
文章目录
前言
CSDN上已经有很多大佬发过Xpath,而且讲的都很好,我是因为刚开始学习网络爬虫,对这些基础重要知识不太了解,所以写一下来加深印象,本篇文章只是简单介绍一下Xpath及使用,总体来说比较基础。
一、Xpath简介
XPath(XML Path Language - XML路径语言),它是一种用来确定XML文档中某部分位置的语言。
Xpath以XML为基础,提供用户在数据结构树中寻找节点的能力,Xpath被很多开发者亲切的称为
小型查询语言
。
二、Xpath语法规则
xpath可以使用路径表达式在XML上选取节点,从而达到确认元素的目的,我们先来介绍以下语法规则。
语法规则
表达式作用nodename选取此层级节点下的所有子节点/代表从根节点进行选取//可以理解为匹配,就是在所有节点中选取此节点,直到匹配为止.选取当前节点…选取当前节点上一层(上一级目录)@选取属性(也是匹配)
标签定位
方式效果/html/body/div表示从根节点开始寻找,标签与标签之间/表示一个层级/html//div表示多个层级 作用于两个标签之间(也可以理解为在html下进行匹配寻找标签div)//div从任意节点开始寻找,也就是查找所有的div标签./div表示从当前的标签开始寻找div
属性定位
需求格式定位div中属性名为href,属性值为‘www.baidu.com’的div标签@属性名=属性值href为属性名 'www.baidu.com’为属性值/html/body/div[href=‘www.baidu.com’]
索引定位
需求格式定位ul下第二个li标签(下图)//ul/li[2]索引值开始位置为1
取文本内容
方法效果/text()获取标签下直系的标签内容//text()获取标签中所有的文本内容string()获取标签中所有的文本内容
在网页上获取Xpath其实很容易,直接找到标签后,右键复制就好了。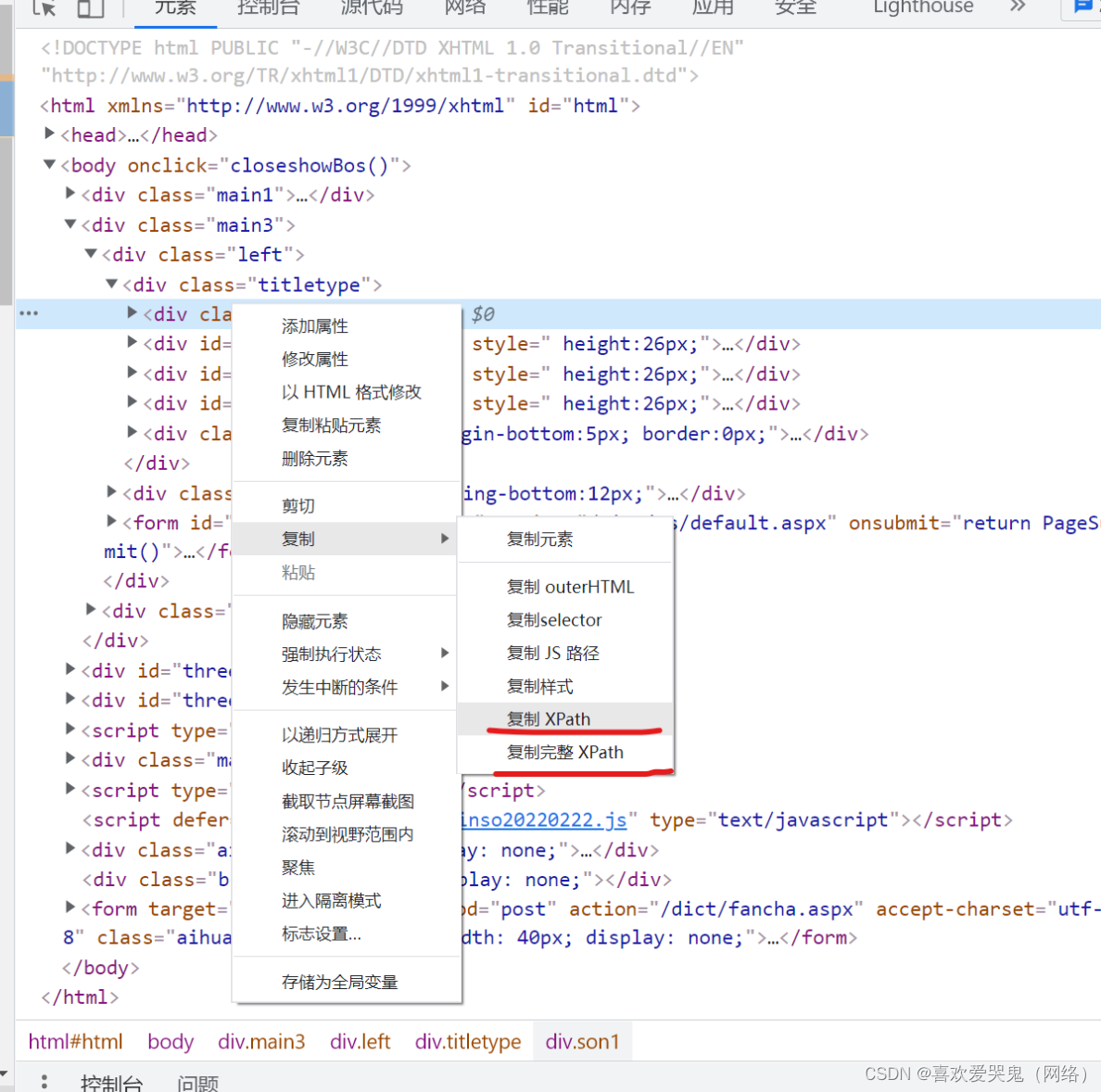
