
By 远方时光原创,可转载,open
合作微信公众号:**大数据左右手 **

16年骑行到一个上坡时候,正好下着冰雹,有点累就停了下来,转身觉得风景很美,随手拍下了这张照片。累了就歇一会。
一 什么是数据倾斜
1.先回顾一下并行计算和分布式计算
并行计算:单个计算机内同时处理多个计算任务。(单机多核处理任务)
分布式计算:将计算任务分配给多台计算机或者节点处理的方式。(多机多核处理任务)
2.数据倾斜
处理海量数据时候,通过分布式计算,使用多个节点帮我们处理海量数据,假如每个节点计算资源是均匀的,那我们希望分给每个节点的数据要尽量均匀。
数据倾斜就是我们在计算数据的时候,数据的分散度不够,导致大量的数据集中到了一台或者几台机器上计算,造成数据热点问题(数据倾斜的另一种说法),这些数据的计算速度远远低于平均计算速度,导致整个计算过程过慢(木桶效应)。
形象的比方:小罗,小蒋,小万个人能力差不多,我们希望领导分活尽量均匀分给每一个人,而不是领导把大部分任务都分给小罗(数据倾斜),小罗累死干不完。
二 spark****数据倾斜表现
Spark中的数据倾斜,包括Spark Streaming和Spark Sql,表现主要有下面几种:
- Executor lost,OOM,Shuffle过程出错;
- Driver OOM;
- 单个Executor执行时间特别久,整体任务卡在某个阶段不能结束;
- 正常运行的任务突然失败;
三 数据倾斜产生原因
我们以Spark和Hive的使用场景为例。
他们在做数据运算的时候会涉及到,count distinct、group by、join on等操作,这些都会触发Shuffle动作。一旦触发Shuffle,所有相同key的值就会被拉到一个或几个Reducer节点上,容易发生单点计算问题,导致数据倾斜。
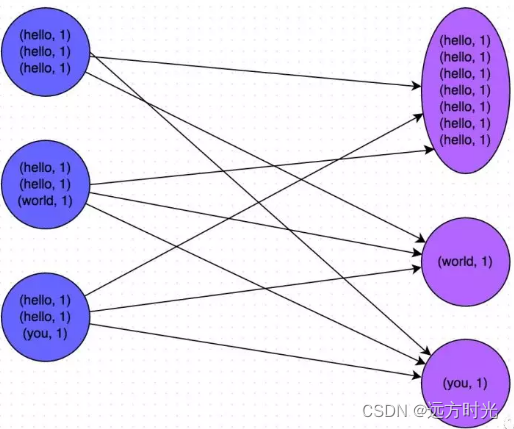
四 解决数据倾斜思路
很多数据倾斜的问题,都可以用和平台无关的方式解决,比如更好的数据预处理,异常值的过滤等。因此,解决数据倾斜的重点在于对数据设计和业务的理解,这两个搞清楚了,数据倾斜就解决了大部分了。
1.异常key, 找到异常数据,比如key为null,业务上没用用的话过滤掉。
2.对分布不均匀的key,单独计算。
3.预聚合,减少shuffle。
4.两阶段聚合*(局部聚合+全局聚合)*:先对key做一层hash,先将数据随机打散让它的并行度变大,再汇集。
五 定位导致数据倾斜代码
Spark数据倾斜只会发生在shuffle过程中。常用的并且可能会触发shuffle操作的算子:distinct、groupByKey、reduceByKey、aggregateByKey、join、cogroup、repartition等。
出现数据倾斜时,可能就是你的代码中使用了这些算子中的某一个所导致的。
**某个task执行特别慢的情况, **看task运行时间和数据量
首先要看的,就是数据倾斜发生在第几个stage中:
如果是用yarn-client模式提交,那么在提交的机器本地是直接可以看到log,可以在log中找到当前运行到了第几个stage;如果是用yarn-cluster模式提交,则可以通过Spark Web UI来查看当前运行到了第几个stage。都可以在Spark Web UI上深入看一下当前这个stage各个task分配的数据量,从而进一步确定是不是task分配的数据不均匀导致了数据倾斜。
