
一. 安装准备
1. 打开虚拟机,启动配置了NameNode节点的虚拟机(一般和mysql在同一台虚拟机)并连接shell

二. 安装
1. 上传hive安装包
hive安装包
提取码:6666
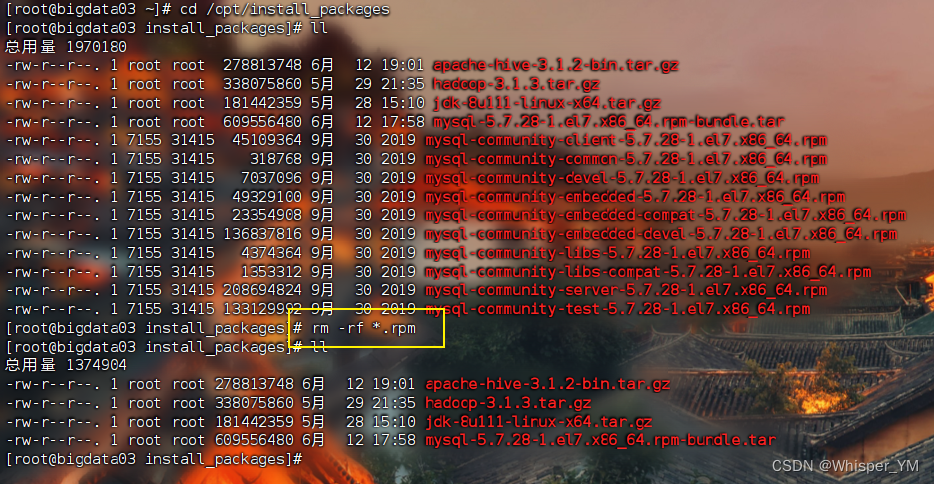
切换到/opt/install_packages目录下
可以将之前解压的rpm文件删除
将安装包拖至目录下

2. 解压
tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/softs/
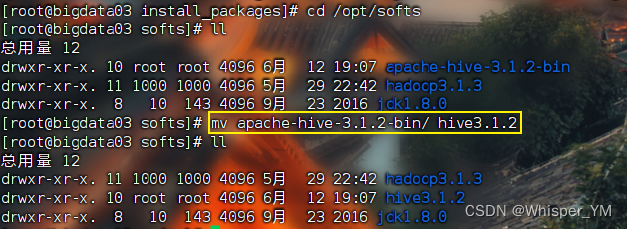
切到/opt/softs目录下,修改包名称
cd /opt/softs
mv apache-hive-3.1.2-bin/ hive3.1.2
3. 配置环境变量
vim /etc/profile
添加以下内容
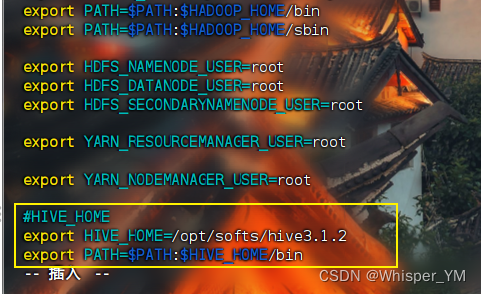
#HIVE_HOME
export HIVE_HOME=/opt/softs/hive3.1.2
export PATH=$PATH:$HIVE_HOME/bin
重新加载配置文件
source /etc/profile
输出路径检查
echo $HIVE_HOME

4. 解决jar包冲突
进入hive3.1.2目录下
cd /opt/softs/hive3.1.2
ll
cd lib
ll
(1)将log4j-slf4j-impl-2.10.0.jar设置为不可用(修改后缀的方式)
mv log4j-slf4j-impl-2.10.0.jar log4j-slf4j-impl-2.10.0.jar.bak 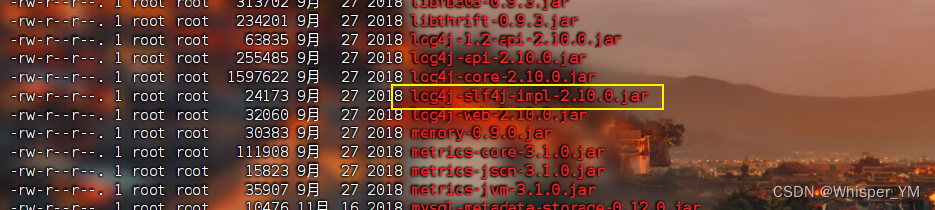

(2)上传mysql连接的jar包
jar包
提取码:6666
将jar包拖至jar目录下
将上传的jar包拷贝到hive的lib目录下
cp /opt/jar/mysql-connector-java-5.1.37.jar /opt/softs/hive3.1.2/lib/

