
前言
前几期我们在云耀云服务器L实例上分别使用docker和直接在centos上部署了yolov5识别API,前端项目vue,后端项目.net Core Web Api,但是从监控图上来看,都没什么压力,调用接口也很流畅。
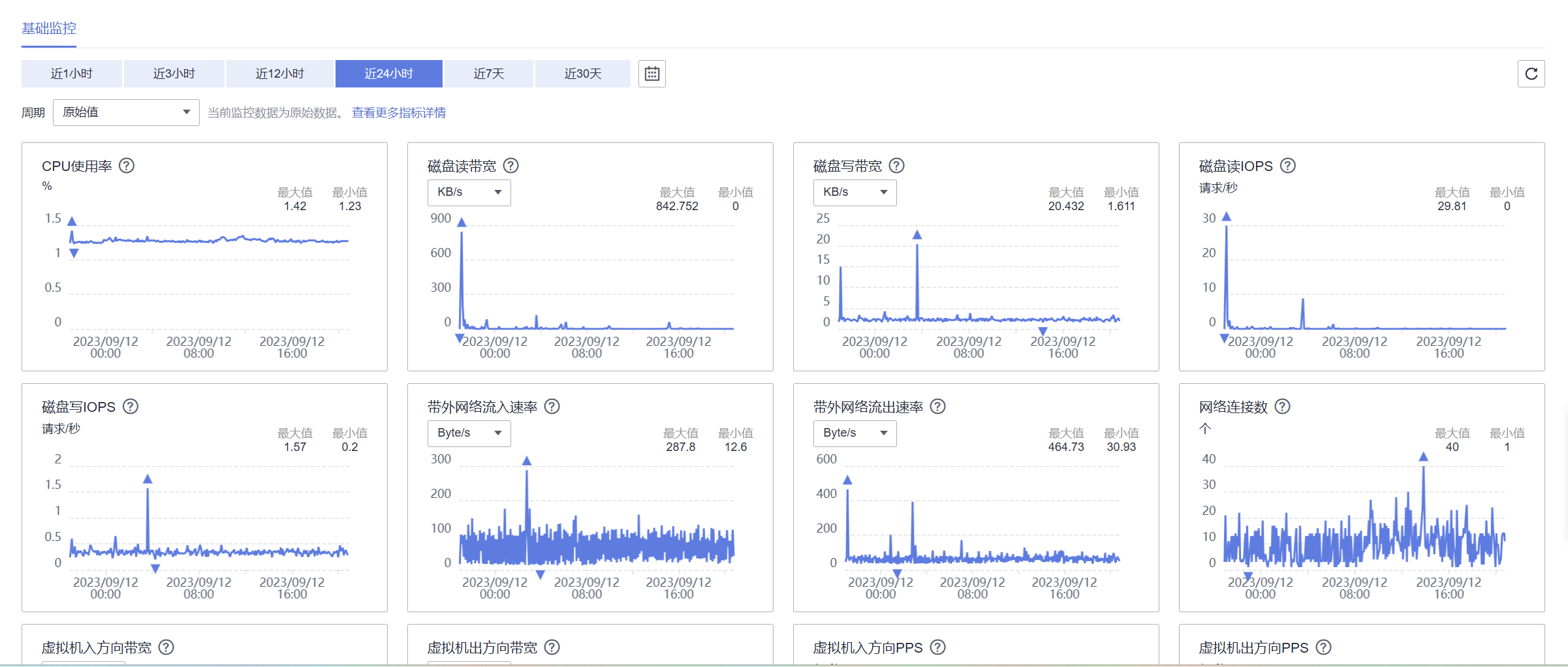
在实例介绍中看到,华为云擎天架构加持,软硬协同结合顶尖AI算法智能调度。于是有了一个疯狂的想法,这期我们给服务器来点压力,[坏笑!],这期我们要在服务器上部署yolov8进行AI模型训练。
YOLOv8 发布于2023 年 1月 10 号,是 ultralytics 公司在 开源的 YOLOv5 的下一个重大更新版本,是一种尖端的、最先进的 (SOTA) 模型

登录服务器
因为要训练AI模型,我们要处理图片,查看图片效果,方便起见,这次服务器我选择了系统镜像Windows Server

