
论文作者 | Lu Qi, Jason Kuen , Zhe Lin, and etal
论文来源 | CVPR2022
文章解读 | William
1、摘要
为了提高检测/分割的性能,现有的自监督和半监督方法从未标记的数据中提取任务相关或任务特定的训练标签,但这两种方法对于任务性能都是次优的,使用过少的特定任务训练标签会导致下游任务的ground-truth标签欠拟合,反之则会导致对ground-truth标签过拟合。
为此,本文提出了一种新的未知类的半监督学习(Class-Agnostic Semi-Supervised Learning,CA-SSL)框架,以便于在从无标记数据中提取训练标签时实现更有利的任务特异性平衡。CA-SSL有三个训练阶段,分别作用于真实标签(标记数据)或伪标签(未标记数据)。这种解耦策略避免了传统SSL方法中平衡两种数据类型贡献的复杂方案。此外,还引入了一个预训练阶段,通过忽略伪标签中的类信息,在保留本地化训练标签的同时实现更优的任务特异性平衡。因此,在检测和分割任务中对ground-truth标签进行微调时,预训练模型可以更好地避免欠拟合/过拟合。,在FCOS对象检测上使用360万未标记数据进行训练,可以实现比imagenet预训练基线模型高4.7%的显著性能增益。此外,预训练模型展示了对其他检测和分割框架的良好可移植性
2、主要贡献
①提出了一种新的未知类的半监督学习框架,用于实例级检测/分割任务。通过利用级联训练阶段和未知类的伪标签,能够从无标签数据中提取的训练标签来保证更优的任务特异性。
②对目标检测进行了广泛的消融和对比实验,证明了该方法的有效性。目前,这是第一个以3.6M无标记数据规模进行半监督对象检测的框架。
③经过预训练的未知类预训练模型可以显著提高其他实例级检测/分割任务和框架的性能
3、方法
