
笔者在完成课程设计时,突然想到把大数据框架同时部署到PC端虚拟机以及ARM架构的Linux板上,这篇博客记录集群部署流程以及例程测试。
部署架构如下图:若下文与架构图冲突,则以架构图为准。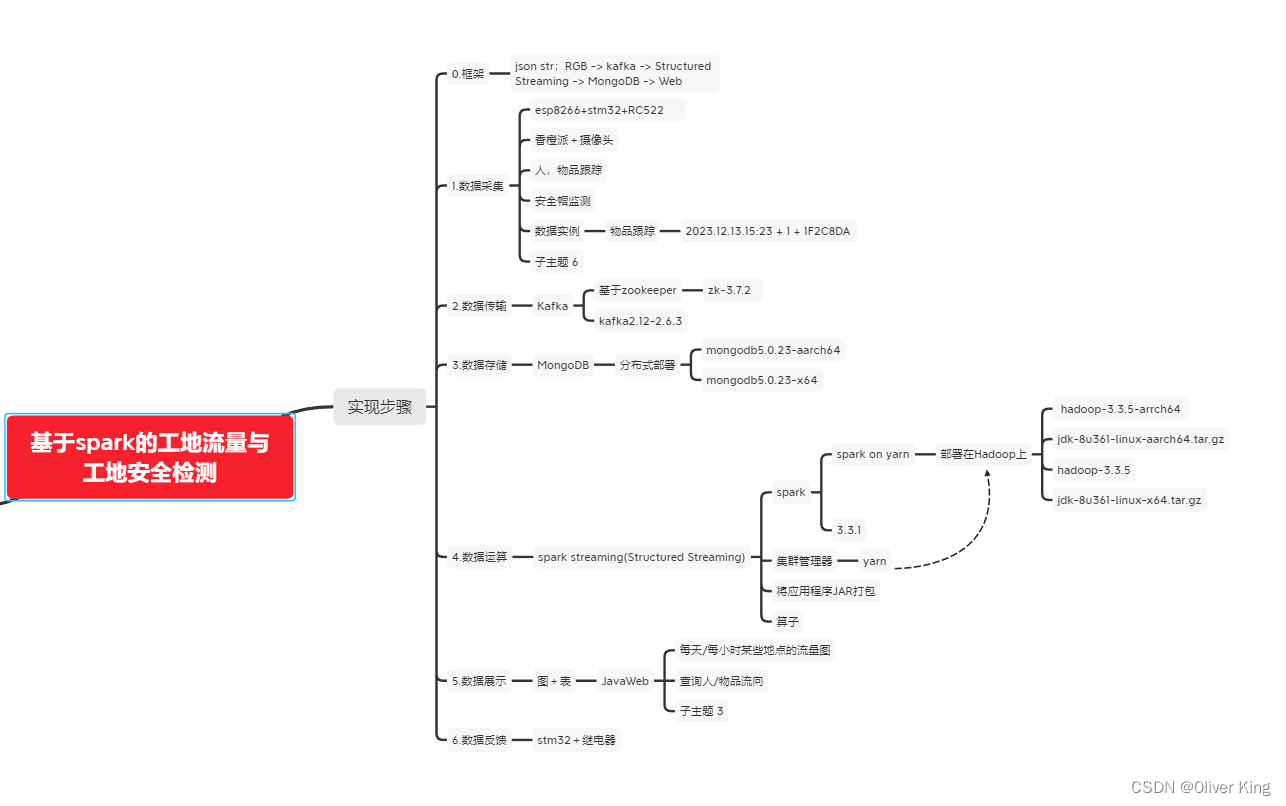
运行环境:
PC方面,使用两台Ubuntu 20.04 LTS Focal Fossa虚拟机
ARM板子则使用香橙派5(RK3588S),系统是香橙派官方适配的Ubuntu20.04
三台设备通过手机作为路由器在同一网段下。
本篇主要包括:
- 配置虚拟机
- Hadoop安装
- spark安装
- zookeeper安装
- kafka安装
- mongodb安装
- Kafka和香橙派串口测试例程
- spark streaming 例程
- pyspark Structured Streaming kafka 例程
- 最终测试部分代码
配置虚拟机
一、下载ubuntu
清华源下载Ubuntu20.04
二、VMware加载镜像
三、基础配置
1.配置ssh
$ sudo apt-get update # 更新源
$ sudo apt-get upgrade # 更新已安装包
$ sudo apt install openssh-server # 安装ssh服务器
$ sudo apt install openssh-client # 安装ssh客户机
$ sudo vi /etc/ssh/ssh_config # 去掉PasswordAuthentication yes前面的"#"号
$ sudo vi /etc/ssh/sshd_config
# 在PermitRootLogin prohibit-password这行行首加上"#"
# 在此行下面添加新一行
PermitRootLogin yes
重启ssh
sudo /etc/init.d/ssh restart
$ sudo passwd # 输入密码,并确认密码
$ sudo apt install net_tools # 安装最新版本的net_tools
$ ifconfig -a # inet <ip地址> 就是远程ssh的ip
2.换源
Ubuntu系统中,软件源文件地址为:/etc/apt/sources.list
1.备份原来的源,将以前的源备份一下,以防以后可以用的。
sudo cp /etc/apt/sources.list /etc/apt/sources.list.bak
2.打开/etc/apt/sources.list文件,在前面添加如下条目,并保存。
sudo vi /etc/apt/sources.list(可将vi更换为自己熟悉的编辑器)
#添加阿里源
deb http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ focal-backports main restricted universe multiverse
#添加清华源
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-updates main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-backports main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-backports main restricted universe multiverse
deb https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security main restricted universe multiverse
# deb-src https://mirrors.tuna.tsinghua.edu.cn/ubuntu/ focal-security main restricted universe multiverse multiverse
更新源
sudo apt-get update
更新软件:
sudo apt-get upgrade
3.下载vim
sudo apt-get install vim
修改vim配置:
vim /etc/vim/vimrc
在最后加上
set ai " 自动缩进,新行与前面的行保持—致的自动空格
set aw " 自动写,转入shell或使用:n编辑其他文件时,当前的缓冲区被写入
set flash " 在出错处闪烁但不呜叫(缺省)
set ic " 在查询及模式匹配时忽赂大小写
set nu
set number " 屏幕左边显示行号
"set showmatch " 显示括号配对,当键入“]”“)”时,高亮度显示匹配的括号
