
模板初阶与STL简介::
1.泛型编程
如何实现一个通用的交换函数呢?
void Swap(int& left, int& right)
{
int temp = left;
left = right;
right = temp;
}
void Swap(double& left, double& right)
{
double temp = left;
left = right;
right = temp;
}
void Swap(char& left, char& right)
{
char temp = left;
left = right;
right = temp;
}
使用函数重载虽然可以实现,但是有以下几个不好的地方:
1.重载的函数仅仅是类型不同,代码复用率比较低,只要有新类型出现时,就需要用户自己增加对应的函数
2.代码的可维护性低,一个出错可能所有的重载均出错
那能否告诉编译器一个模具,让编译器根据不同的类型利用该模具来生成代码呢?
如果在C++存在一种模具,通过给这个模具中填充类型,来生成具体类型的代码,那将会极大程度的提高效率。
泛型编程:编写与类型无关的通用代码,是代码复用的一种手段。模板是泛型编程的基础。
2.函数模板
函数模板的概念:
函数模板代表了一个函数家族,该函数模板与类型无关,在使用时被参数化,根据函数类型产生函数的特定类型的版本。
函数模板样式:
template<typename T1, typename T2,......,typename Tn>
返回值类型 函数名(参数列表){}
template<typename T>
void Swap(T& left, T& right)
{
T temp = left;
left = right;
right = temp;
}
注意:typename是用来定义模板参数关键字,也可以使用class(切记:不能使用struct代替class)
函数模板的原理:
函数模板是一个蓝图,它本身并不是函数,是编译器用使用方式产生特定具体类型函数的模具,所以模板就是将本来应该我们重复做的事情交给了编译器。
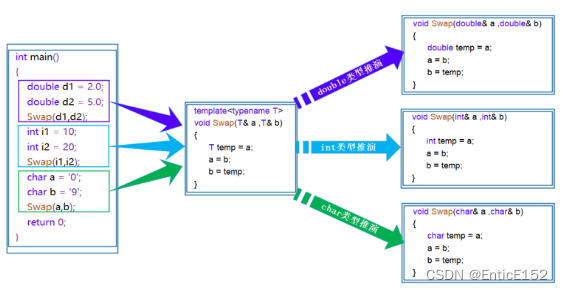
在编译器编译阶段,对于模板函数的使用,编译器需要根据传入的实参类型来推演生成对应类型的函数以供调用。比如:当调用double类型使用函数模板时,编译器通过对实参类型的推演,将T确定为double类型,然后产生一份专门处理double类型的代码,对于字符类型也是如此。
函数模板的实例化:
用不同类型的参数使用函数模板时,称为函数模板的实例化。模板参数实例化分为:隐式实例化和显示实例化。
1.隐式实例化:让编译器根据实参推演模板参数的实际类型
template<class T>
T Add(const T& left, const T& right)
{
return left + right;
}
int main()
{
int a1 = 10, a2 = 20;
double d1 = 10.0, d2 = 20.0;
Add(a1, a2);
Add(d1, d2);
/*
该语句不能通过编译,因为在编译期间,当编译器看到该实例化时,需要推演其实参类型
通过实参a1将T推演为int,通过实参d1将T推演为double类型,但模板参数列表中只有一个T,
编译器无法确定此处到底该将T确定为int 或者 double类型而报错
注意:在模板中,编译器一般不会进行类型转换操作,因为一旦转化出问题,编译器就需要背黑锅
Add(a1, d1);
*/
// 此时有两种处理方式:1. 用户自己来强制转化 2. 使用显式实例化
Add(a, (int)d);
return 0;
}
2.显示实例化:在函数名后的<>中指定模板参数的实际类型
如果类型不匹配,编译器会尝试进行隐式类型转换,如果无法转换成功编译器将会报错。
int main(void)
{
int a = 10;
double b = 20.0;
// 显式实例化
Add<int>(a, b);
return 0;
}
模板参数的匹配原则:
1.一个非模板函数可以和一个同名的模板函数同时存在,而且该函数模板还可以被实例化为这个非模板函数。
// 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T>
T Add(T left, T right)
{
return left + right;
}
void Test()
{
Add(1, 2); // 与非模板函数匹配,编译器不需要特化
Add<int>(1, 2); // 调用编译器特化的Add版本
}
2.对于非模板函数和同名函数模板,如果其他条件都相同,在调用时会优先调用非模板函数而不会从该模板产生出一个实例。如果模板可以产生一个具有更好匹配的函数,那么将选择模板。
// 专门处理int的加法函数
int Add(int left, int right)
{
return left + right;
}
// 通用加法函数
template<class T1, class T2>
T1 Add(T1 left, T2 right)
{
return left + right;
}
void Test()
{
Add(1, 2); // 与非函数模板类型完全匹配,不需要函数模板实例化
Add(1, 2.0); // 模板函数可以生成更加匹配的版本,编译器根据实参生成更加匹配的Add函数
}
3.模板函数不允许自动类型转换,但普通函数可以进行自动类型转换。
3.类模板
问题:typedef为什么不能更好的支持泛型编程?
typedef int STDataType;
class StackInt
{
public:
Stack(int capacity = 4)
{
cout << "Stack(int capacity = )" << capacity << endl;
_a = (STDataType*)malloc(sizeof(STDataType) * capacity);
if (_a == nullptr)
{
perror("malloc fail");
exit(-1);
}
}
~Stack()
{
cout << "~Stack()" << endl;
free(_a);
_a = nullptr;
_top = _capacity = 0;
}
void Push(STDataType x)
{
//...
