
一、Hadoop基础操作
按要求完成以下操作:
1、在HDFS中创建目录 /user/root/你的名字。 例如:李四同学 /user/root/lisi,后同。
首先需要启动hdfs,在终端输入如下命令:
start-dfs.sh
在终端输入如下命令创建目录:
hdfs dfs -mkdir -p /user/root/***(你自己的名字全拼,下同)
2、创建本地文件lisi.txt,文件内容为包括Lisi love Hadoop等其他任意输入的6行英文句子,并将该文件上传到HDFS中第1题所创建的目录中。
在终端的root目录下面创建本地文件并输入题目要求的内容:
vim ***.txt
然后我们再在终端输入上传命令:
hdfs dfs -put ***.txt /user/root/***
3、查看上传到HDFS中的lisi.txt文件的内容。
直接在终端输入查看命令:
hdfs dfs -cat /user/root/***/***.txt
4、在Hadoop官方的示例程序包hadoop-mapreduce-examples-3.1.3.jar中,包括计算Pi值的测试模块,使用hadoop jar命令提交计算Pi的MapReduce任务。
首先,启动yarn,命令如下:
start-yarn.sh
然后进入到hadoop下的mapreduce目录中:
cd /usr/local/servers/hadoop/share/hadoop/mapreduce/
最后执行如下命令即可计算Pi:
hadoop jar hadoop-mapreduce-examples-3.1.3.jar pi 4 4
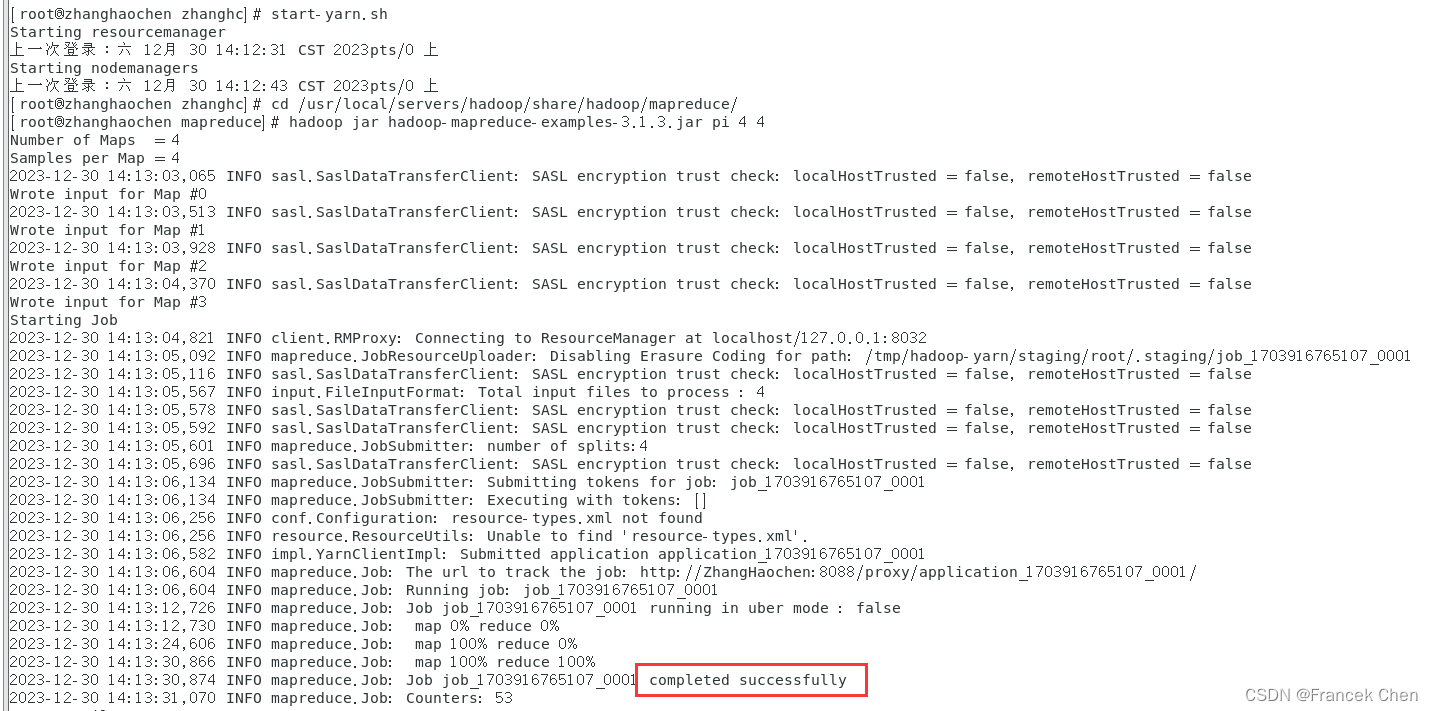
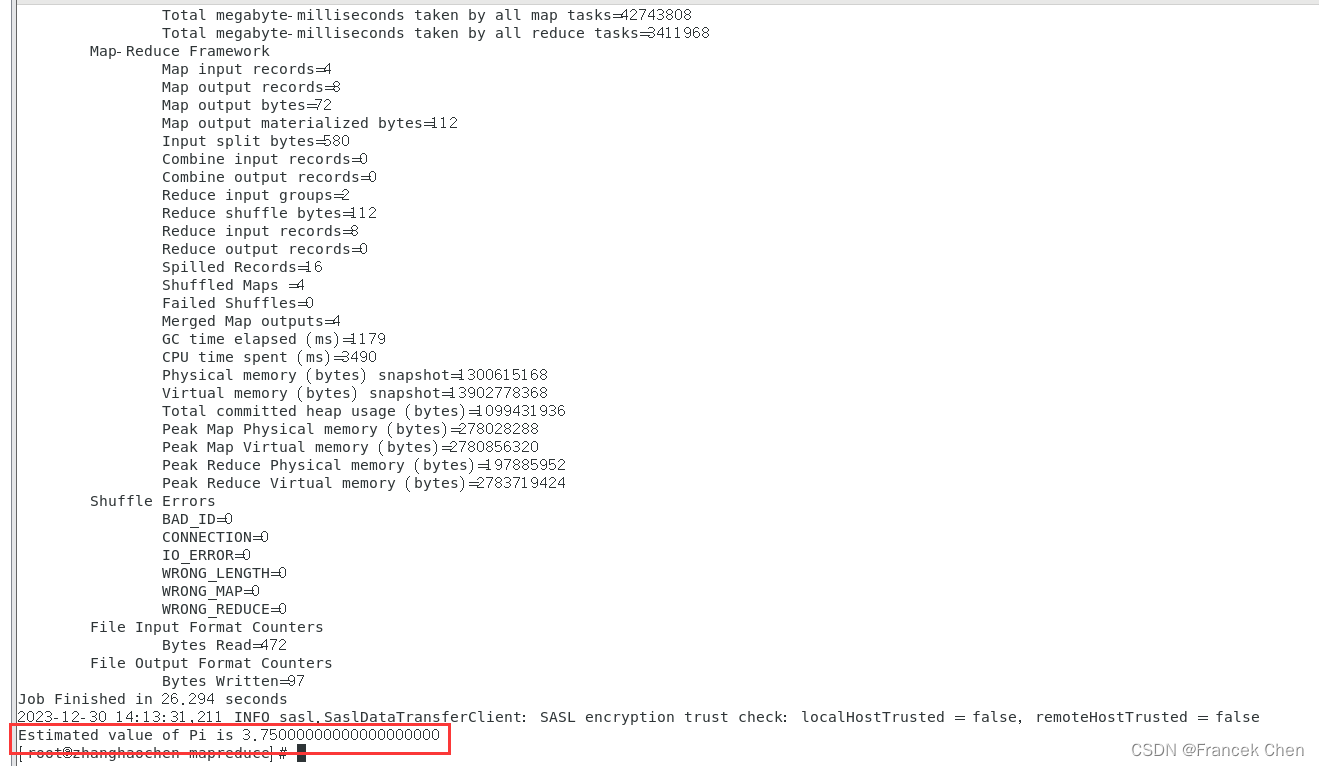
可以看出精度不是很高,上面命令后面的两个数字含义是,第一个4是运行4次map任务,第二个4是每个map任务投掷次数,总投掷次数就是两者相乘,想要提高精度就可以让数字变大,但是很容易出现作业计算失败的异常,这是因为计算内存不够,所以不能调的太大。
5、直接将第4题的计算结果保存到/user/root/lisi目录中lisiPi文件里。
先将计算结果保存到本地系统home目录下:
hadoop jar hadoop-mapreduce-examples-3.1.3.jar pi 4 4 > /home/zhanghc/***PI.txt
然后将***PI.txt文件上传到HDFS的“/user/root/***”目录下并查看结果:
hdfs dfs -put /home/zhanghc/***PI.txt /user/root/***
hdfs dfs -cat /user/root/***/***PI.txt

