
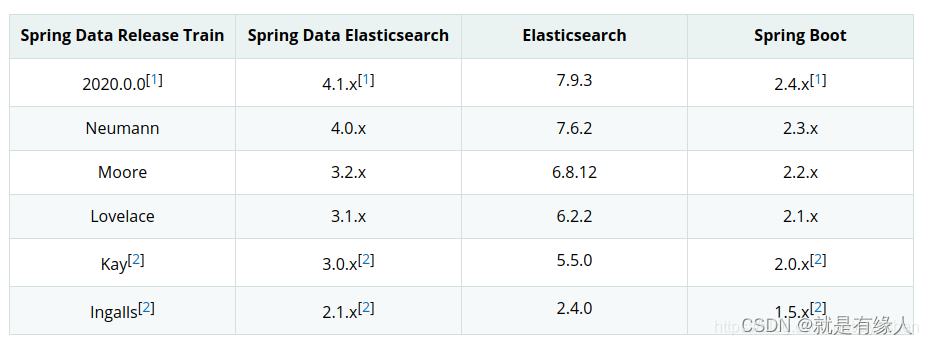
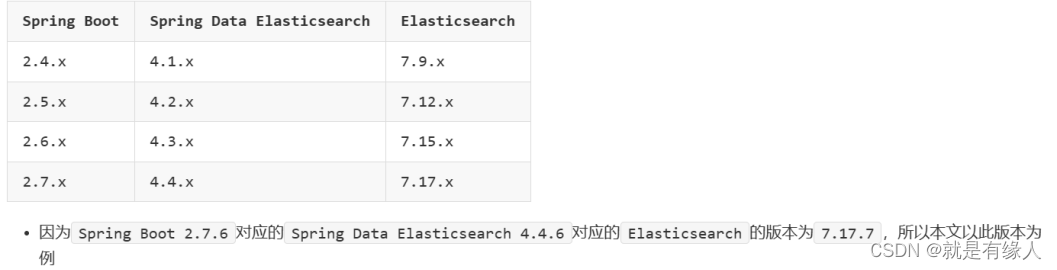
一、版本对应关系****
(具有指导价值,但版本对应存在很高容错率)
1.Elasticsearch 7.6.2 SpringBoot2.5.6 (实现)
2.Elasticsearch 7.17.3 SpringBoot2.7.5 (实现)
二、Elasticsearch安装步骤****
****参考网址:****https://blog.csdn.net/weixin_42633131/article/details/82902812
三、SpringBoot项目集成Elasticsearch
*1.pom所需依赖*
pom.xml
<!--ES核心依赖-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<!--配置客户端需要的依赖,不存在添加,存在不添加-->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<!--若不需要Tomcat,则只需要依赖spring-web-->
<!--<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-web</artifactId>
</dependency>-->
2.application项目配置文件
application.yml
# yml配置elasticsearch客户端地址(可配置项有限)
spring:
elasticsearch:
uris: http://127.0.0.1:9200 # elasticsearch 连接地址
#username: elastic # 用户名
#password: 123456 # 密码
connection-timeout: 10s # 连接超时时间(默认1s)
socket-timeout: 30s # 数据读取超时时间(默认30s)
3.项目实体映射
package com.nengyy.rest_server.elasticsearch.entity;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import lombok.experimental.Accessors;
import org.springframework.data.annotation.Id;
import org.springframework.data.elasticsearch.annotations.Document;
import org.springframework.data.elasticsearch.annotations.Field;
import org.springframework.data.elasticsearch.annotations.FieldType;
import java.io.Serializable;
import java.math.BigDecimal;
import java.util.Objects;
@Data
@Accessors(chain = true) // 支持链式set赋值功能
@AllArgsConstructor // 自动生成包含全部参数的构造方法
