
说明
Hive join语法有6中连接
inner join(内连接)、left join(左连接)、right join(右连接)、full outer join(全外连接)、left semi join(左半开连接)、**cross **join(交叉连接,也叫做笛卡尔乘积)。
参考网址:从零开始学大数据(二十九):HQL join连接查询,Hive参数配置 - 知乎
Hive join使用注意事项:LanguageManual Joins - Apache Hive - Apache Software Foundation
数据准备
表1:employee 员工表;
表2:employee_address 员工住址信息表;
表3:employee_connection 员工联系方式表;
--table1: 员工表
CREATE TABLE employee(
id int,
name string,
deg string,
salary int,
dept string
) row format delimited
fields terminated by ',';
--table2:员工住址信息表
CREATE TABLE employee_address (
id int,
hno string,
street string,
city string
) row format delimited
fields terminated by ',';
--table3:员工联系方式表
CREATE TABLE employee_connection (
id int,
phno string,
email string
) row format delimited
fields terminated by ',';--加载数据到表中
load data local inpath '/root/hivedata/employee.txt' into table employee;
load data local inpath '/root/hivedata/employee_address.txt' into table employee_address;
load data local inpath '/root/hivedata/employee_connection.txt' into table employee_connection;
语法说明
Hive inner join
内连接是最常见的一种连接,它也被称为普通连接,而关系模型提出者E.FCodd(埃德加•科德)最早称之为自然连接。其中inner可以省略。inner join == join 等价于早期的连接语法。
内连接,只有进行连接的两个表中都存在与连接条件相匹配的数据才会被留下来。
即,取交集数据
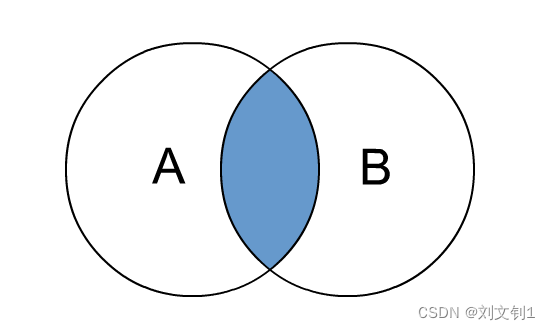
--1、inner join
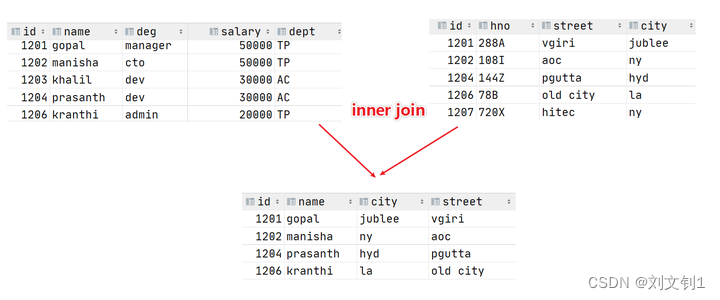
select e.id,e.name,e_a.city,e_a.street
from employee e inner join employee_address e_a
on e.id =e_a.id;
--等价于 inner join=join
select e.id,e.name,e_a.city,e_a.street
from employee e join employee_address e_a
on e.id =e_a.id;
--等价于 隐式连接表示法
select e.id,e.name,e_a.city,e_a.street
from employee e , employee_address e_a
where e.id =e_a.id;
Hive left join
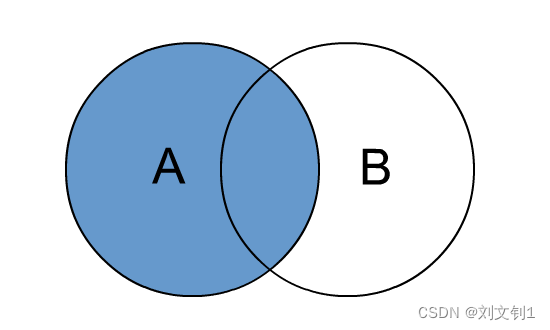
left join中文叫做是左外连接(Left Outer Jion)或者左连接,其中outer可以省略,left outer join是早期的写法。
left join的核心就在于left左。左指的是join关键字左边的表,简称左表。
通俗解释:join时以左表的全部数据为准,右边与之关联;左表数据全部返回,右表关联上的显示返回,关联不上的显示null返回。
即:取左表所有数据,及右表与左表交集数据
注意空值处理
--2、left join
select e.id,e.name,e_conn.phno,e_conn.email
from employee e left join employee_connection e_conn
on e.id =e_conn.id;
--等价于 left outer join
select e.id,e.name,e_conn.phno,e_conn.email
from employee e left outer join employee_connection e_conn
on e.id =e_conn.id;

Hive right join
right join中文叫做是右外连接(Right Outer Jion)或者右连接,其中outer可以省略。
right join的核心就在于Right右。右指的是join关键字右边的表,简称右表。
通俗解释:join时以右表的全部数据为准,左边与之关联;右表数据全部返回,左表关联上的显示返回,关联不上的显示null返回。
很明显,right join和left join之间很相似,重点在于以哪边为准,也就是一个方向的问题。


Hive full outer join
full outer join 等价 full join ,中文叫做全外连接或者外连接。
包含左、右两个表的全部行,不管另外一边的表中是否存在与它们匹配的行 在功能上,它等价于对这两个数据集合分别进行左外连接和右外连接,然后再使用消去重复行的操作将上述两个结果集合并为一个结果集。
注意空值处理

