
背景:物联网平台背景,传感器采集频率干到了1000Hz,分了100多张表出来,还是把mysql干炸了。当前单表数据量在1000来w,从kafka上拉数据异步批量插入,每次插入数据量1500条,测试的时候还没问题,结果上线没多久,kafka服务器直接挂了,赶忙看日志,kafka服务器堆积了几十G的数据,再去看生产环境日志,发现到最后单次批量插入用时固定在10多秒,甚至20多秒,kafka直接把消费端踢出了消费组…从而kafka消息一直没有消费,总重导致kafka数据堆积挂掉了…
在这样的情况下:采取的处理方案无非就分库分表,减少单表数据量,降低数据库压力;提高批量插入效率,提高消费者消费速度。
本文主要把精力放在如何提高批量插入效率上。
使用的mybatisplus的批量插入方法:saveBatch(),之前就看到过网上都在说在jdbc的url路径上加上
rewriteBatchedStatements=true 参数mysql底层才能开启真正的批量插入模式。
保证5.1.13以上版本的驱动,才能实现高性能的批量插入。 MySQL JDBC驱动在默认情况下会无视executeBatch()语句,把我们期望批量执行的一组sql语句拆散,一条一条地发给MySQL数据库,批量插入实际上是单条插入,直接造成较低的性能。只有把rewriteBatchedStatements参数置为true, 驱动才会帮你批量执行SQL。 另外这个选项对INSERT/UPDATE/DELETE都有效。
可是我之前已经添加了,而且数据表目前是没有建立索引的,即使是在1000来w的数据量下进行1500条的批量插入也不可能消耗20来秒吧,于是矛盾转移到saveBatch方法,使用版本:V3.4.3.4
查看源码:
publicbooleansaveBatch(Collection<T> entityList,int batchSize){String sqlStatement =this.getSqlStatement(SqlMethod.INSERT_ONE);returnthis.executeBatch(entityList, batchSize,(sqlSession, entity)->{
sqlSession.insert(sqlStatement, entity);});}
protected<E>booleanexecuteBatch(Collection<E> list,int batchSize,BiConsumer<SqlSession,E> consumer){returnSqlHelper.executeBatch(this.entityClass,this.log, list, batchSize, consumer);}
publicstatic<E>booleanexecuteBatch(Class<?> entityClass,Log log,Collection<E> list,int batchSize,BiConsumer<SqlSession,E> consumer){Assert.isFalse(batchSize <1,"batchSize must not be less than one",newObject[0]);return!CollectionUtils.isEmpty(list)&&executeBatch(entityClass, log,(sqlSession)->{int size = list.size();int i =1;for(Iterator var6 = list.iterator(); var6.hasNext();++i){E element = var6.next();