@NoArgsConstructor // 自动生成无参构造方法
// @Document是SpringDataES标记实体类的注解
// indexName指定关联的索引名称,运行时如果items索引不存在,SpringData会自动将它创建出来
@Document(indexName = "items")
public class ItemEfm implements Serializable {
// SpringData标记当前属性为ES的主键
@Id //ES本条数据ID(只能为long类型等转化为的String类型,不能出现数字之外的字母或汉字)(暂未研究解决方法)
private Long id; //想用ES自带增删改查方法,此id需要为Long类型
// SpringData标记title属性是text类型支持分词的,以及分词器
@Field(type = FieldType.Keyword)
private String GoodsId;
@Field(type = FieldType.Text, //生成索引时使用 ik_max_word,在搜索时用ik_smart
analyzer = "ik_max_word", //最细粒度拆分-->(字会重复被使用)(生成索引时,进行分词使用)
searchAnalyzer = "ik_smart") //最粗粒度拆分-->智能拆分(字不会被重复使用)(搜索时,对搜索词进行分词)
private String title; // 商品描述
// Keyword类型是不需要分词的字符串类型
@Field(type = FieldType.Keyword)
private String category; // 商品分类
@Field(type = FieldType.Keyword)
private String brand; // 品牌(商品描述备用字段)(此字段用来做全称查询,用来补充分词查询的不足)
@Field(type = FieldType.Keyword)
private String price; // 价格
@Field(type = FieldType.Keyword)
private String origPrice; // 原价
// 图片地址不会成为搜索条件,所以设置index = false
// 这样ES就不会为它创建索引库了,能够节省空间
@Field(type = FieldType.Keyword,index = false)
private String imgPath; // 图片地址
// images/1a123s-as4td-asdsa-jasbdjff.png
@Field(type = FieldType.Keyword)
private String intertestNum;//关注人数
//重写equals,用于contains判断,非必要不会用到
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (obj == null || getClass() != obj.getClass()) return false;
ItemEfm other = (ItemEfm) obj;
return Objects.equals(GoodsId, other.GoodsId) &&
