
学习Elasticsearch这一篇就够了
一、ES介绍
Elasticsearch是一个基于Apache Lucene的开源搜索引擎。Lucene可以被认为是迄今为止最先进、性能最好的、功能最全的搜索引擎库。 特点: 分布式的实时文件存储,每个字段都被索引并可被搜索 分布式的实时分析搜索引擎–做不规则查询 可以扩展到上百台服务器,处理PB级结构化或非结构化数据 Elasticsearch也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
二、单体ES安装
1.ES下载
ES官网:ElasticSearch官网
2.安装
1.上传后解压

解压命令:
tar -zxvf elasticsearch-7.4.2-linux-x86_64.tar.gz
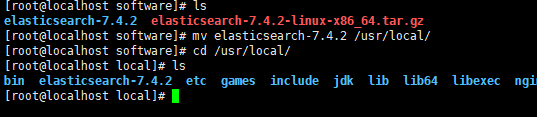
移动解压后的文件到/usr/local/目录下:
mv elasticsearch-7.4.2 /usr/local/
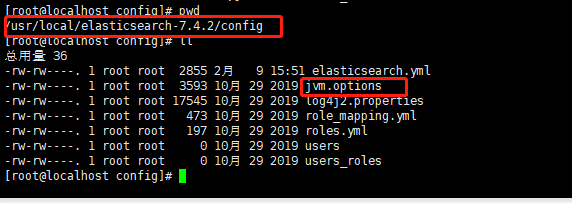
2.ES目录介绍
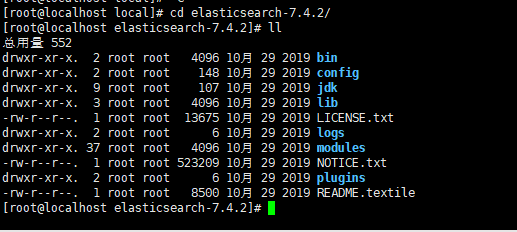
- bin:可执行文件在里面,运行es的命令就在这个里面,包 含了一些脚本文件等
- config:配置文件目录
- jdk:java环境
- lib:依赖的jar,类库
- logs:日志文件
- modules:es相关的模块
- plugins:可以自己开发的插件
- data:这个目录没有,自己新建一下,后面要用->mkdir data,这个作为索引目录
3.修改核心配置文件elasticearch.yml
- 修改集群名称,默认是elasticsearch,虽然目前是单机,但 是也会有默认的
- 为当前的s节点取个名称,名称随意,如果在集群环境中, 都要有相应的名字
vim config/elasticsearch.yml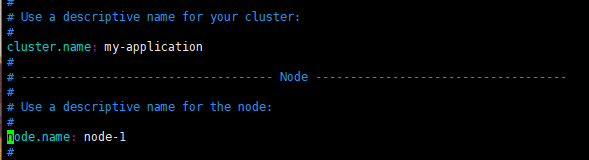
- 修改data数据保存地址
- 修改日志数据保存地址
/usr/local/elasticsearch-7.4.2/data`````` /usr/local/elasticsearch-7.4.2/logs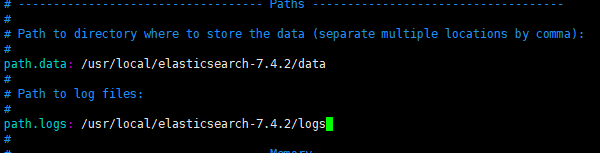
- 绑定es网络ip,原理同redis
- 默认端口号,可以自定义修改

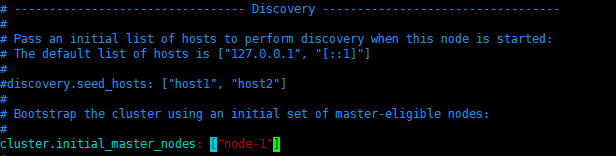
- 集群节点,名字可以先改成之前的那个节点名称
4.修改JVM参数
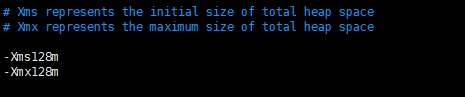
默认xms和xmx都是1g,虚拟机内存没这么大,修改一下即可,线上环境内存大可以不修改!
