
Doris 学习日常记录
(记录学习过程和遇到的坑,仅是个人学习使用)
怕自己忘记特来记录一下学习Doris 的学习过程和遇到的各种坑。文中图片,文字知识点大多来自网络,如果有不妥之处,请指出,马上修改或是删除;
Doris浅略介绍
关键词:实时数据仓库 ( 之前叫百度 Palo,2018年贡献到 Apache 社区后,更名为 Doris )
身份:基于大规模并行处理技术的分布式 SQL 数据库,百度在 2017 年开源,2018 年 进入 Apache 孵化器。新浪微博,美团,小米都有使用。
定位:
MPP 架构 ( Massively Parallel Processing ),即大规模并行处理。将任务并行的分散到多个服务器和节点上,在每个节点上计算完成后,将各自部分的结果汇总在一起得到最终的结果 ( 与 Hadoop 相似 )。每个执行器有单独的CPU,内存和硬盘资源。节点之间的信息交互只能通过节点互联网络实现的,这个过程称为数据重分配。
其优点:MPP架构不用将中间数据写入磁盘,单一的执行器只会处理一个单一的任务,直接将数据stream到下一个执行阶段。这个过程称为流水线技术(时间并行),它提供了很大的性能提升。
也有缺陷:对于MPP架构来说,因为任务和节点的绑定,如果某个执行器执行过慢或故障,会导致整个集群的性能限于这个故障节点的执行速度(就是木桶短板效应)。另集群中的节点越多,则某个节点出现问题的概率越大,而一旦有节点出现问题,对于MPP架构来说,将导致整个集群性能受限,所以一般实际生产中MPP架构的集群节点不易过多。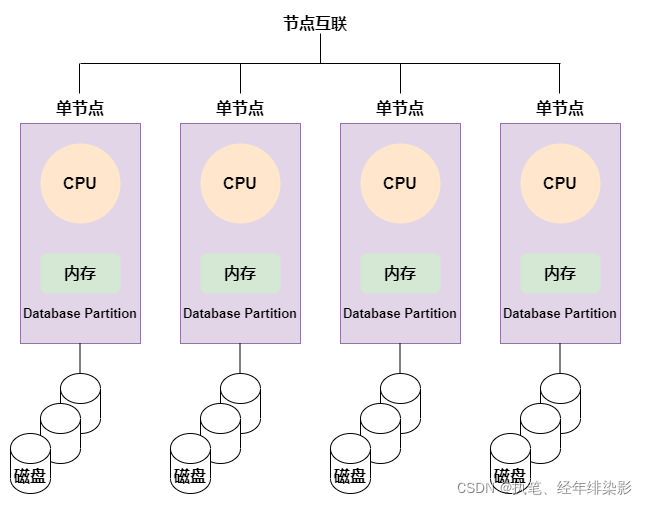
PB (2的50次方)级别大数据集,秒级/毫秒级查询。(如果高于 PB 级别,不推荐使用 Doris 解决,可以考虑用 Hive 等工具),解决结构化数据,查询时间一般在秒级或毫秒级。
doris 优点:
通过扩建集群实现高并发,可扩展200台机器以上;
兼容mysql,不依赖外部存储系统多副本,元数据高可用;
主要用于多维分析和报表查询;
MPP的运行框架,充分挖掘多核CPU的并行计算能力;
分布式架构支持多副本支撑高可用;
采取分区分桶的机制,支持多种索引技术,满足PB级的存储和分析能力;
支持Mysql协作,简单、易用;
列式存储和压缩技术,提升查询性能;
Doris 主要整合了
Google Mesa(取 数据模型): Mesa是 2014年 Google 内部,为解决其在线广告报表和分析业务,拥有准实时的数据更新能力和低延迟的数据查询性能,实现的可扩展的分析型数据仓库系统。Doris用它来支撑 PB 级别数据上亿次查询和数万亿次数据读取服务,同时提供每秒完成数百万行数据的更新性能。另外,Mesa能够提供全球复制功能,可以跨多个数据中心备份,并且在低延时提供一致的和可重复的请求响应,即使其中一个整个数据中心挂掉也没问题。
Apache Impala(取 MPP Query Engine): Impala是架构在hadoop上的开源MPP查询引擎,它可以直接访问数据,提供低延迟、高并发以读为主的查询且还支持SQL语法,ODBC驱动。Doris 可以通过Impala,让你可以使用SELECT、DELETE和聚合函数SUM等sql 语句。 impala只需要几秒钟或者分钟级别就能返回数据