consumer.accept(sqlSession, element);if(i % batchSize ==0|| i == size){
sqlSession.flushStatements();}}});}
最终来到了executeBatch()方法,可以看到这很明显是在一条一条循环插入,通过sqlSession.flushStatements()将一个个单条插入的insert语句分批次进行提交,而且是同一个sqlSession,这相比遍历集合循环insert来说有一定的性能提升,但是这并不是sql层面真正的批量插入。
通过查阅相关文档后,发现mybatisPlus提供了sql注入器,我们可以自定义方法来满足业务的实际开发需求。
sql注入器官网
sql注入器官方示例
在mybtisPlus的核心包下提供的默认可注入方法有这些: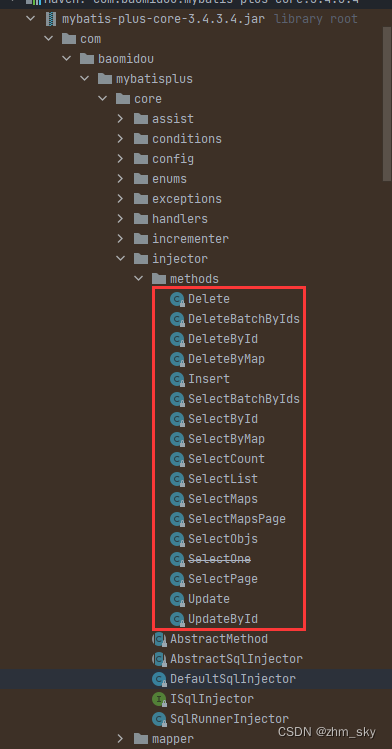
在扩展包下,mybatisPlus还为我们提供了可扩展的可注入方法: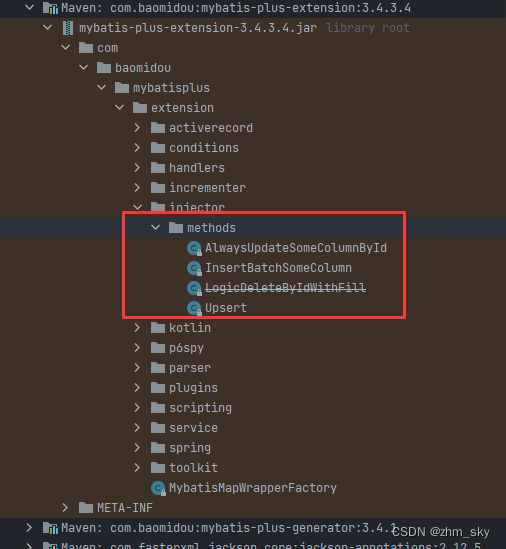
AlwaysUpdateSomeColumnById: 根据Id更新每一个字段,全量更新不忽略null字段,解决mybatis-plus中updateById默认会自动忽略实体中null值字段不去更新的问题;
InsertBatchSomeColumn: 真实批量插入,通过单SQL的insert语句实现批量插入;
Upsert: 更新or插入,根据唯一约束判断是执行更新还是删除,相当于提供insert on duplicate key update支持。
可以发现mybatisPlus已经提供好了InsertBatchSomeColumn的方法,我们只需要把这个方法添加进我们的sql注入器即可。
publicMappedStatementinjectMappedStatement(Class<?> mapperClass,Class<?> modelClass,TableInfo tableInfo){KeyGenerator keyGenerator =NoKeyGenerator.INSTANCE;SqlMethod sqlMethod =SqlMethod.INSERT_ONE;List<TableFieldInfo> fieldList = tableInfo.getFieldList();String insertSqlColumn = tableInfo.getKeyInsertSqlColumn(true,false)+this.filterTableFieldInfo(fieldList,this.predicate,TableFieldInfo::getInsertSqlColumn,"");//------------------------------------拼接批量插入语句----------------------------------------String columnScript ="("+ insertSqlColumn.substring(0, insertSqlColumn.length()-1)+")";String insertSqlProperty = tableInfo.getKeyInsertSqlProperty(true,"et.",false)+this.filterTableFieldInfo(fieldList,this.predicate,(i)->{return i.getInsertSqlProperty("et.");},"");
