
1. 前言
1.1. 什么是消息队列
消息队列(MQ)是消息传递中间件解决方案的一个组件,旨在支持独立的应用和服务之间的信息交换。 消息队列按发送顺序存储“消息”(由应用所创建、供其他应用使用的数据包),直到使用方应用能够处理它们为止。 这些消息安全地等待接收方应用做好准备,因此,即使网络或接收方应用出现问题,消息队列中的消息也不会丢失。
1.2. 为什么用消息队列
1.2.1. 解耦
生产者(客户端)发送消息到MQ中去,接受者(服务端)处理消息,需要消费的系统直接去MQ取消息进行消费即可而不需要和其他系统有耦合。
例如订单服务在电商订单创建后,发送扣减可用库存消息到MQ,库存系统在接受到消息后处理扣减可用库存。后续如果还需要扩展,通知其他第三方系统,只需要新增一个消费者去接收扣减信息处理即可。
1.2.2. 异步
将用户的请求数据存储到MQ之后就立即返回结果。随后,系统再对消息进行消费。
例如短信验证码业务,登录服务在接受到用户手机号之后,将手机号发送到MQ,短信服务接受消息后进行短信发送。登录服务不需要等待发送验证码完成,即可继续后续处理。
1.2.3. 削峰
先将短时间高并发产生的事务消息存储在MQ中,然后后端服务再慢慢根据自己的能力去消费这些消息。
例如电商大促时,可在订单服务前架设一层订单接收服务,只负责接收订单并将订单信息发送到MQ,订单服务根据自身消费能力来接收订单信息并创建订单。 这样就避免订单服务因过高流量而宕机。
1.3. Kafka
Kafka是最初由Linkedin公司开发,是一个分布式、支持分区的(partition)、多副本的(replica),基于zookeeper协调的分布式消息系统,它的最大的特性就是可以实时的处理大量数据以满足各种需求场景:比如基于hadoop的批处理系统、低延迟的实时系统、storm/Spark流式处理引擎,web/nginx日志、访问日志,消息服务等等,用scala语言编写,Linkedin于2010年贡献给了Apache基金会并成为顶级开源项目。