Objects.equals(title, other.title) &&
Objects.equals(price, other.price) &&
Objects.equals(origPrice, other.origPrice) &&
Objects.equals(imgPath, other.imgPath) &&
Objects.equals(intertestNum, other.intertestNum);
}
@Override
public int hashCode() {
return Objects.hash(GoodsId, title, price, origPrice, imgPath, intertestNum);
}
}
4.持久层接口
解析:持久层ItemRepository 接口继承extends ElasticsearchRepository 后,可以实现和MybatisPlus等同的作用
package com.nengyy.rest_server.elasticsearch.repository;
import com.nengyy.rest_server.elasticsearch.entity.ItemEfm;
import org.springframework.data.domain.Page;
import org.springframework.data.domain.Pageable;
import org.springframework.data.elasticsearch.repository.ElasticsearchRepository;
import org.springframework.stereotype.Repository;
import java.util.List;
// Spring 家族持久层命名规范为repository
@Repository
public interface ItemRepository extends ElasticsearchRepository<ItemEfm,Long>{
// 当前ItemRepository接口可以继承SpringDataElasticsearch框架提供的父接口ElasticsearchRepository
// 一旦继承,效果是会为指定的实体类自动生成基本的增删改查方法
// ElasticsearchRepository<[关联的实体类名],[实体类主键类型]>
// SpringData自定义查询
// 遵循SpringData框架给定的格式,编写方法名称,就可以自动生成查询语句
// query(查询): 表示当前方法是一个查询方法,类似sql中的select
// Item\Items: 表示要查询的实体类,不带s返回单个对象,带s返回集合类型
// By(通过): 标识开始设置条件的关键词,类似sql中的where
// Title: 要查询的字段名称
// Matches: 执行的查询操作,Matches表示执行查询支持分词的字符串 类似sql中的like
Iterable<ItemEfm> queryItemsByTitleMatches(String title);
// 四.es详细分词查询(多条件查询and)
// 多条件查询
// 多个条件之间需要使用逻辑运算符And或Or来分割