(3)调整guava-*.jar包
复制一个窗口,到hadoop目录下去找类似的包
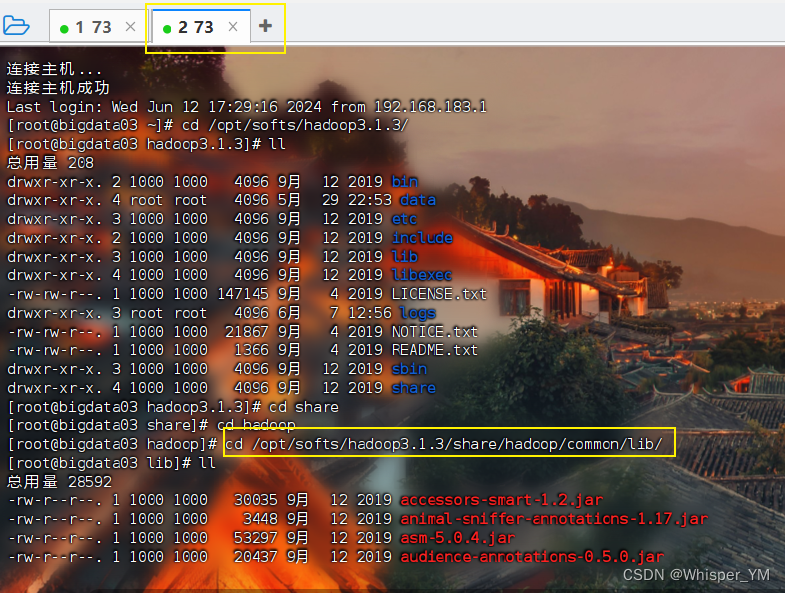
cd /opt/softs/hadoop3.1.3/share/hadoop/common/lib/
ll

把高版本的jar包拷贝到hive 的lib目录下
cp guava-27.0-jre.jar /opt/softs/hive3.1.2/lib
执行成功后回到原窗口检查

