
Hadoop运行模式主要包括三种:本地模式、伪分布式模式以及完全分布式模式。
1. 本地模式(Local/Standalone Mode):在这种模式下,Hadoop作为一个独立的系统运行,不依赖于外部资源或网络连接。它可以在单个服务器上运行,数据通常存储在本地的HDFS(Hadoop Distributed FileSystem)上。这种模式适合用于学习和开发阶段的调试,因为它不需要额外的配置和管理。
2. 伪分布式模式(Pseudo-Distributed Mode):在这种模式下,Hadoop仍然是一个独立的系统,但它通过模拟分布式环境的各个组件来运行。这意味着数据会被存储在HDFS上,但是所有的工作流程都在单台服务器上完成,即没有真正的分布式处理能力。伪分布式模式常用于小型的测试环境。
3. 完全分布式模式(Fully-Distributed Mode):这是Hadoop最常用的模式,它涉及到多台服务器组成的集群,每个服务器负责特定的任务。在这种模式下,数据被分散存储在HDFS上,而且不同节点的任务之间可以进行通信。完全分布式模式适用于大规模数据处理和高并发请求的场景。
本地模式单机运行,只是用来简单演示一下官方案例,生产环境不用。伪分布模式也是单机运行,但是具备Hadoop集群的所有功能,一台服务器模拟一个分布式的环境。
本篇文章我们给大家介绍一下本地模式如何使用。我们来演示一下官方的WordCount例子。
1. 安装Hadoop
(1)下载Hadoop安装包
第一种方法是从Hadoop的官网去下载,可能网速比较慢。
第二种方法从国内的镜像源进行下载。我一般从清华大学镜像源去下载。(Hadoop清华大学镜像源内下载地址)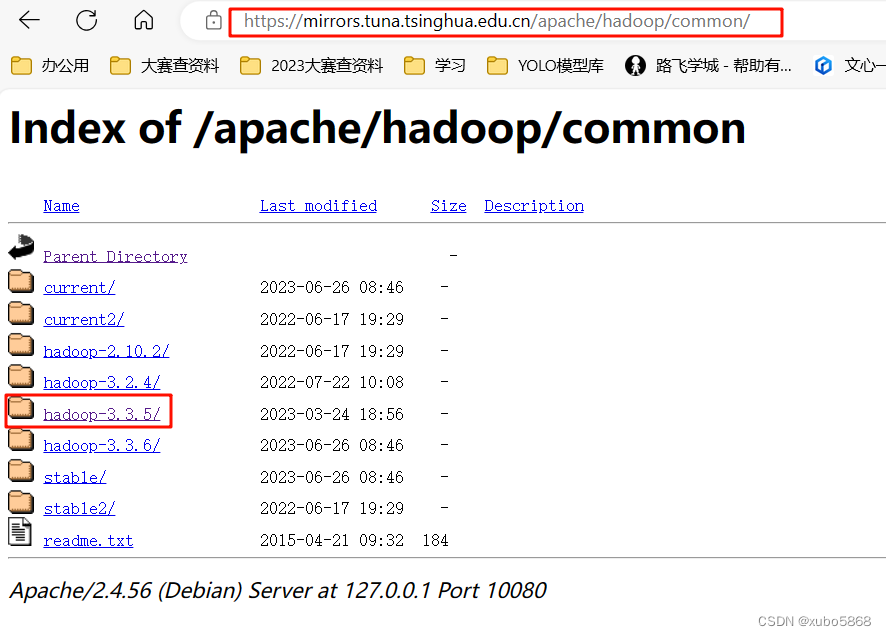
选择3.3.5版本进行下载。
(2)上传Hadoop安装包并解压
下载后通过mobaXterm上传至bigdata01节点上的/opt/software路径下。然后通过下面命令进行解压到/opt/module路径下,并进行重命名为hadoop_local。
tar -zxvf hadoop-3.3.5.tar.gz -C /opt/module/
cd /opt/module
cp -r hadoop-3.3.5/ hadoop-local

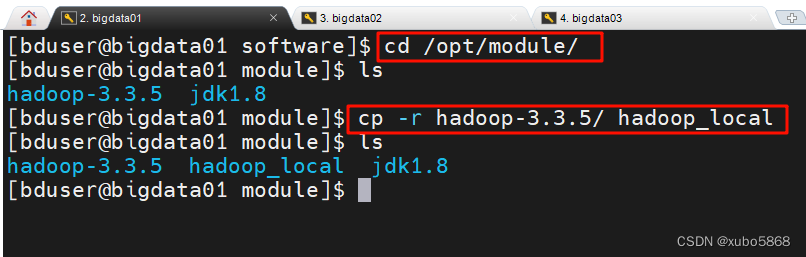
