
前言:
\textcolor{Green}{前言:}
前言:
💞这个专栏就专门来记录一下寒假参加的第五期字节跳动训练营
💞从这个专栏里面可以迅速获得Go的知识
Go的性能优化建议
性能优化对于一个系统来说是非常重要的,因为我们在编写代码结束的时候有可能不会对性能有过多的关注,但是对于用户来说性能是非常重要的,我们肯定希望使用的系统是流畅的。这是一个速度决定一切的年代,只要我们的还继续在这个时代中,线下的流程与系统就在持续向线上转移,我们就会碰到性能问题。
3 性能优化建议
简介
- 性能优化的前提是满足正确可靠、简洁清晰等质量因素
- 性能优化是综合评估,有时候时间效率和空间效率可能对立
- 针对 Go 语言特性,介绍 Go 相关的性能优化建议
3.1 性能优化建议 - Benchmark
如何使用
- 性能表现需要实际数据衡量
- Go 语言提供了支持基准性能测试的 benchmark 工具
go test -bench=. -benchmen
// from fib.gofuncFib(n int)int{if n <2{return n
}returnFib(n -1)+Fib(n -2)}// from fib_test.gofuncBenchmarkFib10(b *testing.B){// run the Fib function b.N timesfor n :=0; n < b.N; n++{Fib(10)}}
结果说明

- BenchmarkFib10-8:BenchmarkFib10是测试函数名,-8 表示 GOMAXPROCS 的值为8
- 1855870:表示一共执行 1855870次, 即 b.N 的值
- 602.5 ns/op:表示每次执行花费 602.5 ns
- 0 B/op:表示每次执行申请多大的内存
- 0 allocs/op:表示每次执行申请几次内存
GOMAXPROCS 1.5版本后,默认值为CPU核数,https://pkg.go.dev/runtime#GOMAXPROCS
3.2 性能优化建议 - slice
slice 预分配内存
- 尽可能在使用 make() 初始化切片时提供容量信息
查看下面的代码,可以发现,提供容量信息后数据明显好
funcNoPreAlloc(size int){
data :=make([]int,0)for k :=0; k < size; k++{
data =append(data, k)}}funcPreAlloc(size int){
data :=make([]int,0, size)for k :=0; k < size; k++{
data =append(data, k)}}
BenchmarkNoPreAlloc-83529980331.1 ns/op2040 B/op8 allocs/opBenchmarkPreAlloc-811171086107.1 ns/op896 B/op1 allocs/op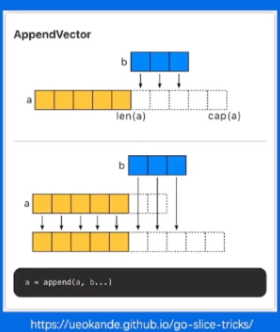
此时我们明白了
- 切片本质是一个数组片段的描述 - 包括数组指针- 片段长度- 片段的容量(不改变内存分配情况下的最大长度)
- 切片操作并不复制切片指向的元素
- 创建一个新的切片会复用原来切片的底层数组
type slice struct{ array unsafe.Pointer lenintcapint}
另一个陷阱:大内存未释放
- 在已有切片基础上创建切片,不会创建新的底层数组
- 场景: - 原切片较大,代码在原切片基础上新建小切片- 原底层数组在内存中有引用,得不到释放
- 可使用 copy 替代 re-slice
funcGetLastBySlice(origin []int)[]int{return origin[len(origin)-2:]}funcGetLastByCopy(origin []int)[]int{
result :=make([]int,2)copy(result, origin[len(origin)-2:])return result
}
functestGetLast(t *testing.T, f func([]int)[]int){
result :=make([][]int,0)for k :=0; k <100; k++{
origin :=generateWithCap(128*1024)// 1M
result =append(result,f(origin))}printMem(t)_= result
}
可以查看链接直达
3.3 性能优化建议 - Map
map 预分配内存
funcNoPreAlloc(size int){
data :=make(map[int]int)for k :=0; k < size; k++{
data[i]=1}}funcPreAlloc(size int){
data :=make(map[int]int, size)for k :=0; k < size; k++{
data[i]=1}}
BenchmarkNoPreAlloc-82269951972ns/op82327B/op9 allocs/opBenchmarkPreAlloc-81234189622ns/op40984B/op2 allocs/op
分析:
- 不断向 map 中添加元素的操作会触发 map 的扩容
- 提前分配好空间可以减少内存拷贝和 Rehash 的消耗
- 建议根据实际需求提前预估好需要的空间
3.4 性能优化建议 - 字符串处理
- 常见的字符串拼接方式
funcPlus(n int, str string)string{
s :=""for i :=0; i < n; i++{
s += str
}}
funcStrBuilder(n int, str string)string{var bulider strings.Builder
for i :=0; i < n; i++{
builder.WriteString(str)}return builder.String()}
使用 strings.Builder
funcByteBuffer(n int, str string)string{
