
在七月算法上报了《无人驾驶实战》课程,老师讲的真好。好记性不如烂笔头,记录一下学习内容。 课程入口,感兴趣的也可以跟着学一下。
—————————————————————————————————————————
激光雷达的分类:
机械式Lidar:TOF、N个独立激光单元、旋转产生360度视场 MEMS式Lidar:不旋转
激光雷达的输出是点云,点云数据特点:
简单:x y z i (i为信号强度) 稀疏:7%(相同场景范围,与图像数据相比的结果) 无序:N!(角度不同、震动、扫描顺序不同 ) 精确:+-2cm

图像VS点云
点云:简单精确适合几何感知 图像:丰富多变适合语义感知
3D点云数据来源:
CAD模型:一般分类问题的数据集是CAD (虚拟生成) LiDAR传感器 RGBD相机(结构光、双目相机)
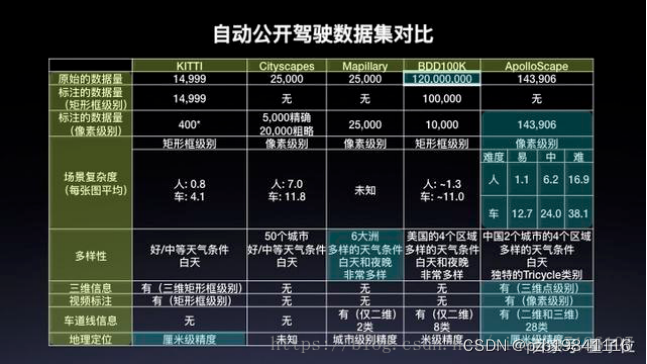
无人驾驶公开数据集
点云数据的可视化:
一般转换为鸟瞰图和前视图。点云数据采用右手坐标系,可以设计一个空间位置与图像坐标的映射关系。


点云分析的传统方法的难点:
基于点云的目标检测:分割地面->点云聚类->特征提取->分类 地面分割依赖于人为设计的特征和规则,如设置一些阈值、表面法线等,泛化能力差 多阶段的处理流程意味着可能产生复合型错误——聚类和分类并没有建立在一定的上下文基础上,目标周围的环境信息缺失 这类方法对于单帧激光雷达扫描的计算时间和精度是不稳定的,这和自动驾驶场景下的安全性要求(稳定,小方差)相悖
点云分析的深度学习方法的难点:
非结构化数据,只是一堆点XYZI,没有网格之类的组织结构 无序性:相同的点云可以由多个完全不同的矩阵表示(只是点的摆放顺序不同而已) 数量变化大:图像中像素数量是常数,点云的数量可能会有很大(例如:不同线的激光雷达) 表现形式变化大:一辆车向左转,同一辆车向右转,会有不同的点云代表同一辆车 缺少数据:没有图片数据多,扫描时通常被遮挡部分数据丢失,数据稀疏
深度学习中处理点云数据的几种思路:
1.Pixel-Base 基于像素的
基本思想:
3D->2D,三维点云在不同角度的相机投影(映射) 再借助2D图像处理领域成熟的深度学习框架进行分析 典型算法: MVCNN、MV3D、AVOD、 Appllo2.0、SqueezeSeg
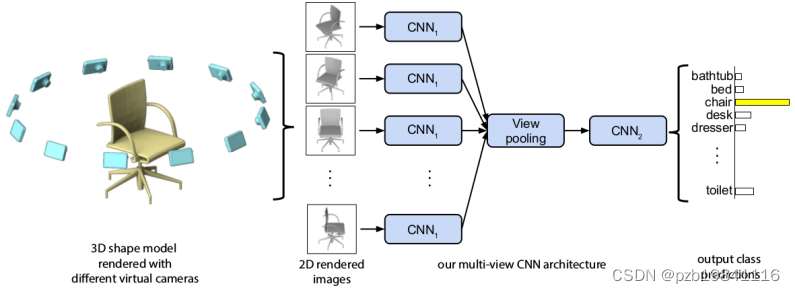
MVCNN
最早用深度学习处理点云数据的方法,用于分类。
主要思路是用虚拟相机从12个不同的位置给点云数据拍照,成像结果送入CNN进行分类。
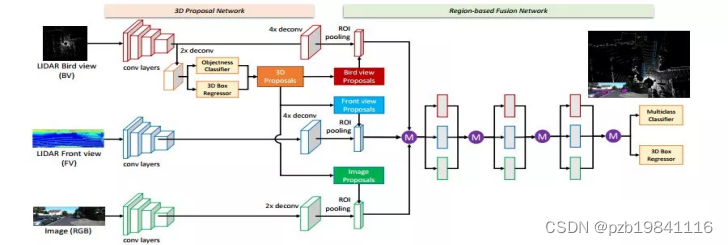
MV3D
输入:BV+FV+RGB: 并非简单投影,而是提取高度/密度/强度/距离等特征作为像素值 ROI:在BV训练一个3D RPN,分别向3种视图映射得到3种ROI,并融合 缺点:该方法在检测诸如行人和骑车人等小物体方面滞后(因为他们在BEV中特征本来就少又加上多次降采样),并且不能容易地适应具有垂直方向上的多个物体的场景(只用了BV)
AVOD
输入:BEV+RGB 从[-40, 40]×[0, 70]×[0, 2.5]范围内点云数据生成6-channel BEV map,分辨率为0.1m, 700x800x6 Z轴上[0,2.5]平分5段,前五个通道是每个栅格单元的最大高度, 第六个通道是每个单元中的密度信息