5.添加用户
ES不允许使用root操作es,需要添加用户,操作如下:
#添加用户
useradd esuser
#授权
chown -R esuser:esuser /usr/local/elasticsearch-7.4.2
su esuser
whoami
6.启动ES
./elasticsearch
如果出现如下错误:
那么需要切换到oot用户下去修改配置如下:
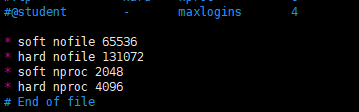
vim /etc/security/limits.conf
* soft nofile 65536
* hard nofile 131072
* soft nproc 2048
* hard nproc 4096
vim /etc/sysctl.conf
vm.max_map_count=262145

别忘记
sysctl -p
刷新一下
最后再次启动OK
7.测试
访问你的虚拟机ip+端口号9200,如下则表示OK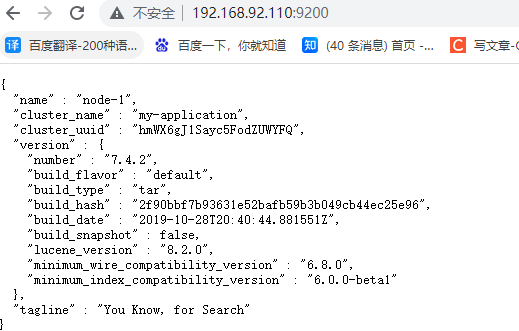
停止es
如果是前台启动,直接ctrl+c就可以停止
后台启动:
./elasticsearch -d
停止杀进程:
jps
kill+进程号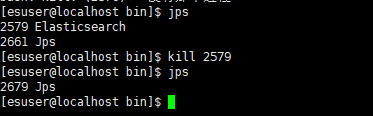
端口号意义
- 9200:Http协议,用于外部通讯
- 9300:Tcp协议,ES集群之间是通过9300通讯
三、Elasticsearch 集群构建
1. 先进行克隆三台服务器
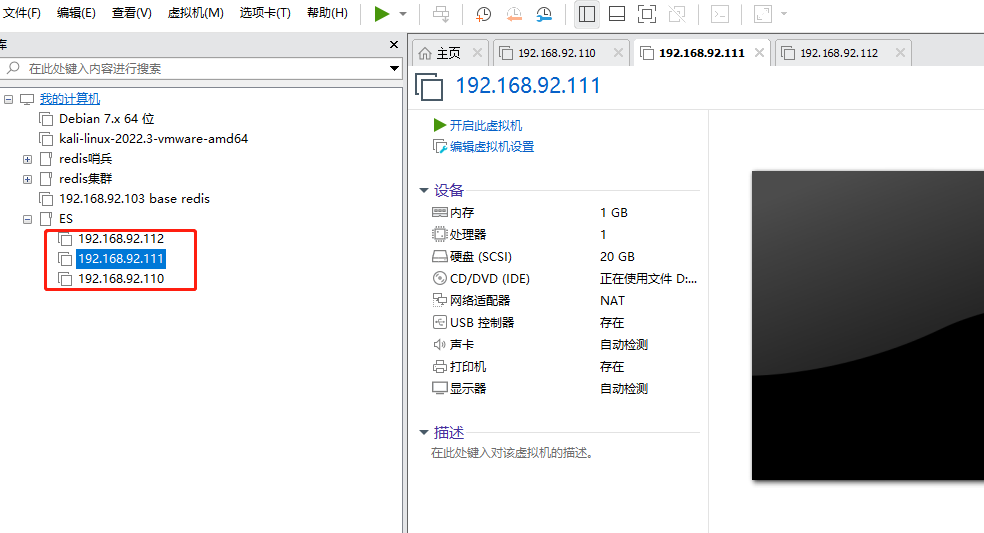
2. 搭建es集群
环境准备
HOSTNAMEIPes01192.168.92.110es02192.168.92.111es03192.168.92.112
