
1.1 下载数据集
在此,我们将使用National Health and Nutrition Health Survey数据集。
 图3-1 National Health and Nutrition Health Survey数据集
图3-1 National Health and Nutrition Health Survey数据集
1.2 理解数据
National Health and Nutrition Health Survey数据集出现在 2019年由 An Dinh、Amber Young和 Stacey Miertschin撰写并发表在《BMC医学信息学与决策制定》杂志上的题为 《基于机器学习的数据驱动方法预测糖尿病和心血管疾病》的论文中。
NHANES数据集旨在通过访谈、体检和实验室测试评估美国成人和儿童的健康和营养状况。该数据集由美国疾病控制和预防中心(CDC)的国家卫生统计中心(NCHS)资助,并包括了来自美国各地的调查受访者。针对这个特定的子集,年龄65岁及以上的受访者被标记为“老年人”,而所有年龄在65岁以下的个体则被标记为“非老年人”
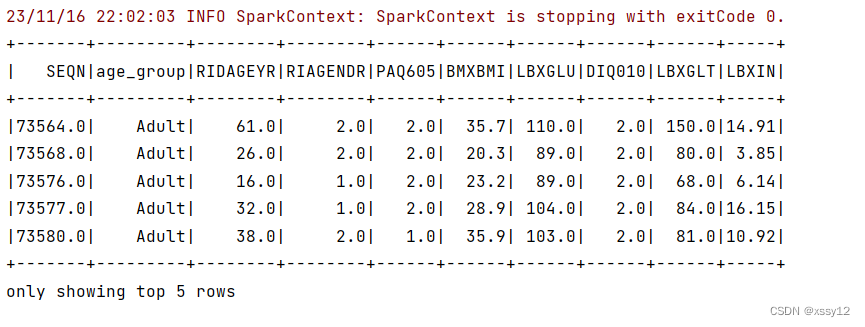
这些数据包含6287个观测值,每个方价都对应7个特征数量:
SEQN ID:表示受访者序列号
age_group:表示受访者的年龄组别(老年人/非老年人)
RIDAGEYR:表示受访者年龄
RIAGENDR :表示受访者性别
PAQ605:表示受访者是否在典型的一周内参与中等或剧烈强度的运动、健身或娱乐活动
BMXBMI:表示受访者的体重指数
LBXGLU:表示受访者禁食后的血糖水平
DIQ010:表示受访者是否患糖尿病
LBXGLT:表示受访者口腔中的血糖水平
LBXIN:表示受访者的血胰岛素水平
1.3 读入数据
在将数据加载到 DataFrame 时指定数据的类型将提供比类型推断更好的性能。
读取数据 dataframe:
val df: DataFrame = spark.read
.format("csv")
.option("header", "true")
.load(filePath)
显示DataFrame的内容:
df.show()
查看描述性统计信息:
df.describe().show()
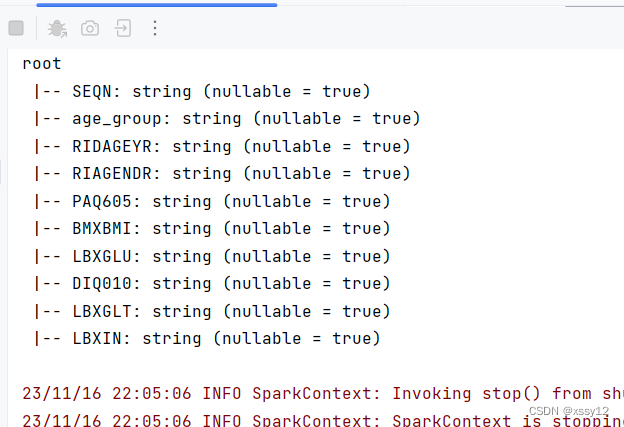
显示spark dataframe的列名:
1.4探索数据
通过spark选取指定列,并展示前10行数据:
val selectedColumns = Seq("age_group", "RIDAGEYR", "RIAGENDR", "PAQ605", "BMXBMI", "LBXGLU", "DIQ010", "LBXGLT", "LBXIN")