--4、full outer join
select e.id,e.name,e_a.city,e_a.street
from employee e full outer join employee_address e_a
on e.id =e_a.id;
--等价于
select e.id,e.name,e_a.city,e_a.street
from employee e full join employee_address e_a
on e.id =e_a.id;

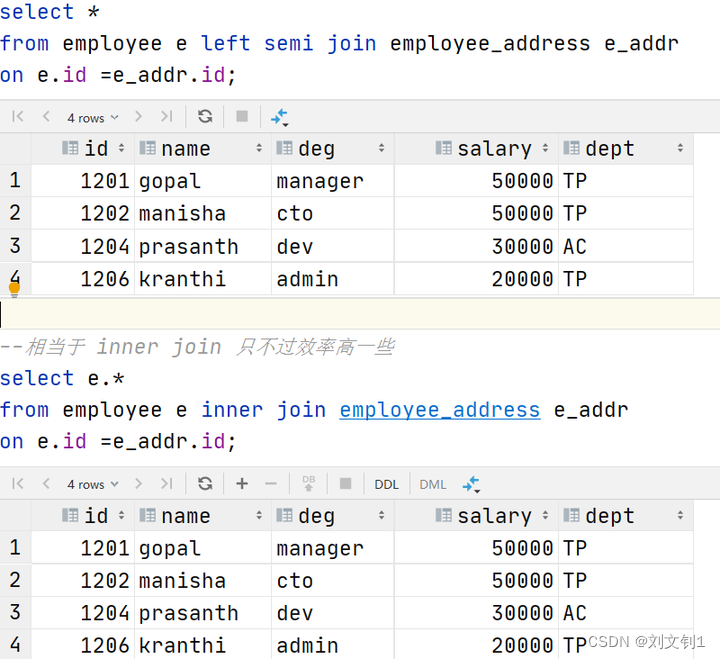
Hive left semi join
左半开连接(LEFT SEMI JOIN)会返回左边表的记录,前提是其记录对于右边的表满足ON语句中的判定条件。
从效果上来看有点像inner join之后只返回左表的结果。
Hive cross join
交叉连接cross join,将会返回被连接的两个表的笛卡尔积,返回结果的行数等于两个表行数的乘积。对于大表来说,cross join慎用。
在SQL标准中定义的cross join就是无条件的inner join。返回两个表的笛卡尔积,无需指定关联键。
在HiveSQL语法中,cross join 后面可以跟where子句进行过滤,或者on条件过滤。
--6、cross join
--下列A、B、C 执行结果相同,但是效率不一样:
--A:
select a.*,b.* from employee a,employee_address b where a.id=b.id;
--B:
select * from employee a cross join employee_address b on a.id=b.id;select * from employee a cross join employee_address b where a.id=b.id;
--C:
select * from employee a inner join employee_address b on a.id=b.id;
--一般不建议使用方法A和B,因为如果有WHERE子句的话,往往会先进行笛卡尔积返回数据然后才根据WHERE条件从中选择。
--因此,如果两个表太大,将会非常非常慢,不建议使用。
Hive join使用注意事项
- 如果每个表在联接子句中使用相同的列,则Hive将多个表上的联接转换为单个MR作业
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
--由于联接中仅涉及b的key1列,因此被转换为1个MR作业来执行SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
--会转换为两个MR作业,因为在第一个连接条件中使用了b中的key1列,而在第二个连接条件中使用了b中的key2列。
第一个map / reduce作业将a与b联接在一起,然后将结果与c联接到第二个map / reduce作业中。
join时的最后一个表会通过reducer流式传输,并在其中缓冲之前的其他表,因此,将大表放置在最后有助于减少reducer阶段缓存数据所需要的内存
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
--由于联接中仅涉及b的key1列,因此被转换为1个MR作业来执行,并且表a和b的键的特定值的值被缓冲在reducer的内存中。
然后,对于从c中检索的每一行,将使用缓冲的行来计算联接。
SELECT a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key2)
--计算涉及两个MR作业。其中的第一个将a与b连接起来,并缓冲a的值,同时在reducer中流式传输b的值。
在第二个MR作业中,将缓冲第一个连接的结果,同时将c的值通过reducer流式传输。
在join的时候,可以通过语法STREAMTABLE提示指定要流式传输的表。如果省略STREAMTABLE提示,则Hive将流式传输最右边的表。
SELECT /*+ STREAMTABLE(a) */ a.val, b.val, c.val FROM a JOIN b ON (a.key = b.key1) JOIN c ON (c.key = b.key1)
--a,b,c三个表都在一个MR作业中联接,并且表b和c的键的特定值的值被缓冲在reducer的内存中。
然后,对于从a中检索到的每一行,将使用缓冲的行来计算联接。
如果省略STREAMTABLE提示,则Hive将流式传输最右边的表。
join在WHERE条件之前进行。
SELECT /*+ MAPJOIN(b) */ a.key, a.value FROM a JOIN b ON a.key = b.key
--不需要reducer。对于A的每个Mapper,B都会被完全读取。
限制是不能执行FULL / RIGHT OUTER JOIN b。
如果除一个要连接的表之外的所有表都很小,则可以将其作为仅map作业执行
版权归原作者 刘文钊1 所有, 如有侵权,请联系我们删除。