
Hive的元数据服务
之前讲了hive的元数据,它存储着hiveSQL映射和hdfs具体文件数据的对应关系。
但是元数据存在单独的mysql中 直接将它暴露给外部是不安全的,所以hive特别增加了一个元数据服务。 它作为元数据和外部客户端之间的一个中间人。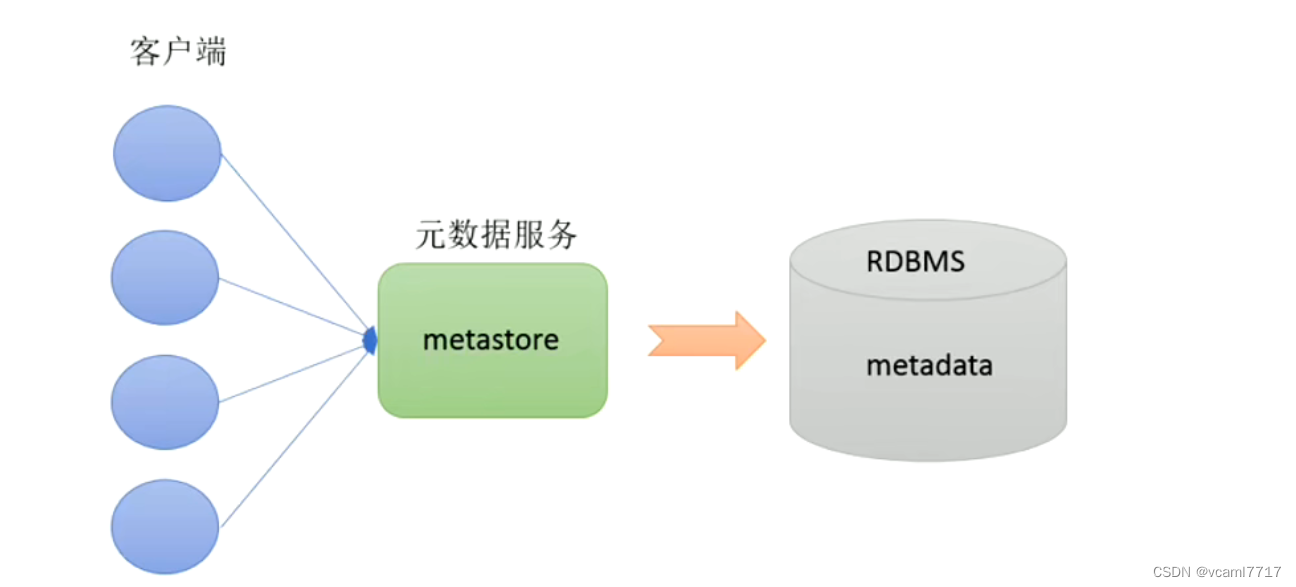
metastore有三种服务配置模式 同时也可以说这是hive的三种安装模式: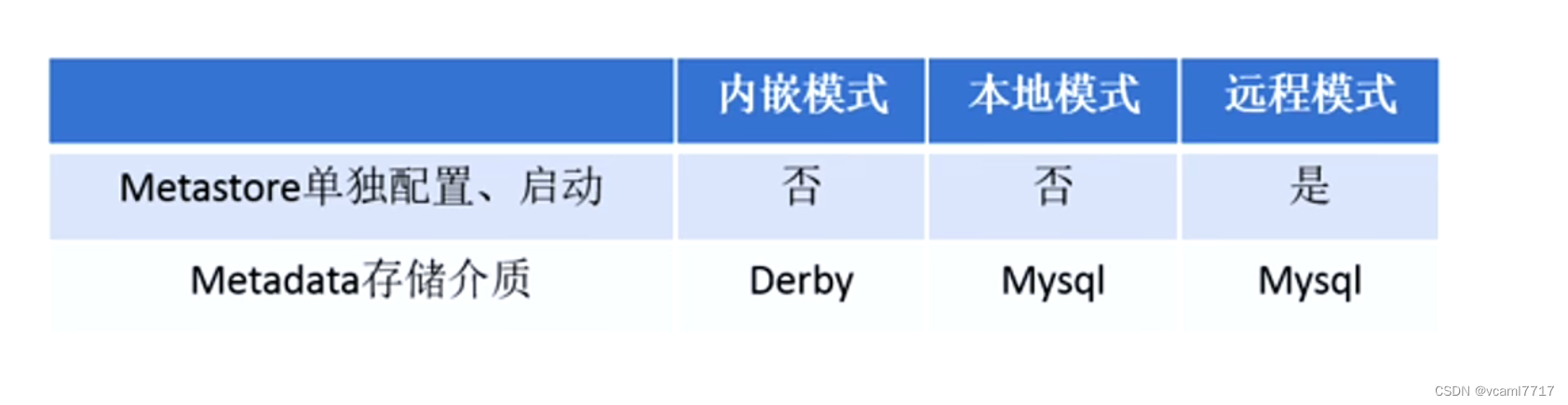
我们正常使用hive的时候 都是推荐远程模式 因为这种模式最接近我们日常的使用场景。
远程模式:
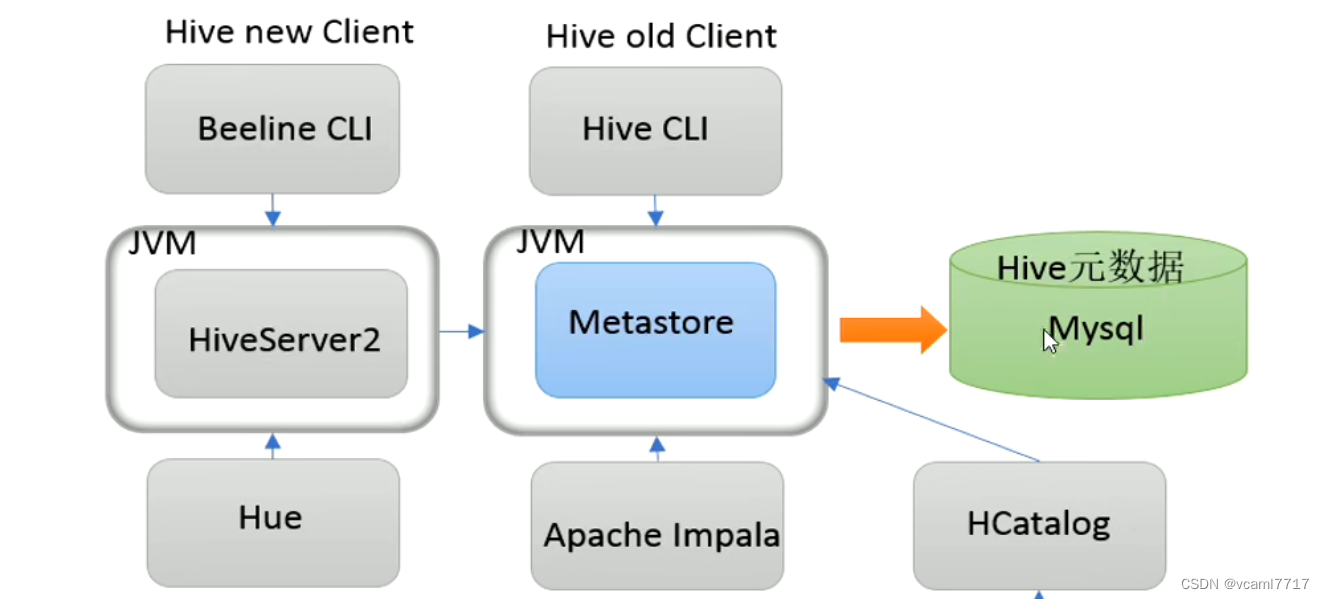
远程模式有新老两套配置。
现在都强烈用新配置了, 这里新配置由多了一个东西 叫做HS2,新手觉得很sb,本来元数据外面套一个元数据服务,现在元数据服务外面还有再套一个HS2.
只能说设计者刚开始就没想周全,所以后面新框架又加了这个组件。
所以现在我们通用的就是二代客户端,二代客户端怎么访问呢?
在 hive_home/bin/ 下面 有一个 beeline 他是一个jdbc客户端 他的性能和安全性都要比第一代优秀。
这里有个关键点要注意, beeline只能访问HS2服务 不能跳过去直接访问metastore, 所以我们在启动H2服务之前 必须先确定启动元数据服务
启动Hive服务
现在万事俱备,我们一步一步启动服务,先启动hadoop集群
start-all.sh
然后我们启动元数据服务
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service metastore &
启动完之后 打开jps 查看一下 发现多了一个runjar 这个就是metastore的后台进程
最后我们启动HS2服务:
nohup /export/server/apache-hive-3.1.2-bin/bin/hive --service hiveserver2 &
这样我们的hive服务就启动成功了!