拿到服务器,第一步还是要重置密码,在控制台,找到对应的服务器,点击操作列的更多、重置密码。
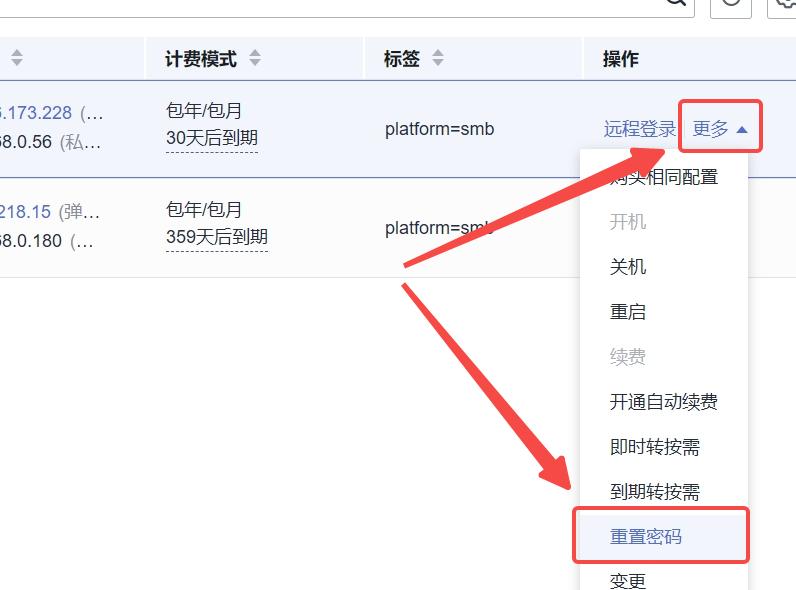
记得一定要勾选自动重启,这样我们的密码才能立马生效!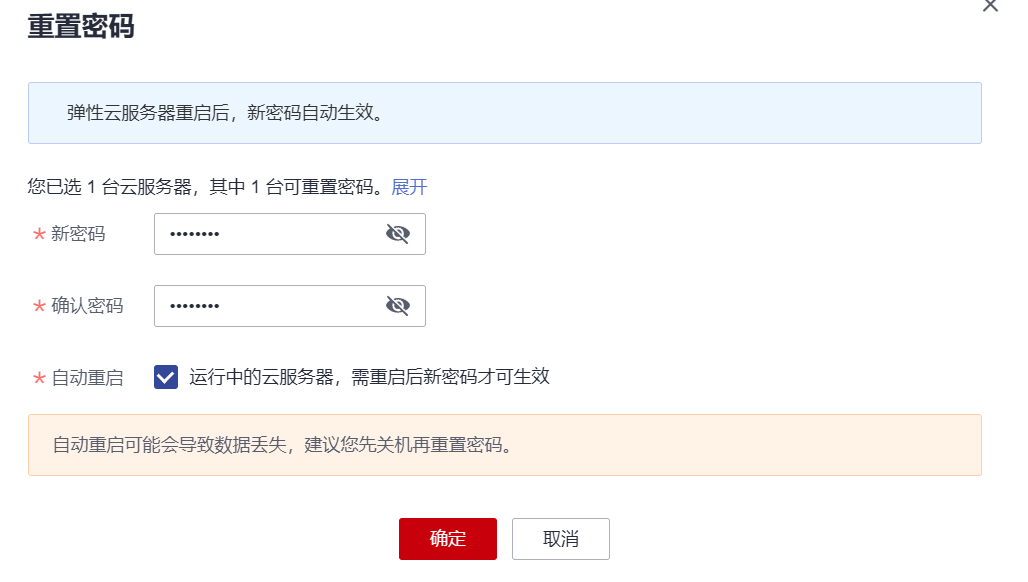
然后我们有两种方式来登录,一种是直接点击操作列的远程登录,在其他方式这里,点击立即登录来使用控制台提供的VNC方式登录!
或者快捷键Win + R ,在弹出的页面中输入 mstsc,确定!

然后在弹出的远程桌面连接中,输入我们服务器的弹性IP
然后在验证界面,点击下面的更多选择,选择其他账户
用户名:Administrator 密码:刚刚重置密码时你设置的密码
弹出的无法验证身份,点击是 !
然后就连上我们的服务器了,桌面非常干净,只有一个回收站!