其中的Feature Extractor采用编解码方式,全分辨率的Feature Map对小目标友好。

融合两种特征图:先通过1×1的卷积对两个feature map进行降维,每个3D anchor投影到BEV以及image获得两个roi,每个roi进行crop resized to 3x3然后进行像素级别的特征融合(特征风丰富,可适应垂直方向多物体)。

在融合的特征图上训练RPN(mv3d仅在BEV上训练RPN)在BEV上采用2D NMS将top k proposals 送入第二阶段检测网络
融合后的feature通过三层全连接层得到类别(全分类)、bounding box、方向的输出,得到精确有方向有类别的 3D bounding boxs。每个bounding box有四个可能的朝向,选取离regressed orientation vector最近的朝向。

Apollo 2.0
基于激光雷达的感知方案,
俯视投影到地面网格(2D grid-map) 每个网格计算8个统计量 使用UNet做障碍物分割

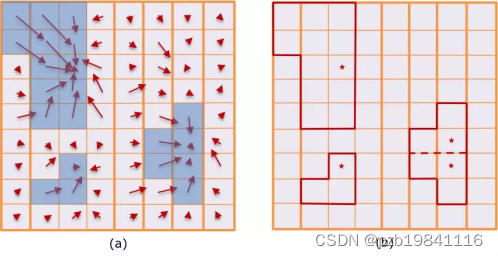
Squeeze Seg
使用的是球面投影,(x,y,z)->(θ,ϕ) 3D->2D,ϕ(azimuth) θ(Altitude)。
球面坐标系下的每一个点都可以使用一个直角坐标系中点表示的点表示,提取点云中每一个点的5个特征:(x, y,z, intensity, range)放入对应的二维坐标 (i,j)。