Apache ORCFile (取 存储格式,编码和压缩) : ORC 格式在 2013 年 1 月提出,目的是提高 Hadoop Hive 的计算性能和存储效率。做为一种为大规模流式读取而专门设计优化的自描述列存储格式,可以根据不同的列类型选择不同的压缩算法。
DORIS 组成
FrontEnd DorisDB简称 FE:前端节点负责管理元数据、管理客户端的连接、进行查询规划和调度等工作;接收、解析查询请求,规划查询计划,调度查询执行,返回查询结果;执行SQL DDL命令, 用Catalog记录库, 表, 分区, tablet副本等信息。
FE介绍:FE 主要有有三个角色,一个是 leader,一个是 follower,还有一个 observer。leader 跟 follower,主要是用来达到元数据的高可用,保证单节点宕机的情况下,元数据能够实时地在线恢复,而不影响整个服务。follower 节点通过 bdbje(BerkeleyDB Java Edition (opens new window))进行 leader 选举,其中一个 follower 成为 leader 节点,负责元数据的写入操作。当 leader 节点宕机后,其他 follower 节点会重新选举出一个 leader,保证服务的高可用,完成各个 FE 之间数据同步等工作。
observer 节点仅从 leader 节点进行元数据同步,不参与选举。发现集群压力非常大的情况下,需要去扩展整个查询的能力,那么可以加 observer 的节点。observer 不参与任何的写入,只参与读取。
- 管理元数据, 执行SQL DDL命令, 用Catalog记录库, 表, 分区, tablet副本等信息。
- FE高可用部署, 使用复制协议选主和主从同步元数据, 所有的元数据修改操作, 由FE leader节点完成, FE follower节点可执行读操作。 元数据的读写满足顺序一致性。 FE的节点数目采用2n+1, 可容忍n个节点故障。 当FE leader故障时, 从现有的follower节点重新选主, 完成故障切换。
- FE的SQL layer对用户提交的SQL进行解析, 分析, 改写, 语义分析和关系代数优化, 生产逻辑执行计划。
- FE的Planner负责把逻辑计划转化为可分布式执行的物理计划, 分发给一组BE。
- FE监督BE, 管理BE的上下线, 根据BE的存活和健康状态, 维持tablet副本的数量。
- FE协调数据导入, 保证数据导入的一致性。
 BackEnd DorisDB简称 BE:后端节点负责数据存储、计算执行、副本管理等;BE 节点依据 FE 生成的物理计划,分布式地执行查询。 - 管理tablet副本, tablet是table经过分区分桶形成的子表, 采用列式存储BE管理tablet副本, tablet是table经过分区分桶形成的子表, 采用列式存储。- BE受FE指导, 创建或删除子表。- BE接收FE分发的物理执行计划并指定BE coordinator节点, 在BE coordinator的调度下, 与其他BE worker共同协作完成执行。- BE读本地的列存储引擎获取数据,并通过索引和谓词下沉快速过滤数据。- BE后台执行compact任务, 减少查询时的读放大。 -数据导入时, 由FE指定BE coordinator, 将数据以fanout的形式写入到tablet多副本所在的BE上。