// 方法参数赋值的依据是根据方法名称中参数的顺序来决定的(参数不能乱取名字,title,brand)
Iterable<ItemEfm> queryItemsByTitleMatchesAndBrandMatches(String title, String brand);
// 四.es详细分词查询(多条件排序查询or)
// query、By、Matches、Or、OrderBy、Desc(倒序):均为关键字
// Items :实体映射名字(也是此实体对应es其中一个索引库的名字)
// Title、Brand :需要根据什么字段进行查询
// Price :配合OrderBy、Desc意思是根据价格倒序
Iterable<ItemEfm> queryItemsByTitleMatchesOrBrandMatchesOrderByPriceDesc(String title,String brand);
// 一.全称查询(多写一个字段,对其设置FieldType.Keyword, 如此此字段就是不分词的全称索引)
ItemEfm findByBrand(String brand);
// 二.es精确分词查询(全称+分词+模糊三种查询合一)(精确查询,前端传参的分词与后端索引,必须全部匹配到才能查询到)
org.springframework.data.domain.Page<ItemEfm> findByTitleOrderByIntertestNumDesc(String title,Pageable pageable);
// 三.分页查询+分词查询--->分词查询(传参和索引都会进行分词,然后进行一一匹配,并通过自带算法做好排序)(自己也可以设置排序) (前端传参的分词与后端索引,只要能匹配到一个就能查询出来)
// 实现分页查询:最后一个参数的位置添加声明类型Pageable的变量
// 返回值修改为Page类型,这个类型的对象不但能够保存查询出的数据,而且还能自动计算出分页信息
// 分页信息中包括:当前页,总页数,总条数,是否有上一页或下一页等
Page<ItemEfm> queryItemsByTitleMatchesOrBrandMatchesOrderByIntertestNumDesc(
String title,String brand,Pageable pageable);
List<ItemEfm> queryItemsByTitleMatchesOrBrandMatchesOrderByOrigPriceDesc(String title,String brand);
}
5.业务逻辑层实现类
package com.nengyy.rest_server.service.impl.mall;
import com.baomidou.mybatisplus.core.metadata.IPage;
import com.baomidou.mybatisplus.extension.plugins.pagination.Page;
import com.nengyy.dao_mysql.common.utils.PageUtil;
import com.nengyy.dao_mysql.mapper.primary.mall.CommodityListMapper;
import com.nengyy.dem_common.utils.ListUtils;