2.1 分别对三台服务器(es01, es02, es03 )做如下操作
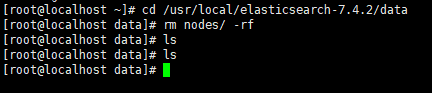
进入es的data目录下, 删除nodes数据
cd /usr/local/elasticsearch-7.4.2/data
rm nodes/ -rf
2.2 操作三台服务器(es01, es02, es03 节点)
操作config文件, 修改ES核心配置文件中的cluster的name值为同一个
- 即修改cluster.name为: my-application
- 分别修改 node.name为:es-node1, es-node2, es-node3
vim /usr/local/elasticsearch-7.4.2/config/elasticsearch.yml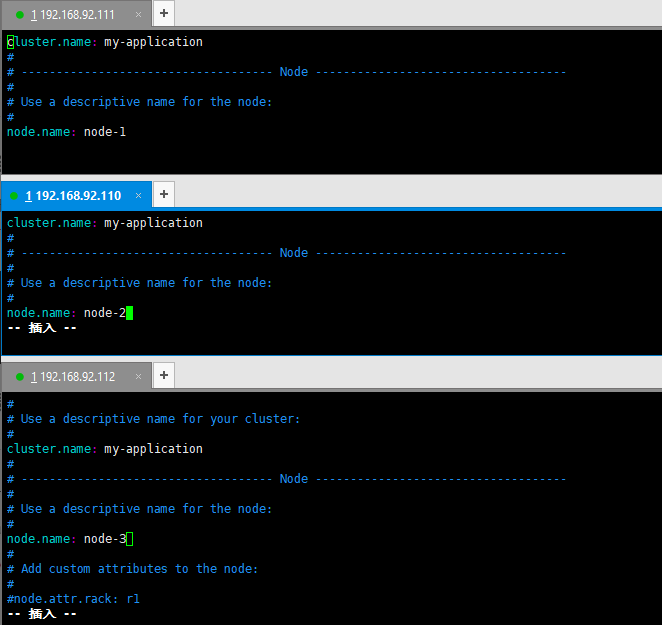
- 三台都开启master, data master: 表示在未来可以成为master节点 data: 用来存储文档数据
node.master: true
node.data: true
- 三台都进行配置节点信息.
discovery.seed_hosts: ["192.168.92.110", "192.168.92.111","192.168.92.112"]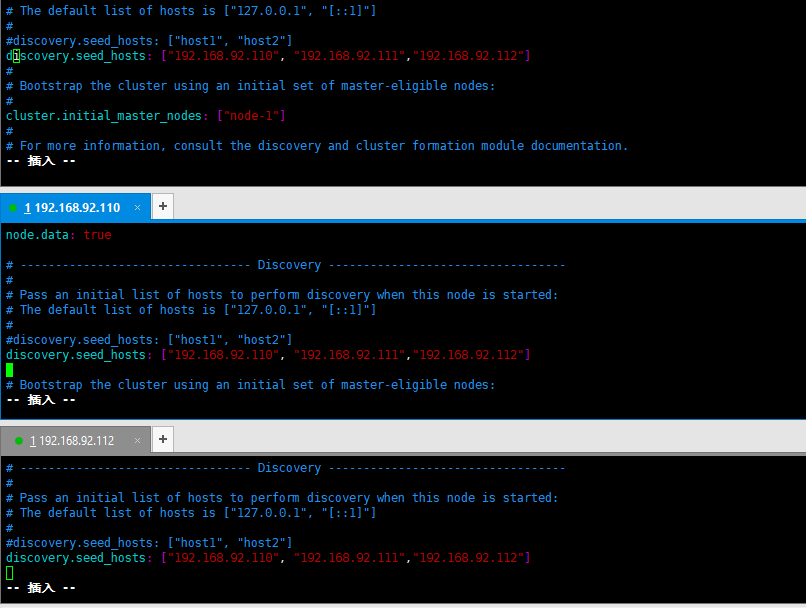
2.3 查看配置信息
cd /usr/local/elasticsearch-7.4.2/config/more elasticsearch.yml | grep ^[^#]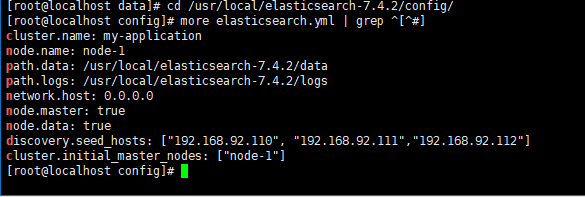
2.4 启动ES集群
