
计算不同分区中相同key的平均值。
aggregateByKey实现、combineByKey实现。
aggregateByKey
import org.apache.spark.{SparkConf, SparkContext}
object RDD_Operator_Transform_aggregateByKey {
def main(args: Array[String]): Unit = {
//TODO 创建环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
//TODO RDD算子——key-value——aggregateByKey
//计算不同分区中相同key的平均值
val rdd = sc.makeRDD(List(
("A", 1), ("B", 2), ("C", 3), ("D", 4), ("A", 5), ("B", 6), ("C", 7), ("A", 8)
), 2)
val newRDD = rdd.aggregateByKey((0, 0))(
(t, v) => {
(t._1 + v, t._2 + 1)
},
(t1, t2) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
val RDD1 = newRDD.mapValues {
case (num, c) => {
num / c
}
}
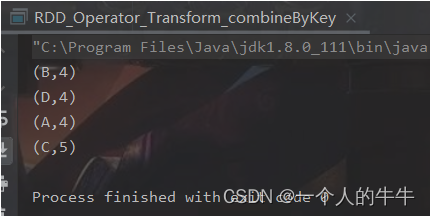
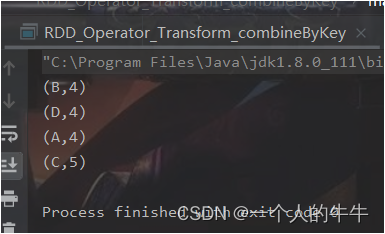
RDD1.collect().foreach(println)
//TODO 关闭环境
sc.stop()
}
}
combineByKey
import org.apache.spark.{SparkConf, SparkContext}
object RDD_Operator_Transform_combineByKey {
def main(args: Array[String]): Unit = {
//TODO 创建环境
val sparkConf = new SparkConf().setMaster("local[*]").setAppName("Operator")
val sc = new SparkContext(sparkConf)
//TODO RDD算子——key-value——combineByKey
//计算不同分区中相同key的平均值
val rdd = sc.makeRDD(List(
("A", 1), ("B", 2), ("C", 3), ("D", 4), ("A", 5), ("B", 6), ("C", 7), ("A", 8)
), 2)
//第一个:将相同key的第一个数据进行结构的转换
//第二个:分区内的计算规则
//第三个:分区间的计算规则
val newRDD = rdd.combineByKey(
v => (v, 1),
(t: (Int, Int), v) => {
(t._1 + v, t._2 + 1)
},
(t1: (Int, Int), t2: (Int, Int)) => {
(t1._1 + t2._1, t1._2 + t2._2)
}
)
val RDD1 = newRDD.mapValues {
case (num, c) => {
num / c
}
}
RDD1.collect().foreach(println)
//TODO 关闭环境
sc.stop()
}
}
本文转载自: https://blog.csdn.net/qq_55906442/article/details/125962090
版权归原作者 一个人的牛牛 所有, 如有侵权,请联系我们删除。
版权归原作者 一个人的牛牛 所有, 如有侵权,请联系我们删除。