将原来版本的加上bak后缀
mv guava-19.0.jar guava-19.0.jar.bak

三. 配置文件的修改
修改hive的conf文件
cd /opt/softs/hive3.1.2/conf/
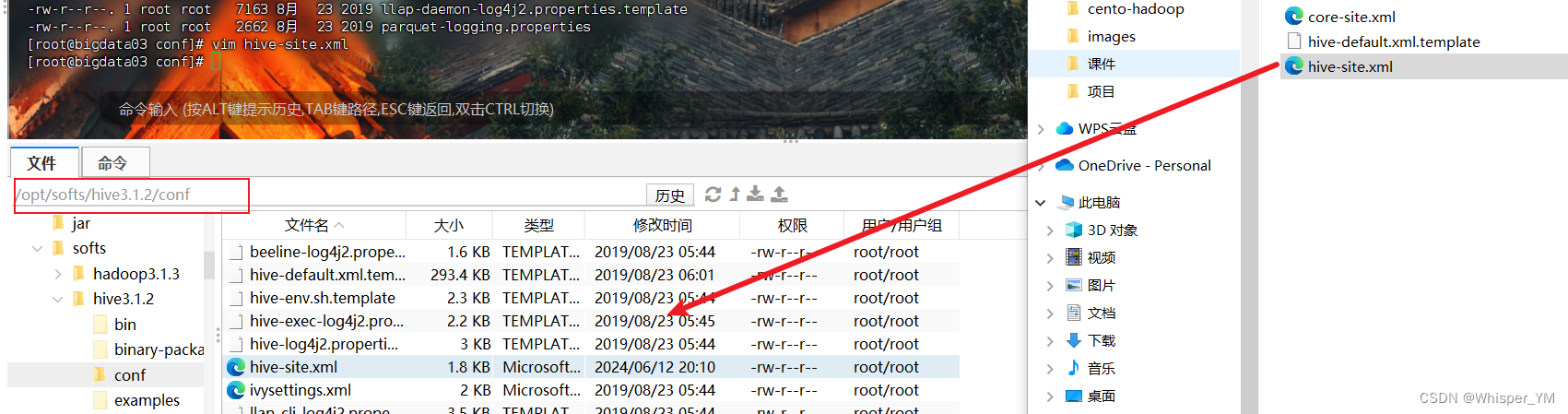
1. hive-site.xml内容如下,编写完成后上传到conf目录下
<?xml version="1.0" encoding="UTF-8" standalone="no"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <configuration> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://bigdata03:3306/hive?createDatabaseIfNotExist=true&useSSL=false&useUnicode=true&characterEncoding=UTF-8</value> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.jdbc.Driver</value> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>root</value> </property> <property> <name>javax.jdo.option.ConnectionPassword</name> <value>123456</value> </property><property> <name>hive.metastore.warehouse.dir</name> <value>/user/hive/warehouse</value> </property><!-- Hive 默认在 HDFS 的工作目录 --><property> <name>hive.server2.thrift.bind.host</name> <value>bigdata03</value> </property> <property> <name>hive.server2.thrift.port</name> <value>10000</value> </property> <property> <name>hive.server2.enable.doAs</name> <value>false</value> </property> <property> <name>hive.server2.active.passive.ha.enable</name> <value>true</value> </property> </configuration><!-- 指定 hiveserver2 连接的 host hive的安装host根据实际进行修改 -->
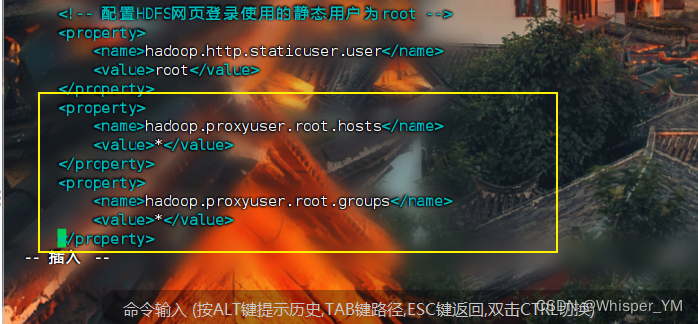
2. 在hadoop中core-site.xml中添加如下配置
<property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property><!-- 安装hive时 在hadoop中core-site.xml中添加如下配置 --> <!-- 从任何主机登录的root用户可以伪装成一个属于任何group的用户 -->
vim /opt/softs/hadoop3.1.3/etc/hadoop/core-site.xml
3. 将修改同步到另外两台虚拟机
scp core-site.xml root@bigdata04:/opt/softs/hadoop3.1.3/etc/hadoop/
scp core-site.xml root@bigdata05:/opt/softs/hadoop3.1.3/etc/hadoop/
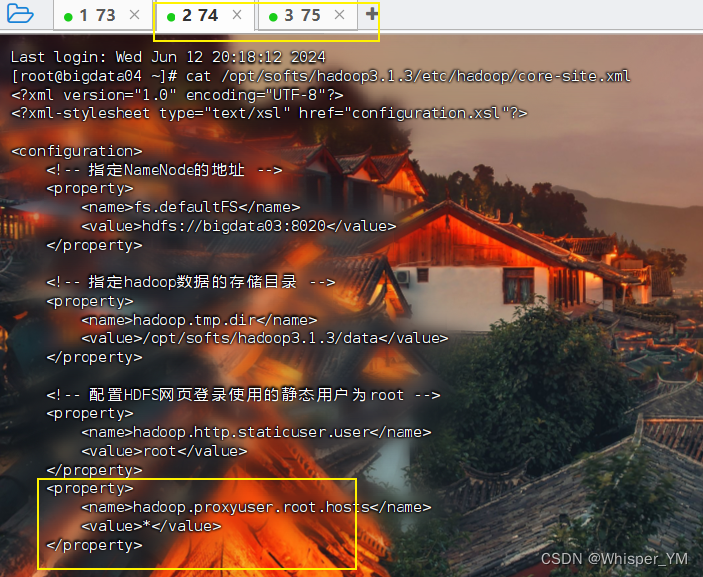
 分别到另两台虚拟机上查看
分别到另两台虚拟机上查看
cat /opt/softs/hadoop3.1.3/etc/hadoop/core-site.xml
四. 初始化hive的元数据库
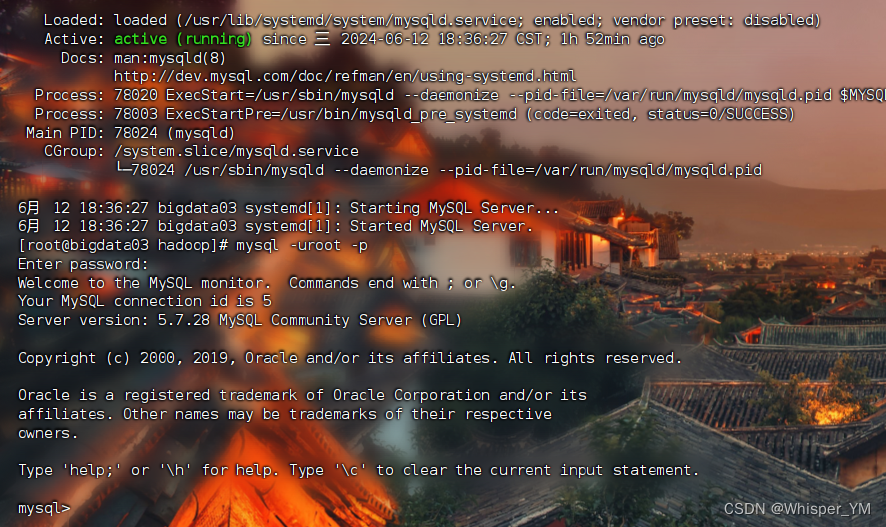
1.开启mysql并连接数据库
2. 进行初始化
再复制一台虚拟机
cd /opt/softs/hive3.1.2/bin
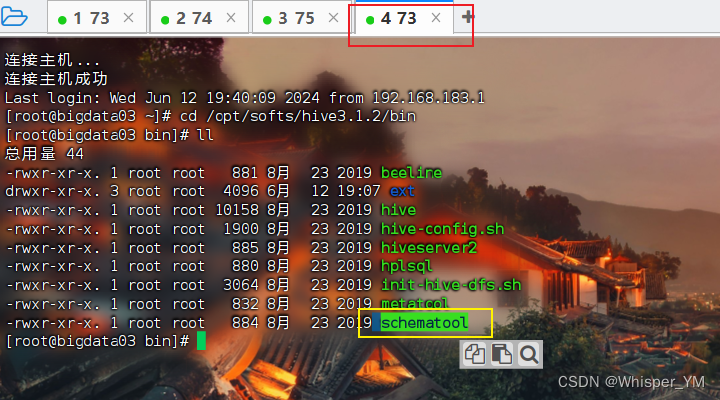
schematool -dbType mysql -initSchema
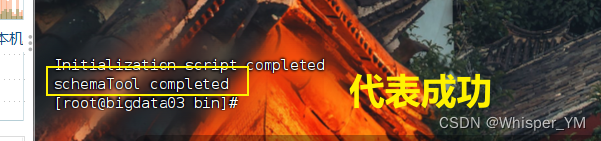
3. 查看
在原虚拟机上查看数据库
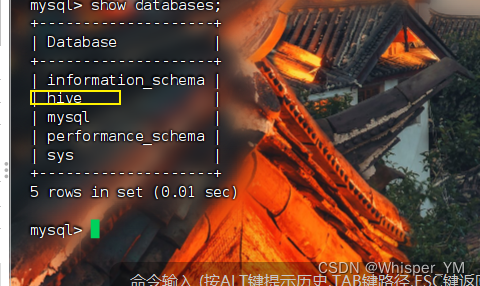
use hive;
show tables;

