
本文介绍了如何从零开始开发车牌对象检测模型。整体项目中还包含了一个使用Flask的API。在本文中我们将解释如何从头开始训练自定义对象检测模型。
项目架构
现在,让我们看看我们要构建的车牌识别和OCR的项目架构。
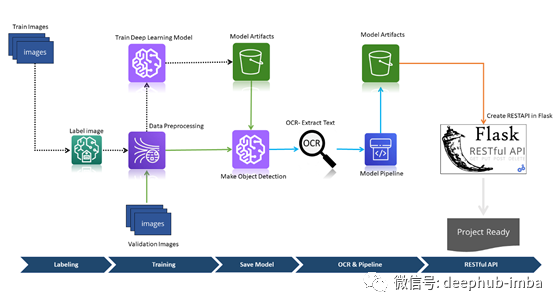
在上面的架构中,有六个模块。标记、训练、保存模型、OCR和模型管道,以及RESTful API。但是本文只详细介绍前三个模块。过程如下。首先,我们将收集图像。然后使用python GUI开发的开源软件图像标注工具对图像进行车牌或号牌的标注。然后在对图像进行标记后,我们将进行数据预处理,在TensorFlow 2中构建和训练一个深度学习目标检测模型(Inception Resnet V2)。完成目标检测模型训练过程后,使用该模型裁剪包含车牌的图像,也称为关注区域(ROI),并将该ROI传递给Python中的 Tesserac API。使用PyTesseract,我们将从图像中提取文本。最后我们将所有这些放在一起,并构建深度学习模型管道。在最后一个模块中,将使用FLASK Python创建一个Web应用程序项目。这样,我们可以将我们的应用程序发布供他人使用。
标注
为了建立车牌识别,我们需要数据。为此,我们需要收集车牌出现在其上的车辆图像。这对于图像标签,我使用了LabelImg图像标注工具。从GitHub下载labelImg并按照说明安装软件包。打开之后,GUI给出指示,然后单击CreateRectBox并绘制如下所示的矩形框,然后将输出保存为XML。
pip install pyqt=5
pip install lxml
pyrcc5 -o libs/resources.py resources.qrc
python labelImg.py
python labelImg.py [IMAGE_PATH] [PRE-DEFINED CLASS FILE
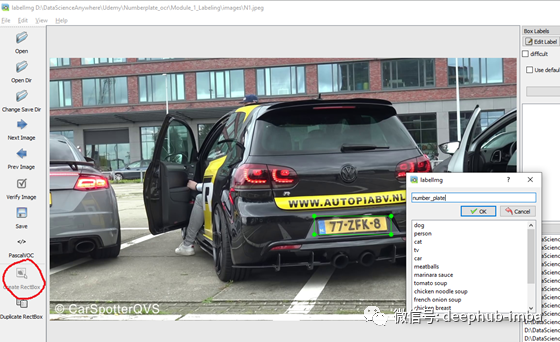
这是一个手动过程,您需要对所有图像进行处理。标注时要注意,因为这个过程会直接影响模型的准确性。
从XML解析信息
完成标注过程后,现在我们需要进行一些数据预处理。

由于标注的输出是XML,为了将其用于训练过程,我们需要处理格式数据。因此我们将从标签中获得有用的信息,例如它的边界框的对角点,分别是xmin,ymin,xmax,ymax,如图3所示 ,我们需要提取信息并将其保存为任何方便的格式,在这里,我将边界信息转换为CSV,随后,我将使用Pandas将其转换为数组。现在,让我们看看如何使用Python解析信息。
我使用xml.etree python库来解析XML中的数据,并导入pandas和glob。首先使用glob获取在标记过程中生成的所有XML文件。
import pandas as pd
from glob import glob
import xml.etree.ElementTree as xet
path = glob('./images/*.xml')
labels_dict = dict(filepath=[],xmin=[],xmax=[],ymin=[],ymax=[])
for filename in path:
info = xet.parse(filename)
root = info.getroot()
member_object = root.find('object')
labels_info = member_object.find('bndbox')
xmin = int(labels_info.find('xmin').text)
xmax = int(labels_info.find('xmax').text)
ymin = int(labels_info.find('ymin').text)
ymax = int(labels_info.find('ymax').text)
#print(xmin,xmax,ymin,ymax)
labels_dict['filepath'].append(filename)
labels_dict['xmin'].append(xmin)
labels_dict['xmax'].append(xmax)
labels_dict['ymin'].append(ymin)
labels_dict['ymax'].append(ymax)
在上面的代码中,我们分别获取每个文件并将其解析为xml.etree,然后找到对象-> bndbox,它位于第2至7行。然后提取xmin,xmax,ymin,ymax并将这些值保存在字典中 在第8至17行中。然后,将其转换为pandas的df,并将其保存到CSV文件中,如下所示。
df = pd.DataFrame(labels_dict)
df.to_csv('labels.csv',index=False)
df.head()