buf :=new(bytes.Buffer)for i :=0; i < n; i++{
buf.WriteString(str)}return buf.String()}
BenchmarkPlus-84318280260ns/op3212595 B/op999 allocs/opBenchmarkStrBulider-82692572392 ns/op26744 B/op15 allocs/opBenchmarkByteBuffer-82092785699 ns/op25008 B/op9 allocs/op
- 使用 + 拼接性能最差,strings.Builder,bytes.Buffer 相近,strings.Buffer 更快
- 分析 - 字符串在 Go 语言中是不可变类型,占用内存大小是固定的- 使用 + 每次都会重新分配内存- strings.Builder,bytes.Buffer 底层都是 []byte 数组- 内存扩容策略,不需要每次拼接重新分配内存
注意看下面的
- bytes.Buffer 转换为字符串时重新申请了一块空间
- strings.Builder 直接将底层的 []byte 转换成了字符串类型返回
// to build strings more efficiently, see the strings.Builder type.func(b *Buffer)String()string{if b ==nil{// Special case, useful in debugging.return"<nil>"}returnstring(b.buf[b.off:])}// String returns the accumulated stringfunc(b *Builder)String()string{return*(*string)(unsafe.Pointer(&b.buf))}
funcPreStrBuilder(n int, str string)string{var bulider strings.Builder
builder.Grow(n *len(str))for i :=0; i < n; i++{
builder.WriteString(str)}return builder.String()}
funcPreByteBuilder(n int, str string)string{
buf :=new(bytes.Buffer)
buf.Grow(n *len(str))for i :=0; i < n; i++{
buf .WriteString(str)}return buf .String()}
这五个进行对比
BenchmarkPlus-84272279704 ns/op3212596 B/op999 allocs/opBenchmarkStrBulider-82687474405 ns/op26744 B/op15 allocs/opBenchmarkByteBuffer-846705670 ns/op25008 B/op9 allocs/opBenchmarkPreStrBulider-839383938 ns/op6144 B/op1 allocs/opBenchmarkPreByteBuffer-845784578 ns/op12288 B/op2 allocs/op
3.5 性能优化建议 - 空结构体
使用空结构体节省内存
- 空结构体 struct{} 实例不占据任何的内存空间
- 可作为各种场景下的占位符使用 - 节省资源- 空结构体本身具备很强的语义,即这里不需要任何值,仅作为占位符
funcEmptyStructMap(n int){
m :=make(map[int]struct{})for i :=0; i < n; i++{
m[i]=struct{}{}}}funcBoolMap(n int){
m :=make(map[int]bool)for i :=0; i < n; i++{
m[i]=false}}
BenchmarkEmptyStructMap-82372505970 ns/op378864 B/op133 allocs/opBenchmarkBoolMap-82266526095 ns/op412362 B/op165 allocs/op
- 实现 Set,可以考虑用 map 来代替
- 对于这个场景,只需要用到 map 的键,而不需要值
- 即使是将 map 的值设置为 bool类型,也会多占据 1 个字节空间
一个开源实现:https://github.com/deckarep/golang-set/blob/main/threadunsafe.go
3.6 性能优化建议 - atomic包
如何使用 atomic 包
type atomicCounter struct{
i int32}funcAtomicAddOne(c *atomicCounter){
atomic.AddInt32(&c, i,1)}
type mutexCounter struct{
i int32
m sync.Mutex
}funcMutexAddOne(c *mutexCounter){
c.m.Lock()
c.i++
c.m.Unlock()}
BenchmarkAtomicAddOne-81418243728.045 ns/op4 B/op1 allocs/opBenchmarkNutexAddOne-86048704421.73 ns/op16 B/op1 allocs/op
使用 atomic 包
- 锁的实现是通过操作系统来实现,属于系统调用
- atomic 操作是通过硬件实现的,效率比锁高
- sync.Mutex 应该用来保护一段逻辑,不仅仅用于保护一个变量
- 对于非数值操作,可以使用 atomic.Value,能承载一个 interface{}
性能优化建议小结
- 避免常见的性能陷阱可以保证大部分程序的性能
- 普通应用代码,不要一昧的追求程序的性能
- 越高级的性能优化手段越容易出现问题
- 在满足正常可靠、简洁清晰的质量要求的前提下提高程序性能
版权归原作者 秦 羽 所有, 如有侵权,请联系我们删除。