val selectedDF = df.select(selectedColumns.map(col): _*)
selectedDF.show(10)

接下来看下该数据集中位数年龄分布情况:
// 构建直方图数据集
val binIndex = frequencies._1.indices
for (i <- binIndex.dropRight(1)) { // 使用 dropRight(1) 避免超出索引范围
dataset.addValue(frequencies._2(i).toDouble, "", s"${frequencies._1(i)}-${frequencies._1(i + 1)}")
}

从上图可以看到该数据集青少年居多。
Spark DataFrames 包含一些用于统计处理的内置函数。describe() 函数对所有数值列执行汇总统计计算,并将它们作为 DataFrame 返回。
val numericColumns = df.dtypes.filter{ case (_, dataType) => dataType == "DoubleType" } // 过滤出 DoubleType 类型的列
.map{ case (column, _) => column }
// 使用 describe 函数统计数值列
val summaryStats = df.describe(numericColumns: _*)
// 打印汇总统计结果
summaryStats.show()
 从上面的统计结果中,我们可以看到所有数据的最小值和最大值。这些数据范围很大,因此我们需要标准化这个数据集。
从上面的统计结果中,我们可以看到所有数据的最小值和最大值。这些数据范围很大,因此我们需要标准化这个数据集。
1.5数据预处理
// 缺失值处理
val imputer = new Imputer()
.setInputCols(Array("RIDAGEYR", "BMXBMI", "LBXGLU", "LBXGLT", "LBXIN"))
.setOutputCols(Array("imputed_RIDAGEYR", "imputed_BMXBMI", "imputed_LBXGLU", "imputed_LBXGLT", "imputed_LBXIN"))
val imputedData = imputer.fit(df).transform(df)
// 标签编码
val labelIndexer = new StringIndexer()
.setInputCol("age_group")
.setOutputCol("label")