BackEnd DorisDB简称 BE:后端节点负责数据存储、计算执行、副本管理等;BE 节点依据 FE 生成的物理计划,分布式地执行查询。 - 管理tablet副本, tablet是table经过分区分桶形成的子表, 采用列式存储BE管理tablet副本, tablet是table经过分区分桶形成的子表, 采用列式存储。- BE受FE指导, 创建或删除子表。- BE接收FE分发的物理执行计划并指定BE coordinator节点, 在BE coordinator的调度下, 与其他BE worker共同协作完成执行。- BE读本地的列存储引擎获取数据,并通过索引和谓词下沉快速过滤数据。- BE后台执行compact任务, 减少查询时的读放大。 -数据导入时, 由FE指定BE coordinator, 将数据以fanout的形式写入到tablet多副本所在的BE上。
DorisManager 和 Broker:DorisManager管理工具,负责提供集群管理、在线查询、故障查询、监控报警的可视化工具;Broker负责和外部存储(HDFS或对象存储)进行数据的导出导入等辅助功能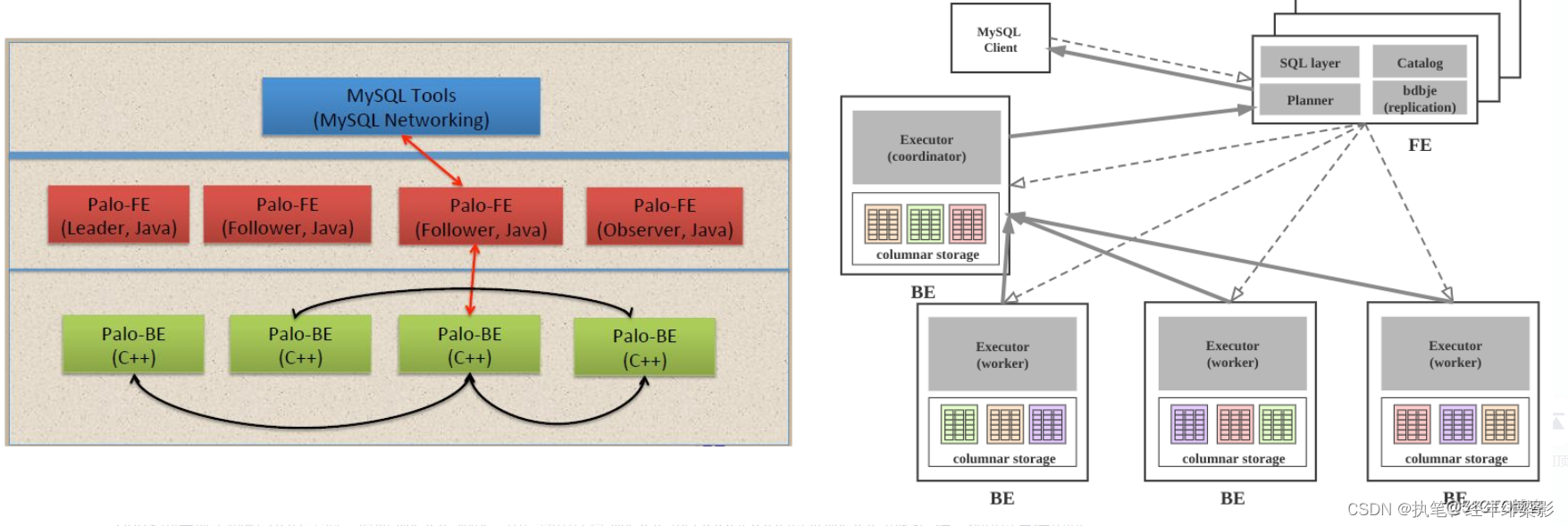
表先分区再进行分桶: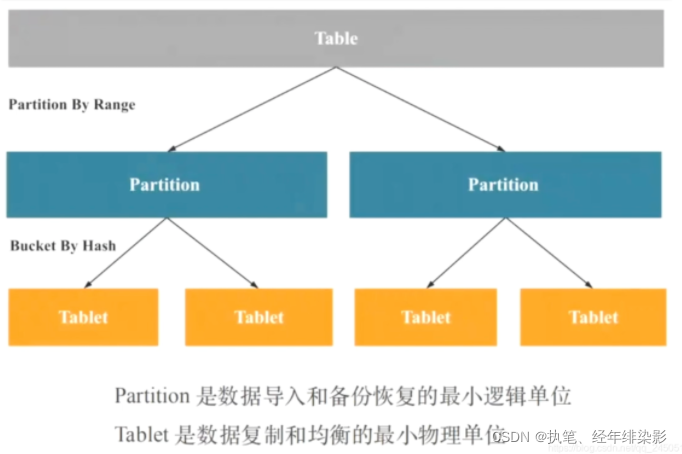
// 最好不要删除数据 (用delete 方式删除时,会生成一个空的rowset来记录删除,每次读取都要对删除条件进行过滤,在条件较多时性能会受影响。)
Doris中存储的数据都是以追加(Append)的方式进入系统,意味着已写入的数据不可变更。所以 Doris采用标记的方式来实现数据更新的目的。即在一批更新数据中,将之前的数据标记为删除,并写入新的数据。
在读取过程中,Doris会自动处理这些标记数据(Merge-on-Read),保证用户读取到的是最新的数据。同时,Doris后台的数据合并(Compaction)线程也会不断的对数据进行合并,消除标记数据,以减少在读取过程中需要进行的合并操作,加速查询。
大部分对数据修改的场景仅适用于 Unique Key 数据模型,因为只有该模型可以保证主键的唯一性,从而支持按主键对数据进行更新。
CREATETABLE'表名'('字段1'varchar(100)null commit '描述','字段2'varchar(100)null commit '描述',//索引'字段3'varchar(100) replace not null commit '描述',//替换'字段4'varchar(100) max not null commit '描述'//取最大值) engine = olap //引擎选择模型
