
主机名和IP地址的映射
移动到该目录下,注意如果是在
[XZH@westgisB040 ~]$
下可能找不到该目录,需要多执行一步cd /回到根目录
cd etc
打开里面的hosts文件
vi hosts
在该文件增加HDFS涉及的所有节点的ip地址和节点名称,例如我的就是:
10.103.105.40 westgisB040
……
执行完后记得回到~下
实现免密登录(主节点到从节点,主节点到主节点)
注意!!!在安装前要使用root账号在每个节点上创建好账号(进root后再/home下使用useradd -m username)
在主节点产生公钥
ssh-keygen -t rsa
一直按enter就可以
进入.ssh目录
cd ~/.ssh
追加公钥文件至authorized_keys文件
cat id_rsa.pub >> authorized_keys
传输authorized文件到从节点.ssh的目录下
ssh-copy-id 10.103.105.41
此处ip地址为从节点的ip地址
执行完上述三个步骤已经能实现免密登录,分别如下语句测试是否成功(所有从节点和本机的)若成功执行改语句后是不需要输入密码的。
ssh username@IP
如不成功可能是authorized_keys的权限有问题,更改权限即可
**请一定确保!!!主节点到主节点的免密也实现了!!!!!!!再继续后续,否在在开启集群时无法开始!!!!!!!!!! **
**请一定确保!!!主节点到主节点的免密也实现了!!!!!!!再继续后续,否在在开启集群时无法开始!!!!!!!!!! **
**请一定确保!!!主节点到主节点的免密也实现了!!!!!!!再继续后续,否在在开启集群时无法开始!!!!!!!!!! **
集群规划
本次配置包括六台主机,其中
10.103.105.40 主节点namenode
10.103.105.41 从节点datanode
10.103.105.42 从节点datanode
10.103.105.43 从节点datanode
10.103.105.44 从节点datanode
10.103.105.45 client
传输并解压安装包
如果是在win上下好的可以用scp命令把压缩包传输到linux主节点上,
注意win是斜杠,linux是反斜杠
scp '.\jdk-8u131-linux-x64.tar.gz' username@IP:/home/username/
如果是直接在linux上下的也可以,这里使用的版本如下,一般官网都能找到资源下载这里就不再准备资源和下载教程
jdk-8u131-linux-x84
hadoop-3.1.3
解压安装包
依次执行下列指令
tar -zxvf jdk-8u131-linux-x64.tar.gz
tar -zxvf hadoop-3.1.3.tar.gz
有些linux版本不支持(),如果你传输的压缩包含“()”而且使用转义字符也失败的话可以使用tab键自动补全名称
配置环境变量
纵向配置
在/home/username/下
vi .bashrc
增加如下内容
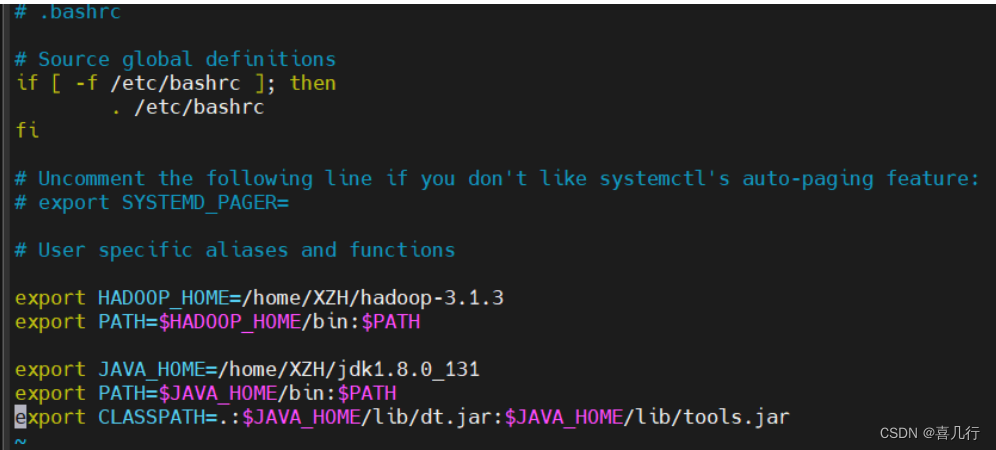
export HADOOP_HOME=/home/username/hadoop-3.1.3
export PATH=$HADOOP_HOME/bin:$PATH
export JAVA_HOME=/home/username/jdk1.8.0_131
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
如图所示我的就是配成这样的
其中HADOOP_HOME和JAVA_HOME 就是你解压之后的文件夹的路径,其他的都是一样的
刷新使其生效
source .bashrc
输入下列语句检测是否配置成功
java -version
hadoop verison
[XZH@westgisB040 ~]$ java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
[XZH@westgisB040 ~]$ hadoop version
Hadoop 3.1.3
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiled with protoc 2.5.0
From source with checksum ec785077c385118ac91aadde5ec9799
This command was run using /home/XZH/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar
横向配置
进入
cd hadoop-3.1.3/etc/hadoop
修改四个配置文件,分别在给四个配置文件中增加以下内容
vi core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://IP:8020</value>
</property>
</configuration>
IP为主节点ip地址