val encodedData = labelIndexer.fit(imputedData).transform(imputedData)
// 特征向量化
val featureCols = Array("RIDAGEYR", "RIAGENDR", "PAQ605", "BMXBMI", "LBXGLU", "DIQ010", "LBXGLT", "LBXIN")
val assembler = new VectorAssembler()
.setInputCols(featureCols)
.setOutputCol("features")
val assembledData = assembler.transform(encodedData)
// 独热编码
val encoder = new OneHotEncoder()
.setInputCol("RIAGENDR")
.setOutputCol("encoded_gender")
val encodedData = encoder.transform(assembledData)
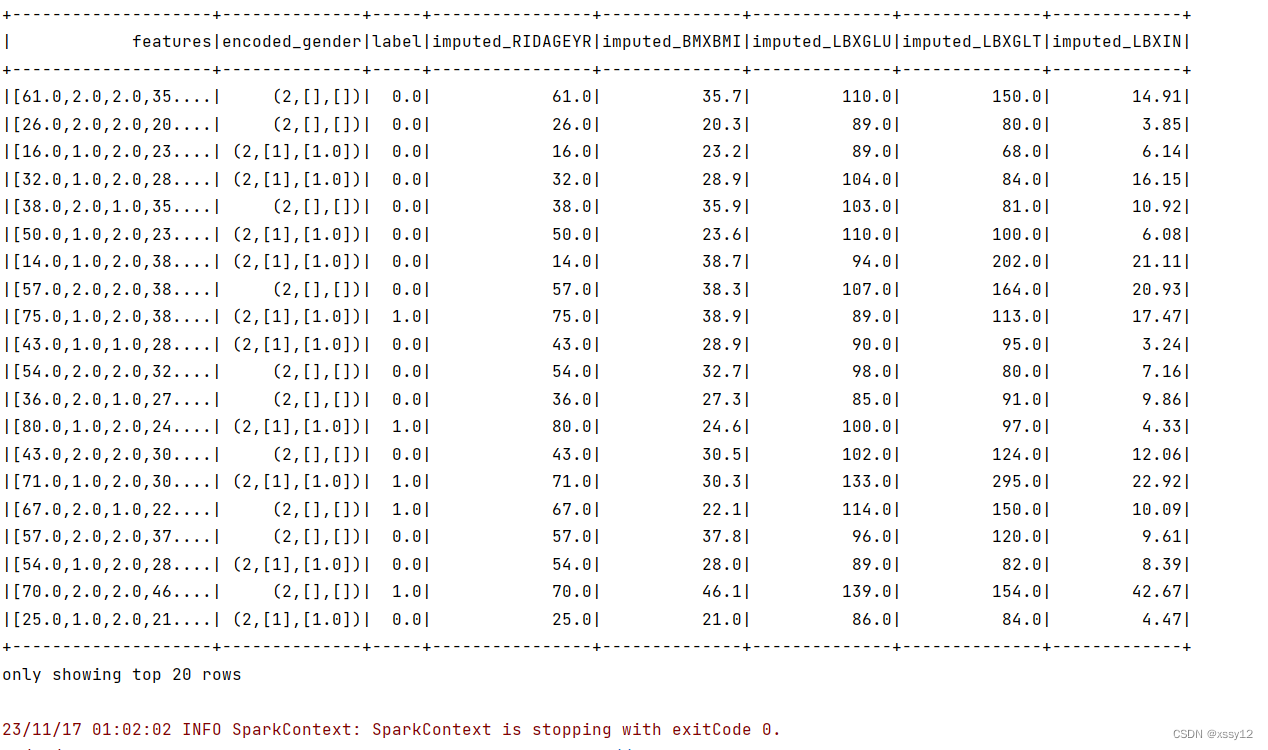
如上图所示,所有的特征都变成了一个密集向量features。
1.6标准化
接下来,我们终于可以使用 StandardScaler 缩放数据了。输入列是特征,将输出列将命名为"features_scaled":
// 特征规范化
val scaler = new StandardScaler()
.setInputCol("features")
.setOutputCol("features_scaled")
.setWithMean(true)
.setWithStd(true)
val scaledData = scaler.fit(assembledData).transform(assembledData)
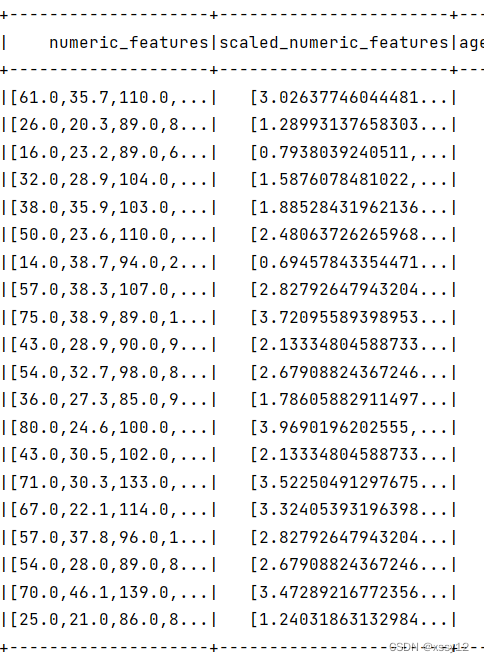
在上面特征处理中,我们使用了标准化,那是因为我们用到的特征都是数值特征,但是在有些数据集中还会有类别类特征、文本特征、以及其他特征。
其中,类别特征,它们的取值只能是可能状态集合中的某一种。比如说用户性别、职业等便是这类。当类别特征处于原始形式的时候,其取值来自所有可能构成的集合而不是一个数字,故不能作为输入。因此我们需要把类别变量进过编码处理。
文本特征的处理方法有很多,最简单且标准的方法就是词袋法(bag-of-word)。该方法将一段文本视为由其中的文本或数字组成的集合,其处理过程一版分为:分词、删除停用词、提取词干、向量化等步骤。
版权归原作者 xssy12 所有, 如有侵权,请联系我们删除。