insertSqlProperty ="("+ insertSqlProperty.substring(0, insertSqlProperty.length()-1)+")";String valuesScript =SqlScriptUtils.convertForeach(insertSqlProperty,"list",(String)null,"et",",");//------------------------------------------------------------------------------------------String keyProperty =null;String keyColumn =null;if(tableInfo.havePK()){if(tableInfo.getIdType()==IdType.AUTO){
keyGenerator =Jdbc3KeyGenerator.INSTANCE;
keyProperty = tableInfo.getKeyProperty();
keyColumn = tableInfo.getKeyColumn();}elseif(null!= tableInfo.getKeySequence()){
keyGenerator =TableInfoHelper.genKeyGenerator(this.getMethod(sqlMethod), tableInfo,this.builderAssistant);
keyProperty = tableInfo.getKeyProperty();
keyColumn = tableInfo.getKeyColumn();}}String sql =String.format(sqlMethod.getSql(), tableInfo.getTableName(), columnScript, valuesScript);SqlSource sqlSource =this.languageDriver.createSqlSource(this.configuration, sql, modelClass);returnthis.addInsertMappedStatement(mapperClass, modelClass,this.getMethod(sqlMethod), sqlSource,(KeyGenerator)keyGenerator, keyProperty, keyColumn);}
接下来就通过SQL注入器实现真正的批量插入
默认的sql注入器
publicclassDefaultSqlInjectorextendsAbstractSqlInjector{publicDefaultSqlInjector(){}publicList<AbstractMethod>getMethodList(Class<?