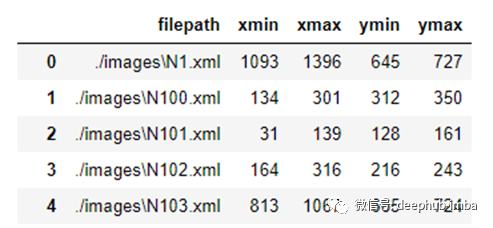
通过以上代码,我们成功提取了每个图像的对角线位置,并将数据从非结构化格式转换为结构化格式。
现在,我们来提取XML的相应图像文件名。
import os
def getFilename(filename):
filename_image = xet.parse(filename).getroot().find('filename').text
filepath_image = os.path.join('./images',filename_image)
return filepath_image
image_path = list(df['filepath'].apply(getFilename))
image_path
验证数据
到目前为止,我们都是进行的手动处理,因此重要的是要验证所获得的信息是否有效。我们只需验证边界框对于给定图像正确显示。
file_path = "N1.jpeg"
xmin,xmax,ymin,ymax = 1093,1396,645,727
img = cv2.imread(file_path)
cv2.rectangle(img,(xmin,ymin),(ymin,ymax),(0,255,0),3)
cv2.namedWindow('example',cv2.WINDOW_NORMAL)
cv2.imshow('example',img)
cv2.waitKey(0)
cv2.destroyAllWindows()

数据处理
这是非常重要的一步,在此过程中,我们将获取每张图像,并使用OpenCV将其转换为数组,然后将图像调整为224 x 224,这是预训练的转移学习模型的标准兼容尺寸。
from sklearn.model_selection import train_test_split
from tensorflow.keras.preprocessing.image import load_img, img_to_array
import cv2
import numpy as np
labels = df.iloc[:,1:].values
data = []
output = []
for ind in range(len(image_path)):
image = image_path[ind]
img_arr = cv2.imread(image)
h,w,d = img_arr.shape
# prepprocesing
load_image = load_img(image,target_size=(224,224))
load_image_arr = img_to_array(load_image)
norm_load_image_arr = load_image_arr/255.0 # normalization
# normalization to labels
xmin,xmax,ymin,ymax = labels[ind]
nxmin,nxmax = xmin/w,xmax/w
nymin,nymax = ymin/h,ymax/h
label_norm = (nxmin,nxmax,nymin,nymax) # normalized output
# -------------- append
data.append(norm_load_image_arr)
output.append(label_norm)
我们将通过除以最大数量来归一化图像,因为我们知道8位图像的最大数量为 255
我们还需要对标签进行规范化。因为对于深度学习模型,输出范围应该在0到1之间。为了对标签进行归一化,我们需要将对角点除以图像的宽度和高度。
X = np.array(data,dtype=np.float32)
y = np.array(output,dtype=np.float32)
sklearn的函数可以方便的将数据分为训练和测试集。
x_train,x_test,y_train,y_test = train_test_split(X,y,train_size=0.8,random_state=0)
x_train.shape,x_test.shape,y_train.shape,y_test.shape
训练
现在我们已经可以准备训练用于对象检测的深度学习模型了。本篇文章中,我们将使用具有预训练权重的InceptionResNetV2模型,并将其训练到我们的数据中。首先从TensorFlow 2.3.0导入必要的库
from tensorflow.keras.applications import InceptionResNetV2
from tensorflow.keras.layers import Dense, Dropout, Flatten, Input
from tensorflow.keras.models import Model