二、RDD编程
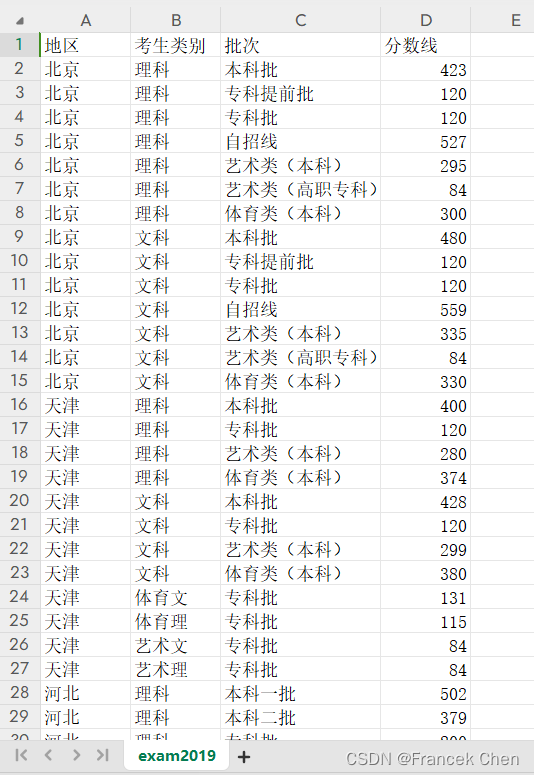
现有一份2019年我国部分省份高考分数线数据文件exam2019.csv,共有四个数据字段,字段说明如表1所示:
表1 高考分数线数据字段说明
字段名称
说明
地区
省、直辖市或自治区
考生类别
考生报考类别,如理科
批次
划定的学校级别,如本科批次
分数线
达到所属批次的最低分
为了解2019年全国各地的高考分数线情况,请使用Spark编程,完成以下需求:
1、读取exam2019.csv并创建RDD。
首先将该文件上传到我们的终端,我是放在主目录“/home/zhanghc”下的。
然后启动pyspark:
pyspark
再读取我们的文件并创建RDD:
>>> data = sc.textFile("file:///home/zhanghc/exam2019.csv")
2、查找出各地区本科批次的分数线。
# 对RDD数据进行map操作,拆分每一行数据
>>> data_map = data.map(lambda x: x.split(","))
# 对拆分后的RDD进行filter操作,过滤出本科的数据
>>> data_filter = data_map.filter(lambda x: x[2] == '本科批')
# 对过滤后的RDD进行map操作,抽取出地区和分数线
>>> data_result = data_filter.map(lambda x:(x[0],x[3]))
# 对抽取后的RDD进行reduceByKey操作,按地区进行分组
>>> data_reduce = data_result.reduceByKey(lambda x,y:x+','+y)
# 打印结果
>>> data_reduce.collect()
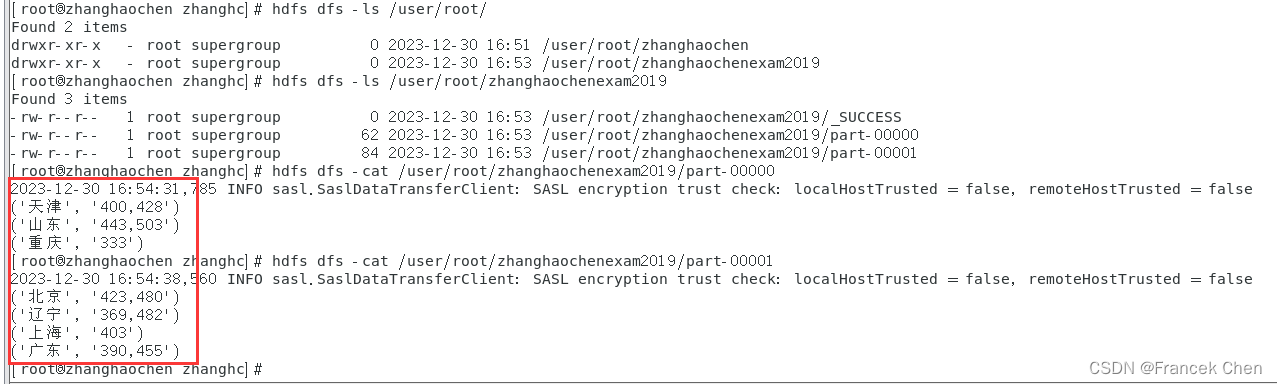
3、将结果以文本格式存储到HDFS上,命名为/user/root/你的名字exam2019。
>>> data_reduce.saveAsTextFile("hdfs://localhost:9000/user/root/***exam2019")

查看上传到HDFS的“***exam2019”中的文件内容:
三、Spark SQL编程
某餐饮企业预备使用大数据技术对过往餐饮点评大数据进行分析以提高服务与菜品质量,实现服务升级,具体情况如下:现有一份顾客对某城市餐饮店的点评数据restaurant.csv,记录了不同类别餐饮店在口味、环境、服务等方面的评分,数据共有12列,前10列数据字段的说明如表2所示,最后两列的数据为空则不描述。
表2 顾客对某城市餐饮店的点评数据字段说明
字段名称
