
《肖申克的救赎》通过深刻的人性描绘、对自由的追求、对希望的坚持以及对救赎的探讨,向我们展示了一个充满哲理和人生智慧的世界。它告诉我们,无论生活多么艰难,只要我们有信念、有希望、有勇气,就能找到属于自己的救赎之路。
认识Spark
首先简单介绍了Spark的发展历史、Spark的特点,然后介绍了Spark的生态圈和Spark的应用场景。接着详细介绍单机模式、单机伪分布式模式和完全分布式模式下Spark集群的搭建过程。最后重点介绍了Spark的架构、Spark作业的运行流程和Spark的核心数据集RDD。
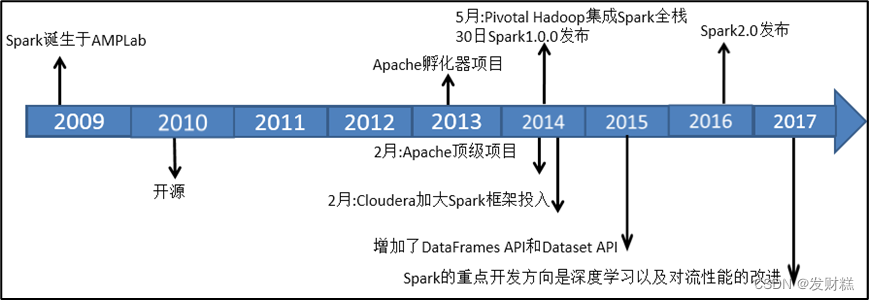
认识spark之发展史
Spark****之特点
快速、易用、通用、随处运行、代码简洁
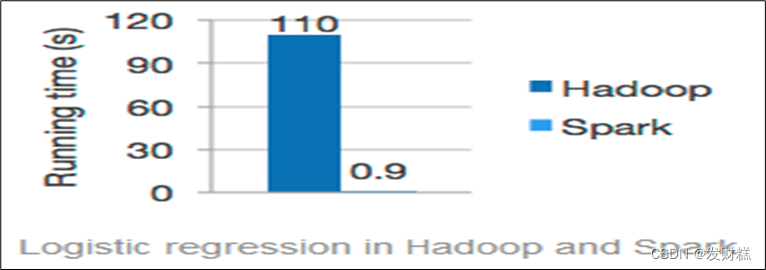
- 快速:一般情况下,对于迭代次数较多的应用程序,Spark程序在内存中的运行速度是Hadoop MapReduce运行速度的100多倍,在磁盘上的运行速度是Hadoop MapReduce运行速度的10多倍。

- 易用:Spark支持使用Scala、Python、Java及R语言快速编写应用。同时Spark提供超过80个高阶算子,使得编写并行应用程序变得容易,并且可以在Scala、Python或R的交互模式下使用Spark。



- 通用:Spark可以与SQL、Streaming及复杂的分析良好结合。Spark还有一系列的高级工具,包括Spark SQL、MLlib(机器学习库)、GraphX(图计算)和Spark Streaming(流计算),并且支持在一个应用中同时使用这些组件。