> mapperClass,TableInfo tableInfo){if(tableInfo.havePK()){return(List)Stream.of(newInsert(),newDelete(),newDeleteByMap(),newDeleteById(),newDeleteBatchByIds(),newUpdate(),newUpdateById(),newSelectById(),newSelectBatchByIds(),newSelectByMap(),newSelectCount(),newSelectMaps(),newSelectMapsPage(),newSelectObjs(),newSelectList(),newSelectPage()).collect(Collectors.toList());}else{this.logger.warn(String.format("%s ,Not found @TableId annotation, Cannot use Mybatis-Plus 'xxById' Method.", tableInfo.getEntityType()));return(List)Stream.of(newInsert(),newDelete(),newDeleteByMap(),newUpdate(),newSelectByMap(),newSelectCount(),newSelectMaps(),newSelectMapsPage(),newSelectObjs(),newSelectList(),newSelectPage()).collect(Collectors.toList());}}}
继承DefaultSqlInjector自定义sql注入器
/**
* @author zhmsky
* @date 2022/8/15 15:13
*/publicclassMySqlInjectorextendsDefaultSqlInjector{@OverridepublicList<AbstractMethod>getMethodList(Class<?> mapperClass){List<AbstractMethod> methodList =super.getMethodList(mapperClass);//更新时自动填充的字段,不用插入值
methodList.add(newInsertBatchSomeColumn(i -> i.getFieldFill()!=FieldFill.UPDATE));return methodList;}}
将自定义的sql注入器注入到Mybatis容器中
/**
* @author zhmsky
* @date 2022/8/15 15:15
*/@ConfigurationpublicclassMybatisPlusConfig{@BeanpublicMySqlInjectorsqlInjector(){returnnewMySqlInjector();}}
继承 BaseMapper 添加自定义方法
/**
* @author zhmsky
* @date 2022/8/15 15:17
*/publicinterfaceCommonMapper<T>extendsBaseMapper<T>{/**
* 真正的批量插入
* @param entityList
* @return
*/intinsertBatchSomeColumn(List<T> entityList);}
对应的mapper层接口继承上面自定义的mapper
*@author zhmsky