import com.nengyy.dem_common.utils.StringUtils;
import com.nengyy.dto.mall.*;
import com.nengyy.rest_server.elasticsearch.entity.ItemEfm;
import com.nengyy.rest_server.elasticsearch.repository.ItemRepository;
import com.nengyy.rest_server.service.impl.consignment.DatacenterIdGenerator;
import com.nengyy.rest_server.service.mall.ItemRepositoryService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.data.domain.PageRequest;
import org.springframework.stereotype.Service;
import java.util.*;
/**
* @Author: cyz
* @Date: 2023/04/24
* @Description:
*/
@Service
public class ItemRepositoryServiceImpl implements ItemRepositoryService {
private final ItemRepository itemRepository;
private final CommodityListMapper commodityListMapper;
@Autowired
public ItemRepositoryServiceImpl(ItemRepository itemRepository, CommodityListMapper commodityListMapper) {
this.itemRepository = itemRepository;
this.commodityListMapper = commodityListMapper;
}
/**从数据库查出所有符合条件的商品 , 每天定时进行es索引的刷新*/
@Override
public String goodsList() {
List<ESCommodityListDto> data = commodityListMapper.getGoodsList();
List<ItemEfm> list = new ArrayList<>();
DatacenterIdGenerator snowId1 = new DatacenterIdGenerator(17,18);//获取雪花算法ID
ItemEfm item;
if(data != null){
for (ESCommodityListDto listDto:data) {
if("2".equals(listDto.getGoodsSource())){
item = new ItemEfm();
item.setId(snowId1.nextId());
item.setGoodsId(listDto.getGoodsId());
item.setTitle(listDto.getGoodsDesc());