** 4.随处运行:用户可以使用Spark的独立集群模式运行Spark,也可以在EC2(亚马逊弹性计算云)、Hadoop YARN或者Apache Mesos上运行Spark。并且可以从HDFS、Cassandra、HBase、Hive、Tachyon**和任何分布式文件系统读取数据。
** 6.代码简洁:**
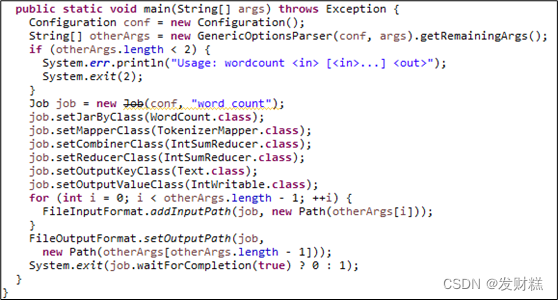
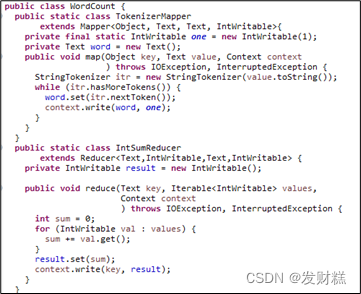
Spark****之搭建
Spark****集群的环境可分为单机版环境、单机伪分布式环境和完全分布式环境。
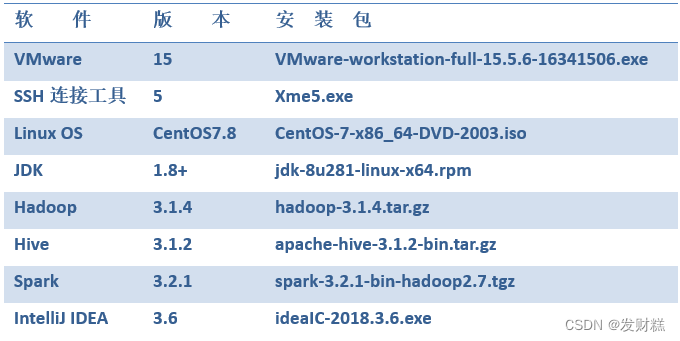
软件环境:
搭建单机版集群
- 下载Spark安装包到Windows本地。
- 将Spark安装包上传到Linux的/opt****目录下。
- 将Spark安装包解压到/usr/local目录下。
- 进入到Spark安装包的bin目录下,使用SparkPi来计算Pi的值,其中参数2****是指两个并行度,运行结果如下。
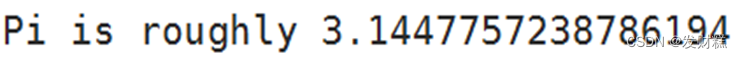
搭建单机伪分布式集群
Spark单机伪分布式是在一台机器上既有Master,又有Worker进程。搭建Spark单机伪分布式环境可在Hadoop****伪分布式的基础上进行搭建。
搭建Spark****单机伪分布式集群的步骤如下。
将Spark安装包解压到/usr/local目录下。
进入到Spark安装包的conf目录下,将spark-env.sh.template复制为spark-env.sh。
打开spark-env.sh****文件,在文件末尾添加如下所示的内容。
目录切换到sbin****目录下启动集群。
jps****查看进程。
使用计算SparkPi来计算Pi的值。


搭建完全分布式集群
搭建Spark完全分布式集群的步骤如下。
将Spark安装包解压至/usr/local目录下。
切换至Spark安装目录的/conf目录下。
配置文件。
在主节点(master节点)中,将配置好的Spark安装目录远程复制至子节点(slave1、slave2节点)的/usr/local目录下。
启动Hadoop集群,并创建/spark-logs目录。
jps查看进程。
切换至Spark安装目录的/sbin目录下,启动Spark集群。
启动关闭Spark
- 启动Spark
cd /usr/local/spark-3.2.1-bin-hadoop2.7/
sbin/start-all.sh
sbin/start-history-server.sh
- 关闭Spark
cd /usr/local/spark-3.2.1-bin-hadoop2.7/
sbin/stop-all.sh
sbin/stop-history-server.sh
了解Spark核心数据集RDD
RDD(Resilient Distributed Datasets弹性分布式数据集),可以简单的把RDD理解成一个提供了许多操作接口的数据集合,和一般数据集不同的是,其实际数据分布存储于一批机器中(内存或磁盘中)。


了解Spark核心原理
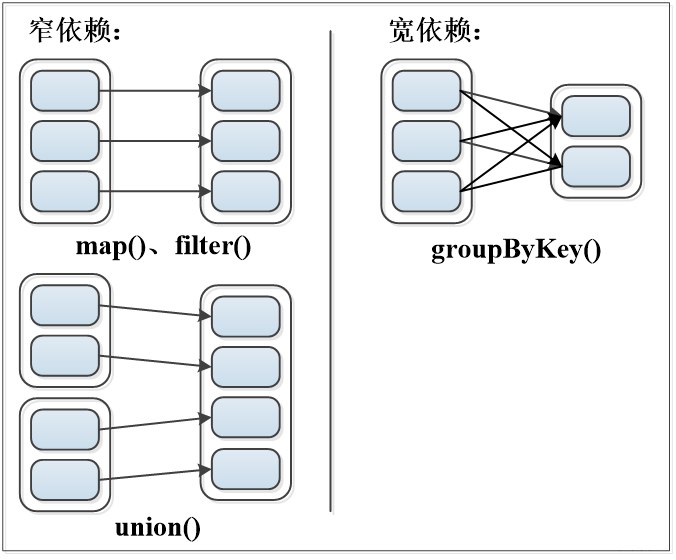
- 窄依赖:表现为一个父RDD的分区对应于一个子RDD的分区或者多个父RDD的分区对应于一个子RDD的分区。
- 宽依赖:表现为存在一个父RDD的一个分区对应一个子RDD的多个分区。
小结
- 首先简单介绍了Spark的发展历史、Spark的特点,然后介绍了Spark的生态圈和Spark的应用场景。
- 接着详细介绍单机模式、单机伪分布式模式和完全分布式模式下Spark集群的搭建过程。
- 最后重点介绍了Spark的架构、Spark作业的运行流程和Spark的核心数据集RDD。
版权归原作者 发财糕 所有, 如有侵权,请联系我们删除。