*@since2021-12-01*/@MapperpublicinterfaceUserMapperextendsCommonMapper<User>{}
最后直接调用UserMapper的insertBatchSomeColumn()方法即可实现真正的批量插入。
@TestvoidcontextLoads(){for(int i =0; i <5; i++){User user =newUser();
user.setAge(10);
user.setUsername("zhmsky");
user.setEmail("[email protected]");
userList.add(user);}long l =System.currentTimeMillis();
userMapper.insertBatchSomeColumn(userList);long l1 =System.currentTimeMillis();System.out.println("-------------------:"+(l1-l));
userList.clear();}
查看日志输出信息,观察执行的sql语句,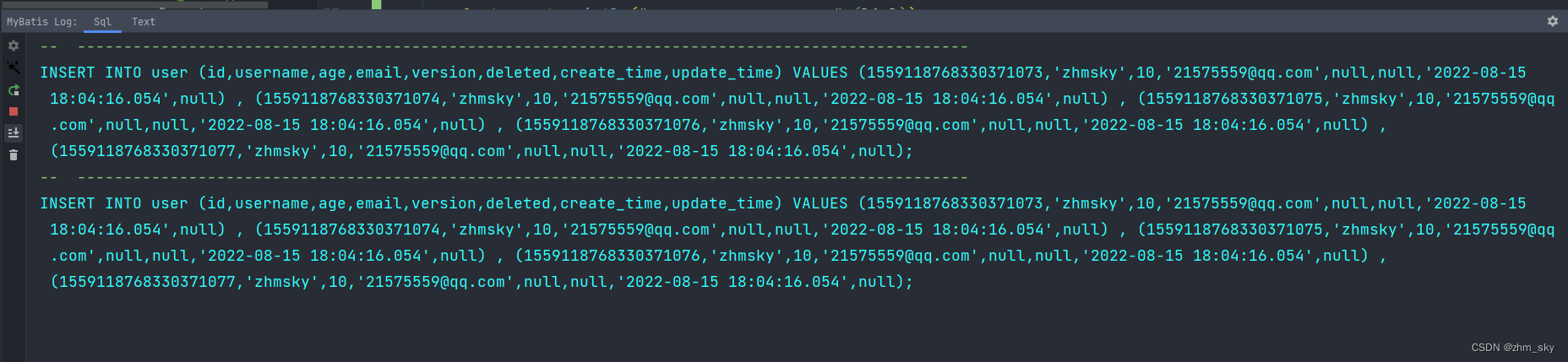
发现这才是真正意义上的sql层面的批量插入。
但是,到这里并没有结束,mybatisPlus官方提供的insertBatchSomeColumn方法不支持分批插入,也就是有多少直接全部一次性插入,这就可能会导致最后的sql拼接语句特别长,超出了mysql的限制,于是我们还要实现一个类似于saveBatch的分批的批量插入方法。
添加分批插入
模仿原来的saveBatch方法:
*@author zhmsky
*@since2021-12-01*/@ServicepublicclassUserServiceImplextendsServiceImpl<UserMapper,User>implementsUserService{@Override@Transactional(rollbackFor ={Exception.class})publicbooleansaveBatch(Collection<User> entityList,int batchSize){try{int size = entityList.size();int idxLimit =Math.min(batchSize, size);int i =1;//保存单批提交的数据集合List<User> oneBatchList =newArrayList<>();for(Iterator<User> var7 = entityList.iterator(); var7.hasNext();++i){User element = var7.next();
oneBatchList.add(element);if(i == idxLimit){
baseMapper.insertBatchSomeColumn(oneBatchList);//每次提交后需要清空集合数据
oneBatchList.clear();
idxLimit =Math.min(idxLimit + batchSize, size);}}}catch(Exception e){
log.error("saveBatch fail", e);returnfalse;}returntrue;}}
测试:
@TestvoidcontextLoads(){for(int i =0; i <20; i++){User user =newUser();