分别进入用户 esuser
su esuser
./usr/local/elasticsearch-7.4.2/bin/elasticsearch
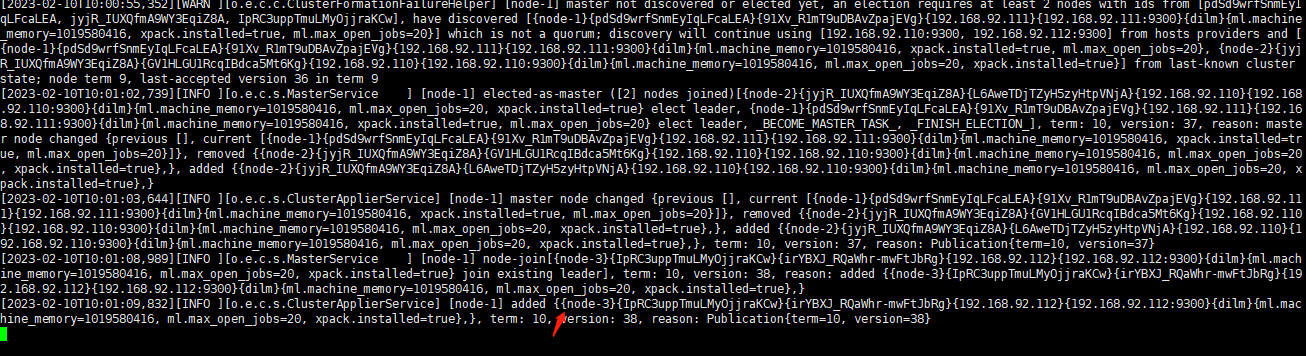
2.5 测试ES集群
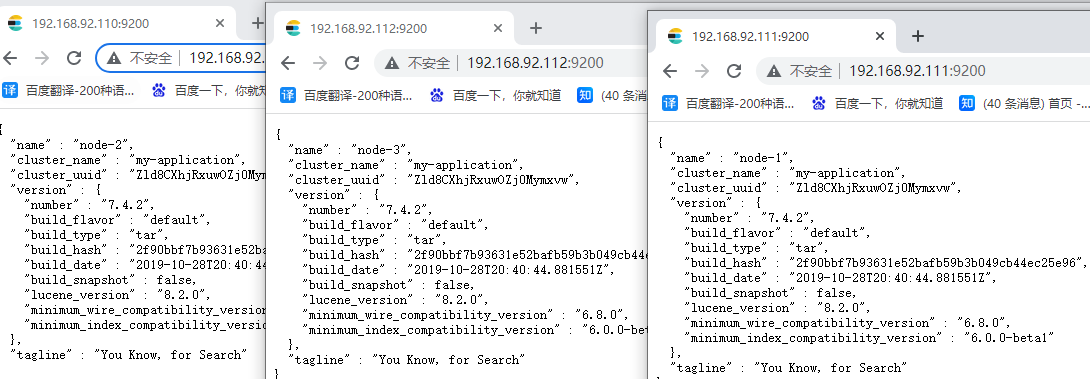
四、ik中文分词器
安装ik
ik中文分词器和ES版本需要一致,安装方法一样
1. 安装ik中文分词器(6.4.3版本)
上传zip文件到我们的服务器
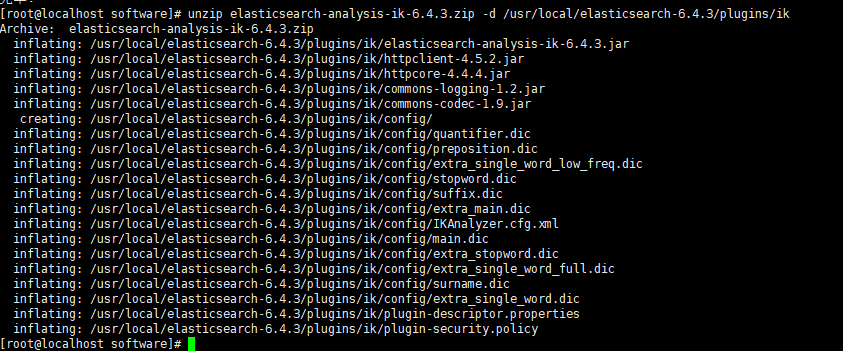
2. 解压并放在elasticsearch的plugins的ik文件夹下
yum install -y unzip zip
安装zip工具,已安装可跳过
unzip elasticsearch-analysis-ik-6.4.3.zip -d /usr/local/elasticsearch-6.4.3/plugins/ik
3.进入ES的ik目录下
cd /usr/local/elasticsearch-6.4.3/plugins/ik
4.重新启动ES
jps
kill ***
su esuser
cd /usr/local/elasticsearch-6.4.3/bin
./elasticsearch -d
使用ik中文分词器
2.1 分词器: ik_max_word
此分词器会将文本进行最细粒度的拆分, 比如将"中华人民共和国国歌"
拆分为"中华人民共和国",“中华人民”,“中华”,“华人”,“人民共和国”,“人民”,“人”,“民”,“共和国”,“共和”,“和”,“国国”,“国歌”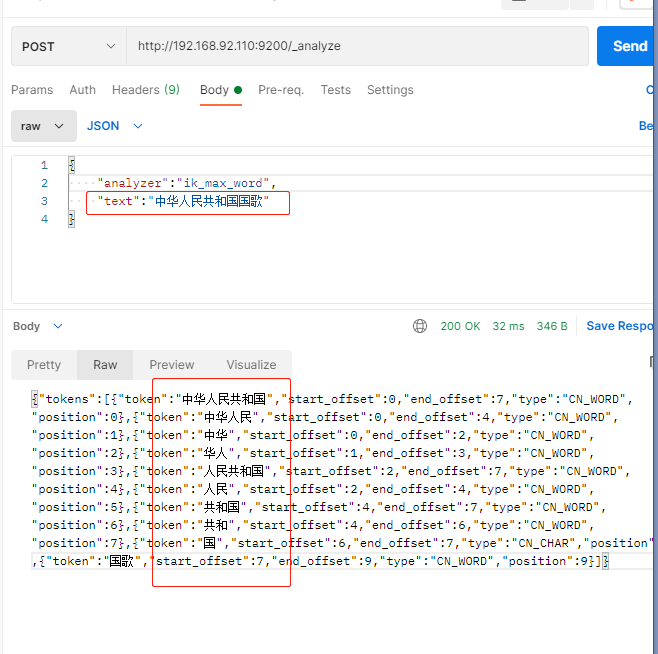