aggregate key(字段1,字段2....)//索引的字段有。。。 UNIQUE KEY(order_id) //唯一字段
partition by range('date字段')//分区字段,是时间或者list 字符串
(
partition '分区名' values less than ("2022-01-04"),//超过这个分区,数据无法插入的
partition '分区名' values less than ("2022-06-04")
)
DISTRIBUTEDBYHASH(字段1)BUCKETS8;// 分桶列字段1,可以是多列,但必须为 Key 列。分桶列可和 Partition 列相同或不同。 分桶,(如果使用了 Partition,则该语句描述的是数据在各个分区内的划分规则。如果不使用 Partition,则描述的是对整个表的数据的划分规则。) 8是分桶数量理论上没有上限。properties(//配置信息"replication_num"="3", //3个be节点"in_memory"="true",//为 true 时,Doris会尽可能将该表的数据和索引Cache到BE 内存中"storage_format"="v2"// 从 0.13 版本开始,新建表的默认存储格式将为 Segment V2,新的特性:bitmap 索引 内存表 page cache 字典压缩 延迟物化(Lazy Materialization))
安装Doris步骤
- 开启fe节点 - 进入fe文件夹下,开启FE 节点(如果目录下没有 doris-meta 文件夹(存储运行数据),先创建一个)- 执行命令 sh bin/start_fe.sh --daemon 开启fe节点;- 输入命令 jps查看是否开启成功;
- 开启be节点 - 进入be节点文件夹下(如果目录下没有 storage 文件夹(存储物理数据),先创建一个)- 执行命令 sh bin/start_be.sh --daemon 开启be节点;- ps -ef |grep palo_be查看是否开启成功
- 后端连接进行设置 - mysql 进行登陆:输入 mysql -h 127.0.0.1 -P 9030 –uroot 命令(注意:无端口会连接到mysql上)- SET PASSWORD FOR ‘用户名’ = PASSWORD(‘密码’); 初始密码设置;- 赋予权限远程连接 :GRANT ALL PRIVILEGES ON . TO ‘用户名’@’%’ IDENTIFIED BY ‘密码’; (看mysql版本,8.0不支持这种写法)
- BE节点加入到FE去(多机器启动后也是这样加入) - 加入be节点命令:ALTER SYSTEM ADD BACKEND “IP地址:端口"; 会显示添加成功的信息- 查看BE状态:SHOW PROC '/backends’\G- 删除be节点:ALTER SYSTEM DROPP BACKEND “ip:port";(暴力删除,直接删除数据,不推荐)- alter system decommission backend “ip:port";(优雅删除,会把数据同步到其他be节点再进行删除。推荐!)