set showmode " 处于文本输入方式时加亮按钮条中的模式指示器
set showcmd " 在状态栏显示目前所执行的指令,未完成的指令片段亦会显示出来
set wrap " 长行显示自动折行
"colorscheme evening " 设定背景为夜间模式
filetype plugin on " 自动识别文件类型,自动匹配对应的, “文件类型Plugin.vim”文件,使用缩进定义文件
set autoindent " 设置自动缩进:即每行的缩进值与上一行相等;使用 noautoindent 取消设置
set cindent " 以C/C++的模式缩进
set noignorecase " 默认区分大小写
set ruler " 打开状态栏标尺
set scrolloff=5 " 设定光标离窗口上下边界 5 行时窗口自动滚动
set shiftwidth=4 " 设定 << 和 >> 命令移动时的宽度为 4
set softtabstop=4 " 使得按退格键时可以一次删掉 4 个空格,不足 4 个时删掉所有剩下的空格)
set tabstop=4 " 设定 tab 长度为 4
set wrap " 自动换行显示
syntax enable
syntax on " 自动语法高亮
4.设置静态ip
不多赘述,不要忘记设置DNS
二、Hadoop安装
这里主要借鉴了这篇博客,按照此博主流程一步一步来即可,这里不再赘述,同时为了各类框架的兼容,请读者使用笔者部署架构里列出的版本号。
【大数据】Hadoop-3.3.4完全分布式安装(包含VMware16和Ubuntu22的下载安装及配置)、搭建、配置教程,以及Hadoop基础简介_hadoop hadoop-3.3.4 jdk jdk1 jdk1.8.0_144-CSDN博客
三、spark安装
# 解压
tar -zxvf spark-3.1.2-bin-hadoop3.2.tgz -C ../program/
# 配置环境
配置Spark由如下5个环境变量需要设置
SPARK_HOME: 表示Spark安装路径在哪里
PYSPARK_PYTHON: 表示Spark想运行Python程序, 那么去哪里找python执行器
JAVA_HOME: 告知Spark Java在哪里
HADOOP_CONF_DIR: 告知Spark Hadoop的配置文件在哪里
HADOOP_HOME: 告知Spark Hadoop安装在哪里
这5个环境变量 都需要配置在: /etc/profile中
# JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_361
# HADOOP_HOME
export HADOOP_HOME=/usr/local/hadoop-3.3.5
# SPARK_HOME
export SPARK_HOME=/usr/local/spark-3.3.1-bin-hadoop3
# PYSPARK_PYTHON
export PYSPARK_PYTHON=python3
export PYTHONPATH=$SPARK_HOME/python:$SPARK_HOME/python/lib/py4j-0.10.9.5-src.zip:$PYTHONPATH
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HDFS_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$SPARK_HOME/bin:$PATH
PYSPARK_PYTHON
和
JAVA_HOME
需要同样配置在:
~/.bashrc
中
# JAVA_HOME
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_361
# PYSPARK_PYTHON
export PYSPARK_PYTHON=/usr/local/bin/python3
export PATH=$JAVA_HOME/bin:$PATH
生效
source /etc/profile
source ~/.bashrc
配置Spark配置文件
cd /usr/local/spark-/conf
cp spark-env.sh.template spark-env.sh
文件最后加入以下内容:
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_361
export PYSPARK_PYTHON=python3
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop
export SPARK_DIST_CLASSPATH=$(/usr/local/hadoop-3.3.5/bin/hadoop classpath)
测试
# 进入样例 jar 包所在位置
cd ~/program/spark-3.1.2-bin-hadoop3.2/examples/jars
# 提交任务
spark-submit --master yarn --class org.apache.spark.examples.SparkPi spark-examples_2.12-3.1.2.jar 1000
修改yarn配置
cd /export/server/hadoop/etc/hadoop
vim /export/server/hadoop/etc/hadoop/yarn-site.xml
<configuration>
<!-- 配置yarn主节点的位置 -->
<property>
<name>yarn.resourcemanager.hostname</name>
<value>node1</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<!-- 设置yarn集群的内存分配方案 -->
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>20480</value>
</property>
<property>
<name>yarn.scheduler.minimum-allocation-mb</name>
<value>2048</value>
</property>
<property>
<name>yarn.nodemanager.vmem-pmem-ratio</name>
<value>2.1</value>
</property>
<!-- 开启日志聚合功能 -->
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<!-- 设置聚合日志在hdfs上的保存时间 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>604800</value>
</property>
<!-- 设置yarn历史服务器地址 -->
<property>
<name>yarn.log.server.url</name>
<value>http://node1:19888/jobhistory/logs</value>
</property>
<!-- 关闭yarn内存检查 -->
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
</property>
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
</property>
</configuration>
四、zookeeper安装
一、清华源下载.bin.tar.gz
二、解压
/usr/local/zookeeper.tar.gz -C /usr/local
三、修改 conf 下配置
cd /../zookeeper/conf
cp zoo_sample.cfg zoo.cfg
vim zoo.cfg
dataDir=/usr/local/apache-zookeeper-3.7.2-bin/data //配置datadir文件
server.1=master:2888:3888
server.2=slave1:2888:3888
server.3=slave2:2888:3888
四、写入节点ID
在dataDir=/usr/local/apache-zookeeper-3.7.2-bin/下创建data
data下创建myid
写入conf下的ID:例如master就写1,slave2就写3
五、修改环境变量
/etc/profile中加入:
export ZK_HOME=/usr/local/apache-zookeeper-3.7.2-bin
export PATH=$PATH:$ZK_HOME/bin
使生效
source /etc/profile
六、启动
三台设备都要执行命令:
# 启动Zookeeper服务
zkServer.sh start
# 查看该节点的Zookeeper角色
zkServer.sh status
关闭也要三台设备都执行:
zkServer.sh stop
出现异常:
为文件夹添加权限
chmod 777 文件夹目录 -R
编写zookeeper启动脚本:myzookeeper.sh
#! /bin/bash
case $1 in
"start"){
for i in master slave1 slave2
do
echo " -------- $i 正在启动 Zookeeper ......"