安装pyhton
因为服务器上什么环境都没有,我们先来安装python3,在官网随便下一个大于大于3.8的python安装包,选择amd64的exe版本,安装的时候勾选最底下的帮我们添加环境变量
等待一会之后,出现下面这个界面就是安装成功了。
打开控制台,执行 python -V 和 pip -V ,看看我们的环境变量是否设置成功。

部署yolov8
去官网将yolov8的源码下载下来
ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite (github.com)

安装项目依赖
pip install ultralytics
pip install yolo
速度慢的话换国内镜像,在命令后面加上
-i https://pypi.tuna.tsinghua.edu.cn/simple numpy
安装Pytorch
到官网安装Pytorch
Start Locally | PyTorch
在安装之前看看自己买的服务器是否有GPU,可以使用命令来查看
- 查看CPU型号:cat /proc/cpuinfo | grep "model name"
- 查看GPU型号(Nvidia GPU):nvidia-smi --query-gpu=gpu_name --format=csv
- 查看GPU型号(AMD Radeon GPU):sudo lshw -C display
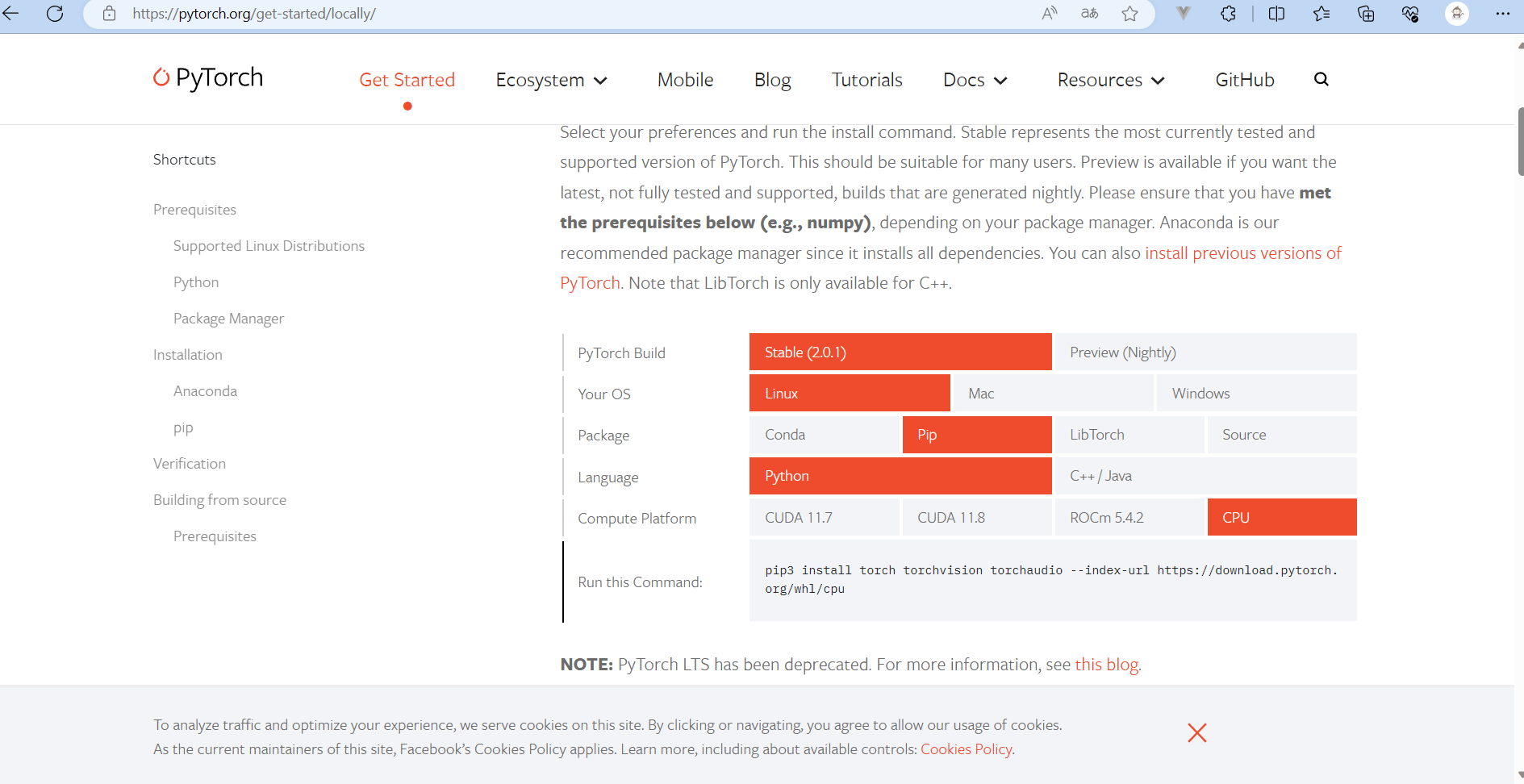
因为我这台是只有CPU的,因此在官网中选择Stable(稳定版),系统Linux,用pip来安装吧,然后Compute Platform选择CPU,然后把Run this Command:中的命令👇丢到服务器上去执行
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
下载权重文件
因为项目没有权重文件,跑命令的时候他会自己去官网下载权重文件,但是因为是从github上下载,太慢了,我选择自己下好再拉到服务器上。

在yolo中有几种识别模式,因为我们目的只是测试服务器性能,所以我们选择Classify,图像分类模型,他的素材比较好整理。
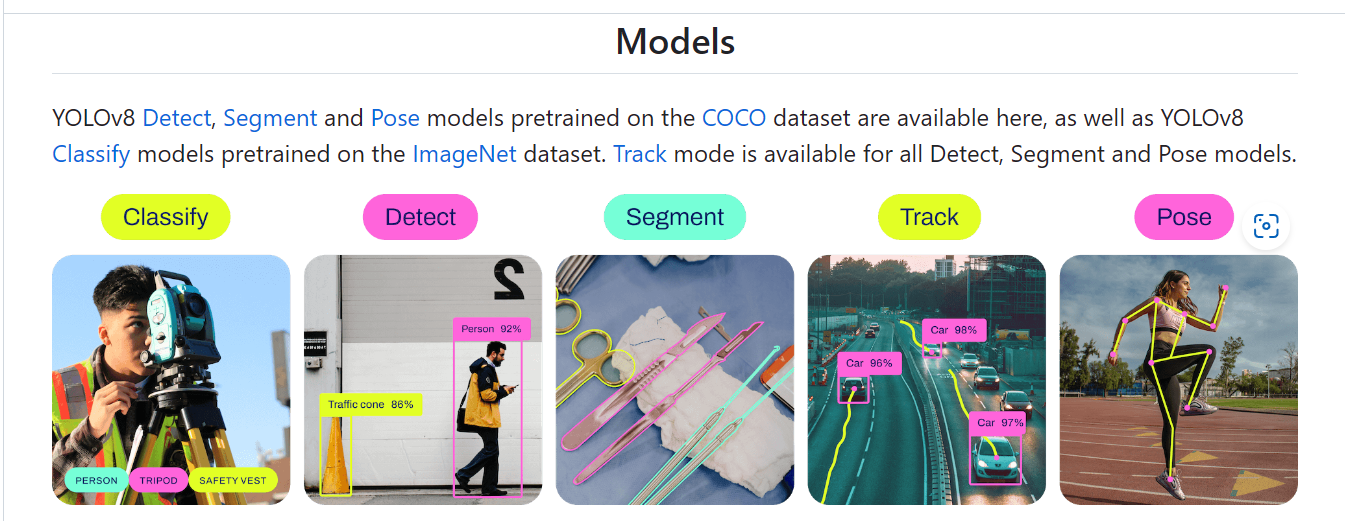
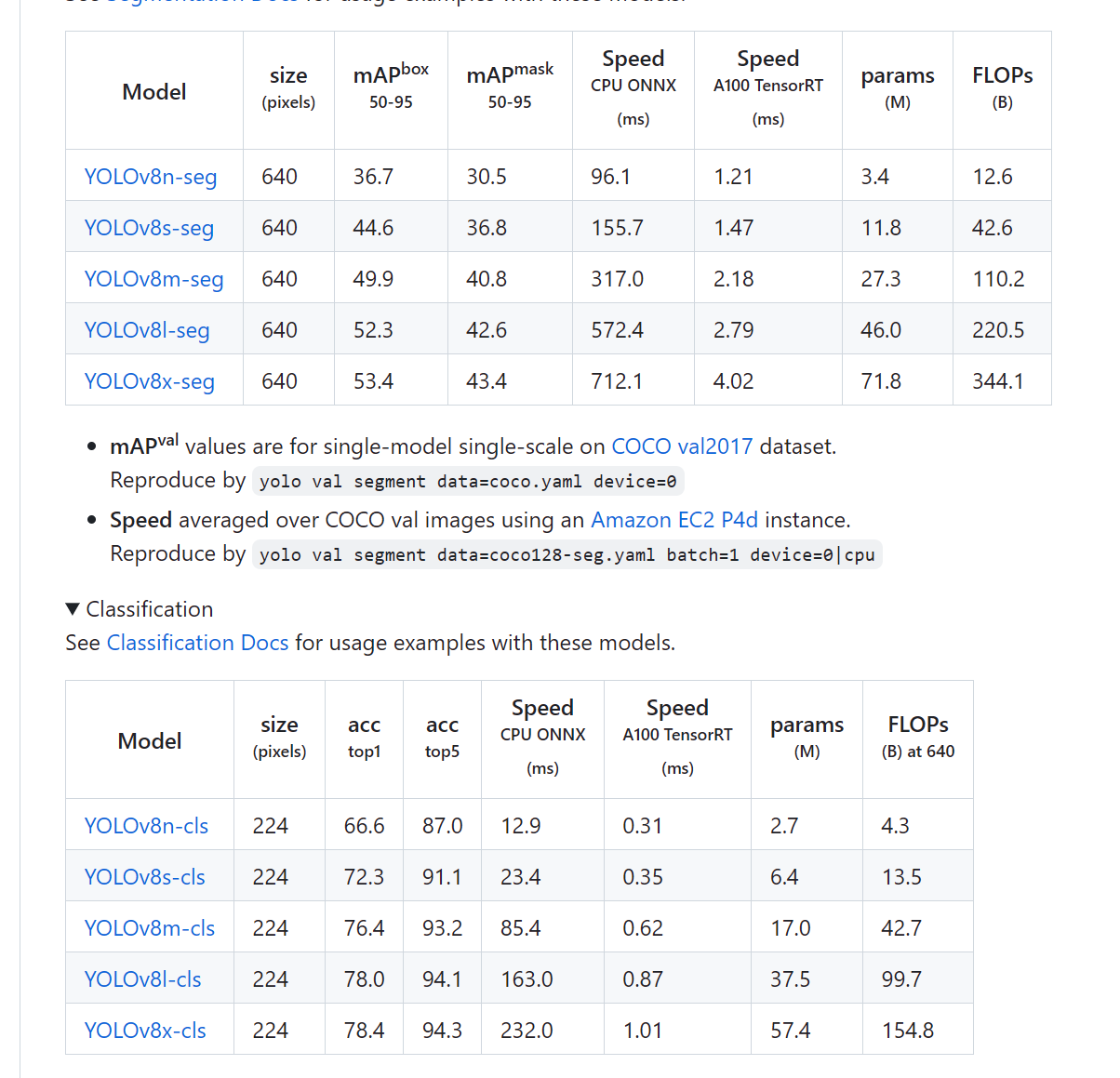