由于IP地址变换,导致的 doris FE 重启失败问题
换了个 地址,数据都还在,但是却无法连接FE了,重启 be,也是报错错误的集群 id;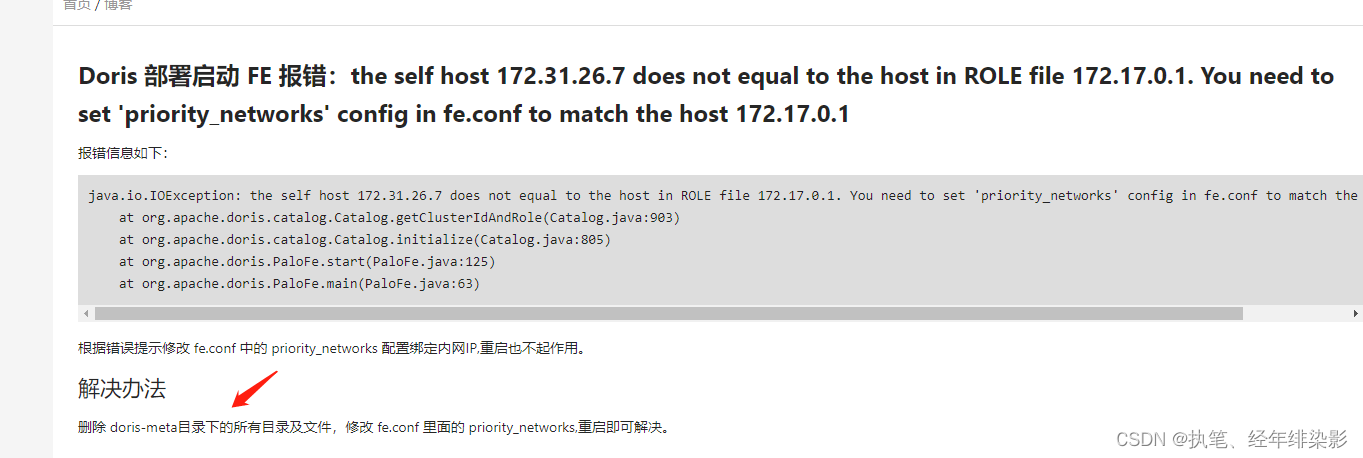

解决:删掉 镜像文件,全部重启(危险,数据丢失)
Doris 连接与可视化使用
1.前端界面进行操作;直接在浏览器打开 地址 ip:8030 ,登陆;
2.可以使用可视化工具进行操作如 navicat ;
3. 可以直接在部署的界面进行操作: 使用命令mysql -h 127.0.0.1 -P 9030 -uroot
Doris 避坑
1.Be节点集群扩展;
注意:一台机器上可以部署多个 BE 实例(但通常来说只会取一个),但是只能部署一个 FE。如果需要 3 副本数据,那么至少需要 3 台机器各部署一个 BE 实例(而不是1台机器部署3个BE实例)。
可以将安装包复制到多台机器上去,分别开启be节点;
通过一台 FE 加入不同地址的BE节点(ALTER SYSTEM ADD BACKEND “地址:端口”)
2.Be 节点会自动关闭;
消费字段要及时更新,否则,数据产生偏移超过一定的数量会导致BE节点被暂停消费;
查询内存不足,导致关闭;(可以通过单机扩内存或 扩容be节点解决)
3.有问题,看日志,找对应文件下的log文件夹。warning类型log;
4.不支持update,删除单条记录(你要把分区也一起写出来才可以)
delete from 表 partition 分片名 where 条件;(尽量不要删除,不然影响性能)
5.元数据的每次更新,都首先写入到磁盘的日志文件中,然后再写到内存中,最后定期checkpoint到本地磁盘上。
1.Doris 采用 insert into 表 values 报错一堆:
解决:尽量不要用 insert into 表 values 这种方式去导入数据而是要用 insert into 表 select。。。。。
但是我的数据根本没有那么大,一次就几百条 所以 我就要用它。
导致如下错误:
tablet writer write failed, tablet_id=0000, txn_id=0000, err=-235 or -215
这个就是说 我们的 tablet的 数据版本 超过了最大限制(默认500),最后排查问题发现:是我代码逻辑 导致数据 循环插入了,也就是说我本来 300多条数据。变成了 300*300 条,它不断的循环,插入 ,更新,替换。导致版本超限。
排查方法:
doris 执行下列的命令:
show tablet tabletid(报错的那个)
在结果里面关注最后一列,输入它的内容再次查询
SHOW PROC ‘。。。。。。’; 这时候可以发现版本的数量了
解决方法:
1.优化自身的代码,将数据处理完全后,再进行入库
2.减少 插入频率,插入几条后,就停顿一下,不要频繁的插入
3.更换插入 方式, 先把数据存入到 kafka,hdfs 或者其他地方后,再进行 入库 doris
