
Hadoop概述
框架逻辑:
1.框架的作用具体是什么,应用场景在什么地方
2.当前框架的简单使用
1.命令
2.API代码
3.框架组件
框架一般是多个部分组件的
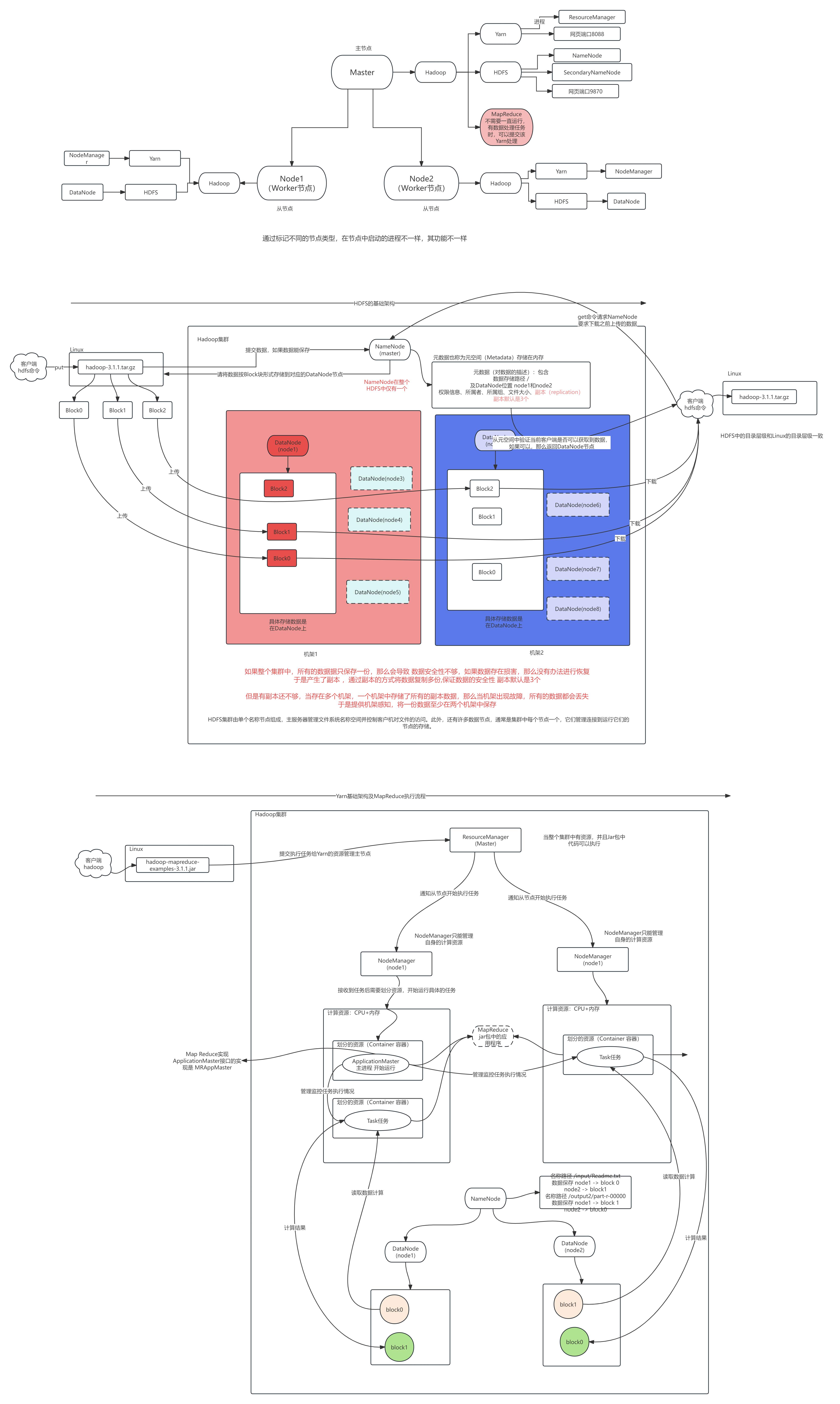
Hadoop: HDFS MapReduce Yarn
Spark: SparkCore SparkSQL SparkStream …
要了解每个组件的功能是什么
4.原理(面试)
组件的进程 ,进程的作用
比如对于HDFS: NameNode DataNode SecondaryNameNode …
进程之间如何通过协同调用完成相关的功能
5.联合一些业务或者其他组件进行联合使用,完成比较复杂的功能
6.基于原理和功能模块对当前框架进行优化(面试)
对大家的要求:
- 对于框架要知道干什么的 2. 对于命令和API需要会使用 比如Hadoop需要有Java基础和linux命令基础 3.重点介绍的原理需要能自己描述 语言表达能力很重要 原理图需要自己能绘制 4.对于优化要知道其问题,以及怎么操作
什么是大数据
大数据指高速 (Velocity) 涌现的大量 (Volume) 多样化 (Variety) 具有一定价值( Value )并且真实( veracity )的数据,其特性可简单概括为 5V
高速: 数据每秒产生的速度相对比较块
大量: 数据总量一般比较庞大,所考虑的存储和计算与一般的其他技术会不一样
多样化: 数据的种类相对较多 比如:获取关系型数据 ,非结构化数据(json,日志:一般指前后端的业务系统中的埋点数据,埋点数据包括:互联网公司的页面的访问请求、网络请求日志、图片数据转成文件数据再进行分析 )
价值: 大数据最终的目的是需要从数据中挖掘数据的价值,给现实业务提供支撑
大量数据计算存储所带来的问题:
- 对于单台节点所能处理的数据量是有限的 2. 使用多台电脑处理 ,需要考虑哪些问题? 2.1 数据存储问题 ① 当一个文件过大 超过TB时,现在需要使用多台主机,进行存储 ,每个台主机需要保存其中的一部分数据 , 当文件被切分后,那么需要知道文件切分成多少块, 每个数据块保存的位置信息 2.2 数据计算问题 ① 当一个文件过大 超过TB时,单个主机计算性能不够,所以需要多个主机进行同时计算,需要先读取数据 ,那么需要将数据发送到本地或者直接在本地加载 ,于是可以在每台主机中保存一部分数据,计算时,当前主机只计算本地的数据 ② 当数据做计算后,那么需要将计算的结果进行汇总,汇总的策略是什么?
Hadoop安装
前置条件
1.虚拟中可以ping通外网 ping www.baidu.com
2.可以使用xshell 连接
3.需要使用非桌面模式
# multi-user.target: analogous to runlevel 3# graphical.target: analogous to runlevel 5## To view current default target, run:# systemctl get-default## To set a default target, run:
systemctl set-default multi-user.target
4.资源配置
处理器1 内核 2个
5.JDK环境验证
[root@master ~]# java -versionjava version "1.8.0_171"
Java(TM) SE Runtime Environment (build 1.8.0_171-b11)
Java HotSpot(TM)64-Bit Server VM (build 25.171-b11, mixed mode)[root@master ~]# echo $JAVA_HOME
/usr/local/soft/jdk1.8.0_171
6.防火墙
# 查看防火墙状态
systemctl status firewalld
7.主机名为Master
虚拟机克隆
1.需要克隆3台虚拟机
前提:Master需要关机
1.选择一台虚拟机(Master) -> 右键 -> 管理 -> 克隆
注意:克隆时需要完整克隆,存放虚拟机的位置需要使用固态硬盘
新建虚拟机文件夹
虚拟机文件夹保存三个节点虚拟机,方便后续使用
配置虚拟机网络
配置网络:注意每次配置一定要只启动一个虚拟机节点
- 开启一个节点后修改IP地址
vim /etc/sysconfig/network-scripts/ifcfg-ens32
# 找到IPADDR选项修改IPADDR=修改后的IP
- 配置主机名 node1 node2
vim /etc/hostname
# 修改其主机名 #重启生效reboot
- 之后再配置其他主机
- 主机映射 三台节点都需要
vim /etc/hosts
# 添加如下内容:192.168.136.100 master
192.168.136.110 node1
192.168.136.120 node2
- 免密登录
从Master连接node1 和 node2 使用 ssh 协议
格式:ssh 用户名@IP 连接后输入密码
退出登录 使用 ctrl + d 按键
在Hadoop中,由于其是主从结构,程序启动后,需要在主节点使用ssh 协议连接到从节点,那么需要配置免密登录
配置过程:
# 1、生成密钥 过程中三次回车
ssh-keygen -t rsa
# 2、配置免密登录
ssh-copy-id master
ssh-copy-id node1
ssh-copy-id node2
# 3、测试免密登录# 从master分别登录node1、node2# 观察是否需要密码,如不需要则免密登录配置成功ssh node1
ssh node2
安装包下载
Hadoop发行版本下载仓库
Hadoop集群搭建
参考如下文件:
Hadoop 3.1.1 分布式搭建文档.md
Haoop基础概念
HDFS文件系统命令
HDFS中的命令除了hdfs dfs 命令前缀以外,还可以使用 hadoop fs
上传
hdfs dfs -put 本地路径 HDFS路径
hdfs dfs -put ./students.csv /input
hdfs dfs -moveFromLocal ./students.sql /input
下载
hdfs dfs -get HDFS路径 本地路径
创建目录
hdfs dfs -mkdir HDFS路径
hadoop fs -mkdir HDFS路径
查看目录
hdfs dfs -ls-h /
删除目录
hdfs dfs -rm-r-f /data1
# Moved: 'hdfs://master:9000/data1' to trash at: hdfs://master:9000/
user/root/.Trash/Current/data1
# 删除数据时,是将数据移动到垃圾箱 等待一天的时间 之后自动对其进行删除
可以通过该参数修改 默认保存时间
fs.trash.interval
1440
修改目录及文件权限
# 需要知道 路径权限的意思# -rw-r---w- 1 root supergroup 1366 2024-01-23 09:52 /data/README.txt# chmod 可以使用 用户+/-权限表达式 也可以使用数字表达式 数字表达式在2.x版本不支持 # -R 表示迭代更新当前目录中所有的目录及文件
hdfs dfs -chmod-R o-r /data
修改目录及文件的所属者及组
hdfs dfs -chown-R 用户:用户组 路径
移动目录
hdfs dfs -mv /input /data/
查看文件内容
# cat
hdfs dfs -cat /data/README.txt
# tail # tail命令可以监听某个文件,如果文件有变化,那么会将新增内容打印到控制台# 一般用于对日志的监控 # linux tail -f 文件 用于监听某个文件 文件被删除命令消失 # tail -F 文件 当文件被删除后重新创建也可以继续监听# text
hdfs dfs -text
追加信息到文件中
# appendToFile
hdfs dfs -appendToFile 本地路径 hdfs路径
查看占用情况
hdfs dfs -du-h /data
复制文件
# -cp
hdfs dfs -cp hdfs路径 hdfs目标路径
查看HDFS状态
hdfs dfsadmin -report
注意:所有对文件的操作,如果目标路径的目录不存在,那么默认路径末尾是文件
比如:使用cp命令 末尾如果目录不存在,那么复制后的是一个重命名的文件
HDFS 详解
元数据
什么是元数据?
对数据的表述信息,比如对于Mysql数据库来说,存储的数据是真实数据,所创建的表,字段信息是数据的元数据信息
在HDFS中,元数据是指 当前存储在HDFS中的文件信息,文件信息包括: 文件名、文件路径、权限、副本数、创建修改时间、block块存储位置
文件系统
常见的文件系统:windows、linux、NAS、星际文件系统 HDFS文件系统
分布式文件系统
HDFS不适合用于存储小文件:
前提:NameNode是用于存储元数据信息,而该部分的元数据信息是保存在内存当中的,如果从极端考虑,当上传的文件大小在 kb及以下,那么元数据信息和具体的数据所占用空间相差不大,那么如果要存储 1TB的小文件 那么对于NameNode的内存占用也在 1TB左右
NameNode元数据存储策略
前提:NameNode中保存元数据信息,在内存中,内存断电或程序关闭,内存会自动清理
如果按照上述存储方式,存在数据安全问题:
可以使用磁盘保存内存数据 ,但是会导致数据不一致的问题或者数据丢失
如果按照内存中所有的元数据一次性保存下来(快照),最后一次快照数据之后的数据会丢失 如果按照 客户端所有的写操作命令都记录下载,此时会解决数据丢失的问题,但是会导致文件过大的问题,同时数据恢复会特别慢所以可以对其进行综合:
客户端写操作命令执行时会修改内存中的数据,同时也会在磁盘中将操作命令记录下载,保证完整性,同时也将内存中的数据按照快照的形式保存下来,于是HDFS中存在了两种文件 1.fsimage 2.edits fsimage是存储了内存中的快照数据
edits是存储了用户的写操作记录数据
# 该命令可以解析edits文件中的用户操作记录
hdfs oev -i edits_inprogress_0000000000000000427 -o edits_inprogress.xml -p XML
# 该命令可以解析fsimage文件中的元数据信息
hdfs oiv -i fsimage_0000000000000000426 -o fsimage.xml -p XML
通过上述两个命令知道,edits文件保存的是用户的写操作,但是并不是全部的
fsimage文件中保存的也不是最新的元数据信息
但是将两个文件的信息合并 就是最新的 元数据信息
元数据操作的过程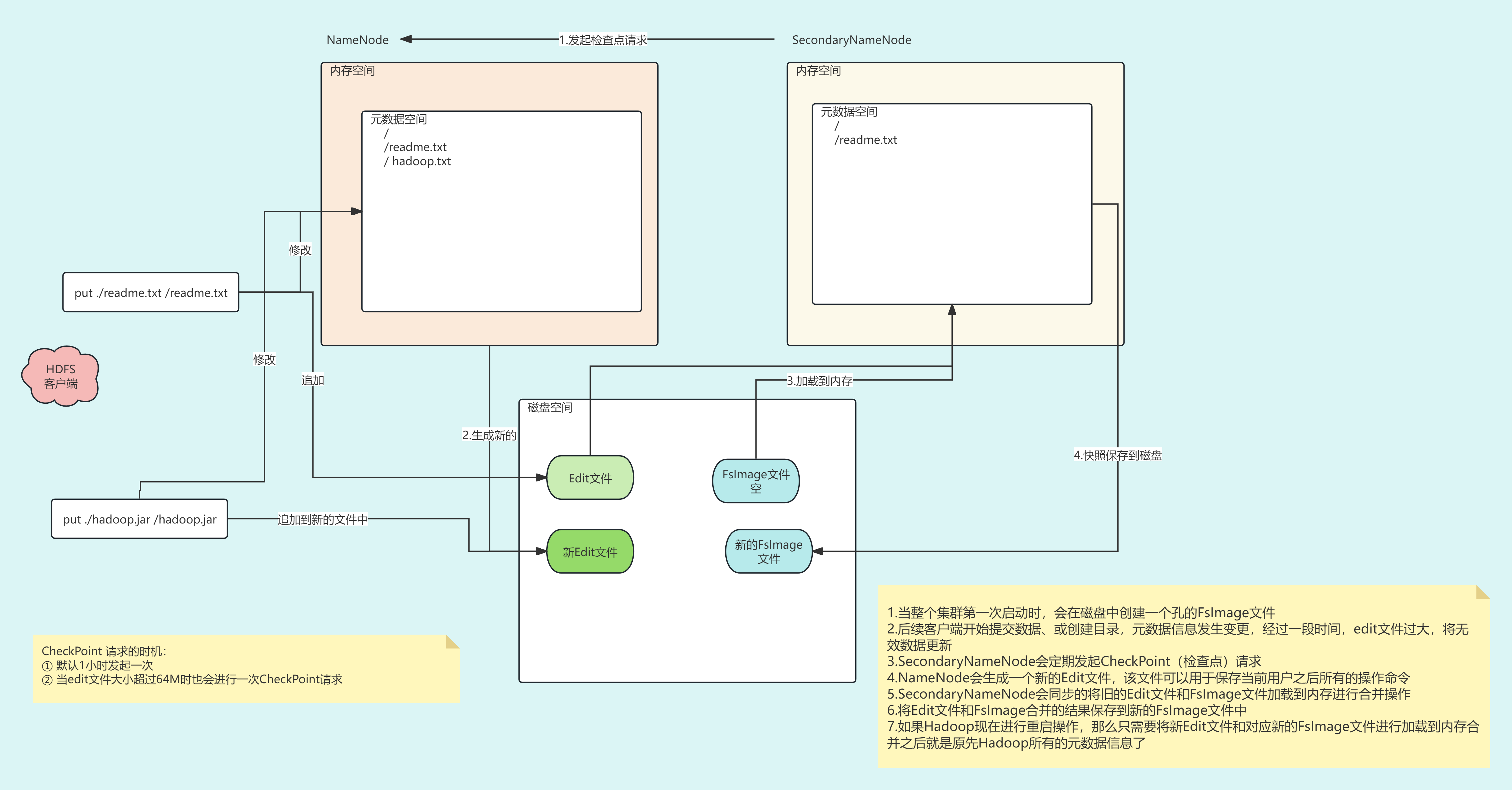
DataNode
作用:
为整个集群提供真实文件数据的存储服务,同时管理本节点中所有Block块
Block块大小
Block块是对文件进行切分得到的数据块,再将这些Block块存储到HDFS中的DataNode节点上,Block块大小该如何划分
如果文件大小为1G
Block块如果大小为 1M 一共会产生 1000个左右的Block块 ,此时HDFS有一个缺陷, 不能存储过的元数据信息,同时元数据过多,内存中检索的压力会很大
Block块如果大小为 256M 一共会产生 4 个Block 块,元数据信息少了,但是单个节点下载Block的压力较大,并且DataNode中维护较大的数据块压力大,后续计算时,根据计算本地化要求,计算单个的Block时间较长,计算压力大从时间角度考虑:
从内存中检索元数据信息的时间为 10ms 以内,同时Block块下载的时间要求为检索时间的100倍 -> 1s
于是 根据上述要求,一般网络和磁盘的IO速度 大概在128M/s ,那么Block大小可以设置为 128M大小 比较合适
设置BLock块大小的配置信息:
可以在hdfs-site.xml中dfs.blocksize属性配置Block块
注意:在HDFS中一个文件被切分BLock块时,如果数据量不足128M那么也会被保存为一个Block块
HDFS副本机制
HDFS中副本数默认为3,当数据存储到HDFS中时,需要对当前的数据复制两外两份,数据的存储位置此时就需要进行选择
副本保存策略:
前提:副本数现在为3的情况下
- 一个机架中保存一份数据 另外一个机架中保存两份数据
- 分机架保存,保证了数据在机架间的安全,但是不能分的过于分散,因为后续的数据丢失需要备份时,此时需要跨机架进行复制,此时链路较长,速度较慢,同时后续做数据计算时,也有可能会使用到同机架中其他数据
- Hadoop会根据网络的拓扑结构,感知到DataNode所在的机架
Hadoop页面内容
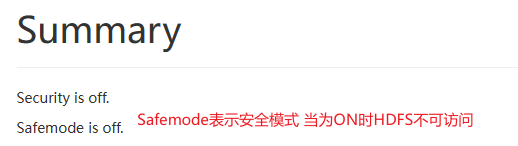
当HDFS的安全模式自动开启,没有关闭时,其原因:
基本为 DataNode 节点未启动,导致当前集群数据丢失,导致元数据一直处于更新状态
如何手动关闭该安全模式?
[-safemode <enter | leave | get | wait>]
hdfs dfsadmin -safemode enter 开启安全模式
# 当安全模式开启后,可以获取元数据信息,但是不能修改 #hdfs dfs -put fsimage.xml /# 关闭安全模式
hdfs dfsadmin -safemode leave
页面描述信息
DataNode页面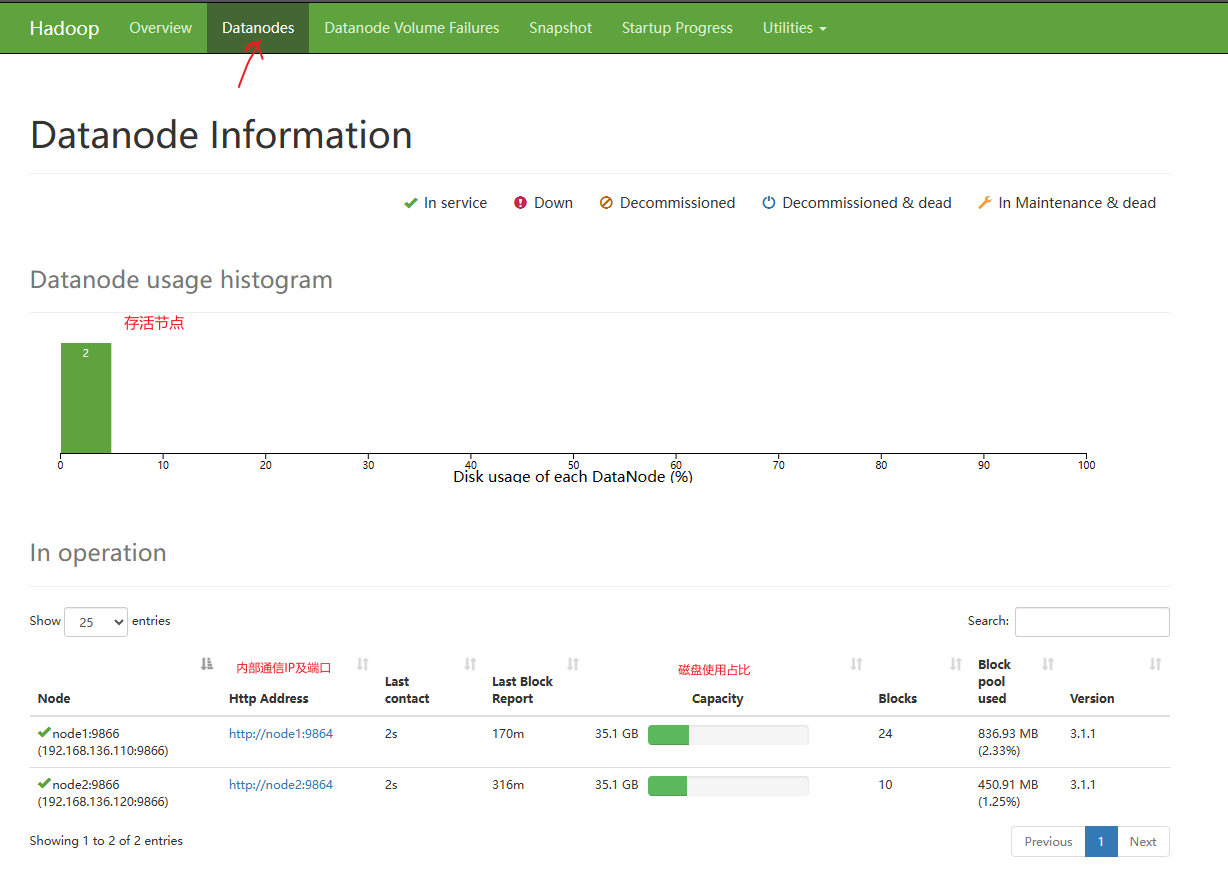
其他页面
Hadoop日志
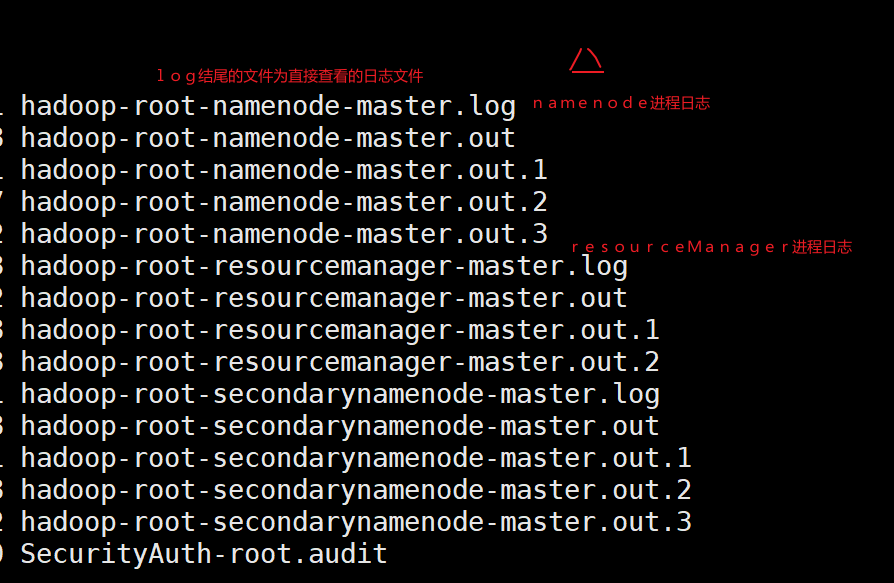
Hadoop框架运行过程中会产生大量的日志,如果集群存在问题,那么可以通过日志来分析其问题
日志保存路径:默认在按照目录下的logs目录中
日志查看可以使用 cat 或者 tail 命令 查看日志等级为 ERROR的
日志在主节点和从节点都存在,且日志目录路径一致
HDFS API操作
客户端环境准备
将hadoop-3.1.1.zip解压到D:\software下