user.setAge(10);
user.setUsername("zhmsky");
user.setEmail("[email protected]");
userList.add(user);}long l =System.currentTimeMillis();
userService.saveBatch(userList,10);long l1 =System.currentTimeMillis();System.out.println("-------------------:"+(l1-l));
userList.clear();}
输出结果: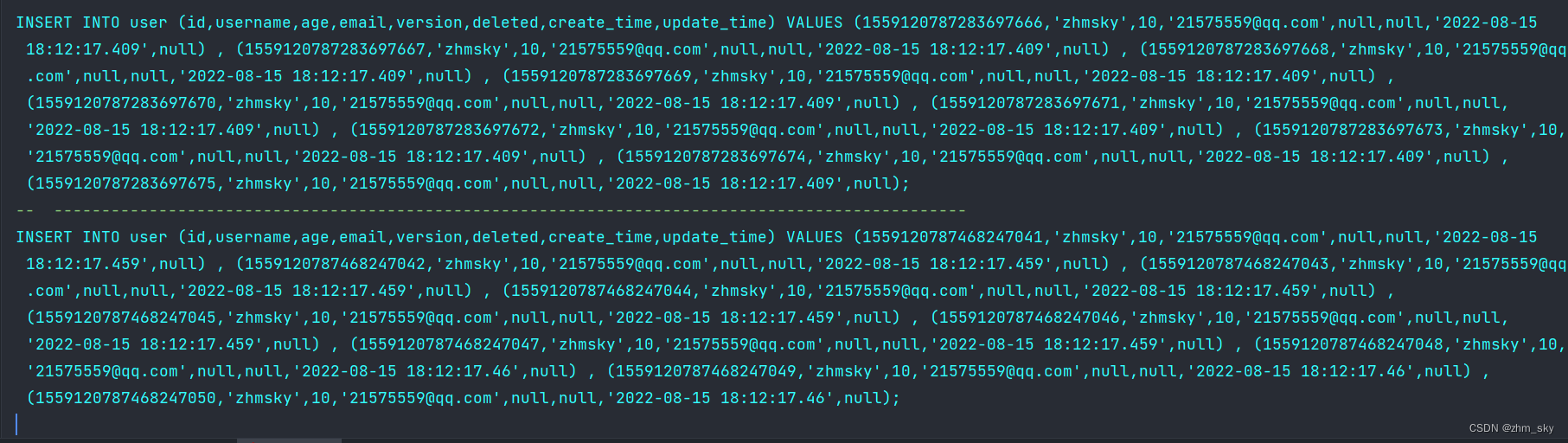
分批插入已满足,到此收工结束了。
接下来最重要的测试下性能
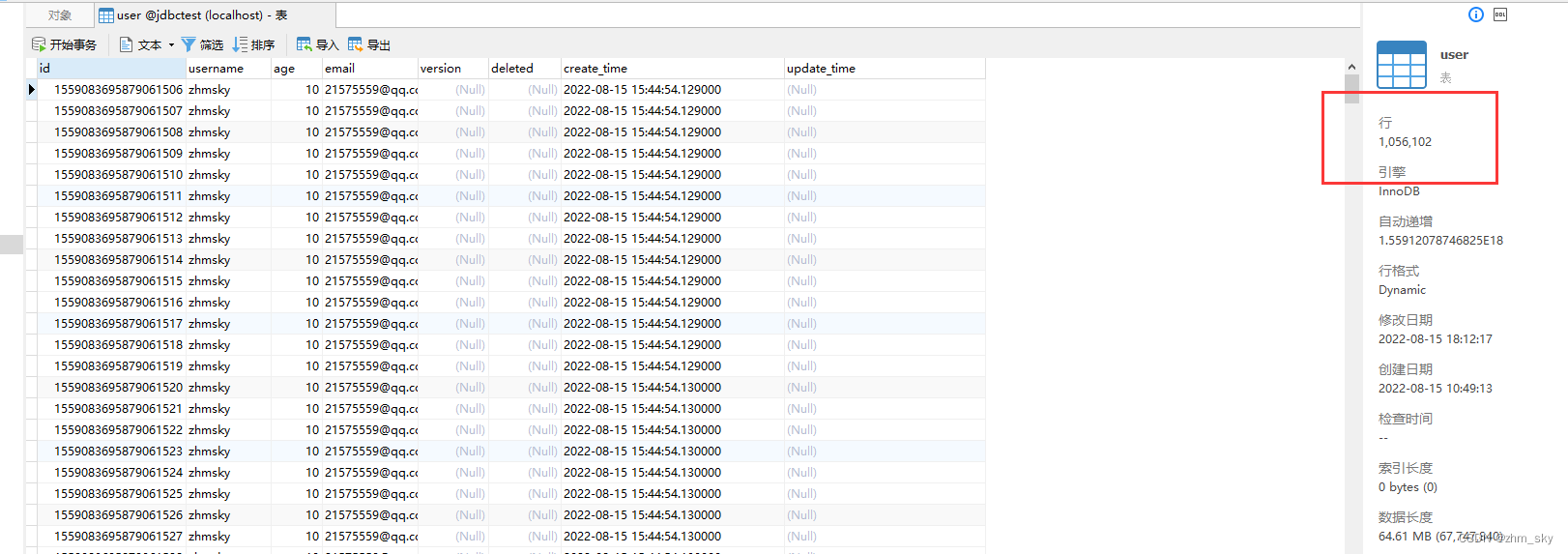
当前数据表的数据量在100w多条,在此基础上分别拿原始的saveBatch(假的批量插入)和 insertBatchSomeColumn(真正的批量插入)进行性能对比----(jdbc均开启rewriteBatchedStatements):
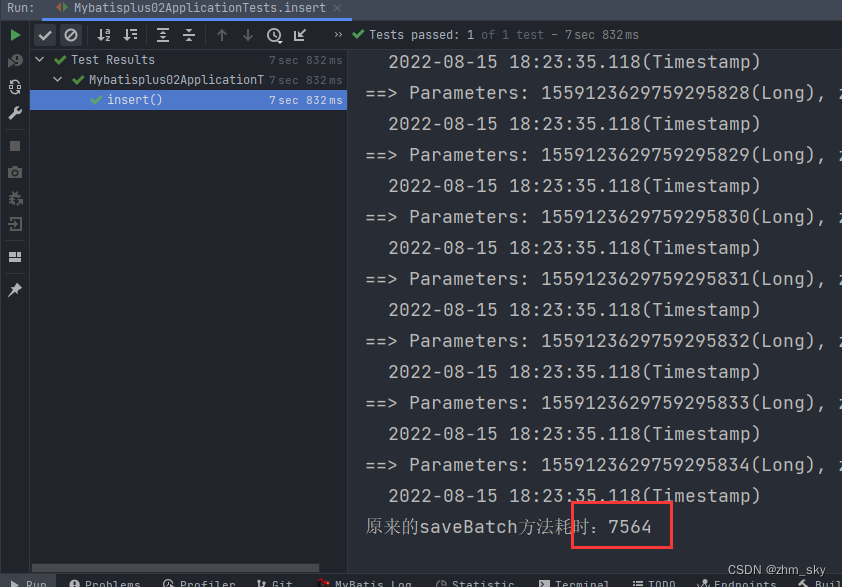
原来的假的批量插入:
@Testvoidinsert(){for(int i =0; i <50000; i++){User user =newUser();
user.setAge(10);
user.setUsername("zhmsky");
user.setEmail("[email protected]");
userList.add(user);}long l =System.currentTimeMillis();
userService.saveBatch(userList,1000);long l1 =System.currentTimeMillis();System.out.println("原来的saveBatch方法耗时:"+(l1-l));}
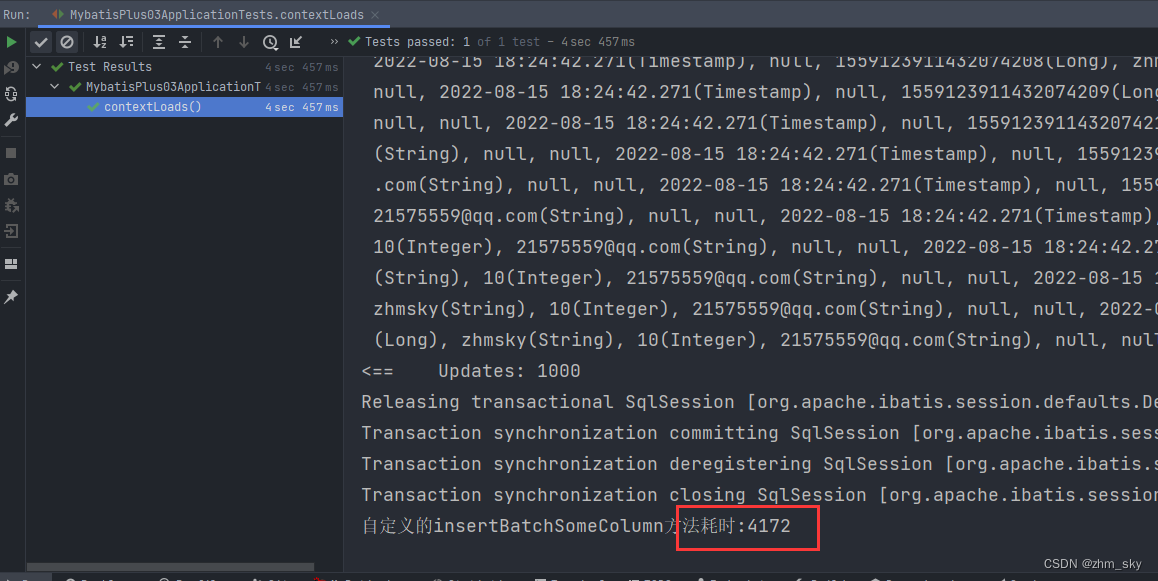
自定义的insertBatchSomeColumn:
@TestvoidcontextLoads(){for(int i =0; i <50000; i++){User user =newUser();
user.setAge(10);
user.setUsername("zhmsky");
user.setEmail("[email protected]");
userList.add(user);}long l =System.currentTimeMillis();
userService.saveBatch(userList,1000);long l1 =System.currentTimeMillis();System.out.println("自定义的insertBatchSomeColumn方法耗时:"+(l1-l));
userList.clear();}
分批插入5w条数据,自定义的真正意义上的批量插入耗时减少了3秒左右,用insertBatchSomeColum分批插入1500条数据耗时650毫秒,这速度已经挺快了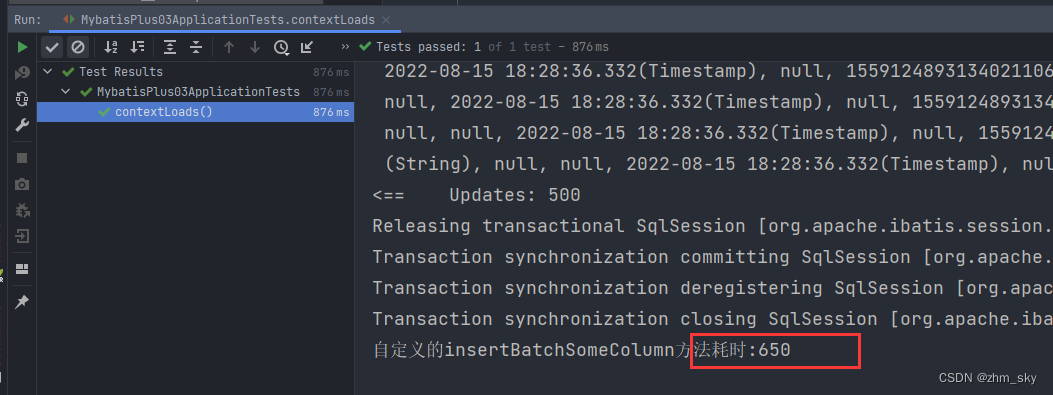
版权归原作者 zhm_sky 所有, 如有侵权,请联系我们删除。