doris 多频率插入 最多只能存入 12天数据 优化(找到doris be节点问题)(doris 系统本身不适合 单条数据(超过500 报错)的导入,建议批量导入,要原因是insert into values受限于mysql的协议导入效率不高,而且DorisDB需要微批导入,不希望几百几千行数据就导入一次。
ck也是推荐使用insert into select的方式来导入,如果用insert into values写入大量版本也同样出现too many parts等错误。)因为compaction的速度跟不上高频导入的速度,导致数据版本无限堆积。默认上线是500.
这种情况通常是因为导入频率过高导致版本合并不及时,需要降低导入频率,或暂停导入等待compaction将数据版本数量降低。
2.Doris 报错:errCode = 2, detailMessage = Unknown column ‘ROUTINE_SCHEMA’ in ‘ROUTINES’
这种问题一般是 : 用户发送了一个 不合法的 查询导致的。比如 查询的这个 数据库不存在,表不存在,列不存在等;都会有这个错误的;
先建表,保证数据库有这样的数据库,表,和列;
3.配置文件
enable_concurrent_update 字段:通过修改 FE 配置 enable_concurrent_update。当配置值为 true 时,则对更新并发无限制。实际应用中,如果用户自己可以保证即使并发更新,也不会同时对同一行进行操作的话,就可以手动打开并发限制。风险 由于 Doris 目前支持的是行更新,并且采用的是读取后再写入的两步操作,则如果 Update 语句和其他导入或 Delete 语句刚好修改的是同一行时,存在不确定的数据结果。所以用户在使用的时候,一定要注意用户侧自己进行 Update 语句和其他 DML 语句的并发控制。
max_user_connection : 用户最大的连接数,默认值为100。一般情况不需要更改该参数,除非查询的并发数超过了默认值。
客户端到FE的最大连接数可以通过该命令设置 :SET PROPERTY [FOR ‘user’] ‘key’ = ‘value’ [, ‘key’ = ‘value’]
wait_timeout: 默认是 28800,超时等待时间,如果这个时间设置的太长 会导致 doris 一直连接着超时的 客户端,等许久才断开,会导致 一直有 报错 连接数太多的情况。
FE 配置更改:
静态: conf/fe.conf 文件中添加配置项。文件会在 FE 进程启动时被读取。没有在 fe.conf 中的配置项将使用默认值。修改后,重启会永久的有效。
动态:连接命令方式,(需要管理员权限)
通过 ADMIN SHOW FRONTEND CONFIG; 命令结果中的 IsMutable 列查看是否支持动态配置。
运行
ADMIN SET FRONTEND CONFIG (“fe_config_name” = “fe_config_value”);
查看修改后的值:
set forward_to_master=true;
ADMIN SHOW FRONTEND CONFIG;
注意,这种方式虽然在线可实现,但是 FE 进程重启后还是会失效。