字段名称
类别
餐饮店类别
行政区
餐饮店所在位置区域
点评数
有多少人进行了点评
口味
口味评分
环境
环境评分
服务
服务评分
人均消费
人均消费(单位:元)
城市
餐饮店所在城市
Lng
经度
Lat
纬度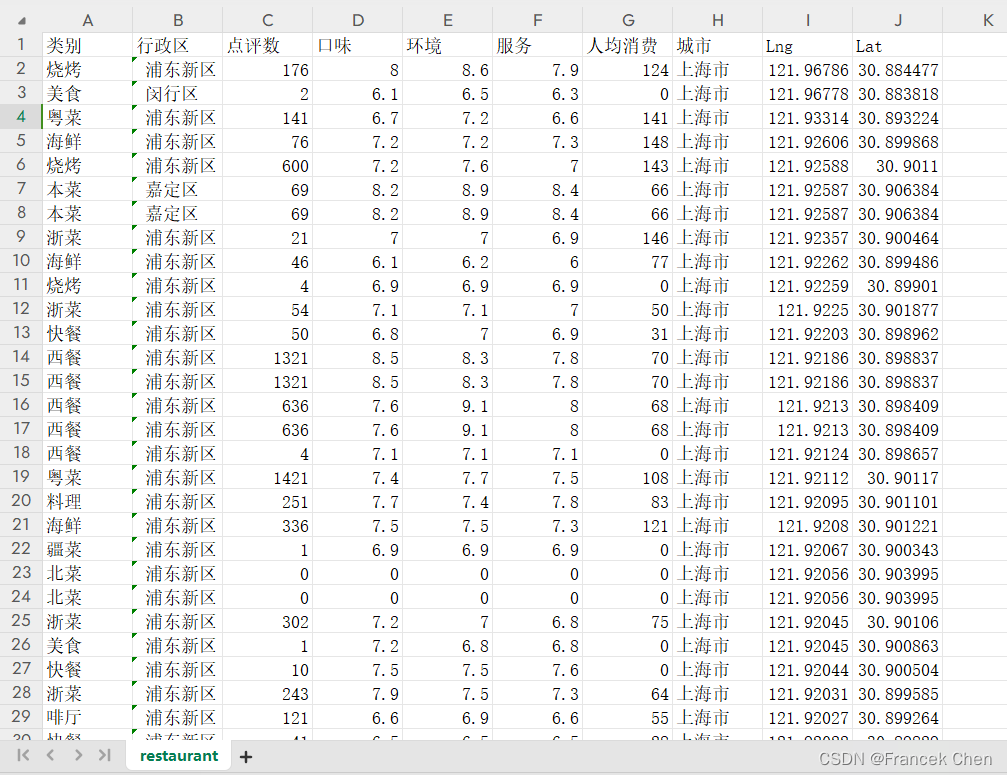
为探究人们对该城市餐饮店的点评分布情况,分析客户在餐饮方面的消费喜好,请使用Spark SQL进行编程,完成如下需求:
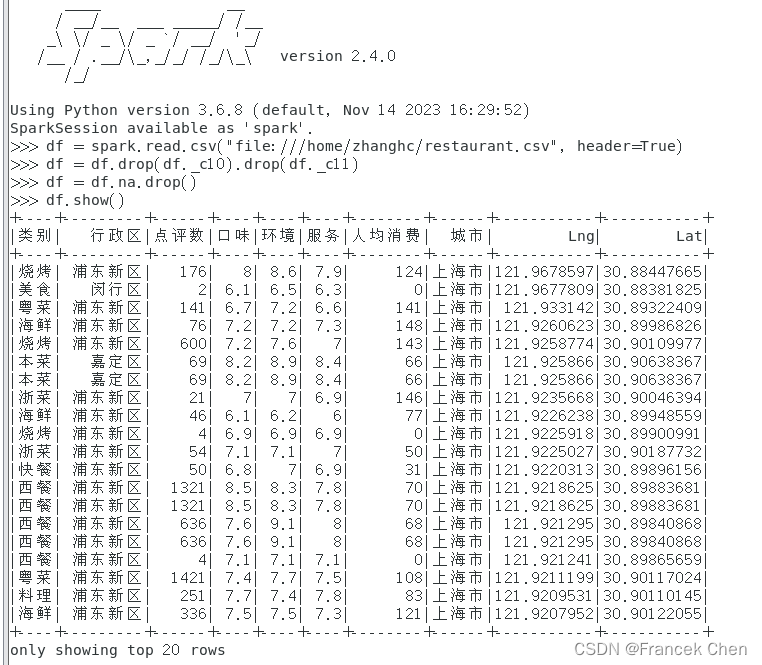
1、读取restaurant.csv数据,删除最后为空值的两列,再删除含有空值的行。
# 读取文件
>>> df = spark.read.csv("file:///home/zhanghc/restaurant.csv", header=True)
# 删除最后两列
>>> df = df.drop(df._c10).drop(df._c11)
# 删除含有空值的行
>>> df = df.na.drop()
# 查看结果
>>> df.show()
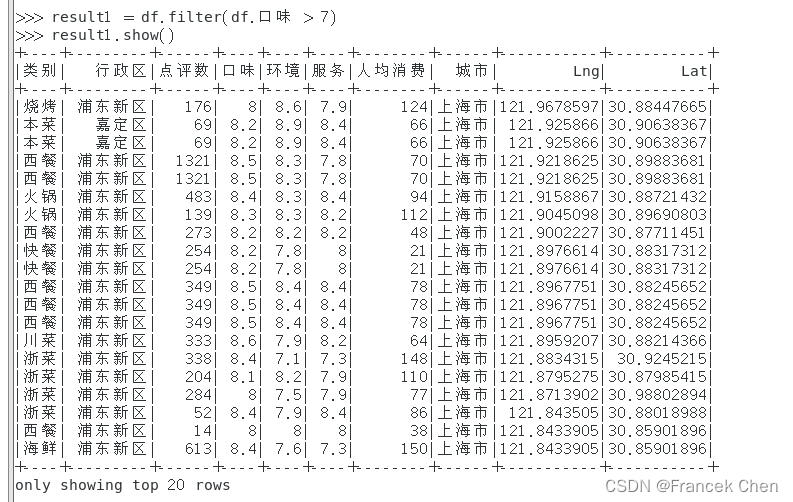
2、筛选出口味评分大于7分的数据。
>>> result1 = df.filter(df.口味 > 7)
>>> result1.show()
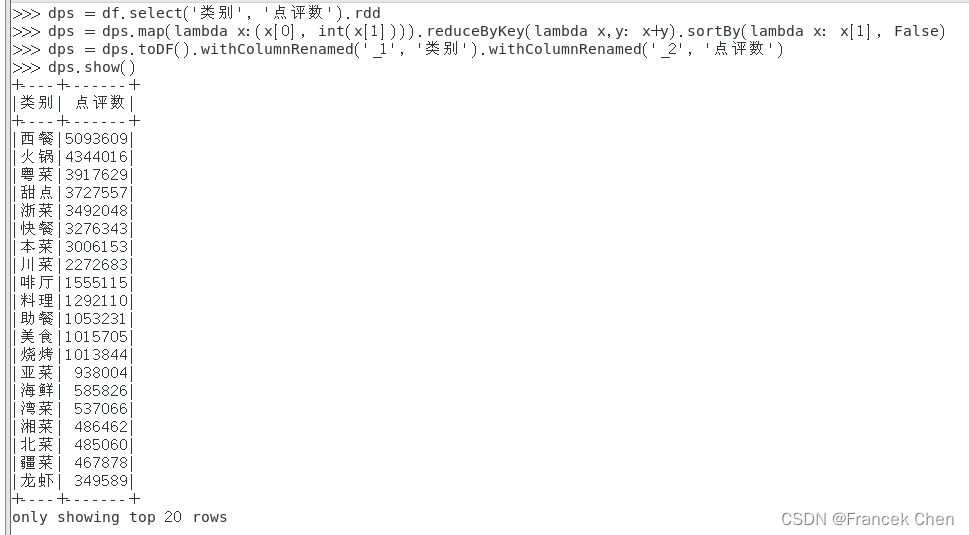
3、统计各类别餐饮店点评数,并按降序排列。
# 选出需要的列,转换成rdd
>>> dps = df.select('类别', '点评数').rdd
# 计算每种类别餐饮点评数的总和
>>> dps = dps.map(lambda x:(x[0], int(x[1]))).reduceByKey(lambda x,y: x+y).sortBy(lambda x: x[1], False)
# 将计算得出的表格标签进行修改
>>> dps = dps.toDF().withColumnRenamed('_1', '类别').withColumnRenamed('_2', '点评数')
显示结果
>>> dps.show()
4、将步骤2和步骤3的结果保存到HDFS上,命名为/user/root/你的名字restaurant。
>>> result1.rdd.saveAsTextFile("hdfs://localhost:9000/user/root/***restaurant1")
>>> dps.rdd.saveAsTextFile("hdfs://localhost:9000/user/root/***restaurant2")
查看上传到HDFS的“***restaurant”中的文件内容:

