
1.3 SparkStreaming与Kafka整合
1.3.1 整合简述
kafka是做消息的缓存,数据和业务隔离操作的消息队列,而sparkstreaming是一款准实时流式计算框架,所以二者的整合,是大势所趋。
二者的整合,有主要的两大版本。
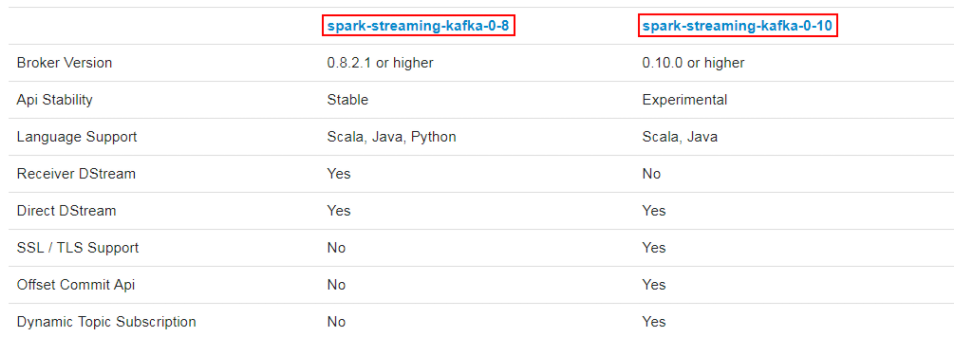
kafka作为一个实时的分布式消息队列,实时的生产和消费消息,在实际开发中Spark Streaming经常会结合Kafka来处理实时数据。Spark Streaming 与 kafka整合需要引入spark-streaming-kafka.jar,该jar根据kafka版本有2个分支,分别是spark-streaming-kafka-0-8 和 spark-streaming-kafka-0-10。jar包分支选择原则:
- 0.10.0>kafka版本>=0.8.2.1,选择 08 接口
- kafka版本>=0.10.0,选择 010 接口
sparkStreaming和Kafka整合一般两种方式:Receiver方式和Direct方式
Receiver方式(介绍)
Receiver方式基于kafka的高级消费者API实现
(高级优点:高级API写起来简单;不需要去自行去管理offset,系统通过zookeeper自行管理;不需要管理分区,副本等情况,系统自动管理;消费者断线会自动根据上一次记录在 zookeeper中的offset去接着获取数据;高级缺点:不能自行控制 offset;不能细化控制如分区、副本、zk 等)
。Receiver从kafka接收数据,存储在Executor中,Spark Streaming 定时生成任务来处理数据。

默认配置的情况,Receiver失败时有可能丢失数据。如果要保证数据的可靠性,需要开启预写式日志,简称WAL(Write Ahead Logs,Spark1.2引入),只有接收到的数据被持久化之后才会去更新Kafka中的消费位移。接收到的数据和WAL存储位置信息被可靠地存储,如果期间出现故障,这些信息被用来从错误中恢复,并继续处理数据。
还有几个需要注意的点:
- 在Receiver的方式中,Spark中的 partition 和 kafka 中的 partition 并不是相关的,如果加大每个topic的partition数量,仅仅是增加线程来处理由单一Receiver消费的主题。但是这并没有增加Spark在处理数据上的并行度;
- 对于不同的 Group 和 Topic 可以使用多个 Receiver 创建不同的Dstream来并行接收数据,之后可以利用union来统一成一个Dstream;
- 如果启用了Write Ahead Logs复制到文件系统如HDFS,那么storage level需要设置成 StorageLevel.MEMORY_AND_DISK_SER,也就是:KafkaUtils.createStream(..., StorageLevel.MEMORY_AND_DISK_SER)
- WAL将接收的数据备份到HDFS上,保证了数据的安全性。但写HDFS比较消耗性能,另外要在备份完数据之后还要写相关的元数据信息,这样总体上增加job的执行时间,增加了任务执行时间;
- 总体上看 Receiver 方式,不适于生产环境;
1.3.2 Direct的方式
Direct方式从Spark1.3开始引入的,通过 KafkaUtils.createDirectStream 方法创建一个DStream对象,Direct方式的结构如下图所示。
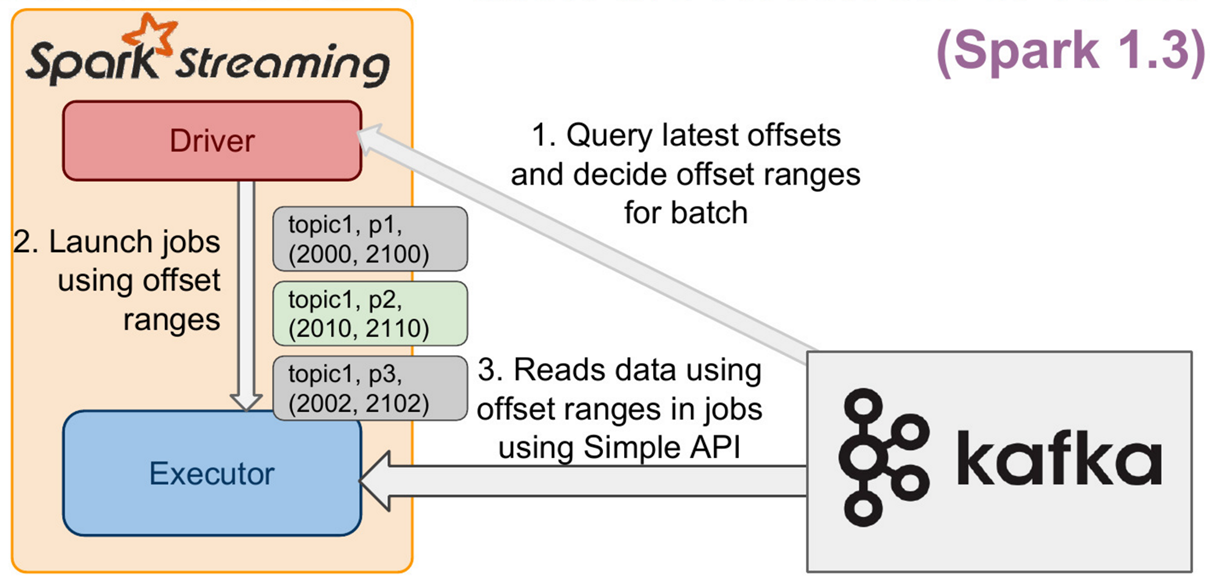
Direct 方式特点如下:
- 对应Kafka的版本 0.8.2.1+
- Direct 方式
- Offset 可自定义
- 使用kafka低阶API
- 底层实现为KafkaRDD
该方式中Kafka的一个分区与Spark RDD对应,通过定期扫描所订阅Kafka每个主题的每个分区的最新偏移量以确定当前批处理数据偏移范围。与Receiver方式相比,Direct方式不需要维护一份WAL数据,由Spark Streaming程序自己控制位移的处理,通常通过检查点机制处理消费位移,这样可以保证Kafka中的数据只会被Spark拉取一次。