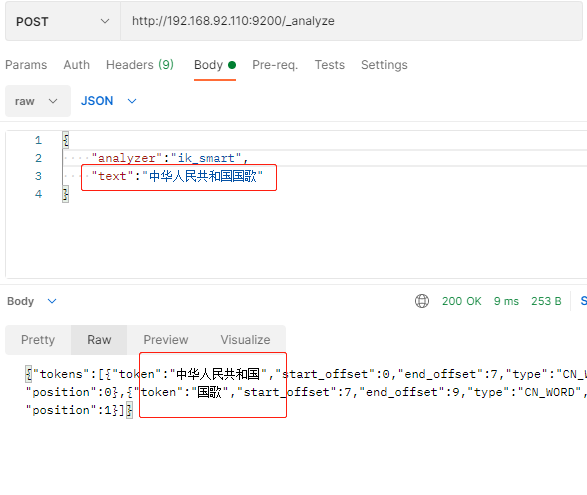
2.1 分词器: ik_smart
此分词器会将文本进行最粗粒度的拆分.
五、logstash 数据同步
1. logstash 简介
Logstash是一个开源数据收集引擎,具有实时管道功能。Logstash可以动态地将来自不同数据源的数据统一起来,并将数据标准化到你所选择的目的地。
Logstash是一个开源的服务器端数据处理管道,可以同时从多个数据源获取数据,并对其进行转换,然后将其发送到你最喜欢的“存储”。(当然,最喜欢的是Elasticsearch)
数据采集: 可以从数据库中采集到 Elasticsearch
以 自增id(不建议, 会无法识别修改的数据) 或者 update_time 作为同步的边界
可以通过新版 Elasticsearch 所集成的插件 logstash-input-jdbc 直接使用
使用logstash时候要与 Elasticsearch 的版本号保持一致
2. logstash 安装
2.1 (前提是安装好jdk)上传logstash, mysql驱动

2.2 logstash 同步配置
- 解压logstash:
tar -zxvf logstash-6.4.3.tar.gz - 移动 logstash:
mv logstash-6.4.3 /usr/local/ - 进入该目录:
cd /usr/local/logstash-6.4.3/ - 创建文件夹sync, 将相关的同步配置放在该文件夹下:
mkdir sync - 创建配置文件(后面会进行编辑, 这里进行创建):
vim logstash-db-sync.conf
- 将数据库驱动进行拷贝到当前的目录下: cp /home/software/mysql-connector-java-5.1.41.jar .