去到官网,找到下图中的模型表,点击model列的模型名字,就会自动下载了,然后丢到我们项目的根目录,不同的模型,识别的速度,目标大小,准确度都不一样,并且对电脑性能的要求也不一样,在官网中都有详细介绍。这里我测试使用的是yolov8s-cls
ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLite (github.com)
项目部署好了,模型有了,接下来就差数据集了,像下图中这种格式,我们只需要以类名称为文件夹,然后在统一放到一个大文件夹下面就好了,因为分类识别只需要识别出这个图片是什么,而不需要知道具体在什么位置,因此不需要进行标注,所以他的数据集是最简单的,这也是为什么我选择这个模型在这里做演示。

训练模型
然后我们执行命令来开始训练模型了。
yolo detect train data=你放数据集的路径 model=yolov8s-cls.pt epochs=100 imgsz=640
执行完发现报了下图的错,缺少msvc-runtime库,使用下面命令安装
pip install msvc-runtime

然后再执行一次识别命令,可以看到大概1分钟一轮,
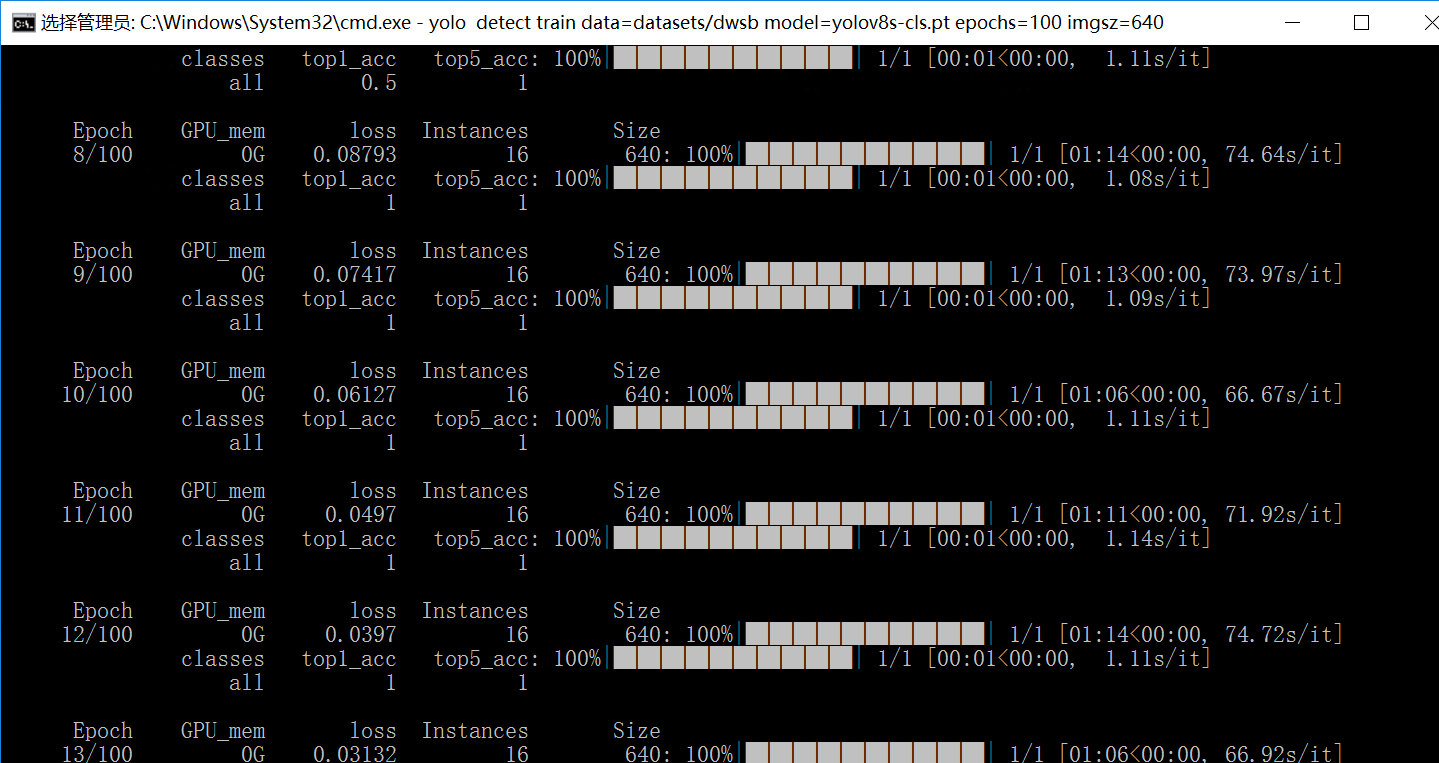