vi hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>/home/username/namenode</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/home/username/datanode</value>
</property>
</configuration>

vi hadoop-env.sh
export JAVA_HOME=/home/username/jdk1.8.0_131
export HADOOP_IDENT_STRING=$USER

vi workers
westgisB041
westgisB042
westgisB043
westgisB044
注意!!!要删去原来的localhost不然主节点也会变成一个从节点
复制主节点配置到所有从节点
(其实这一步可以写脚本会更快一些)即要将./bashsc,hadoop-3.1.3,jdk1.8.0_131,全部传输到所有从节点上
传输之前请确保配置文件没出错!!!!!!!!最好别自己打,复制,不然就是要好好检查清楚,如果出错后面配置不成功会很麻烦
[XZH@westgisB040 ~]$ scp .bashrc [email protected]:/home/XZH
[XZH@westgisB040 ~]$ scp .bashrc [email protected]:/home/XZH
[XZH@westgisB040 ~]$ scp .bashrc [email protected]:/home/XZH
[XZH@westgisB040 ~]$ scp .bashrc [email protected]:/home/XZH
[XZH@westgisB040 ~]$ scp -r hadoop-3.1.3 [email protected]:/home/XZH
[XZH@westgisB040 ~]$ scp -r hadoop-3.1.3 [email protected]:/home/XZH
[XZH@westgisB040 ~]$ scp -r hadoop-3.1.3 [email protected]:/home/XZH
[XZH@westgisB040 ~]$ scp -r hadoop-3.1.3 [email protected]:/home/XZH
[XZH@westgisB040 ~]$ scp -r jdk1.8.0_131/ [email protected]:/home/XZH
[XZH@westgisB040 ~]$ scp -r jdk1.8.0_131/ [email protected]:/home/XZH
[XZH@westgisB040 ~]$ scp -r jdk1.8.0_131/ [email protected]:/home/XZH
[XZH@westgisB040 ~]$ scp -r jdk1.8.0_131/ [email protected]:/home/XZH
在每个从节点上执行./bashrc文件
[XZH@westgisB040 ~]$ ssh [email protected] source .bashrc
[XZH@westgisB040 ~]$ ssh [email protected] source .bashrc
[XZH@westgisB040 ~]$ ssh [email protected] source .bashrc
[XZH@westgisB040 ~]$ ssh [email protected] source .bashrc
执行完后每个从节点上应该已经有java和hadoop的版本显示了
[XZH@westgisB040 ~]$ ssh XZH@10.103.105.41 java -version
java version "1.8.0_131"
Java(TM) SE Runtime Environment (build 1.8.0_131-b11)
Java HotSpot(TM) 64-Bit Server VM (build 25.131-b11, mixed mode)
[XZH@westgisB040 ~]$ ssh XZH@10.103.105.41 hadoop version
Hadoop 3.1.3
Source code repository https://gitbox.apache.org/repos/asf/hadoop.git -r ba631c436b806728f8ec2f54ab1e289526c90579
Compiled by ztang on 2019-09-12T02:47Z
Compiled with protoc 2.5.0
From source with checksum ec785077c385118ac91aadde5ec9799
This command was run using /home/XZH/hadoop-3.1.3/share/hadoop/common/hadoop-common-3.1.3.jar
集群初始化与启动
格式化HDFS
注意只能格式一次!!!如果多次格式化要找主节点的VERSION中的clusterid和从节点的对应
hadoop namenode -format
启动HDFS
$HADOOP_HOME/sbin/start-dfs.sh
检查节点进程
jps
正常的应该是namenode下只有namenode、secondarynamenode,jps
datanode下只有datanode,jps
启动hadoop后如果可以打开https://主节点ip地址:9870网页则证明配置成功

停止hadoop
$HADOOP_HOME/sbin/stop-dfs.sh
如果是多人使用同一集群,要确保自己开启hadoop时其他人没有开启,如果此时其他人开启的话,你是打不开的。
常见错误包括配置文件错误,多次格式化等,详细解决方法在另一篇文章中记录。
版权归原作者 喜几行 所有, 如有侵权,请联系我们删除。