task运行时间:有的task运行特别快,只需要几秒钟就可以运行完;而有的task运行特别慢,需要几分钟才能运行完,此时单从运行时间上看就已经能够确定发生数据倾斜了。
task数据量:运行时间特别短的task只需要处理几百KB的数据即可,而运行时间特别长的task需要处理几千KB的数据,处理的数据量差了10倍。此时更加能够确定是发生了数据倾斜。
某个task莫名其妙内存溢出的情况
建议直接看yarn-client模式下本地log的异常栈,或者是通过YARN查看yarn-cluster模式下的log中的异常栈。一般来说,通过异常栈信息就可以定位到你的代码中哪一行发生了内存溢出。然后在那行代码附近找找,一般也会有shuffle类算子,此时很可能就是这个算子导致了数据倾斜。
要注意的是,不能单纯靠偶然的内存溢出就判定发生了数据倾斜。因为自己编写的代码的bug,以及偶然出现的数据异常,或者资源不足,也可能会导致内存溢出。
因此还是要按照上面所讲的方法,通过Spark Web UI查看报错的那个stage的各个task的运行时间以及分配的数据量,才能确定是否是由于数据倾斜才导致了这次内存溢出。
六 查看导致数据倾斜的key分布情况
先对pairs采样10%的样本数据,然后使用countByKey算子统计出每个key出现的次数,最后在客户端遍历和打印样本数据中各个key的出现次数。
val sampleDF: Dataset[Row] = outputStream.sample(false, 0.1)
val groupbyDF: DataFrame = sampleDF.groupBy("key").count()
groupbyDF.show()
七 数据倾斜的解决方案
提高shuffle操作的并行度
方案适用场景:
如果我们必须要对数据倾斜迎难而上,那么建议优先使用这种方案,因为这是处理数据倾斜最简单的一种方案。
方案实现思路:
你可以按照以下方式设置shuffle并行度:
// 设置shuffle并行度为200
spark.conf.set("spark.sql.shuffle.partitions", "200")
// 在创建DataFrame时指定shuffle并行度
val yourDataFrame = // 你的DataFrame的创建操作
val increasedShuffleDF = yourDataFrame.repartition(200)
在第一种方式中,通过spark.conf.set方法设置全局的shuffle并行度。在第二种方式中,使用repartition方法在创建DataFrame时指定shuffle并行度。根据你的数据规模和集群配置来调整并行度的具体值。增加并行度可能有助于提高性能,但也需要注意资源消耗。
方案实现原理:
增加shuffle read task的数量,可以让原本分配给一个task的多个key分配给多个task,从而让每个task处理比原来更少的数据。那么自然每个task的执行时间都会变短了。

方案优缺点:
优点:实现起来比较简单,可以有效缓解和减轻数据倾斜的影响。
缺点:只是缓解了数据倾斜而已,没有彻底根除问题,根据实践经验来看,其效果有限。
方案实践经验:
该方案通常无法彻底解决数据倾斜,因为如果出现一些极端情况,比如某个key对应的数据量有100万,那么无论你的task数量增加到多少,这个对应着100万数据的key肯定还是会分配到一个task中去处理,因此注定还是会发生数据倾斜的。所以这种方案只能说是在发现数据倾斜时尝试使用的第一种手段,尝试去用最简单的方法缓解数据倾斜而已。