添加HADOOP_HOME环境变量

添加path

验证 Hadoop 环境变量是否正常。cmd命令运行winutils.exe
winutils
要重启idea

创建项目并在pom中添加依赖
<dependencies><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.1</version></dependency></dependencies>
FileSysterm是使用java代码操作hdfs的api接口
文件操作
create 写文件
open 读取文件
delete 删除文件
目录操作
mkdirs 创建目录
delete 删除文件或目录
listStatus 列出目录的内容
getFileStatus 显示文件系统的目录和文件的元数据信息
getFileBlockLocations 显示文件存储位置
api的连接操作
主机名为master 需要在本地配置IP映射
C:\Windows\System32\drivers\etc中的hosts 添加 192.168.118.100 master
package com.shujia.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
public class Demo01HDFSCon {
public static void main(String[] args) throws IOException {
//1.获取操作对象 HDFS文件系统 可以使用FileSystem类
//注意包:org.apache.hadoop.fs.FileSystem
// new FileSystem(); // 构造方法为protected
//该类为配置类=>需要配置连接信息
Configuration conf = new Configuration();
//主机名为master 需要在本地配置IP映射
// C:\Windows\System32\drivers\etc中的hosts 添加 192.168.118.100 master
conf.set("fs.defaultFS","hdfs://master:9000");
//Configuration conf
FileSystem fileSystem=FileSystem.get(conf);
// 查看FileSystem中的实现类
// org.apache.hadoop.hdfs.DistributedFileSystem
System.out.println(fileSystem.getClass().getName());
// exists 可以判断某个路径在HDFS中是否存在
boolean exists = fileSystem.exists(new Path("/data"));
System.out.println("路径是否存在:"+exists);
// 关闭
fileSystem.close();
}
}
package com.shujia.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.*;
import org.apache.hadoop.fs.permission.FsPermission;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.util.Arrays;
public class Demo2Operator {
FileSystem fileSystem;
@Before
public void init() throws IOException {
Configuration conf = new Configuration();
// 主机名master 需要在本地配置 其IP 映射
// C:\Windows\System32\drivers\etc中的hosts 添加 192.168.118.100 master
conf.set("fs.defaultFS","hdfs://master:9000");
// Configuration conf 获得客户端对象
fileSystem = FileSystem.get(conf);
}
@Test
public void putData() throws IOException {
fileSystem.copyFromLocalFile(new Path("data/students.txt"),new Path("/data/students.txt"));
}
@Test
public void getData() throws IOException {
// 下载数据到本地 需要注意
// java.lang.RuntimeException: java.io.FileNotFoundException: java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset.
// 需要在本地配置Hadoop的环境变量 需要重启idea
fileSystem.copyToLocalFile(new Path("/data/students.txt"),new Path("data/download.txt"));
}
@Test
public void mkdir() throws IOException {
fileSystem.mkdirs(new Path("/api/test1"));
fileSystem.mkdirs(new Path("/api/test1/test11"));
}
@Test
public void delete() throws IOException {
//删除路径
fileSystem.delete(new Path("/api/test1/test11"));
}
@Test
public void listStatus() throws IOException {
FileStatus[] fileStatuses = fileSystem.listStatus(new Path("/api"));
for (FileStatus fileStatus : fileStatuses) {
Path path=fileStatus.getPath();
String owner = fileStatus.getOwner();
FsPermission permission = fileStatus.getPermission();
System.out.println("path:"+path+"\towner:"+owner+"\tpermission:"+permission);
}
System.out.println("==============");
FileStatus fileStatus = fileSystem.getFileStatus(new Path("/data/students.txt"));
Path path = fileStatus.getPath();
// Block块大小 => 128M长度
long blockSize = fileStatus.getBlockSize();
System.out.println(blockSize);
// len 数据长度
long len = fileStatus.getLen();
System.out.println(len);
// Block块所在位置
// getFileBlockLocations(FileStatus file, long start, long len)
// 需要传入一个FileStatus对象 开始下标(偏移量) 和长度
// 返回BlockLocation对象数组,该数组中每一个对象表示为Block的位置对象
System.out.println("++++++++++++++++++++++++");
BlockLocation[] fileBlockLocations = fileSystem.getFileBlockLocations(fileStatus, 0, len);
// 由于只有一个Block块,那么返回的就是该块的所有存储位置
for (BlockLocation blockLocation : fileBlockLocations) {
String[] hosts = blockLocation.getHosts();
System.out.println(Arrays.toString(hosts));
}
}
@Test
public void testMv() throws IOException {
//更改目录或文件名
fileSystem.rename(new Path("/api/test1"),new Path("/api/test2"));
}
@Test
public void fileDetail() throws IOException {
//获取文件所有信息
RemoteIterator<LocatedFileStatus> listFiles = fileSystem.listFiles(new Path("/"), true);
// 遍历文件
while (listFiles.hasNext()) {
LocatedFileStatus fileStatus = listFiles.next();
System.out.println("==========" + fileStatus.getPath() + "=========");
System.out.println(fileStatus.getPermission());
System.out.println(fileStatus.getOwner());
System.out.println(fileStatus.getGroup());
System.out.println(fileStatus.getLen());
System.out.println(fileStatus.getModificationTime());
System.out.println(fileStatus.getReplication());
System.out.println(fileStatus.getBlockSize());
System.out.println(fileStatus.getPath().getName());
// 获取块信息
BlockLocation[] blockLocations = fileStatus.getBlockLocations();
System.out.println(Arrays.toString(blockLocations));
}
}
@After
public void close() throws IOException {
fileSystem.close();
}
}
package com.shujia.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class Demo03Properties {
public static void main(String[] args) throws IOException, URISyntaxException, InterruptedException {
// 在当前本地执行时,使用的是Hadoop的默认配置,而Hadoop默认配置 副本数是 3 所以上传数据是3个副本 但是当前集群节点为 2
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://master:9000"); // 设置参数
// 方式1:在当前代码中进行修改配置参数
// conf.set("dfs.replication","1");
FileSystem fileSystem = FileSystem.get(conf);
fileSystem.copyFromLocalFile(new Path("hadoop/data/students.txt"),new Path("/api/"));
fileSystem.close();
// 方式2:可以在resources目录中添加配置
//将hdfs-site.xml 放到当前项目的resources目录下,改变该文件的value值,值为副本数量了,k
// 配置生效的等级:
// 代码 Configuration > hdfs-site.xml > 默认配置hdfs-default.xml
// // 用户如何改变
// Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://master:9000"); // 设置参数
// // 方式1:在当前代码中进行修改配置参数
// conf.set("dfs.replication","1");
// // FileSystem get(final URI uri, final Configuration conf, String user)
// // uri表示HDFS的访问路径
// // conf 表示默认配置参数
// // user 表示用户
// FileSystem fileSystem = FileSystem.get(new URI("hdfs://master:9000"),conf,"root");
// fileSystem.copyFromLocalFile(new Path("hadoop/data/students.txt"),new Path("/api/"));
// fileSystem.close();
}
}
练习:
create 写文件
使用IO流的方式将本地的students.txt数据写入到/api/create/目录中
open 读取文件
和create 方向相反
package com.shujia.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
public class Demo04CreateAndRead {
FileSystem fileSystem;
@Before
public void init() throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://master:9000");
fileSystem = FileSystem.get(conf);
}
@Test
public void createFile() throws IOException {
try (FileInputStream in = new FileInputStream("data/img.png")) {
// 创建HDFS输出流
FSDataOutputStream out = fileSystem.create(new Path("/data/img.png"), false);
byte[] buffer = new byte[1024];
int bytesRead;
// 从本地文件读取数据并写入HDFS
while ((bytesRead = in.read(buffer)) > 0) {
out.write(buffer, 0, bytesRead);
}
out.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
@Test
public void readFile(){
try (FSDataInputStream in = fileSystem.open(new Path("/data/img.png"));
FileOutputStream out = new FileOutputStream("data/local_img.png")) {
byte[] buffer = new byte[1024];
int bytesRead;
// 从HDFS文件读取数据并写入本地文件
while ((bytesRead = in.read(buffer)) > 0) {
out.write(buffer, 0, bytesRead);
}
out.flush();
} catch (IOException e) {
e.printStackTrace();
}
}
@After
public void close() throws IOException {
fileSystem.close();
}
}
将学生数据中男性和女性的人数进行统计,只读取hdfs内文件,由于文件过大不下载统计
package com.shujia.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
//Java是值传递,所以传递给processLine的maleCount和femaleCount只是它们的拷贝,而不是原始值。因此,对它们的修改不会影响到原始的maleCount和femaleCount。
//通过将maleCount和femaleCount封装到一个对象中,传递对象的引用,以便在方法内修改对象的属性。
class GenderCount {
int maleCount;
int femaleCount;
}
public class Demo05Total {
FileSystem fileSystem;
@Before
public void init() throws IOException {
Configuration conf = new Configuration();
conf.set("fs.defaultFS", "hdfs://master:9000");
fileSystem = FileSystem.get(conf);
}
@Test
//将学生数据中男性和女性的人数进行统计,将统计结果保存到HDFS中,分隔符使用, 写入过程要求使用 create 或者其他
public void total(){
try{
FSDataInputStream in = fileSystem.open(new Path("/data/students.txt"));
// 创建统计对象
GenderCount genderCount = new GenderCount();
byte[] buffer = new byte[1024];
int read;
// 上一个读取的剩余部分
String remaining = "";
while ((read = in.read(buffer)) > 0) {
String content = remaining + new String(buffer, 0, read);
String[] lines = content.split("\n");
for (int i = 0; i < lines.length - 1; i++) {
// 处理完整的行
String line = lines[i];
if (isValidDataFormat(line)) {
processLine(line, genderCount);
} else {
System.out.println("数据格式错误:" + line);
}
}
// 保存当前读取的剩余部分
remaining = lines[lines.length - 1];
}
// 处理最后一个读取周期的剩余部分
if (isValidDataFormat(remaining)) {
processLine(remaining, genderCount);
} else {
// 处理数据格式错误
System.err.println("数据格式错误: " + remaining);
}
// 输出统计结果
System.out.println("Male Count: " + genderCount.maleCount);
System.out.println("Female Count: " + genderCount.femaleCount);
} catch (IOException e) {
e.printStackTrace();
}
}
private boolean isValidDataFormat(String line) {
// 假设每行数据格式为 "学号,姓名,年龄,性别,班级"
String[] parts = line.split(",");
return parts.length == 5;
}
private void processLine(String line, GenderCount genderCount) {
// 假设每行数据格式为 "学号,姓名,年龄,性别,班级"
String[] parts = line.split(",");
String gender = parts[3].trim().toLowerCase();
if (gender.equals("男")) {
genderCount.maleCount++;
} else if (gender.equals("女")) {
genderCount.femaleCount++;
}
}
@After
public void close() throws IOException {
fileSystem.close();
}
}
API基础操作
● 上传
● 下载 -> 注意本地要配置hadoop的环境变量
● 创建⽂件夹
● 删除
● 获取状态
● 获取Block块存储位置
● 读取⽂件
● 写⼊⽂件
API做数据清洗思考
⼤数据的⼀般处理流程:
1.数据采集 2.数据存储 3.数据分析
当数据是存放在Mysql(业务系统数据存储的位置)中 —> 将数据通过API的⽅式采集到HDFS中对
应⽬录
业务系统中的数据⼀般情况下会存在有数据缺失的情况 于是需要对数据进⾏做数据清洗⼯作
数据清洗的逻辑:
1.对数据中的问题进⾏ 探查 -> 数据探查阶段
数据探查的⼀般思路:
① 统计当前表中的空值率
② 统计重复率
③ 编码是否异常
④ 异常值
2.需要根据数据中的问题进⾏针对性的清洗
① 如果有发现空值怎么处理?
② 重复数据是否能直接删除?
③ 编码异常如何解决
④ 对于异常值如何处理
上述问题如何处理,处理的思路及依据是什么?
⽐如当表中有⼀条数据,其中⼀个字段为空,那么如何处理,如果直接删除,那么删除的
依据是什么
需求:
将Mysql中的数据写⼊到HDFS中,并对数据进⾏初步清洗,其中清洗的问题是 经过数据探查发
现有编码异常需要进⾏编码统
HDFS 写读流程
4.1 HDFS 写数据流程
4.1.1 剖析文件 写入
借用尚硅谷的一个架构图:
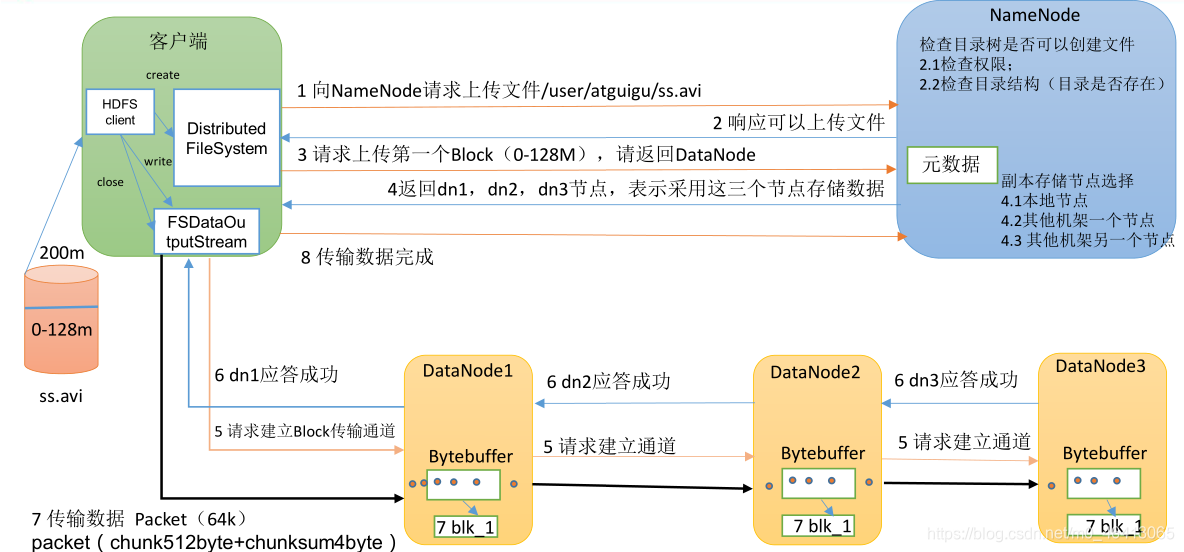
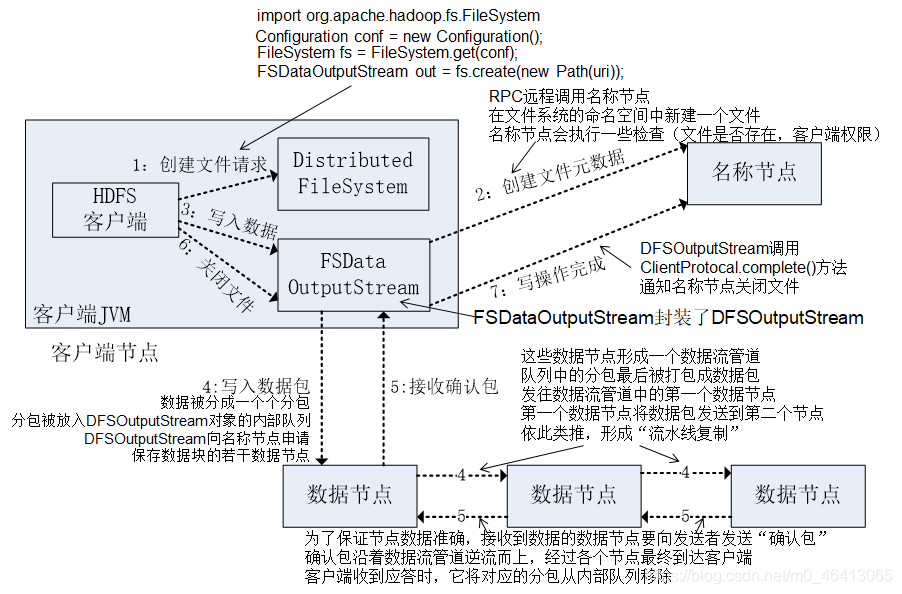
(1)客户端通过 Distributed FileSystem 模块向 NameNode 请求上传文件,NameNode 检
]查目标文件是否已存在,父目录是否存在。
(2)NameNode 返回是否可以上传。
(3)客户端请求第一个 Block 上传到哪几个 DataNode 服务器上。
(4)NameNode 返回 3 个 DataNode 节点,分别为 dn1、dn2、dn3。
(5) 客户端通过 FSDataOutputStream 模块请求 dn1 上传数据, dn1 收到请求会继续调用
dn2,然后 dn2 调用 dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3 逐级应答客户端。
(7) 客户端开始往 dn1 上传第一个 Block (先从磁盘读取数据放到一个本地内存缓存) ,
以 Packet 为单位,dn1 收到一个 Packet 就会传给 dn2,dn2 传给 dn3;dn1 每传一个 packet
会放入一个应答队列等待应答。
(8)当一个 Block 传输完成之后, 客户端再次请求 NameNode 上传第二个 Block 的服务
器。(重复执行 3-7 步)。
4.1.2 网络拓扑- 节点 距离计算
在 HDFS 写数据的过程中,NameNode 会选择距离待上传数据最近距离的 DataNode 接
收数据。那么这个最近距离怎么计算呢?
节点距离:两个节点到达最近的共同祖先的距离总和。
例如,假设有数据中心 d1 机架 r1 中的节点 n1。该节点可以表示为/d1/r1/n1。利用这种
标记,这里给出四种距离描述。
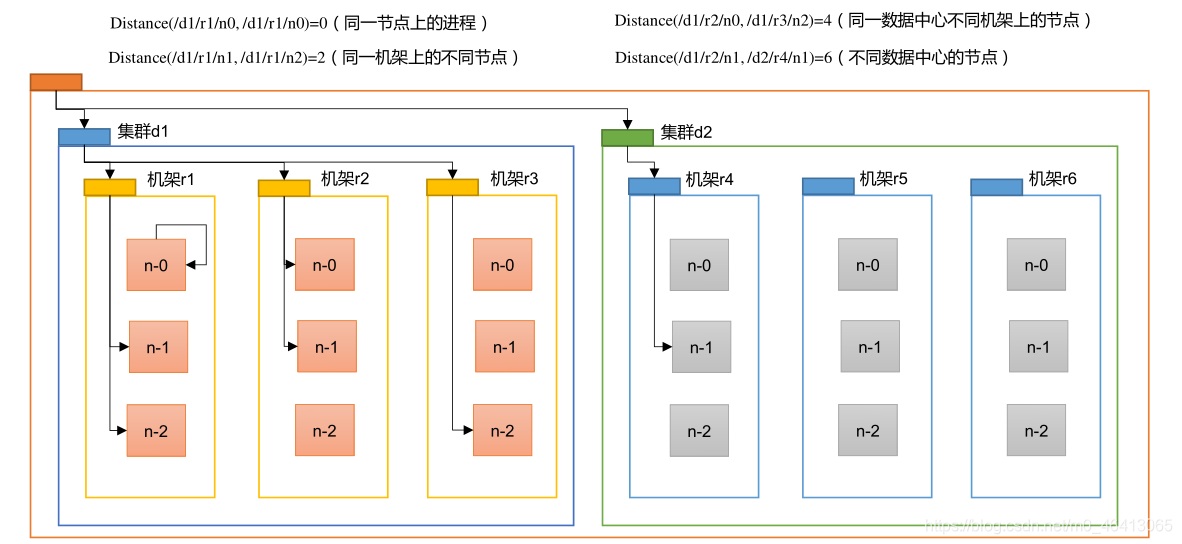
4.1.3 机架 感知 (副本 存储 节点 选择)
1 )机架感知说明
(1)官方说明
http://hadoop.apache.org/docs/r3.1.3/hadoop-project-dist/hadoop-hdfs/HdfsDesign.html#Data_Replication
For the common case, when the replication factor is three, HDFS’s placement policy is to put one replica on the local machine if the writer is on a datanode, otherwise on a random datanode, another replica on a node in a different (remote) rack, and the last on a different node in the same remote rack. This policy cuts the inter-rack write traffic which generally improves write performance. The chance of rack failure is far less than that of node failure; this policy does not impact data reliability and availability guarantees. However, it does reduce the aggregate network bandwidth used when reading data since a block is placed in only two unique racks rather than three. With this policy, the replicas of a file do not evenly distribute across the racks. One third of replicas are on one node, two thirds of replicas are on one rack, and the other third are evenly distributed across the remaining racks. This policy improves write performance without compromising data reliability or read performance.
(2)源码说明
Crtl + n 查找 BlockPlacementPolicyDefault,在该类中查找 chooseTargetInOrder 方法。
2 )Hadoop3.1.3 副本节点选择
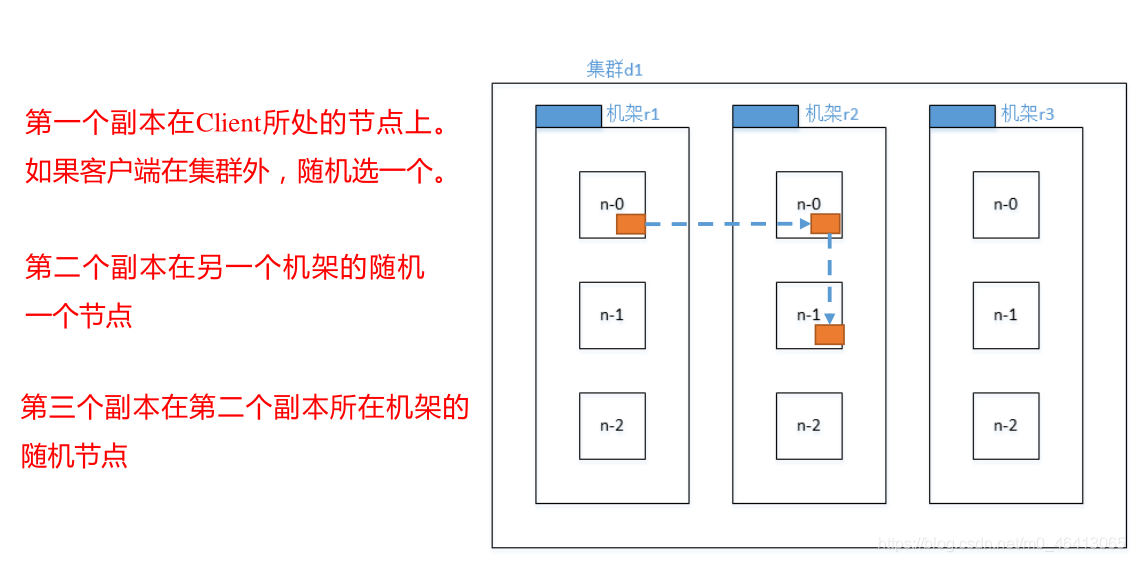
第一个选择最近的节点
第二个节点跨机架保证副本的可靠性
第三个节点还是兼顾效率
4.2 HDFS 读数据流程
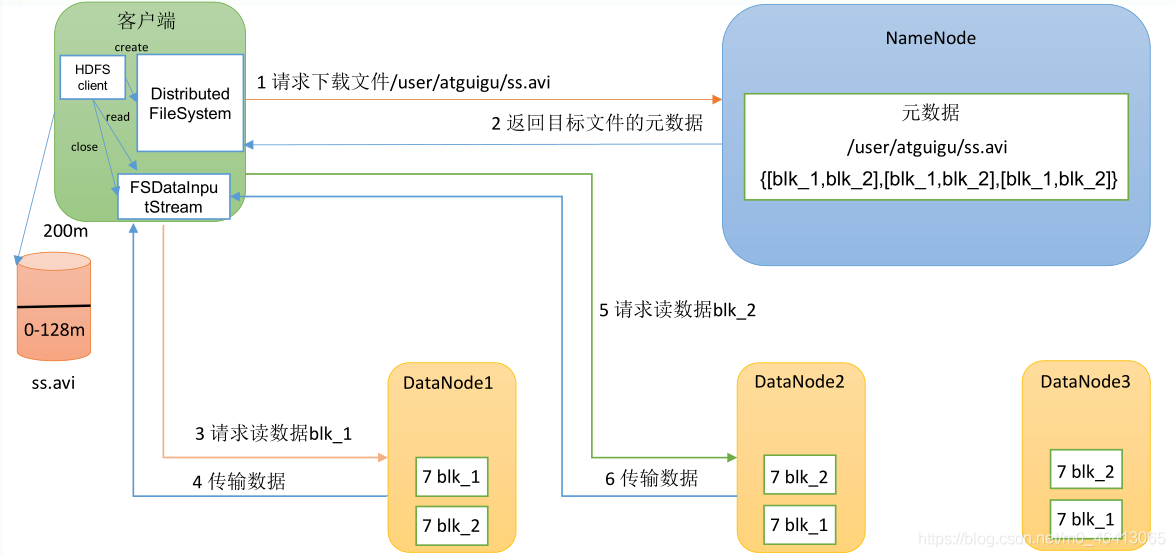
(1)客户端通过 DistributedFileSystem 向 NameNode 请求下载文件,NameNode 通过查询元数据,找到文件块所在的 DataNode 地址。
(2)挑选一台 DataNode(就近原则,然后随机(会考虑当前节点的负载能力))服务器,请求读取数据。
(3)DataNode 开始传输数据给客户端(从磁盘里面读取数据输入流,以 Packet 为单位来做校验)。
(4)客户端以 Packet 为单位接收,先在本地缓存,然后写入目标文件。
NameNode 和SecondaryNameNode
引入
5.1 NN 和 2NN 工作机制
思考:NameNode 中的元数据是存储在哪里的?
首先,我们做个假设,如果存储在 NameNode 节点的磁盘中,因为经常需要进行随机访问,还有响应客户请求,必然是效率过低。因此,元数据需要存放在内存中。但如果只存在内存中,一旦断电,元数据丢失,整个集群就无法工作了。因此产生在磁盘中备份元数据的FsImage。
这样又会带来新的问题,当在内存中的元数据更新时,如果同时更新 FsImage,就会导致效率过低,但如果不更新,就会发生一致性问题,一旦 NameNode 节点断电,就会产生数据丢失。因此,引入 Edits 文件(只进行追加操作,效率很高)。每当元数据有更新或者添加元数据时,修改内存中的元数据并追加到 Edits 中。这样,一旦 NameNode 节点断电,可以通过 FsImage 和 Edits 的合并,合成元数据。 但是,如果长时间添加数据到 Edits 中,会导致该文件数据过大,效率降低,而且一旦断电,恢复元数据需要的时间过长。因此,需要定期进行 FsImage 和 Edits 的合并,如果这个操作由NameNode节点完成, 又会效率过低。 因此, 引入一个新的节点SecondaryNamenode,专门用于 FsImage 和 Edits 的合并。
NameNode工作机制
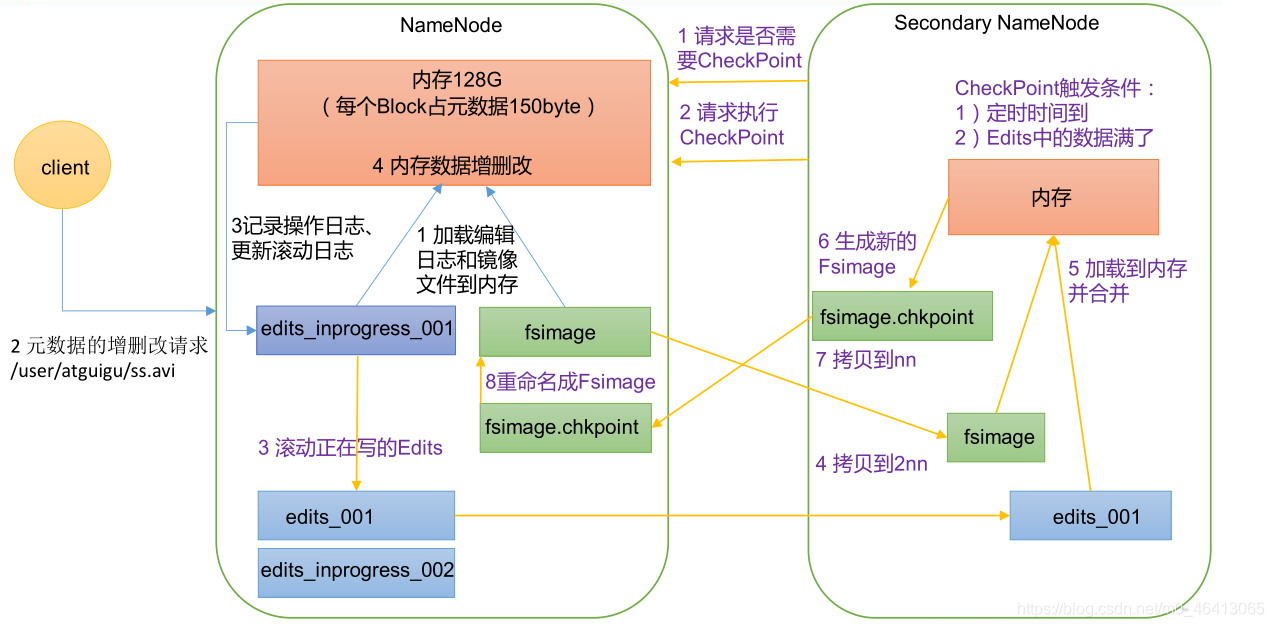
1 ) 第一 阶段:NameNode 启动
(1)第一次启动 NameNode 格式化后,创建 Fsimage 和 Edits 文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode 记录操作日志,更新滚动日志。
(4)NameNode 在内存中对元数据进行增删改。
2 ) 第二 阶段:Secondary NameNode 工作
(1)Secondary NameNode 询问 NameNode 是否需要 CheckPoint。直接带回 NameNode是否检查结果。
(2)Secondary NameNode 请求执行 CheckPoint。
(3)NameNode 滚动正在写的 Edits 日志。
(4)将滚动前的编辑日志和镜像文件拷贝到 Secondary NameNode。
(5)Secondary NameNode 加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件 fsimage.chkpoint。
(7)拷贝 fsimage.chkpoint 到 NameNode。
(8)NameNode 将 fsimage.chkpoint 重新命名成 fsimage。
5.2 Fsimage 和 Edits 解析