由于高度64小于其宽度512,网络主要对宽度进行降维(通过Max Pooling),最后被输入到一个条件随机场中做进一步的矫正


单纯的CNN逐像素分类结果会出现边界模糊的问题(下采样丢失细节),为解决该问题,CNN输出的label map被输入到一个CRF(由RNN实现)进一步的矫正CNN输出的label map。
优点:速度快 缺点:分割的精度仍然偏低 需要大量的训练集,而语义分割数据集标注困难 改进版:SqueezeSegV2
2.Voxel-Base 基于体素的
将点云划分成均匀的空间三维体素(体素网格提供了结构,体素数量像图片一样是不变的,也解决了顺序问题)
优点:表示方式规整,可以将卷积池化等神经网络运算迁移到三维 缺点:体素表达的数据量大(计算量很大 例如256x256x256 = 16777216),一般会减小分辨率(引入量化误差/局限性 例如64x64x64)
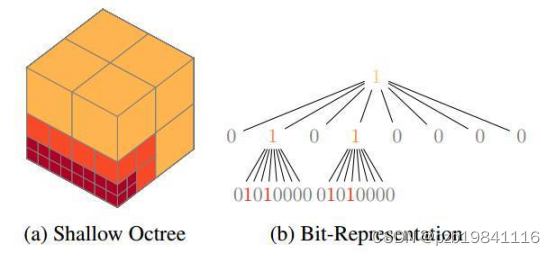
基于Tree的结构化点云:
使用tree来结构化点云 对稀疏点云进行高效地组织 再套用成熟的神经网络进行处理 ,常用的有八叉树、k-d tree
优点:与体素相比是更高效的点云结构化方法 (该粗的粗该细的细) 缺点:仍然需要额外步骤对数据进行处理(类似体素化) 所以在端到端处理方面存在劣势
基于点的方法:直接对点云进行处理,有以下几个问题要解决。使用对称函数解决点的无序性,使用空间变换解决旋转/平移性。
无序性:点云本质上是一堆点(nx3矩阵,其中n是点数) 点的顺序不影响它在空间中对整体形状的表示(相同的点云可以由两个完全不同的矩阵表示) 。希望不同的点云顺序可以得到相同的特征提取结果,可以用对称函数g (例如maxpooling或sumpooling)。 旋转/平移性: 相同的点云在空间中经过一定的刚性变化(旋转或平移)坐标发生变化,希望不论点云在怎样的坐标系下呈现网络都能正确的识别出, 可以通过STN(spacial transform network)解决。

PointNet
maxpooling作为对称函数解决无序性问题:每个点云分别提取特征之后,maxpooling可以对点云的整体提取出global feature
空间变换网络解决旋转问题:三维的STN可以通过点云本身的位姿信息学习(loss调整)到一个最有利于网络进行分类或分割的变换矩阵,将点云变换到合适的视角(例如 俯视图看车 正视图看人)

两次STN,第一次input transform 可以理解为将原始点云旋转出一个更有利于分类或分割的视角,第二次feature transform是在特征层面对点云进行变换。
PointNet++
PointNet:单个点云特征 -> 全局特征,中间缺少局部信息(相当于用很大的卷积核/pooling只做了一层卷积/pooling 感受野一下就变最大) 单个PointNet操作可以看做一种特殊的卷积操作 PointNet++:单个点云特征 -> 局部点云特征 -> 更大局部点云特征-> ... ->全局信息。PointNet的分层版本(相当于多次卷积 感受野逐渐变大)

set abstraction的步骤:
采样:选取一些比较重要的点作为每一个局部区域的中心点 分组:在这些中心点的周围选取k个近邻点(欧式距离给定半径内) PointNet: 使用PointNet提取局部特征(一次PointNet相当于一次卷积,故而称作PointNet卷积), 点云子集的特征 结果输出到下一个set abstraction重复这个过程

