
sqoop数据同步——问题与解决方案
1、sqoop导出oracle数据,数据源无法选择表空间,只能指定默认表空间的表。
- 方案:不指定数据源的表名,而是使用–query,利用sql语句把数据带出来。 例:
--query "SELECT REQUESTID, WORKFLOWID, LASTNODEID, LASTNODETYPE FROM ECOLOGY.WORKFLOW_REQUESTBASE WHERE \$CONDITIONS" - 注意点: –table 是直接导出表中所有数据列,导入hive时,字段名字不会相匹配,只会按照顺序导入,所以这种导入方式要注意hive的建表语句中字段顺序应与原表一致。 –query 是sql抽取出数据列,数据可以来自不同表,也可以转换/计算。这种导入方式抽取的数据列会与hive中的字段名匹配,所以当sql进行数据计算时,取别名一定要与hive字段名匹配,否则不匹配的字段将会是NULL。 注:sqoop1.4.6不支持–query和–as-parquetfile同时使用,但是sqoop1.4.7支持。
2、sqoop导出oracle数据,数据源的表字段中有CLOB类型,导致数据类型转换失败报错:ERROR tool.ImportTool: Import failed: Cannot convert SQL type 2005。
- 方案1:利用–query将数据列抽取出来,同时对CLOB类型的数据做类型转换。 例:
--query "SELECT ID, FLMC, CAST(FLFZR as VARCHAR2(10))FLFZR, FKFSJQX FROM ECOLOGY.UF_XDF WHERE \$CONDITIONS"注:但是这种方案一定要保证转换成VARCHAR2类型的字符串的长度一定要够长,否则转换完的数据还是错的。 - 方案2:导入hive前,利用–map-column-java对指定数据列做数据类型的转换。(推荐使用) 例:
--map-column-java HRMIDS=String
3、sqoop导出oracle数据,指定非默认表空间时,报错:INFO mapreduce.Job: Task Id : attempt_1472465929944_0013_m_000000_0, Status : FAILED Error: Java heap space。
- 方案:sqoop开启时指定参数:mapreduce.map.java.opts和mapreduce.map.memory.mb 例:
-Dmapreduce.map.java.opts=-Xmx3600m -Dmapreduce.map.memory.mb=4000个人推断时表字段过多造成的内存溢出,可以断定与数据的条数无关。 - 注意点: 这两个都是Map Memory的指定参数,mapreduce.map.memory.mb(map的运行内存大小)与Yarn的内存大小有关,Yarn内存默认为4G,所以设定mapreduce.map.memory.mb=4000;mapreduce.map.java.opts(JVM 堆大小)应小于mapreduce的运行内存大小,因为要预留内存空间用于存储java代码。
4、sqoop导出oracle数据,数据源数据时间数据类型:timestamp,hive端数据类型默认转换为:bigint的时间戳格式。
- 方案:利用–query,在数据导出时将数据类型转换为varchar字符串类型。 例:
--query "SELECT FCREATORID, TO_CHAR(FCREATETIME,'yyyy-MM-dd HH24:mi:ss')FCREATETIME, FLASTUPDATEUSERID, TO_CHAR(FLASTUPDATETIME,'yyyy-MM-dd HH24:mi:ss')FLASTUPDATETIME, CFISFEEDCONUT FROM LIHUA.CT_BRL_PIGSIYANG WHERE \$CONDITIONS"
5、sqoop导出oracle数据,导入hive,但hive表不存在,依旧显示导入成功任务,以后需注意,导入任务结束后最好再确认一下。
- sqoop命令:
sqoop import --connect ${rdbms_connstr} \
--username ${rdbms_username} \
--password ${rdbms_pwd} \
--query "SELECT FCREATORID, TO_CHAR(FCREATETIME,'yyyy-MM-dd HH24:mi:ss')FCREATETIME, FLASTUPDATEUSERID, TO_CHAR(FLASTUPDATETIME,'yyyy-MM-dd HH24:mi:ss')FLASTUPDATETIME, FCONTROLUNITID, FNUMBER, TO_CHAR(FBIZDATE,'yyyy-MM-dd HH24:mi:ss')FBIZDATE, FHANDLERID, FDESCRIPTION, FHASEFFECTED, FAUDITORID, FSOURCEBILLID, FSOURCEFUNCTION, FID, FFIVOUCHERED, CFORGUNITID, CFISFEEDCOUNT, CFAUDITUSERID, CFIFAUDITING FROM LIHUA.CT_PIG_INTEGRATIONSIYANG WHERE \$CONDITIONS" \
--hive-overwrite \
--hive-database ${hive_database} \
--hive-table ${hive_table} \
--delete-target-dir \
--target-dir/db/${hive_database}/${hive_table} \
--fields-terminated-by "\001" \
--as-parquetfile \
--m 1
- 个人推测该命令未找到对应表名,则直接将数据压缩存储值指定 target-dir。之后直接建表,指定存储路径保持一致,便可以查到表数据了。
6、hive黑界面直接查询导入数据量(count),数据溢出报错:FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
- 报错信息:
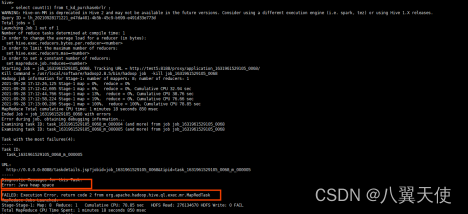
- 分析思路: 可以看出,mr进程在map过程中数据就溢出了,所以可以调节map的相关参数:
- map默认的启动数量与文件数有关,一个文件启动一个map。通过增大map数来提高并行度:
set mapred.max.split.size=67108864;(设置每个map的切分大小)但是该设置对压缩格式无效
set mapred.reduce.tasks=100;(直接设置map的数量)→解决问题
set hive.exec.mappers.bytes.per.mapper=20971520;(设定每个map处理的数据量默认为为20Mb=20 000 000)
- 另一种方法:
set mapreduce.job.maps = 10;(每个job默认开启map的数量)
- 设定map运行的占用资源:
set mapreduce.map.memory.mb=2048;set mapreduce.reduce.memory.mb=2048;set mapreduce.map.java.opts=Xmx1800M;set mapreduce.reduce.java.opts=Xmx1800M;set mapreduce.map.cpu.vcores=2;set mapreduce.reduce.cpu.vcores=2;
- 数据倾斜时,可以启用自动小文件合并:
set hive.input.format= org.apache.hadoop.hive.ql.io.CombineHiveInputFormat;
- 提高sql的执行速度,开启并行:
set hive.exec.parallel=true; (打开任务并行执行)
set hive.exec.parallel.thread.number=16; (同一个 sql 允许最大并行度,默认为 8)
6、为提高数据导入效率和表数据读取的效率,最好保持每个数据块在 128M左右,为此需要调整 map 的启动数量
- sqoop 命令:
sqoop import -Dmapreduce.map.java.opts=-Xmx3600m -Dmapreduce.map.memory.mb=4000 \
--connect ${rdbms_connstr} \
--username ${rdbms_username} \
--password ${rdbms_pwd} \
--query "SELECT FSEQ, FPARENTID, FID, FGRADEID, FCAGEBRLRQTY, FQTY, FGROSSWT, FCAGEWT, FNETWT, FSELPRICE, FSELAMT, FGENETICSMRKID, FPASTITEM, FBATCH, FNEXTNAME, FTYP, FAUDITBILLENTRYID, FCOEFFPRICE, FAUDITPRICE, CFPURBILLNUM, CFPURBILLID, CFREARERID, CFAVGWT, CFPOUNDID, CFSHILONG, TO_CHAR(CFPURDATE,'yyyy-MM-dd HH24:mi:ss')CFPURDATE, CFCALCPRICE FROM LIHUA.T_KD_BROILERSELLENTRYS1 WHERE \$CONDITIONS" \
--hive-overwrite \
--hive-database ${hive_database} \
--hive-table ${hive_table} \
--delete-target-dir \
--target-dir/db/${hive_database}/${hive_table} \
--fields-terminated-by "\001" \
--as-parquetfile \
--split-by"MOD(ORA_HASH(FID),10)" \
--m 10
–map 需要和 --split-by 一起连用
–map 指定读取数据的启动的map数量
–split-by 指定切分的规则,本处是按 FID 的hash值对10取余的数进行切分。
- 导出结果如图:
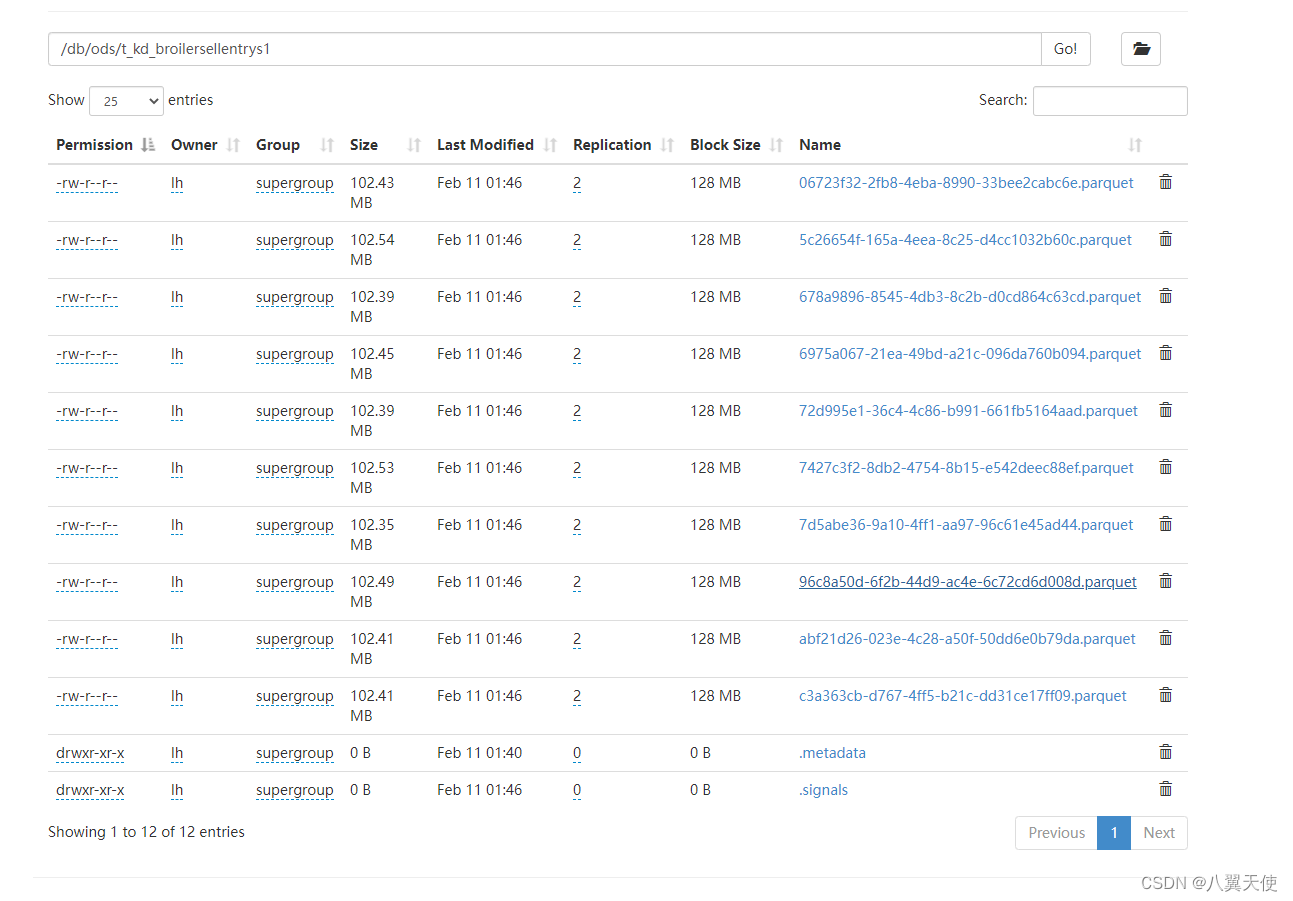
未解决问题:有时指定map数量为N,但是最后导出的文件数为N-1,少了一个,但是会有一个文件的size是其他文件的两倍左右,不知道是什么原因,这个希望有大佬可以解释一下。
本文转载自: https://blog.csdn.net/weixin_42151880/article/details/128980926
版权归原作者 欲乘风,潇潇雨 所有, 如有侵权,请联系我们删除。
版权归原作者 欲乘风,潇潇雨 所有, 如有侵权,请联系我们删除。