2. 安装
2.1. 官网
Apache Kafka
2.2. docker安装
version: "1"
services:
kafka:
image: 'bitnami/kafka:latest'
hostname: kafka
ports:
- 9092:9092
- 9093:9093
volumes:
- 'D:\Docker\Kafka\data:/bitnami/kafka'
networks:
- kafka_net
environment:
# KRaft settings
- KAFKA_CFG_NODE_ID=0
- KAFKA_CFG_PROCESS_ROLES=controller,broker
- KAFKA_CFG_CONTROLLER_QUORUM_VOTERS=0@kafka:9093
# Listeners
- KAFKA_CFG_LISTENERS=PLAINTEXT://:9092,CONTROLLER://:9093
- KAFKA_CFG_ADVERTISED_LISTENERS=PLAINTEXT://192.168.2.51:9092
- KAFKA_CFG_LISTENER_SECURITY_PROTOCOL_MAP=CONTROLLER:PLAINTEXT,PLAINTEXT:PLAINTEXT
- KAFKA_CFG_CONTROLLER_LISTENER_NAMES=CONTROLLER
- KAFKA_CFG_INTER_BROKER_LISTENER_NAME=PLAINTEXT
networks:
kafka_net:
driver: bridge
docker-compose -f .\docker-compose.yml up -d
3. 简单使用
3.1. 可视化工具
3.1.1. offset explorer
Offset Explorer
- 配置Cluster name名字,Bootrap servers地址等信息