4.连接
启动mysql 先,
命令:service mysqld restart
service mysqld status 看状态
全量数据迁移 ,出现 FE节点启动不了情况:
5.报错:Dask Dataframe read_parquet: OSError: Couldn’t deserialize thrift: TProtocolException: Invalid data
navicat 也报错连接错误:
最后排查发现,虽然 be是live,但是 没有任何内存信息,又去 be排查,发现都没有问题,但是日志,be.info.log 报错: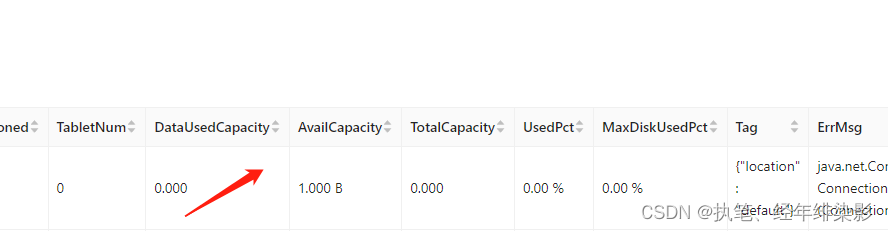

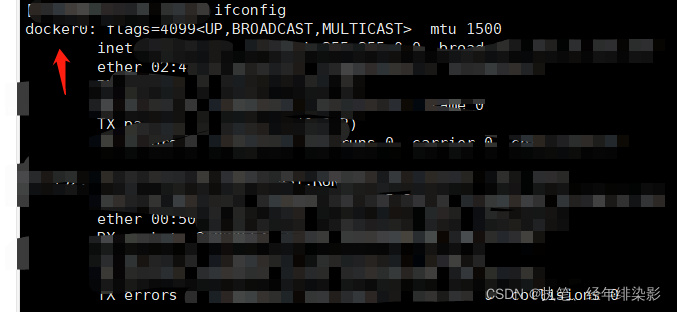
好家伙:多了docker,导致,有了虚拟地址,,,,,,取不到它。靠。
解决:卸载docker,
6.报错report TASK failed. status: -1, master host:
fe 使用了 docker后,be加入 报错,,,,,,,report TASK failed. status: -1, master host:。
7.开通Doris 用户 并授权只读数据库:
CREATE USER readonly IDENTIFIED BY “1111”;
GRANT SELECT_PRIV ON . TO readonly;
登陆 :readonly 密码:1111
其他权限Node_priv:节点变更权限。包括 FE、BE、BROKER 节点的添加、删除、下线等操作。目前该权限只能授予 Root 用户。
Grant_priv:权限变更权限。允许执行包括授权、撤权、添加/删除/变更 用户/角色 等操作。
Select_priv:对数据库、表的只读权限。
Load_priv:对数据库、表的写权限。包括 Load、Insert、Delete 等。
Alter_priv:对数据库、表的更改权限。包括重命名 库/表、添加/删除/变更 列等操作。
Create_priv:创建数据库、表的权限。
Drop_priv:删除数据库、表的权限。
Usage_priv:使用某种 资源 的权限。:
文章许多知识点和图片大多来自网络,仅供自己学习记录使用。具体地址如下图
[1]:https://codeantenna.com/a/eO5VdPeSFV
[2]: https://cloud.tencent.com/developer/news/835349
[3]: https://its201.com/article/ly_zixuan/119888575
[4]: https://www.cnblogs.com/tgzhu/p/14749968.html
[5]:https://www.jianshu.com/p/9fa7137f91e6
[6]:https://doris.apache.org/master/zh-CN/installing/compilation.html
版权归原作者 执笔、泛影成双 所有, 如有侵权,请联系我们删除。