- 引入依赖
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.1.2</version>
</dependency>
- 模拟kafka生产数据
package com.qianfeng.sparkstreaming
import java.util.{Properties, Random}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
/**
* 向kafka中test主题模拟生产数据;;;也可以使用命令行生产:kafka-console-producer.sh --broker-list qianfeng01:9092,hadoop02:9092,hadoop03:9092 -topic test
*/
object Demo02_DataLoad2Kafka {
def main(args: Array[String]): Unit = {
val prop = new Properties()
//提供Kafka服务器信息
prop.put("bootstrap.servers","qianfeng01:9092")
//指定响应的方式
prop.put("acks","all")
//请求失败重试的次数
prop.put("retries","3")
//指定key的序列化方式,key是用于存放数据对应的offset
prop.put("key.serializer",
"org.apache.kafka.common.serialization.StringSerializer")
//指定value的序列化方式
prop.put("value.serializer",
"org.apache.kafka.common.serialization.StringSerializer")
//创建producer对象
val producer = new KafkaProducer[String,String](prop)
//提供一个数组,数组中数据
val arr = Array(
"hello tom",
"hello jerry",
"hello dabao",
"hello zhangsan",
"hello lisi",
"hello wangwu",
)
//提供一个随机数,随机获取数组中数据向kafka中进行发送存储
val r = new Random()
while(true){
val message = arr(r.nextInt(arr.length))
producer.send(new ProducerRecord[String,String]("test",message))
Thread.sleep(r.nextInt(1000)) //休眠1s以内
}
}
}
- 实时消费kafka数据
package com.qianfeng.sparkstreaming
import org.apache.kafka.clients.consumer.ConsumerConfig
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.DStream
import org.apache.spark.streaming.kafka010.{ConsumerStrategies, KafkaUtils, LocationStrategies}
import org.apache.spark.streaming.{Seconds, StreamingContext}
/**
* sparkStreaming消费Kafka中的数据
*/
object Demo03_SparkStreamingWithKafka {
def main(args: Array[String]): Unit = {
//1.创建SparkConf对象