# 用于KafkaManager监控
ssh $i "source /etc/profile;zkServer.sh start "
done
echo " -------- Zookeeper 集群已启动完成!-------"
};;
"stop"){
for i in master slave1 slave2
do
echo " -------- $1 正在停止Zookeeper -------"
ssh $i "source /etc/profile;zkServer.sh stop"
done
echo " -------- Zookeeper 集群已全部停止!-------"
};;
esac
五、kafka安装
一、下载解压
/usr/local/kafka.tar -C /usr/local
二、修改环境变量
sudo vim /etc/profile
# 添加如下内容
export KAFKA_HOME=/usr/local/kafka_2.12-2.6.3
export PATH=$PATH:$KAFKA_HOME/bin
使生效
source /etc/profile
三.修改配置
在 Kafka 安装目录下创建kafka-logs文件夹(用来存储分区信息的 ,不要把它与存放错误日志的目录混淆了,日志目录是配置在 `log4j.properties文件 里的 )
[jiang@hadoop01 kafka-2.1.0]$ mkdir kafka-logs
进入安装目录的
config/
目录下,修改配置文件
server.properties
,找到对应数据进行修改:
# broker的全局唯一标识号,不能重复. 给集群中的每个broker配置一个不同的id
broker.id=1,2,3
# 分区数据的存储位置
log.dirs=/usr/local/kafka_2.12-2.6.3/kafka-logs
# 连接Zookeeper集群地址
zookeeper.connect=master:2181,slave1:2181,slave2:2181
四、编写启动关闭集群shell命令
kafka.sh
#! /bin/bash
case $1 in
"start"){
for i in master slave1 slave2
do
echo " -------- $i 正在启动 Kafka ......"
# 用于KafkaManager监控
ssh $i "source /etc/profile; nohup /usr/local/kafka_2.12-2.6.3/bin/kafka-server-start.sh -daemon /usr/local/kafka_2.12-2.6.3/config/server.properties "
done
echo " -------- Kafka 集群已启动完成!-------"
};;
"stop"){
for i in master slave1 slave2
do
echo " -------- $1 正在停止Kafka -------"
ssh $i "source /etc/profile; /usr/local/kafka_2.12-2.6.3/bin/kafka-server-stop.sh"
