
文章目录
一. 下载Flink安装包并解压
cd /home/software
https://archive.apache.org/dist/flink/flink-1.14.5/flink-1.14.5-bin-scala_2.12.tgz
tar -xvf flink-1.14.5-bin-scala_2.12.tgz -C /home
二. 修改配置
2.1 用户环境变量
vi /etc/profile
export FLINK_HOME=/home/flink-1.14.5
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
export HADOOP_CLASSPATH=`hadoop classpath`
export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$FLINK_HOME/bin
2.2 flink-conf.yaml
前面三个只要放开就好,第四个指定zk复用(相当于 hp5:2181,hp6:2181,hp7:2181,带目录是因为zk集群不止给flink用还有kafka等)
hdfs dfs -mkdir /flink-cluster
hdfs dfs -mkdir -p /vmcluster/flink/ha/
hdfs dfs -mkdir -p /vmcluster/flink-checkpoints
hdfs dfs -mkdir -p /vmcluster/flink-savepoints
hdfs dfs -mkdir -p /vmcluster/completed-jobs/
hdfs dfs -mkdir -p /vmcluster/flink/ha/flink-cluster
cd /home/flink-1.14.5/conf/
vi flink-conf.yaml
jobmanager.rpc.address: hp5
jobmanager.rpc.port: 6123
jobmanager.memory.process.size: 1600m
