
本文旨在教会读者能够简单使用两种爬虫,完成一些基础的爬虫操作,会给出一些优化思路,并不会深入的讲解优化方法。
目录
前言
如何安全的爬虫?
大家都在说着爬虫的入门到入狱,让初学的我也心惊胆战
虽然技术本无对错之分,但是在爬虫时还是要遵循爬虫的‘君子’协议来保护自己。
1.解析网站robots.txt规则
2.避开个人隐私信息数据
3.不要影响网站正常运行
4.避免数据的私下买卖
5.控制反爬破解代码传播
6.拒绝商业数据和恶意竞争
“本文默认已经安装requests库、bs4库、selenium库并配置环境”
一、爬虫部分——网页源码获取
1、Requests
常用方法介绍
import requests
#发送一个get请求并得到响应
r = requests.get('https://www.baidu.com')
#查看响应对象的类型
print(type(r))
#查看响应状态码,200为正常访问的值
print(r.status_code)
#查看响应的内容
print(r.text)
#查看cookies
print(r.cookies)
我们使用get方法时,需要传入一个请求头,否则,默认的请求头会很容易被网站检测到并拒绝访问。
此外,当爬取多个网页时,尽量使用time.sleep()以防止频繁访问而出现错误。
import requests
header = {"User-Agent": "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (HTML, like Gecko) Chrome/35.0.2117.157 Safari/537.36"}
#发送一个get请求并得到响应
r = requests.get(url='https://www.baidu.com', headers=header)
print(r.text)
# 现在的r.text即为我们需要处理的网页内容
我们向浏览器发送请求的目的就是得到网页的全部内容,再通过数据处理,将需要的网页内容解析出来最终得到我们需要的数据。
本文只是对requests库的基础使用进行介绍
详细的使用方法可以参考这篇文章 -> requests库的使用(一篇就够了) 
部分运行结果如图所示,可见与我们审查时的网页元素是一致的,但是有些网页爬取下来的内容与我们看到的并不一致,这些网页就属于异步加载的页面,需要我们使用异步爬虫,本文会使用selenium库来实现异步爬取。
2、Selenium
selenium库能模拟浏览器的各种操作,但是速度比较慢
在完成环境配置后,可用如下代码实验是否可用
from selenium import webdriver
# 启动Chrome浏览器,如果能成功打开就证明环境配置成功,接下来就可以开始愉快的爬虫了
driver = webdriver.Chrome()
常用方法演示
from selenium import webdriver
from selenium.webdriver.common.by import By
import time
# 启动 Chrome 浏览器
driver = webdriver.Chrome()
# 访问百度首页
driver.get("https://www.baidu.com")
# 在搜索框中输入关键字
search_box = driver.find_element(By.ID, 'kw')
# 同一标签的定位方法也不一定只有一种,也可以替换成search_box = driver.find_element(By.NAME, "wd")
# 在搜索框中输入文本
search_box.send_keys("Python")
# 点击搜索按钮
search_button = driver.find_element(By.ID, "su")
search_button.click()
# 等待1s让网页加载
time.sleep(1)
# 打印当前网页内容
print(driver.page_source)
# 10s后关闭浏览器
time.sleep(10)
# 关闭浏览器
driver.quit()
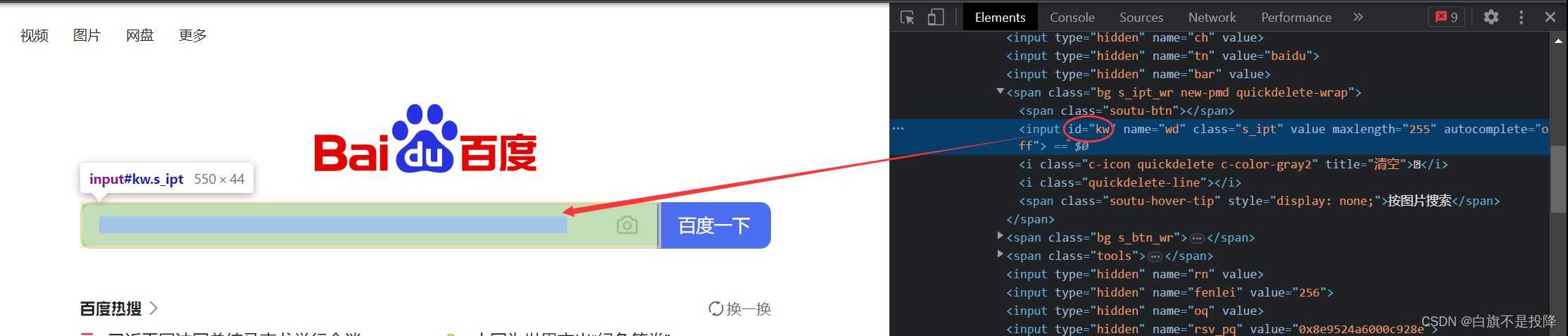
根据检查得到的数据可以帮助我们定位到需要进行操作的位置,但是定位时使用的这些方式,只有id是唯一的,其他的像是name,class,tag都是可能有多个的,因此容易定位不到我们需要的位置上。因此为了更准确的定位,我们选用xpath定位方法。
XPath 是一种在 XML 和 HTML 文档中查找信息的语言。XPath 使用路径表达式来选取文档中的节点或者节点集合。这些路径表达式类似于在文件系统中的路径,可以用来指定文档树中的某个位置或节点。在浏览器中,打开审查,我们可以通过点击某元素右键复制XPath。
import time
from selenium.webdriver.common.by import By
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.baidu.com")
# 定位到输入框并输入‘python’
driver.find_element(By.XPATH, '/html/body/div[1]/div[1]/div[5]/div/div/form/span[1]/input').send_keys('Python')
# 定位到搜索按钮并点击
driver.find_element(By.XPATH, '/html/body/div[1]/div[1]/div[5]/div/div/form/span[2]/input').click()
# 等待1s响应
time.sleep(1)
# 打印当前网页源码
print(driver.page_source)
其中time.sleep(1)目的是让网页在点击后能够响应出内容,否则爬取到的内容不一定是目标内容。
如果还未进行环境配置或者想要了解更多操作可以参考这篇文章 -> selenium用法详解