五. 启动hive
在复制的虚拟机上执行hive命令
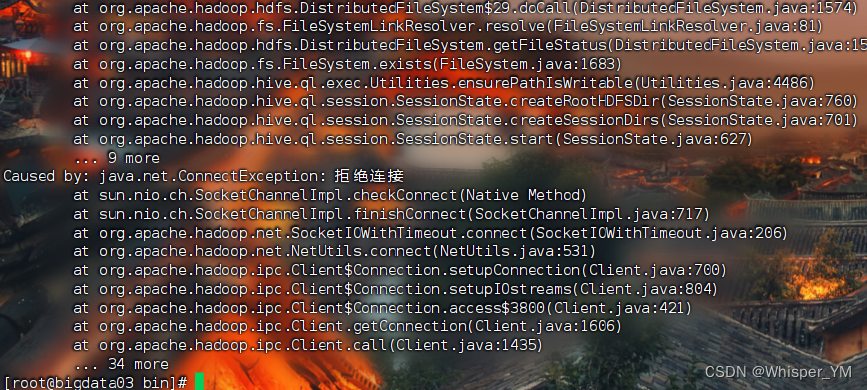
出错喽
因为没启动hdfs
启动一下
start-dfs.sh
再次启动hive
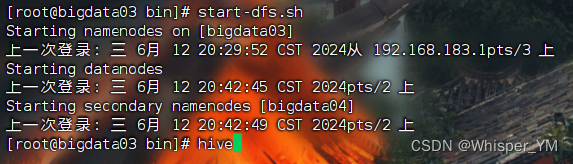
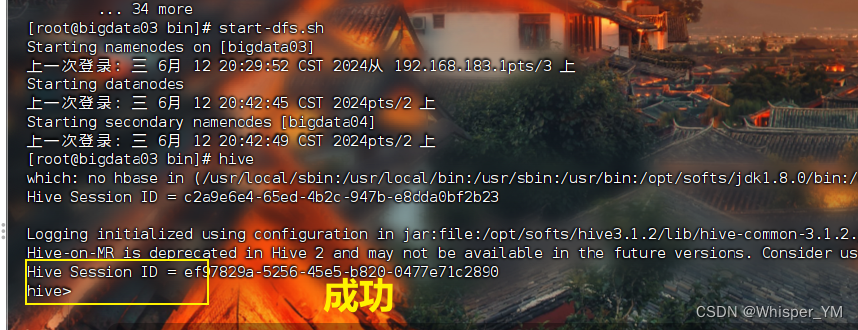
如果启动有问题,可以查看hive日志
tail -500f /tmp/root/hive.log
版权归原作者 Whisper_YM 所有, 如有侵权,请联系我们删除。