//扩容
_a[_top++] = x;
}
private:
STDataType* _a;
int _top;
int _capacity;
};
typedef double STDataType;
class StackDouble
{
public:
Stack(int capacity = 4)
{
cout << "Stack(int capacity = )" << capacity << endl;
_a = (STDataType*)malloc(sizeof(STDataType) * capacity);
if (_a == nullptr)
{
perror("malloc fail");
exit(-1);
}
}
~Stack()
{
cout << "~Stack()" << endl;
free(_a);
_a = nullptr;
_top = _capacity = 0;
}
void Push(STDataType x)
{
//...
//扩容
_a[_top++] = x;
}
private:
STDataType* _a;
int _top;
int _capacity;
};
当我们需要两个栈,一个在栈中插入int类型的数据,一个在栈中插入double类型的数据,那么typedef将不再适用,代码可重复性过高。
因此typedef不能更好的支持泛型编程,只是提高了代码的可维护性,需要在此引入类模板。
template<typename T>
class Stack
{
public:
Stack(int capacity = 4)
{
cout << "Stack(int capacity = )" << capacity << endl;
_a = (T*)malloc(sizeof(T) * capacity);
if (_a == nullptr)
{
perror("malloc fail");
exit(-1);
}
}
~Stack()
{
cout << "~Stack()" << endl;
free(_a);
_a = nullptr;
_top = _capacity = 0;
}
void Push(const T& x)
{
//...
//扩容
_a[_top++] = x;
}
private:
T* _a;
int _top;
int _capacity;
};
int main()
{
//类模板没有推演的时机,函数模板通过实参传递形参,推演模板参数
//类模板统一显示实例化
//他们是同一个类模板实例化出来的 但是模板参数不同 他们就是不同的类
Stack<int> st1;
st1.Push(1);
Stack<double> st2;
st2.Push(1.1);
return 0;
}
类模板的定义格式:
template<class T1, class T2, ..., class Tn>
class 类模板名
{
// 类内成员定义
};
// 动态顺序表
// 注意:Vector不是具体的类,是编译器根据被实例化的类型生成具体类的模具
template<class T>
class Vector
{
public:
Vector(size_t capacity = 10)
: _pData(new T[capacity])
, _size(0)
, _capacity(capacity)
{}
// 使用析构函数演示:在类中声明,在类外定义。
~Vector();
void PushBack(const T& data);
void PopBack();
// ...
size_t Size()
{
return _size;
}
T& operator[](size_t pos)
{
assert(pos < _size);
return _pData[pos];
}
private:
T* _pData;
size_t _size;
size_t _capacity;