done
echo " -------- Kafka 集群已全部停止!-------"
};;
esac
报错
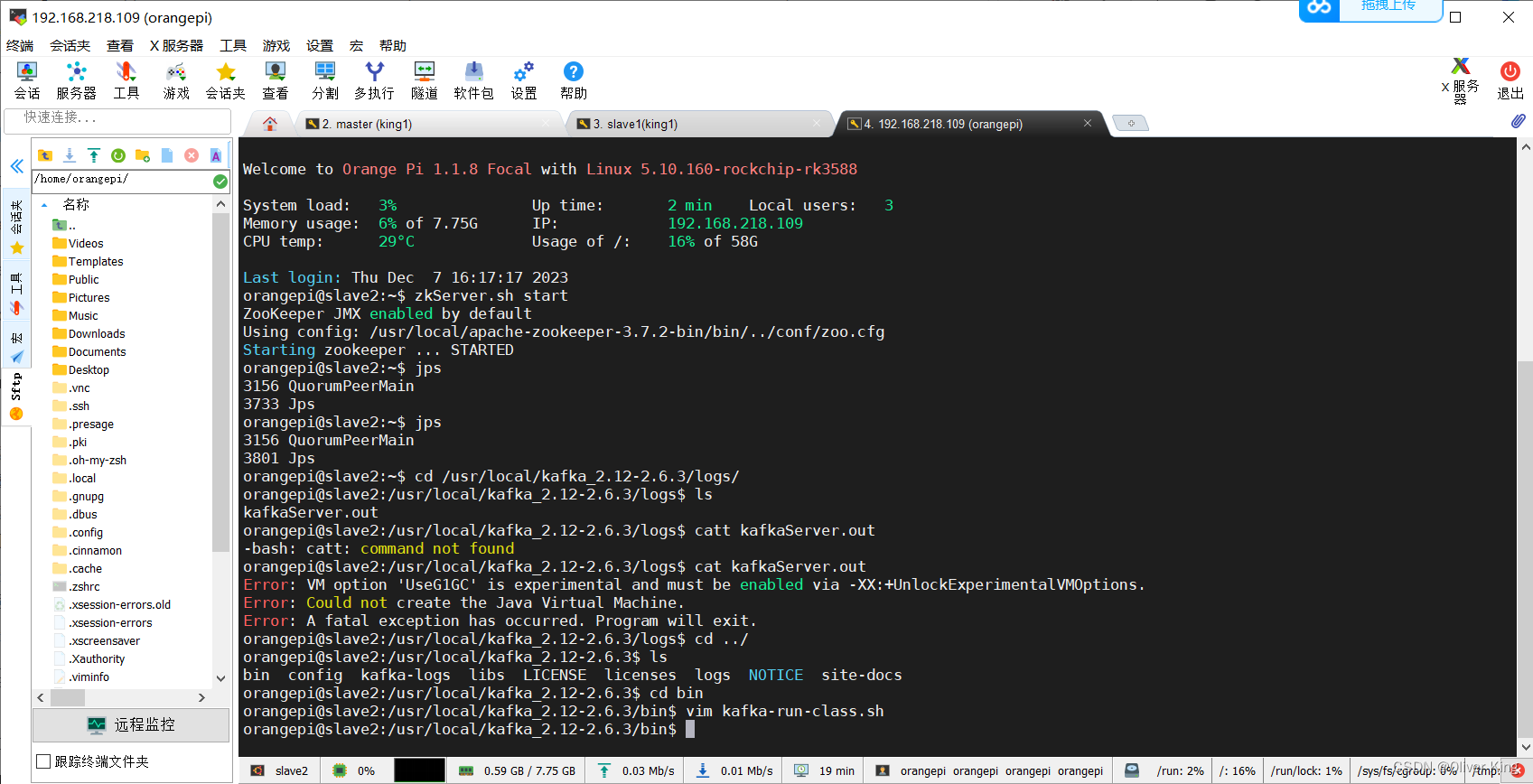
修改kafka-run-class.sh
删掉**-XX:+UseG1GC**
问题解决
六、mongodb安装
一、概念
副本集ReplicaSet部署方式
副本集概念和原理:
副本集是MongoDB中实现高可用性和数据备份的一种方式。副本集由一个主节点(Primary)和多个从节点(Secondary)组成。主节点负责处理读写请求,从节点复制主节点的数据。当主节点发生故障时,系统会自动选举一个从节点作为新的主节点,保证服务的持续可用性。
二、下载,解压
解压安装包
tar zxf mongodb-linux-x86_64-rhel70-5.0.23.tgz -C /usr/local
由于解压后的文件夹名称太长了,重命名一下
mv mongodb-linux-x86_64-rhel70-5.0.2 mongodb-5.0.23
配置
/usr/local/mongodb-5.0.23/ 目录下 创建目录 用于存放 配置文件,日志以及数据
mkdir-p conf log data
在 conf 目录 新建 mnogodb.conf 配置文件
vi mongodb.conf
#端口号
port = 27017
bind_ip = 0.0.0.0
#数据目录
dbpath = /usr/local/mongodb-5.0.23/data
#日志目录
logpath = /usr/local/mongodb-5.0.23/log/mongodb.log
#设置后台运行
fork = true
#日志输出方式
logappend = true
#开启认证
auth = true
启动 MongoDB
bin/mongod -config ./conf/mongodb.conf
报错:
bin/mongod: error while loading shared libraries: libcurl.so.4: cannot open shared object file: No such file or directory
解决办法:安装依赖
sudo apt-get update
sudo apt-get install libcurl4-openssl-dev
sudo apt-get install curl
终端连接
bin/mongo --port 27017
查看版本
db.version()
此时,如果 注释了 auth = true 远端已经可以连接 MongoDB了
创建 root 用户
先切换用户
use admin
db.createUser(
{
user: "root",
pwd: "123456",
roles: [ { role: "root", db: "admin" } ]
}
)
此时就可以使用可视化工具远程连接数据库
关闭服务
连接终端
bin/mongo --port 27017