四、Spark Streaming编程
现有一份某饭店的菜单数据文件menu.txt,部分数据如表3所示,每一行有3个字段,分别表示菜品ID、菜名和单价(单位:元)。
表3 某饭店的菜单数据
1 香菇肥牛 58
2 麻婆豆腐 32
3 红烧茄子 15
4 小炒凉粉 16
5 京酱肉丝 22
6 剁椒鱼头 48
7 土豆炖鸡 38
8 锅巴香虾 66
一位顾客依次点了麻婆豆腐、土豆炖鸡、红烧茄子和香菇肥牛共4个菜,为实时计算顾客点餐的费用,请使用Spark streaming 编程完成以下操作:
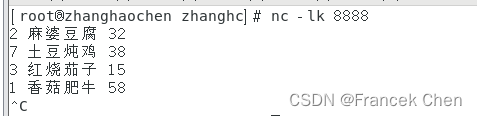
1、在虚拟机上启动8888端口。
直接在终端输入如下命令:
nc -lk 8888
2、使用Spark streaming连接虚拟机的8888端口,并实时统计顾客点餐的总费用。
创建一个py程序名为prizeSum.py,并填入如下代码:
vi prizeSum.py
# /home/zhanghc/prizeSum.py
from __future__ import print_function
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
import sys
# 从sys.argv中获取主机名和端口号
if len(sys.argv) != 3:
print("Usage:prizeSum.py <hostname> <port>", file=sys.stderr)
exit(-1)
# 创建SparkContext
sc = SparkContext(appName="pythonSparkStreamingPrizeSum")
# 创建StreamingContext
ssc = StreamingContext(sc, 5)
# 创建函数,实现累加
def accumulate(values, sums):
return sum(values) + (sums or 0)
# 设置检查点目录
ssc.checkpoint("file:///home/zhanghc/")
initialStateRDD = sc.parallelize([])
# 从指定的主机和端口接收数据流
lines = ssc.socketTextStream(sys.argv[1], int(sys.argv[2]))
# 将数据流中的每一行转换为一个元组
costs= lines.map(lambda x: x.split(" "))
# 将每一行的价格累加
totalCost = costs.map(lambda x: ("总价", int(x[2]))).updateStateByKey(accumulate, initialRDD=initialStateRDD)