这里又要画重点理解了, 注意 我们在集群的每天机器上 都安装了hadoop, 并且配置了主从节点。 但是hive我们并没有每天机器都安装,我们只安装第一台机器,所以从安装角度说他是单机的,但是它为什么优势分布式查询呢? 因为它的数据只存在hdfs 计算又用的是MR 所以它等于是自己是单机 但是白嫖了hdfs的集群特性。 所以它虽然只安装一台机器 但是背靠hadoop这颗大树 依然可以达到分布式的效果
理解hive的配置文件
理解配置文件是非常必要的,这个必要性就在于 从配置文件你能体会到hive的各个组合是怎么联系起来的,它是怎么和Hadoop配合的
这里主要放两个文件 其他文件就不多啰嗦了
我们找到hive目录的conf文件夹下面:
- hive-env:

这里面配置环境相关的比如 这台机器上Hadoop的路径
比如总的配置目录指定了这个conf文件夹
比如指定了jar包的路径
- hive-site: 这个配置文件很重要:
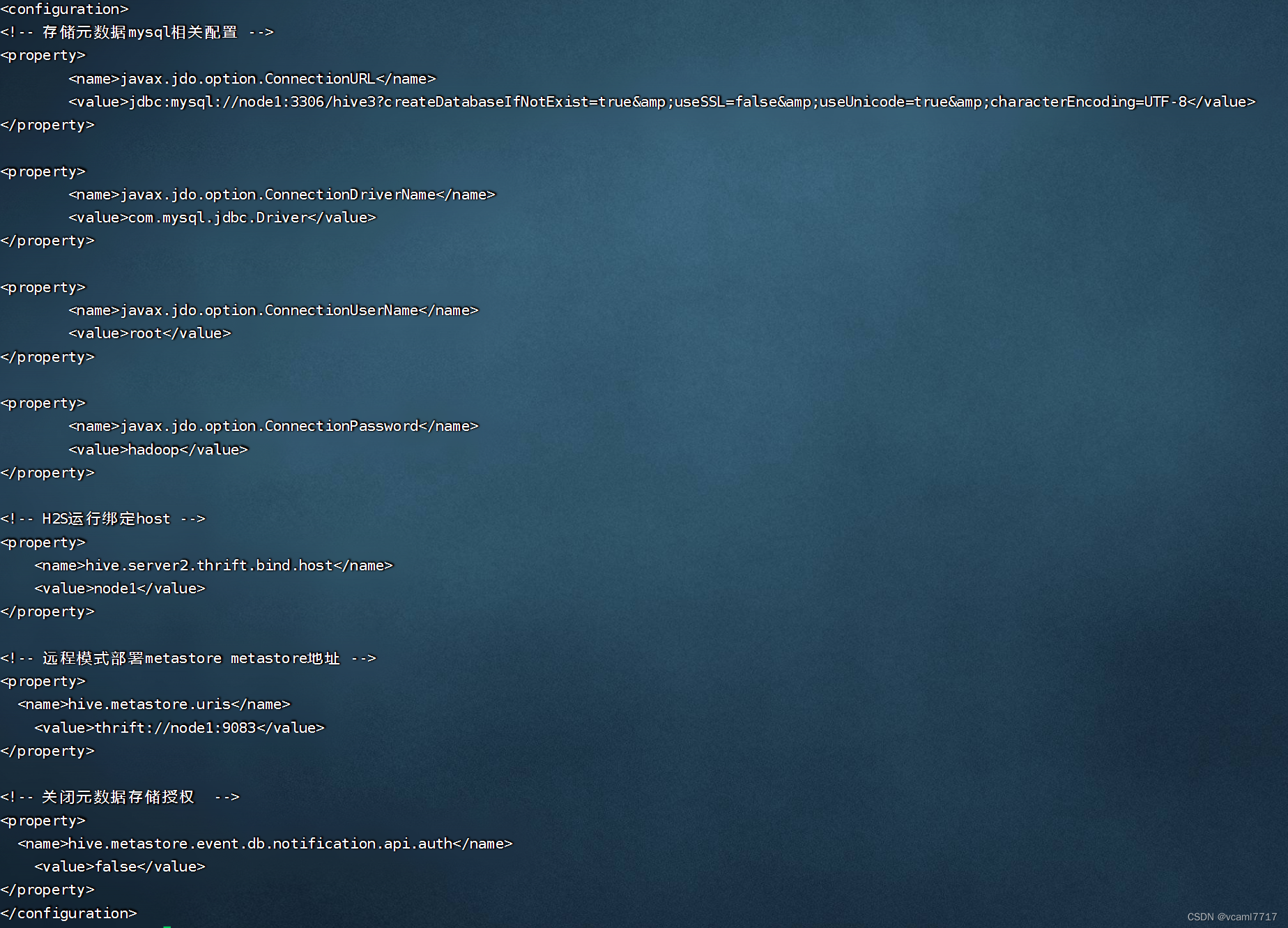 仔细读一下这个配置文件 首先刚开始可以看到 他配置了存储元数据的mysql信息,既然远程模式元数据要单独存储mysql,那么你mysql的ip要有吧 端口要有吧 数据库名要有吧 jdbc连接驱动要有吧 用户名密码 肯定要有吧 这里都配齐全了,所以这就是为什么metastore能连接到mysql里的元数据了
仔细读一下这个配置文件 首先刚开始可以看到 他配置了存储元数据的mysql信息,既然远程模式元数据要单独存储mysql,那么你mysql的ip要有吧 端口要有吧 数据库名要有吧 jdbc连接驱动要有吧 用户名密码 肯定要有吧 这里都配齐全了,所以这就是为什么metastore能连接到mysql里的元数据了
然后它配置了H2运行绑定host 它绑定了node1 这台机器 作为H2服务的运行机器
然后它配置了远程模式部署metastore的地址, 你的元数据服务部署在哪台机器上? 部署在node这台机器上 它的端口号是9083.