1 )oiv 查看 Fsimage 文件
(1)查看 oiv 和 oev 命令
[leokadia@hadoop102 current]$ hdfs
oiv apply the offline fsimage viewer to an fsimage
oev apply the offline edits viewer to an edits file
(2)基本语法
hdfs oiv -p 文件类型 -i 镜像文件 -o 转换后文件输出路径
(3)案例实操
[leokadia@hadoop102 current]$
pwd
/opt/module/hadoop-3.1.3/data/dfs/name/current
[leokadia@hadoop102 current]$
hdfs oiv -p XML -i fsimage_0000000000000000261 -o /opt/module/hadoop-3.1.3/fsimage.xml
在刚刚的输出目录下找到了镜像文件
现在将其传输到windows环境:
将其下载到桌面上
打开镜像文件查看
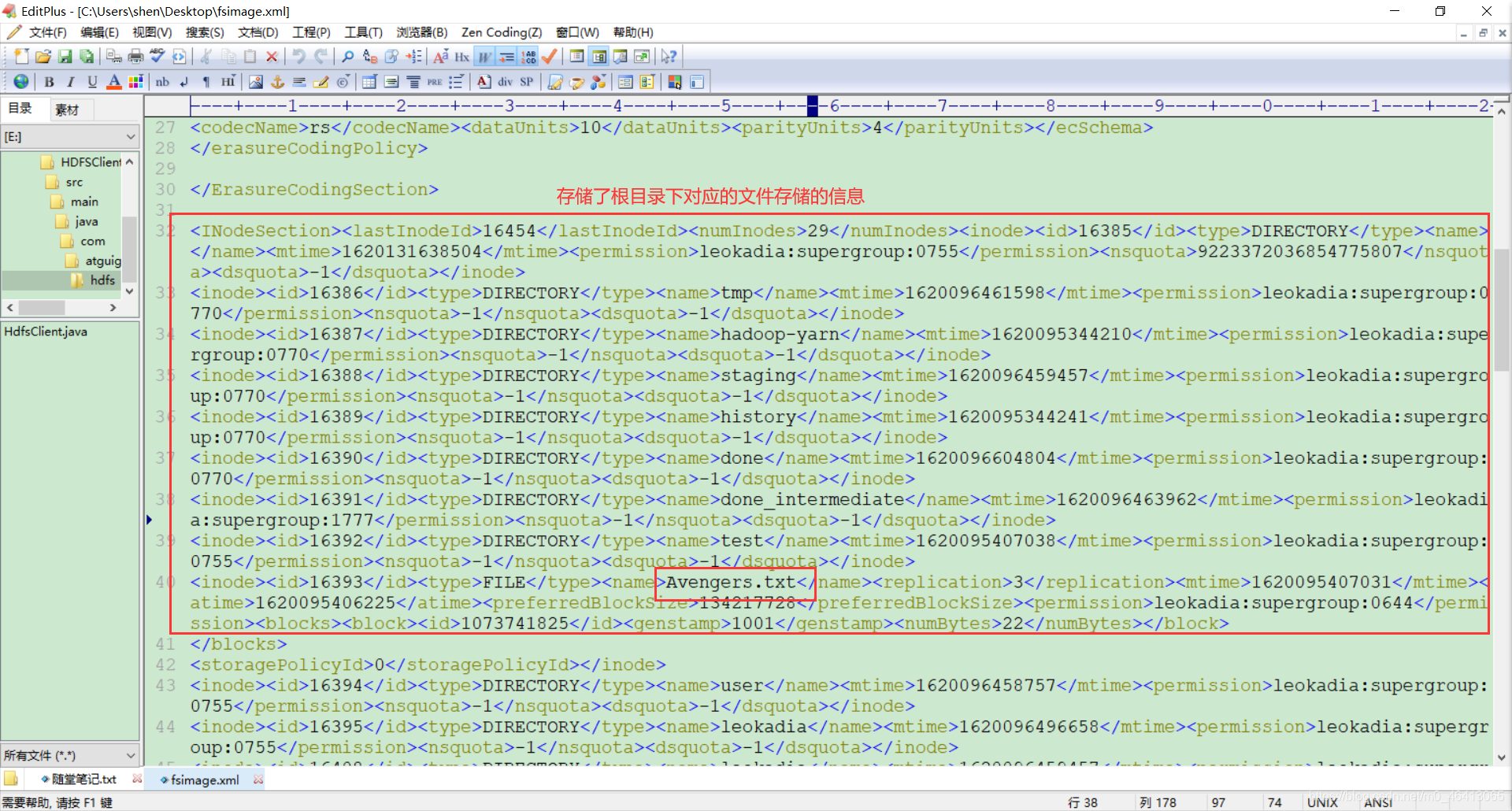
思考:可以看出,Fsimage 中没有记录块所对应 DataNode,为什么?
在集群启动后,要求 DataNode 上报数据块信息,并间隔一段时间后再次上报。
2 )oev 查看 Edits 文件
(1)基本语法
hdfs oev -p 文件类型 -i 编辑日志 -o 转换后文件输出路径
(2)案例实操
[leokadia@hadoop102 current]$ hdfs oev -p XML -i edits_inprogress_0000000000000000262 -o/opt/module/hadoop-3.1.3/edits.xml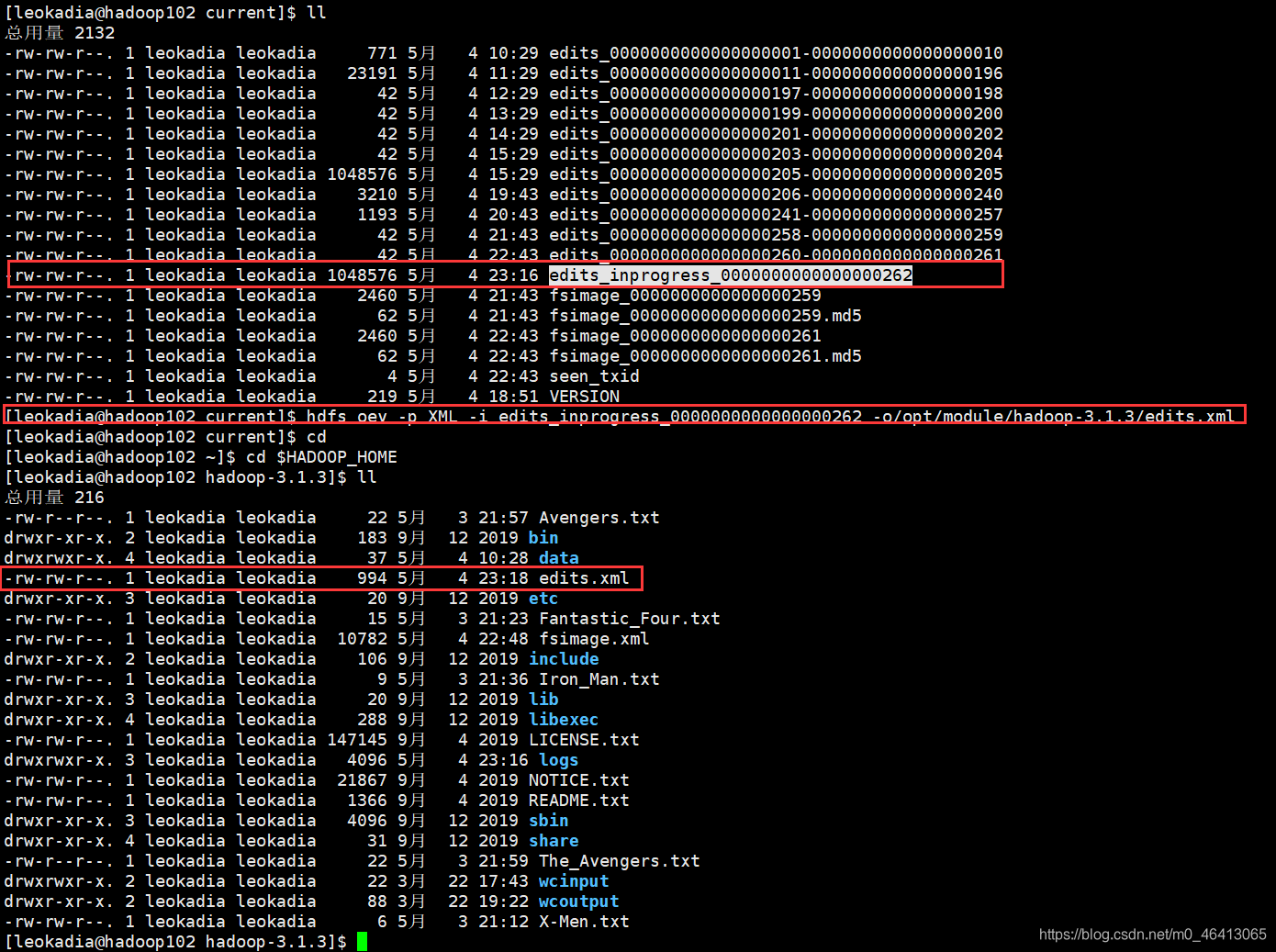
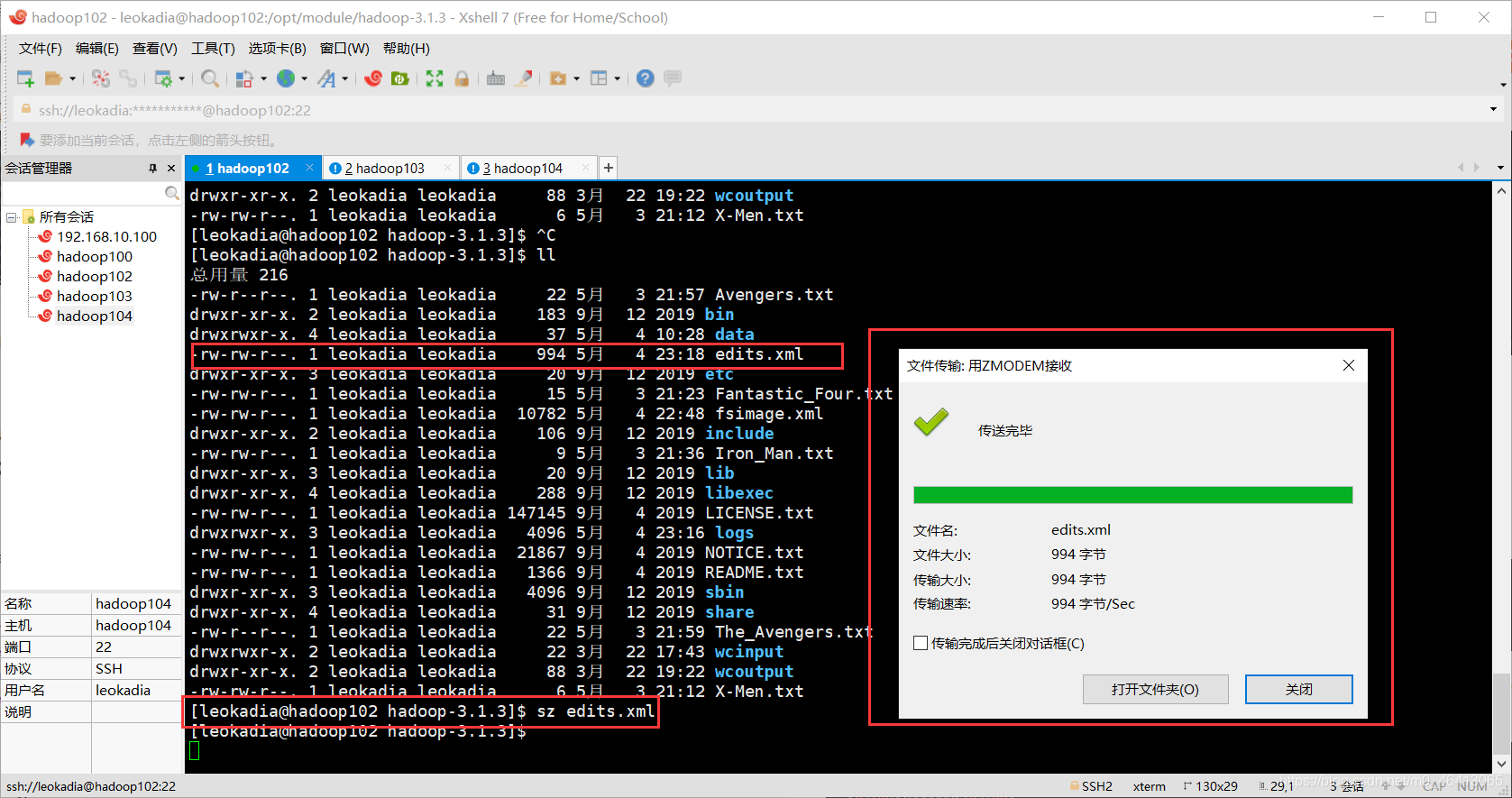
继续下载到桌面:
[leokadia@hadoop102 hadoop-3.1.3]$
sz edits.xml
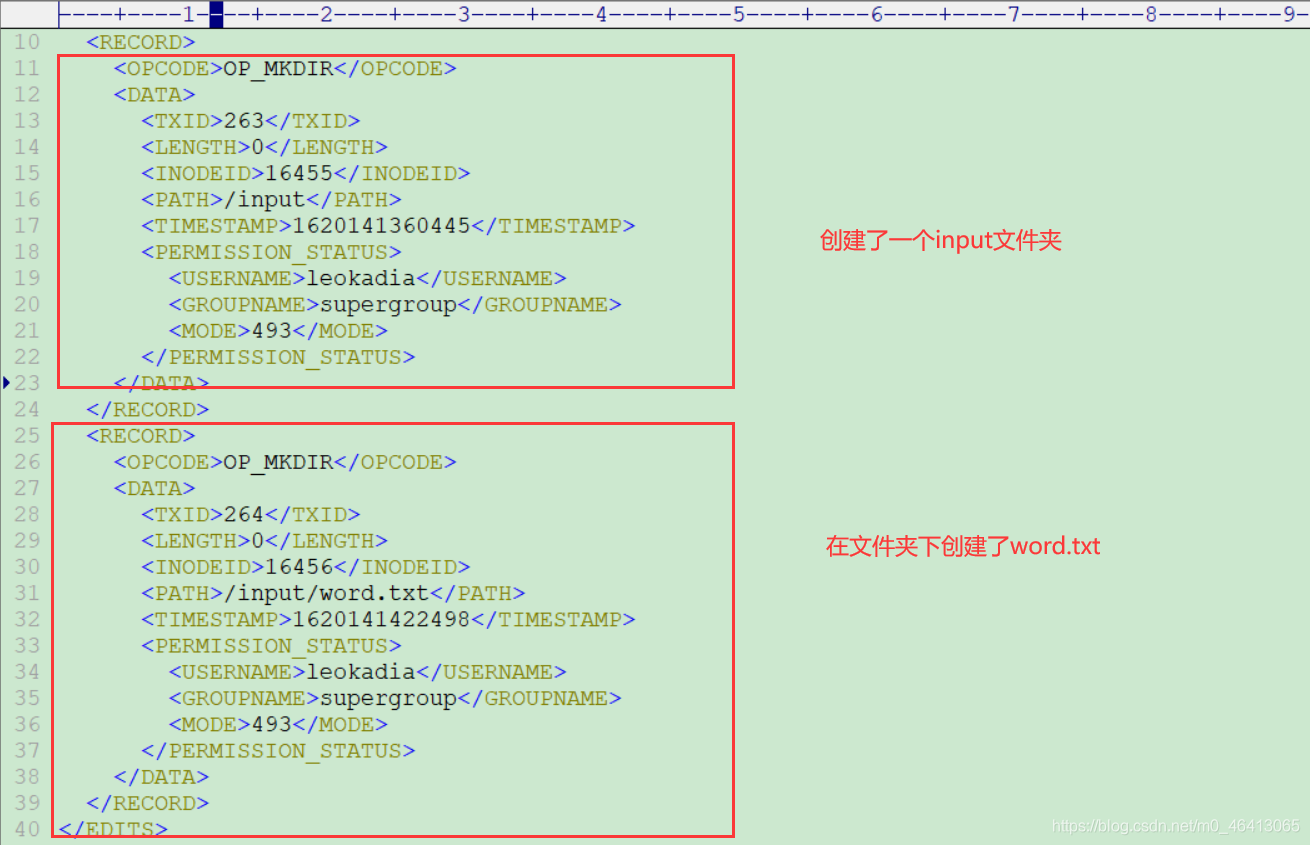
思考:NameNode 如何确定下次开机启动的时候合并哪些 Edits?
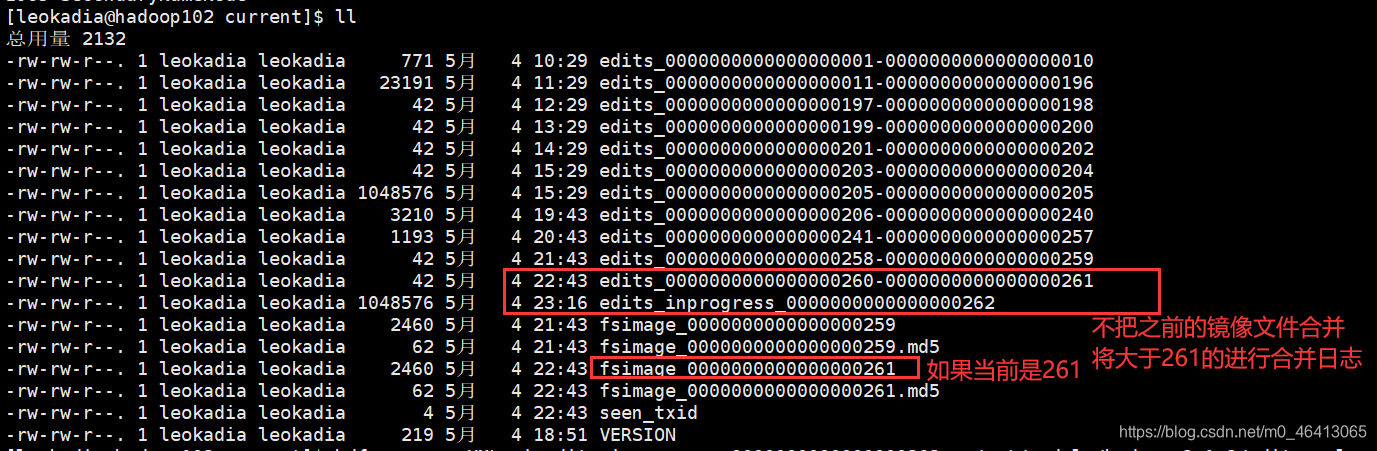
注意时间,看到每间隔1h进行一次合并
集群一停止、开关机也要合并一次
5.3 CheckPoint 时间设置
1 ) 通常情况下,SecondaryNameNode 每隔一小时执行一次
[hdfs-default.xml]
<property>
<name>dfs.namenode.checkpoint.period</name>
<value>3600s</value>
</property>
2 ) 一分钟检查一次操作次数,当操作次数达到 1 百万时,SecondaryNameNode执行一次
<property>
<name>dfs.namenode.checkpoint.txns</name>
<value>1000000</value>
<description>操作动作次数</description>
</property>
<property>
<name>dfs.namenode.checkpoint.check.period</name>
<value>60s</value>
<description> 1 分钟检查一次操作次数</description>
</property>
SecondaryNameNode是用来帮助NameNode完成元数据信息合并,从角色上看属于NameNode的“秘书”
其工作流程如下:
- secondary向NameNode发起Checkpoint请求
- secondary从namenode获得fsimage和edits
- secondary将fsimage载入内存,然后开始合并edits
- secondary将新的fsimage发回给namenode
5.namenode用新的fsimage替换旧的fsimage
CheckPoint发起时机:
1.fs.checkpoint.period 指定两次checkpoint的最大时间间隔,默认3600秒。
2.fs.checkpoint.size 规定edits文件的最大值,一旦超过这个值则强制checkpoint,不管是否到达最大时间间隔默认大小是64M。
DataNode
6.1 DataNode 工作机制
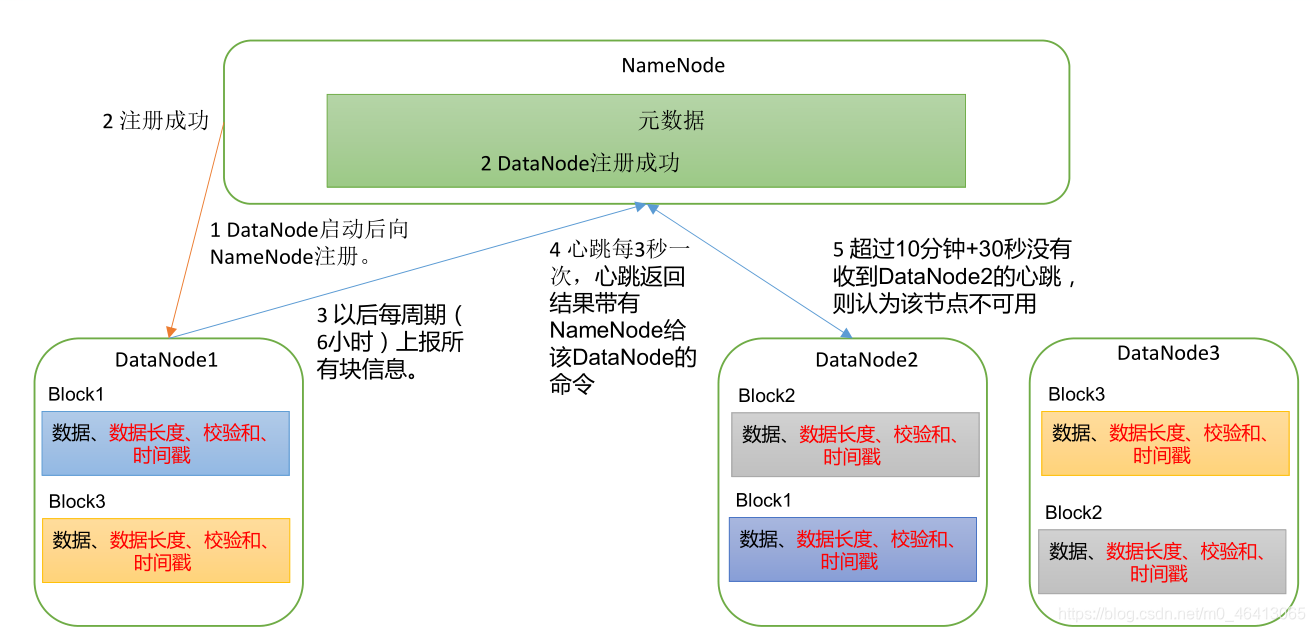
(1)一个数据块在 DataNode 上以文件形式存储在磁盘上,包括两个文件,一个是数据本身,一个是元数据包括数据块的长度,块数据的校验和,以及时间戳。
(2)DataNode 启动后向 NameNode 注册,通过后,周期性(6 小时)的向 NameNode 上报所有的块信息。
相关配置参数如下:
DN 向 NN 汇报当前解读信息的时间间隔,默认 6 小时;
相关配置参数如下:
<property>
<name>dfs.blockreport.intervalMsec</name>
<value>21600000</value>
<description>Determines block reporting interval in
milliseconds.</description>
</property>
DN 扫描自己节点块信息列表的时间,默认 6 小时
相关配置参数如下:
<property>
<name>dfs.datanode.directoryscan.interval</name>
<value>21600s</value>
<description>Interval in seconds for Datanode to scan data
directories and reconcile the difference between blocks in memory and on
the disk.
Support multiple time unit suffix(case insensitive), as described
in dfs.heartbeat.interval.
</description>
</property>
3)心跳是每 3 秒一次,心跳返回结果带有 NameNode 给该 DataNode 的命令如复制块数据到另一台机器, 或删除某个数据块。 如果超过 10 分钟+30s没有收到某个 DataNode 的心跳,则认为该节点不可用。 就认为该节点挂了,不会再向其传输信息。
(4)集群运行中可以安全加入和退出一些机器。
6.2 数据完整性
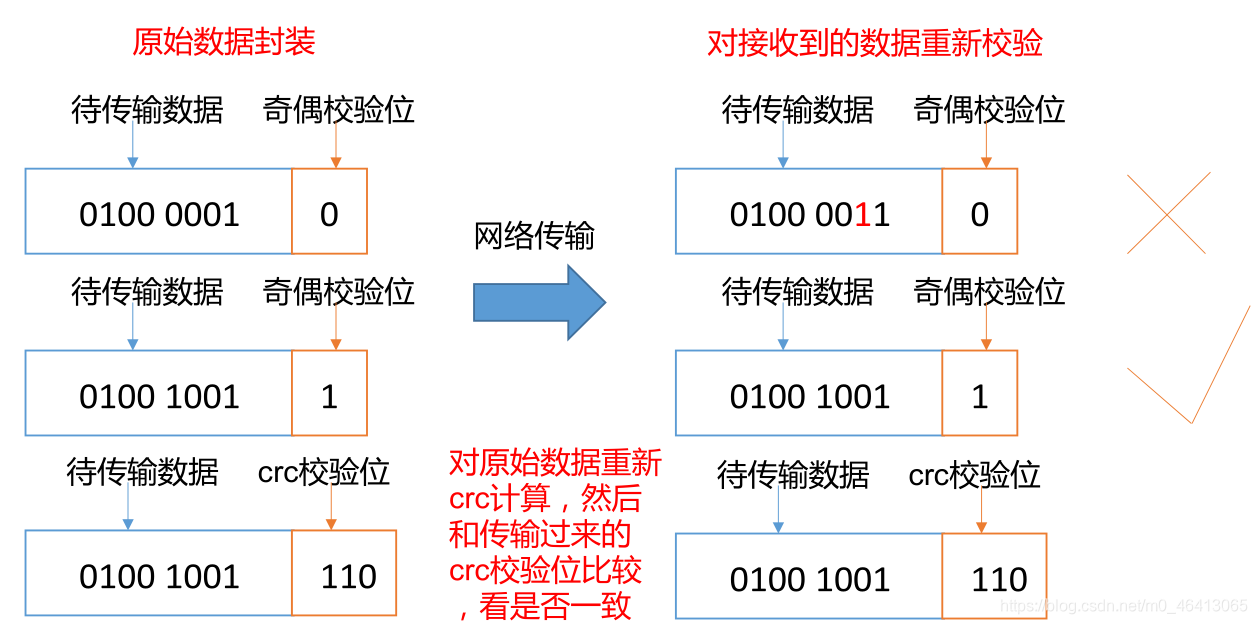
思考: 如果电脑磁盘里面存储的数据是控制高铁信号灯的红灯信号 (1) 和绿灯信号 (0) ,但是存储该数据的磁盘坏了,一直显示是绿灯,是否很危险?同理 DataNode 节点上的数据损坏了,却没有发现,是否也很危险,那么如何解决呢?
如下是 DataNode 节点保证数据完整性的方法。
(1)当 DataNode 读取 Block 的时候,它会计算 CheckSum。
(2)如果计算后的 CheckSum,与 Block 创建时值不一样,说明 Block 已经损坏。
(3)Client 读取其他 DataNode 上的 Block。
(4)常见的校验算法 crc(32),md5(128),sha1(160)
(5)DataNode 在其文件创建后周期验证 CheckSum。
6.3 DataNode掉线时限参数设置
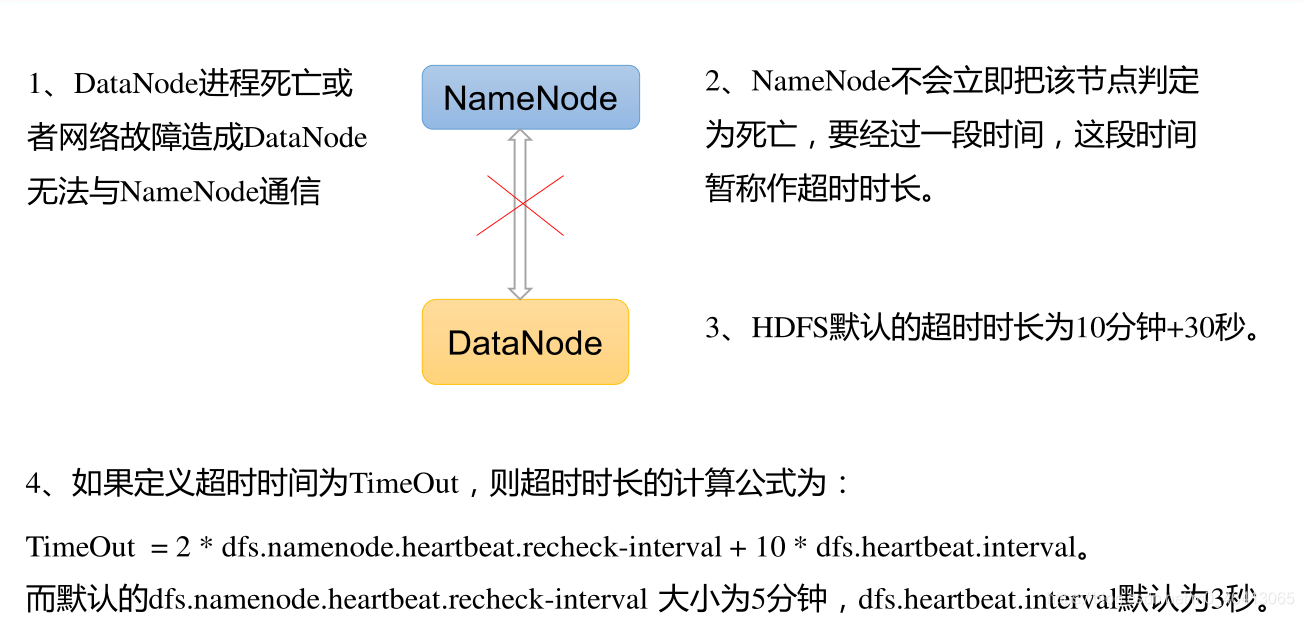
需要注意的是 hdfs-site.xml 配置文件中的 heartbeat.recheck.interval 的单位为毫秒,dfs.heartbeat.interval 的单位为秒。
相关配置参数如下:
<property>
<name>dfs.namenode.heartbeat.recheck-interval</name>
<value>300000</value>
</property>
<property>
<name>dfs.heartbeat.interval</name>
<value>3</value>
</property>
练习:数据清洗的逻辑:
1.对数据中的问题进行 探查 -> 数据探查阶段
数据探查的一般思路:
① 统计当前表中的空值率
② 统计重复率
③ 编码是否异常
④ 异常值
2.需要根据数据中的问题进行针对性的清洗
① 如果有发现空值怎么处理?
② 重复数据是否能直接删除?
③ 编码异常如何解决
④ 对于异常值如何处理
对给的student.sql中的数据进行清洗写入HDFS中,并向客户说明数据清洗的逻辑以及依据

package com.shujia.hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.FileNotFoundException;
import java.io.FileReader;
import java.io.IOException;
import java.sql.*;
import java.util.Properties;
public class Demo7MysqlHadoop {
public static void main(String[] args) throws IOException, ClassNotFoundException, SQLException {
/*
数据清洗的逻辑:
1.对数据中的问题进行 探查 -> 数据探查阶段
数据探查的一般思路:
① 统计当前表中的空值率
② 统计重复率
③ 编码是否异常
④ 异常值
2.需要根据数据中的问题进行针对性的清洗
① 如果有发现空值怎么处理?
② 重复数据是否能直接删除?
③ 编码异常如何解决
④ 对于异常值如何处理
对给的student.sql中的数据进行清洗写入HDFS中,并向客户说明数据清洗的逻辑以及依据
*/
/*
TODO:
1.连接Mysql,对要采集的数据进行读取
2.针对问题数据,需要使用代码进行判断编码是否存在问题
3.将清洗后的数据直接使用FileSystem对象写入到HDFS当中
hdfs dfs -cat /data/mysql_stu_data.csv |head -n 20
//xShell命令读取前20行
*/
Properties properties=new Properties();
properties.load(new FileReader("C:\\Users\\19783\\IdeaProjects\\bigdate28_1\\hadoop\\src\\main\\resources\\mysqlPool.properties"));
String driver=properties.getProperty("driver");
String url = properties.getProperty("url");
String user = properties.getProperty("user");
String passwd = properties.getProperty("passwd");
String hdfsPath = properties.getProperty("hdfs_path");
// TODO:获取HDFS连接对象
Configuration conf = new Configuration();
conf.set("fs.defaultFS","hdfs://master:9000");
FileSystem fileSystem=FileSystem.get(conf);
// TODO:创建HDFS的输出流
FSDataOutputStream fsDataOutputStream = fileSystem.create(new Path(hdfsPath));
// TODO:1.注册MySQL驱动
Class.forName(driver);
// TODO:2.获取连接
Connection myCon = DriverManager.getConnection(url, user, passwd);
// TODO:3.获取操作对象
Statement statement = myCon.createStatement();
//TODO:4.执行SQL语句
String sql="SELECT * FROM student";
ResultSet resultSet=statement.executeQuery(sql);
//TODO:5.遍历数据并进行数据清洗,在存入hdfs
while(resultSet.next()){
int id = resultSet.getInt("id");
String name = resultSet.getString("name");
int age = resultSet.getInt("age");
String gender = resultSet.getString("gender");
String clazz = resultSet.getString("clazz");
// TODO: 对数据进行清洗 : 编码异常 将 0-> 女 1-> 男 空值不做处理
if (gender.equals("0")) {
gender = "女";
}
if (gender.equals("1")) {
gender = "男";
}
// TODO:将清洗后的数据写入HDFS
// 按行写出到HDFS中,并且是字符
if (id != 0 && !name.isEmpty() && age != 0 && !gender.isEmpty() && !clazz.isEmpty()) {
fsDataOutputStream.write((id + "," + name + "," + age + "," + gender + "," + clazz + "\n").getBytes());
fsDataOutputStream.flush();
}
}
// TODO: 6.关闭
statement.close();
myCon.close();
}
}
Hadoop----hdfs dfs常用命令的使用
第一种:全部启动集群所有进程
启动:start-all.sh
停止:stop-all.sh
第二种:单独启动hdfs【web端口50070】和yarn【web端口8088】的相关进程
启动:start-dfs.sh sbin/start-yarn.sh
停止:stop-dfs.sh sbin/stop-yarn.sh
每次重新启动集群的时候使用
第三种:单独启动某一个进程
启动hdfs:hadoop-daemon.sh start (namenode | datanode)
停止hdfs:hadoop-daemon.sh stop (namenode | datanode)
启动yarn:yarn-daemon.sh start (resourcemanager | nodemanager)
停止yarn:yarn-daemon.sh stop(resourcemanager | nodemanager)
用于当某个进程启动失败或者异常down掉的时候,重启进程
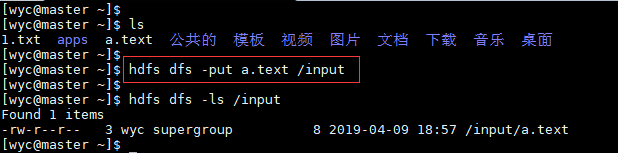
1.上传
hdfs dfs -put 本地路径 HDFS路径
hdfs dfs -copyFromLocal 本地路径 HDFS路径
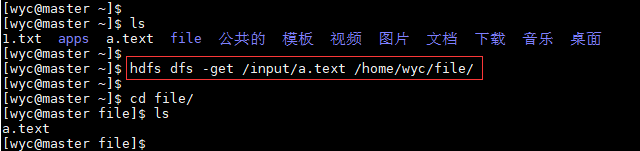
2.下载
hdfs dfs -get HDFS路径 本地路径
hdfs dfs -copyToLocal HDFS路径 本地路径
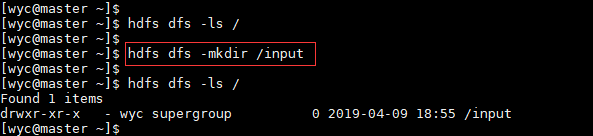
3.创建目录
hdfs dfs -mkdir HDFS路径
1.-mkdir
创建目录
Usage:hdfs dfs -mkdir [-p] < paths>
选项:-p
很像Unix mkdir -p,沿路径创建父目录。
2.-ls
查看目录下内容,包括文件名,权限,所有者,大小和修改时间
Usage:hdfs dfs -ls [-R] < args>
选项:-R
递归地显示子目录下的内容
3.-put
将本地文件或目录上传到HDFS中的路径
Usage:hdfs dfs -put < localsrc> … < dst>
4.-get
将文件或目录从HDFS中的路径拷贝到本地文件路径
Usage:hdfs dfs -get [-ignoreCrc] [-crc] < src> < localdst>
选项:
-ignorecrc选项复制CRC校验失败的文件。
-crc选项复制文件和CRC。
5.-du
显示给定目录中包含的文件和目录的大小或文件的长度,用字节大小表示,文件名用完整的HDFS协议前缀表示,以防它只是一个文件。
Usage:hdfs dfs -du [-s] [-h] URI [URI …]
选项:
-s选项将显示文件长度的汇总摘要,而不是单个文件。
-h选项将以“人类可读”的方式格式化文件大小(例如64.0m而不是67108864)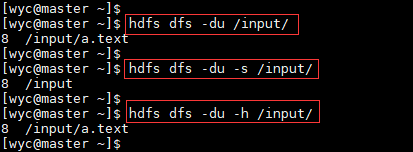
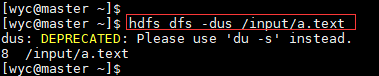
6.-dus
显示文件长度的摘要。
Usage:hdfs dfs -dus < args>
注意:不推荐使用此命令。而是使用hdfs dfs -du -s。
7.-mv
在HDFS文件系统中,将文件或目录从HDFS的源路径移动到目标路径。不允许跨文件系统移动文件。
Usage: hdfs dfs -mv URI [URI …] < dest>

8.-cp
在HDFS文件系统中,将文件或目录复制到目标路径下
Usage:hdfs dfs -cp [-f] [-p | -p [topax] ] URI [ URI …] < dest>
选项:
-f选项覆盖已经存在的目标。
-p选项将保留文件属性[topx](时间戳,所有权,权限,ACL,XAttr)。如果指定了-p且没有arg,则保留时间戳,所有权和权限。如果指定了-pa,则还保留权限,因为ACL是一组超级权限。确定是否保留原始命名空间扩展属性与-p标志无关。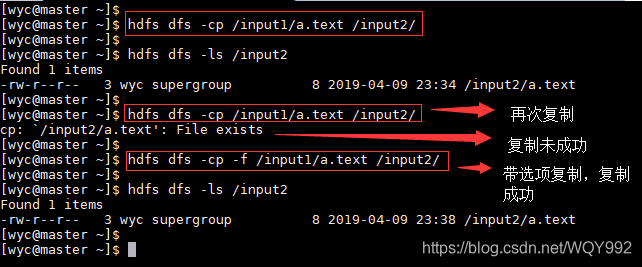
9.-copyFromLocal
从本地复制文件到hdfs文件系统(与-put命令相似)
Usage: hdfs dfs -copyFromLocal < localsrc> URI
选项:
如果目标已存在,则-f选项将覆盖目标。
10.-copyToLocal
复制hdfs文件系统中的文件到本地 (与-get命令相似)
Usage: hdfs dfs -copyToLocal [-ignorecrc] [-crc] URI < localdst>
11.-rm
删除一个文件或目录
Usage:hdfs dfs -rm [-f] [-r|-R] [-skipTrash] URI [URI …]
选项:
如果文件不存在,-f选项将不显示诊断消息或修改退出状态以反映错误。
-R选项以递归方式删除目录及其下的任何内容。
-r选项等效于-R。
-skipTrash选项将绕过垃圾桶(如果已启用),并立即删除指定的文件。当需要从超配额目录中删除文件时,这非常有用。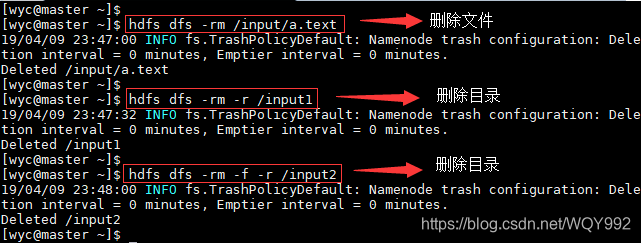
12.-cat
显示文件内容到标准输出上。
Usage:hdfs dfs -cat URI [URI …]

13.-text
Usage: hdfs dfs -text
获取源文件并以文本格式输出文件。允许的格式为zip和TextRecordInputStream。
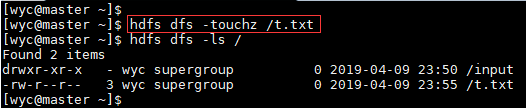
14.-touchz
创建一个零长度的文件。
Usage:hdfs dfs -touchz URI [URI …]
15.-stat
显示文件所占块数(%b),文件名(%n),块大小(%n),复制数(%r),修改时间(%y%Y)。
Usage:hdfs dfs -stat URI [URI …]
16.-tail
显示文件的最后1kb内容到标准输出
Usage:hdfs dfs -tail [-f] URI
选项:
-f选项将在文件增长时输出附加数据,如在Unix中一样。
17.-count
统计与指定文件模式匹配的路径下的目录,文件和字节数
Usage: hdfs dfs -count [-q] [-h] < paths>
18.-getmerge
将源目录和目标文件作为输入,并将src中的文件连接到目标本地文件(把两个文件的内容合并起来)
Usage:hdfs dfs -getmerge < src> < localdst> [addnl]
注:合并后的文件位于当前目录,不在hdfs中,是本地文件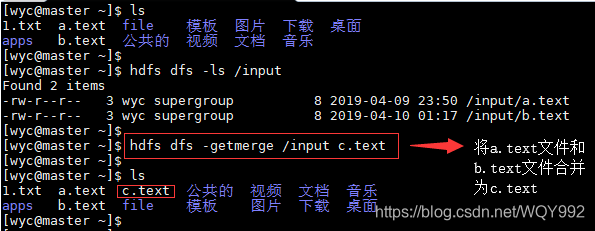
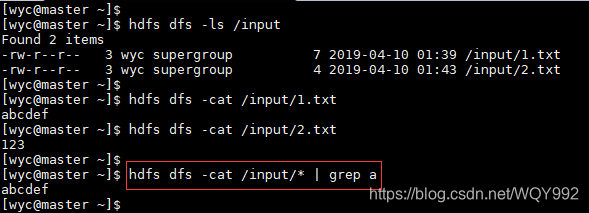
19.-grep
从hdfs上过滤包含某个字符的行内容
Usage:hdfs dfs -cat < srcpath> | grep 过滤字段
RPC协议
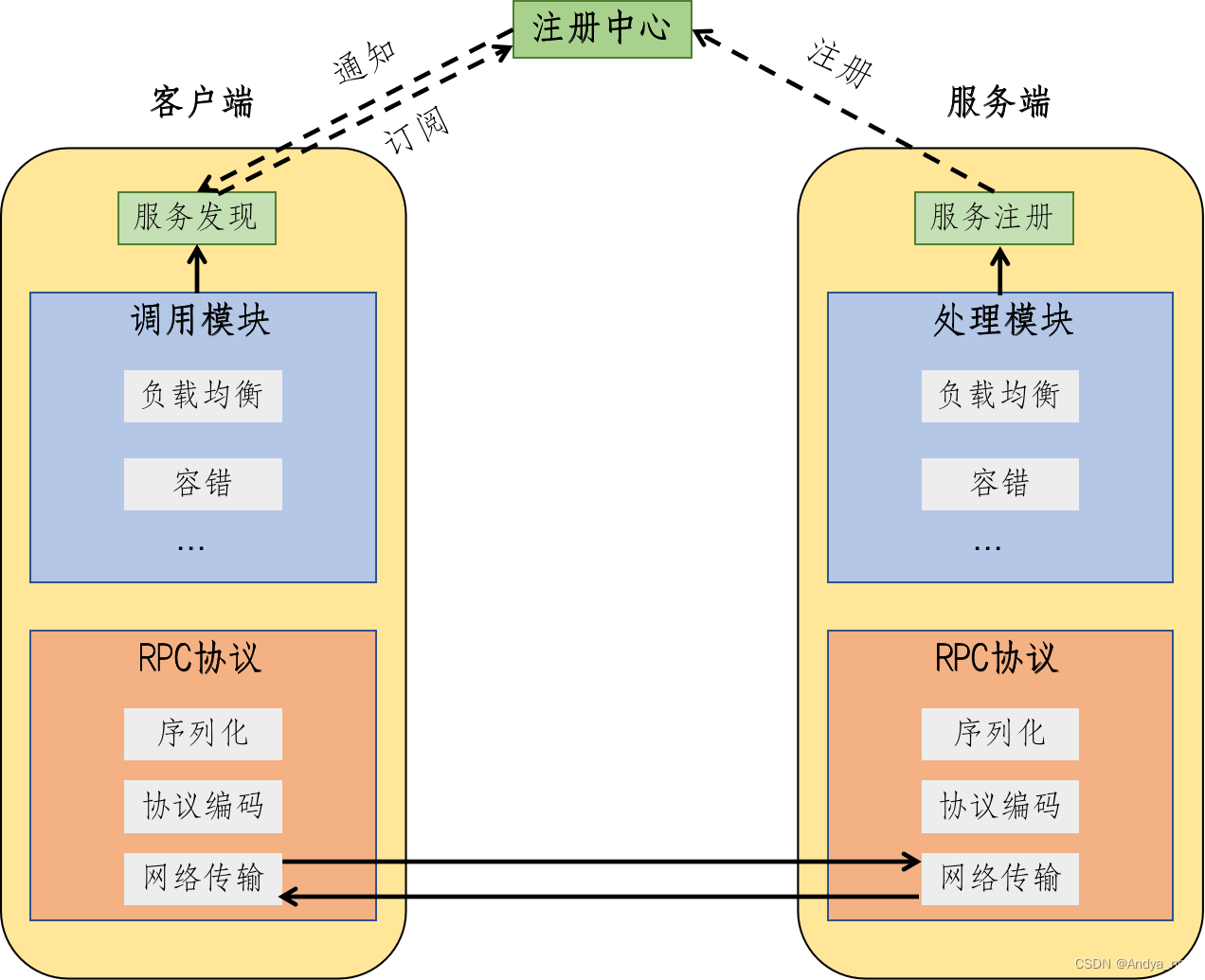
RPC为远程过程调用协议,它是一种通过网络从远程计算机程序上请求服务,而不需要了解底层网络技术的协议。RPC协议假定某些传输协议的存在,如TCP或UDP,为通信程序之间携带信息数据。
RPC采用客户机(client)/服务器(server)模式。请求程序就是一个客户机,而服务提供程序就是一个服务器。首先,客户机调用进程发送一个有进程参数的调用信息到服务进程,然后等待应答信息。在服务器端,进程保持睡眠状态直到调用信息的到达为止。当一个调用信息到达,服务器获得进程参数,计算结果,发送答复信息,然后等待下一个调用信息,最后,客户端调用进程接收答复信息,获得进程结果,然后调用执行继续进行。
架构图
一次RPC调用流程
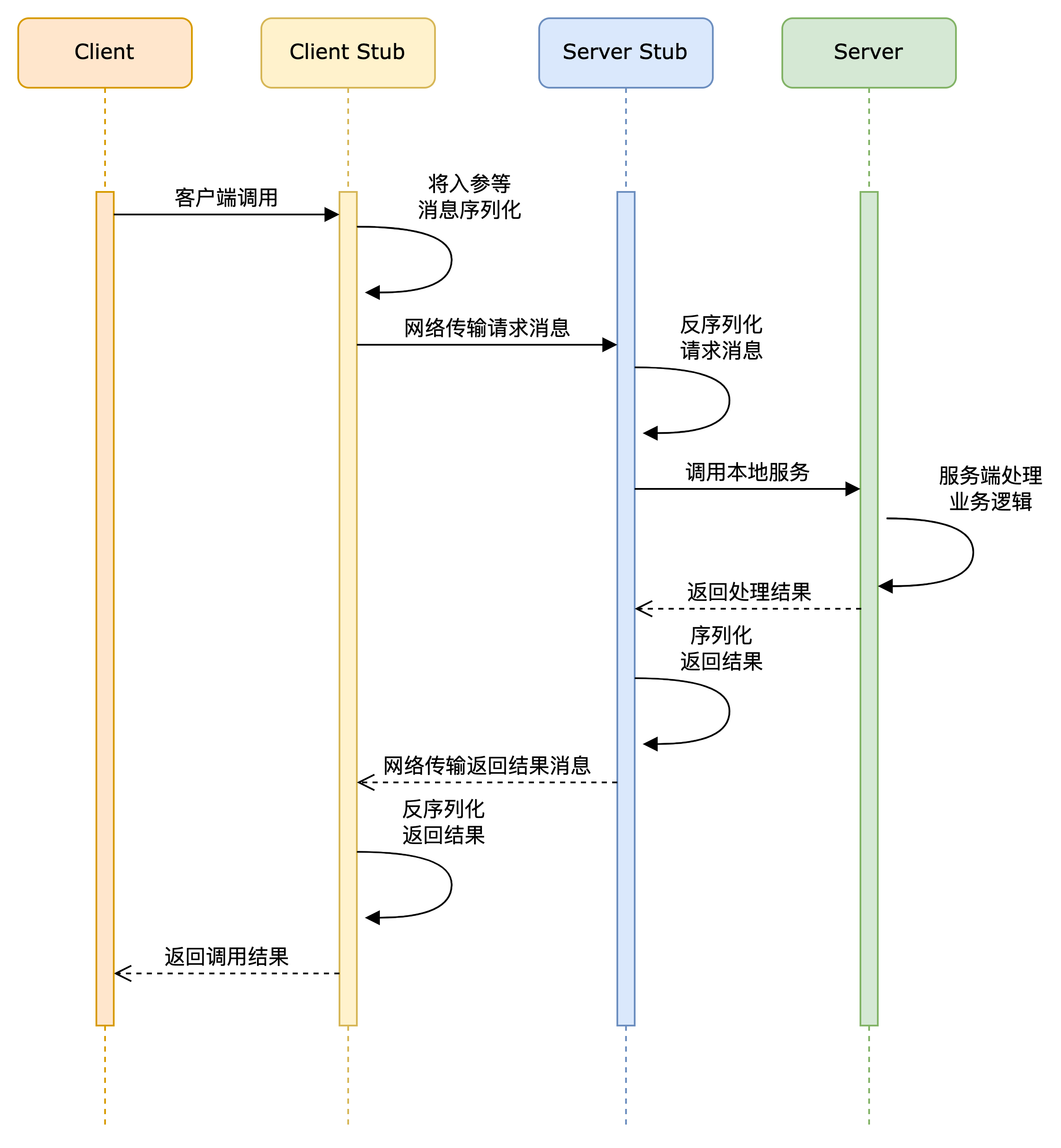
MapReduce
MapReduce知识点总览图