- 创建sql存储文件: foodie-items.sql
SELECT i.id AS itemId, i.item_name AS itemName, i.sell_counts AS sellCounts, ii.url AS imgUrl, tempSpec.price_discount AS price, i.updated_time AS updated_timeFROM items iLEFTJOIN items_img iiON i.id = ii.item_idLEFTJOIN(SELECT item_id,MIN(price_discount) as price_discount FROM items_spec GROUPBY item_id ) tempSpecON i.id = tempSpec.item_idWHERE ii.is_main =1AND i.updated_time >=:sql_last_value - 进行修改配置文件 logstash-db-sync.conf:
vim logstash-db-sync.conf
input {
jdbc {
# 设置 MySql/MariaDB 数据库url以及数据库名称
jdbc_connection_string =>"jdbc:mysql://192.168.92.110:3306/foodie-shop-dev?useUnicode=true&characterEncoding=UTF-8&autoReconnect=true"
# 用户名和密码
jdbc_user =>"root"
jdbc_password =>"root"
# 数据库驱动所在位置,可以是绝对路径或者相对路径
jdbc_driver_library =>"/usr/local/logstash-6.4.3/sync/mysql-connector-java-5.1.41.jar"
# 驱动类名
jdbc_driver_class =>"com.mysql.jdbc.Driver"
# 开启分页
jdbc_paging_enabled =>"true"
# 分页每页数量,可以自定义
jdbc_page_size =>"1000"
# 执行的sql文件路径
statement_filepath =>"/usr/local/logstash-6.4.3/sync/foodie-items.sql"
# 设置定时任务间隔 含义:分、时、天、月、年,全部为*默认含义为每分钟跑一次任务
schedule =>"* * * * *"
# 索引类型
type =>"_doc"
# 是否开启记录上次追踪的结果,也就是上次更新的时间,这个会记录到 last_run_metadata_path 的文件
use_column_value =>true
# 记录上一次追踪的结果值
last_run_metadata_path =>"/usr/local/logstash-6.4.3/sync/track_time"