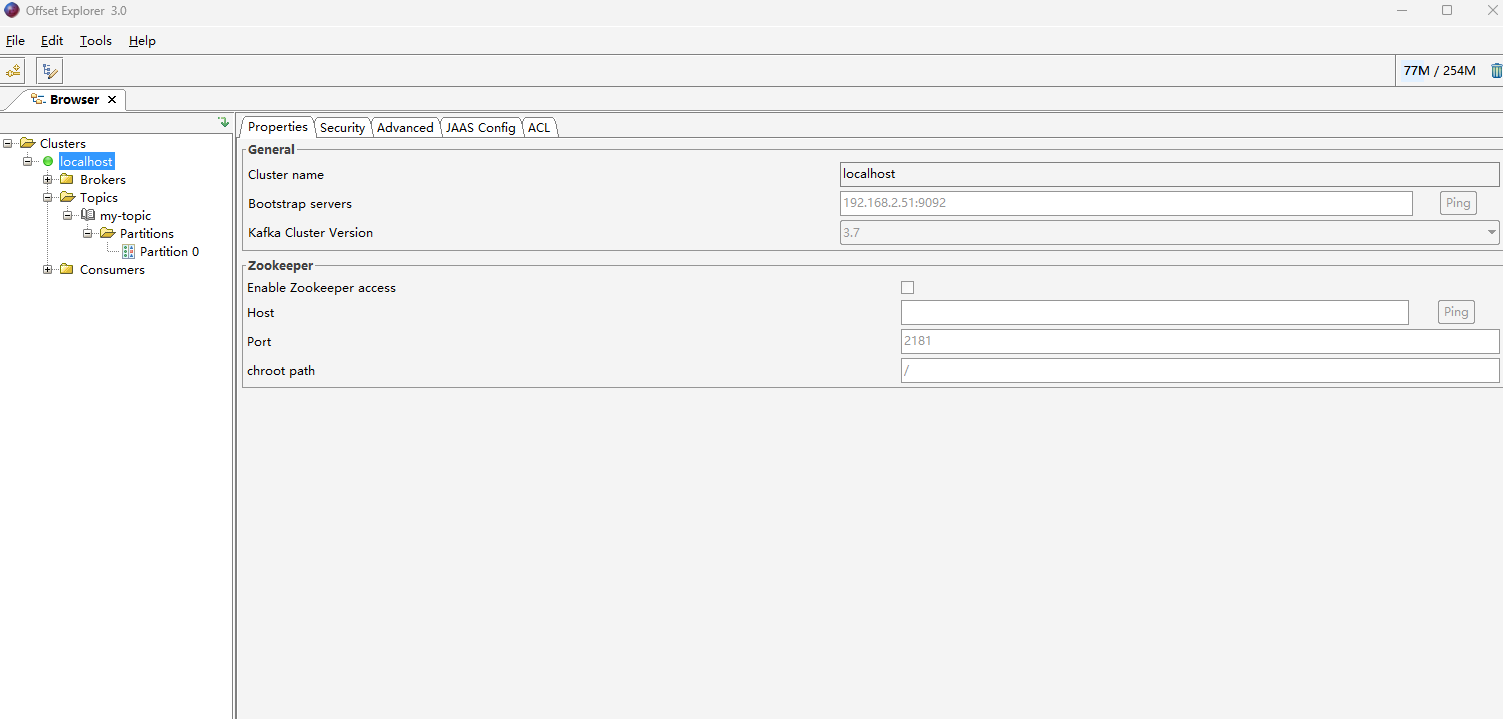
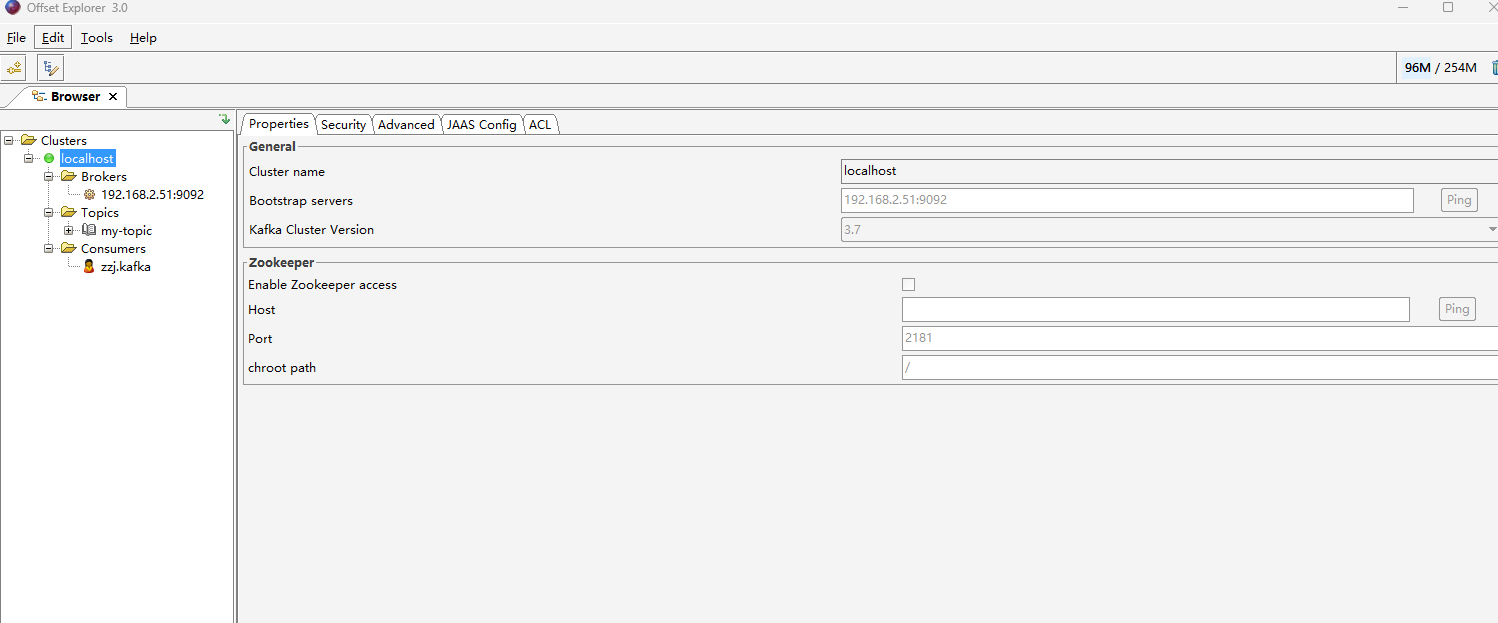
- 可以查看kafka节点,topic主题和consumers消费者等信息。
3.1.2. 可视化工具添加消息
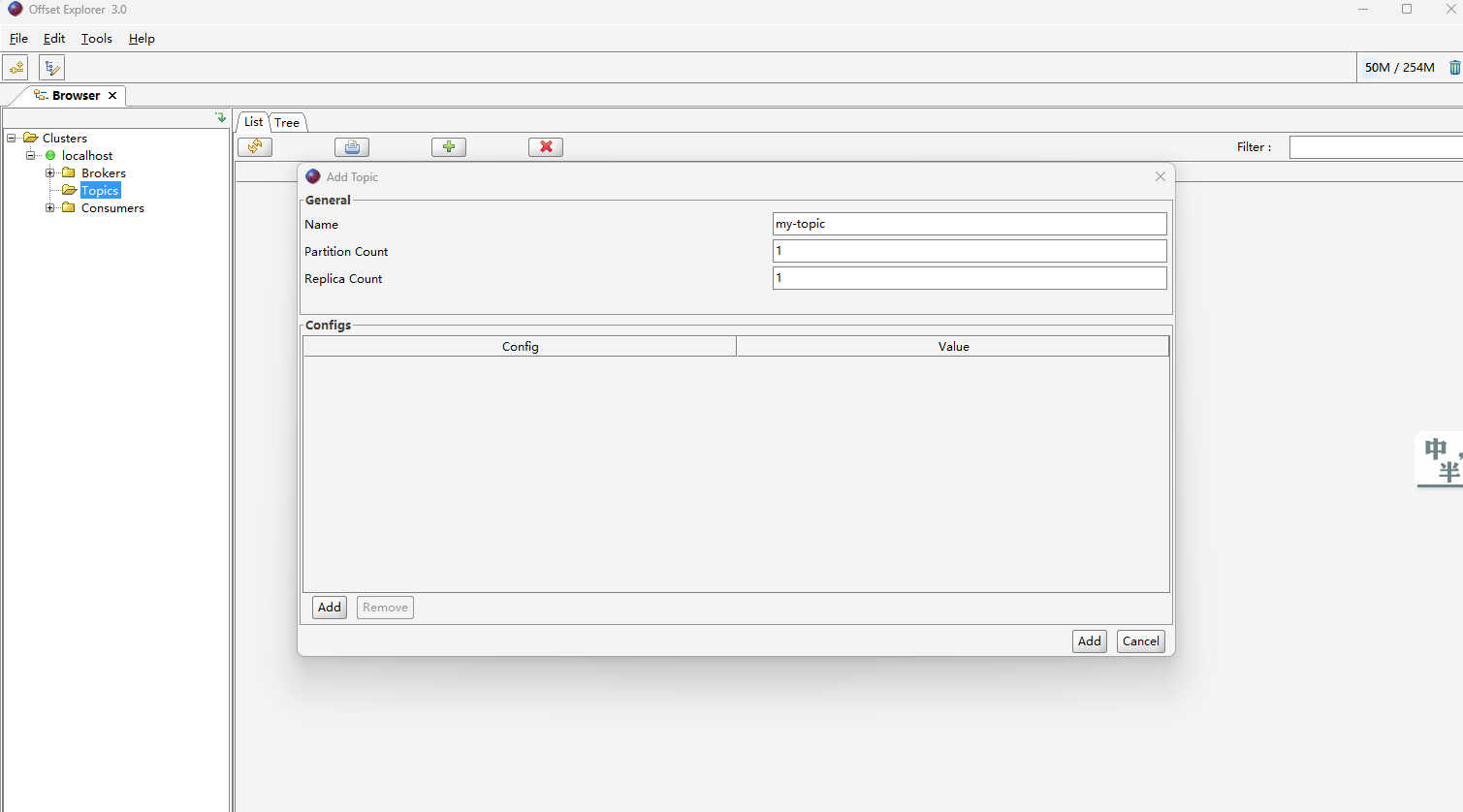
- 创建topic
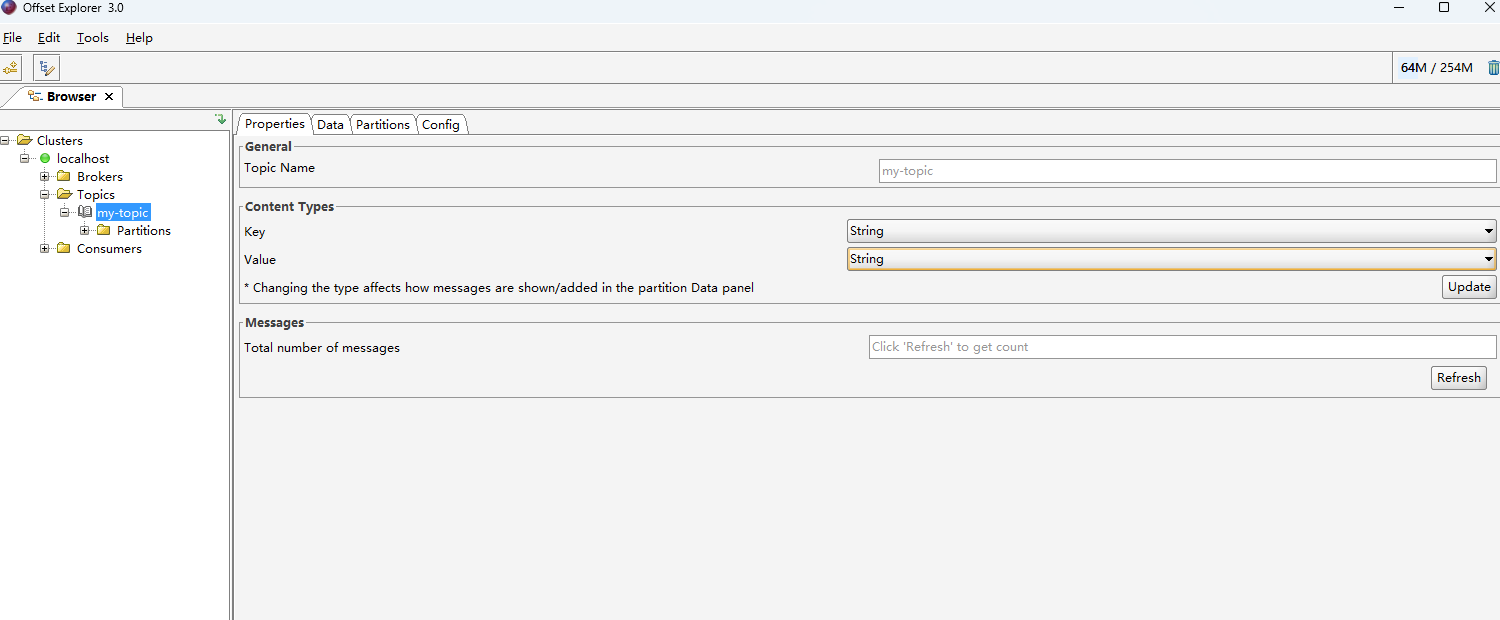
- 修改内容类型为String(记得点Update)
- 选中Partition,点击加号,选择Add Single Message 。Key和Value都Enter Manualy,Key可不填。点击Add
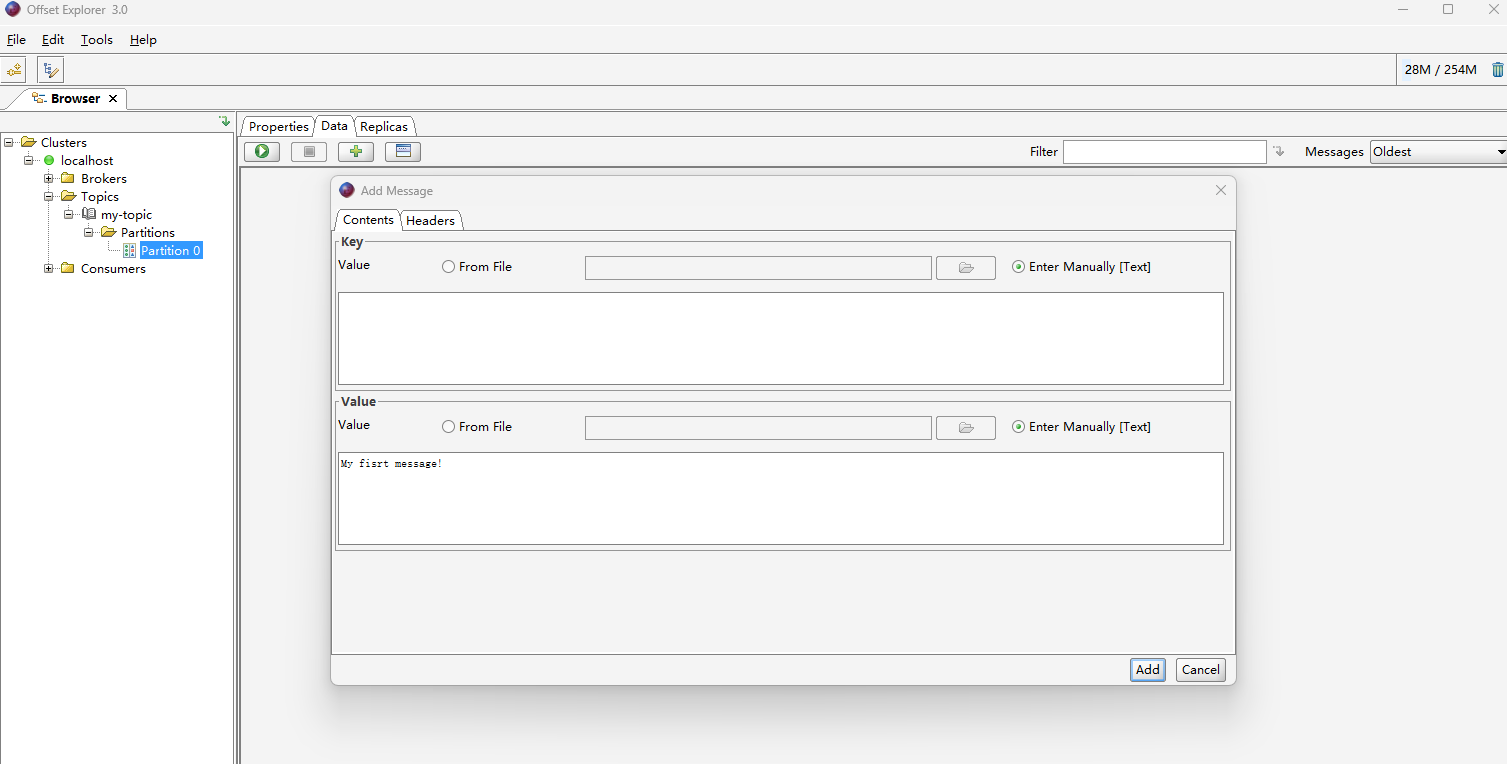
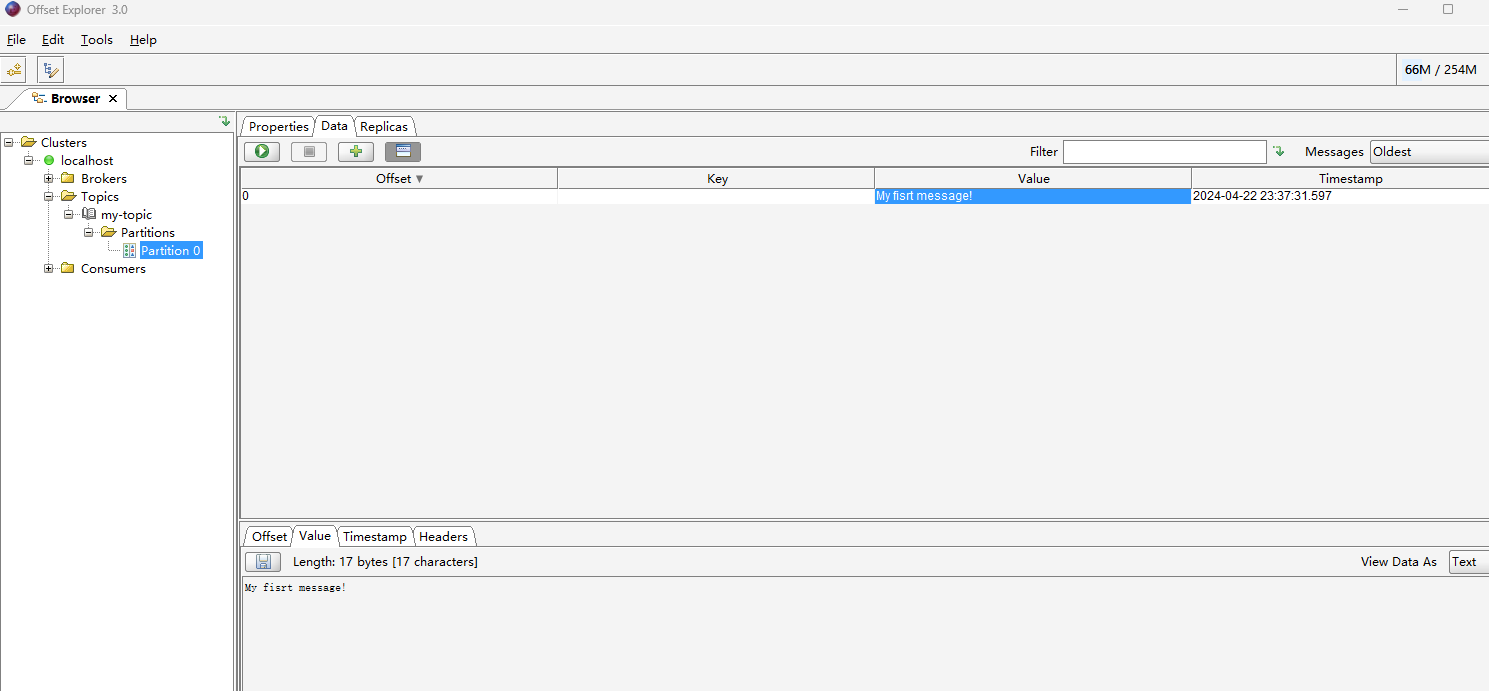
- 点击绿色Retrieve按钮,刷新分区消息。
3.2. 简单应用
3.2.1. 发送消息
- 项目中添加Kafka依赖
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka-clients -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.7.0</version>
</dependency>
- 构建生产者者,填写对应的配置信息,模拟发送五次消息,并打印发送的信息
Properties properties = new Properties();
//修改为对应的bootstrap.servers
properties.put("bootstrap.servers", "192.168.2.51:9092");
properties.put("acks", "all");
properties.put("retries", 0);