1.1 MapReduce 定义
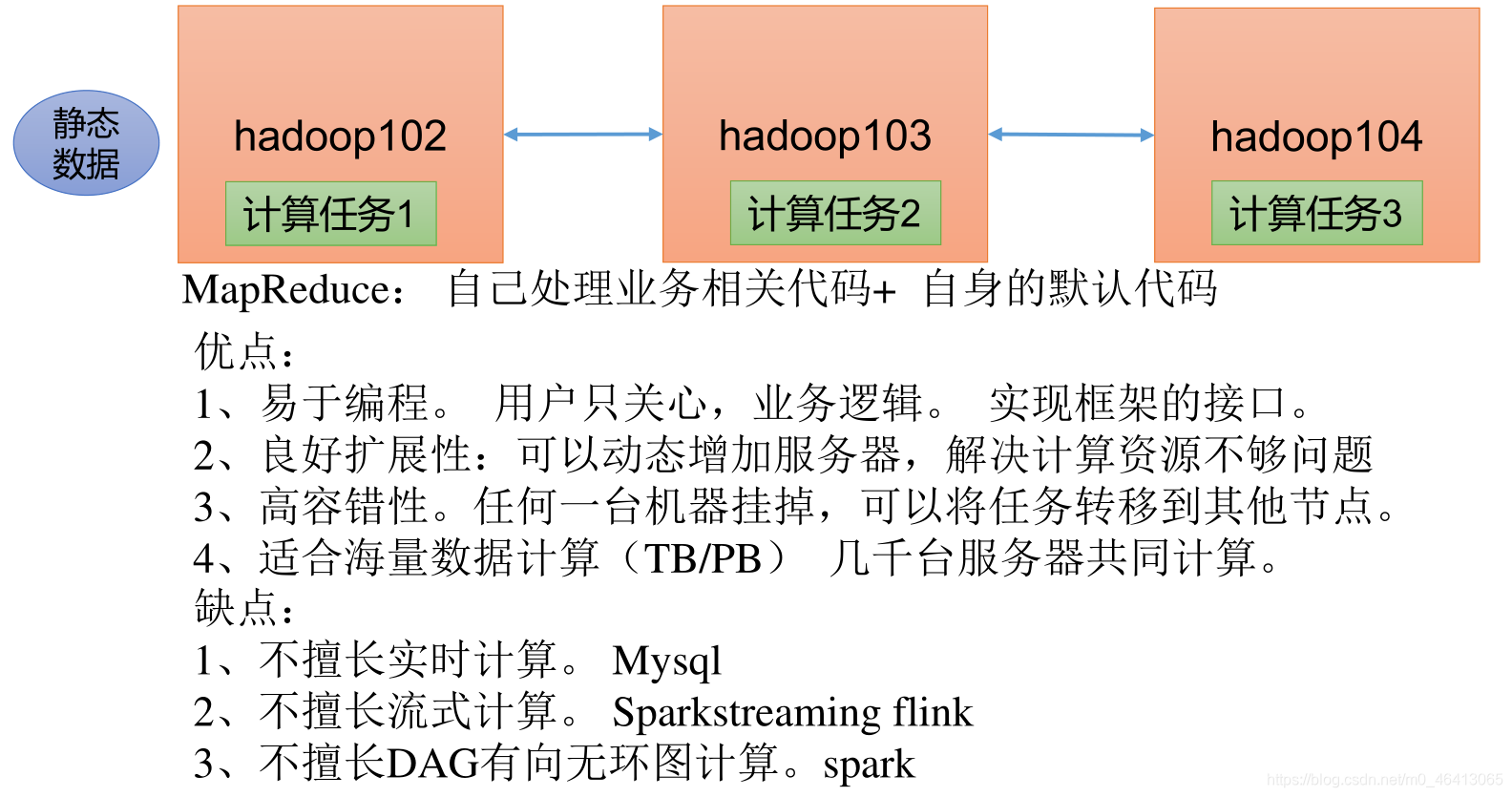
MapReduce 是一个分布式运算程序的编程框架,是用户开发“基于 Hadoop 的数据分析应用”的核心框架。
MapReduce 核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并发运行在一个 Hadoop 集群上。
1.2 MapReduce 优缺点
1.2.1 优点
1 )MapReduce 易于编程
它简单的实现一些接口, 就可以完成一个分布式程序, 这个分布式程序可以分布到大量廉价的 PC 机器上运行。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。就是因为这个特点使得 MapReduce 编程变得非常流行。
2 ) 良好的扩展性
当你的计算资源不能得到满足的时候, 你可以通过简单的增加机器来扩展它的计算能力。
3 ) 高容错性
MapReduce 设计的初衷就是使程序能够部署在廉价的 PC 机器上, 这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败, 而且这个过程不需要人工参与, 而完全是由Hadoop内部完成的。
4 ) 适合 PB 级以上海量数据的离线处理
可以实现上千台服务器集群并发工作,提供数据处理能力。
1.2.2 缺点
1 ) 不擅长实时计算
MapReduce 无法像 MySQL 一样,在毫秒或者秒级内返回结果。
2 ) 不擅长流式计算
流式计算的输入数据是动态的, 而 MapReduce 的输入数据集是静态的, 不能动态变化。
这是因为 MapReduce 自身的设计特点决定了数据源必须是静态的。
3 ) 不擅长 DAG (有向无环图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce 并不是不能做, 而是使用后, 每个 MapReduce 作业的输出结果都会写入到磁盘,会造成大量的磁盘 IO,导致性能非常的低下。
1.3 MapReduce 核心编程思想
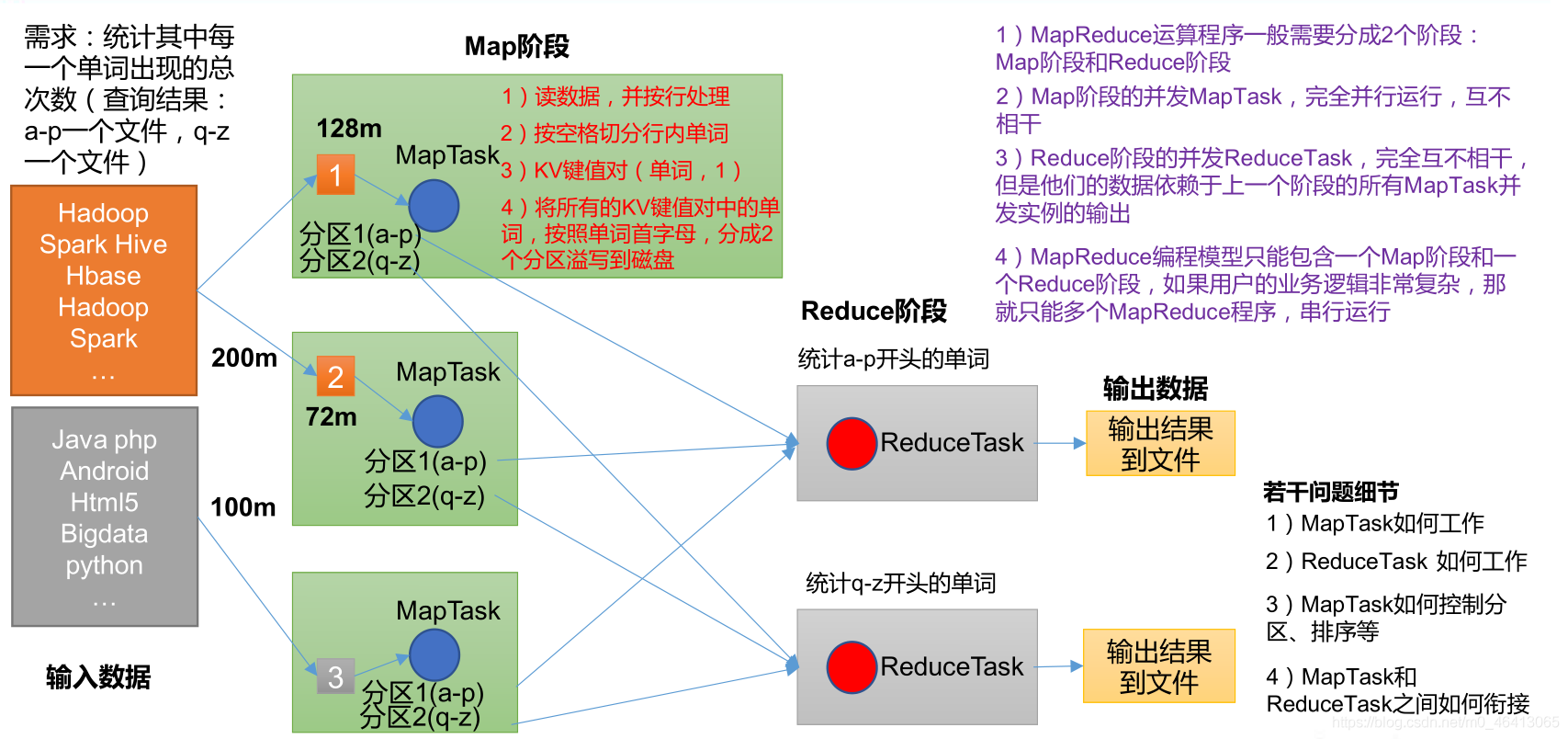
(1)分布式的运算程序往往需要分成至少 2 个阶段。
(2)第一个阶段的 MapTask 并发实例,完全并行运行,互不相干。
(3)第二个阶段的 ReduceTask 并发实例互不相干,但是他们的数据依赖于上一个阶段的所有 MapTask 并发实例的输出。
(4)MapReduce 编程模型只能包含一个 Map 阶段和一个 Reduce 阶段,如果用户的业务逻辑非常复杂,那就只能多个 MapReduce 程序,串行运行。
总结:分析 WordCount 数据流走向深入理解 MapReduce 核心思想。
1.4 MapReduce 进程
一个完整的 MapReduce 程序在分布式运行时有三类实例进程:
(1)MrAppMaster:负责整个程序的过程调度及状态协调。
(2)MapTask:负责 Map 阶段的整个数据处理流程。
(3)ReduceTask:负责 Reduce 阶段的整个数据处理流程。
1.5官方 WordCount 源码
采用反编译工具反编译源码,发现 WordCount 案例有 Map 类、Reduce 类和驱动类。且数据的类型是 Hadoop 自身封装的序列化类型。
先下载官方源码:
下载下来是一个jar包:
如何查看里面的代码程序呢?
可以从网上下载一个反编译工具:
点击jd-gui.exe运行,显示如下界面:
将桌面上的源码jar包拖拽过来:
打开其中官方WordCount程序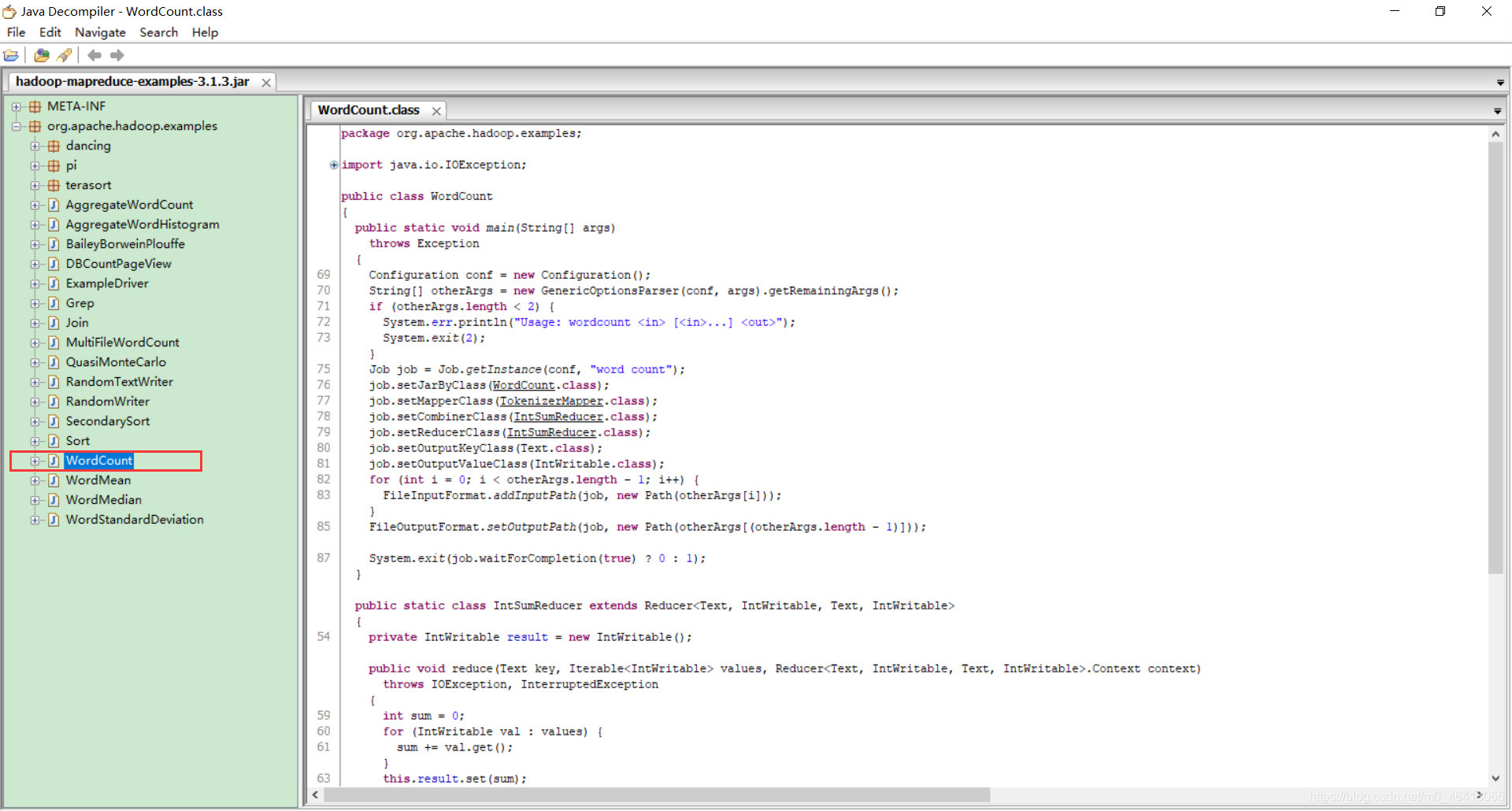
详细剖析其中代码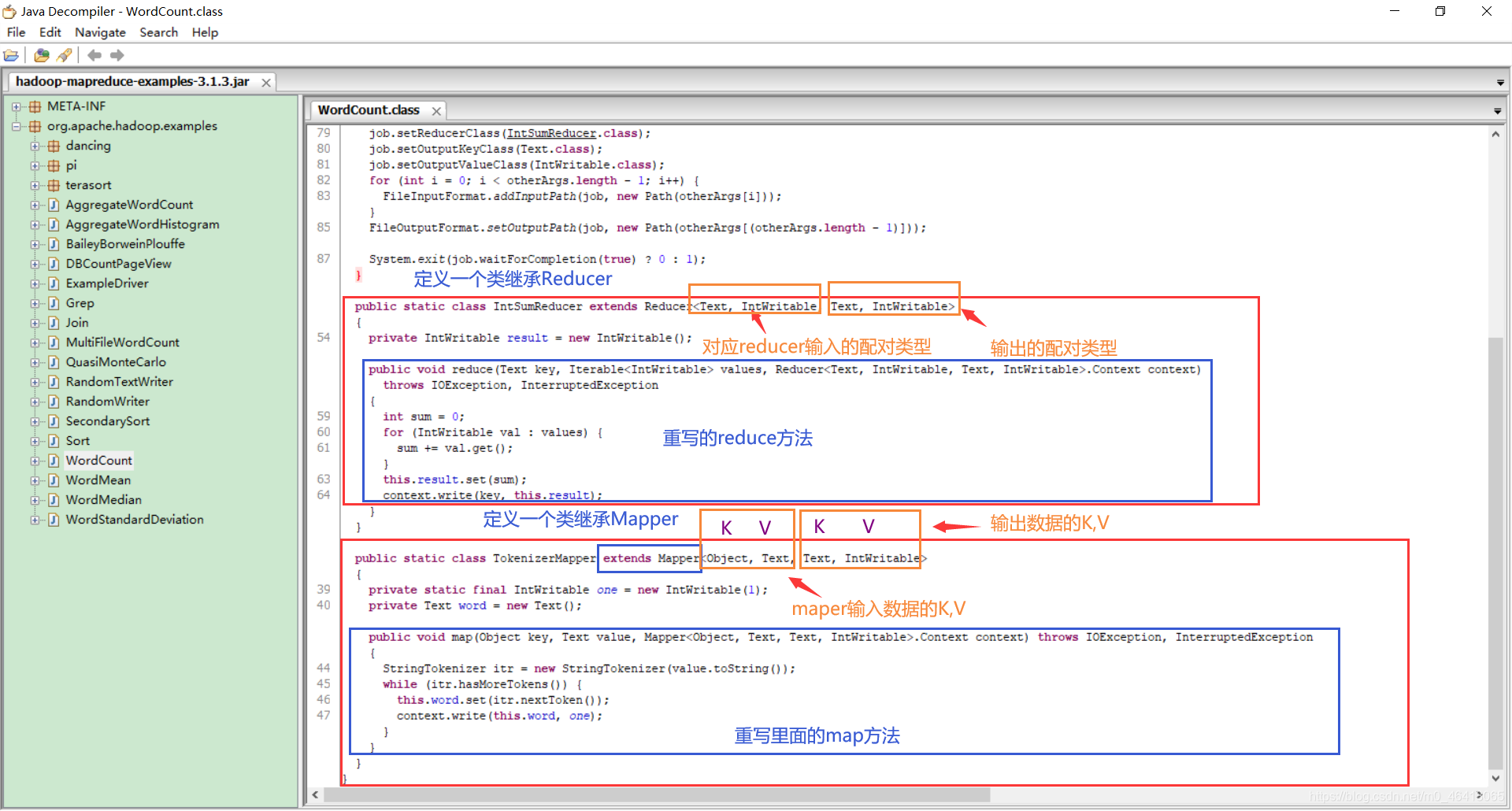
1.6 常用数据 序列化类型

1.7 MapReduce 编程规范
用户编写的程序分成三个部分:Mapper、Reducer 和 Driver。
1.Mapper阶段
(1)用户自定义的Mapper要继承自己的父类
(2)Mapper的输入数据是KV对的形式(KV的类型可自定义)
p.s. K是这一行的偏移量,V是这一行的内容。
(3)Mapper中的业务逻辑写在map()方法中

(4)Mapper的输出数据是KV对的形式(KV的类型可自定义)
(5)map()方法(MapTask进程)对每一个<K,V>调用一次
2.Reducer阶段
(1)用户自定义的Reducer要继承自己的父类
(2)Reducer的输入数据类型对应Mapper的输出数据类型,也是KV
(3)Reducer的业务逻辑写在reduce()方法中
(4)ReduceTask进程对每一组相同k的<k,v>组调用一次reduce()方法
3.Driver阶段
相当于YARN集群的客户端,用于提交我们整个程序到YARN集群,提交的是封装了MapReduce程序相关运行参数的job对象
1.8 WordCount 案例实操
1.8.1 本地测试
1 ) 需求
在给定的文本文件中统计输出每一个单词出现的总次数
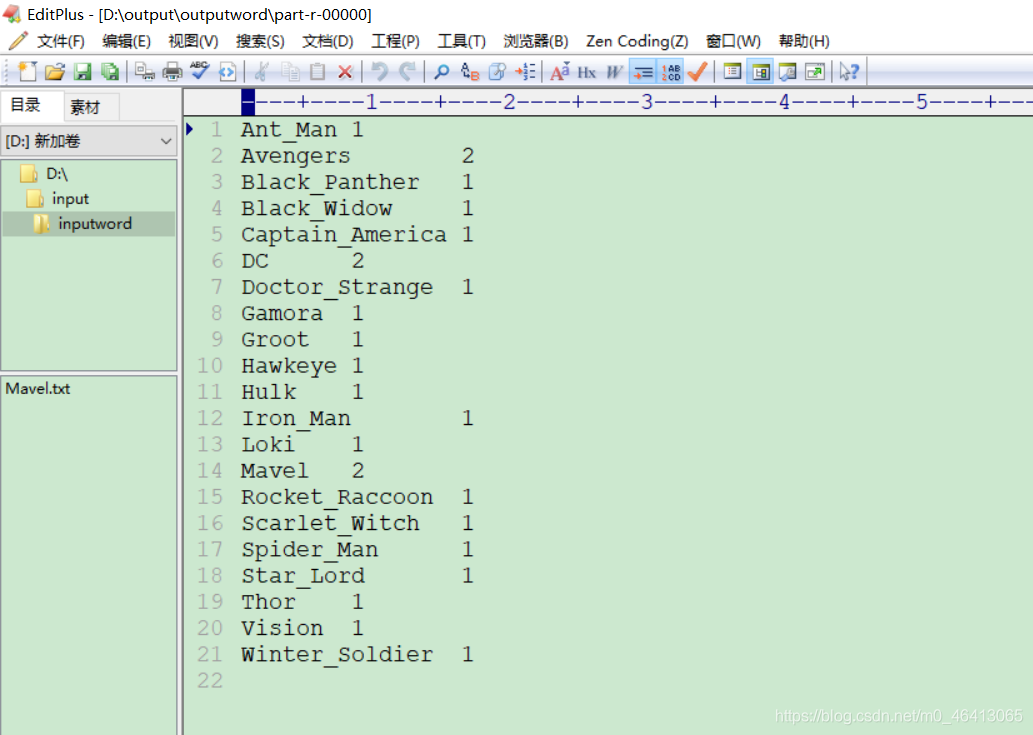
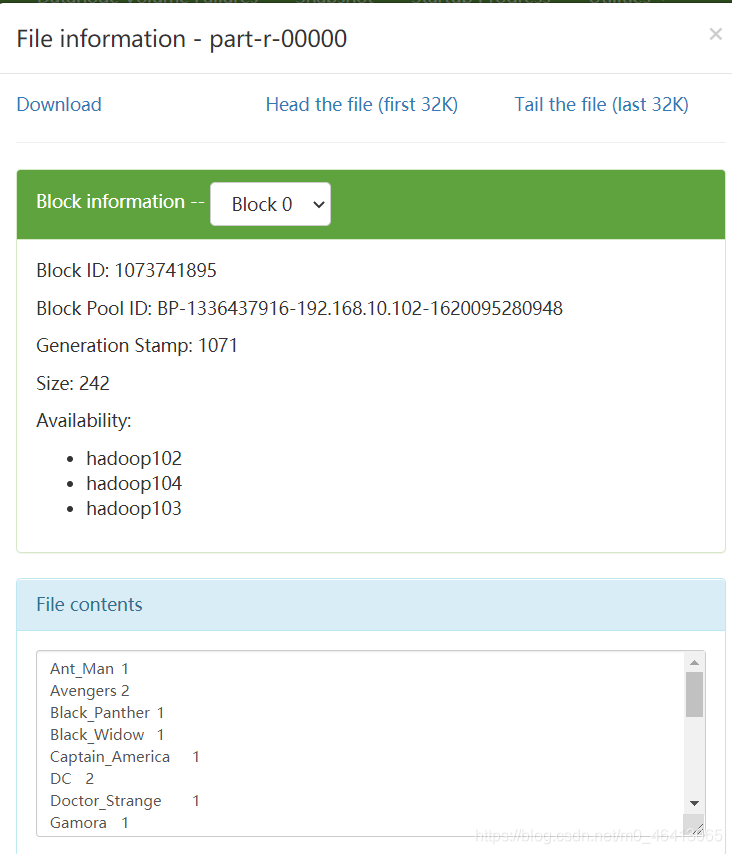
(1)输入数据
创建一个文件夹

里面写上想要测试的数据
Avengers Avengers
DC DC
Mavel Mavel
Iron_Man
Captain_America
Thor
Hulk
Black_Widow
Hawkeye
Black_Panther
Spider_Man
Doctor_Strange
Ant_Man
Vision
Scarlet_Witch
Winter_Soldier
Loki
Star_Lord
Gamora
Rocket_Raccoon
Groot
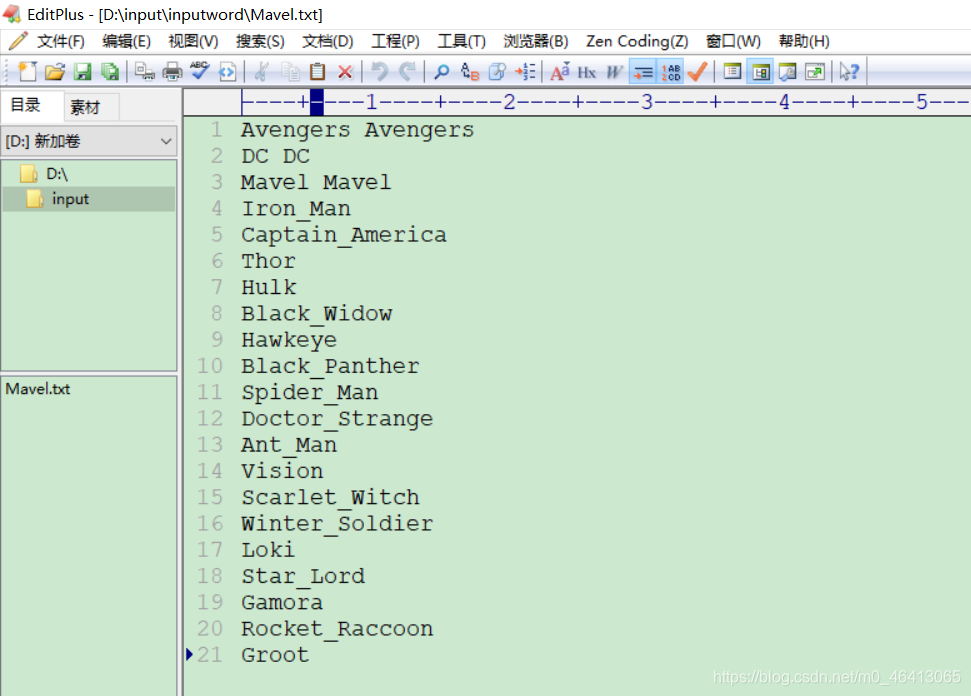
(2)期望输出数据(自己会排序根据字典顺序)
(涉及到输入的排序问题)
Ant_Man 1
Avengers 2
Black_Panther 1
Black_Widow 1
Captain_America 1
DC 2
Doctor_Strange 1
Gamora 1
Groot 1
Hawkeye 1
Hulk 1
Iron_Man 1
Loki 1
Mavel 2
Rocket_Raccoon 1
Scarlet_Witch 1
Spider_Man 1
Star_Lord 1
Thor 1
Vision 1
Winter_Soldier 1
2 ) 需求分析
按照 MapReduce 编程规范,分别编写 Mapper,Reducer,Driver。