该框架包括三个阶段,包括伪标签训练、预训练和微调。在第一阶段,使用标记的数据,但只使用未知类的注释来训练伪标签器,然后在未标记的图像上预测未知类的伪标签。在预训练中,这些大量未标记的图像及其伪标签被用来训练目标检测器,这里只使用基于本地化的伪标签作为训练数据,而忽略类标签。最后,使用特定类的注释对标记数据集上的预训练目标检测器进行微调。
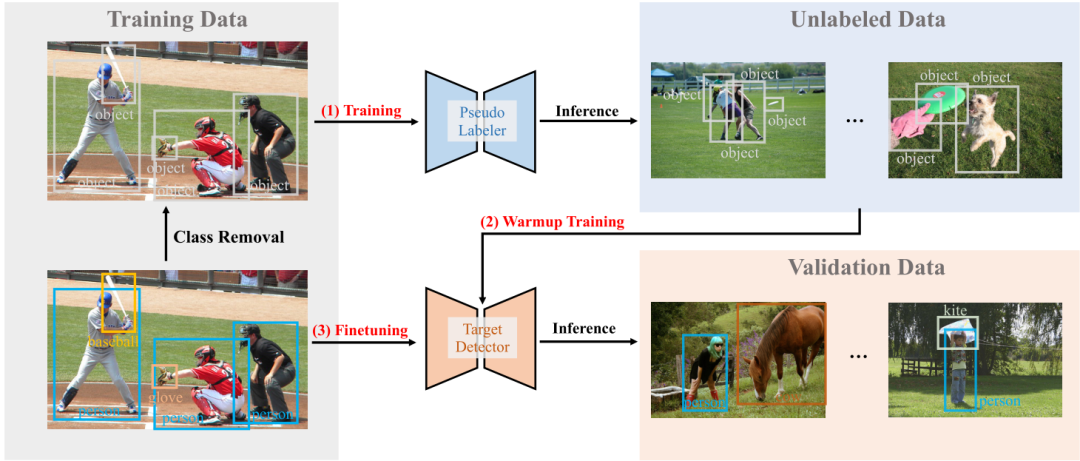
图1 CA-SSL框架
通常,给定来自手工标记的训练数据集Dt的输入图像I及其ground-truth注释Y,用于复合检测损失(分类损失和定位损失)训练记为h *的检测模型。检测模型h 是通过函数H()来学习,它决定了神经网络的假设空间。
3.1 伪标签训练
这个阶段的目标是在Dt上训练一个伪标签器,从未标记的数据集Du中分割生成高质量未知类的伪标签Dp。为了保持训练和推理的一致性,使用从Dt中获得的未知类来注释和训练伪标签器。使用未知类转换函数α(·)直接从Dt中的注释中删除类信息,并将每个标签视为无类的对象。为了训练伪标签器,使用特定于类的检测框架,并用二进制分类器替换其多类分类器。给定标签数据集Dt,伪标签器训练如下:
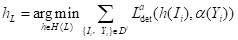
(1)
其中表示Ldet的未知类标签,H(L)表示以标记检测任务为条件的神经网络假设。
训练完成后,将伪标签器应用于未标记的图像,然后使用单个评分阈值δ对预测结果进行过滤。未知类的伪标签在预测结果中没有语义类标签,避免了类特定预测中存在的长尾问题。给定伪标签器和得分阈值δ,可以获得伪标签Y p和伪标签数据集Dp得知未知类伪标签过程:
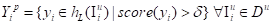
(2)
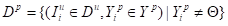
(3)
其中“p”表示与伪标签的关联,score(·)返回任何预测的客观性得分。
3.2 预训练
这里只在伪标签数据集Dp上进行目标检测器的预训练,且不使用任何ground-truth数据集。为了得到预训练目标“T”得检测模型hT,进行了如下训练:
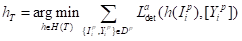
(4)
其中[·]是将转换为二进制训练目标。这里的预训练与自监督学习的前训练步骤有关,对于模型的权重也进行了初始化,这样可以提供相对更丰富的信息和特定于任务的监督信号。
3.3 微调
得到预训练模型hT后,使用Dt特定类的ground-truth标注对其进行微调,以用于下游任务。目标检测器的语义分类器输出通道应适应当前下游任务的预定义类的数量。多类别分类初始化有随机初始化和分类层的输出通道初始化两种方式。获得最终下游任务模型hF的微调过程表示为:
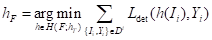
(5)
H (F;hT)表示同时以任务“F”和预训练模型hT为条件的神经网络假设。由于只使用了未标记的数据来训练目标检测器,保证了它不太容易过度拟合下游任务的图像和ground-truth标签。
4、实验结果与分析
4.1 预训练数据
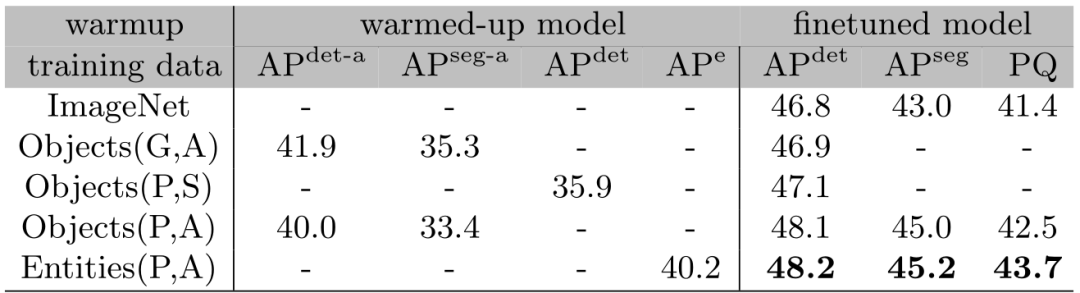
其结果如表1所示。前两行可以观察到ImageNet预训练模型和未知类别的ground-truth标签上预训练模型的下游性能最差。然而,在最后三行中,利用伪标签进行训练的模型始终能够获得更强的下游性能。
表1 微调后预训练数据的选择对下游任务的影响
4.2 上限性能
这里研究在预训练和微调阶段实现上限性能所需的训练轮数。表2显示了不同预训练次数下未知类的性能。当epoch数从12增加到48时,训练后的模型在未知类的APe方面的性能从38.4提高到40.2,但在40轮数后达到饱和。
表2 不同预训练次数下的未知类性能
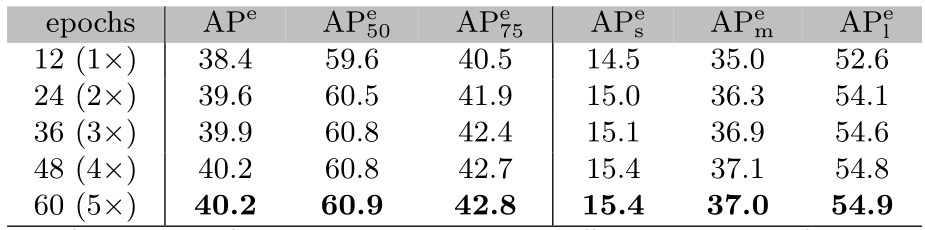
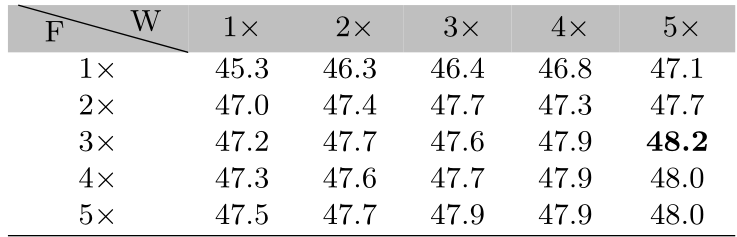