properties.put("batch.size", 16384);
properties.put("linger.ms", 1);
properties.put("buffer.memory", 33554432);
//序列化类型。
properties.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer");
properties.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer");
Producer<String, String> producer = null;
try {
producer = new KafkaProducer<>(properties);
for (int i = 0; i < 5; i++) {
String topic = "my-topic";
String value = "My first message" + i;
ProducerRecord<String, String> producerRecord = new ProducerRecord<>(topic, value);
producer.send(producerRecord);
System.out.println("Sent:" + producerRecord);
}
} catch (Exception e) {
e.printStackTrace();
} finally {
producer.close();
}
- 效果展示
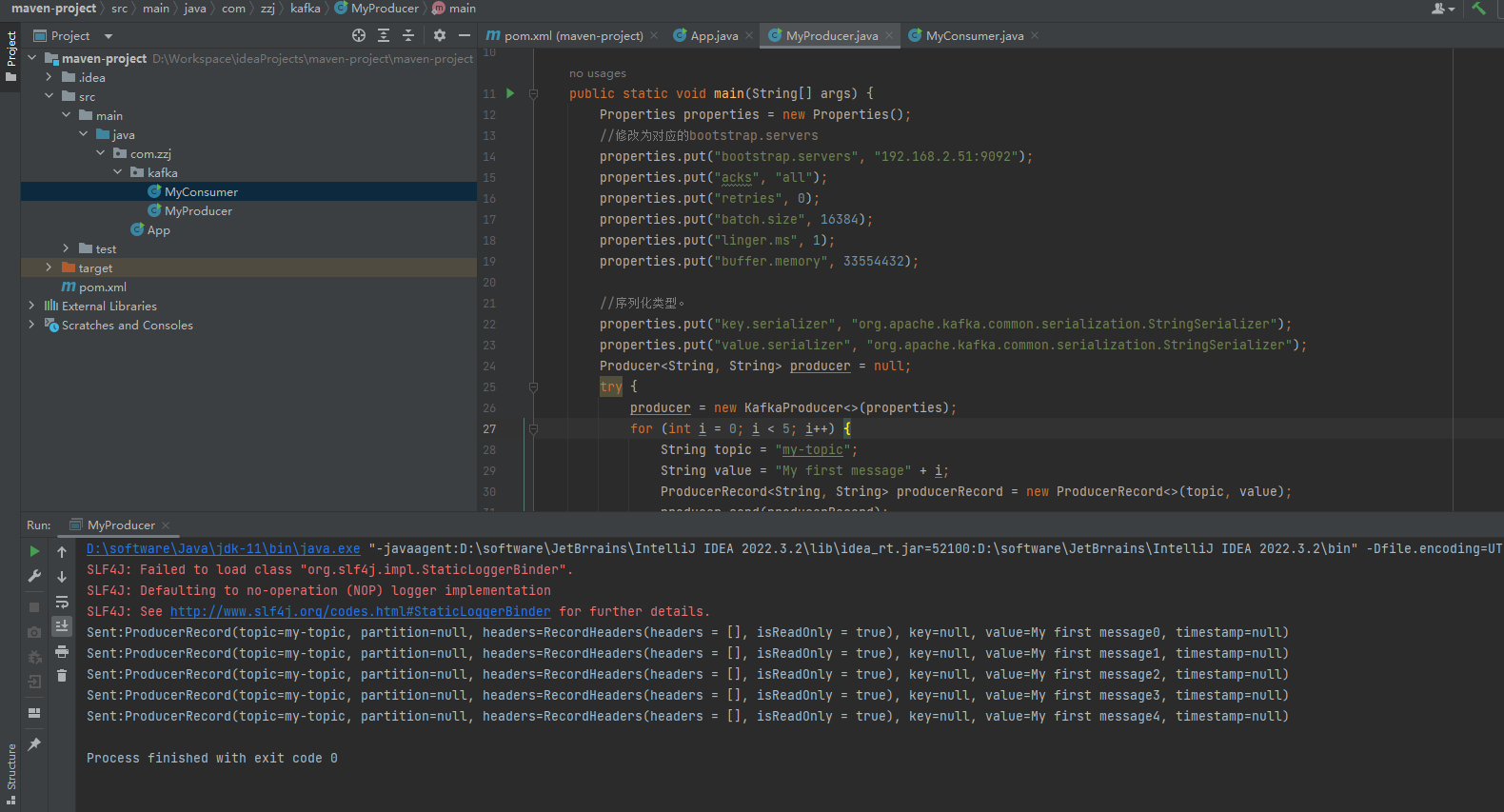
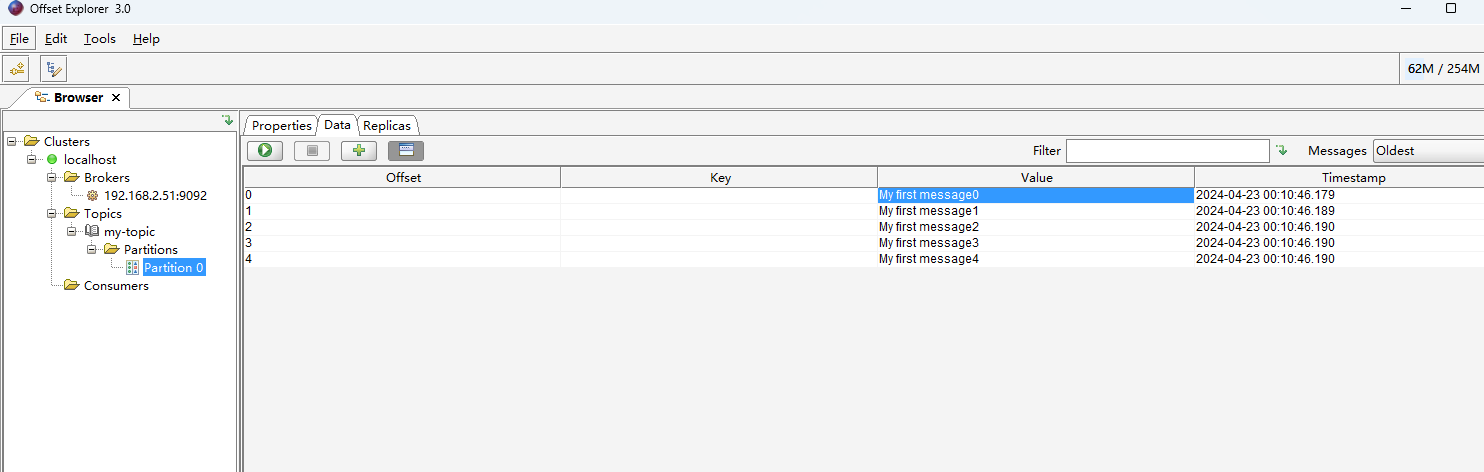
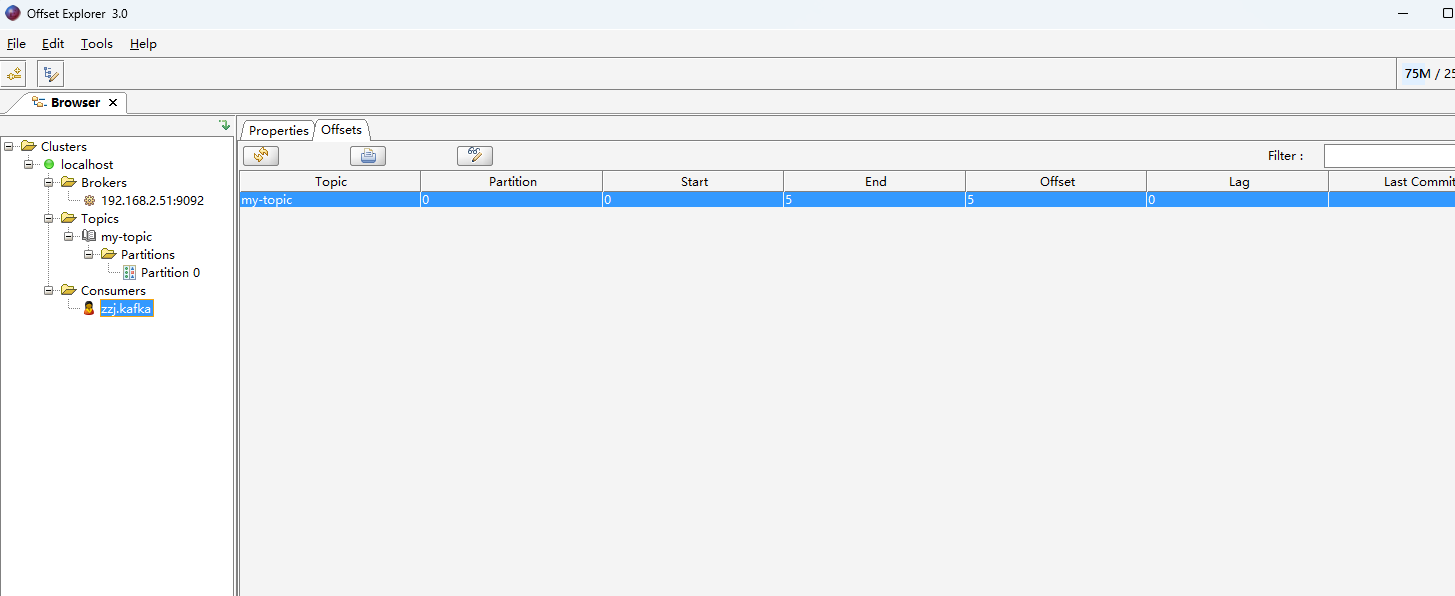
- 工具查看Kafka中的消息
3.2.2. 消费消息
- 构建消费者,填写对应的配置信息,while循环模拟消费线程,并打印消费的信息