totalCost.map(lambda x: x.values())
# 打印结果
totalCost.pprint()
# 启动Streaming处理流
ssc.start()
# 等待程序终止
ssc.awaitTermination()
3、启动Spark streaming程序,在8888端口输入顾客所点的菜单数据,如“3 红烧茄子15”,查看顾客本次点餐的总费用。
启动prizeSum.py程序:
spark-submit prizeSum.py localhost 8888


五、Flume的安装配置
Flume是非常流行的日志采集系统,可以作为Spark Streaming的高级数据源。请到Flume官网下载Flume安装文件(版本不限),并将其安装到你的系统中。要求把Flume Source设置为netcat类型,从终端上不断给Flume Source发送各种消息,Flume把消息汇集到Sink(这里把Sink类型设置为avro),由Sink把消息推送给Spark Streaming,由自己编写的Spark Streaming应用程序对消息进行处理。
1、安装Flume
(1)下载Flume:
到Flume官网下载Flume1.7.0安装文件,下载地址如下:
http://www.apache.org/dyn/closer.lua/flume/1.7.0/apache-flume-1.7.0-bin.tar.gz
下载完成后上传到虚拟机的“/usr/local/uploads”目录下。
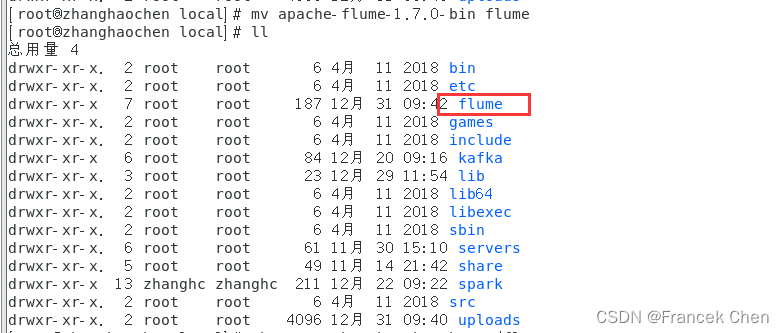
(2)解压安装包:
首先进入到“uploads”目录下。
tar -zxvf apache-flume-1.7.0-bin.tar.gz -C /usr/local #解压到“/usr/local”目录下
cd /usr/local
mv apache-flume-1.7.0-bin flume #将解压的文件修改名字为flume,简化操作
chown -R hadoop:hadoop ./flume #把/usr/local/flume目录的权限赋予当前登录Linux系统的用户,这里假设是hadoop用户
(3)配置环境变量:
首先,修改/etc/profile配置文件:
vi /etc/profile
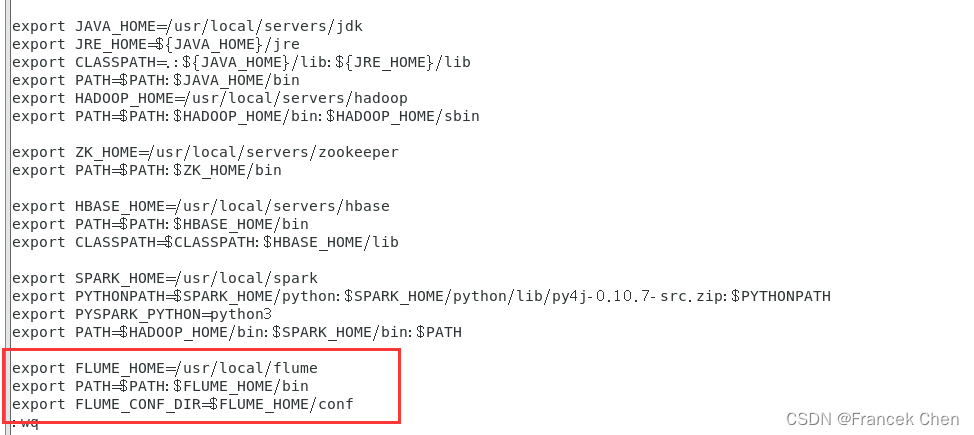
export FLUME_HOME=/usr/local/flume
export PATH=$PATH:$FLUME_HOME/bin
export FLUME_CONF_DIR=$FLUME_HOME/conf