item.setCategory(listDto.getGoodsType());
item.setBrand(listDto.getGoodsDesc()); //此字段用来做全称查询,用来补充分词查询的不足
item.setPrice(listDto.getGoodsFee());
item.setOrigPrice(listDto.getReservFee1());
item.setImgPath(listDto.getFilePath());
item.setIntertestNum(listDto.getIntertestNum());
list.add(item);
}else{
item = new ItemEfm();
item.setId(snowId1.nextId());
item.setGoodsId(listDto.getGoodsId());
item.setTitle(listDto.getGoodsName());
item.setCategory(listDto.getGoodsType());
item.setBrand(listDto.getGoodsName()); //此字段用来做全称查询,用来补充分词查询的不足
item.setPrice(listDto.getGoodsFee());
item.setOrigPrice(listDto.getReservFee1());
item.setImgPath(listDto.getFilePath());
item.setIntertestNum(listDto.getIntertestNum());
list.add(item);
}
}
//先删除之前存的索引(批量删)
itemRepository.deleteAll();
//添加新的索引 (批量加)
itemRepository.saveAll(list);
}
return "成功";
}
/**
* Es搜索出的商品(分页获取商品列表)
* @param in
* @return
*/
@Override
public Page<CommodityListDto> searchCommodityList(SiftEsCommodityListDto in) {
//一.全称查询(不分词查询)
ItemEfm oneGoods = itemRepository.findByBrand(in.getGoodsDesc());
//二.es精确分词查询(全称+分词+模糊三种查询合一)(精确查询,前端传参的分词与后端索引,必须全部匹配到才能查询到)
org.springframework.data.domain.Page<ItemEfm> pageGoodsList = itemRepository.findByTitleOrderByIntertestNumDesc(in.getGoodsDesc(),PageRequest.of(0, 49));
//三.分页查(非精确分词查询)(前端传参的分词与后端索引,只要能匹配到一个就能查询出来)
int size = in.getPageSize() - pageSizeExtra;
int size1 = size >=0 ? size :1;
org.springframework.data.domain.Page<ItemEfm> page = itemRepository