Properties properties = new Properties();
//修改为对应的bootstrap.servers
properties.put("bootstrap.servers", "192.168.2.51:9092");
//可自行修改,消费组名称
properties.put("group.id", "zzj.kafka");
properties.put("enable.auto.commit", "true");
properties.put("auto.commit.interval.ms", "1000");
properties.put("auto.offset.reset", "earliest");
properties.put("session.timeout.ms", "30000");
//反序列化
properties.put("key.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
properties.put("value.deserializer", "org.apache.kafka.common.serialization.StringDeserializer");
KafkaConsumer<String, String> kafkaConsumer = new KafkaConsumer<>(properties);
//制定消费的topic主题
kafkaConsumer.subscribe(Arrays.asList("my-topic"));
while (true) {
ConsumerRecords<String, String> records = kafkaConsumer.poll(100);//100是超时时间
for (ConsumerRecord<String, String> record : records) {
System.out.printf("offset = %d, value = %s", record.offset(), record.value());
System.out.println();
}
}
- 效果展示
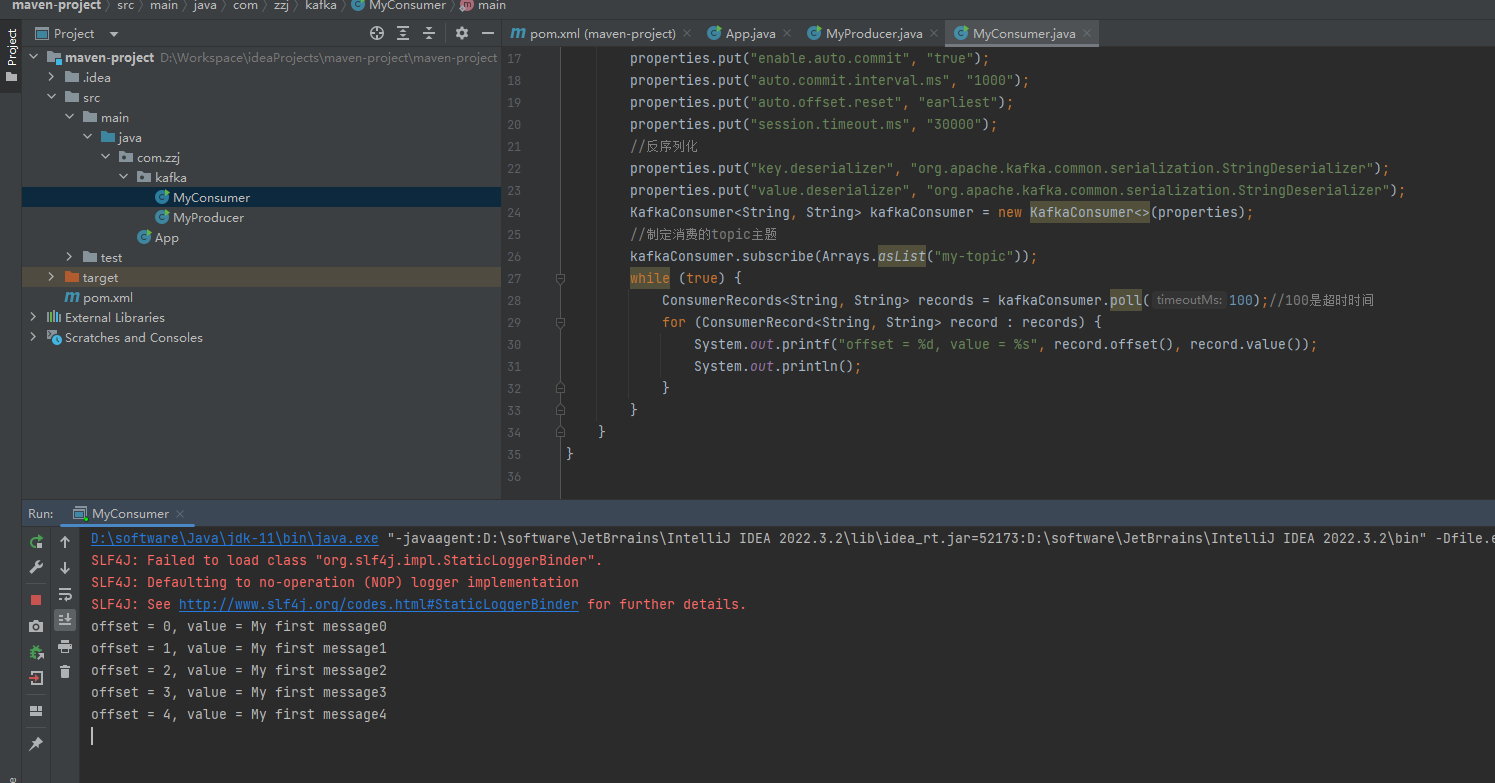
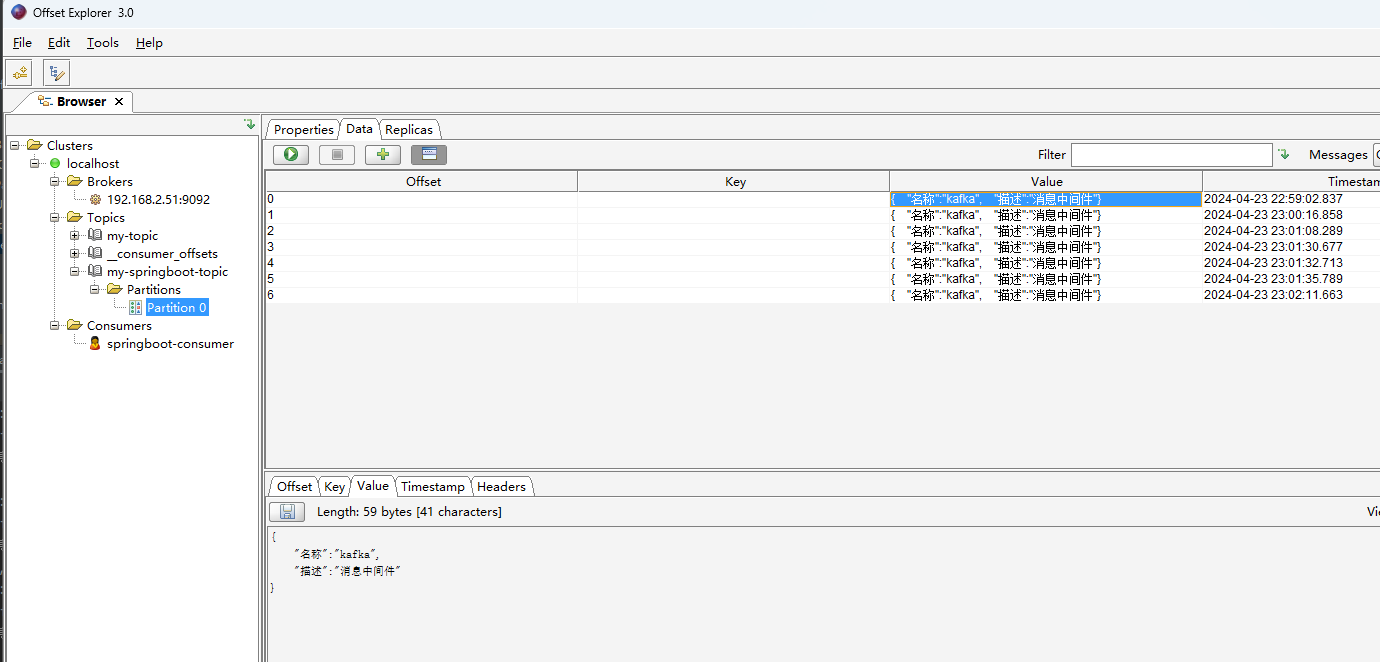
- 工具查看消费记录,选择对应的group.id消费组。可查看offset偏移量等信息
3.3. Springboot项目应用
3.3.1. Springboot集成Kafka
- 项目中添加Kafka依赖
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
- 添加Kafka生成者和消费者配置
spring.kafka.bootstrap-servers=localhost:9092
spring.kafka.producer.key-serializer=org.apache.kafka.common.serialization.StringSerializer
spring.kafka.producer.value-serializer=org.apache.kafka.common.serialization.StringSerializer
- 模拟生产者代码,使用spring-kafak封装的KafkaTemplate
import lombok.extern.slf4j.Slf4j;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.http.HttpStatus;
import org.springframework.http.ResponseEntity;
import org.springframework.kafka.core.KafkaTemplate;