3 ) 环境准备
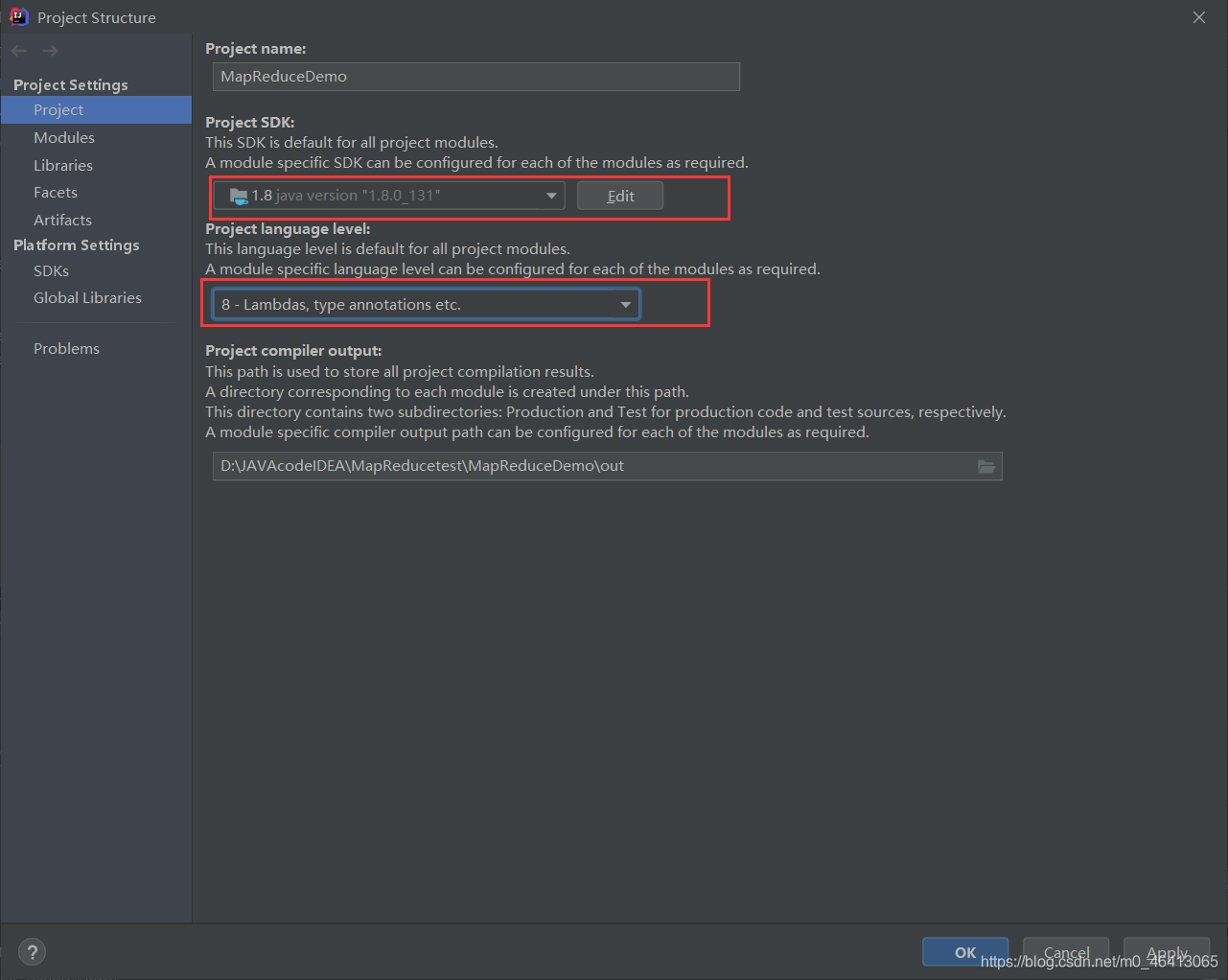
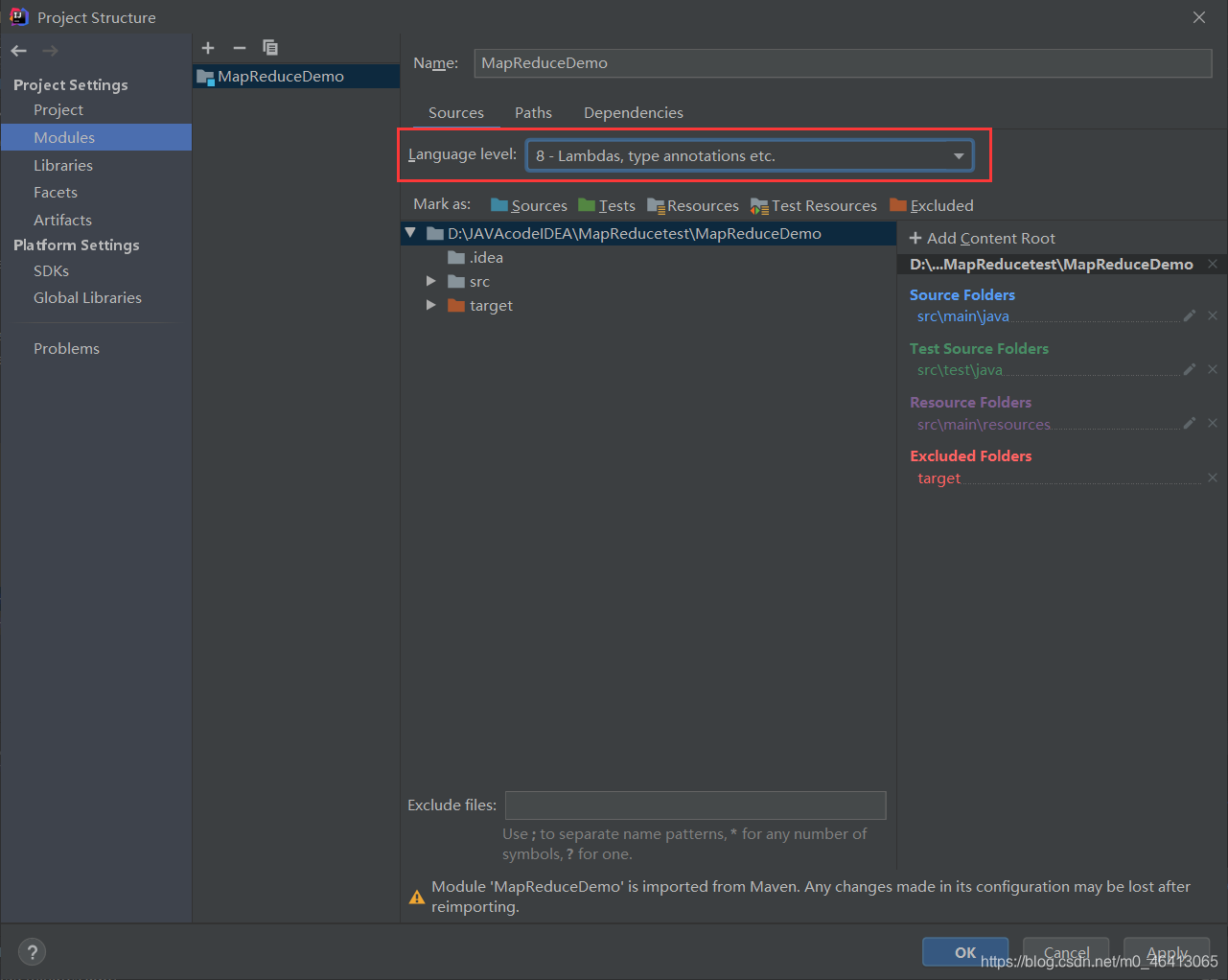
(1)创建 maven 工程,MapReduceDemo
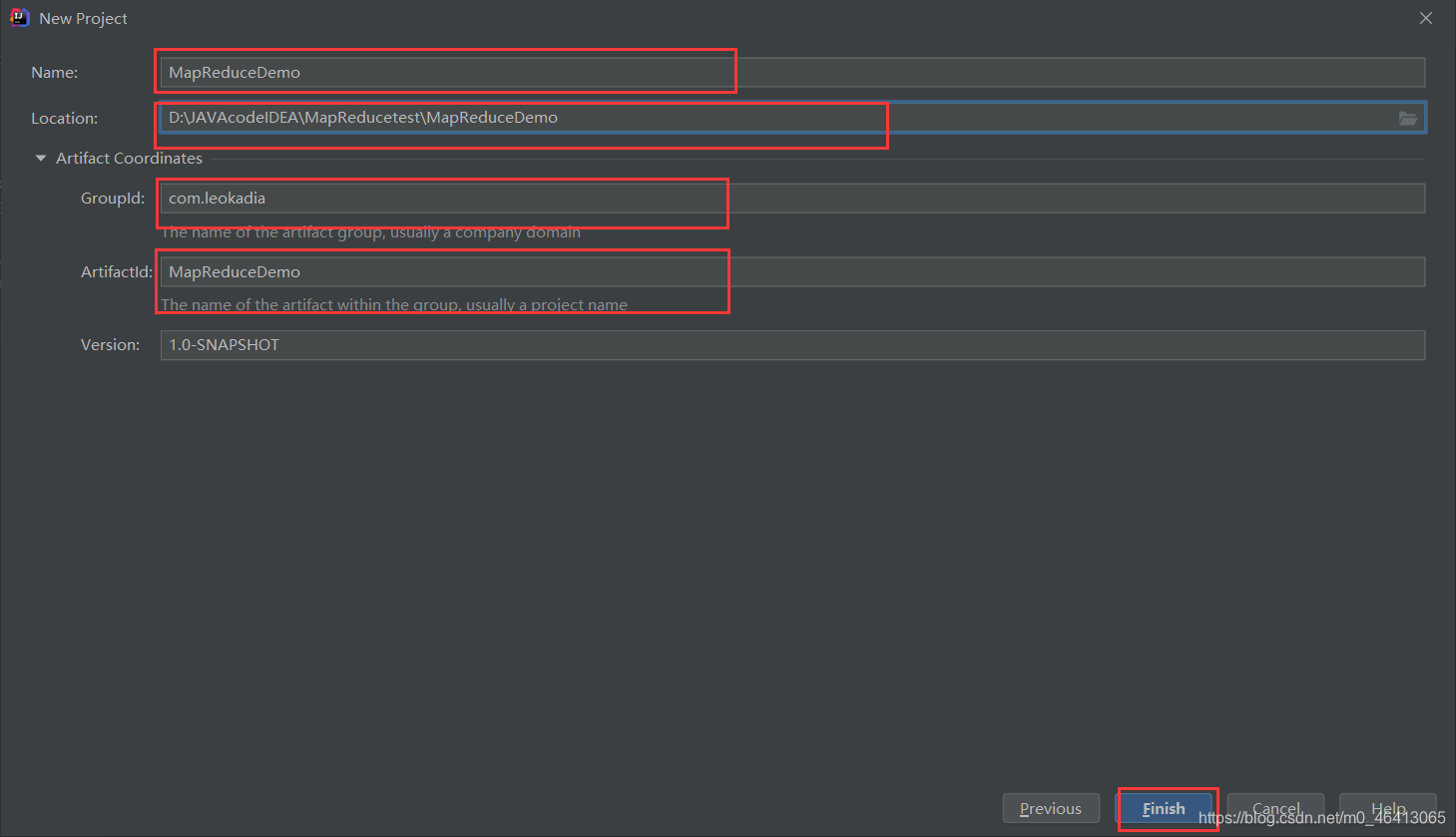
按照之前的修改成自己的Maven仓库,相关内容可参考:
HDFS的API环境准备小知识——Maven 安装与配置
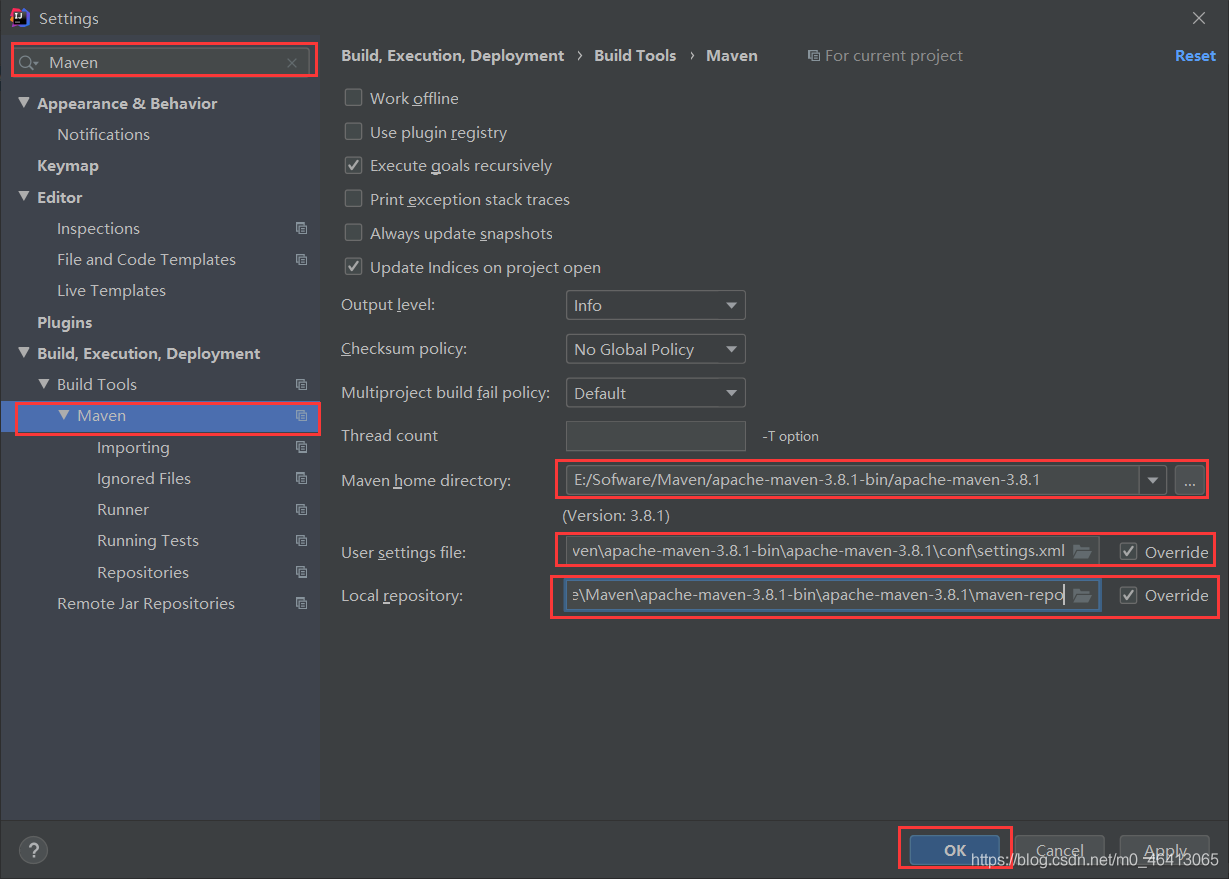
然后将相关java编译器配成自己的版本
相关内容参考
【Maven报错】Error:java: 不再支持源选项 5。请使用 6 或更高版本。(JDK14版成功解决)
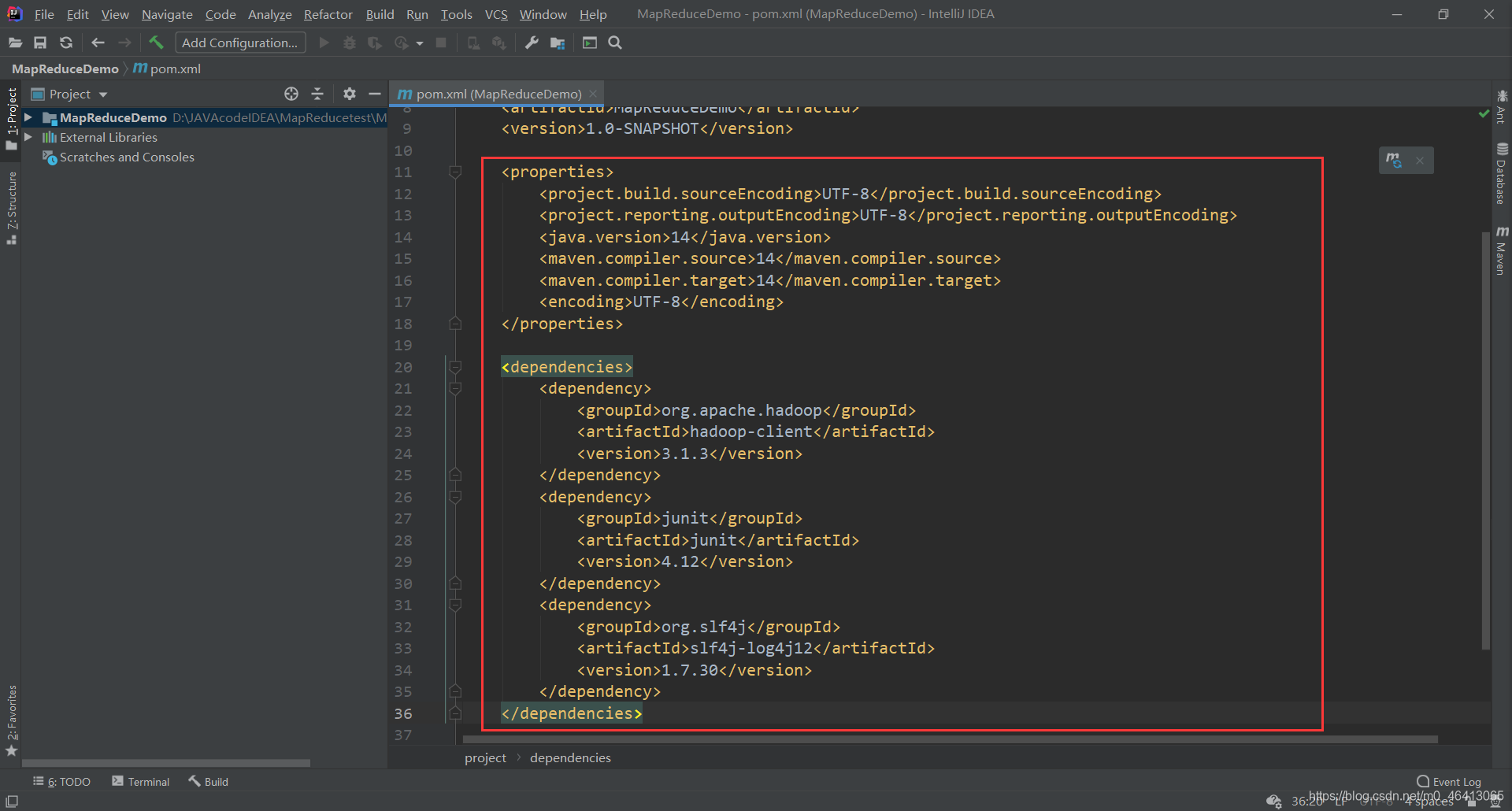
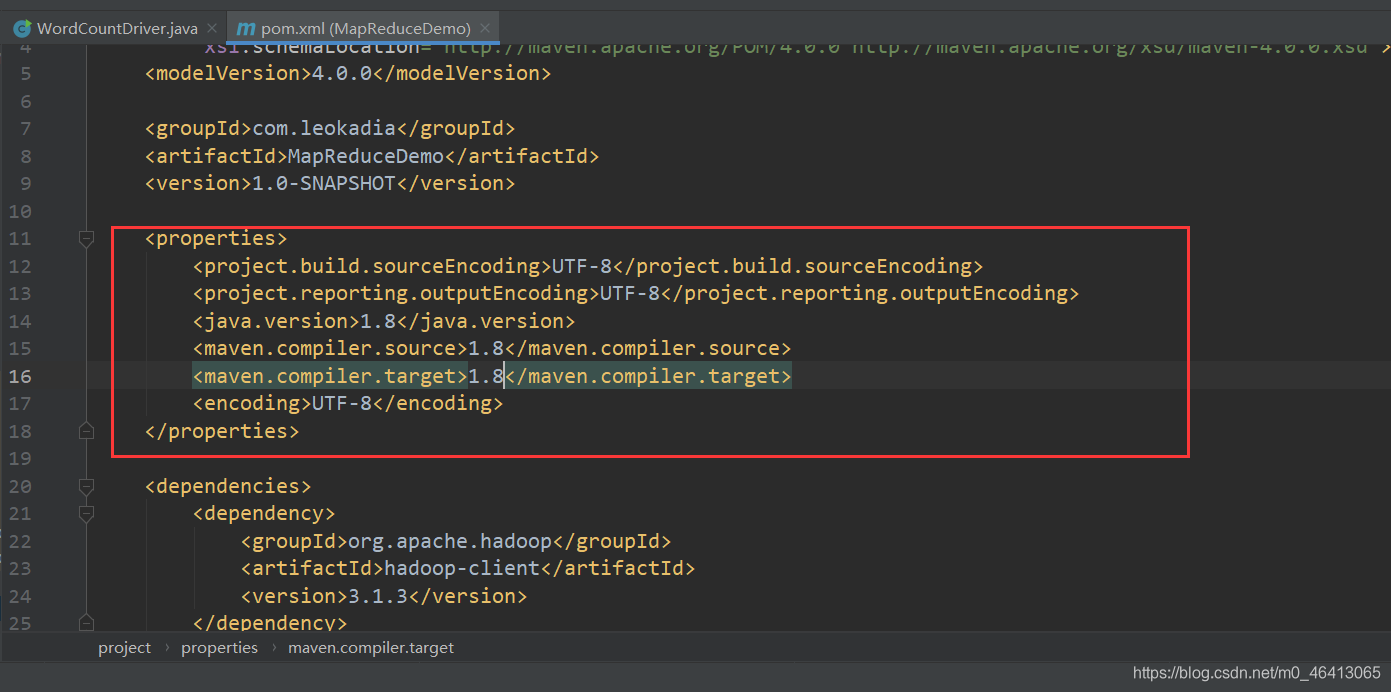
(2)在 pom.xml 文件中添加版本信息以及相关依赖
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<encoding>UTF-8</encoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.1.3</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.12</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.30</version>
</dependency>
</dependencies>
(2)在项目的 src/main/resources 目录下,新建一个文件,命名为“log4j.properties”(打印相关日志)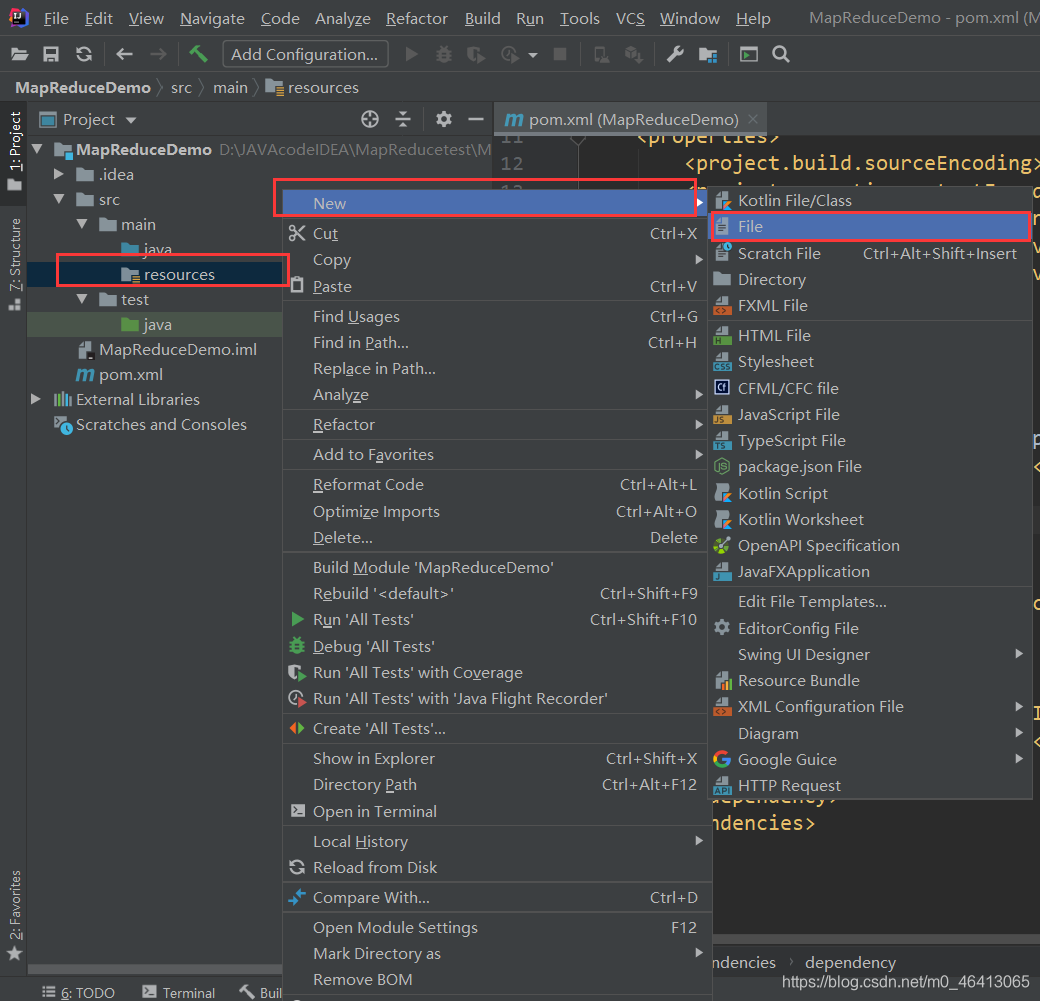