};
//注意:类模板中函数放在类外进行定义时,需要加模板参数列表template<class T>
template <class T>
Vector<T>::~Vector()
{
if (_pData)
{
delete[] _pData;
}
_size = _capacity = 0;
}
类模板的实例化:
类模板实例化与函数模板实例化不同,类模板实例化需要在类模板名字后跟<>,然后将实例化的类型放在<>即可,类模板名字不是真正的类,而实例化出的结果才是真正的类。
// Vector类名,Vector<int>才是类型
Vector<int> s1;
Vector<double> s2;
用模板模拟实现静态数组
相比静态数组的优势 越界的检查能检查出来(C语言的静态数组对于越界的检查是抽查 越界写可能检查到 越界读检查不到)
#define N 10
template<class T>
class array
{
public:
inline T& operator[](size_t i)
{
assert(i < N);
return _a[i];
}
private:
T _a[N];
};
int main()
{
array<int> a1;
for (size_t i = 0; i < N; ++i)
{
//等价于a1.operator[](i) = i
a1[i] = i;
}
for (size_t i = 0; i < N; ++i)
{
a1[i]++;
}
for (size_t i = 0; i < N; ++i)
{
cout << a1[i] << endl;
}
return 0;
}
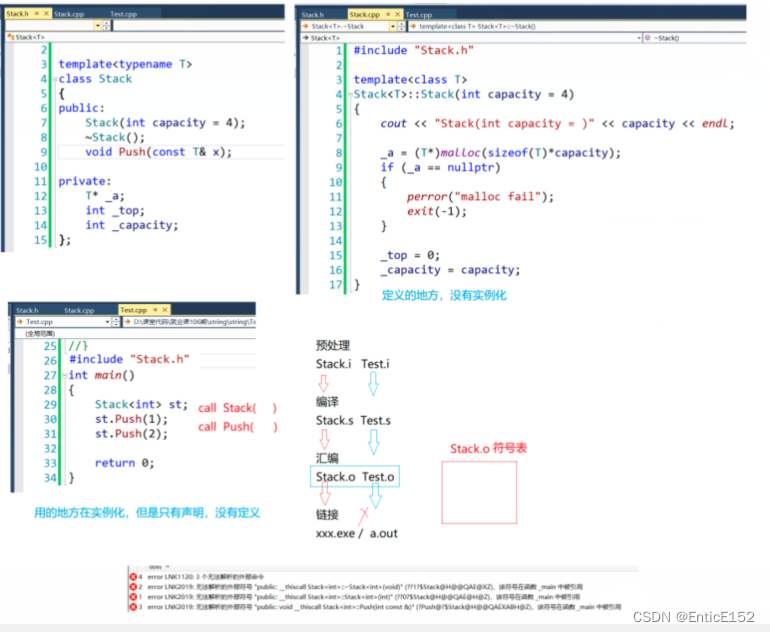
注意:模板不支持分离编译
原因:
因为定义的文件中没有对模板实例化
链接在将符号表的合并和重新定位时没有有效因此没有有效的地址的地址链接出错
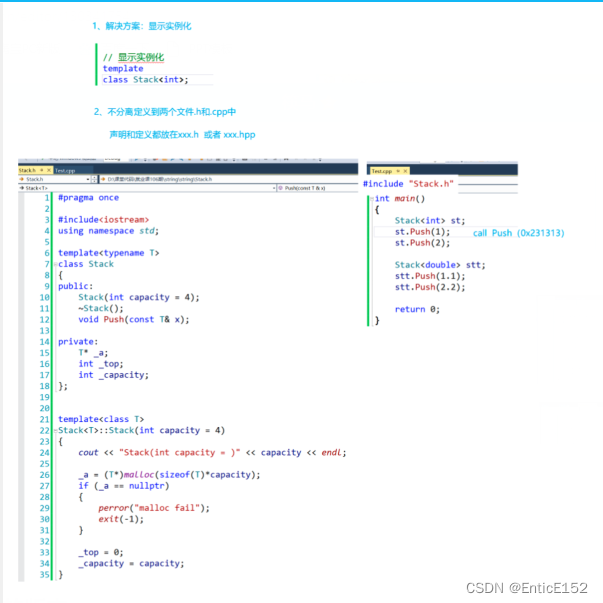
解决方案:
1.在定义的地方显示实例化
2.模板函数不声明和定义到两个文件.h和.cpp中
4.什么是STL
STL(standard template libaray—标准模板库):是C++标准库的重要组成部分,不仅是一个可复用的组件库,而且是一个包含数据结构与算法的软件框架。
5.STL的版本
原始版本:
Alexander Stepanov、Meng Lee在惠普实验室完成的原始版本,本着开源的精神,他们声明允许任何人任意运用、拷贝、修改、传播、商用这些代码,无需付费。唯一的条件就是需要向原始版本一样做开源使用。HP版本—所有STL实现版本的始祖。
P.J.版本:
由P.J.Plauger开发,继承自HP版本,被Windows Visual C++采用,不能公开或修改,缺陷:可读性比较低,符号命名比较怪异。
RW版本:
由Rouge Wage公司开发,继承自HP版本,被C++Bulider采用,不能公开或修改,可读性一般。
SGI版本:
由Silicon Graphics Computer Systems,Inc公司开发,继承自HP版本。被GCC(Linux)采用,可移植性好,可公开、修改甚至贩卖,从命名风格和编程风格上看,阅读性非常高。
6.STL的六大组件
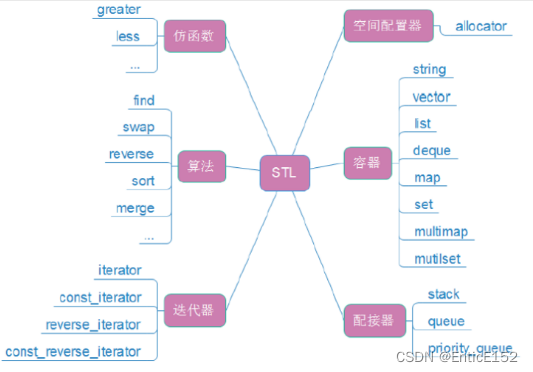
7.STL的缺陷
1.STL库的更新太慢了,上一版是C++98,中间的C++03做了一些修订,C++11出来已经相隔13年了,STL才进一步更新。
2.STL现在都没有支持线程安全,并发环境下需要我们自己加锁,并且锁的粒度是比较大的。
3.STL极度的追求效率,导致内部比较复杂。比如类型萃取,迭代器萃取。
4.STL的使用会有代码膨胀的问题,比如使用vector/vector/vector这样会生成多份代码,当然这是模板语法本身导致的。
版权归原作者 EnticE152 所有, 如有侵权,请联系我们删除。