使文件生效:
source /etc/profile
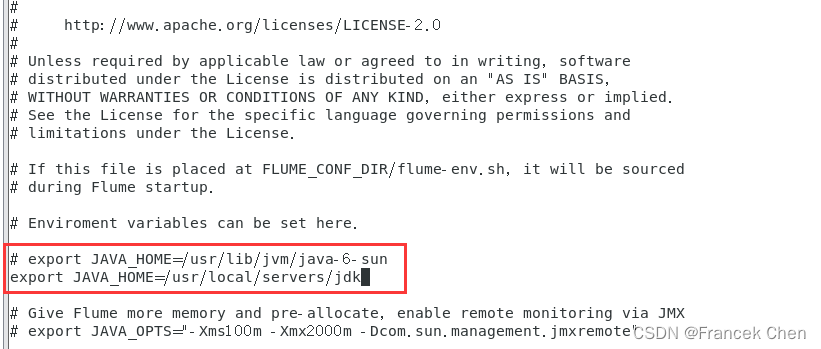
下面修改 flume-env.sh 配置文件:
cd /usr/local/flume/conf
cp flume-env.sh.template flume-env.sh
vi flume-env.sh

在文件中增加一行内容,用于设置JAVA_HOME变量:
export JAVA_HOME=/usr/local/servers/jdk
然后,保存flume-env.sh文件,并退出vim编辑器。
(4)查看Flume版本信息:
cd /usr/local/flume
./bin/flume-ng version

2、使用Flume作为Spark Streaming数据源
(1)在“/usr/local/flume/conf”目录下创建两个conf文件:
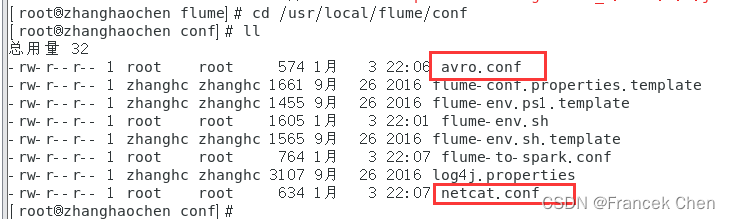
#/usr/local/flume/conf/avro.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
#注意这个端口名,在后面的教程中会用得到
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
#/usr/local/flume/conf/netcat.conf
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 44444
#同上,记住该端口名
# Describe the sink
a1.sinks.k1.type = logger
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
(2)Spark准备工作:
首先,到官网下载spark-streaming-flume_2.11-2.3.4.jar:
https://mvnrepository.com/artifact/org.apache.spark/spark-streaming-flume
上面的网址要是打不开,可以用下面的这个网址:
https://repo1.maven.org/maven2/org/apache/spark/spark-streaming-flume_2.11

把这个jar文件放到“/usr/local/spark/jars/flume”目录下。
cd /usr/local/spark/jars
mkdir flume
cd flume
cp /usr/local/uploads/spark-streaming-flume_2.11-2.3.4.jar .

