
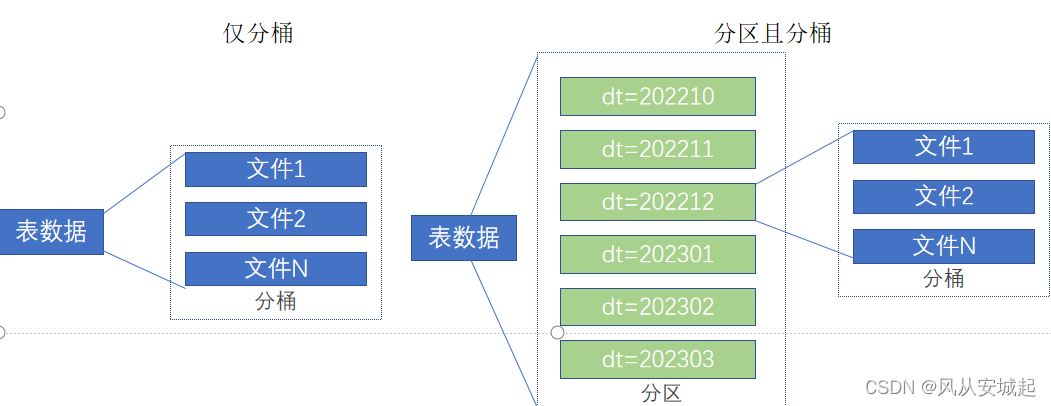
二,分桶表
分桶和分区一样,也是一种通过改变表的存储模式,从而完成对表优化的一种调优方式 但和分区不同,分区是将表拆分到不同的子文件夹中进行存储,而分桶是将表拆分到固定数量的不同文件中进行存储
(1)分桶表的创建
开启分桶的自动优化(自动匹配reduce task数量和桶数量一致)
set hive.enforce.bucketing=true;
(2)创建分桶表
create table course (c_id string,c_name string,t_id string) clustered by(c_id) into 3 buckets row format delimited fields terminated by '\t';
(3)分桶表数据加载
桶表的数据加载,由于桶表的数据加载通过load data无法执行,只能通过insert select. 所以,比较好的方式是
1. 创建一个临时表(外部表或内部表均可),通过load data加载数据进入表
2. 然后通过insert select 从临时表向桶表插入数据
(1)创建一个临时中转表
create table myhive.course_tmp (c_id string,c_name string,t_id string) row format delimited fields terminated by '\t';
(2)向中转表load data数据
load data local inpath '/home/hadoop/score.txt' into table myhive.course_tmp;
(3)从中转表进行insert select向分桶表加载数据
insert overwrite table myhive.course select * from myhive.course_tmp cluster by(c_id); select * from myhive.course;
三,修改表
1.表的重命名
alter table old_table_name rename to new_table_name;
2.修改表的属性
ALTER TABLE table_name SET TBLPROPERTIES table_properties;
table_properties : (property_name = property_value, property_name = property_value, ... )
3.添加分区
ALTER TABLE tablename ADD PARTITION (month='201101'); 新分区是空的没数据,需要手动添加或上传数据文件
4.修改分区值
ALTER TABLE tablename PARTITION (month='202005') RENAME TO PARTITION (month='201105');
5.删除分区(只删除元数据,数据本身还在)
ALTER TABLE tablename DROP PARTITION (month='201105');
6.增加列
ALTER TABLE table_name ADD COLUMNS (v1 int, v2 string);
7.修改列名
ALTER TABLE test_change CHANGE v1 v1new INT;
8.清空数据
TRUNCATE TABLE tablename; 只可以清空内部表
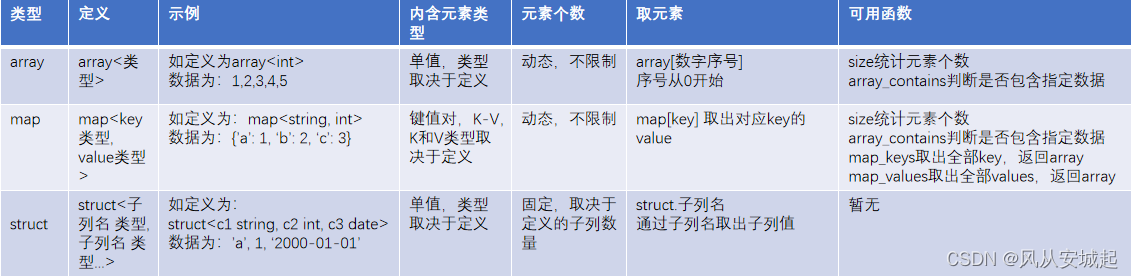
四,数组类型
create table myhive.test_array(name string, work_locations array<string>) row format delimited fields terminated by '\t' collection items terminated by ',';row format delimited fields terminated by '\t' 表示列分隔符是\t
collection items terminated by ',' 表示集合(array)元素的分隔符是逗号
导入数据
load data local inpath '/home/hadoop/data_for_array_type.txt' overwrite into table myhive.test_array;
arry查询:
-- 查询所有数据
select * from myhive.test_array;
-- 查询loction数组中第一个元素
select name, work_locations[0] location from myhive.test_array;
-- 查询location数组中元素的个数
select name, size(work_locations) location from myhive.test_array;
-- 查询location数组中包含tianjin的信息
select * from myhive.test_array where array_contains(work_locations,'tianjin');
五,map类型
map类型其实就是简单的指代:
Key-Value型数据格式。 有如下数据文件,其中members字段是key-value型数据 字段与字段分隔符: “,”;需要map字段之间的分隔符:"#";map内部k-v分隔符:":"
id,name,members,age 1,zhangsan,father:xiaoming#mother:xiaohuang#brother:xiaoxu,28 2,lisi,father:mayun#mother:huangyi#brother:guanyu,22 3,wangwu,father:wangjianlin#mother:ruhua#sister:jingtian,29 4,mayun,father:mayongzhen#mother:angelababy,26
create table myhive.test_map( id int, name string, members map<string,string>, age int ) row format delimited fields terminated by ',' collection items terminated by '#' map keys terminated by ':';
row format delimited fields terminated by ',' 字段之间的分割
collection items terminated by '#'每个键值之间的分隔符
map keys terminated by ':' 每个键值内部,k和v的分隔符
# 查询全部 select * from myhive.test_map; # 查询father、mother这两个map的key select id, name, members['father'] father, members['mother'] mother, age from myhive.test_map; # 查询全部map的key,使用map_keys函数,结果是array类型 select id, name, map_keys(members) as relation from myhive.test_map; # 查询全部map的value,使用map_values函数,结果是array类型 select id, name, map_values(members) as relation from myhive.test_map; # 查询map类型的KV对数量 select id,name,size(members) num from myhive.test_map; # 查询map的key中有brother的数据 select * from myhive.test_map where array_contains(map_keys(members), 'brother');
六,struct结构
struct类型是一个复合类型,可以在一个列中存入多个子列,每个子列允许设置类型和名称 有如下数据文件,说明:字段之间#分割,struct之间冒号分割
1#周杰轮:11
2#林均杰:16
3#刘德滑:21
4#张学油:26
5#蔡依临:23
create table myhive.test_struct( id string, info struct<name:string, age:int> )
row format delimited fields terminated by '#'
collection items terminated by ':';
版权归原作者 风从安城起 所有, 如有侵权,请联系我们删除。