
selenium简介
selenium是一个用于web应用程序的自动化测试工具,通过Selenium可以写出自动化程序,拟人在浏览器对网页进行操作。selenium可以编写出自动化程序,简化手动保存的部分。
requests简介
requests库可以向第三方发送http请求,是一个用于网络请求的模块,通常以GET方式请求特定资源,请求中不应该包含请求体,所有需要向被请求资源传递的数据都应该通过 URL 向服务器传递。
webdriver简介
使用selenium,离不开webdriver。selenium编写出自动化程序告知浏览器驱动,浏览器驱动再去驱动浏览器。webdriver由浏览器厂家提供,以chrome浏览器为例:
首先,从设置中查找chrome版本号。
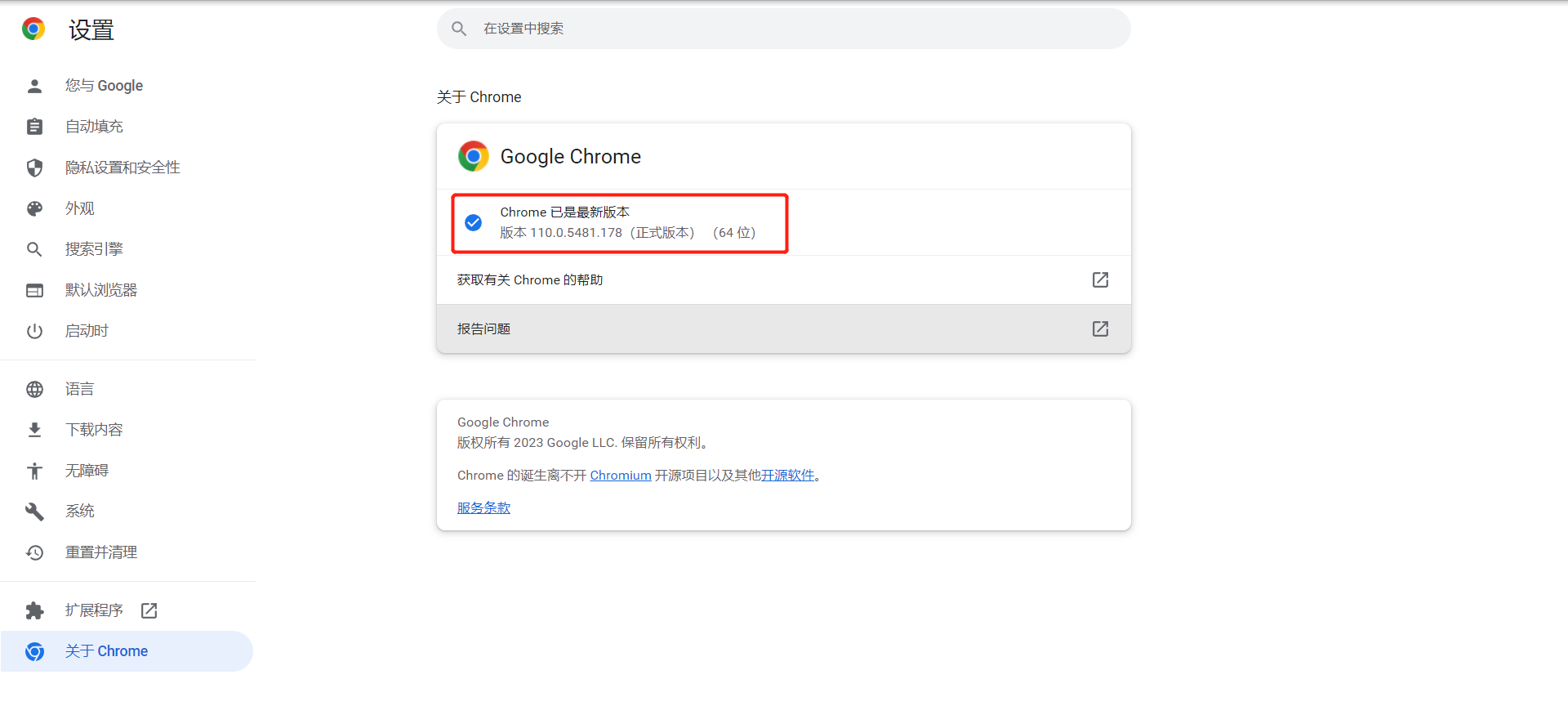
接着,根据以下网址,查找浏览器对应的驱动版本号:
https://chromedriver.storage.googleapis.com/index.html
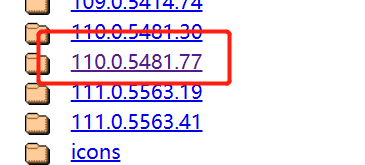
直接下载即可,webdriver可以直接放置在项目路径下,路径指定更加方便。
代码实现
step1:驱动浏览器
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
wd = webdriver.Chrome(service=Service(r'chromedriver.exe'))# 驱动浏览器
wd.get("https://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&dyTabStr=MCwzLDYsMSw1LDQsOCw3LDIsOQ%3D%3D&word=%E6%B5%B7%E7%BB%B5%E5%AE%9D%E5%AE%9D")
wd.implicitly_wait(5) # 隐式等待,每隔半秒查询一次,五秒后结束
step2:通过xpath定位元素获取url()
from selenium.webdriver.common.by import By
elements = wd.find_elements(By.XPATH, "//*[@class='rich_pages wxw-img']")# 通过Xpath根据图片的class查询
step3:导入requests包,将图片保存到指定路径(PS:这里图片的class可以通过在网页中按f12查询,不建议使用css查询,很多class名有空格,但是在css中的空格表示后代关系)
import requests
import os
i = 0
for element in elements:
i += 1
print('----------------')
t = element.get_attribute('src')