因为我们分别演示三种不同模式,所以,我们将hadoop的解压包分别复制成三种不同的文件夹。
(3)将hadoop添加到环境变量(bigdata_env.sh)
sudovim /etc/profile.d/bigdata_env.sh
在bigdata_env.sh中添加下面的内容。
#HADOOPexportHADOOP_HOME=/opt/module/hadoop_local
exportPATH=$PATH:$HADOOP_HOME/bin
然后使环境变量生效。
source /etc/profile

(4)测试是否安装成功
hadoop version
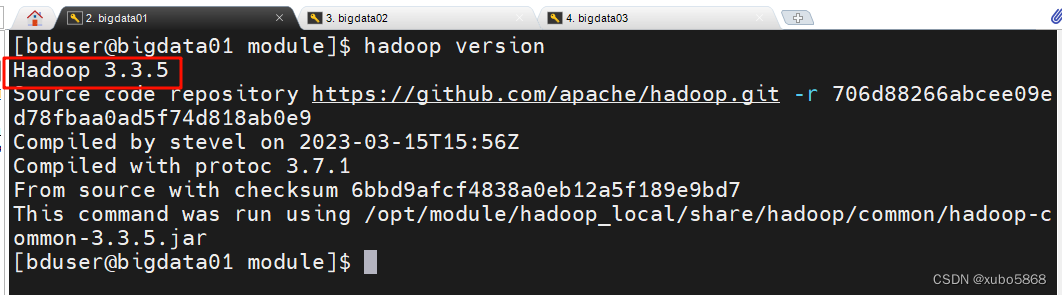
2.本地运行模式
(1)在hadoop_local路径下创建一个wcinput文件夹
[bduser@bigdata01 hadoop_local]$ mkdir wcinput
(2)在wcinput文件夹下创建一个word.txt文件
[bduser@bigdata01 hadoop_local]$ cd wcinput
[bduser@bigdata01 wcinput]$ touch word.txt
(3)编辑word.txt文件
[bduser@bigdata01 wcinput]$ vim word.txt
在word文件中输入以下内容:
hadoop yarn
hadoop mapreduce
hello world
hello java
hello spark
(4)返回到目录/opt/module/hadoop_local
(5)执行程序
[bduser@bigdata01 hadoop_local]$ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-3.3.5.jar
wordcount wcinput wcoutput
(6)查看结果
[bduser@bigdata01 hadoop_local]$ cat wcoutput/part-r-00000
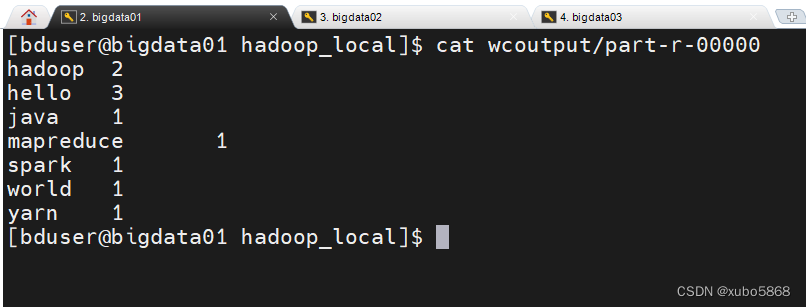
至此Hadoop的本地模式演示完成。
版权归原作者 努力奋斗的守望者 所有, 如有侵权,请联系我们删除。