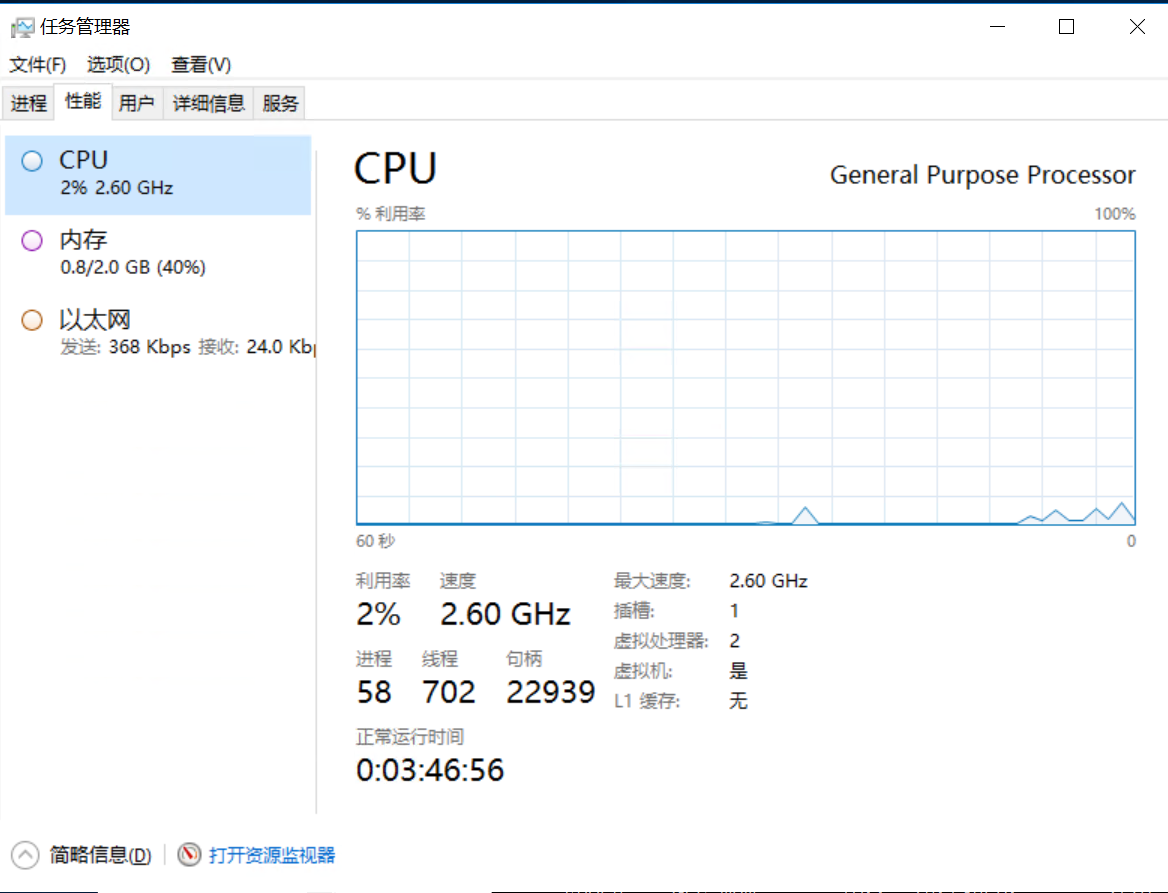
看一下性能监视器,我只能说,遥遥领先!说实话我一开始觉得他会直接宕机的,没想到居然可以一分钟一轮的训练,这已经是很好的成绩了
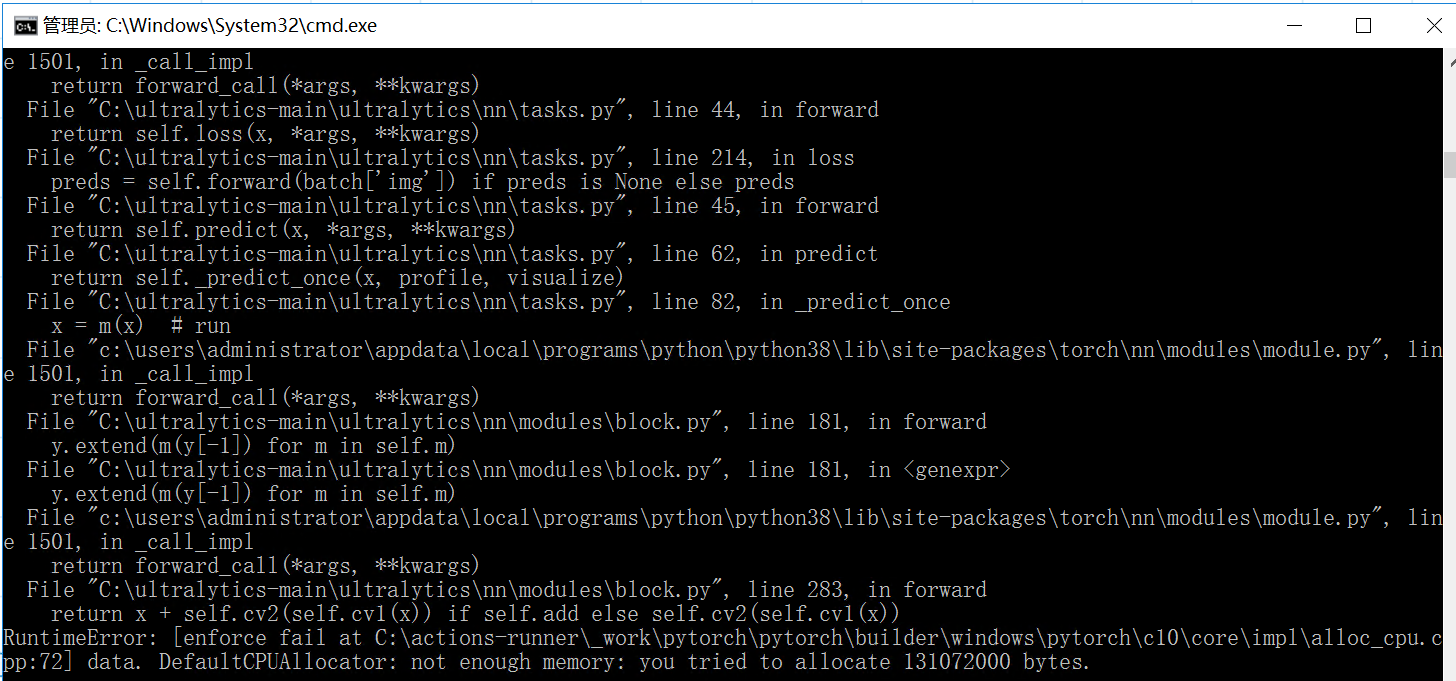
换成最大的模型再试一次,服务器没有死撑,把任务停掉了,控制台打印内存不足,意料之中,不过能带的动s模型已经很不错了。
模型使用
在一段时间的等待之后,模型训练完成会出现如下信息。
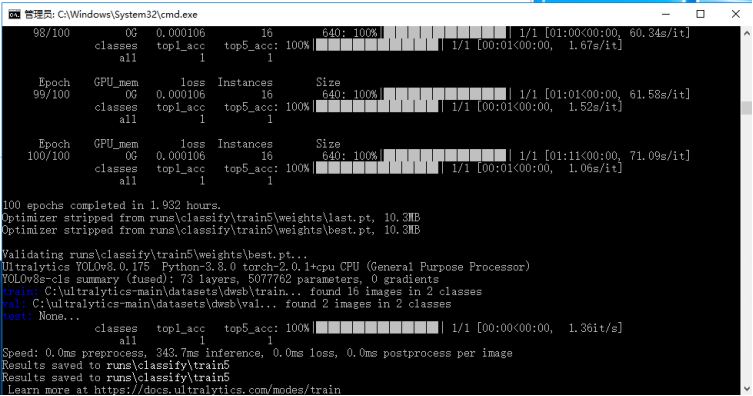
然后在我们项目路径的runs/classify下会有我们每次训练保存的数据,如生成的confusion_matrix是一个混淆矩阵的可视化图像,用于展示模型在不同类别上的分类效果,通过观察非对角线上的数值,我们可以了解模型在哪些类别上容易发生错误分类,进而对模型进行调整和改进。

打开weights文件夹,这里面就是我们训练好的模型了,可以看到这里有bset和last两个权重文件。