然后,修改spark目录下conf/spark-env.sh文件中的SPARK_DIST_CLASSPATH变量。把flume的相关jar包添加到此文件中。
cd /usr/local/spark/conf
vi spark-env.sh
:/usr/local/spark/jars/flume/*:/usr/local/flume/lib/*
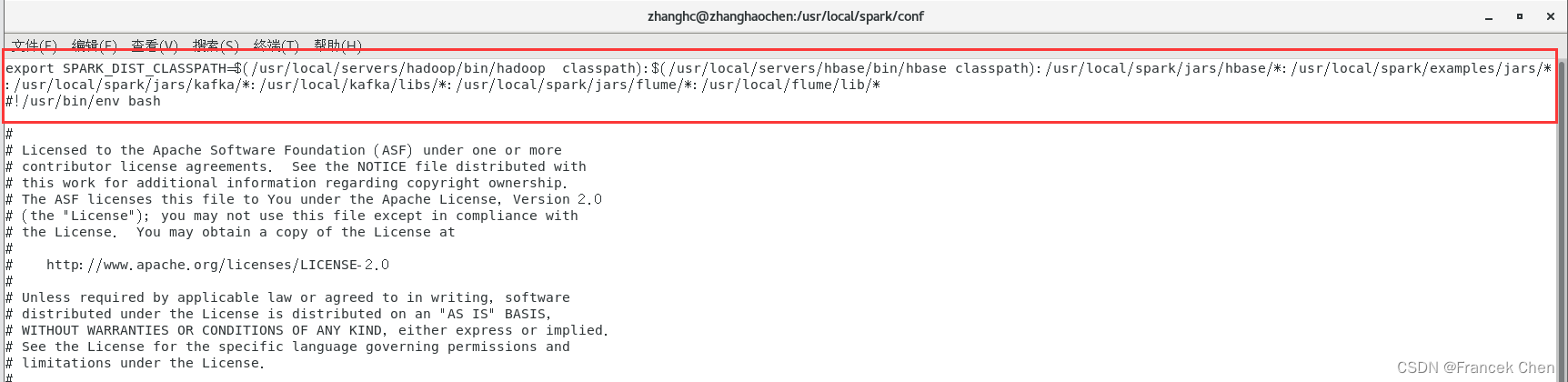
这样,Spark环境就准备好了。
(3)创建flume-to-spark.conf
cd /usr/local/flume/conf
vi flume-to-spark.conf
#flume-to-spark.conf: A single-node Flume configuration
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = netcat
a1.sources.r1.bind = localhost
a1.sources.r1.port = 33333
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = localhost
a1.sinks.k1.port =44444
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 1000000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
#说明:
1、Flume suorce类为netcat,绑定到localhost的33333端口,消息可以通过telnet localhost 33333 发送到flume suorce
2、Flume Sink类为avro,绑定44444端口,flume sink通过localhost 44444端口把消息发送出来。而spark streaming程序一直监听44444端口。
#注意!!先不要启动Flume agent,因为44444端口还没打开,sink的消息无处可去,44444端口由spark streaming程序打开。
(4)编写Spark程序使用Flume数据源
A、创建python文件
cd /home/zhanghc/sparkcode
mkdir flume
cd flume
vi FlumeEventCount.py
在FlumeEventCount.py中输入以下代码:
#/home/zhanghc/sparkcode/flume/FlumeEventCount.py
from __future__ import print_function
import sys
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
from pyspark.streaming.flume import FlumeUtils