.queryItemsByTitleMatchesOrBrandMatchesOrderByIntertestNumDesc( //通过商品描述和商品品牌(暂定传值为空)进行查询并通过关注人数进行排序
in.getGoodsDesc(),"",PageRequest.of(in.getPageNo() - 1, size1));
}
6.自定义查询方法****
Spring Data根据方法名称自动实现功能: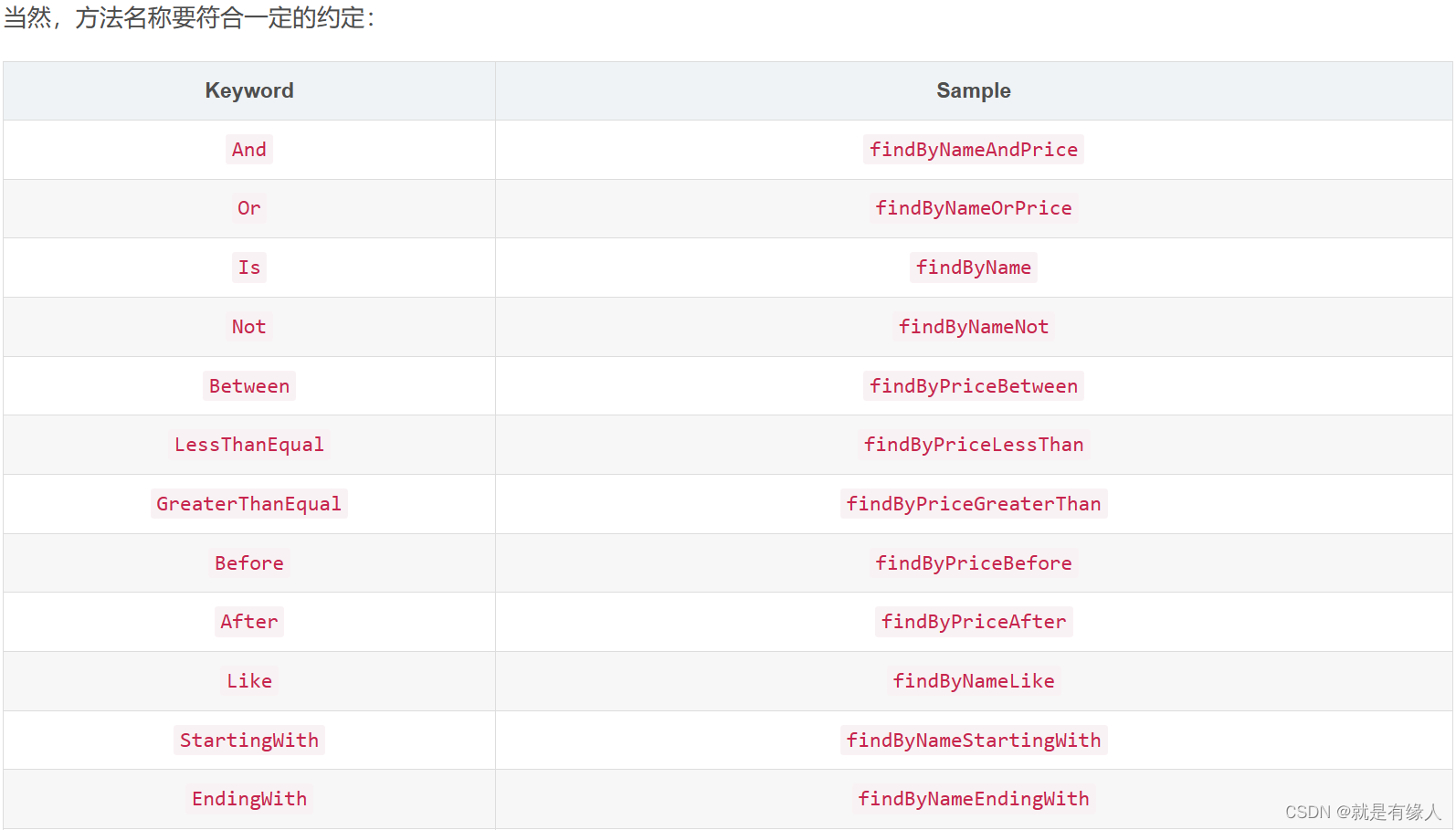
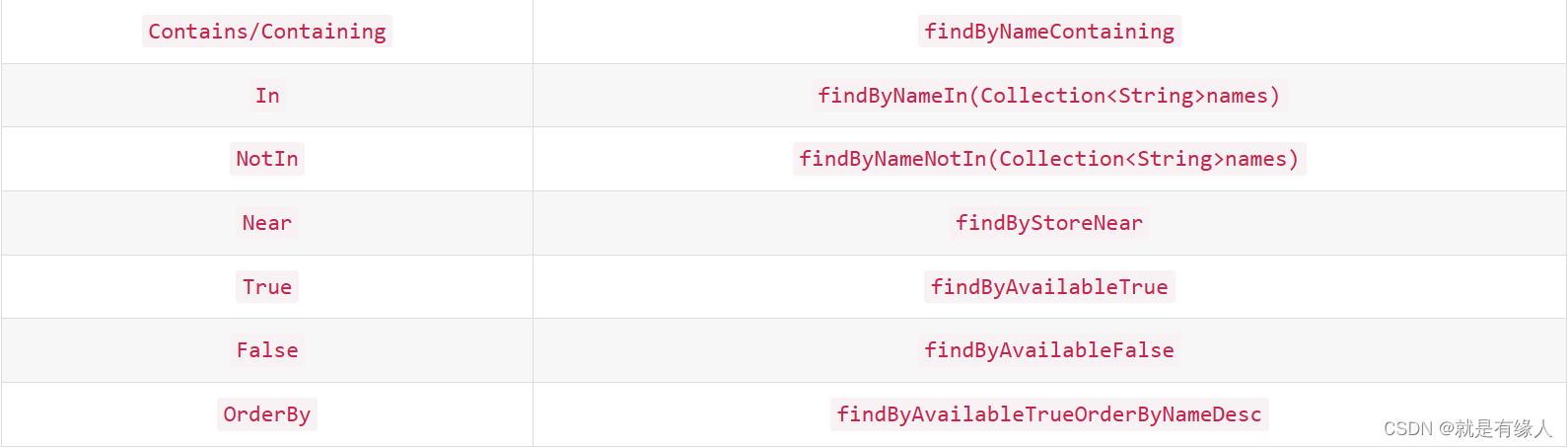
查询方式两种:query(详细查询)与find(精确查询)
// 四.es详细分词查询(多条件排序查询or)
// query、By、Matches、Or、OrderBy、Desc(倒序):均为关键字 // Items :实体映射名字(也是此实体对应es其中一个索引库的名字) // Title、Brand :需要根据什么字段进行查询 // Price :配合OrderBy、Desc意思是根据价格倒序 //黑色和蓝色均为关键字 实体映射名 根据哪个字段查询 根据哪个字段倒序Iterable<ItemEfm> queryItemsByTitleMatchesOrBrandMatchesOrderByPriceDesc(String title,String brand);
// 二.es精确分词查询(全称+分词+模糊三种查询合一)(精确查询,前端传参的分词与后端索引,必须全部匹配到才能查询到)
org.springframework.data.domain.Page<ItemEfm> findByTitleOrderByIntertestNumDesc(String title,Pageable pageable);// 三.分页查询+分词查询--->分词查询(传参和索引都会进行分词,然后进行一一匹配,并通过自带算法做好排序)(自己也可以设置排序) (前端传参的分词与后端索引,只要能匹配到一个就能查询出来)
// 实现分页查询:最后一个参数的位置添加声明类型Pageable的变量
// 返回值修改为Page类型,这个类型的对象不但能够保存查询出的数据,而且还能自动计算出分页信息
// 分页信息中包括:当前页,总页数,总条数,是否有上一页或下一页等
Page<ItemEfm> queryItemsByTitleMatchesOrBrandMatchesOrderByIntertestNumDesc( String title,String brand,Pageable pageable);
7.有可能出现的错误
1.-问题:Elasticsearch 与Spring Data与Lucene 等存在版本冲突


2.-解决方法:添加指定版本的lucene依赖而不使用默认的Elasticsearch自带的lucene
可以通过chatGpt自行问****Elasticsearch不同版本对应的lucene版本
<dependency></dependency><groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>8.11.1</version>

3.-实体映射Document注解规则