在文件中填入:
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
3)创建包名:com.leokadia.mapreduce.wordcount
创建三个类
4 ) 编写程序
(1)编写 Mapper 类
package com.leokadia.mapreduce.wordcount;
/**
* @author sa
* @create 2021-05-05 10:46
*/
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* KEYIN, map阶段输入的key的类型:LongWritable
* VALUEIN,map阶段输入value类型:Text
* KEYOUT,map阶段输出的Key类型:Text
* VALUEOUT,map阶段输出的value类型:IntWritable
*/
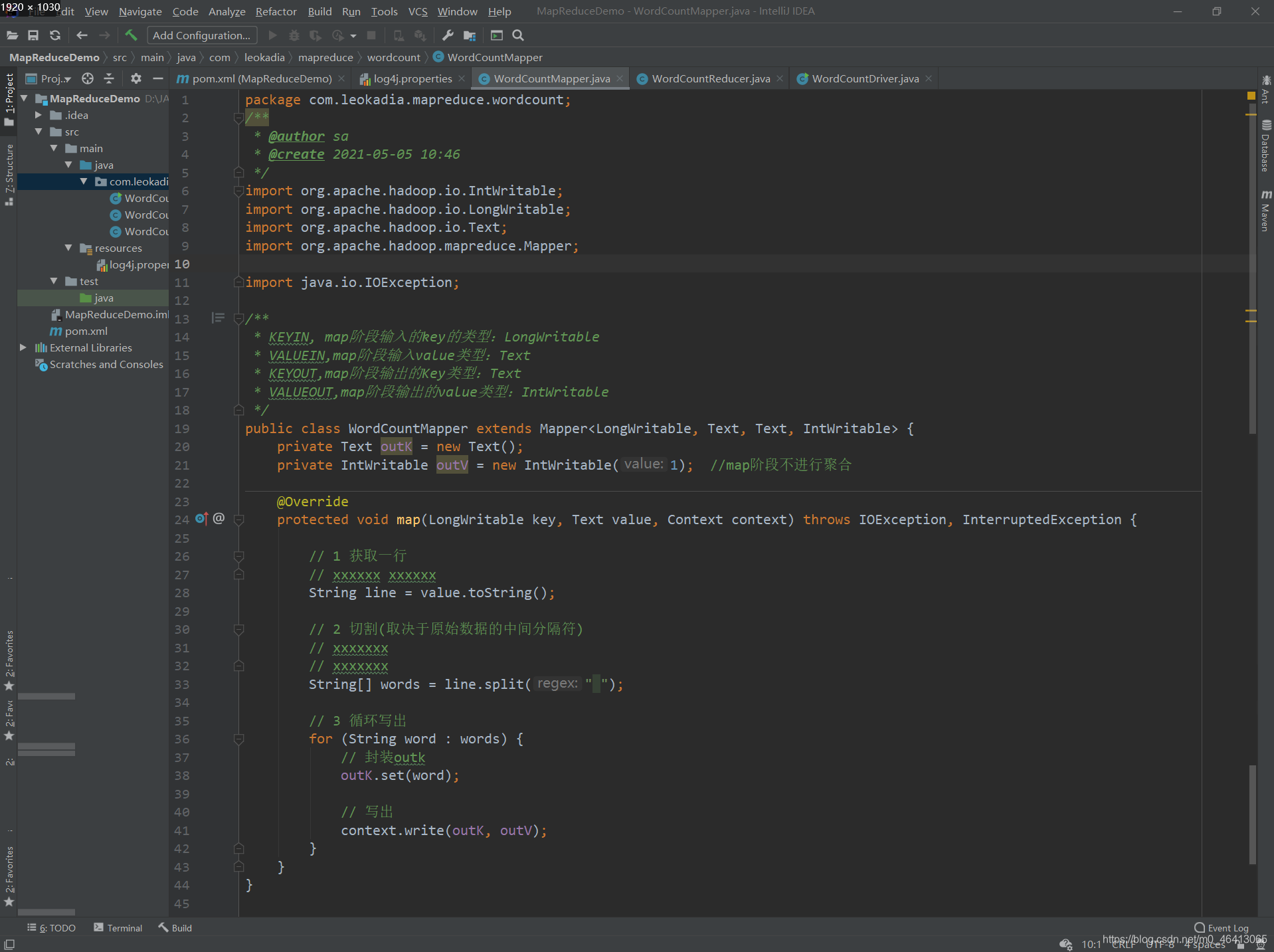
public class WordCountMapper extends Mapper<LongWritable, Text, Text, IntWritable> {
private Text outK = new Text();
private IntWritable outV = new IntWritable(1); //map阶段不进行聚合
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
// 1 获取一行
// xxxxxx xxxxxx
String line = value.toString();
// 2 切割(取决于原始数据的中间分隔符)
// xxxxxxx
// xxxxxxx
String[] words = line.split(" ");
// 3 循环写出
for (String word : words) {
// 封装outk
outK.set(word);
// 写出
context.write(outK, outV);
}
}
}
2)编写 Reducer 类
package com.leokadia.mapreduce.wordcount;
/**
* @author sa
* @create 2021-05-05 10:47
*/
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* KEYIN, reduce阶段输入的key的类型:Text
* VALUEIN,reduce阶段输入value类型:IntWritable
* KEYOUT,reduce阶段输出的Key类型:Text
* VALUEOUT,reduce阶段输出的value类型:IntWritable
*/
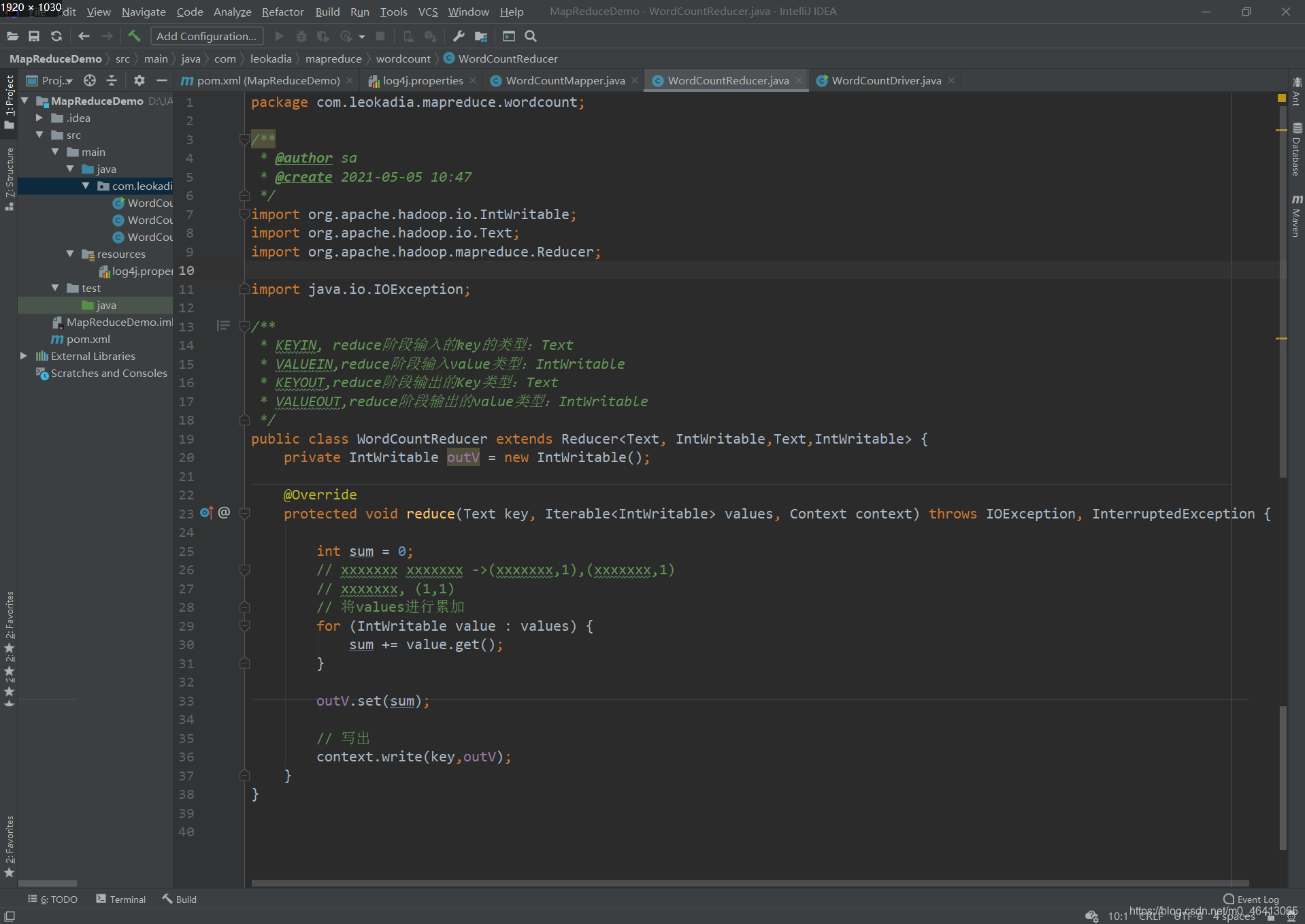
public class WordCountReducer extends Reducer<Text, IntWritable,Text,IntWritable> {
private IntWritable outV = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
// xxxxxxx xxxxxxx ->(xxxxxxx,1),(xxxxxxx,1)
// xxxxxxx, (1,1)
// 将values进行累加
for (IntWritable value : values) {
sum += value.get();
}
outV.set(sum);
// 写出
context.write(key,outV);
}
}
3)编写 Driver 驱动类
package com.leokadia.mapreduce.wordcount;
/**
* @author sa
* @create 2021-05-05 10:47
*/
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
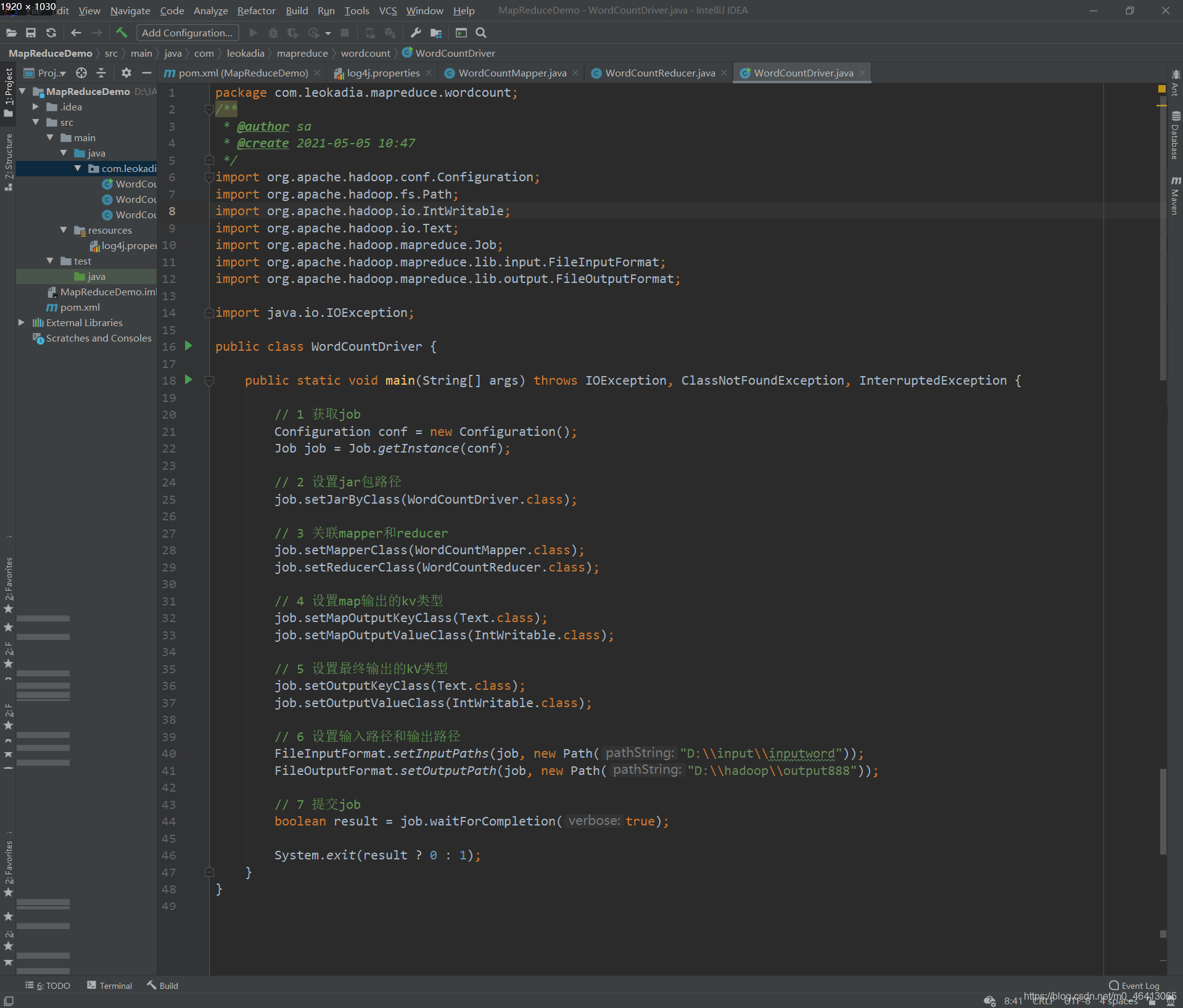
public class WordCountDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
// 1 获取job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf);
// 2 设置jar包路径
job.setJarByClass(WordCountDriver.class);
// 3 关联mapper和reducer
job.setMapperClass(WordCountMapper.class);
job.setReducerClass(WordCountReducer.class);
// 4 设置map输出的kv类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
// 5 设置最终输出的kV类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
// 6 设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\input\\inputword"));
FileOutputFormat.setOutputPath(job, new Path("D:\\hadoop\\output888"));
// 7 提交job
boolean result = job.waitForCompletion(true);
System.exit(result ? 0 : 1);
}
}
5 ) 本地测试
(1)需要首先配置好 HADOOP_HOME 变量以及 Windows 运行依赖
(2)在 IDEA 上运行程序
运行:
注意:此时如果再运行一遍,会报错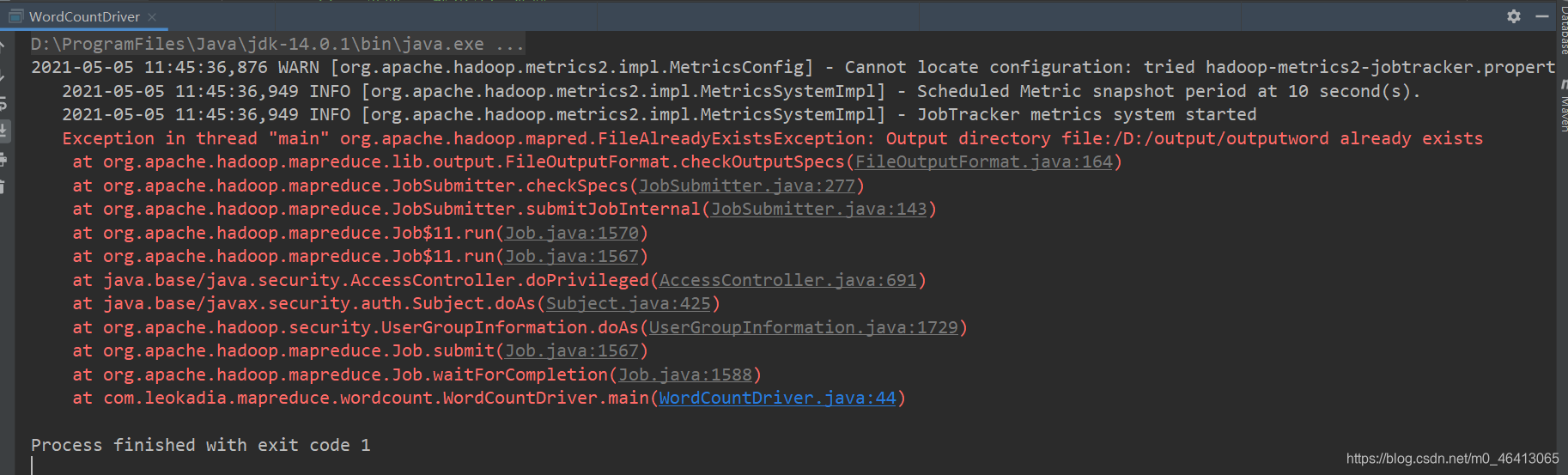
在mapreduce中,如果输出路径存在会报错
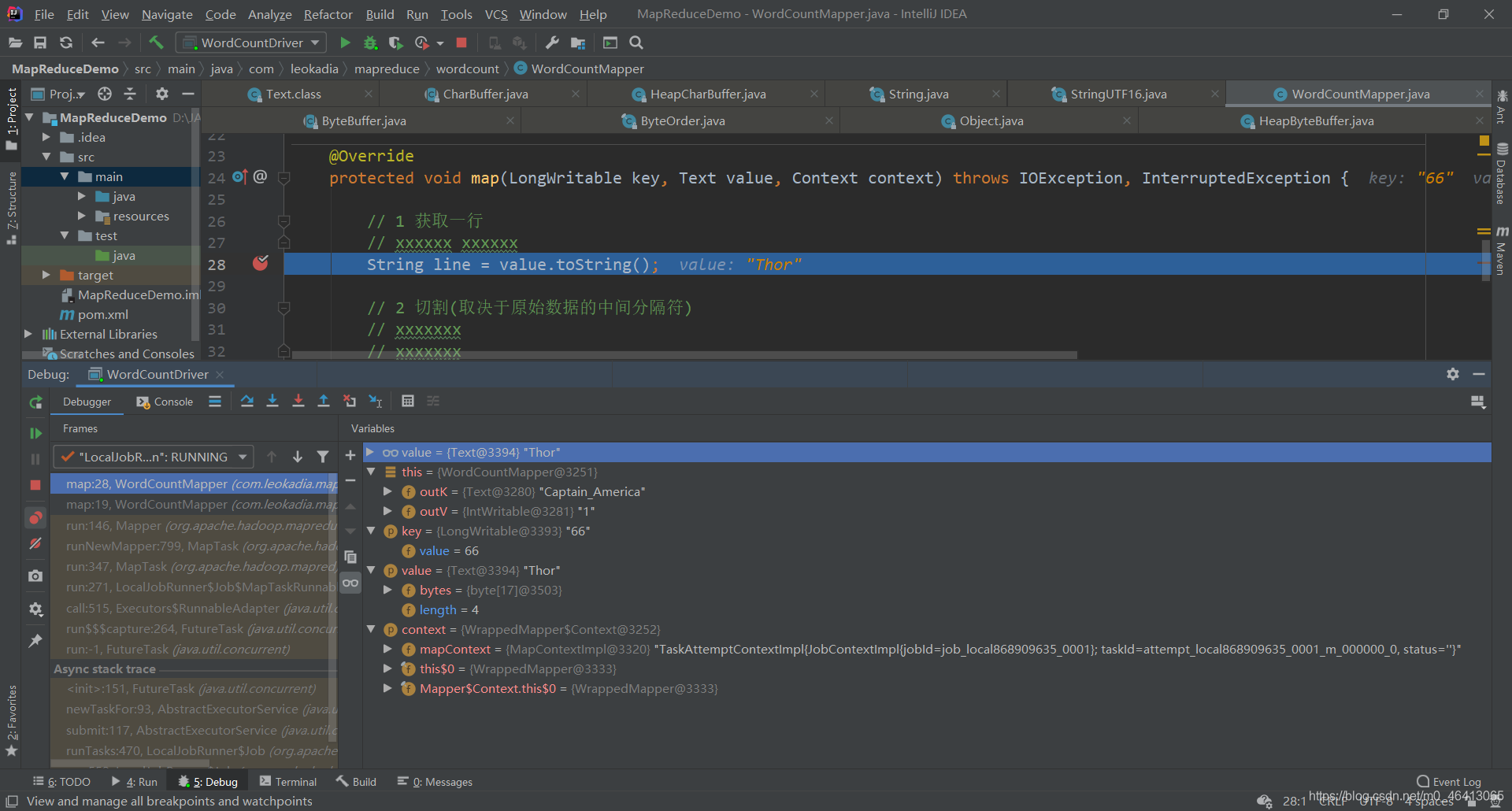
1.8.2 WordCount案例Debug调试
在以下几个地方打好断点
开始Debug
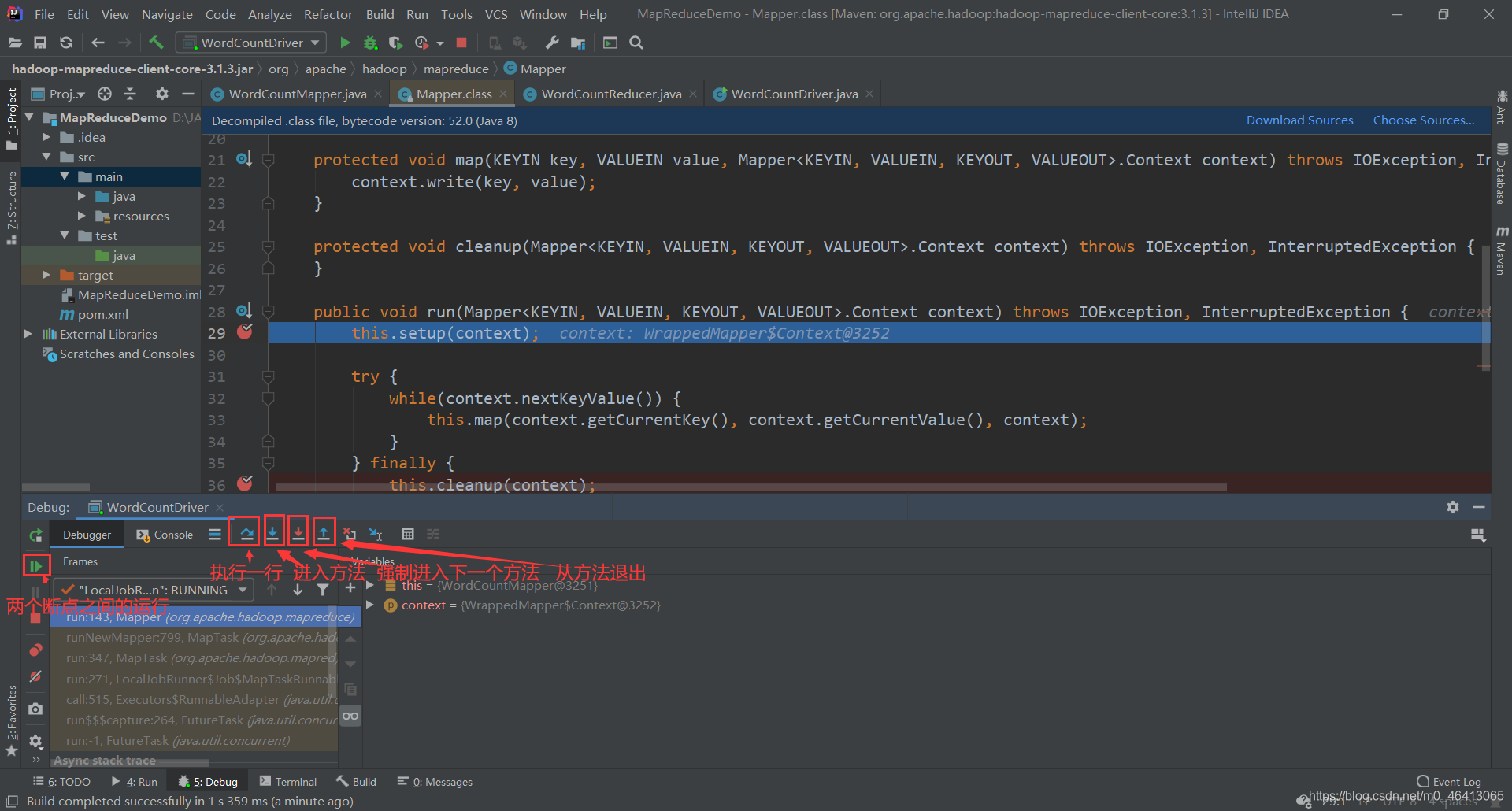
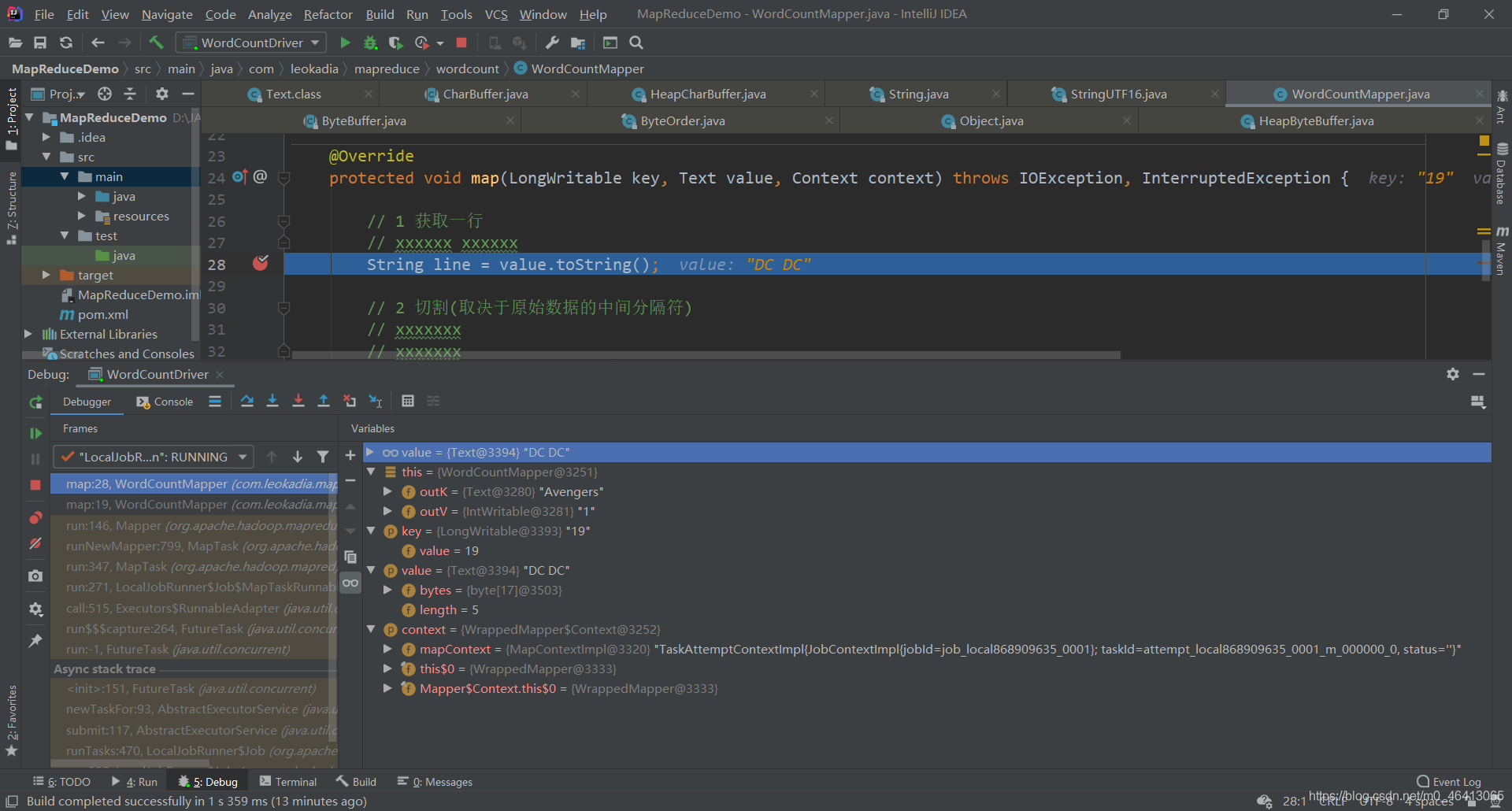
通过调试可以更清楚的理解机制
1.8.3 提交到集群测试
刚刚上面的代码是在本地运行的,是通过下载了hadoop相关的依赖,运用本地模式运行的
这样肯定是不行的,因为未来生产环境中,我们肯定是要在linux虚拟机上去运行
集群上测试
(1)用 maven 打 jar 包,需要添加的打包插件依赖
将下面的代码放在之前配置的依赖后面
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.6.1</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
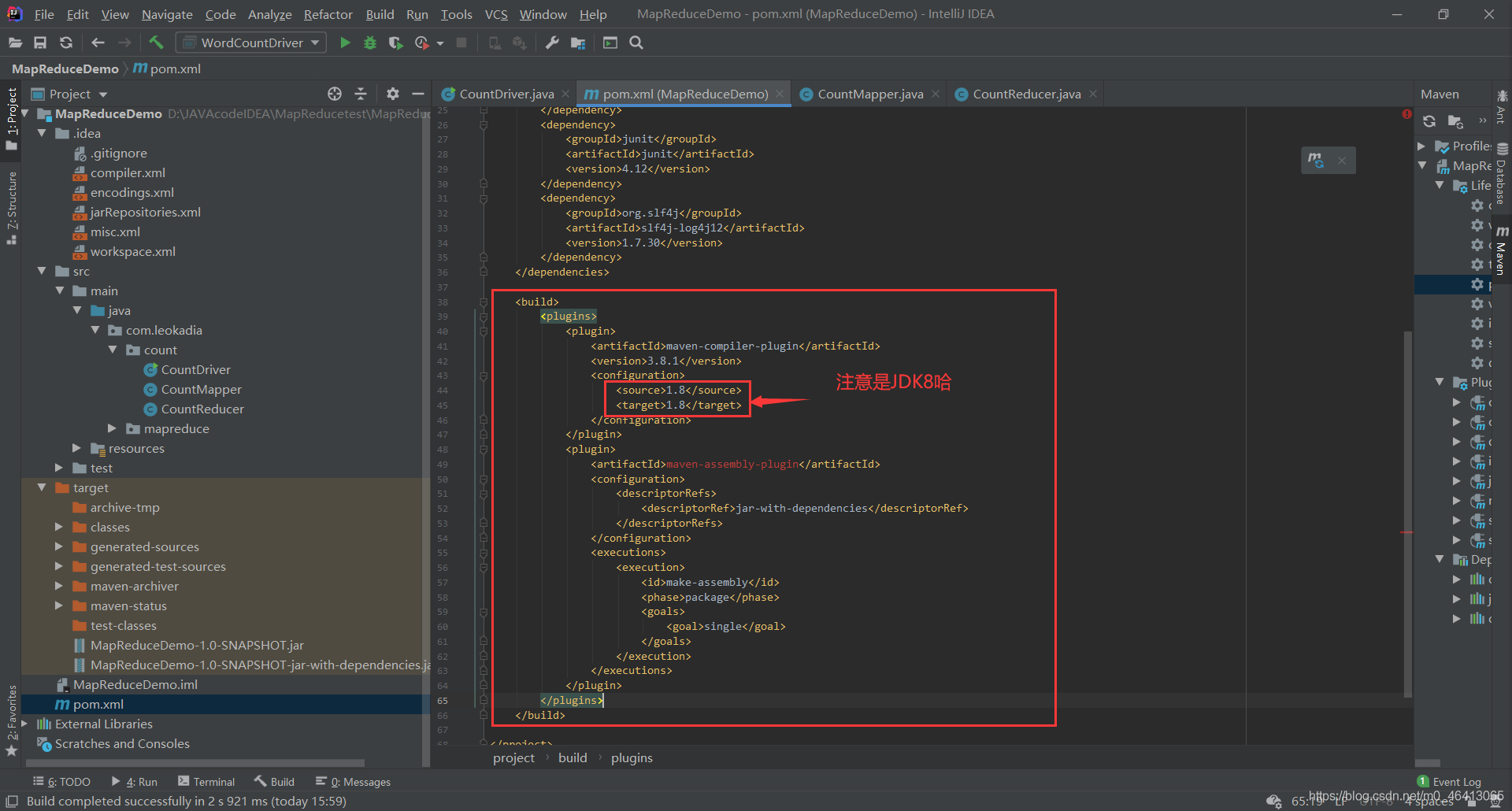
注意:博主原来的配置是14后面你们会发现14其实hadoop不支持,所以应该配置为JDK8,我将放的代码都改成了8的配置哈。
注意:如果工程上显示红叉。在项目上右键->maven->Reimport 刷新即可。
(2)将程序打成 jar 包
打包完毕,生成jar包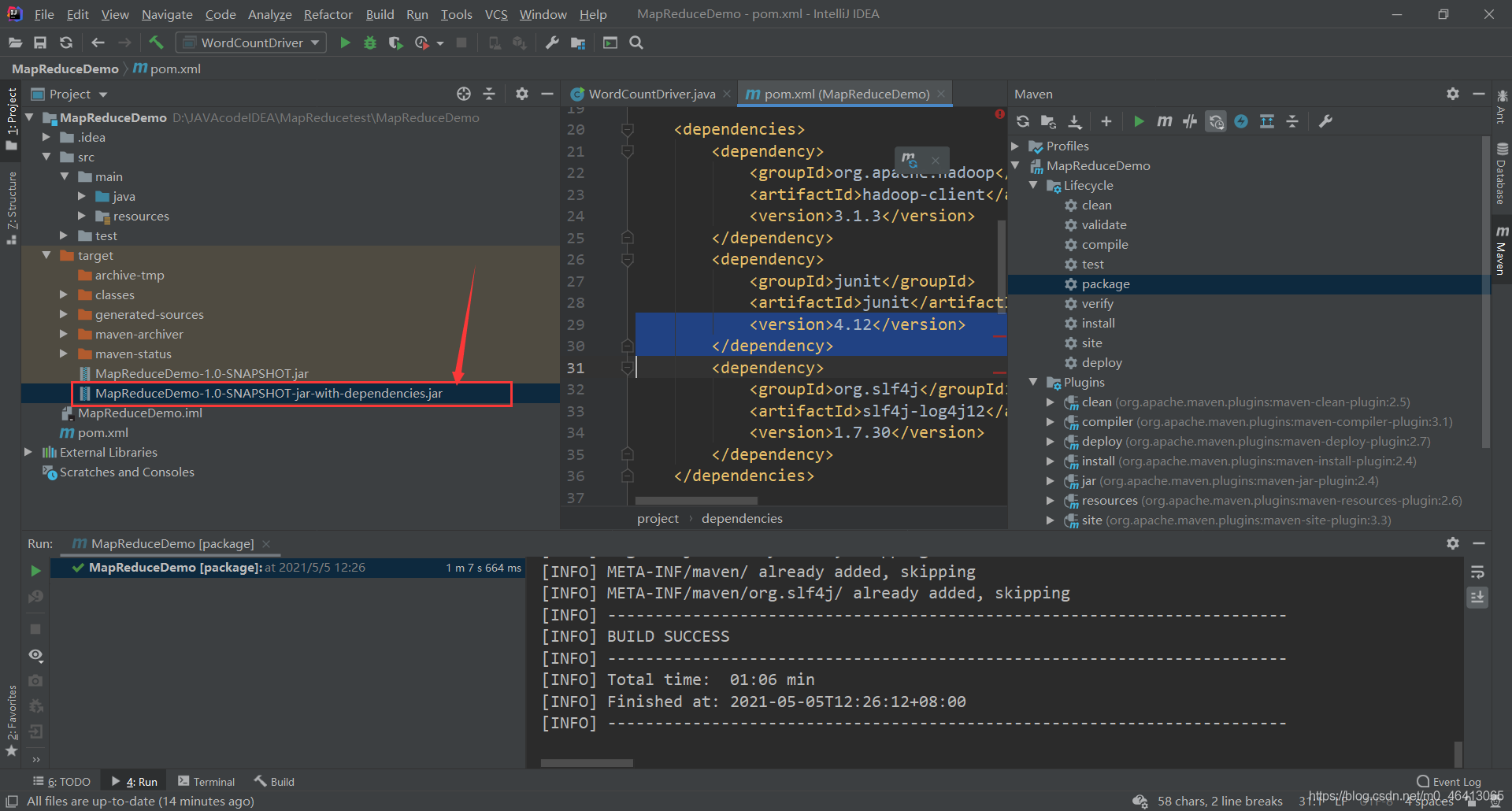
去文件夹里查看一下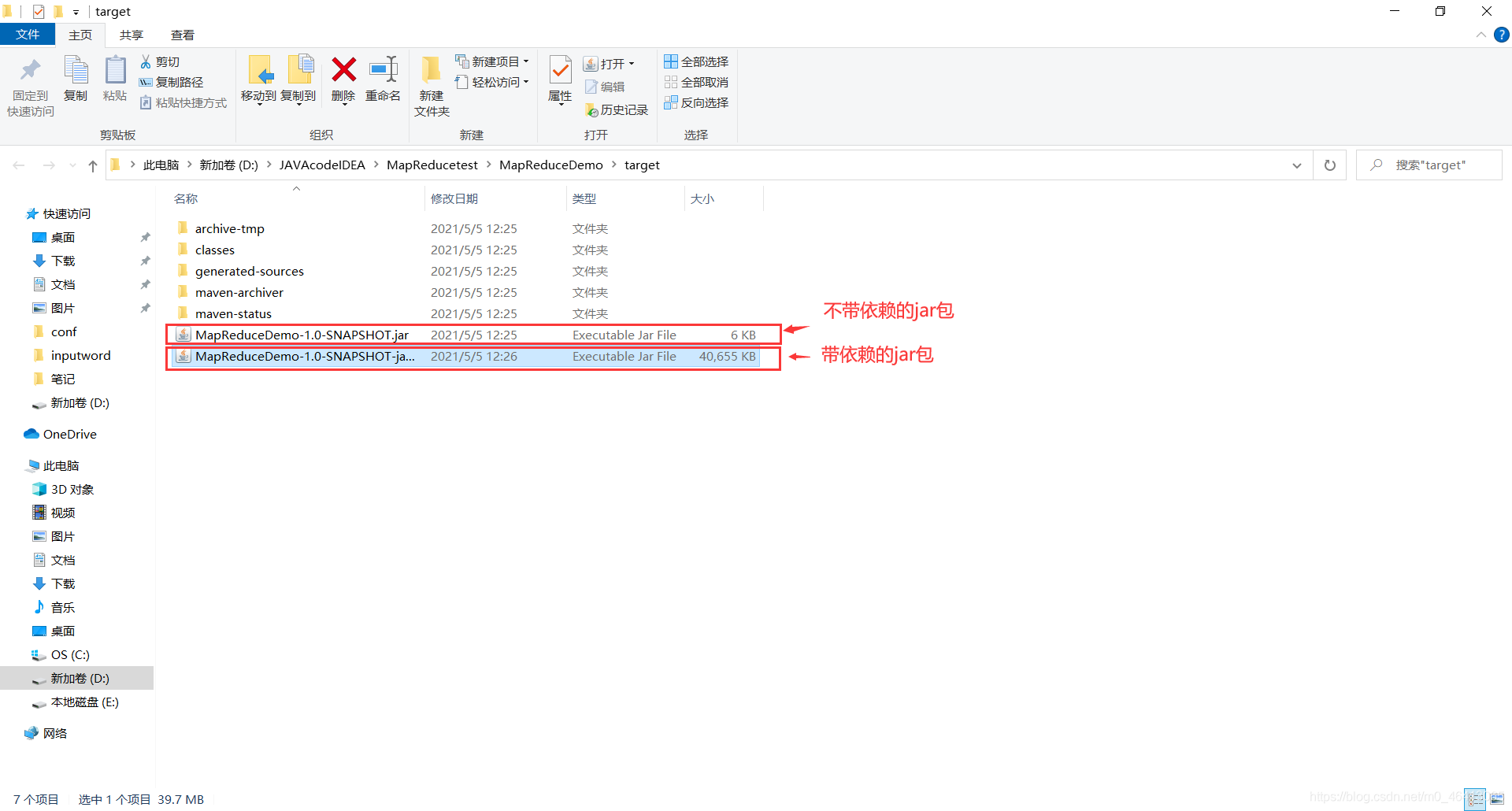
由于我们集群里面配置了相关依赖的内容,用上面的即可
3)修改不带依赖的 jar 包名称为 wc.jar,并拷贝该 jar 包到 Hadoop 集群的/opt/module/hadoop-3.1.3 路径
将上面6kb的复制到桌面并改名
思考:
刚刚的程序中,我们写的路径是本地windows的路径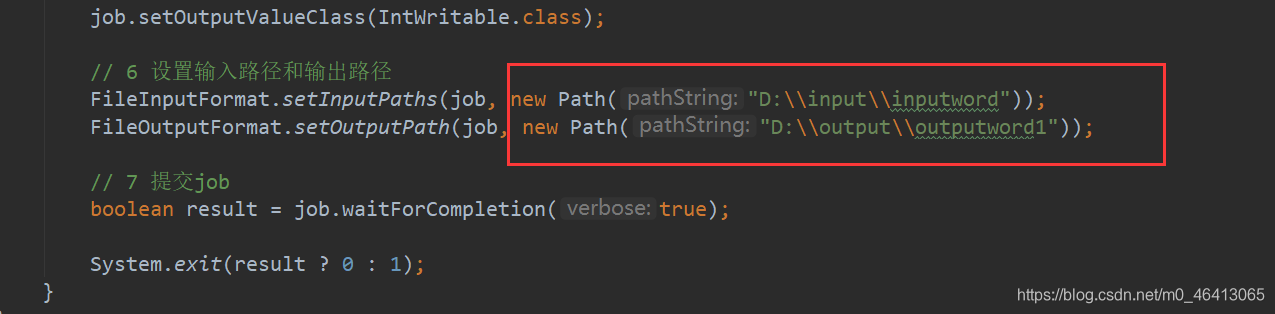
上传到linux环境后它其实没有这个路径,输入输出路径不存在,于是我们需要对它进行修改,改成对应的集群路径
如果想更灵活一点——根据传入的路径来确定输入的路径
回顾之前的
我们再创建一个wordcount2包,跟wordcount内容一致,就将输入输出路径修改了一下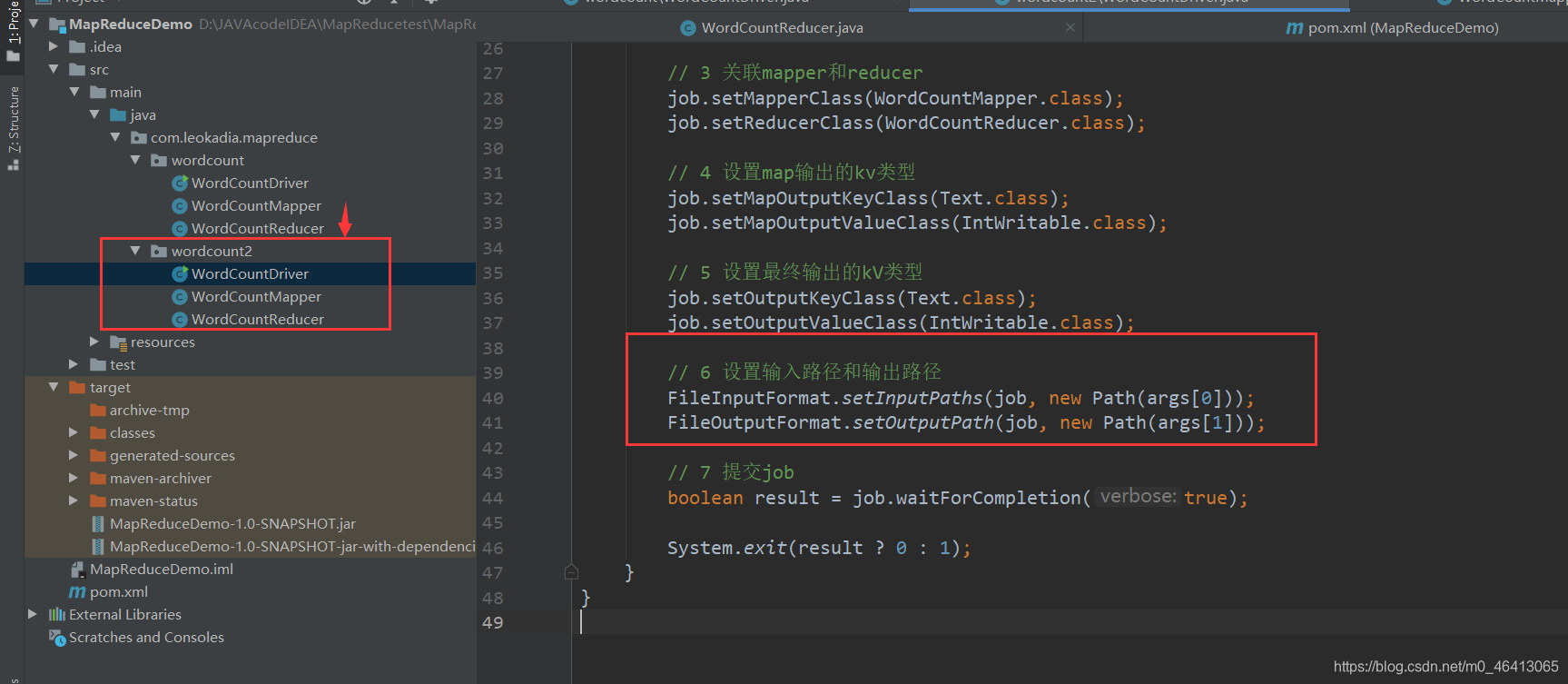
将
// 6 设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path("D:\\input\\inputword"));
FileOutputFormat.setOutputPath(job, new Path("D:\\hadoop\\output888"));
改为
e// 6 设置输入路径和输出路径
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileOutputFormat.setOutputPath(job, new Path(args[1]));
这样的修改将使你的 MapReduce 作业的输入路径和输出路径从固定的本地路径(“D:\input\inputword” 和 “D:\hadoop\output888”)改为通过命令行参数动态传递。在运行程序时,你需要在命令行中提供两个参数,即输入路径和输出路径。
例如,你可以这样运行你的程序:
虚拟机运行
hadoop jar YourJarFile.jar com.leokadia.mapreduce.wordcount.WordCountDriver /input/path /output/path
这里
/input/path
是输入数据的HDFS路径,
/output/path
是输出结果的HDFS路径。通过这样的修改,你可以更方便地在不同的环境中运行你的 MapReduce 作业,而不需要每次都修改代码中的路径。
对于新改的程序,先点clean把前面的删掉,再点package进行导包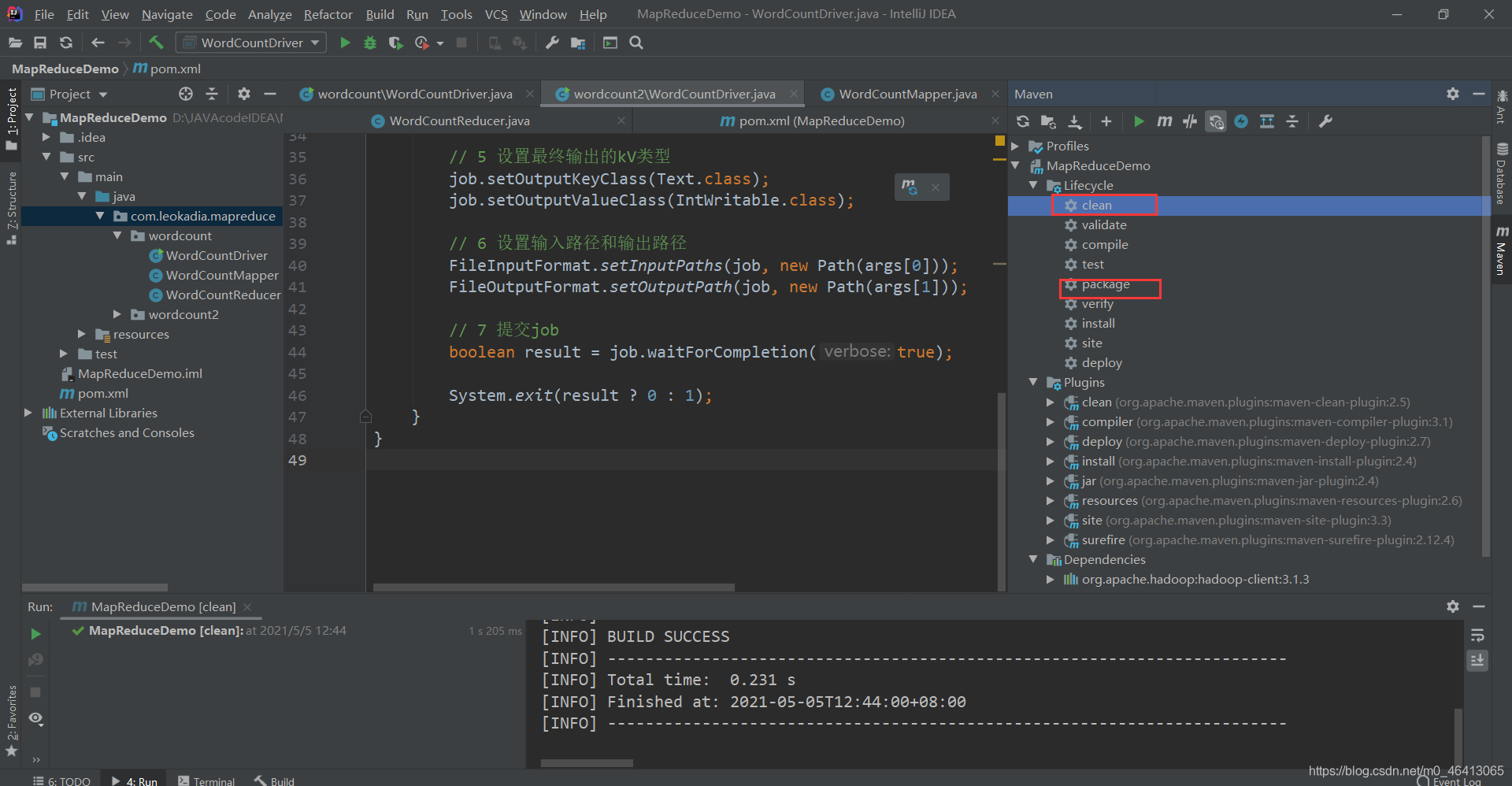