三、语法规则练习
接下来我们开始练习一下本地导入,加深一下理解,这个是一个比较简单的网页结构,我们先学会用法即可。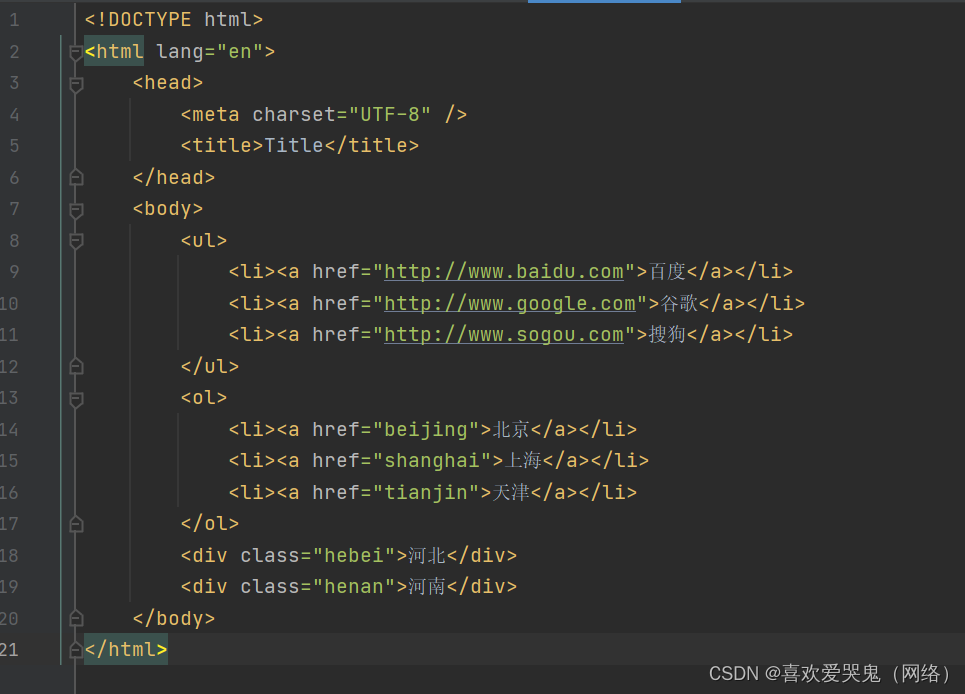
任务要求: 可以达到随心所欲的定位每一个元素
准备工作
#导入所需要的包from lxml import etree
#采用本地源码获取方式并加载到etree内
tree = etree.parse('test.html')
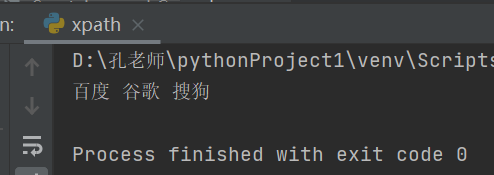
1.获取百度、谷歌、搜狗文本内容
#引用xpath方法并进行标签定位#''.join是取字符串内的内容
text =' '.join(tree.xpath('/html/body/ul/li/a/text()'))print(text)
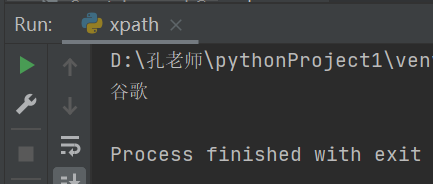
2.获取单个谷歌
text1 = tree.xpath("//ul/li[2]/a/text()")[0]print(text1)
3.获取北京、上海、天津的属性值
text2 =' '.join(tree.xpath("//ol/li/a/@href"))print(text2)

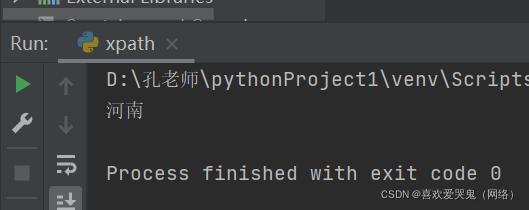
4.获取河南文本
#获取河南文本
text3 = tree.xpath("/html/body/div[2]/text()")[0]print(text3)
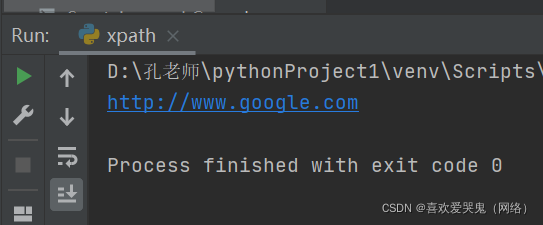
5.获取谷歌属性值
text4 = tree.xpath("//ul/li[2]/a/@href")[0]print(text4)
至此我们已经可以随心定位任意标签 完成任务 收工
版权归原作者 秦同学学学 所有, 如有侵权,请联系我们删除。