客户端使用hive
前面一堆操作 我们已经正式启动了hive 装也装好了 配也配好了 服务也起来了,现在我们可以正式的使用它了。
然后我们启动beeline: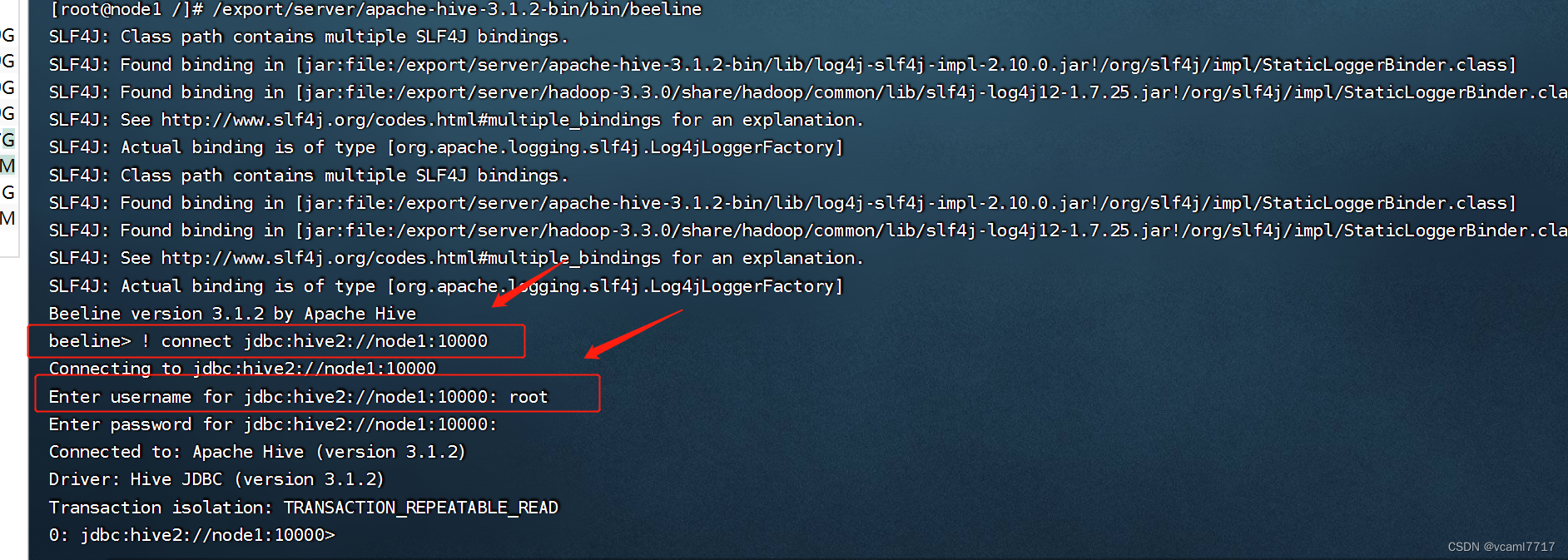
注意这里有个坑 启动beeline命令之后: 你需要输入具体的 hive2的url和端口,然后再输入用户名和密码
这个其实好理解 beeline 命令连接到hive2服务 h2服务再连接到metastore。 但是你连接hive2 你要告诉beeline hive服务的具体信息 它才能登进去 就像你从数据库管理软件 登入mysql一样。
*这里记一个h2服务的默认端口 10000,类似mysql是3306
然后一路下去 hive服务就算起来了!:
现在你可以输入各种基础的sql命令 来玩hive了!
版权归原作者 vcaml7717 所有, 如有侵权,请联系我们删除。