1.数据库内部命令关闭:
> use admin
> db.shutdownServer()
2.使用MongoDB命令关闭:
/usr/local/mongodb/bin/mongod --shutdown -f /etc/mongodb_master.conf
3.使用kill命令关闭:(危险的很,我就是这样被锁的)
ps -ef | grep mongo
kill 18288
至此,单机安装成功,下面开始副本集ReplicaSet部署
mongodb.conf后面加上
systemLog:
#MongoDB发送所有日志输出的目标指定为文件
destination: file
#mongod或mongos应向其发送所有诊断日志记录信息的日志文件的路径
path: "/usr/local/mongodb-5.0.23/log/mongodb.log"
#当mongos或mongod实例重新启动时,mongos或mongod会将新条目附加到现有日志文件的末尾。
logAppend: true
storage:
#mongod实例存储其数据的目录。storage.dbPath设置仅适用于mongod。
dbPath: "/usr/local/mongodb-5.0.23/data"
journal:
#启用或禁用持久性日志以确保数据文件保持有效和可恢复。
enabled: true
processManagement:
#启用在后台运行mongos或mongod进程的守护进程模式。
fork: true
#指定用于保存mongos或mongod进程的进程ID的文件位置,其中mongos或mongod将写入其PID
pidFilePath: "/usr/local/mongodb-5.0.23/run/mongod.pid"
net:
#服务实例绑定所有IP,有副作用,副本集初始化的时候,节点名字会自动设置为本地域名,而不是ip
#bindIpAll: true
#服务实例绑定的IP
bindIp: 0.0.0.0
#绑定的端口
port: 27017
replication:
#副本集的名称
replSetName: rs
启动节点服务
/usr/local/mongodb-5.0.23/bin/mongod -f /usr/local/mongodb-5.0.23/conf/mongodb.conf
###报错:
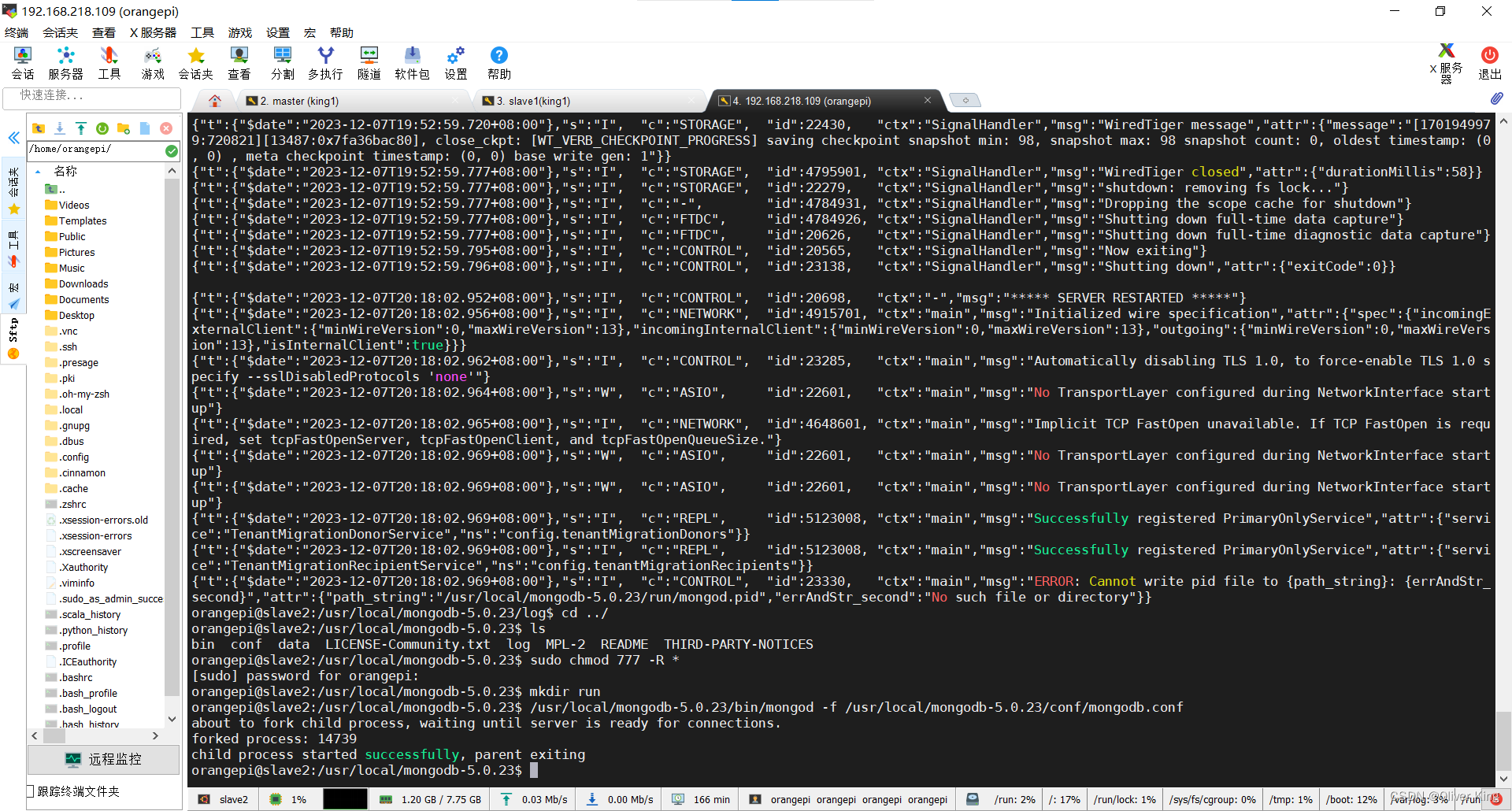
添加权限
sudo chmod 777 -R *
问题解决
连接主节点
/usr/local/mongodb-5.0.23/bin/mongo --port 27017
使用默认的配置初始化副本集,启动副本集
rs.initiate()
查看副本集的配置内容
rs.conf()
查看副本集状态
rs.status()
说明:
1) “set” : “rs” :副本集的名字
2) “myState” : 1:说明状态正常
3) “members” :副本集成员数组,此时只有一个: “name” : “node1:27017” ,该成员的角色是 “stateStr” : “PRIMARY”, 该节点是健康的: “health” : 1