taskmanager.memory.process.size: 1728m
taskmanager.numberOfTaskSlots: 3
parallelism.default: 1
high-availability: zookeeper
high-availability.cluster-id: /flink-cluster
high-availability.storageDir: hdfs://hp5:8020/vmcluster/flink/ha/
high-availability.zookeeper.quorum: hp5:2181,hp6:2181,hp7:2181
state.backend: filesystem
state.checkpoints.dir: hdfs://hp5:8020/vmcluster/flink-checkpoints
state.savepoints.dir: hdfs://hp5:8020/vmcluster/flink-savepoints
jobmanager.execution.failover-strategy: region
jobmanager.archive.fs.dir: hdfs://hp5:8020/vmcluster/completed-jobs/
historyserver.archive.fs.dir: hdfs://hp5:8020/vmcluster/completed-jobs/
classloader.check-leaked-classloader: false
hdfs路径:
此处是hp5:8020
具体参考core-site.xml配置文件中的fs.default.name属性
2.3 配置${FLINK_HOME}/conf/masters文件
cd ${FLINK_HOME}/conf/
vi masters
hp5:8081
2.4 配置${FLINK_HOME}/conf/workers文件
cd ${FLINK_HOME}/conf/
vi workers
hp5
hp6
hp7
2.5 将flink目录传到其它节点
scp -r /home/flink-1.14.5 root@hp6:/home/
scp -r /home/flink-1.14.5 root@hp7:/home/
三. flink Standalone部署模式
3.1 启动flink Standalone
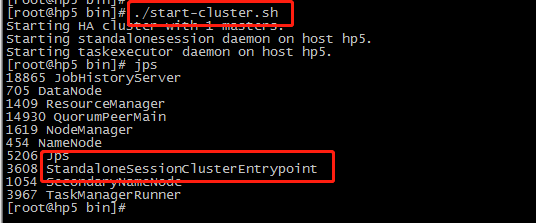
cd /home/flink-1.14.5/bin/
./start-cluster.sh
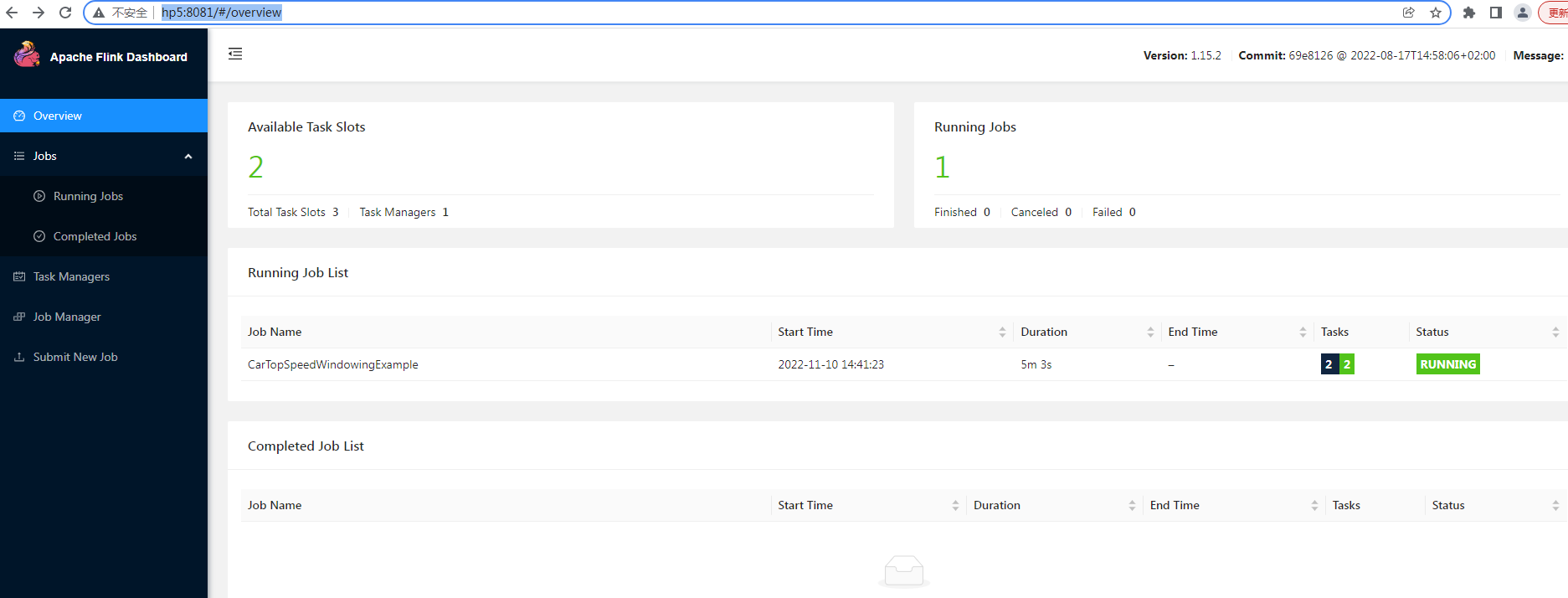
3.2 测试运行Flink程序
flink run /home/flink-1.14.5/examples/streaming/TopSpeedWindowing.jar

web页面查看:
8081是默认端口
http://hp5:8081/
四. flink on yarn部署模式
注意:
确保hdfs和yarn集群运行正常。
4.1 Application Mode
部署服务是一个消耗资源比较大的服务,并且很难计算出实际资源限制,Flink 1.11 引入了另外一种部署选项 Application Mode, 该模式允许更加轻量级,可扩展的应用提交进程,将之前客户端的应用部署能力均匀分散到集群的每个节点上。由于每个应用程序有一个JobManager,因此可以更平均地分散网络负载。Application 模式允许提交由多个Job组成的应用程序。Job执行的顺序受启动Job的调用的影响不受部署模式的影响。
Application Mode将在YARN上启动一个Flink集群,其中Application jar的main()方法将在YARN中的JobManager上执行。应用程序一完成,集群就会立即关闭。你可以手动停止集群使用yarn application -kill 或者 cancelling Flink job。
4.1.1 提交flink job
flink run-application -t yarn-application /home/flink-1.14.5/examples/streaming/TopSpeedWindowing.jar