将新的包按上面的操作更名wc.jar
(4)启动 Hadoop 集群
[leokadia@hadoop102 mapreduce]$
myhadoop.sh start
对于已启动好的集群,直接拖拽
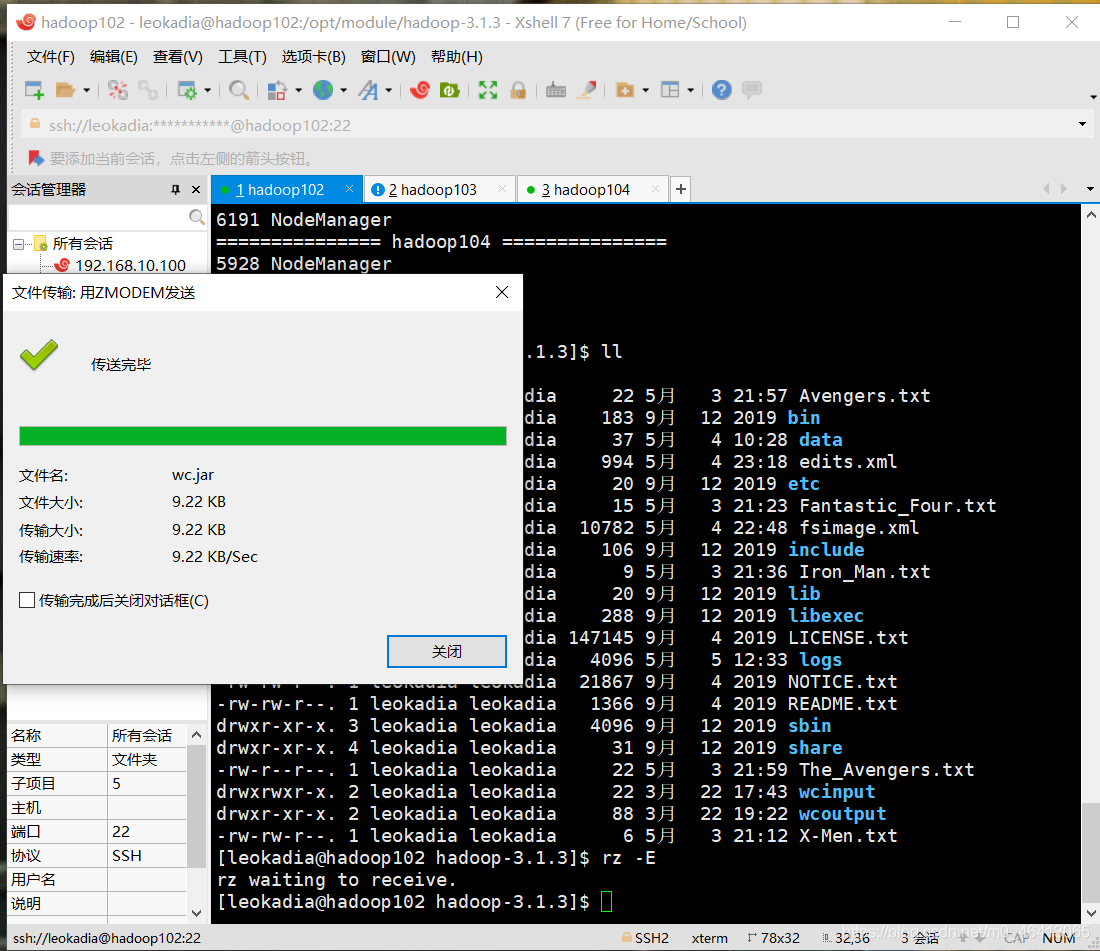
jar包导入完毕!
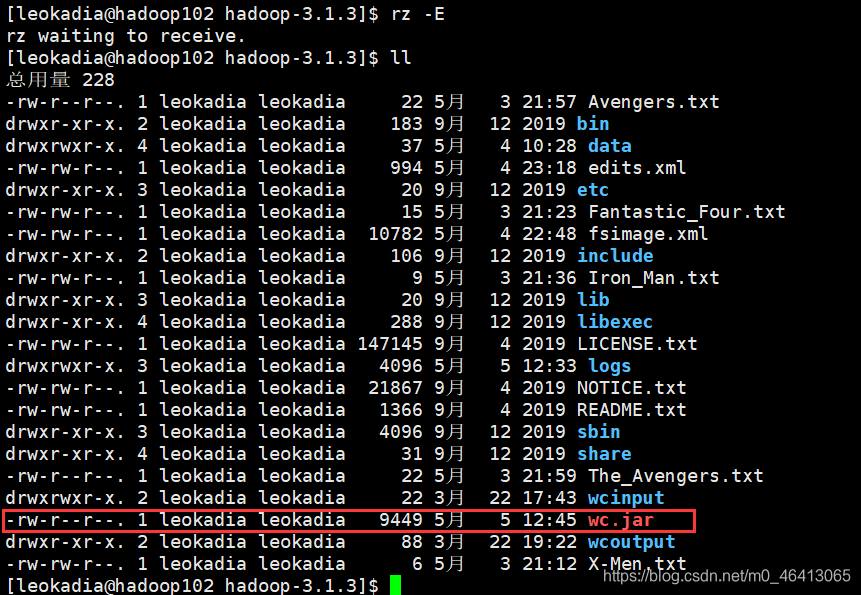
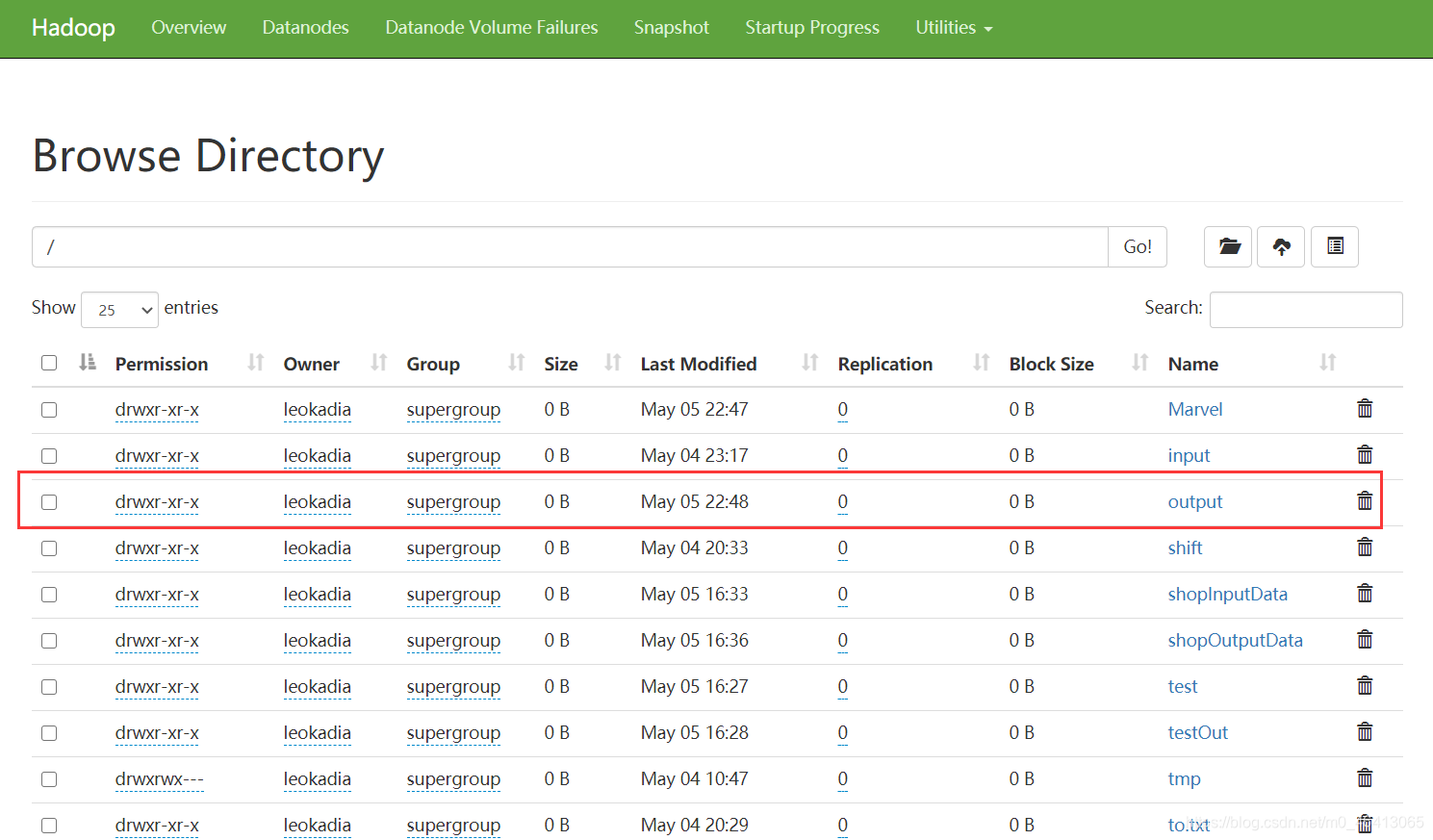
先在HDFS集群中设置刚刚要wordcount的源文件
在集群中建一个Marvel文件夹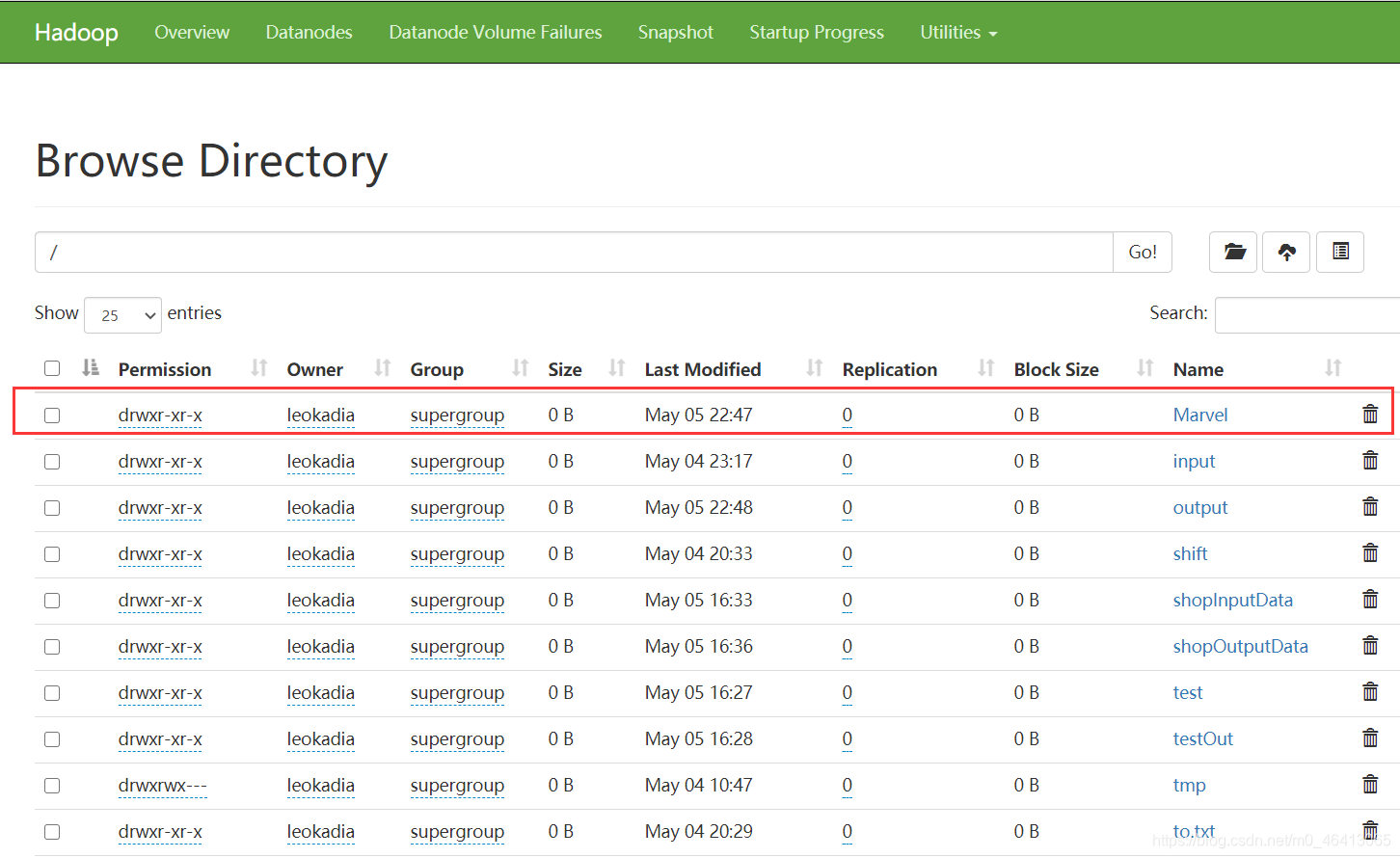
在文件夹中上传我们之前要wordcount的Marvel.txt源文件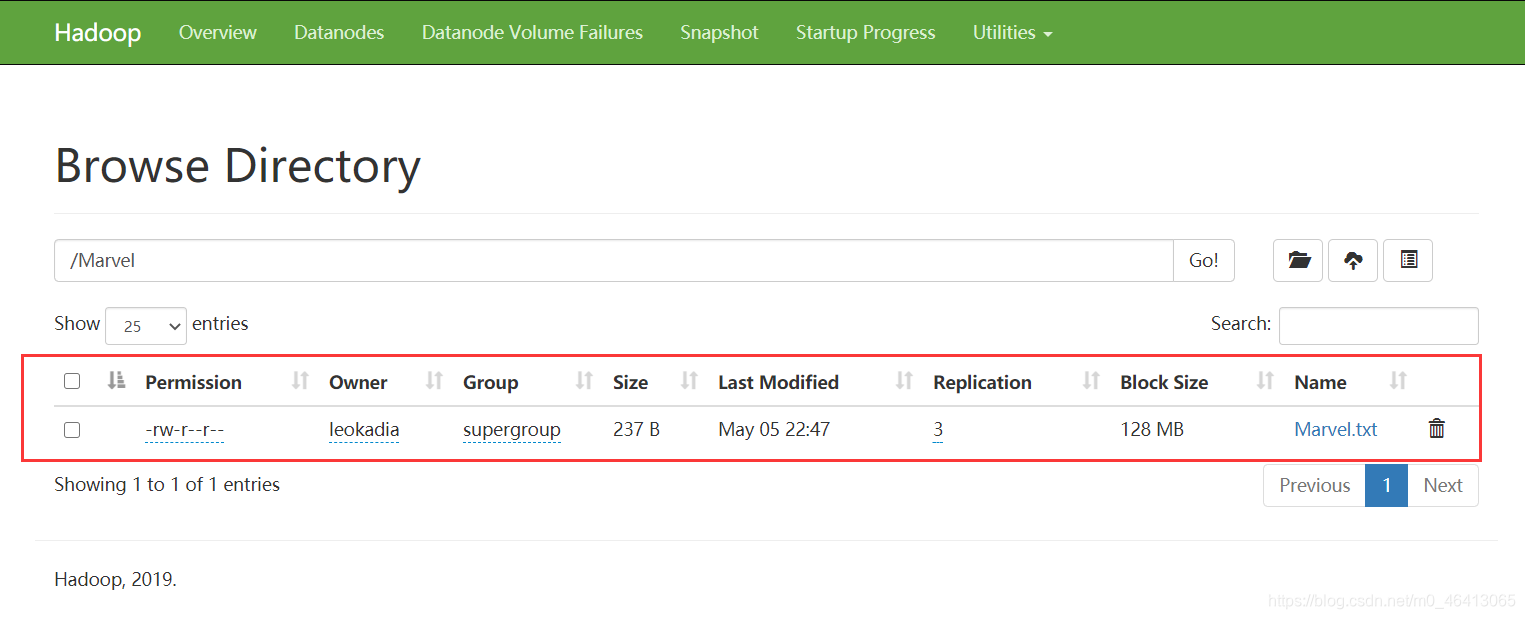
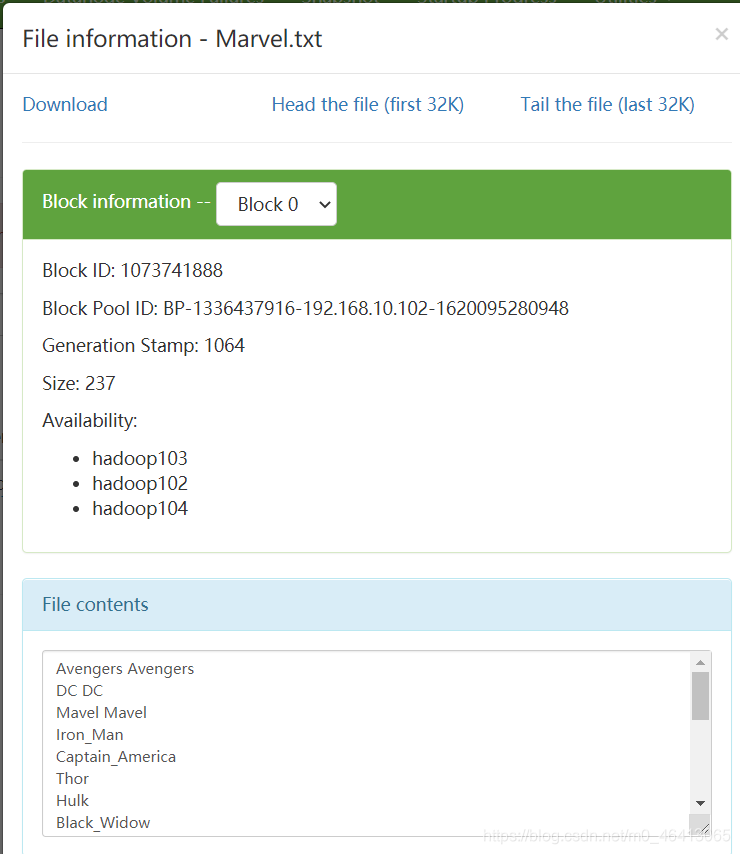
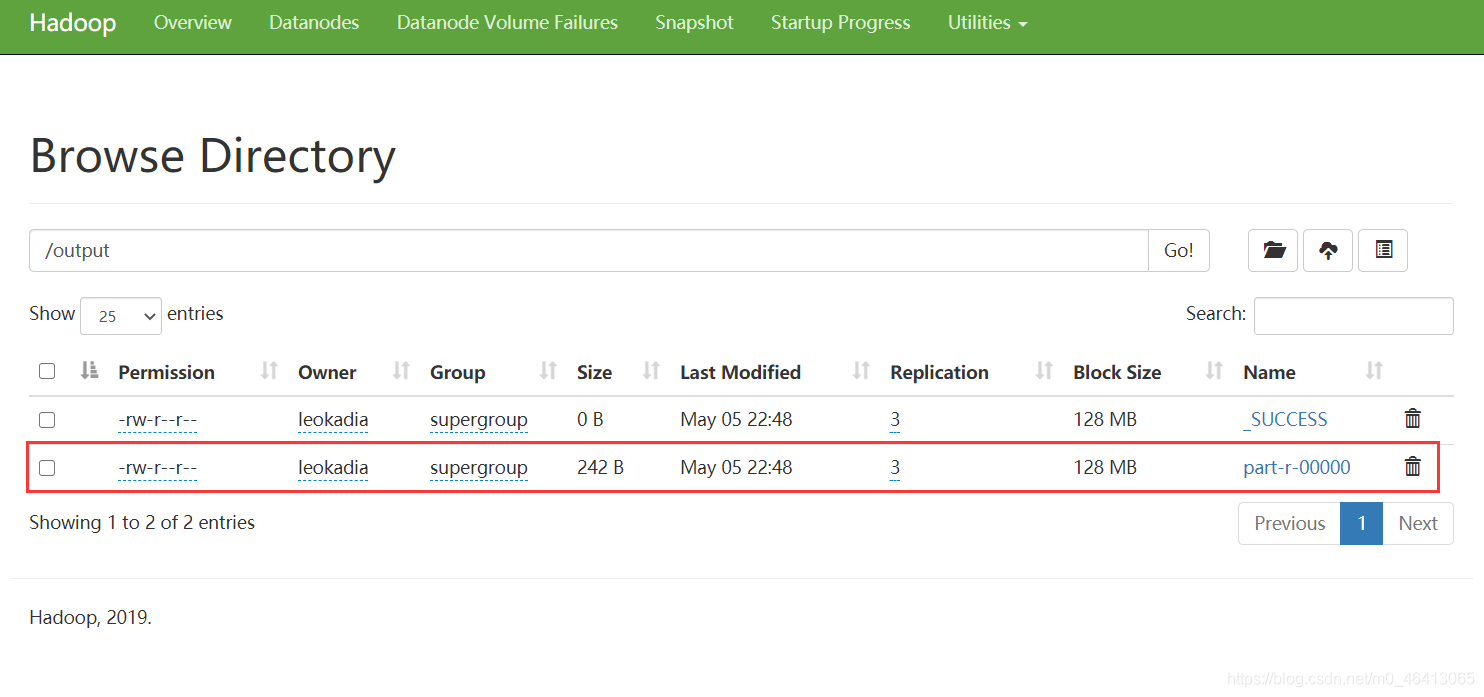
5)执行 WordCount 程序
[leokadia@hadoop102 hadoop-3.1.3]$ hadoop jar wc.jar com.leokadia.mapreduce.wordcount2.WordCountDriver /user/leokadia/Marvel /user/leokadia/output
你以为输入以上代码就是最后一步大功告成了?
不好意思,博主的java本地版本与hadoop的版本不兼容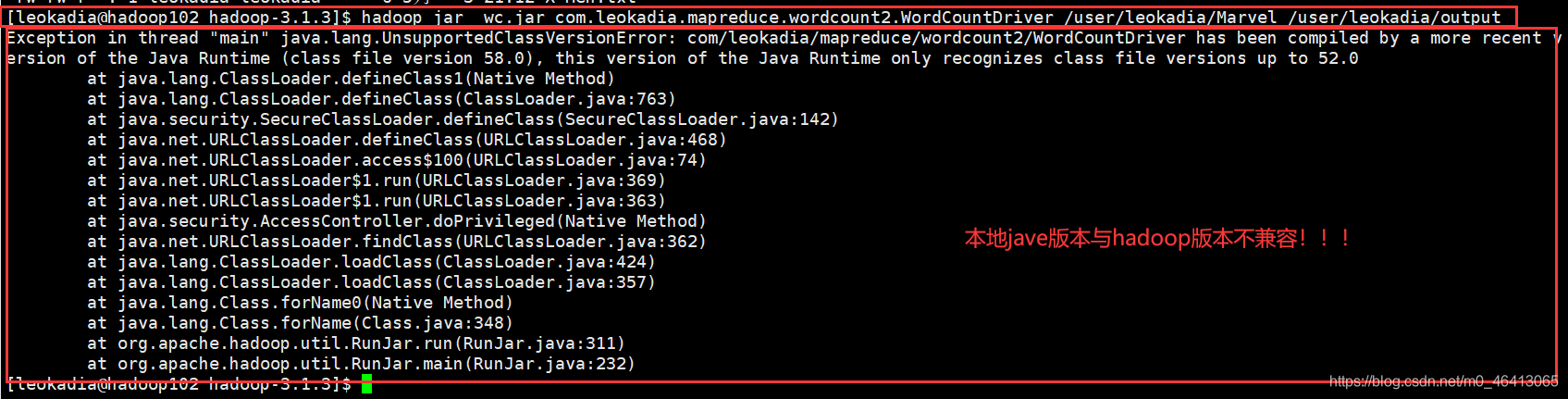
博主本地装的14,当时在hadoop里面配置的8
博主本地的java版本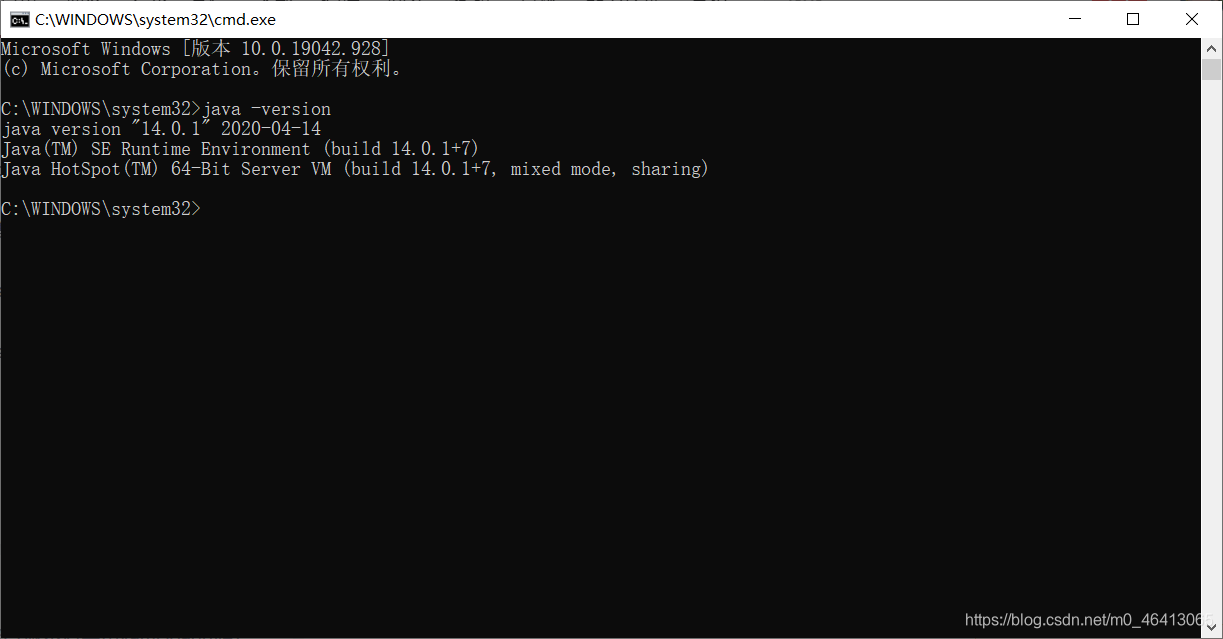
博主hadoop里面装的java版本
于是,然后经过查证,hadoop3.x目前只支持jdk1.8
博主只好将本地的jdk版本改成8
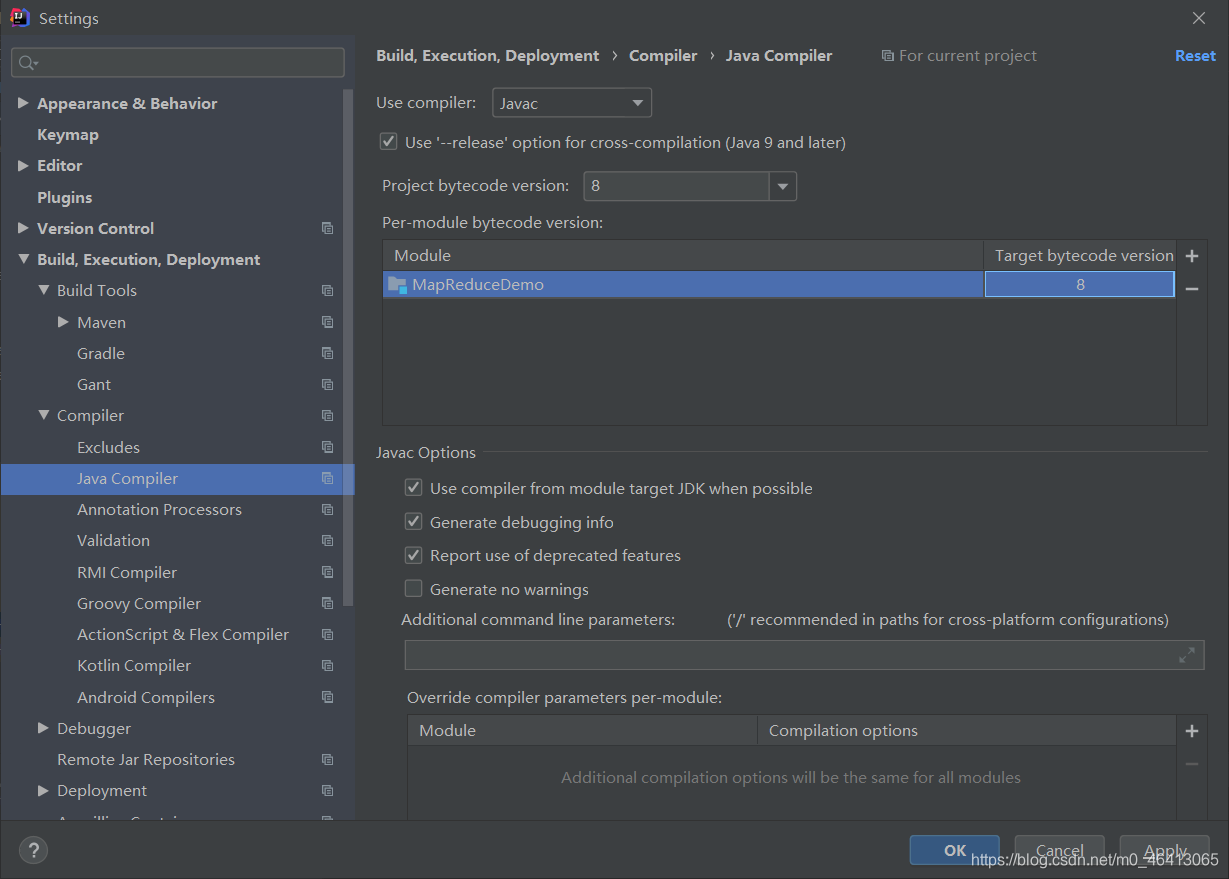

然后再重新生成jar包,导入jar包到集群,再重新运行程序
[leokadia@hadoop102 hadoop-3.1.3]$ hadoop jar wc.jar com.leokadia.mapreduce.wordcount2.WordCountDriver /Marvel /output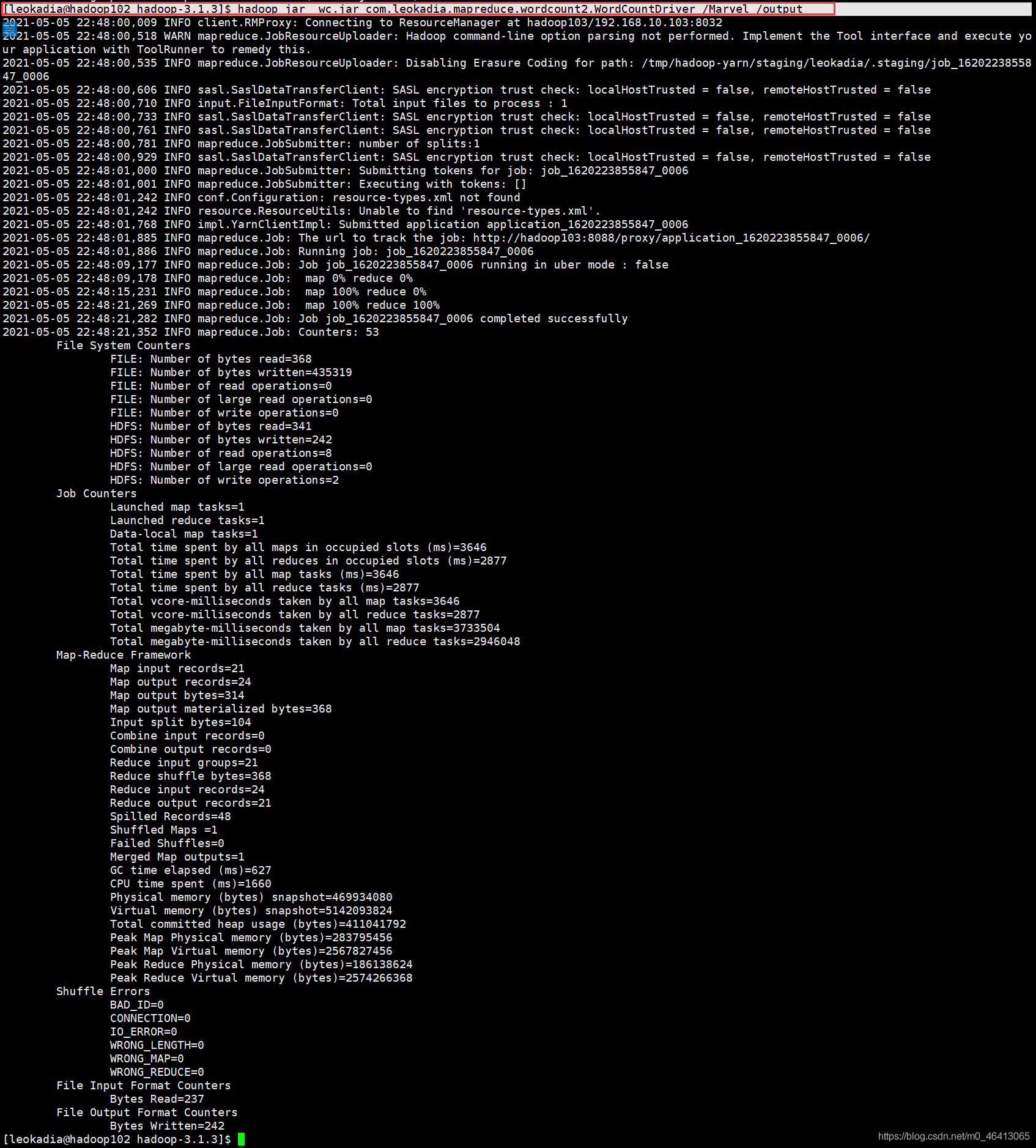
yarn架构分析
资源的调度和管理平台
主从结构
主节点,可以有2个:ResourceManager
从节点,有很多个: NodeManager
ResourceManager负责
集群资源的分配与调度
MapReduce、Storm、Spark等应用,必须实现ApplicationMaster接口,才能被RM管理
NodeManager负责
单节点资源的管理(CPU+内存)
mapreduce架构分析
依赖磁盘io的批处理计算模型
主从结构
主节点,只有一个: MRAppMaster
从节点,就是具体的task
MRAppMaster负责
接收客户端提交的计算任务
把计算任务分给NodeManager的Container中执行,即任务调度
Container是YARN中资源的抽象,它封装了某个节点上一定量的资源(CPU和内存两类资源)
Container由ApplicationMaster向ResourceManager申请的,由ResouceManager中的资源调度器异步分配给ApplicationMaster
Container的运行是由ApplicationMaster向资源所在的NodeManager发起的
监控Container中Task的执行情况
Task负责:
处理数据
HDFS架构