添加副本从节点
rs.add(host, arbiterOnly)
arbiterOnly boolean 可选的。 仅在 值为字符串时适用。 如果为true,则添加的主机是仲裁者。
host string or document 要添加到副本集的新成员。 指定为字符串或配置文档:1)如 果是一个字符串,则需要指定新成员的主机名和可选的端口 号;2)如果是一个文档,请指定在members数组中找到的副 本集成员配置文档。 您必须在成员配置文档中指定主机字段。 有关文档配置字段的说明,详见下方文档:“主机成员的配置文档”
即
rs.add("slave1:27017")
rs.add("slave2:27017")
ok : 1 说明添加成功 但并不代表指定的副本节点已经正常添加到副本集中
此时可以查看副本集状态
rs.status()
关闭副本
先关闭次要节点,最后关闭主节点
操作
1.数据库相关
查看所有数据库
show databases
选择数据库(如果数据库不存在,不会报错;会隐式创建:当后期该数据库有数据时自动创建)
use 数据库名
删除数据库(先选中数据库)
db.dropDatabase()
2.集合相关
查看所有集合
show collections
创建集合(插入数据会隐式创建)
db.createCollection(‘co’)
删除集合
db.集合名.drop()
3.插入文档
db ; //admin
//db表示当前当前数据库
db.stus.insert({name:"小男孩",age:18,gender:"男"})
db.stus.insert({name:"猪八戒",age:28,gender:"男"});
//指定 _id插入
db.stus.insert({_id:"hello",name:"猪八戒",age:28,gender:"男"});
//插入多个对象
db.stus.insert([
{name:"沙和尚",age:38,gender:"男"},
{name:"白骨精",age:14,gender:"女"},
{name:"蜘蛛精",age:14,gender:"女"}
]);
db.co.insert([
{time:"2023.12.13.15:23",place:'01',RFID:"AF8C297B"},
{time:"2023.12.13.15:23",place:'02',RFID:"AF8C297B"},
{time:"2023.12.15.19:14",place:'01',RFID:"3A69826C"}
]);
//查询全部
db.stus.find();
//生成一个 _id
ObjectId() ;
4.查询
//查询所有
db.collection.find ()
//查询数组中第一个数据
db.collection.findOne()
//简单的条件查询
//查询当前数据库中”stus“集合的所有
db.stus.find();
//查询当前数据库中“stus”集合的 “_id=Hello”的所有数据
db.stus.find({_id:"hello"});
//查询当前数据库中“stus”集合的 “age=16" 并且 "name= 白骨精"的所有数据