二、数据处理——解析网页
数据解析选用BeautifulSoup进行入门
BeautifulSoup则用于解析 HTML 和 XML 文件。它提供了一些方便的方法来遍历、搜索、修改 HTML 和 XML 文件的结构和内容。
BeautifulSoup
from bs4 import BeautifulSoup
# text = r.text 或者 text = drive.page_source 这里使用一段网页源码text以便于演示
text = '''
<!DOCTYPE html>
<html>
<head>
<title>示例表格</title>
</head>
<body>
<ul>
<li><a href="http://example.com/page1.html">Page 1</a></li>
<li><a href="http://example.com/page2.html">Page 2</a></li>
<li><a href="http://example.com/page3.html">Page 3</a></li>
</ul>
<h1>示例表格</h1>
<table>
<tr class='sample0'>
<td>李四</td>
<td>22</td>
<td>女</td>
</tr>
<tr id='sample1'>
<td>王五</td>
<td>25</td>
<td>男</td>
</tr>
</table>
</body>
</html>
'''
# 对所需处理网页内容进行初始化处理
soup = BeautifulSoup(text, 'html.parser')
# 找出text中第一个tr标签的一行内容
data = soup.find('tr')
# 找出text中所有tr标签的内容
datas = soup.find_all('tr')
print(data)
print('-----------')
# datas中由于是网页里所有带tr标签的行,因此可以遍历datas的每一行
for s in datas:
print(s)
print('-----------')
# 在定位时,并不是只有tag标签,还有id,name,calss,style等等。其中id为唯一的,是最准确的定位方式,需要注意的是,为了与python关键词区分开,class后面要加一个'_',如下
print(soup.find_all('tr',class_='sample0'))
print('-----------')
print(soup.find_all('tr',id='sample1'))
print('-----------')
# get_text()方法用于获取标签内的文本内容
print(data.get_text())
for s in datas:
print(s.get_text())
print('-----------')
# 链接的获取
urls = soup.find_all('a')
for url in urls:
print(url['href'])
soup 中'html.parser'为 解析器,简单了解即可 -> BeautifulSoup解析器及区别
输出结果
<tr class="sample0">
<td>李四</td>
<td>22</td>
<td>女</td>
</tr>
-----------
<tr class="sample0">
<td>李四</td>
<td>22</td>
<td>女</td>
</tr>
<tr id="sample1">
<td>王五</td>
<td>25</td>
<td>男</td>
</tr>
-----------
[<tr class="sample0">
<td>李四</td>
<td>22</td>
<td>女</td>
</tr>]
-----------
[<tr id="sample1">
<td>王五</td>
<td>25</td>
<td>男</td>
</tr>]
-----------
李四
22
女
李四
22
女
王五
25
男
-----------
http://example.com/page1.html
http://example.com/page2.html
http://example.com/page3.html
这里只是给出了一段源码进行演示,大家可以关联上爬虫部分,对一些网页进行数据处理。
import requests
from bs4 import BeautifulSoup
header = {"User-Agent": "Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (HTML, like Gecko) Chrome/35.0.2117.157 Safari/537.36"}
r = requests.get(url='https://www.baidu.com', headers=header)
print(r.text)
soup = BeautifulSoup(r.text, 'html.parser')
'''
code_part
这样串联起来即可对网页中所需要数据进行爬取,这样我们就得到了一个完整的爬虫
'''
即使得到了数据,也还是需要我们进行数据整理,可以用xlsxwriter库做excel表格文件或者以csv等形式保存,然后再对数据进行后续的处理。
三、成功入门之后的优化
1、目前很火的httpx+parsel
2、高效便捷的pyppeter
3、爬取速度可以采用多线程、分布式爬虫加快爬取速度,但是注意进程数量,不要对服务器造成较大负载。
4.如果你会正则表达式,搭配xpath能够实现更强大的数据解析功能
总结
以上就是本文的全部内容,本文仅仅简单介绍了两种基础爬虫的使用和简单的数据处理方法,而进一步的优化可以用提供的思路继续学习。如有错误之处还请大家多多指正。
版权归原作者 白旗不是投降 所有, 如有侵权,请联系我们删除。