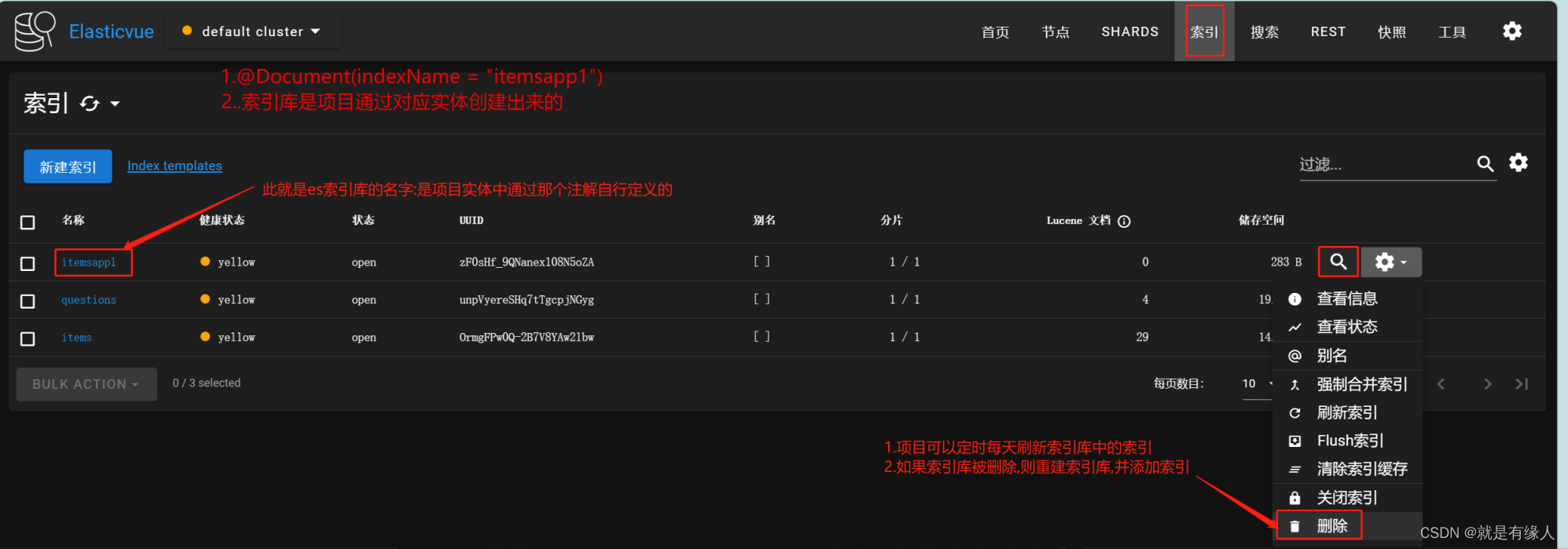
@Document(indexName = "itemsapp1")
//其中itemsapp1是自定义的索引库的库名,es中有很多的索引库,是项目通过不同实体创建的索引库

4.-删除Elasticsearch索引库
解释:(删除索引后,重启项目,调用刷新索引项目可以重建索引库)
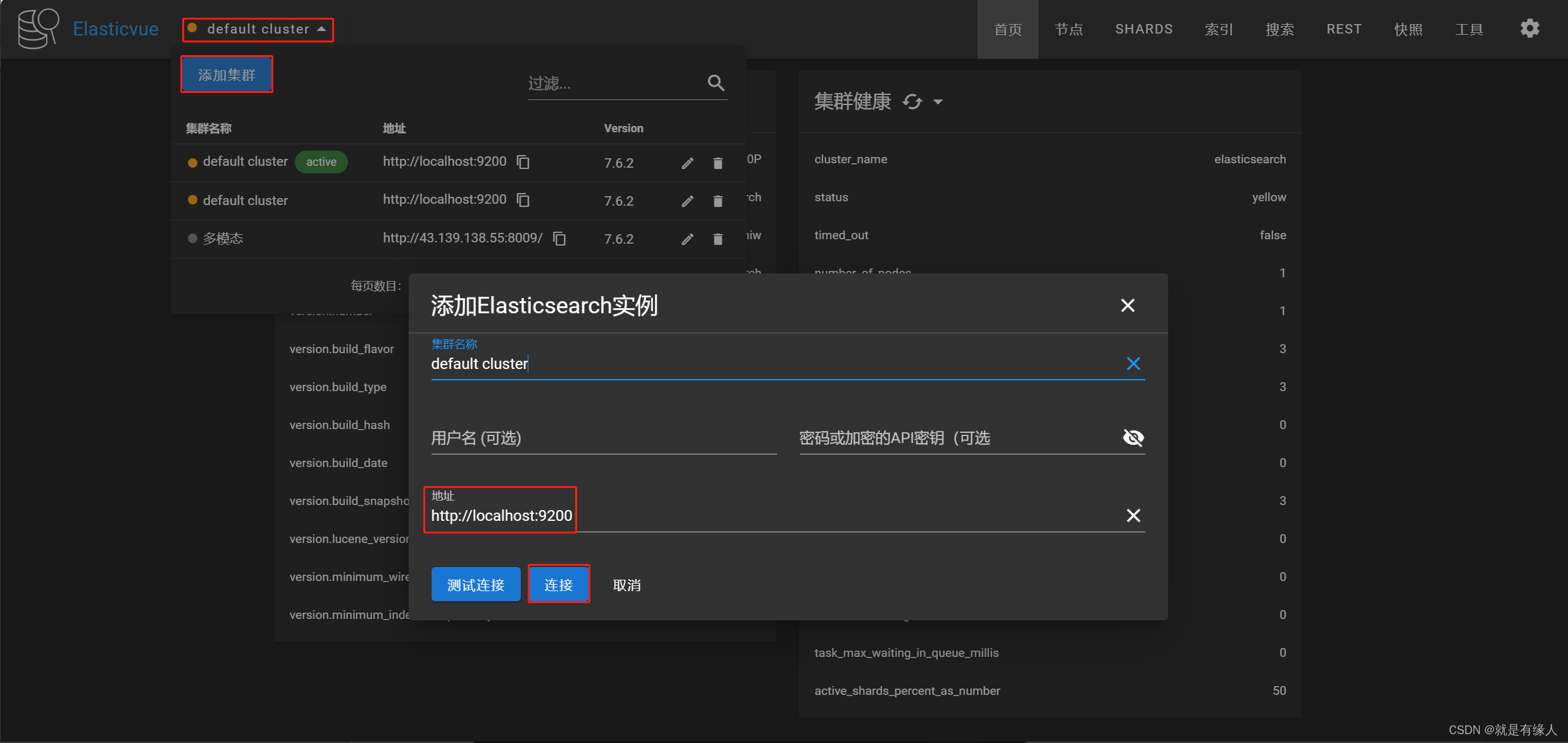
解决方法:1.想删除Elasticsearch索引库,可以使用es的可视化工具
2.Elasticvue -(es的可视化工具)用于浏览器的免费开源 Elasticsearch GUI
****Elasticvue安装步骤网址:****https://blog.csdn.net/UbuntuTouch/article/details/125777834
3.利用Elasticvue连接上Elasticsearch

四、Elasticsearch与ik分词器---用法
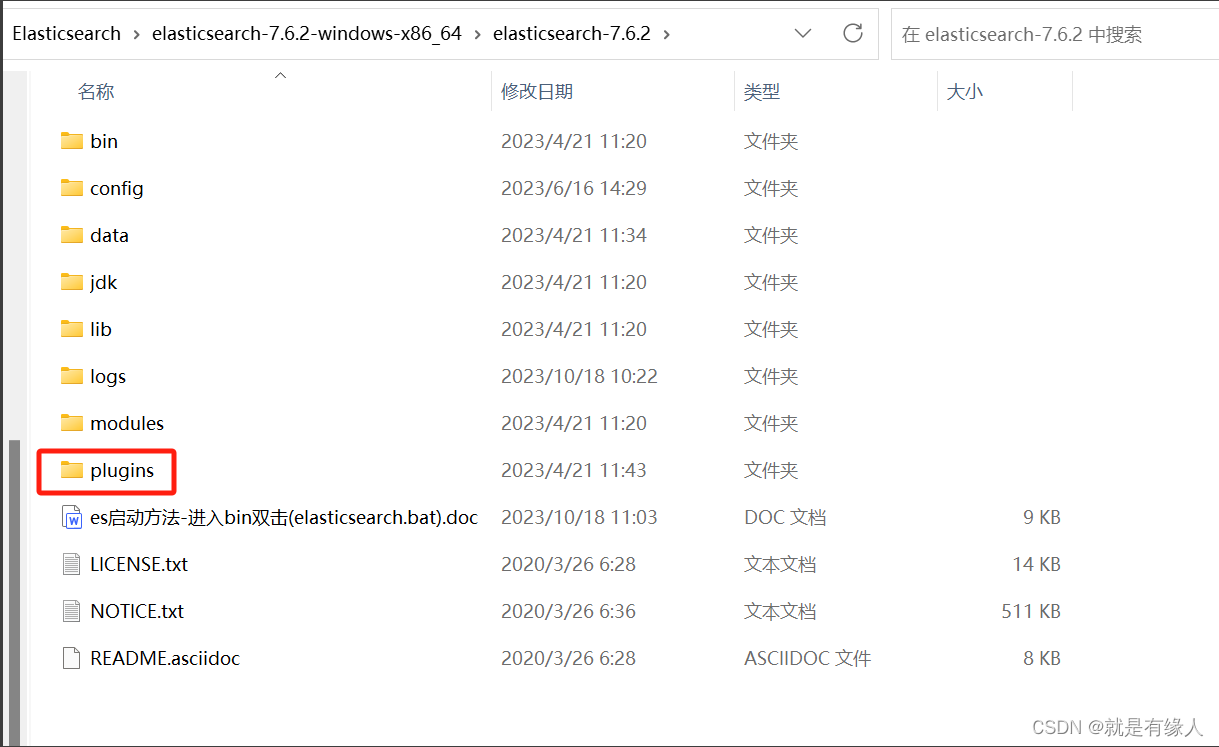
1.给Elasticsearch添加ik分词器
--Ik下载网址: https://github.com/medcl/elasticsearch-analysis-ik/releases
--参考ik详解网址:【精选】ElasticSearch——IK分词器的下载及使用_ik分词器下载-CSDN博客
--将解压的ik分词器改名为ik,放到plugins目录下即可(下之前百度查自己es对应版本的ik,容错率挺高的)
2.java项目直接测试分词效果
1.案例代码
三个#既是分隔符也是注释,两个请求之间必须使用它来分割,否则无法运行
POST http://localhost:9200/_analyze
Content-Type: application/json
{
"text": "绿色冰种手镯",
"analyzer": "ik_smart"
}
2.创建一个demo案例
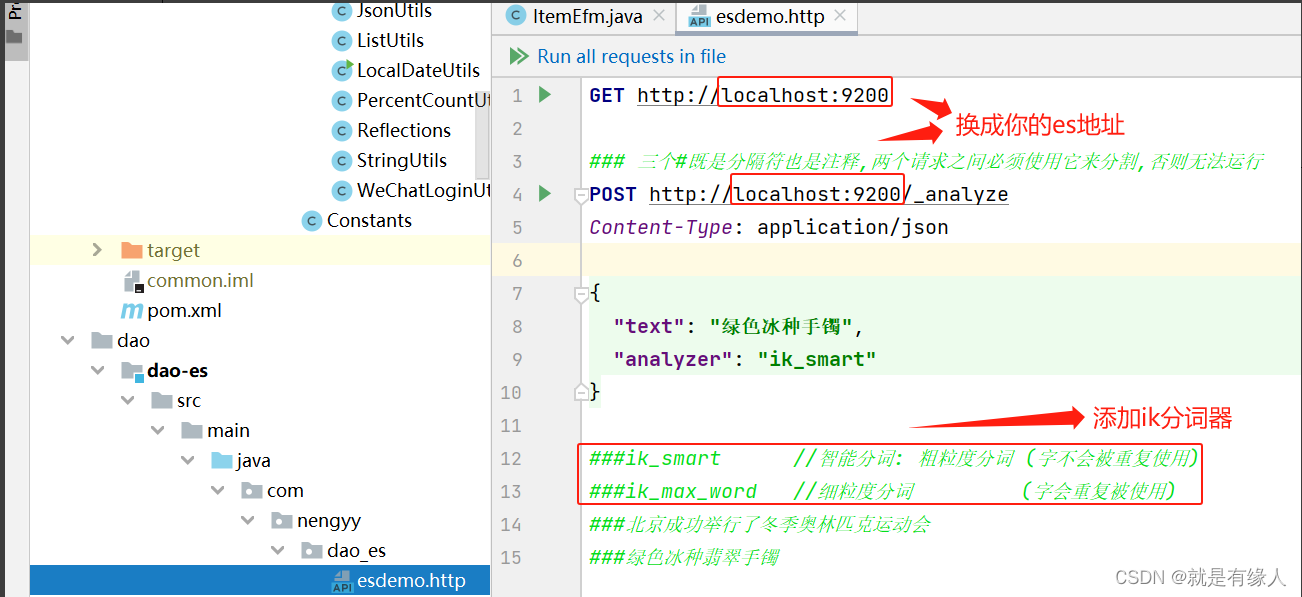
3.Es启动后,直接点击启动就可以测试
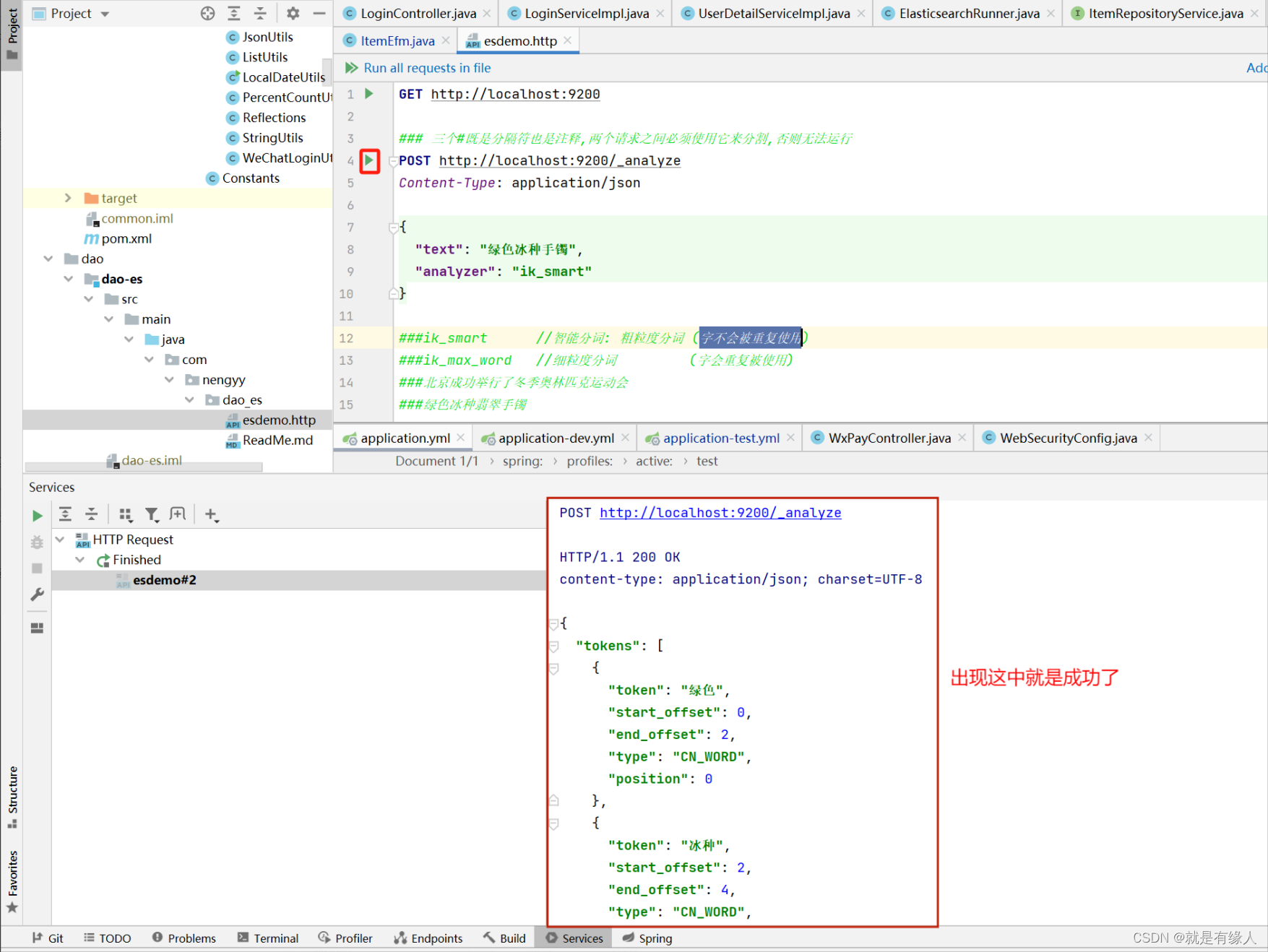
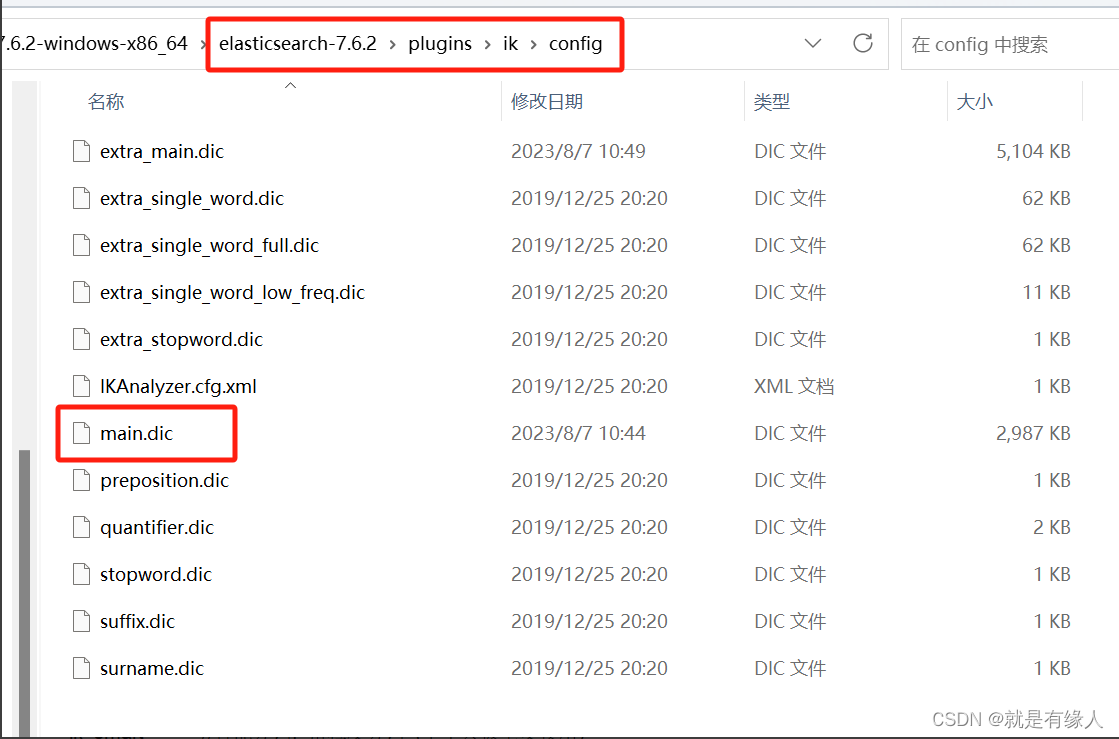
3.自定义一些词不让其进行分词
1.直接用记事本打开main.dic,在里面添加不想进行分词的词语
2.ik_smart和ik_max_word两种分词不同
ik_smart //智能分词: 粗粒度分词 (字不会被重复使用)
ik_max_word //细粒度分词 (字会重复被使用)
项目实体建议:@Field(type = FieldType.Text, //生成索引时使用 ik_max_word,在搜索时(对前端传递来的参数分词)用ik_smart analyzer = "ik_max_word", //最细粒度拆分-->(字会重复被使用)(生成索引时,进行分词使用) searchAnalyzer = "ik_smart") //最粗粒度拆分-->智能拆分(字不会被重复使用)(搜索时,对搜索词进行分词) private String title; // 商品描述
版权归原作者 就是有缘人 所有, 如有侵权,请联系我们删除。