表3显示了不同预训练和微调时间组合下对下游特定对象类的检测性能。在预训练中60 epoch (5×),在微调阶段中36 epoch (3×),可以获得48.2的最佳性能。
表3不同预训练和微调组合下的检测性能
4.3 最优性能对比
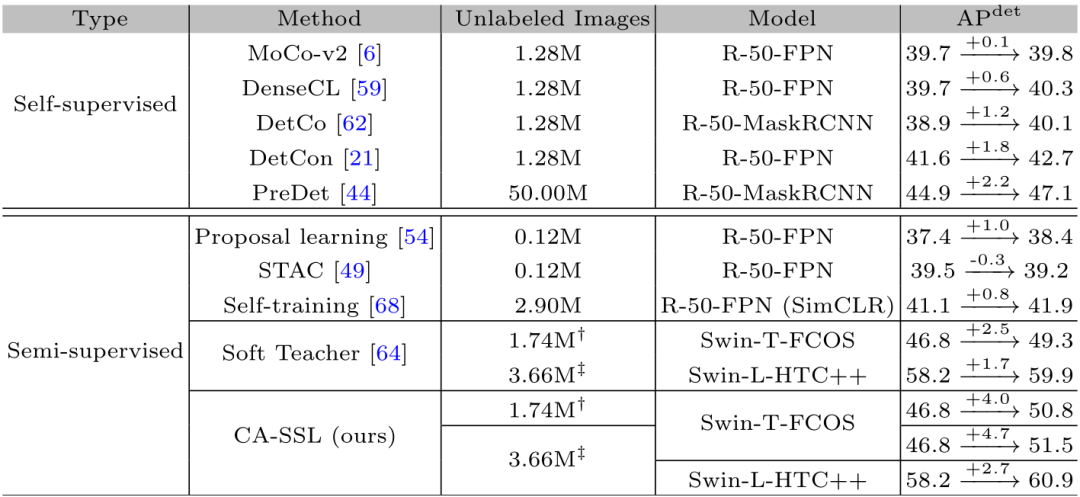
表4中比较了CA-SSL在下游检测任务上的性能与数据增强中最先进的方法性能对比,该方法取得了最显著的性能提升,即使模型是基于Swin-Tiny骨干网络。使用1.74M未标记图像,能够获得50.8 APdet,比ImageNet预训练的基线提高4.0%。此外,通过将未标记图像的数量增加到3.66M,性能增益可以提高4.7%。由于没有明显的性能饱和迹象,因此可以认为使用超大规模的无标记数据集(大于3.66M的数据集或更大)会潜在地显著提高模型性能。
表4 与最先进方法性能对比
4.4 泛化性
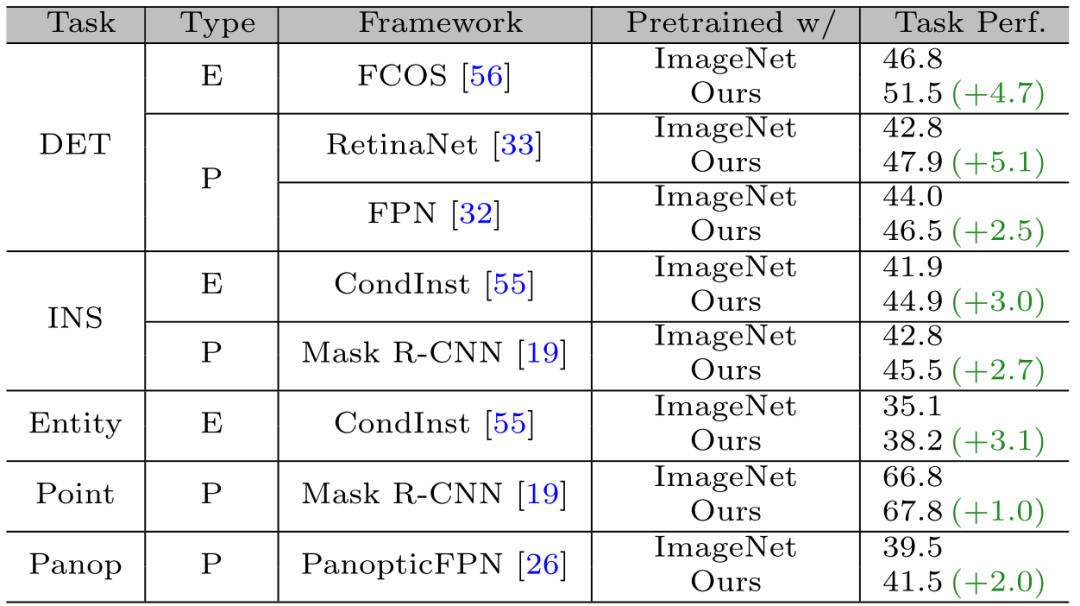
表5显示了在各种实例级检测和分割任务上,使用CA-SSL预训练的单个模型在初始化下游模型所带来的性能改进。比如仅使用FPN骨干预训练权重来初始化Mask R-CNN,最终在实例分割和关键点检测方面实现了2.7 APseg和1.0 APpoint改进。这说明该半监督学习方法具有较强的泛化性。
表5 不同实例级任务下的性能改进
5、结论
提出了一种未知类的半监督学习框架,以提高实例级检测/分割的无标签数据性能。该框架采用不确定类别的伪标签,并包括三个级联训练阶段,其中每个阶段使用特定类型的数据。通过对未标记数据上的大量未知类伪标签进行预训练,未知类模型具有较强的泛化能力,并具备适量的任务特定知识。
当针对不同的下游任务进行微调时,该模型可以更好地避免对ground-truth标签的过拟合,从而获得更好的下游性能。最后,广泛的实验证明了框架对不同的未标记分割的目标检测的有效性。此外,预训练类的未知模型展示了对其他实例级检测框架和任务的出色可移植性。
版权归原作者 深蓝学院 所有, 如有侵权,请联系我们删除。