import tensorflow as tf
我们需要的是一个对象检测模型,而期望的输出数量是4(对角点的信息)。我们将在迁移学习模型中添加一个嵌入神经网络层,如第5至9行所示。
inception_resnet = InceptionResNetV2(weights="imagenet",include_top=False,
input_tensor=Input(shape=(224,224,3)))
inception_resnet.trainable=False
# ---------------------
headmodel = inception_resnet.output
headmodel = Flatten()(headmodel)
headmodel = Dense(500,activation="relu")(headmodel)
headmodel = Dense(250,activation="relu")(headmodel)
headmodel = Dense(4,activation='sigmoid')(headmodel)
# ---------- model
model = Model(inputs=inception_resnet.input,outputs=headmodel)
现在编译模型并训练模型
# complie model
model.compile(loss='mse',optimizer=tf.keras.optimizers.Adam(learning_rate=1e-4))
model.summary()
from tensorflow.keras.callbacks import TensorBoard
tfb = TensorBoard('object_detection')
history = model.fit(x=x_train,y=y_train,batch_size=10,epochs=200,
validation_data=(x_test,y_test),callbacks=[tfb])
我们训练模型通常需要3到4个小时,具体取决于计算机的速度。在这里,我们使用TensorBoard记录了中模型训练时的损失。
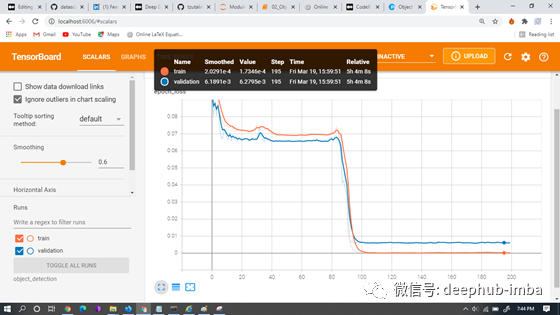
进行边界框预测
这是最后一步。在这一步中,我们将所有这些放在一起并获得给定图像的预测。
# create pipeline
path = './test_images/N207.jpeg'
def object_detection(path):
# read image
image = load_img(path) # PIL object
image = np.array(image,dtype=np.uint8) # 8 bit array (0,255)
image1 = load_img(path,target_size=(224,224))
# data preprocessing
image_arr_224 = img_to_array(image1)/255.0 # convert into array and get the normalized output
h,w,d = image.shape
test_arr = image_arr_224.reshape(1,224,224,3)
# make predictions
coords = model.predict(test_arr)
# denormalize the values
denorm = np.array([w,w,h,h])
coords = coords * denorm
coords = coords.astype(np.int32)
# draw bounding on top the image
xmin, xmax,ymin,ymax = coords[0]
pt1 =(xmin,ymin)
pt2 =(xmax,ymax)
print(pt1, pt2)
cv2.rectangle(image,pt1,pt2,(0,255,0),3)
return image, coords
# ------ get prediction
path = './test_images/N207.jpeg'
image, cods = object_detection(path)
plt.figure(figsize=(10,8))
plt.imshow(image)
plt.show()
本文仅说明了项目架构的50%。下一个过程涉及从车牌中提取文本并在Flask中开发RestfulAPI。
作者:DEVI GUSKRA
原文地址:https://medium.com/codex/7-steps-to-build-automatic-number-plate-recognition-in-python-53e34c9ae583
deephub翻译组