val conf = new SparkConf()
.setAppName("SparkStreamingToKafka")
.setMaster("local[*]")
//2.提供批次时间
val time = Seconds(5)
//3.提供StreamingContext对象
val sc = new StreamingContext(conf, time)
//4.提供Kafka配置参数
val kafkaConfig = Map[String, Object](
ConsumerConfig.BOOTSTRAP_SERVERS_CONFIG -> "qianfeng01:9092",
ConsumerConfig.GROUP_ID_CONFIG -> "qianfeng",
"key.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
"value.deserializer" -> "org.apache.kafka.common.serialization.StringDeserializer",
)
//5.读取Kafka中数据信息生成DStream
val value = KafkaUtils.createDirectStream(sc,
//本地化策略:将Kafka的分区数据均匀的分配到各个执行Executor中
LocationStrategies.PreferConsistent,
//表示要从使用kafka进行消费【offset谁来管理,从那个位置开始消费数据】
ConsumerStrategies.Subscribe[String, String](Set("test"), kafkaConfig)
)
//6.将每条消息kv获取出来
val line: DStream[String] = value.map(record => record.value())
//7.开始计算操作
line.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _).print()
//line.count().print() //每隔5s的数据条数
//8.开始任务
sc.start()
sc.awaitTermination()
}
}
- 说明1. 简化的并行性:不需要创建多个输入Kafka流并将其合并。 使用directStream,Spark Streaming将创建与使用Kafka分区一样多的RDD分区,这些分区将全部从Kafka并行读取数据。 所以在Kafka和RDD分区之间有一对一的映射关系。2. 效率:在第一种方法中实现零数据丢失需要将数据存储在预写日志中,这会进一步复制数据。这实际上是效率低下的,因为数据被有效地复制了两次:一次是Kafka,另一次是由预先写入日志(WriteAhead Log)复制。这个第二种方法消除了这个问题,因为没有接收器,因此不需要预先写入日志。只要Kafka数据保留时间足够长。3. 正好一次(Exactly-once)的语义:第一种方法使用Kafka的高级API来在Zookeeper中存储消耗的偏移量。传统上这是从Kafka消费数据的方式。虽然这种方法(结合提前写入日志)可以确保零数据丢失(即至少一次语义),但是在某些失败情况下,有一些记录可能会消费两次。发生这种情况是因为Spark Streaming可靠接收到的数据与Zookeeper跟踪的偏移之间的不一致。因此,在第二种方法中,我们使用不使用Zookeeper的简单Kafka API。在其检查点内,Spark Streaming跟踪偏移量。这消除了Spark Streaming和Zookeeper/Kafka之间的不一致,因此Spark Streaming每次记录都会在发生故障的情况下有效地收到一次。为了实现输出结果的一次语义,将数据保存到外部数据存储区的输出操作必须是幂等的,或者是保存结果和偏移量的原子事务。
Guff_hys_python数据结构,大数据开发学习,python实训项目-CSDN博客
版权归原作者 Guff_hys 所有, 如有侵权,请联系我们删除。