解决点云密度不均匀问题: 激光扫描时会出现采样密度不均的问题,所以通过固定范围选取的固定个数的近邻点是不合适的。PointNet++提出了两个解决方案:
多尺度分组:在每一个分组层都通过多个尺度来确定每一个中心点的邻域范围,并经过PointNet提取特征后将多个特征拼接起来,得到一个多尺度融合的新特征 多分辨率分组:多分辨率分组法是考虑多种分辨率的融合。左边特征向量是通过一个set abstraction得到的(多次PointNet卷积),右边特征向量是直接对当前patch中所有点进行Pointnet卷积得到。并且当点云密度不均时可以通过判断当前patch的密度对左右两个特征向量给予不同权重,以此达到减少计算量的同时解决密度问题
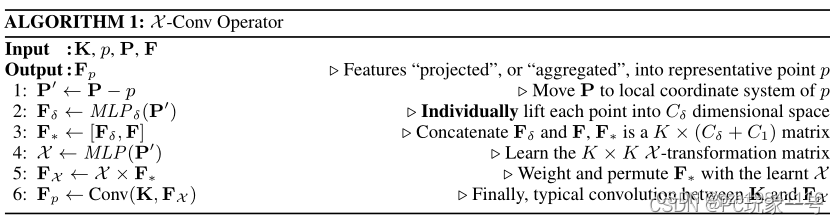
PointCNN
PointNet:点云分别提取特征(顺序无关) -> 对称函数解决顺序问题(maxpooling) “处处小心顺序问题” PointCNN:点云领域提取特征(顺序相关) -> 用X变换解决顺序问题 “前期放开干/后期统一变”
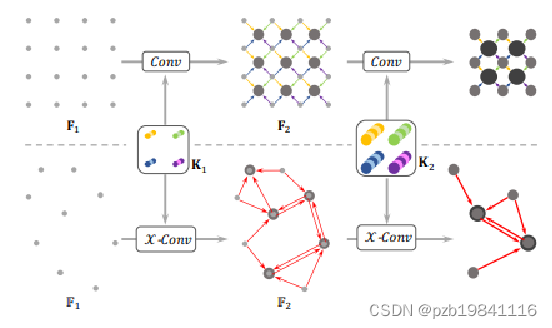
X-Conv算子主要思想就是针对输入来说,以核K,中心p,领域点P,领域的特征F为输入,得到一个K×K的矩阵,这个矩阵就是X变换,它可以保证点云的无序性,然后再通过卷积核K对其进行卷积。最后得到的特征Fp来代表p点的特征,相当于一个映射。
Frustum PointNet
提取视锥体:RGB提取2D box (ROI) 2D box -> 3D视锥体(使用相机投影矩阵)
分割:对成视锥体内点云分割得到物体实例分割(3d mask 类似Mask-RCN在ROI内做二分类)