print(t)# 打印出图片的src
path = "D:\study material\海绵宝宝图\图{}.jpg".format(i)
r = requests.get(t)# 通过requests种的get方法得到图片的src
r.raise_for_status()
with open(path, 'wb') as f:# 保存图片
f.write(r.content)
f.close()
print('保存成功')
wd.quit()# 退出自动化测试
总体代码:
# 移动鼠标到某个元素
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import requests
import os
import time
wd = webdriver.Chrome(service=Service(r'C:\Users\Daisy\Desktop\蓝桥杯\chromedriver.exe'))
wd.implicitly_wait(5)
wd.get('https://image.baidu.com/search/index?tn=baiduimage&ps=1&ct=201326592&lm=-1&cl=2&nc=1&ie=utf-8&dyTabStr=MCwzLDYsMSw1LDQsOCw3LDIsOQ%3D%3D&word=%E6%B5%B7%E7%BB%B5%E5%AE%9D%E5%AE%9D')
elements = wd.find_elements(By.XPATH, "//*[@class='main_img img-hover']")
d = "D:\study material\海绵宝宝图"
i = 0
time.sleep(2)
for element in elements:
i += 1
print('----------------')
t = element.get_attribute('src')
print(t)
path = "D:\study material\海绵宝宝图\图{}.jpg".format(i)
r = requests.get(t)
r.raise_for_status()
with open(path, 'wb') as f:
f.write(r.content)
f.close()
print('保存成功')
wd.quit()
最终效果:
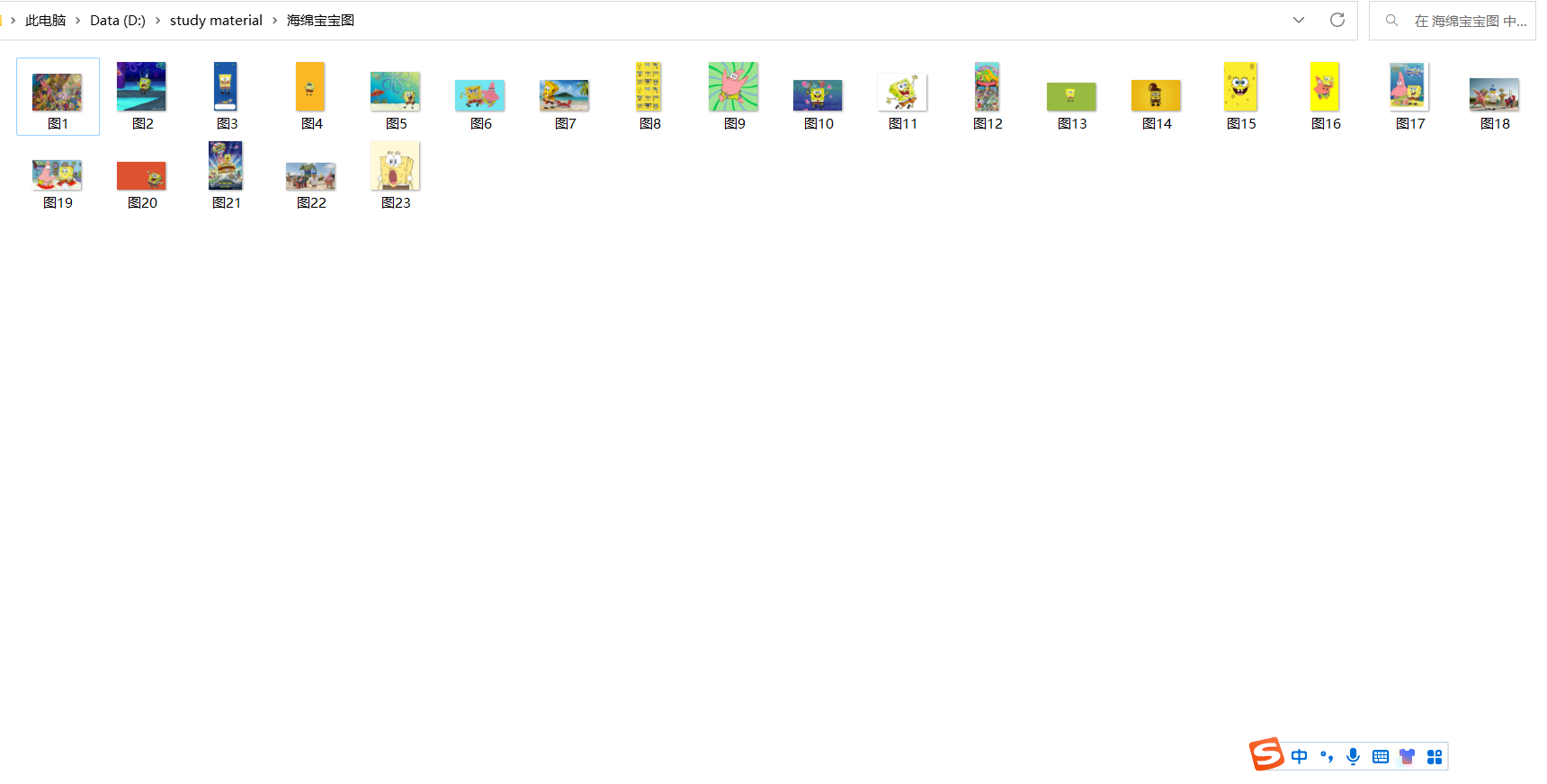
本文转载自: https://blog.csdn.net/Chengxuyuan0307/article/details/129363743
版权归原作者 Chengxuyuan0307 所有, 如有侵权,请联系我们删除。
版权归原作者 Chengxuyuan0307 所有, 如有侵权,请联系我们删除。