db.stus.find({age:16 , name:"白骨精"});
//查询“age=28”的所有数据
db.stus.find({age:14});
//查询 “age=28”的第一个条数据
db.stus.findOne({age:28});
//统计当前数据库中 "stus"集合的所有数据条数
db.stus.find({}).count();
至此,完成框架安装。
测试例程见下文。
七、其他报错
sftp异常
重启服务即可
systemctl restart sshd.service
普通用户ssh登录
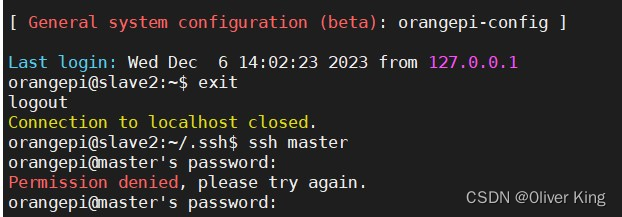
首先你可以试试
1、 ssh username@hostname
这里username是你要连接的电脑的用户名,hostname是它的地址。
如果可以的话,还是恭喜你。一次搞定。
如果失败
Permission denied (publickey,gssapi-keyex,gssapi-with-mic)
应该是你的配置文件出现了问题 /etc/ssh/sshd_config
这里我们使用简单的连接方式,很多同学可能也会使用另一种连接方式,那就是
2、ssh hostname
但是你会发现这样会出现这样的问题
Permission denied (publickey,gssapi-keyex,gssapi-with-mic)
并且一直输入密码总是提示密码不对,并一直报此错误。
那是因为你没有指定连接的用户名,它会默认使用当前的用户名所以会错误。
如果你不嫌麻烦可以使用
ssh username@hostname
当然也可以使用以下简单的方式:映射关系
在.ssh文件下创建一个文本config(如果没有)
touch config
编辑文档:
Host hostname
user username
例如:
HOST hadoop102
USER hadoop102
HoST hadoop103
USER hadoop103
添加的是对你连接关系的映射。
从hadoop102使用ssh hadoop103时默认改为ssh hadoop103@hadoop103,而不是原来的ssh hadoop102@hadoop103了
最后修改的最重要的一点记住权限问题config文档的权限同组用户严格为不能写权限
修改:
chmod644 config
或
chmod600 config
再次使用 ssh 用户名 就ok了!!!
这篇文章我主要想说的就是config文件,不嫌麻烦你可以使用 ssh hadoop103@hadoop103,嫌麻烦你可以添加config文件的映射,直接ssh hadoop102。
至于前面的ssh连接我没有讲的太清楚,那些网上到处都是,就不说了 。
hdfs无法上传,显示用户错误
vim /etc/profile
添加:export HADOOP_USER_NAME=king1(king1为我的用户名)
source /etc/profile(记得执行,以保证立即生效)
版权归原作者 0liver King 所有, 如有侵权,请联系我们删除。