页面提交成功后,就退出了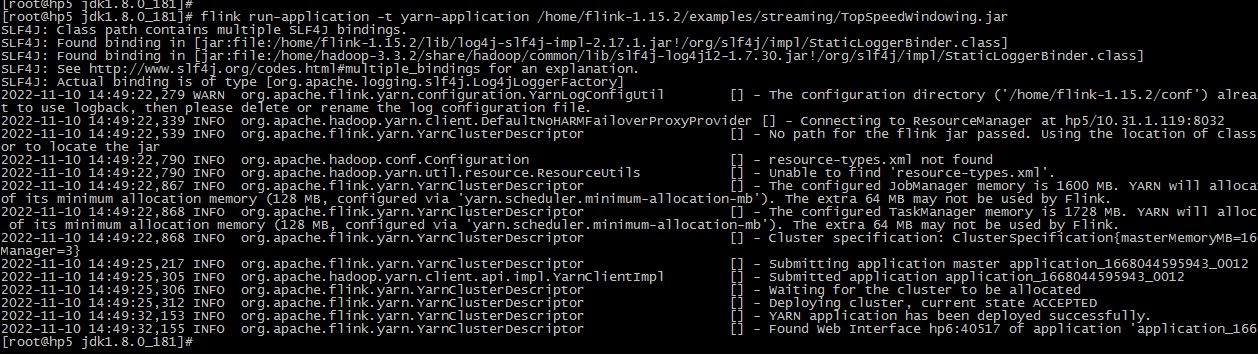
界面查看,yarn中有一个Flink程序在运行。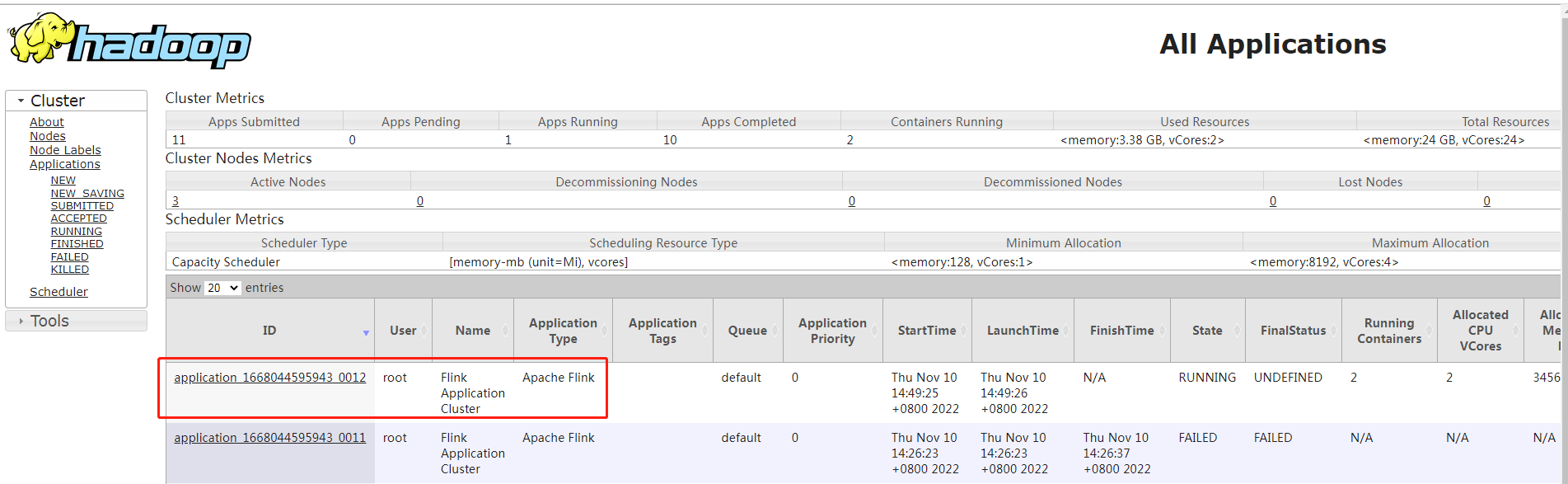
4.1.2 kill flink job
命令行形式:
yarn application -kill application_1668044595943_0012

web 界面 cancel job: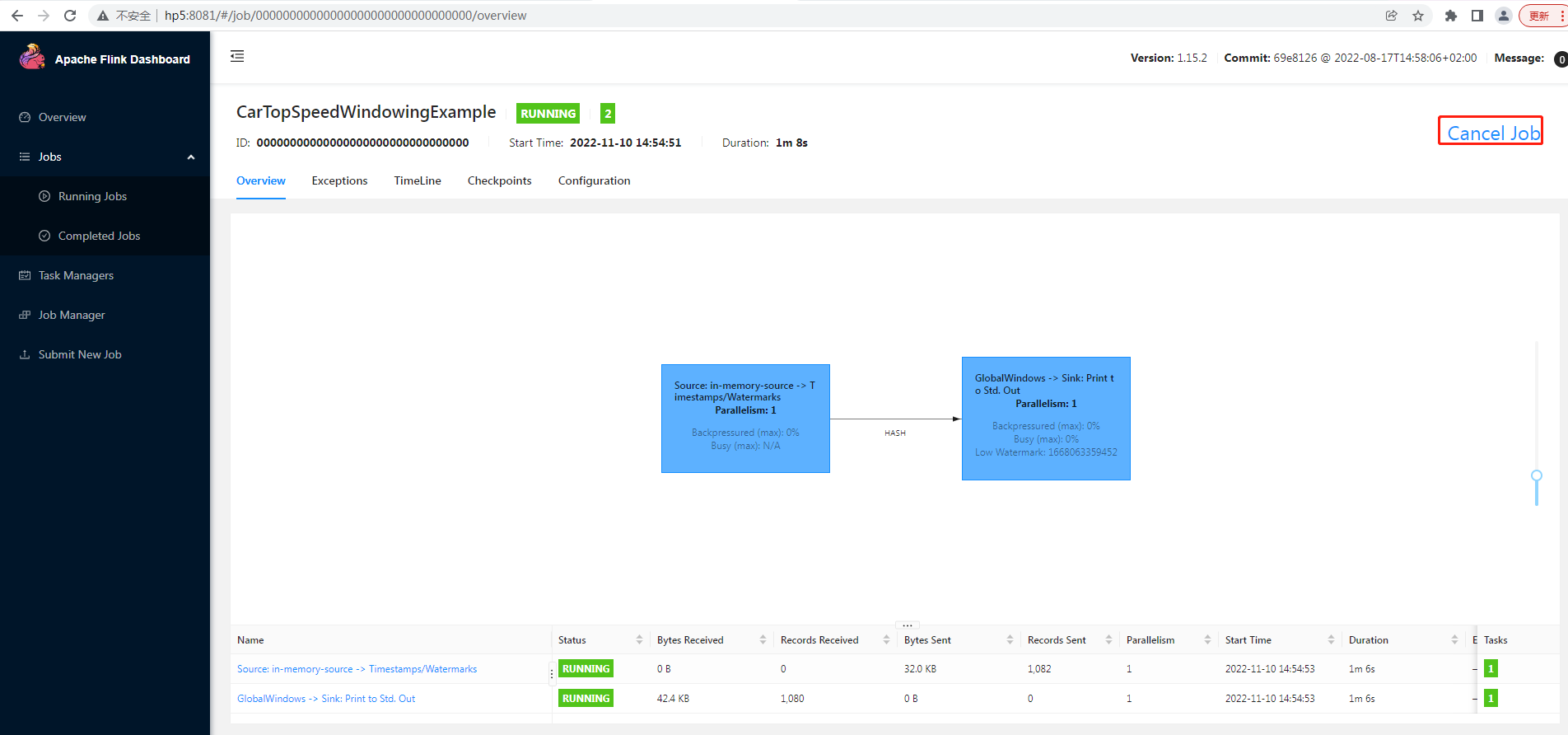
4.2 Per-Job Cluster Mode
直接提交任务给YARN,大作业的场景,使用这种方式。每个Job都有一个JobManager,每个TaskManager只有单个Job。
Per-job Cluster Mode 将在YARN上启动Flink集群,然后在本地运行提供的application jar,最后将JobGraph提交给YARN上的JobManager。如果你传递 --detached参数,client将在提交被接受后停止。
flink run -t yarn-per-job --detached /home/flink-1.14.5/examples/streaming/TopSpeedWindowing.jar
4.3 Session Mode
使用Flink中的Yarn-session(yarn客户端),会启动两个必要的服务JobManager和TaskManager。客户端通过yarn-session提交作业,yarn-session会一直启动,不停地接收客户端提交的作业,有大量的小作业,适合使用这种方式。
在session模式下,集群中的所有作业只有一个JobManager,Job 被随机分配给TaskManager。
yarn-session.sh -n 1 -jm 256 -tm 256
jps
参考:
版权归原作者 只是甲 所有, 如有侵权,请联系我们删除。