import pyspark
if __name__ == "__main__":
if len(sys.argv) != 3:
print("Usage: flume_wordcount.py <hostname> <port>", file=sys.stderr)
exit(-1)
sc = SparkContext(appName="FlumeEventCount")
ssc = StreamingContext(sc, 2)
hostname= sys.argv[1]
port = int(sys.argv[2])
stream = FlumeUtils.createStream(ssc, hostname, port,pyspark.StorageLevel.MEMORY_AND_DISK_SER_2)
stream.count().map(lambda cnt : "Recieve " + str(cnt) +" Flume events!!!!").pprint()
ssc.start()
ssc.awaitTermination()
B、测试运行效果
注意:可能需要安装pyspark,命令为:
pip3 install pyspark

首先,启动Spark streaming程序:
./bin/spark-submit --driver-class-path /usr/local/spark/jars/*:/usr/local/spark/jars/flume/* /home/zhanghc/sparkcode/flume/FlumeEventCount.py localhost 44444
然后,启动一个新的终端,启动Flume Agent:
cd /usr/local/flume
bin/flume-ng agent --conf ./conf --conf-file ./conf/flume-to-spark.conf --name a1 -Dflume.root.logger=INFO,console
最后,再启动一个新的终端连接33333端口:
先要安装telnet:
yum install telnet
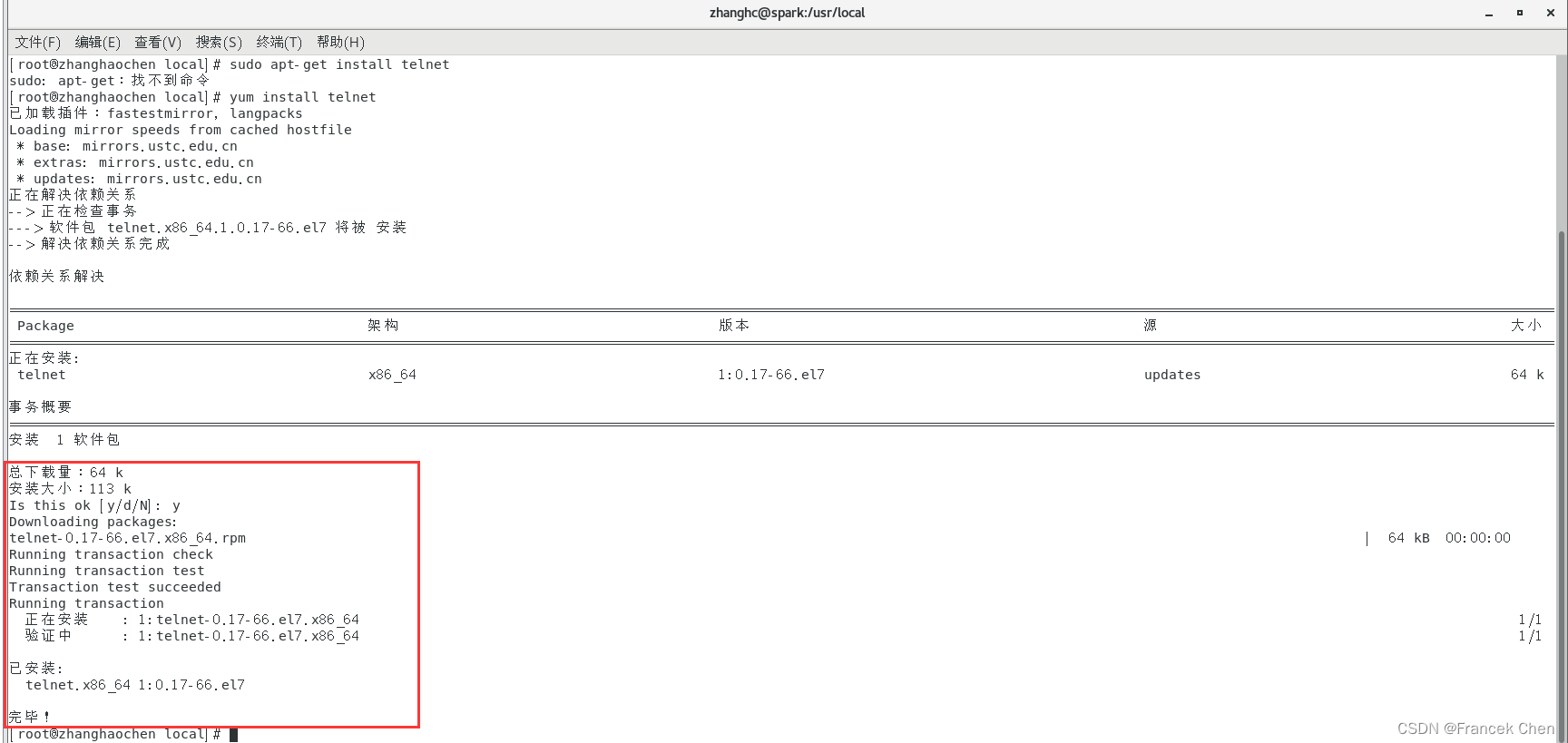
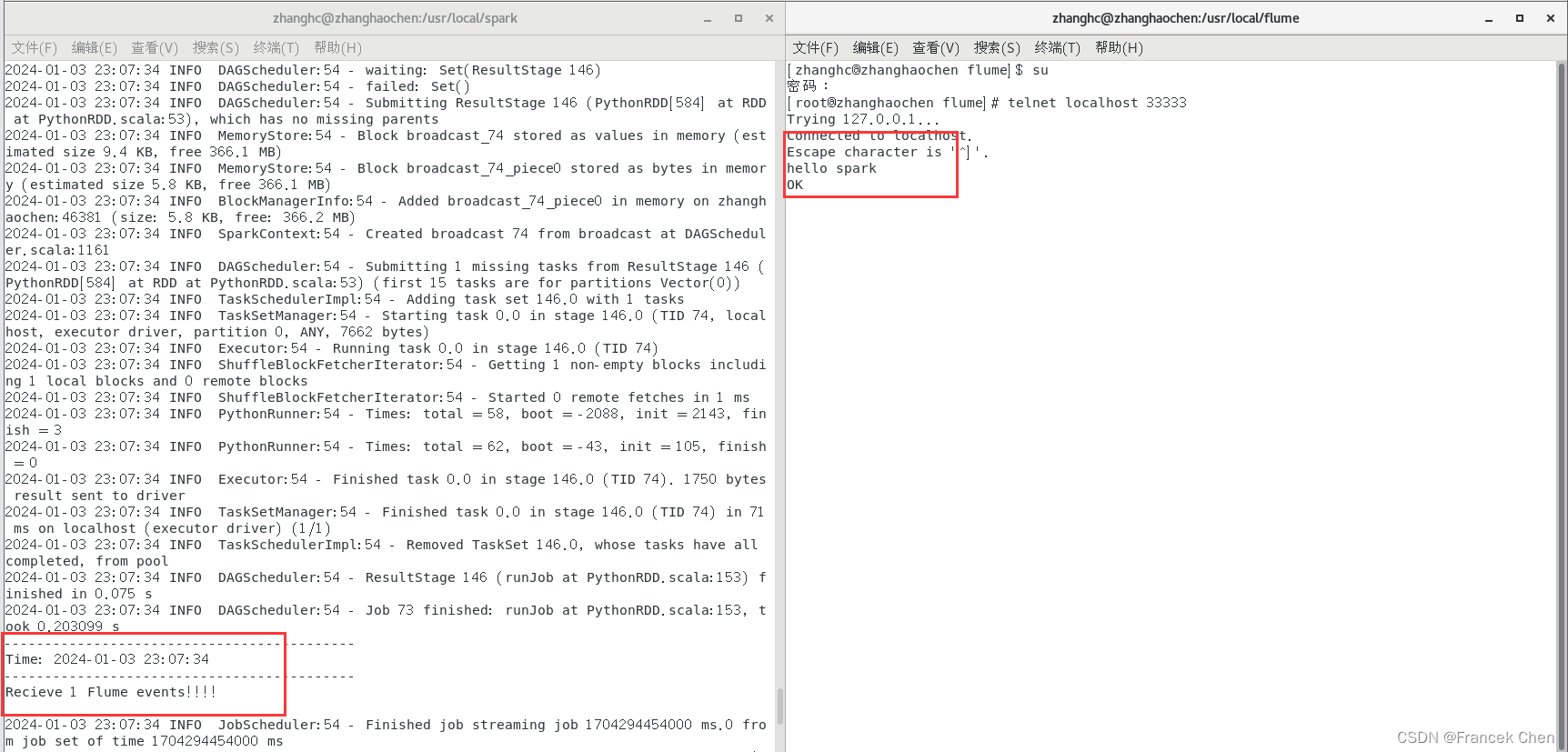
最后输入命令连接33333端口:
telnet localhost 33333
现在你可以在最后这个终端里输入一些字符了。在你输入字符后可以看到第一个终端会显示如下的信息:
-------------------------------------------
Time: 1488029430000 ms
-------------------------------------------
Received 1 flume events!!!
版权归原作者 Francek Chen 所有, 如有侵权,请联系我们删除。