :=[]string{}for d :=range result {
output =append(output, docs[d])// 利用正排索引,找到id对应的存储内容并返回}return output, qy
}
3.2 排序
当我们搜索完结果后,自然会有结果,但是这些结果的排序是不合理的,我们要进行重新排序。排序的规则也有很多,比如文档相似度,竞价排名等等…
那么我们这里就用 最简单的TFIDF来进行计算所搜索出来的doc和term之间的权重。
首先了解一下TFIDF:
TF(词频)指的是某个词在文档中出现的频率。在计算TF时,我们可以简单地使用词出现的次数除以文档中的总词数。IDF(逆文档频率)
指的是某个词在文档集合中的多少文档中出现过的程度。计算IDF时,我们可以将所有文档数目除以包含该词的文档数目。TF-IDF的计算方式是将TF和IDF相乘,得到一个词在文档中的重要性分数。这个分数能够衡量一个词对于文档的重要性:如果一个词在某个文档中频繁出现,并且在整个文档集合中罕见,那么它可能是一个具有较高重要性的词。
计算TF:
term在这个文档中的出现的次数/这个document所有的分词的数量
funccalculateTF(term string, document string)float64{
termCount := strings.Count(document, term)
totalWords :=len(tokenize(document))returnfloat64(termCount)/float64(totalWords)}
计算IDF:
所有文档的数量/term在所有文档中出现的次数
funccalculateIDF(term string, documents []string)float64{
docWithTerm :=0for_, doc :=range documents {if strings.Contains(doc, term){
docWithTerm++}}returnfloat64(len(documents))/float64(docWithTerm)}
TF*IDF即可获取权重,下面这里是由于数据问题,我是乘以100的
funccalculateTFIDF(term string, document string, documents []string)float64{
tf :=calculateTF(term, document)
idf :=calculateIDF(term, documents)return tf * idf *100.0}
先定义好排序所需要的请求体
type SortRes struct{
Docx string
Score float64
Id int}
具体排序:
qy为输入的query分词后的token形式,res则是搜索结构,返回值是将res排序好的结果。
funcsortRes(qy []string, res []string)[]*SortRes {
exist :=make(map[int]*SortRes)for_, v :=range qy {// 遍历每一个query的分词后的token词条for i, v2 :=range res {// 遍历每一个结果
score :=calculateTFIDF(v, v2, res)// 记录分数构成,计算每个词条对每个文档结构的scoreif_, ok := exist[i];!ok {// 如果exist中还没存在这个词条,则进行进行初始化
tmp :=&SortRes{
Docx: v2,
Score: score,
Id: i,}
exist[i]= tmp
}else{// 如果已经存在了,则进行分数的相加// 意思就是每个res中的doc对于每个token的权重之和的结果。权重的对象始终都是res中doc
exist[i].Score += score
}}}
resList :=make([]*SortRes,0)for_, v :=range exist {// 构建结构体
resList =append(resList,&SortRes{
Docx: v.Docx,
Score: v.Score,
Id: v.Id,})}
sort.Slice(resList,func(i, j int)bool{// 按照score进行排序return resList[i].Score > resList[j].Score
})return resList
}
- 演示
funcTestSe(t *testing.T){
query :="王小波,徐克"InitConfig()// 初始化配置
docx :=fileOpen()
index :=BuildIndex(docx)// 创建index
res, qy :=search(index, query, docx)
fmt.Printf("一共%d记录,query分词结果%v\n",len(res), qy)
resList :=sortRes(qy, res)for i :=range resList {
fmt.Println(resList[i].Score, resList[i].Docx)}}
结果:
第一行输出一共多少条搜索记录,然后是输入的query的分词结果
接着输出每一个搜索结果的score,以及对应的docx文本。
一共6记录,query分词结果[小波 王小波 徐克]
39.99999999999999 "王小波的作品《红拂夜奔》将被改编为电影,徐克执导"
20.689655172413794 "王小波经典中篇小说《绿毛水怪》将改编电影。《绿毛水怪》是王小波早期手稿作品,以天马行空的想象,极具魔幻色彩的情感脉络,独树一帜的批评、反讽,受到广大书迷的喜爱。王小波曾创作电影剧本《东宫西宫》,此后尚未有作品改编成电影。据悉,李银河将担任《绿毛水怪》电影版的文学顾问。"
8 "博纳公布新片计划 徐克将开拍《智取威虎山3D》"
3.0769230769230766 "徐克将拍摄电影版《神雕侠侣》三部曲,施南生监制。这是徐克自执导《东方不败风云再起》后,24年来再次拍摄金庸武侠作品,杨过和龙女的故事将登大银幕。自1983年香港邵氏出品制作《杨过与小龙女》电影版后,这部作品34年来都再未出现在大银幕上。"
2.222222222222222 "《抓猴》是一 部徐克导演的现代题材的3D惊悚片,剧情悬疑诡异。影片的主要故事在三个女主演身上展开,在窥视、背叛、阴谋、死亡的惊险不断中,导向一个让人意想不到的结局"
1.4906832298136643 "在去年北影节“跨界与融合—中国电影投融资高峰论坛”上,博纳副总裁丁一岚透露,徐克计划拍《智取威虎山》前传。丁一岚谈到“投资瞄准度”话题时表示博纳是一个“传统的电影公司”,“传统的电影公司会去养一个市场,不会一本万利,我们人人都期待有爆款,可爆款是建立在一将功成万骨枯的基础上,我也不指望所有的项目里面一定有爆款,所以只能按照基础的商业规则去运作每一个项目。接着我们可能启动《智取威虎山》前传,可能还是徐克来导,因为这是用一种新的方式,开发一些被大家忽略的地方。"
当然这个是一个很粗糙的demo,还有很多东西没有,比如如何merge多个倒排索引,如何存储倒排索引,分词如何更好一点,计算排名的权重如何选择和优化等等…
参考
版权归原作者 小生凡一 所有, 如有侵权,请联系我们删除。