# 如果 use_column_value 为true, 配置本参数,追踪的 column 名,可以是自增id或者时间
tracking_column =>"updated_time"
# tracking_column 对应字段的类型
tracking_column_type =>"timestamp"
# 是否清除 last_run_metadata_path 的记录,true则每次都从头开始查询所有的数据库记录
clean_run =>false
# 数据库字段名称大写转小写
lowercase_column_names =>false}}
output {
elasticsearch {
# es地址
hosts =>["192.168.92.110:9200"]
# 同步的索引名
index =>"foodie-items"
# 设置_docID和数据库中的id保持相同
document_id =>"%{id}"
# document_id =>"%{itemId}"}
# 日志输出
stdout {
codec => json_lines
}}
2.3 启动logstash
进入bin目录:
cd /usr/local/logstash-6.4.3/bin
启动logstash:
./logstash -f /usr/local/logstash-6.4.3/sync/logstash-db-sync.conf
后台启动:
nohup ./logstash -f /usr/local/logstash-6.4.3/sync/logstash-db-sync.conf > logstash.log 2>&1 &
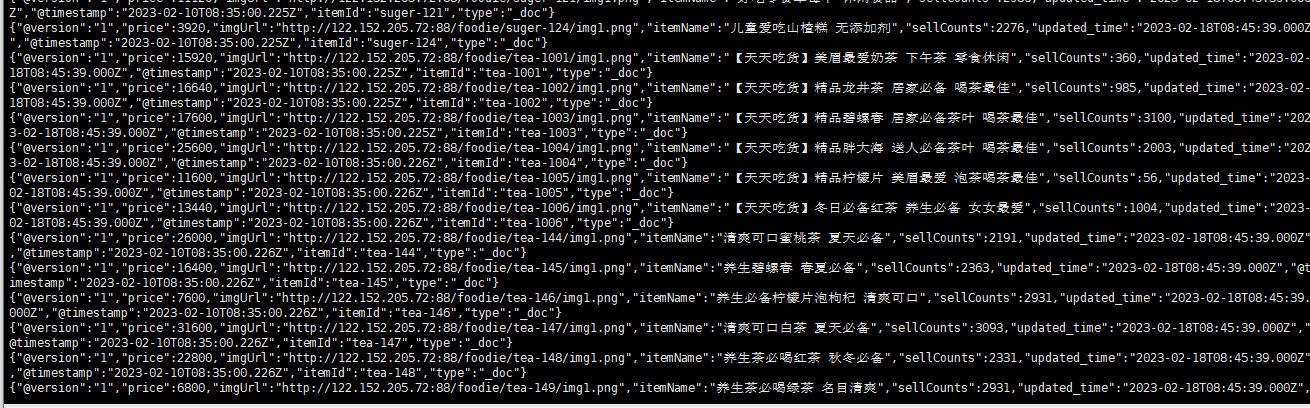
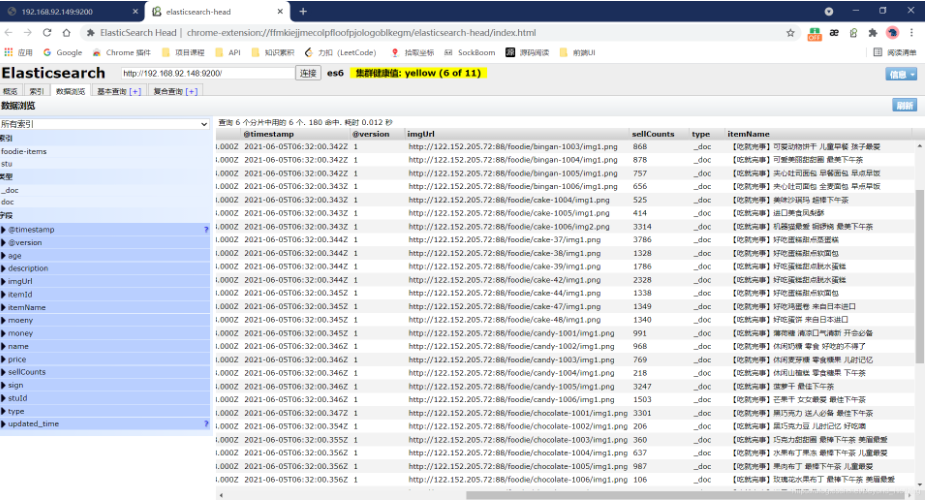
logstash 只对新增和修改的数据可以进行同步, 而对于数据库中删除的数据是不会进行同步到es中的.
所以数据库中删除的数据, 它在es中只是通过更新时间的方式进行逻辑上的删除.
六.安装 ElasticSearch 可视化插件: es-head
1. 下载并且解压es-header
es-header下载
2. 安装 node.js
node.js下载
下载完安装即可
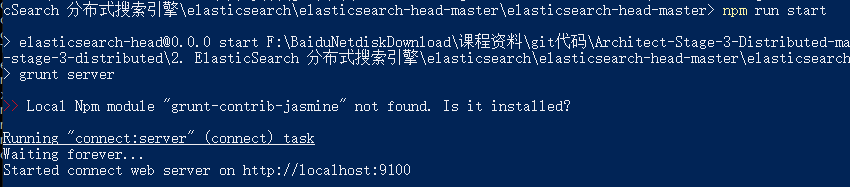
3. 在node.js中执行以下命令
进入es-header目录(在目录按shift右击,打开powershell窗口)
npm install

npm run start
4. 设置跨域
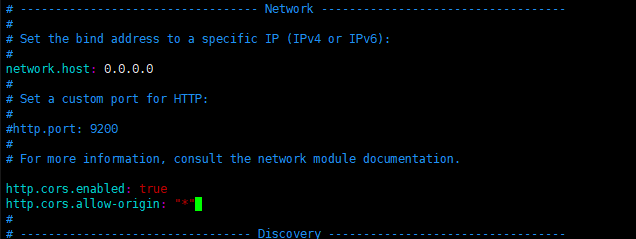
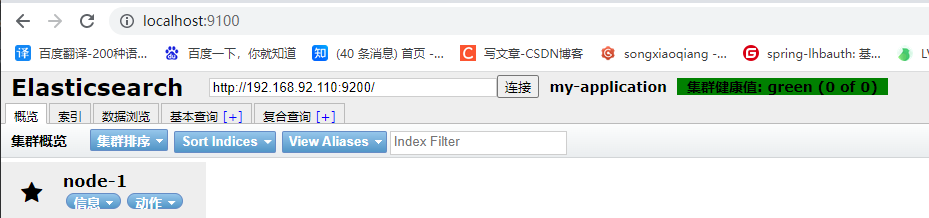
访问http://localhost:9100/ 发现跨域
- 进入 es 核心配置文件, elasticsearch.yml进行添加跨域配置如下
http.cors.enabled: true
http.cors.allow-origin: "*"
5. 测试
版权归原作者 哒不死的小小强 所有, 如有侵权,请联系我们删除。