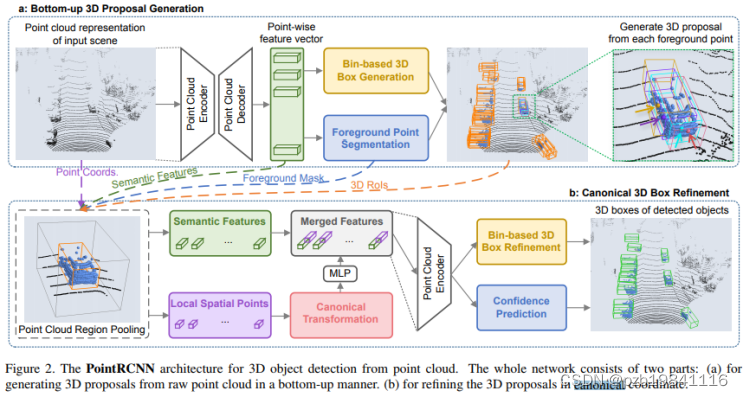
Point RCNN
3D RRN from raw point(使用PointNet++提取特征)
Refining 3D proposals
体素方法小结,解决顺序问题(结构问题):
Pixel-Based: 2D-grid Voxel-Based: 3D-grid Tree-Based: Tree struct Point-Based: 对称函数 / X变换
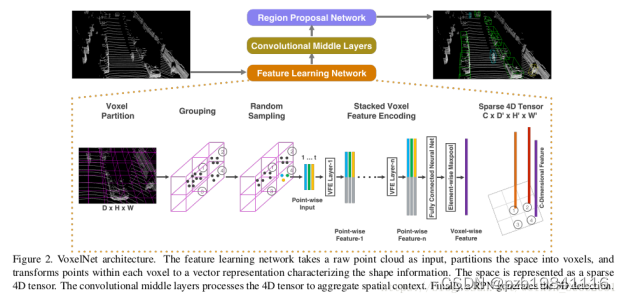
Volex Net
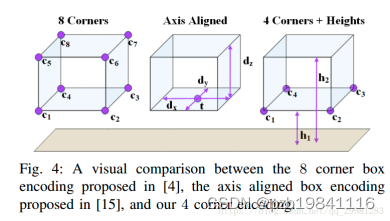
基本思想:在3D网格单元上使用Pointnet学习的特征,而不使用手工制作的网格特征(例如 h_max等)。
整体框架:
输入:仅使用激光雷达数据 特征学习网络 卷积中间层网络 区域提取网络(RPN) 优缺点: 准确度很高, 但在TitanX GPU上只有4fps的低速度
其中特征学习网络:
体素分块(Voxel Partition)输入点云(D,H,W) 体素的深高宽为(vD,vH,vW) voxel grid 点云分组(Grouping)将点云按照上一步分出来的体素格进行分组 随机采样(Random Sampling)每一个体素格随机采样固定数目的点T 因为a) 网格单元内点云数量不均衡 b) 且64线一次扫描点云数量巨大(10w)全部处理需要消耗很多cpu和内存
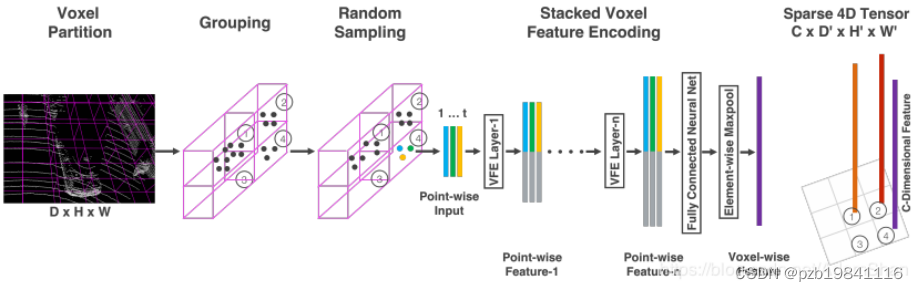
类似PointNet中的 分层多次卷积 -> 小邻域变大邻域,每个卷积中间层ConvMD:3维卷积+BN层+非线性层(ReLU)。
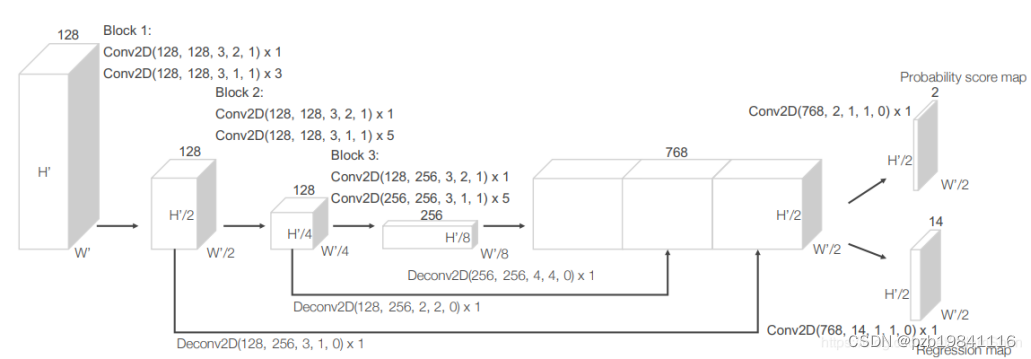
区域提取网络(RPN)
三个全卷积层块(Block)每次尺度减半 每一个块的输出都上采样到相同尺寸进行串联得到高分辨率特征图 输出: Probability Score Map (二分类 例如是否为车) [None, 200/100, 176/120, 2] 和Regression Map(位置修正) [None, 200/100, 176/120, 14]
本文转载自: https://blog.csdn.net/pzb19841116/article/details/132085553
版权归原作者 pzb19841116 所有, 如有侵权,请联系我们删除。
版权归原作者 pzb19841116 所有, 如有侵权,请联系我们删除。