- best.pt文件保存的是在验证集上表现最好的模型权重。在训练过程中,每个epoch结束后都会对验证集进行一次评估,并记录下表现最好的模型的权重。这个文件通常用于推理和部署阶段,因为它包含了在验证集上表现最好的模型的权重,可以获得最佳的性能。
- last.pt文件则保存的是最后一次训练迭代结束后的模型权重。这个文件通常用于继续训练模型,因为它包含了最后一次训练迭代结束时的模型权重,可以继续从上一次训练结束的地方继续训练模型。
简单来说就是best是最好的,last是最后的,所以我们接下来使用这个模型来识别一下。
使用yolo predict来进行识别,model就是我们刚刚训练好的模型,source是你要拿来识别的图片文件夹路径
yolo predict model=runs/classify/train/weights/best.pt source=datasets/test
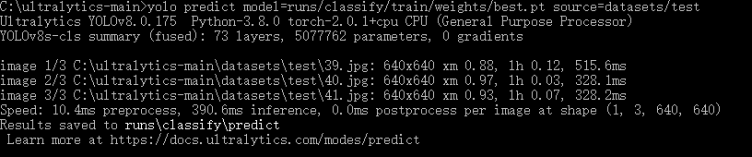 命令执行完成之后,还是在runs/classify 识别结果文件夹名称是predict,在图片左上角,xm 0.97,这个xm就是熊猫的意思,是我自己设置的拼音缩写,因为opencv不支持中文,会出现乱码问题,0.97就是识别的conf,意思他有9.7成把握这是熊猫!