HDFS架构-NameNode
NameNode是整个文件系统的管理节点。它维护着整个文件系统的文件目录树,文件/目录的元信息和每个文件对应的数据块列表。接收用户的操作请求。
文件包括:
fsimage:元数据镜像文件。存储某一时段NameNode内存元数据信息。
edits:操作日志文件,namenode启动后一些新增元信息日志。
fstime:保存最近一次checkpoint的时间
以上这些文件是保存在linux的文件系统中hdfs-site.xml的dfs.namenode.name.dir属性
HDFS架构-Secondary NameNode
SecondaryNameNode是用来帮助NameNode完成元数据信息合并,从角色上看属于NameNode的“秘书”
其工作流程如下:
- secondary向NameNode发起Checkpoint请求
- secondary从namenode获得fsimage和edits
- secondary将fsimage载入内存,然后开始合并edits
- secondary将新的fsimage发回给namenode
- namenode用新的fsimage替换旧的fsimage
CheckPoint发起时机:
1.fs.checkpoint.period 指定两次checkpoint的最大时间间隔,默认3600秒。
2.fs.checkpoint.size 规定edits文件的最大值,一旦超过这个值则强制checkpoint,不管是否到达最大时间间隔默认大小是64M。
HDFS架构-DataNode
DataNode作用?
为整个集群提供真实文件数据的存储服务,同时管理本节点中所有Block块
什么是Block块?
文件块(block):最基本的存储单位。对于文件内容而言,一个文件的长度大小是size,那么从文件的0偏移开始,按照固定的大小,顺序对文件进行划分并编号,划分好的每一个块称一个Block。2.0以后HDFS默认Block大小是128MB,以一个256MB文件,共有256/128=2个Block.可以在hdfs-site.xml中dfs.blocksize属性配置Block块
HDFS读写流程–写流程
1.客户端通过调用DistributedFileSystem的create方法创建新文件
2.DistributedFileSystem通过RPC调用namenode去创建一个没有blocks关联的新文件,创建前,namenode会做各种校验,比如文件是否存在,客户端有无权限去创建等。如果校验通过,namenode就会记录下新文件,否则就会抛出IO异常.
3.前两步结束后会返回FSDataOutputStream的对象,象读文件的时候相似,FSDataOutputStream被封装成DFSOutputStream.DFSOutputStream可以协调namenode和datanode。客户端开始写数据到DFSOutputStream,DFSOutputStream会把数据切成一个个小packet,然后排成队列data quene。
4.DataStreamer会去处理接受data queue,他先问询namenode这个新的block最适合存储的在哪几个datanode里,比如副本数是3,那么就找到3个最适合的datanode,把他们排成一个pipeline.DataStreamer把packet按队列输出到管道的第一个datanode中,第一个datanode又把packet输出到第二个datanode中,以此类推。
5.DFSOutputStream还有一个对列叫ack queue,也是有packet组成,等待datanode的收到响应,当pipeline中的所有datanode都表示已经收到的时候,这时akc queue才会把对应的packet包移除掉。
如果在写的过程中某个datanode发生错误,会采取以下几步:1) pipeline被关闭掉;2)为了防止丢包ack queue里的packet会同步到data queue里;3)把产生错误的datanode上当前在写但未完成的block删掉;4)block剩下的部分被写到剩下的两个正常的datanode中;5)namenode找到另外的datanode去创建这个块的复制。当然,这些操作对客户端来说是无感知的。
6.客户端完成写数据后调用close方法关闭写入流
7.DataStreamer把剩余得包都刷到pipeline里然后等待ack信息,收到最后一个ack后,通知namenode把文件标示为已完成。
HDFS读写流程–读流程
1.首先调用FileSystem对象的open方法,其实是一个DistributedFileSystem的实例
2.DistributedFileSystem通过rpc获得文件的第一个block的locations,同一block按照副本数会返回多个locations,这些locations按照hadoop拓扑结构排序,距离客户端近的排在前面.
3.前两步会返回一个FSDataInputStream对象,该对象会被封装成DFSInputStream对象,DFSInputStream可以方便的管理datanode和namenode数据流。客户端调用read方法,DFSInputStream最会找出离客户端最近的datanode并连接。
4.数据从datanode源源不断的流向客户端。
5.如果第一块的数据读完了,就会关闭指向第一块的datanode连接,接着读取下一块。这些操作对客户端来说是透明的,客户端的角度看来只是读一个持续不断的流。
6.如果第一批block都读完了,DFSInputStream就会去namenode拿下一批blocks的location,然后继续读,如果所有的块都读完,这时就会关闭掉所有的流。
如果在读数据的时候,DFSInputStream和datanode的通讯发生异常,就会尝试正在读的block的排第二近的datanode,并且会记录哪个datanode发生错误,剩余的blocks读的时候就会直接跳过该datanode。DFSInputStream也会检查block数据校验和,如果发现一个坏的block,就会先报告到namenode节点,然后DFSInputStream在其他的datanode上读该block的镜像
该设计的方向就是客户端直接连接datanode来检索数据并且namenode来负责为每一个block提供最优的datanode,namenode仅仅处理block location的请求,这些信息都加载在namenode的内存中,hdfs通过datanode集群可以承受大量客户端的并发访问。
MapReduce 工作流程

MapReduce 编程模型
MapReduce 编程模型开发简单且功能强大,专门为并行处理大规模数据量而设计,接下来,通过一张图来描述 MapReduce 的工作过程,如图所示。
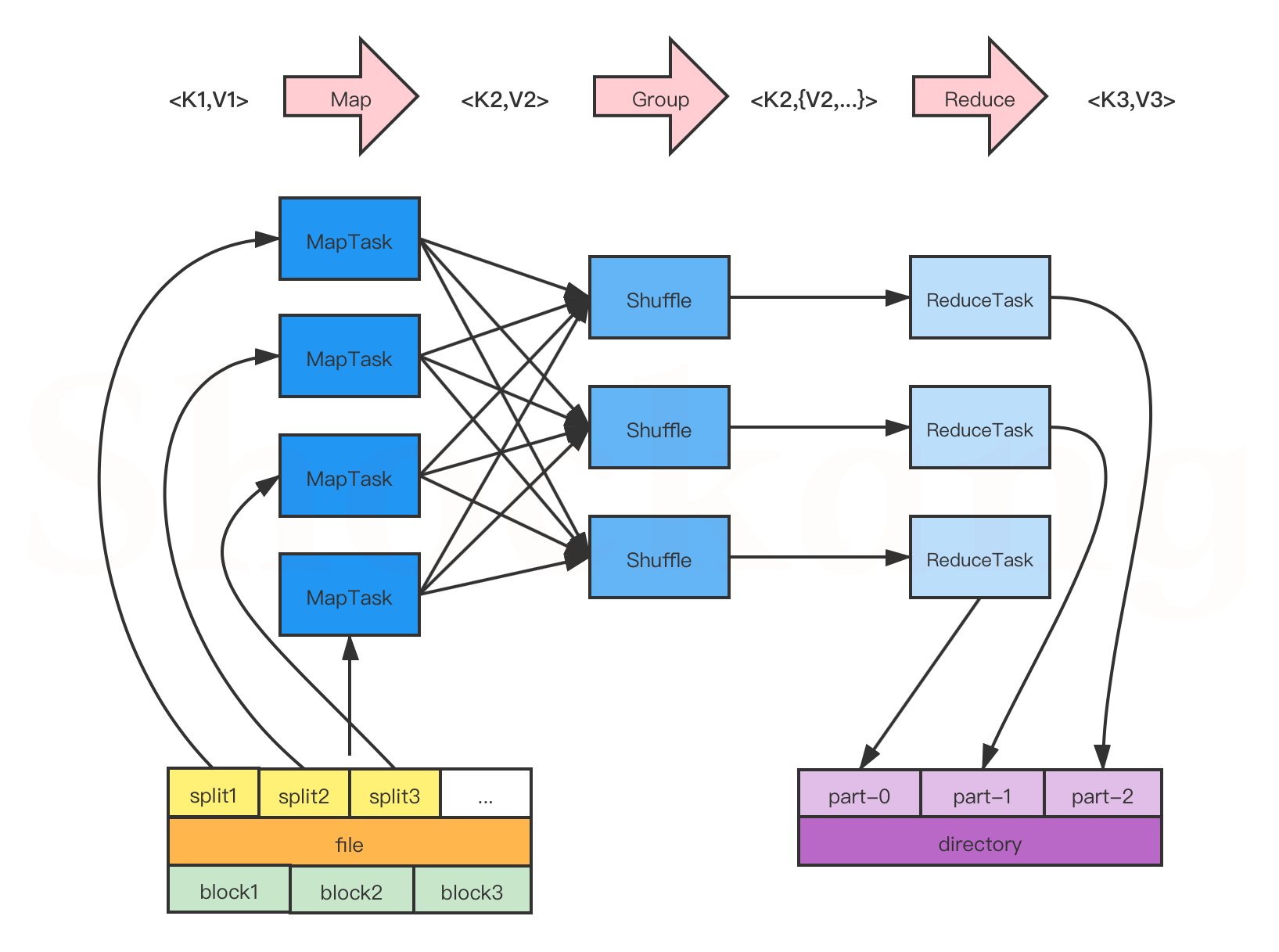
关于 MapReduce 编程模型的更多细节请参考我的这篇博客——MapReduce 编程模型到底是怎样的?
整体流程
在上图中, MapReduce 的工作流程大致可以分为5步,具体如下: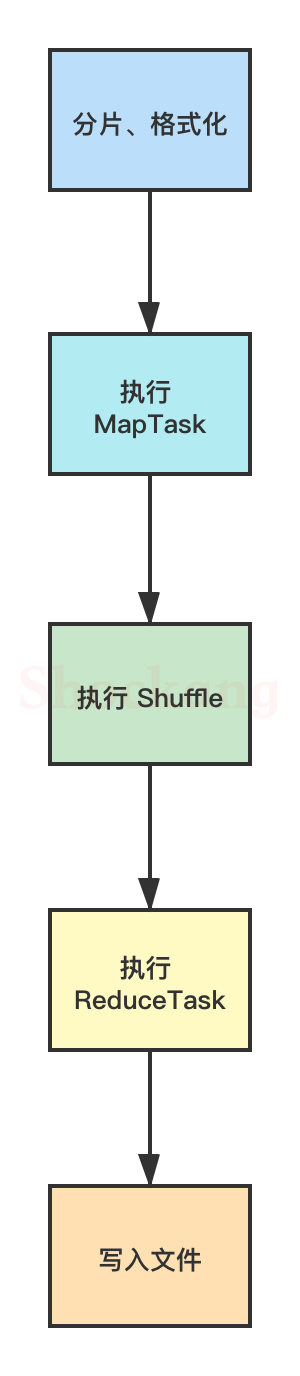
分片、格式化数据源
输入 Map 阶段的数据源,必须经过分片和格式化操作。
- 分片操作:指的是将源文件划分为大小相等的小数据块( Hadoop 2.x 中默认 128MB ),也就是分片( split ), Hadoop 会为每一个分片构建一个 Map 任务,并由该任务运行自定义的 map() 函数,从而处理分片里的每一条记录;
- 格式化操作:将划分好的分片( split )格式化为键值对<key,value>形式的数据,其中, key 代表偏移量, value 代表每一行内容。
执行 MapTask
每个 Map 任务都有一个内存缓冲区(缓冲区大小 100MB ),输入的分片( split )数据经过 Map 任务处理后的中间结果会写入内存缓冲区中。
如果写人的数据达到内存缓冲的阈值( 80MB ),会启动一个线程将内存中的溢出数据写入磁盘,同时不影响 Map 中间结果继续写入缓冲区。
在溢写过程中, MapReduce 框架会对 key 进行排序,如果中间结果比较大,会形成多个溢写文件,最后的缓冲区数据也会全部溢写入磁盘形成一个溢写文件,如果是多个溢写文件,则最后合并所有的溢写文件为一个文件。
执行 Shuffle 过程
MapReduce 工作过程中, Map 阶段处理的数据如何传递给 Reduce 阶段,这是 MapReduce 框架中关键的一个过程,这个过程叫作 Shuffle 。
Shuffle 会将 MapTask 输出的处理结果数据分发给 ReduceTask ,并在分发的过程中,对数据按 key 进行分区和排序。
执行 ReduceTask
输入 ReduceTask 的数据流是<key, {value list}>形式,用户可以自定义 reduce()方法进行逻辑处理,最终以<key, value>的形式输出。
写入文件
MapReduce 框架会自动把 ReduceTask 生成的<key, value>传入 OutputFormat 的 write 方法,实现文件的写入操作。
MapTask
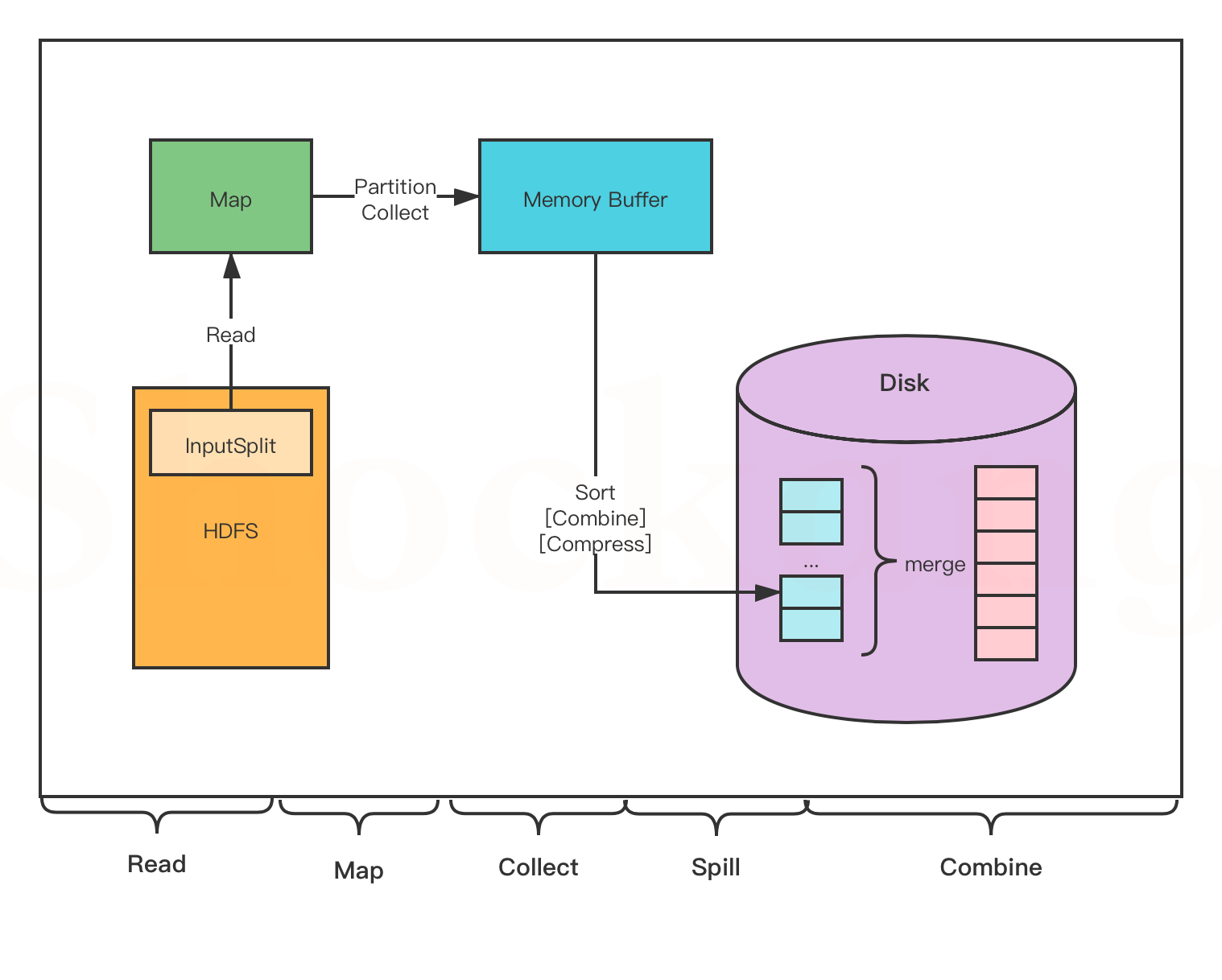
- Read 阶段: MapTask 通过用户编写的 RecordReader ,从输入的 InputSplit 中解析出一个个 key / value 。
- Map 阶段:将解析出的 key / value 交给用户编写的 Map ()函数处理,并产生一系列新的 key / value 。
- Collect 阶段:在用户编写的 map() 函数中,数据处理完成后,一般会调用 outputCollector.collect() 输出结果,在该函数内部,它会将生成的 key / value 分片(通过调用 partitioner ),并写入一个环形内存缓冲区中(该缓冲区默认大小是 100MB )。
- Spill 阶段:即“溢写”,当缓冲区快要溢出时(默认达到缓冲区大小的 80 %),会在本地文件系统创建一个溢出文件,将该缓冲区的数据写入这个文件。
将数据写入本地磁盘前,先要对数据进行一次本地排序,并在必要时对数据进行合并、压缩等操作。
写入磁盘之前,线程会根据 ReduceTask 的数量,将数据分区,一个 Reduce 任务对应一个分区的数据。
这样做的目的是为了避免有些 Reduce 任务分配到大量数据,而有些 Reduce 任务分到很少的数据,甚至没有分到数据的尴尬局面。
如果此时设置了 Combiner ,将排序后的结果进行 Combine 操作,这样做的目的是尽可能少地执行数据写入磁盘的操作。
- Combine 阶段:当所有数据处理完成以后, MapTask 会对所有临时文件进行一次合并,以确保最终只会生成一个数据文件
合并的过程中会不断地进行排序和 Combine 操作,
其目的有两个:一是尽量减少每次写人磁盘的数据量;二是尽量减少下一复制阶段网络传输的数据量。
最后合并成了一个已分区且已排序的文件。
ReduceTask

- Copy 阶段: Reduce 会从各个 MapTask 上远程复制一片数据(每个 MapTask 传来的数据都是有序的),并针对某一片数据,如果其大小超过一定國值,则写到磁盘上,否则直接放到内存中
- Merge 阶段:在远程复制数据的同时, ReduceTask 会启动两个后台线程,分别对内存和磁盘上的文件进行合并,以防止内存使用过多或者磁盘文件过多。
- Sort 阶段:用户编写 reduce() 方法输入数据是按 key 进行聚集的一组数据。
为了将 key 相同的数据聚在一起, Hadoop 采用了基于排序的策略。
由于各个 MapTask 已经实现对自己的处理结果进行了局部排序,因此, ReduceTask 只需对所有数据进行一次归并排序即可。
- Reduce 阶段:对排序后的键值对调用 reduce() 方法,键相等的键值对调用一次 reduce()方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到 HDFS 中
- Write 阶段: reduce() 函数将计算结果写到 HDFS 上。
合并的过程中会产生许多的中间文件(写入磁盘了),但 MapReduce 会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到 Reduce 函数。
Yarn工作流程
YARN Client
YARN Client提交Application到RM,它会首先创建一个Application上下文对象,并设置AM必需的资源请求信息,然后提交到RM。YARN Client也可以与RM通信,获取到一个已经提交并运行的Application的状态信息等。
ResourceManager(RM)
RM是YARN集群的Master,负责管理整个集群的资源和资源分配。RM作为集群资源的管理和调度的角色,如果存在单点故障,则整个集群的资源都无法使用。在2.4.0版本才新增了RM HA的特性,这样就增加了RM的可用性。
NodeManager(NM)
NM是YARN集群的Slave,是集群中实际拥有实际资源的工作节点。我们提交Job以后,会将组成Job的多个Task调度到对应的NM上进行执行。Hadoop集群中,为了获得分布式计算中的Locality特性,会将DN和NM在同一个节点上运行,这样对应的HDFS上的Block可能就在本地,而无需在网络间进行数据的传输。
Container
Container是YARN集群中资源的抽象,将NM上的资源进行量化,根据需要组装成一个个Container,然后服务于已授权资源的计算任务。计算任务在完成计算后,系统会回收资源,以供后续计算任务申请使用。Container包含两种资源:内存和CPU,后续Hadoop版本可能会增加硬盘、网络等资源。
ApplicationMaster(AM)
AM主要管理和监控部署在YARN集群上的Application,以MapReduce为例,MapReduce Application是一个用来处理MapReduce计算的服务框架程序,为用户编写的MapReduce程序提供运行时支持。通常我们在编写的一个MapReduce程序可能包含多个Map Task或Reduce Task,而各个Task的运行管理与监控都是由这个MapReduceApplication来负责,比如运行Task的资源申请,由AM向RM申请;启动/停止NM上某Task的对应的Container,由AM向NM请求来完成。
Yarn是如何执行一个MapReduce job的:
首先,Resource Manager会为每一个application(比如一个用户提交的MapReduce Job) 在NodeManager里面申请一个container,然后在该container里面启动一个Application Master。 container在Yarn中是分配资源的容器(内存、cpu、硬盘等),它启动时便会相应启动一个JVM。然后,Application Master便陆续为application包含的每一个task(一个Map task或Reduce task)向Resource Manager申请一个container。等每得到一个container后,便要求该container所属的NodeManager将此container启动,然后就在这个container里面执行相应的task
等这个task执行完后,这个container便会被NodeManager收回,而container所拥有的JVM也相应地被退出
关于Hadoop|HDFS|MapReduce的一些问题与解答
1、如何解除Hadoop系统的安全模式?
答:
(1)修改dfs.safemode.threshold.pct为一个比较小的值,默认缺省是0.999f。
在hadoop的安装目录中的hdfs-site.xml 加修改的配置项,默认的值是float类型,设置一个较小的数值。
<property>
<name>dfs.safemode.threshold.pct</name>
<value>0.999f</value>
<description>
Specifies the percentage of blocks that should satisfy
the minimal replication requirement defined by
dfs.replication.min.
Values less than or equal to 0 mean not to wait for any particular
percentage of blocks before exiting safemode.
Values greater than 1 will make safe mode permanent.
</description>
</property>
(2)hadoop dfsadmin -safemode leave命令强制离开
用户可以通过dfsadmin -safemode value 来操作安全模式,参数value的说明如下:
enter - 进入安全模式
leave - 强制NameNode离开安全模式
get - 返回安全模式是否开启的信息
wait - 等待,一直到安全模式结束。
两种方法对比:
方法一:可以一劳永逸,但是有风险。
方法二:需要在每次重启hdfs集群的时候都要输入。
2、为什么HDFS不适合低延迟数据访问?
答:
Hadoop 完全是批处理系统, 旨在存储和分析结构化, 非结构化和半结构化数据。
Hadoop 的 map / reduce 框架相对较慢,因为它旨在支持不同的格式,结构和大量数据。
我们不应该说 HDFS 较慢,因为 HBase no-sql 数据库和基于 MPP 的数据源(例如 Impala,Hawq)位于 HDFS 上。这些数据源 Action 更快,因为它们不遵循mapreduce 执行来进行数据检索和处理。
仅由于基于映射/归约的执行的性质而导致出现速度慢,在这种情况下,它会生成大量中间数据,在节点之间交换大量数据,从而导致巨大的磁盘 IO 延迟。此外, 它必须将大量数据保留在磁盘中以在阶段之间进行同步,以便它可以支持从故障中恢复作业。同样,mapreduce 中也没有办法将全部/子集数据缓存在内存中。
3、为什么HDFS无法高效存储大量小文件?
答:
因为Namenode把文件系统的元数据放置在内存中,所以文件系统所能容纳的文件数目是由Namenode的内存大小来决定。一般来说,每一个文件、文件夹和Block需要占据150字节左右的空间,所以,如果你有100万个文件,每一个占据一个Block,你就至少需要300MB内存。当前来说,数百万的文件还是可行的,当扩展到数十亿时,对于当前的硬件水平来说就没法实现了。还有一个问题就是,因为Map task的数量是由splits来决定的,所以用MR处理大量的小文件时,就会产生过多的Maptask,线程管理开销将会增加作业时间。
大量的小文件,也会影响 NameNode 的寻址时间:
(1)小文件过多,会过多占用 namenode 的内存,并浪费 block。文件的元数
据(包括文件被分成了哪些 blocks,每个 block 存储在哪些服务器的哪个 block
块上) ,都是存储在 namenode 上的。
HDFS 的每个文件、目录、数据块占用 150B,因此 300M 内存情况下,只能存储
不超过 300M/150=2M 个文件/目录/数据块的元数据
dataNode 会向 NameNode 发送两种类型的报告: 增量报告和全量报告。
增量报告是当dataNode接收到block或者删除block时, 会向nameNode
报告。
全量报告是周期性的,NN 处理 100 万的 block 报告需要 1s 左右,这 1s
左右 NN 会被锁住,其它的请求会被阻塞
(2)文件过小,寻道时间大于数据读写时间,这不符合 HDFS 的设计:
HDFS 为了使数据的传输速度和硬盘的传输速度接近, 则设计将寻道时间 (Seek)相对最小化,将 block 的大小设置的比较大,这样读写数据块的时间将远大于寻址时间,接近于硬盘的传输速度。
HDFS 天生就是为存储大文件而生的, 一个块的元数据大小大概在 150byte 左右,存储一个小文件就要占用 150byte 的内存,如果存储大量的小文件很快就将内存耗尽,而整个集群存储的数据量很小,失去了 HDFS 的意义可以将数据合并上传,或者将文件 append 形式追加在 HDFS 文件末尾。
总结来说:就是两点:
无法高效的对大量小文件进行存储。
存储大量小文件的话,它会占用NameNode大量的内存来存储文件目录和块信息。这样是不可取的,因为NameNode的内存总是有限的;
小文件存储的寻址时间会超过读取时间,它违反了HDFS的设计目标。
4、为什么HDFS不支持多用户写入及任意修改文件?
答:
不支持多用户写入:HDFS只支持单用户写,因为需要创建副本所以怕冲突,并且若加入多用户写入特性可能会使效率降低;
HDFS 本来就不是适合频繁写入的文件系统,它比较适合一次写入,多次使用。
目前 Hadoop 只支持单用户写,不支持并发多用户写。可以使用 Append 操作在文件的末尾添加数据,但不支持在文件的任意位置进行修改。
5、HDFS如何解决名称节点运行期间EditLog不断变大的问题?
答:
解决方案:利用SecondaryNameNode第二名称节点
第二名称节点是HDFS架构中的一个组成部分,用来保存名称节点中对HDFS 元数据信息的备份,并减少名称节点重启的时间。(SecondaryNameNode一般是单独运行在一台机器上)
SecondaryNameNode的工作情况:
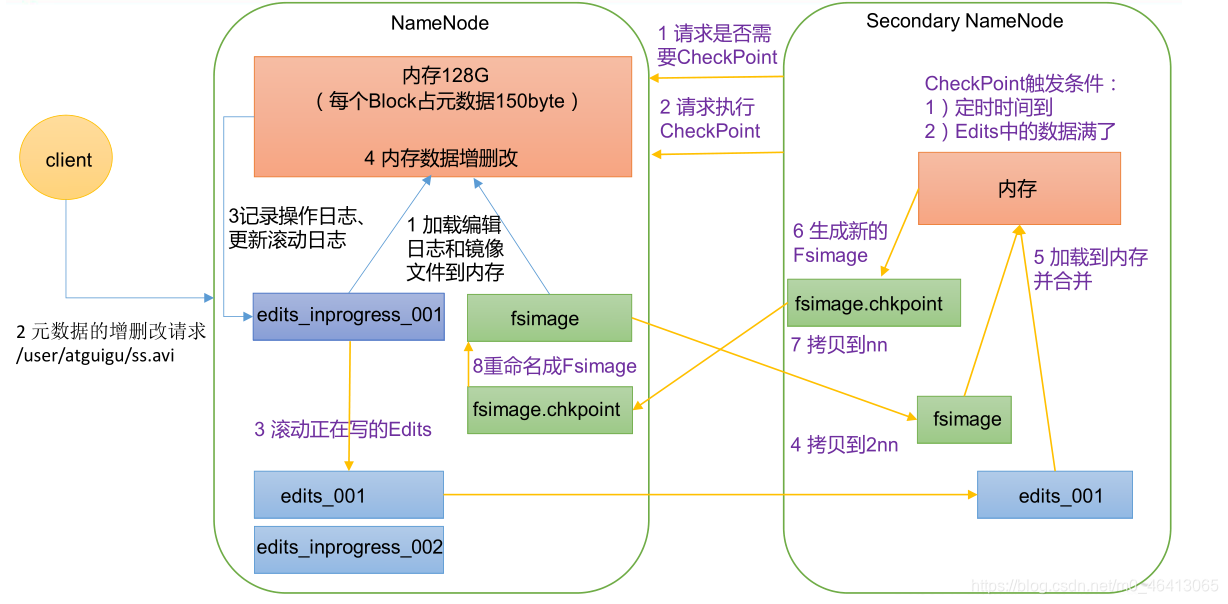
(1)SecondaryNameNode会定期和NameNode通信,请求其停止使用EditLog文件,暂时将新的写操作写到一个新的文件edit.new上来,这个操作是瞬间完成,上层写日志的函数完全感觉不到差别;
(2)SecondaryNameNode通过HTTP GET方式从NameNode上获取到FsImage和EditLog文件,并下载到本地的相应目录下;
(3)SecondaryNameNode将下载下来的FsImage载入到内存,然后一条一条地执行EditLog文件中的各项更新操作,使得内存中的FsImage保持最新;这个过程就是EditLog和FsImage文件合并;
(4)SecondaryNameNode执行完(3)操作之后,会通过post方式将新的FsImage文件发送到NameNode节点上
(5)NameNode将从SecondaryNameNode接收到的新的FsImage替换旧的FsImage文件,同时将edit.new替换EditLog文件,通过这个过程EditLog就变小了
6、Map任务为什么要进行分区操作,如何分区?
为什么需要分区操作:
假设始终使用一个分区,在处理大型文件时效率极低,因为一台机器必须处理所有输出文件,从而完全丧失了 MapReduce 所提供的并行架构的优势。
但是,如果使用一个 partitioner 来描述结果,运行多个 ruduce 任务,运行partition 时,将数据分配到每个 reduce 中,最后合并输出文件,就得到了有意义的最终结果。
在将map()函数处理后得到的(key,value)对写入到缓冲区之前,需要先进行分区操作,这样就能把map任务处理的结果发送给指定的reducer去执行,从而达到负载均衡,避免数据倾斜。
如何进行分区操作:
MapReduce提供默认的分区类(HashPartitioner),我们也可以自定义分区,让其继承Partitioner类,并重写getPartition()方法,让其针对不同情况返回不同数值即可。并在最后通过job设置指定分区类和reducer任务数量即可。
7、MapReduce中多个Reduce任务的结果会做进一步的处理么?为什么?
答:
会,因为reducetask根据自己的分区号,去各个maptask机器上取相应的结果分区数据,取到同一个分区的来自不同maptask的结果文件,reducetask会将这些文件再进行合并(归并排序)形成大文件。
8、参照“第四章-MapReduce”中的图4-7、4-8和4-9,如果有两个Reduce,重新画出用户没有定义Combiner时的MapReduce过程示意图,并简要说明Shuffle过程。
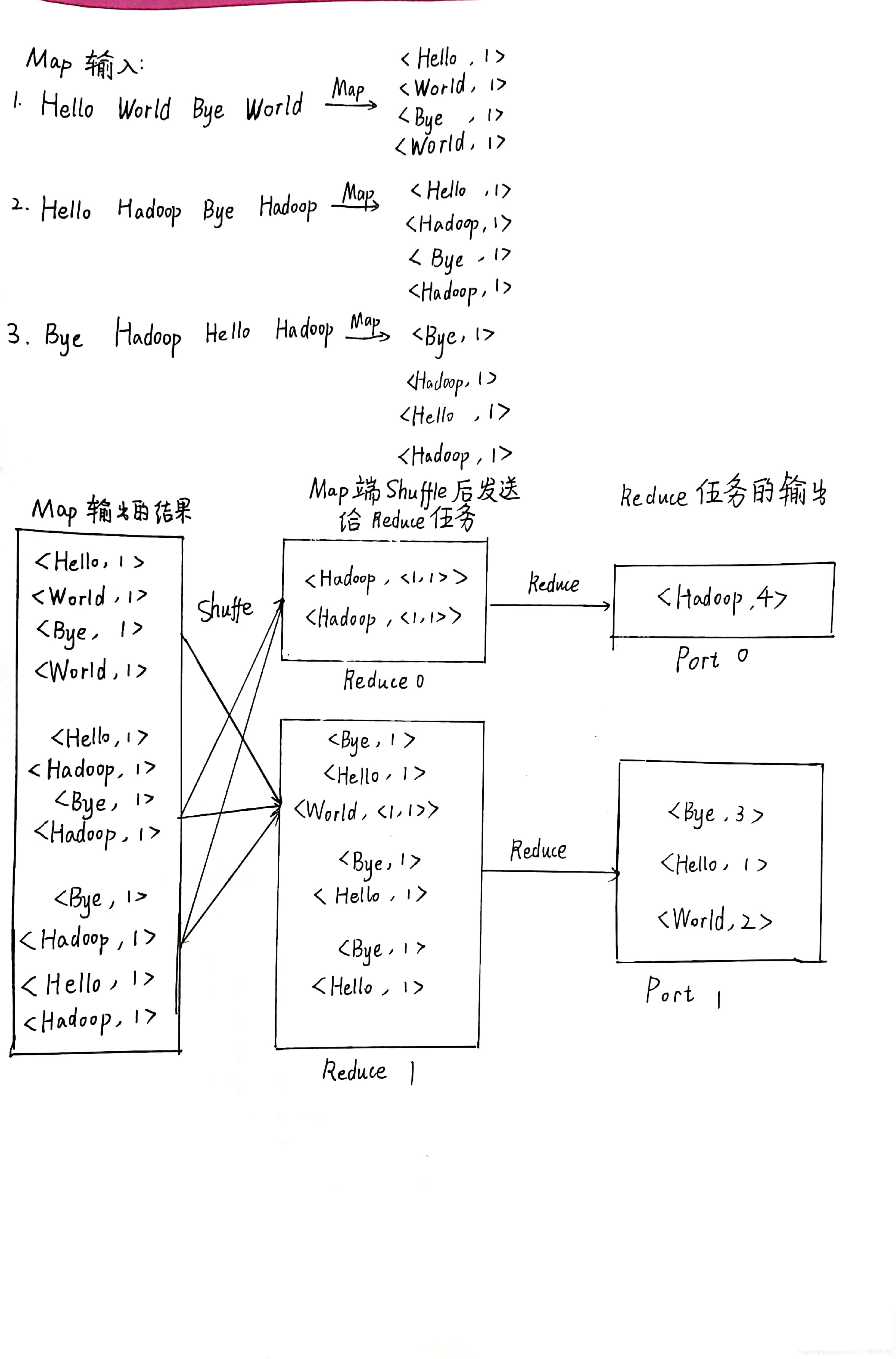
Shuffle 过程:
分区
在将 map 函数处理后得到<key, value>对写入到缓冲区之前, 需要先进行分区操作,这样就能把 Map 任务处理的结果发送给指定的Reducer 去执行,从而达到负载均衡,避免数据倾斜。
执行溢写
一旦缓冲区内容达到阈值,就会会锁定内存,并在每个分区中对其中的键值对按键进行 sort 排序, 排序完成后创建一个溢出写文件, 然后开启一个后台线程把这部分数据以一个临时文件的方式溢出写到本地磁盘中。
归并 merge
如果一个 task 处理的数据很大,以至于超过缓冲区内存时,就会生成多个 spill 文件。此时就需要对同一个 map 任务产生的多个 spill 文件进行归并生成最终的一个已分区且已排序的大文件。 这个过程包括排序和合并,归并得到的文件内键值对可能拥有相同的 key。
版权归原作者 小柔的 所有, 如有侵权,请联系我们删除。