两阶段聚合(局部聚合+全局聚合)
方案适用场景:
Spark SQL中使用group by语句进行分组聚合时,比较适用这种方案。
方案实现思路:
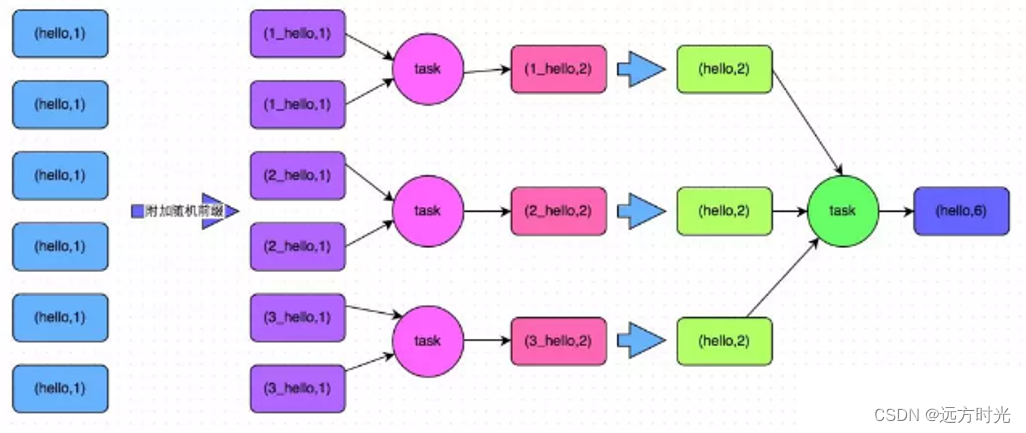
Spark的两阶段聚合(Two-Stage Aggregation)是为了优化shuffle操作而设计的。它主要包括两个阶段:局部聚合(Map 端聚合)和全局聚合(Reduce 端聚合)****。
1. 局部聚合(Map 端聚合):
- 在该阶段,每个分区内的数据进行本地聚合。
- 在map阶段,每个mapper会在本地先进行局部聚合,将相同key的数据聚合在一起。
- 减少了数据通过网络传输到reduce端的量。
2. 全局聚合(Reduce 端聚合):
- 在全局聚合阶段,各个分区的结果会被传输到reduce节点上。
- 在reduce阶段,对每个key的聚合结果再进行全局的聚合,生成最终的聚合结果。
方案实现原理:
将原本相同的key通过附加随机前缀的方式,变成多个不同的key,就可以让原本被一个task处理的数据分散到多个task上去做局部聚合,进而解决单个task处理数据量过多的问题。接着去除掉随机前缀,再次进行全局聚合,就可以得到最终的结果。具体原理见下图。
方案优缺点:
优点
对于聚合类的shuffle操作导致的数据倾斜,效果是非常不错的。通常都可以解决掉数据倾斜,或者至少是大幅度缓解数据倾斜,将Spark作业的性能提升数倍以上。
缺点
仅仅适用于聚合类的shuffle操作,适用范围相对较窄。如果是join类的shuffle操作,还得用其他的解决方案。
将reduce join转为map join
方案适用场景:
在对RDD使用join类操作,或者是在Spark SQL中使用join语句时,而且join操作中的一个表的数据量比较小(比如几百M或者一两G),比较适用此方案。
方案实现思路:
不使用join算子进行连接操作,而使用Broadcast变量与map类算子实现join操作,进而完全规避掉shuffle类的操作,彻底避免数据倾斜的发生和出现。将较小RDD中的数据直接通过collect算子拉取到Driver端的内存中来,然后对其创建一个Broadcast变量,广播给其他Executor节点;
方案实现原理:
普通的join是会走shuffle过程的,而一旦shuffle,就相当于会将相同key的数据拉取到一个shuffle read task中再进行join,此时就是reduce join。
但是如果一个RDD是比较小的,则可以采用广播小RDD全量数据+map算子来实现与join同样的效果,也就是map join,此时就不会发生shuffle操作,也就不会发生数据倾斜。

方案优缺点:
优点:对join操作导致的数据倾斜,效果非常好,因为根本就不会发生shuffle,也就根本不会发生数据倾斜。
缺点:适用场景较少,因为这个方案只适用于一个大表和一个小表的情况。毕竟我们需要将小表进行广播,此时会比较消耗内存资源,driver和每个Executor内存中都会驻留一份小RDD的全量数据。如果我们广播出去的RDD数据比较大,比如10G以上,那么就可能发生内存溢出了。因此并不适合两个都是大表的情况。
版权归原作者 远方时光 所有, 如有侵权,请联系我们删除。