命令执行完成之后,还是在runs/classify 识别结果文件夹名称是predict,在图片左上角,xm 0.97,这个xm就是熊猫的意思,是我自己设置的拼音缩写,因为opencv不支持中文,会出现乱码问题,0.97就是识别的conf,意思他有9.7成把握这是熊猫!

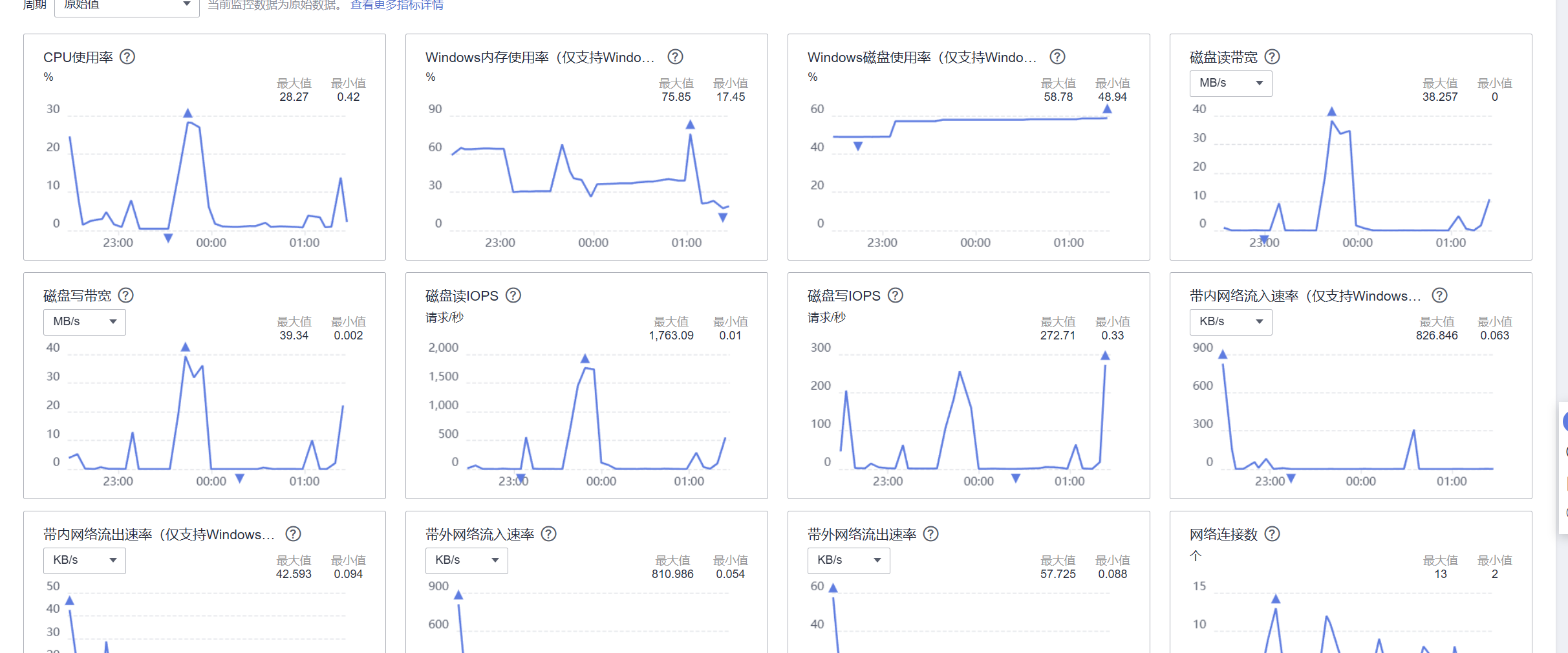
再看一下控制台的监控,我们刚刚在整个训练s模型的过程中,虽然波动有点大,但是对服务器来说还不算构成太大压力。 这一期对云耀云服务器L实例的表现还是相当满意的!
版权归原作者 爱吃香蕉的阿豪 所有, 如有侵权,请联系我们删除。