import org.springframework.web.bind.annotation.*;
@RestController
@RequestMapping("kafka")
@Slf4j
public class KafkaController {
@Autowired
private KafkaTemplate<String, String> kafkaTemplate;
@RequestMapping(method = RequestMethod.POST, value = "/send")
public ResponseEntity<String> send(@RequestBody String body){
log.info("send message: {}", body);
kafkaTemplate.send("my-springboot-topic", body);
return new ResponseEntity<>("success", HttpStatus.OK);
}
}
- 消费者代码,使用@KafkaListener注解配置消费方法
package com.zzj.kafkademo.demos;
import lombok.extern.slf4j.Slf4j;
import org.springframework.kafka.annotation.KafkaListener;
import org.springframework.kafka.annotation.TopicPartition;
import org.springframework.kafka.support.KafkaHeaders;
import org.springframework.messaging.handler.annotation.Header;
import org.springframework.messaging.handler.annotation.Payload;
import org.springframework.stereotype.Component;
@Component
@Slf4j
public class KafkaConsumer {
@KafkaListener(topics = {"my-springboot-topic"}, groupId = "springboot-consumer")
public void listen(
//接收消息体
@Payload String data,
//接收分区编号
@Header(KafkaHeaders.RECEIVED_PARTITION_ID) int partition,
//接收topic主题名
@Header(KafkaHeaders.RECEIVED_TOPIC) String topic,
//接收消息的时间戳
@Header(KafkaHeaders.RECEIVED_TIMESTAMP) long ts
){
log.info("data:{},partition:{},topic:{},ts:{}", data, partition, topic, ts);
}
}
3.3.2. 效果展示
- 使用postman模拟发送消息
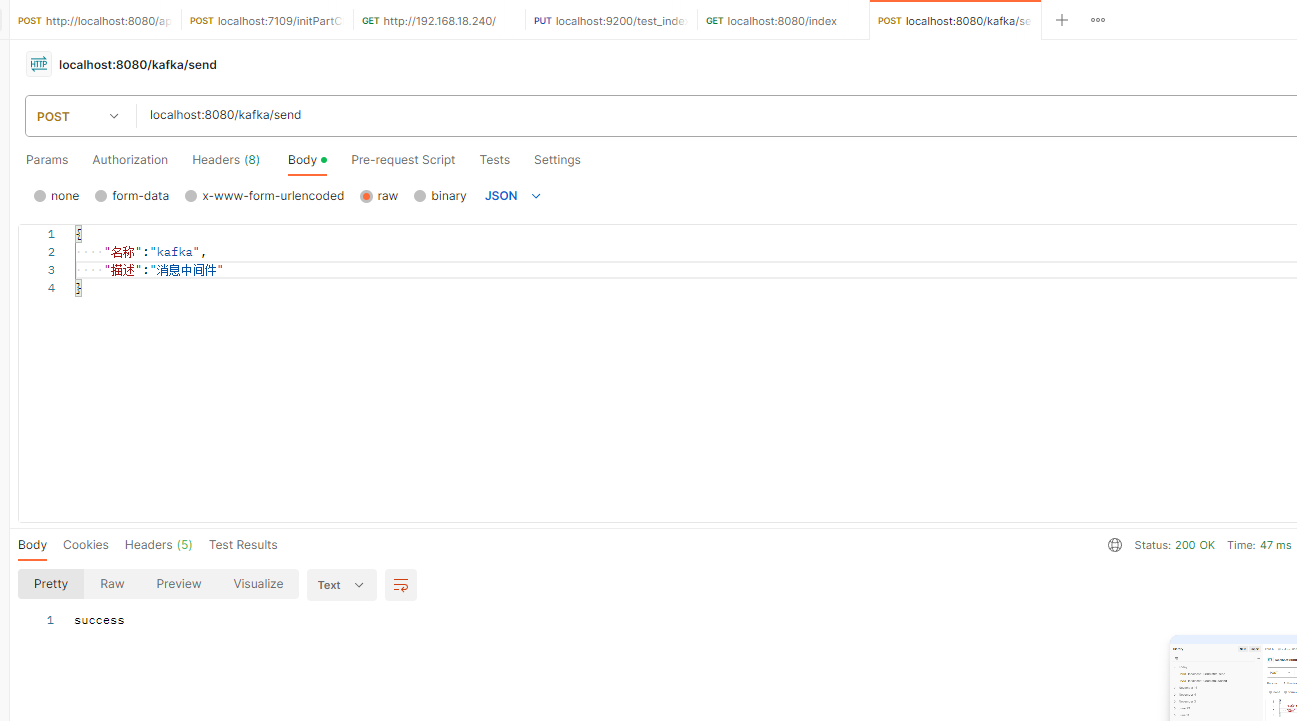
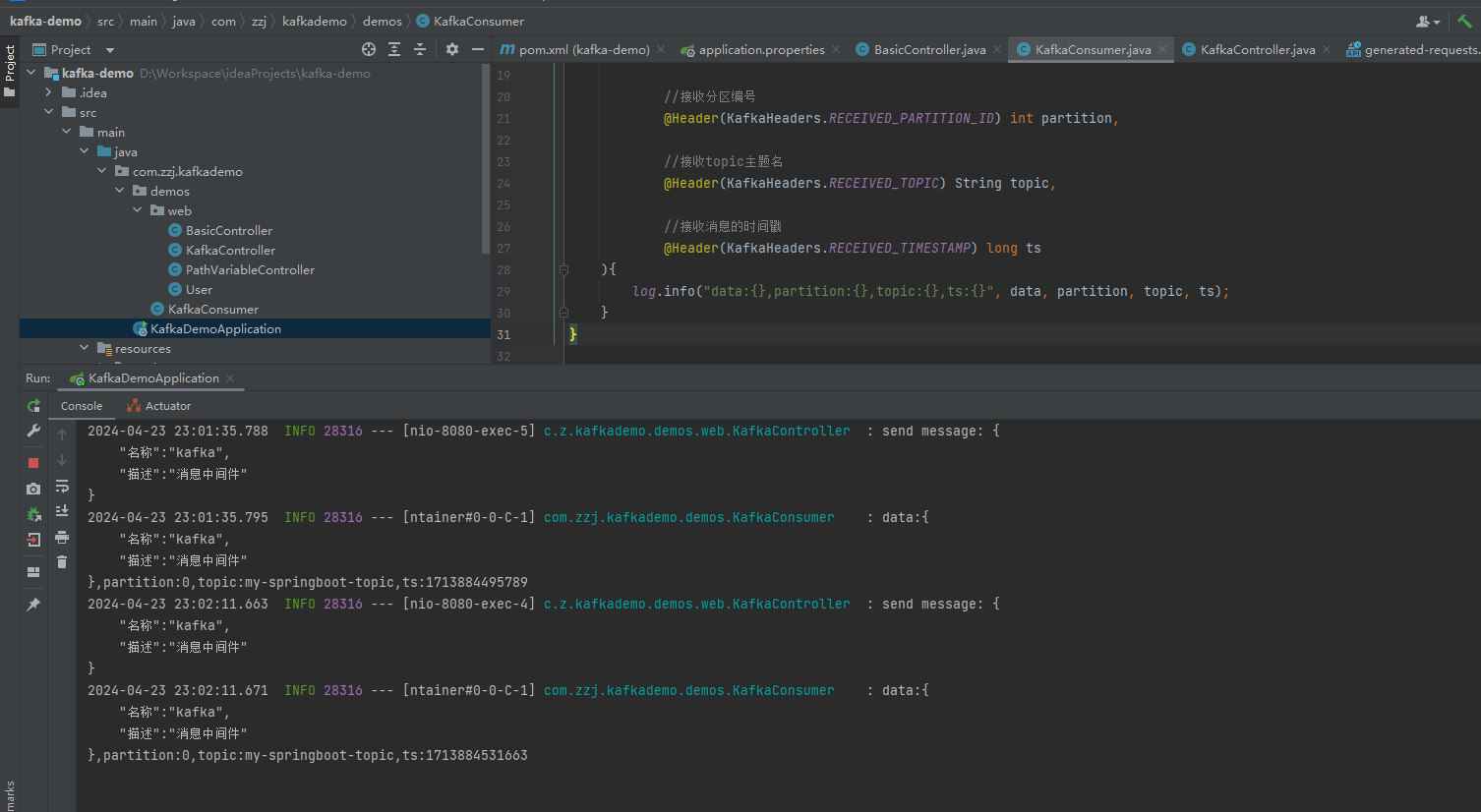
- 查看发送和消费记录,KafkaController中打印发送日志,KafkaConsumer打印消费日记
4. 问题总结
4.1. 系统可用性降低:
系统可用性在某种程度上说是降低了的,为什么这样说呢?在引入Kafka之后,就需要考虑Kafka的稳定性,如果突然挂了要如何处理,如何避免Kafka挂掉等问题。
4.2. 系统复杂性提高:
引入Kafka之后,需要保证消息没有被重复消费、消息是否丢失、还要保证消息传递的顺序性,消息消费错误导致的数据一致性问题等情况。
版权归原作者 梦里的银渐层 所有, 如有侵权,请联系我们删除。